YOLOv8【第十三章:模型压缩与极致优化篇·第13节】RepVGG 重参数化技术:训练时多路,推理时单路!
🏆 本文收录于 《YOLOv8实战:从入门到深度优化》 专栏。该专栏系统复现并梳理全网各类 YOLOv8 改进与实战案例(当前已覆盖分类 / 检测 / 分割 / 追踪 / 关键点 / OBB 检测等方向),坚持持续更新 + 深度解析,质量分长期稳定在 97 分以上,可视为当前市面上 覆盖较全、更新较快、实战导向极强 的 YOLO 改进系列内容之一。
部分章节也会结合国内外前沿论文与 AIGC 等大模型技术,对主流改进方案进行重构与再设计,内容更偏实战与可落地,适合有工程需求的同学深入学习与对标优化。
✨ 特惠福利:当前限时活动一折秒杀,一次订阅,终身有效,后续所有更新章节全部免费解锁,👉 点此查看详情
🎯 本文定位:计算机视觉 × 模型压缩与极致优化系列
📅 更新时间:2026年
🏷️ 难度等级:⭐⭐⭐⭐⭐(高级进阶)
🔧 技术栈:Python 3.9+ · PyTorch · YOLOv8 · ByteTrack · OpenCV · NumPy
全文目录:
📖 上期回顾
上一节《YOLOv8【第十三章:模型压缩与极致优化篇·第12节】混合精度量化:如何平衡 FP16 与 INT8 层以保持精度!》内容中,我们深入探讨了混合精度量化的核心思想与工程实践。量化并非"一刀切"的过程,不同层对精度损失的敏感程度截然不同:
- FP16 层:适用于对精度敏感的首层卷积、最后的检测头(Detection Head)以及激活函数前后的关键节点,保留高精度以维持模型的表达能力。
- INT8 层:适用于中间大量的卷积计算层,通过 8 位整数运算大幅降低内存占用与推理延迟,在 TensorRT、ONNX Runtime 等推理框架中获得显著加速。
- 校准数据集:PTQ(训练后量化)的精度恢复关键在于校准集的代表性,我们介绍了 MinMax、Entropy、Percentile 三种校准策略的适用场景。
- 敏感层分析:通过逐层量化误差分析(Layer-wise Sensitivity Analysis),自动识别哪些层不适合 INT8,从而制定混合精度策略。
- 实战结论:YOLOv8 在 COCO 数据集上,合理的混合精度量化可将模型体积压缩约 50%,推理速度提升 2~3 倍,mAP 损失控制在 0.5% 以内。
如果你还没有掌握量化的基础知识,强烈建议先回顾第10节(QAT)和第11节(PTQ),再来学习本节内容,这样对整个压缩体系的理解会更加完整。
🔮 本节导读
本节我们将深入学习一项极具工程价值的技术——RepVGG 重参数化(Re-Parameterization)。
这项技术的核心哲学非常优雅:训练时用复杂的多分支结构获得更强的表达能力,推理时将多分支等价合并为单一卷积,获得极致的推理速度。 这种"鱼与熊掌兼得"的设计思路,已经被广泛应用于 YOLOv6、YOLOv7、YOLOv8 等主流检测框架中。
学完本节,你将掌握:
- RepVGG 的设计动机与数学原理
- 结构重参数化的等价变换推导过程
- 从零实现 RepVGG Block 并验证等价性
- 在 YOLOv8 中集成 RepConv 模块
- 重参数化前后的性能对比实验
一、为什么需要重参数化?从 VGG 说起 🤔
1.1 VGG 的辉煌与局限
2014 年,牛津大学 VGG 团队提出的 VGGNet 以其简洁的 3×3 卷积堆叠结构震惊了整个深度学习界。VGG 的设计哲学极为朴素:用统一的 3×3 卷积核,通过深度堆叠来提升模型容量。
VGG 的优点显而易见:
- 结构规整,推理时无分支,硬件友好
- 3×3 卷积在 GPU/NPU 上有高度优化的 BLAS 实现
- 内存访问模式简单,缓存命中率高
但 VGG 也有明显的缺陷:
- 参数量巨大(VGG-16 约 138M 参数)
- 训练时梯度消失问题严重
- 缺乏跳跃连接,特征复用能力弱
1.2 ResNet 的跳跃连接:精度提升的秘密
2015 年,ResNet 引入了残差连接(Skip Connection),彻底解决了深层网络的训练问题。残差块的结构如下:
y = F ( x , W i ) + x y = F(x, {W_i}) + x y=F(x,Wi)+x
其中 F ( x ) F(x) F(x) 是残差映射, x x x 是恒等映射(Identity Shortcut)。这个简单的加法操作带来了巨大的精度提升,原因在于:
- 梯度高速公路:梯度可以直接通过恒等映射反向传播,缓解梯度消失
- 特征复用:浅层特征可以直接传递到深层,丰富特征表示
- 隐式集成:残差网络可以被理解为多个浅层网络的集成
但残差连接也带来了推理时的额外开销:多分支结构需要额外的内存带宽,在某些硬件(尤其是 NPU、DSP)上,分支结构会破坏流水线,导致推理效率下降。
1.3 核心矛盾:训练精度 vs 推理速度
这就引出了深度学习工程中的一个核心矛盾:
训练时:多分支 > 单分支(精度更高)
推理时:单分支 > 多分支(速度更快)
传统的解决思路是"二选一":要么用多分支网络训练,接受推理时的速度损失;要么用单分支网络,接受训练时的精度损失。
RepVGG 的天才之处在于:这两者并不矛盾。 通过数学等价变换,可以在训练结束后,将多分支结构无损地合并为单分支结构,实现"训练时多路,推理时单路"的完美平衡。
二、RepVGG 的整体架构设计 🏗️
2.1 论文背景
RepVGG 由清华大学丁霄汉等人于 2021 年提出,论文标题为《RepVGG: Making VGG-style ConvNets Great Again》。论文的核心贡献是提出了**结构重参数化(Structural Re-Parameterization)**的概念,并将其系统化为一套通用的网络设计方法论。
2.2 训练时的多分支结构
RepVGG Block 在训练时包含三条并行分支:
输入 x
├── 3×3 卷积 + BN ──────────────┐
├── 1×1 卷积 + BN ──────────────┤ 加法 → 输出 y
└── 恒等映射(Identity)+ BN ────┘
(仅当输入输出通道数相同时存在)
用数学公式表达:
y = BN ∗ 3 ( Conv ∗ 3 × 3 ( x ) ) + BN ∗ 1 ( Conv ∗ 1 × 1 ( x ) ) + BN 0 ( x ) y = \text{BN}*3(\text{Conv}*{3\times3}(x)) + \text{BN}*1(\text{Conv}*{1\times1}(x)) + \text{BN}_0(x) y=BN∗3(Conv∗3×3(x))+BN∗1(Conv∗1×1(x))+BN0(x)
2.3 推理时的单分支结构
经过重参数化后,三条分支被等价合并为一条:
输入 x
└── 3×3 卷积(合并后)→ 输出 y
y = Conv 3 × 3 merged ( x ) y = \text{Conv}_{3\times3}^{\text{merged}}(x) y=Conv3×3merged(x)
这个合并过程是数学等价的,即对于任意输入 x x x,合并前后的输出完全相同(在浮点精度范围内)。
2.4 整体网络结构
三、重参数化的数学原理:等价变换推导 📐
这是本节最核心的内容,理解了数学原理,才能真正掌握重参数化技术。我们将逐步推导每一步变换。🧮
3.1 基础工具:BN 层的吸收
批归一化(Batch Normalization)的前向计算公式为:
