QDKT4-3-设计AI产品:上下文工程和PRD
第一部分:AI产品的大模型嵌入形态
1.1 三种核心形态分类
AI产品中,大模型的嵌入形态决定了产品的核心运作逻辑,主要分为以下三类:
|
形态类型 |
核心定义 |
运作模式 |
应用场景 |
|
Copilot(辅助型) |
作为人类的辅助工具,仅供参考 |
人和AI同时参与生产流程,对比结果优化效率 |
文案撰写辅助、设计草图生成、代码辅助编写等 |
|
Embedding(节点型) |
作为产品流程中的独立关键节点 |
模型独立承担特定环节的任务,完成后交付给下一流程 |
合同关键信息提取、文档格式转换、数据清洗分类等 |
|
Agent(自主型) |
主导整个产品流程,自主完成全任务 |
AI自行拆解任务、调用工具、制定计划、验证结果 |
全自动调研报告生成、多步骤数据分析、智能客服全流程应答等 |
1.2 关键形态解析
(1)前两种形态的共性与本质
Copilot和Embedding本质上属于“工具化嵌入”,核心特点的是:
- 依赖API调用:需严格按照大模型要求的结构调用,随用随取
- 输入输出确定性强:根据明确的输出结果反推输入约束,逻辑简单
- 上下文工程=提示词约束+资料提供:仅需给模型明确任务边界和所需资料即可
(2)Agent形态的核心优势与发展前景
- 核心优势:随着国产大模型工具调用能力、指令依从能力的提升,能够自主处理复杂、长链条任务
- 发展预期:2026年上半年将成为大模型产品开发的主流形式
- 核心挑战:需解决模型的不确定性,提供更全面的上下文支持与任务管理机制
第二部分:上下文工程设计逻辑
上下文工程的核心是“明确模型需要什么信息,以及如何提供这些信息”,不同类型的AI产品,设计逻辑差异显著。
2.1 工具型产品(Copilot+Embedding):反推式设计
工具型产品的输出结果具有明确的结构化特征,因此采用“以终为始”的反推逻辑,步骤如下:
步骤1:明确结构化输出形态
先定义产品最终要交付的结果是什么,且该结果需具备清晰的结构。
- 示例1(PPT生成工具):输出是“标题+序号+三大板块+子标题+文本”的结构化PPT页面
- 示例2(合同审阅工具):输出是“定位信息(行号+字符位置)+批注文本+批注维度(商务/法律)+风险说明+修改建议”的结构化批注
步骤2:反推所需结构化输入
根据输出结构,确定支撑该输出所需的结构化信息。
- 示例1(PPT生成工具):需输入“大纲+目标页面主题+模板规范+序号/类型/内容等结构化文本”
- 示例2(合同审阅工具):需输入“完整合同文本+审阅维度要求+风险判断标准”
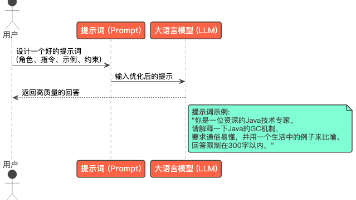
步骤3:设计提示词约束
通过提示词明确模型的角色、任务、参考资料和输出格式,示例如下:
|
Plain Text |
2.2 Agent型产品:全流程支持设计
Agent型产品需自主完成长链条任务,上下文工程更复杂,核心包含三大模块:
(1)提示词设计:泛化+使命对齐
- 核心原则:不严格限定步骤,而是明确最终使命,提升模型泛化能力
- 示例(调研报告生成Agent):“你是专业的行业研究助手,需基于用户提供的主题,完成从关键词检索、资料筛选、数据分析到报告撰写的全流程工作,最终交付一份结构清晰、数据准确的行业调研报告”
- 关键要素:任务使命(抽象拔高)、任务拆解要求(生成todo list)、验证策略(步骤验证+最终结果验证)
(2)工具矩阵配置
需明确告知模型可使用的工具及使用规则,包含:
- 工具的使用场景:什么环节需要用什么工具(如“检索环节使用关键词搜索工具”)
- 工具的输入输出:工具的必填参数、返回结果格式(如“搜索工具输入:关键词;输出:相关文献链接+摘要”)
(3)记忆管理机制
针对超长任务(如百万字资料处理),需设计记忆管理方案:
- 过程产物存储:将中间结果(如检索文献)转化为链接,避免模型全程携带大量文本
- 交互上下文保留:记录人类与AI的交互历史,必要时进行压缩和规则提炼
- 任务状态追踪:记录每个步骤的完成情况,支持模型回溯和调整
第三部分:AI产品PRD专属框架与撰写
传统PRD已无法满足AI产品需求,需新增针对模型的核心模块,形成专属框架。
3.1 AI产品PRD核心框架
|
模块 |
核心内容 |
与传统PRD的差异 |
|
基础模块(保留) |
需求背景、产品定位、目标用户、业务目标 |
无差异,用于统一共识 |
|
用户故事(保留) |
描述用户在什么场景下,为达成什么目标需要产品支持 |
需结合AI产品的交互特点(如“用户仅需输入一句话需求”) |
|