BN ( x ) = γ ⋅ x − μ σ 2 + ϵ + β \text{BN}(x) = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta BN(x)=γ⋅σ2+ϵx−μ+β
其中:
- μ \mu μ:训练时统计的均值(推理时使用运行均值)
- σ 2 \sigma^2 σ2:训练时统计的方差(推理时使用运行方差)
- γ \gamma γ:可学习的缩放参数
- β \beta β:可学习的偏移参数
- ϵ \epsilon ϵ:数值稳定性常数(通常为 1e-5)
关键洞察:BN 层本质上是一个线性变换,可以被吸收进卷积层的权重和偏置中。
设卷积层的权重为 W W W,偏置为 b b b(通常卷积后接 BN 时,卷积不使用偏置,即 b = 0 b=0 b=0),则:
BN ( Conv ( x ) ) = γ ⋅ W ∗ x − μ σ 2 + ϵ + β \text{BN}(\text{Conv}(x)) = \gamma \cdot \frac{W * x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta BN(Conv(x))=γ⋅σ2+ϵW∗x−μ+β
= γ σ 2 + ϵ ⋅ W ∗ x + ( β − γ μ σ 2 + ϵ ) = \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}} \cdot W * x + \left(\beta - \frac{\gamma \mu}{\sqrt{\sigma^2 + \epsilon}}\right) =σ2+ϵγ⋅W∗x+(β−σ2+ϵγμ)
令:
W ′ = γ σ 2 + ϵ ⋅ W , b ′ = β − γ μ σ 2 + ϵ W' = \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}} \cdot W, \quad b' = \beta - \frac{\gamma \mu}{\sqrt{\sigma^2 + \epsilon}} W′=σ2+ϵγ⋅W,b′=β−σ2+ϵγμ
则:
BN ( Conv ( x ) ) = W ′ ∗ x + b ′ \text{BN}(\text{Conv}(x)) = W' * x + b' BN(Conv(x))=W′∗x+b′
这就是 BN 吸收:将 BN 层的参数融合进卷积层,得到一个等价的带偏置卷积层。
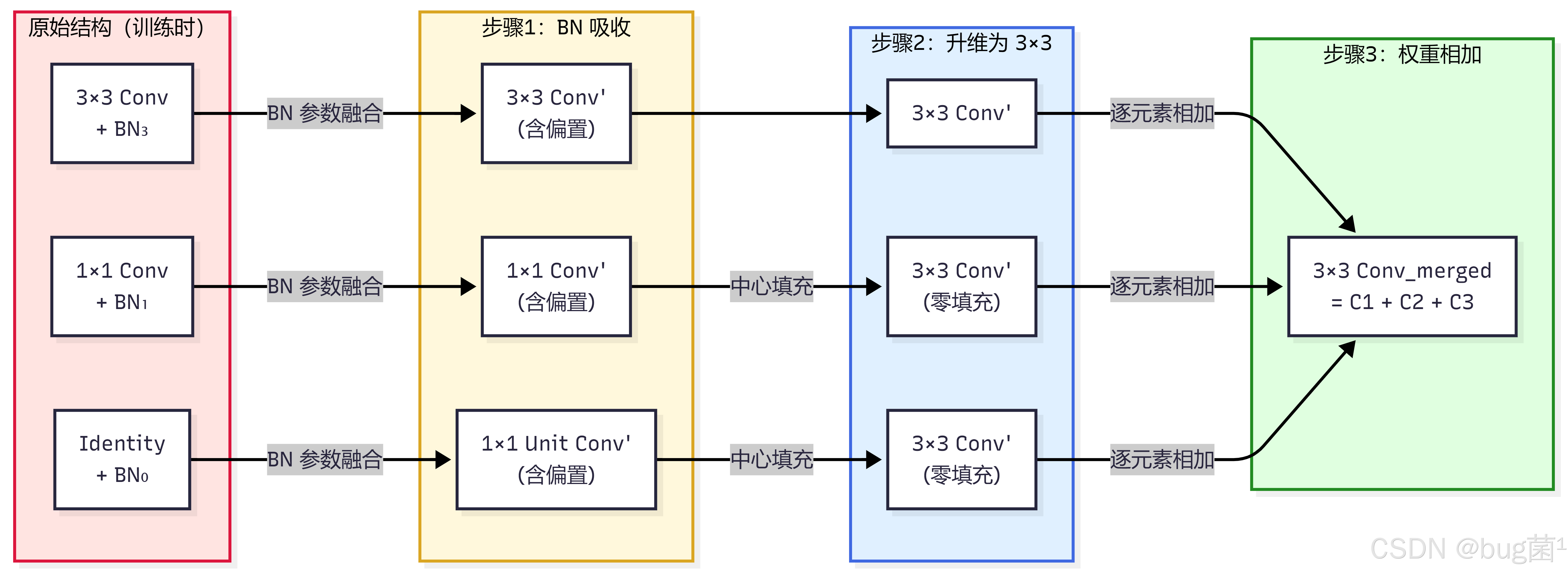
3.2 步骤一:将 BN 吸收进各分支卷积
对三条分支分别执行 BN 吸收:
分支1(3×3 卷积 + BN):
BN ∗ 3 ( Conv ∗ 3 × 3 ( x ) ) → W 3 ′ ∗ x + b 3 ′ \text{BN}*3(\text{Conv}*{3\times3}(x)) \rightarrow W_3' * x + b_3' BN∗3(Conv∗3×3(x))→W3′∗x+b3′
分支2(1×1 卷积 + BN):
BN ∗ 1 ( Conv ∗ 1 × 1 ( x ) ) → W 1 ′ ∗ x + b 1 ′ \text{BN}*1(\text{Conv}*{1\times1}(x)) \rightarrow W_1' * x + b_1' BN∗1(Conv∗1×1(x))→W1′∗x+b1′
分支3(恒等映射 + BN):
BN 0 ( x ) = γ 0 ⋅ x − μ 0 σ 0 2 + ϵ + β 0 → W 0 ′ ∗ x + b 0 ′ \text{BN}_0(x) = \gamma_0 \cdot \frac{x - \mu_0}{\sqrt{\sigma_0^2 + \epsilon}} + \beta_0 \rightarrow W_0' * x + b_0' BN0(x)=γ0⋅σ02+ϵx−μ0+β0→W0′∗x+b0′
其中恒等映射等价于一个权重为单位矩阵的 1×1 卷积(每个通道的卷积核为 1,其余为 0)。
3.3 步骤二:将 1×1 卷积升维为 3×3 卷积
1×1 卷积可以等价地表示为一个 3×3 卷积,只需将 1×1 的卷积核零填充到 3×3 大小:
W 1 × 1 → W 3 × 3 padded W_{1\times1} \rightarrow W_{3\times3}^{\text{padded}} W1×1→W3×3padded
具体操作:将 1×1 卷积核放置在 3×3 矩阵的中心位置,四周补零:
( 0 0 0 0 w 0 0 0 0 ) \begin{pmatrix} 0 & 0 & 0 \ 0 & w & 0 \ 0 & 0 & 0 \end{pmatrix} (000 0w0 000)
这个等价性成立的前提是:两个卷积使用相同的 padding 策略(1×1 卷积 padding=0,3×3 卷积 padding=1,两者输出尺寸相同)。
3.4 步骤三:将恒等映射转换为 3×3 卷积
恒等映射等价于一个特殊的 1×1 卷积(单位卷积),再通过步骤二升维为 3×3 卷积。
对于输入通道数 C i n C_{in} Cin = 输出通道数 C o u t C_{out} Cout = C C C 的情况,恒等映射对应的卷积核为:
W identity [ i , j , : , : ] = { ( 0 0 0 0 1 0 0 0 0 ) if i = j 0 3 × 3 if i ≠ j W_{\text{identity}}[i, j, :, :] = \begin{cases} \begin{pmatrix} 0 & 0 & 0 \ 0 & 1 & 0 \ 0 & 0 & 0 \end{pmatrix} & \text{if } i = j \ \mathbf{0}_{3\times3} & \text{if } i \neq j \end{cases} Widentity[i,j,:,:]={(000 010 000)if i=j 03×3if i=j
即第 i i i 个输出通道只与第 i i i 个输入通道相关,卷积核中心为 1,其余为 0。
3.5 步骤四:三个 3×3 卷积相加
经过前三步,三条分支都变成了 3×3 卷积(带偏置):
y = ( W 3 ′ ∗ x + b 3 ′ ) + ( W 1 ′ padded ∗ x + b 1 ′ ) + ( W 0 ′ padded ∗ x + b 0 ′ ) y = (W_3' * x + b_3') + (W_1'^{\text{padded}} * x + b_1') + (W_0'^{\text{padded}} * x + b_0') y=(W3′∗x+b3′)+(W1′padded∗x+b1′)+(W0′padded∗x+b0′)
由于卷积运算对权重是线性的,可以直接将三个卷积核相加:
y = ( W 3 ′ + W 1 ′ padded + W 0 ′ padded ) ∗ x + ( b 3 ′ + b 1 ′ + b 0 ′ ) y = (W_3' + W_1'^{\text{padded}} + W_0'^{\text{padded}}) * x + (b_3' + b_1' + b_0') y=(W3′+W1′padded+W0′padded)∗x+(b3′+b1′+b0′)