新增模块1:模型故事 |
每个Agent的激活场景、目标、所需输入/输出、作业流程 |
传统PRD无此模块,核心解决“模型需要什么”的问题 |
|
新增模块2:Agent工作流 |
Agent的任务拆解逻辑、步骤时序、数据流转路径 |
替代传统“用户旅程”,明确模型的全流程运作方式 |
|
新增模块3:提示词设计 |
核心Agent的提示词文本、设计理由、版本迭代记录 |
传统PRD无,是AI产品的核心约束 |
|
新增模块4:评估与测试数据集 |
测试用例、评估标准、数据集来源(用户故事模拟、竞品调研等) |
针对模型的不确定性,需全新的测试体系 |
|
功能清单(优化) |
大模型相关功能模块、任务约束、输入输出规范 |
需明确与模型相关的功能细节 |
|
异常处理(强化) |
模型出错后的降级策略、重试机制、交互优化 |
需应对模型的随机性错误 |
|
非功能性需求(保留) |
安全防护(防注入)、性能要求等 |
无本质差异,需兼顾AI模型的特性 |
|
术语定义 |
核心AI术语、模型相关概念解释 |
新增AI领域专属术语说明 |
3.2 核心模块撰写详解
(1)模型故事撰写
需为每个Agent单独撰写,核心要素:
- 激活场景:什么情况下该Agent会被触发(如“前台接待Agent:用户输入非检索类闲聊内容时激活”)
- 核心目标:该Agent需完成的具体任务(如“前台接待Agent:判断用户意图,区分闲聊与检索需求”)
- 输入需求:需要哪些上下文信息(如“用户输入文本、意图识别标准”)
- 输出结果:交付什么内容(如“闲聊回复/检索需求确认信息”)
- 依赖支持:需要调用的工具或其他Agent(如“无需调用工具,独立完成判断”)
(2)Agent工作流设计
- 核心交付物:流程图+时序图
- 流程图:展示Agent之间的协作关系、用户与产品的交互节点
- 时序图:明确数据在不同Agent之间的流转顺序、技术支持要求
- 示例(调研报告生成Agent工作流):
- 前台接待Agent:接收用户需求→判断为检索类需求→传递给Planner Agent
- Planner Agent:拆解任务(关键词生成→检索→数据分析→报告撰写)→生成todo list→依次触发对应Agent
- Researcher Agent:根据关键词调用搜索工具→筛选有效资料→传递给Data Analyst Agent
- Data Analyst Agent:分析资料数据→提取核心结论→传递给Reporter Agent
- Reporter Agent:撰写结构化报告→反馈给用户→触发Human Feedback Agent
- Human Feedback Agent:收集用户修改意见→调整报告
(3)提示词设计撰写
- 核心要求:
- 直接写入PRD,避免由技术人员撰写(产品经理更懂交互灵活性)
- 包含提示词文本、设计理由、版本迭代记录
- 关键Agent需单独设计提示词,同时包含提示词增强方案(如用户输入不清晰时的补充规则)
- 撰写示例:
|
Plain Text |
(4)评估与测试数据集
- 数据集来源:用户故事模拟、竞品调研、实际测试场景
- 核心要求:
- 测试用例需覆盖正常场景与异常场景(如用户输入模糊、工具调用失败等)
- 明确评估标准(如准确率≥90%、任务完成时长≤3分钟)
- 数据结构需适配模型的输入输出格式
- 示例(合同审阅Agent测试用例):
|
测试场景 |
输入内容 |
预期输出 |
评估标准 |
|
正常场景 |
包含“未明确服务期限”的订阅合同 |
标注对应位置+法律性风险+补充服务期限的建议 |
定位准确、风险判断正确、建议可行 |
|
异常场景 |
无实质条款的空白合同 |
提示“合同无有效条款,无法审阅” |
识别异常并给出合理反馈 |
3.3 关键注意事项
- 提示词语言选择:大型项目优先使用英文,因模型训练语料中英文占比极高(95%以上),控制效果更优
- 版本管理:提示词需记录迭代版本、时间、修改原因,便于追溯
- 异常处理:明确模型出错后的兜底策略(如重试3次失败则切换人工服务、等待超时提示用户)
- 非功能性需求:重点关注AI安全(防提示词注入、数据隐私保护)
课程总结
AI产品设计的核心在于“理解模型特性+适配产品逻辑”,本节课重点掌握:
- 三种大模型嵌入形态的应用场景与差异
- 工具型产品的反推式上下文设计与Agent型产品的全流程支持设计
- AI产品PRD的专属框架,尤其是模型故事、提示词设计等核心模块

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)