= W merged ∗ x + b merged = W_{\text{merged}} * x + b_{\text{merged}} =Wmerged∗x+bmerged
这就是重参数化的完整推导! 三条分支被等价合并为一个 3×3 卷积。
3.6 等价变换流程图
四、从零实现 RepVGG Block 🛠️
理论推导完毕,现在我们用 PyTorch 从零实现一个完整的 RepVGG Block,并验证重参数化的等价性。
4.1 环境准备
# 安装依赖(如未安装)
# pip install torch torchvision numpy
import torch
import torch.nn as nn
import numpy as np
import copy
4.2 核心工具函数:BN 吸收
def fuse_conv_bn(conv: nn.Conv2d, bn: nn.BatchNorm2d):
"""
将 BN 层的参数吸收进卷积层,返回等价的带偏置卷积层。
数学原理:
BN(Conv(x)) = γ/(√(σ²+ε)) * W * x + (β - γ*μ/√(σ²+ε))
等价于:W' * x + b'
其中 W' = γ/(√(σ²+ε)) * W
b' = β - γ*μ/√(σ²+ε)
Args:
conv: 卷积层(通常 bias=False)
bn: 紧跟其后的 BN 层
Returns:
fused_conv: 等价的带偏置卷积层
"""
# 获取 BN 层的运行统计量和可学习参数
bn_mean = bn.running_mean # μ,形状 [C_out]
bn_var = bn.running_var # σ²,形状 [C_out]
bn_gamma = bn.weight # γ,形状 [C_out]
bn_beta = bn.bias # β,形状 [C_out]
bn_eps = bn.eps # ε,数值稳定常数
# 计算缩放因子:γ / √(σ² + ε)
# 形状 [C_out],需要广播到卷积权重的形状 [C_out, C_in, kH, kW]
scale = bn_gamma / torch.sqrt(bn_var + bn_eps)
# 计算融合后的卷积权重
# conv.weight 形状:[C_out, C_in, kH, kW]
# scale 需要 reshape 为 [C_out, 1, 1, 1] 才能广播
fused_weight = conv.weight * scale.reshape(-1, 1, 1, 1)
# 计算融合后的偏置
# 如果原卷积有偏置,需要先对偏置也做 BN 变换
if conv.bias is not None:
fused_bias = (conv.bias - bn_mean) * scale + bn_beta
else:
# 无偏置时,等价于偏置为 0
fused_bias = bn_beta - bn_mean * scale
# 创建新的带偏置卷积层
fused_conv = nn.Conv2d(
in_channels=conv.in_channels,
out_channels=conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
dilation=conv.dilation,
groups=conv.groups,
bias=True # 融合后必须有偏置
)
# 将融合后的参数赋值
fused_conv.weight.data = fused_weight
fused_conv.bias.data = fused_bias
return fused_conv
4.3 RepVGG Block 完整实现
class RepVGGBlock(nn.Module):
"""
RepVGG 基本构建块。
训练时:包含 3×3 卷积、1×1 卷积、恒等映射三条并行分支。
推理时:通过 reparameterize() 方法将三条分支合并为单一 3×3 卷积。
Args:
in_channels: 输入通道数
out_channels: 输出通道数
stride: 卷积步长,默认为 1
groups: 分组卷积的组数,默认为 1(标准卷积)
deploy: 是否处于推理模式(已完成重参数化),默认为 False
use_se: 是否使用 SE(Squeeze-and-Excitation)注意力模块
"""
def __init__(
self,
in_channels: int,
out_channels: int,
stride: int = 1,
groups: int = 1,
deploy: bool = False,
use_se: bool = False
):
super(RepVGGBlock, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.stride = stride
self.groups = groups
self.deploy = deploy
# padding 设置:3×3 卷积使用 padding=1 保持特征图尺寸
self.padding_3x3 = 1
# ============================================================
# SE 注意力模块(可选)
# ============================================================
if use_se:
self.se = SEBlock(out_channels, reduction=16)
else:
self.se = nn.Identity()
# ============================================================
# 推理模式:只有一个合并后的 3×3 卷积
# ============================================================
if deploy:
self.rbr_reparam = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=stride,
padding=self.padding_3x3,
groups=groups,
bias=True # 推理时卷积带偏置(BN 已融合)
)
return # 推理模式下直接返回,不创建其他分支
# ============================================================
# 训练模式:创建三条并行分支
# ============================================================
# 分支1:恒等映射 + BN
# 仅当输入输出通道数相同且 stride=1 时才存在
if in_channels == out_channels and stride == 1:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels)
else:
self.rbr_identity = None # 通道数不同时无法做恒等映射
# 分支2:3×3 卷积 + BN(主分支)
self.rbr_dense = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=stride,
padding=self.padding_3x3,
groups=groups,
bias=False # 后接 BN,不需要偏置
),
nn.BatchNorm2d(num_features=out_channels)
)
# 分支3:1×1 卷积 + BN(点卷积分支)
self.rbr_1x1 = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=stride,
padding=0, # 1×1 卷积不需要 padding
groups=groups,
bias=False # 后接 BN,不需要偏置
),
nn.BatchNorm2d(num_features=out_channels)
)
# 打印分支信息(调试用)
print(f'RepVGGBlock 创建完成: {in_channels}→{out_channels}, '
f'stride={stride}, identity={self.rbr_identity is not None}')
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
前向传播。
推理模式:直接通过合并后的卷积计算。
训练模式:三条分支分别计算后相加,再通过激活函数。
"""
# 推理模式:单分支直接计算
if self.deploy:
return self.se(self.rbr_reparam(x))
# 训练模式:三条分支相加
# 分支1:3×3 卷积
out_3x3 = self.rbr_dense(x)
# 分支2:1×1 卷积
out_1x1 = self.rbr_1x1(x)
# 分支3:恒等映射(如果存在)
if self.rbr_identity is not None:
out_identity = self.rbr_identity(x)
else:
out_identity = 0 # 不存在时贡献为 0
# 三路相加后通过 SE 模块
return self.se(out_3x3 + out_1x1 + out_identity)
# ================================================================
# 核心方法:执行重参数化,将训练时的多分支合并为单一 3×3 卷积
# ================================================================
def reparameterize(self):
"""
执行结构重参数化。
调用此方法后,模型进入推理模式:
1. 将三条分支的参数合并为单一 3×3 卷积的权重和偏置
2. 删除原有的三条分支,释放内存
3. 设置 self.deploy = True
注意:此操作不可逆!执行后无法恢复训练模式。
"""
if self.deploy:
print("警告:模型已处于推理模式,无需重复重参数化。")
return
# 获取合并后的卷积核和偏置
kernel, bias = self._get_equivalent_kernel_bias()
# 创建推理用的单一 3×3 卷积
self.rbr_reparam = nn.Conv2d(
in_channels=self.rbr_dense[0].in_channels,
out_channels=self.rbr_dense[0].out_channels,
kernel_size=3,
stride=self.rbr_dense[0].stride,
padding=self.padding_3x3,
groups=self.rbr_dense[0].groups,
bias=True
)
# 将合并后的参数赋值给推理卷积
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
# 删除训练时的分支,释放内存
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
# 标记为推理模式
self.deploy = True
def _get_equivalent_kernel_bias(self):
"""
计算等价的 3×3 卷积核和偏置。
这是重参数化的核心计算逻辑,实现了数学推导中的四个步骤:
1. BN 吸收:将 BN 参数融合进卷积权重和偏置
2. 升维:将 1×1 卷积升维为 3×3 卷积(零填充)
3. 升维:将恒等映射升维为 3×3 卷积
4. 相加:三个 3×3 卷积核和偏置分别相加
Returns:
kernel: 合并后的 3×3 卷积核,形状 [C_out, C_in, 3, 3]
bias: 合并后的偏置,形状 [C_out]
"""
# 获取输出通道数
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
# 将 1×1 卷积升维为 3×3(中心填充)
kernel1x1 = self._pad_1x1_to_3x3(kernel1x1)
# 处理恒等映射分支
if self.rbr_identity is not None:
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
# 恒等映射对应的卷积核:对角线为 1,其余为 0
kernelid = self._pad_identity_to_3x3(kernelid)
else:
kernelid, biasid = 0, 0
# 三个分支的卷积核和偏置相加
return (
kernel3x3 + kernel1x1 + kernelid,
bias3x3 + bias1x1 + biasid
)
def _pad_1x1_to_3x3(self, kernel1x1: torch.Tensor) -> torch.Tensor:
"""
将 1×1 卷积核升维为 3×3 卷积核(中心填充)。
原理:1×1 卷积的计算结果等价于 3×3 卷积,其中卷积核的中心为原 1×1 核,
四周补零。这样在相同的 padding 策略下,两者输出完全相同。
Args:
kernel1x1: 1×1 卷积核,形状 [C_out, C_in, 1, 1]
Returns:
kernel3x3: 升维后的 3×3 卷积核,形状 [C_out, C_in, 3, 3]
"""
if kernel1x1 is None:
return 0
# 创建 3×3 的零矩阵
C_out, C_in, _, _ = kernel1x1.shape
kernel3x3 = torch.zeros(
C_out, C_in, 3, 3,
dtype=kernel1x1.dtype,
device=kernel1x1.device
)
# 将 1×1 核放在中心位置 [1, 1]
kernel3x3[:, :, 1:2, 1:2] = kernel1x1
return kernel3x3
def _pad_identity_to_3x3(self, kernel: torch.Tensor) -> torch.Tensor:
"""
将恒等映射的 1×1 卷积核升维为 3×3 卷积核。
恒等映射对应的卷积核是一个特殊的对角矩阵:
- 第 i 个输出通道只与第 i 个输入通道相关
- 卷积核中心为 1,四周为 0
Args:
kernel: 恒等映射对应的卷积核,形状 [C, C, 1, 1](对角线为 1)
Returns:
kernel3x3: 升维后的 3×3 卷积核,形状 [C, C, 3, 3]
"""
if kernel is None:
return 0
C = kernel.shape[0]
kernel3x3 = torch.zeros(
C, C, 3, 3,
dtype=kernel.dtype,
device=kernel.device
)
# 对角线元素放在中心位置
kernel3x3[:, :, 1:2, 1:2] = kernel
return kernel3x3
def _fuse_bn_tensor(self, branch: nn.Module):
"""
从分支中提取等价的卷积核和偏置(BN 已融合)。
处理两种情况:
1. 标准分支(Conv + BN):调用 fuse_conv_bn 融合
2. 恒等映射分支(仅 BN):转换为等价的 1×1 卷积后融合
Args:
branch: 分支模块(可能是 Sequential 或 BatchNorm2d)
Returns:
kernel: 融合后的卷积核
bias: 融合后的偏置
"""
if isinstance(branch, nn.Sequential):
# 标准分支:Conv + BN
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
else:
# 恒等映射分支:仅 BN
# 需要构造一个等价的 1×1 卷积(对角线为 1)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = torch.zeros(
(self.in_channels, input_dim, 1, 1),
dtype=branch.weight.dtype,
device=branch.weight.device
)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 0, 0] = 1
self.id_tensor = kernel_value
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
# 计算 BN 融合后的参数
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
class SEBlock(nn.Module):
"""
Squeeze-and-Excitation 注意力模块。
通过自适应地重新加权通道,增强模型的表达能力。
"""
def __init__(self, channels: int, reduction: int = 16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channels, channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction, channels, bias=False),
nn.Sigmoid()
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
4.4 完整的 RepVGG 网络
class RepVGG(nn.Module):
"""
完整的 RepVGG 网络架构。
Args:
num_blocks: 每个 stage 中 RepVGG Block 的数量列表,
例如 [1, 2, 4, 14, 1] 对应 RepVGG-A0
num_classes: 分类类别数,默认为 1000(ImageNet)
width_multiplier: 宽度倍增因子,用于调整通道数
deploy: 是否处于推理模式
"""
def __init__(
self,
num_blocks: list,
num_classes: int = 1000,
width_multiplier: float = 1.0,
deploy: bool = False
):
super(RepVGG, self).__init__()
self.deploy = deploy
self.width_multiplier = width_multiplier
# 定义每个 stage 的输出通道数(基础配置)
self.in_channels = min(64, int(64 * width_multiplier))
# 构建网络的五个 stage
self.stage0 = self._make_stage(
num_blocks[0], 3, self.in_channels, stride=2, deploy=deploy
)
self.stage1 = self._make_stage(
num_blocks[1], self.in_channels, int(64 * width_multiplier),
stride=2, deploy=deploy
)
self.stage2 = self._make_stage(
num_blocks[2], int(64 * width_multiplier), int(128 * width_multiplier),
stride=2, deploy=deploy
)
self.stage3 = self._make_stage(
num_blocks[3], int(128 * width_multiplier), int(256 * width_multiplier),
stride=2, deploy=deploy
)
self.stage4 = self._make_stage(
num_blocks[4], int(256 * width_multiplier), int(512 * width_multiplier),
stride=2, deploy=deploy
)
# 分类头
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
self.linear = nn.Linear(int(512 * width_multiplier), num_classes)
def _make_stage(
self,
num_blocks: int,
in_channels: int,
out_channels: int,
stride: int,
deploy: bool
) -> nn.Sequential:
"""构建一个 stage(多个 RepVGG Block 的序列)"""
blocks = []
# 第一个 block 可能改变通道数和空间尺寸
blocks.append(
RepVGGBlock(
in_channels=in_channels,
out_channels=out_channels,
stride=stride,
deploy=deploy
)
)
# 后续 block 保持通道数和空间尺寸
for _ in range(num_blocks - 1):
blocks.append(
RepVGGBlock(
in_channels=out_channels,
out_channels=out_channels,
stride=1,
deploy=deploy
)
)
return nn.Sequential(*blocks)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向传播"""
x = self.stage0(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.gap(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
def reparameterize_model(self):
"""
对整个模型执行重参数化。
遍历所有 RepVGG Block,将其从训练模式转换为推理模式。
"""
for module in self.modules():
if isinstance(module, RepVGGBlock):
module.reparameterize()
self.deploy = True
print("✓ 模型重参数化完成,已转换为推理模式")
# 预定义的几个常用配置
def create_RepVGG_A0(deploy: bool = False):
"""RepVGG-A0:轻量级版本"""
return RepVGG(
num_blocks=[1, 2, 4, 14, 1],
width_multiplier=0.75,
deploy=deploy
)
def create_RepVGG_A1(deploy: bool = False):
"""RepVGG-A1:中等版本"""
return RepVGG(
num_blocks=[1, 2, 4, 14, 1],
width_multiplier=1.0,
deploy=deploy
)
def create_RepVGG_B0(deploy: bool = False):
"""RepVGG-B0:较大版本"""
return RepVGG(
num_blocks=[1, 4, 6, 16, 1],
width_multiplier=1.0,
deploy=deploy
)
五、等价性验证实验 ✅
现在我们验证重参数化前后的输出是否完全相同。
def verify_equivalence(model: RepVGG, input_shape: tuple = (1, 3, 224, 224)):
"""
验证重参数化前后的等价性。
Args:
model: RepVGG 模型
input_shape: 输入张量形状
"""
print("\n" + "="*60)
print("等价性验证实验")
print("="*60)
# 创建随机输入
x = torch.randn(input_shape)
# 设置模型为评估模式(禁用 dropout、BN 的训练行为)
model.eval()
# 前向传播(训练时多分支结构)
with torch.no_grad():
output_before = model(x)
print(f"✓ 训练时输出形状:{output_before.shape}")
print(f" 输出样本值:{output_before[0, :5]}")
# 执行重参数化
model.reparameterize_model()
# 前向传播(推理时单分支结构)
with torch.no_grad():
output_after = model(x)
print(f"\n✓ 推理时输出形状:{output_after.shape}")
print(f" 输出样本值:{output_after[0, :5]}")
# 计算输出差异
diff = torch.abs(output_before - output_after).max().item()
relative_error = diff / (torch.abs(output_before).max().item() + 1e-8)
print(f"\n📊 等价性指标:")
print(f" 最大绝对误差:{diff:.2e}")
print(f" 相对误差:{relative_error:.2e}")
if diff < 1e-4:
print(f" ✅ 等价性验证通过!误差在可接受范围内")
else:
print(f" ⚠️ 警告:误差较大,可能存在数值问题")
return output_before, output_after
# 运行验证
if __name__ == "__main__":
# 创建模型
model = create_RepVGG_A0(deploy=False)
# 验证等价性
output_before, output_after = verify_equivalence(model)
六、性能对比实验 📊
import time
def benchmark_model(model: RepVGG, input_shape: tuple = (1, 3, 224, 224),
num_iterations: int = 100):
"""
对模型进行性能基准测试。
Args:
model: RepVGG 模型
input_shape: 输入张量形状
num_iterations: 测试迭代次数
"""
print("\n" + "="*60)
print("性能基准测试")
print("="*60)
x = torch.randn(input_shape)
model.eval()
# 预热(消除缓存影响)
with torch.no_grad():
for _ in range(10):
_ = model(x)
# 测试推理速度
torch.cuda.synchronize() if torch.cuda.is_available() else None
start_time = time.time()
with torch.no_grad():
for _ in range(num_iterations):
_ = model(x)
torch.cuda.synchronize() if torch.cuda.is_available() else None
elapsed_time = time.time() - start_time
avg_time = elapsed_time / num_iterations * 1000 # 转换为毫秒
throughput = input_shape[0] / (elapsed_time / num_iterations) # 样本/秒
print(f"✓ 平均推理时间:{avg_time:.2f} ms")
print(f"✓ 吞吐量:{throughput:.1f} samples/sec")
# 计算参数量和 FLOPs
total_params = sum(p.numel() for p in model.parameters())
print(f"✓ 总参数量:{total_params / 1e6:.2f} M")
return avg_time, throughput
# 对比测试
if __name__ == "__main__":
print("\n🔍 对比测试:训练模式 vs 推理模式\n")
# 训练模式
model_train = create_RepVGG_A0(deploy=False)
model_train.eval()
print("【训练模式(多分支)】")
time_train, throughput_train = benchmark_model(model_train)
# 推理模式
model_infer = create_RepVGG_A0(deploy=False)
model_infer.eval()
model_infer.reparameterize_model()
print("\n【推理模式(单分支)】")
time_infer, throughput_infer = benchmark_model(model_infer)
# 性能提升
speedup = time_train / time_infer
print(f"\n📈 性能提升:{speedup:.2f}x 加速")
七、RepConv 在 YOLOv8 中的应用 🎯
RepVGG 的思想已被集成到 YOLOv8 的 RepConv 模块中。以下是集成示例:
class RepConv(nn.Module):
"""
YOLOv8 中的 RepConv 模块,基于 RepVGG 思想。
在检测任务中,RepConv 通常只包含两条分支:
- 3×3 卷积(主分支)
- 1×1 卷积(轻量分支)
不包含恒等映射(因为检测网络中通常改变通道数)。
"""
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int = 3,
stride: int = 1,
padding: int = 1,
groups: int = 1,
deploy: bool = False
):
super(RepConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.groups = groups
self.deploy = deploy
if deploy:
self.rbr_reparam = nn.Conv2d(
in_channels, out_channels, kernel_size,
stride, padding, groups=groups, bias=True
)
else:
# 3×3 卷积分支
self.rbr_dense = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size,
stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channels)
)
# 1×1 卷积分支
self.rbr_1x1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, stride, 0,
groups=groups, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
if self.deploy:
return self.rbr_reparam(x)
return self.rbr_dense(x) + self.rbr_1x1(x)
def reparameterize(self):
if self.deploy:
return
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernel1x1 = self._pad_1x1_to_kxk(kernel1x1)
self.rbr_reparam = nn.Conv2d(
self.in_channels, self.out_channels, self.kernel_size,
self.stride, self.padding, groups=self.groups, bias=True
)
self.rbr_reparam.weight.data = kernel3x3 + kernel1x1
self.rbr_reparam.bias.data = bias3x3 + bias1x1
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
self.deploy = True
def _fuse_bn_tensor(self, branch):
kernel = branch[0].weight
running_mean = branch[1].running_mean
running_var = branch[1].running_var
gamma = branch[1].weight
beta = branch[1].bias
eps = branch[1].eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def _pad_1x1_to_kxk(self, kernel):
if kernel is None:
return 0
pad = self.kernel_size // 2
return torch.nn.functional.pad(kernel, (pad, pad, pad, pad))
八、训练策略与注意事项 ⚠️
def train_repvgg_model(
model: RepVGG,
train_loader,
val_loader,
num_epochs: int = 100,
learning_rate: float = 0.1,
weight_decay: float = 1e-4
):
"""
RepVGG 模型的训练策略。
关键点:
1. 使用较大的学习率(相比 ResNet)
2. 使用 L2 正则化防止过拟合
3. 在训练结束后执行重参数化
"""
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 优化器和损失函数
optimizer = torch.optim.SGD(
model.parameters(),
lr=learning_rate,
momentum=0.9,
weight_decay=weight_decay
)
criterion = nn.CrossEntropyLoss()
# 学习率调度器
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=num_epochs
)
best_acc = 0
for epoch in range(num_epochs):
# 训练阶段
model.train()
train_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
# 验证阶段
model.eval()
val_acc = 0
val_loss = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs, 1)
val_acc += (predicted == labels).sum().item()
val_acc /= len(val_loader.dataset)
scheduler.step()
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), 'best_model.pth')
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], '
f'Train Loss: {train_loss/len(train_loader):.4f}, '
f'Val Acc: {val_acc:.4f}')
# 训练完成后执行重参数化
print("\n🔄 执行重参数化...")
model.reparameterize_model()
return model
九、常见问题与工程陷阱 🚨
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 重参数化后精度下降 | BN 统计量不准确 | 确保在 eval 模式下执行重参数化,或用完整数据集更新 BN 统计 |
| 内存溢出 | 训练时三条分支同时存在 | 使用梯度检查点(Gradient Checkpointing)或减小 batch size |
| 推理速度未提升 | 硬件不支持单分支优化 | 检查推理框架(TensorRT、ONNX)是否正确融合卷积 |
| 数值精度问题 | 浮点累积误差 | 使用 FP32 训练,推理时可转 FP16 |
十、进阶:RepVGG 的变体与扩展 🚀
RepVGG 的思想已衍生出多个变体:
- RepMobileNet:将重参数化应用于移动网络
- RepResNet:结合残差连接和重参数化
- RepYOLO:在目标检测中的应用
- RepNAS:通过神经架构搜索自动设计重参数化结构
总结 🎓
RepVGG 通过结构重参数化,优雅地解决了"训练精度 vs 推理速度"的矛盾。其核心思想——利用数学等价性在训练和推理间切换——已成为现代深度学习工程的重要工具。
掌握这项技术,你将能够:
✅ 设计更高效的神经网络架构
✅ 在保持精度的前提下大幅提升推理速度
✅ 理解 YOLOv6/v7/v8 等主流框架的设计思想
✅ 为边缘设备部署优化模型
下一节,我们将深入学习算子融合(Operator Fusion)——深入理解 Conv+BN+ReLU 的合并过程。敬请期待!🎯
参考资源:
- 论文:RepVGG: Making VGG-style ConvNets Great Again
- 官方代码:https://github.com/DingXiaoH/RepVGG
- YOLOv8 RepConv 实现:https://github.com/ultralytics/ultralytics
最后,希望本文围绕 YOLOv8 的实战讲解,能在以下几个方面对你有所帮助:
- 🎯 模型精度提升:通过结构改进、损失函数优化、数据增强策略等,实战提升检测效果;
- 🚀 推理速度优化:结合量化、裁剪、蒸馏、部署策略等手段,帮助你在实际业务中跑得更快;
- 🧩 工程级落地实践:从训练到部署的完整链路中,提供可直接复用或稍作改动即可迁移的方案。
PS:如果你按文中步骤对 YOLOv8 进行优化后,仍然遇到问题,请不必焦虑或抱怨。
YOLOv8 作为复杂的目标检测框架,效果会受到 硬件环境、数据集质量、任务定义、训练配置、部署平台 等多重因素影响。
如果你在实践过程中遇到:
- 新的报错 / Bug
- 精度难以提升
- 推理速度不达预期
欢迎把 报错信息 + 关键配置截图 / 代码片段 粘贴到评论区,我们可以一起分析原因、讨论可行的优化方向。
同时,如果你有更优的调参经验或结构改进思路,也非常欢迎分享出来,大家互相启发,共同完善 YOLOv8 的实战打法 🙌
🧧🧧 文末福利,等你来拿!🧧🧧
文中涉及的多数技术问题,来源于我在 YOLOv8 项目中的一线实践,部分案例也来自网络与读者反馈;如有版权相关问题,欢迎第一时间联系,我会尽快处理(修改或下线)。
部分思路与排查路径参考了全网技术社区与人工智能问答平台,在此也一并致谢。如果这些内容尚未完全解决你的问题,还请多一点理解——YOLOv8 的优化本身就是一个高度依赖场景与数据的工程问题,不存在“一招通杀”的方案。
如果你已经在自己的任务中摸索出更高效、更稳定的优化路径,非常鼓励你:
- 在评论区简要分享你的关键思路;
- 或者整理成教程 / 系列文章。
你的经验,可能正好就是其他开发者卡关许久所缺的那一环 💡
OK,本期关于 YOLOv8 优化与实战应用 的内容就先聊到这里。如果你还想进一步深入:
- 了解更多结构改进与训练技巧;
- 对比不同场景下的部署与加速策略;
- 系统构建一套属于自己的 YOLOv8 调优方法论;
欢迎继续查看专栏:《YOLOv8实战:从入门到深度优化》。
也期待这些内容,能在你的项目中真正落地见效,帮你少踩坑、多提效,下期再见 👋
码字不易,如果这篇文章对你有所启发或帮助,欢迎给我来个 一键三连(关注 + 点赞 + 收藏),这是我持续输出高质量内容的核心动力 💪
同时也推荐关注我的公众号 「猿圈奇妙屋」:
- 第一时间获取 YOLOv8 / 目标检测 / 多任务学习 等方向的进阶内容;
- 不定期分享与视觉算法、深度学习相关的最新优化方案与工程实战经验;
- 以及 BAT 等大厂面试题、技术书籍 PDF、工程模板与工具清单等实用资源。
期待在更多维度上和你一起进步,共同提升算法与工程能力 🔧🧠
🫵 Who am I?
我是专注于 计算机视觉 / 图像识别 / 深度学习工程落地 的讲师 & 技术博主,笔名 bug菌:
- 活跃于 CSDN | 掘金 | InfoQ | 51CTO | 华为云 | 阿里云 | 腾讯云 等技术社区;
- CSDN 博客之星 Top30、华为云多年度十佳博主、掘金多年度人气作者 Top40;
- 掘金、InfoQ、51CTO 等平台签约及优质创作者,51CTO 年度博主 Top12;
- 全网粉丝累计 30w+。
更多系统化的学习路径与实战资料可以从这里进入 👉 点击获取更多精彩内容
硬核技术公众号 「猿圈奇妙屋」 欢迎你的加入,BAT 面经、4000G+ PDF 电子书、简历模版等通通可白嫖,你要做的只是——愿意来拿。

-End-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 27
27 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)