Entropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
有监督微调 (SFT) 是领域自适应的标准范式,但它常常导致灾难性遗忘。与之形成鲜明对比的是,on-policy Reinforcement Learning (RL) 能够有效地保留通用能力。我们研究了这种差异,并发现了一个根本性的分布差距:RL 遵循模型的内部信念,而 SFT 则迫使模型适应外部监督。这种不匹配通常表现为“Confident Conflicts”——即概率低但熵低的 token。在这种情况下,模型对其预测结果非常自信,但却被迫学习一个发散的真实值,从而触发破坏性的梯度更新。为了解决这个问题,我们提出了 Entropy-Adaptive Fine-Tuning (EAFT)。与仅依赖预测概率的方法不同,EAFT 利用 token 级熵作为门控机制来区分认知不确定性和知识冲突。这使得模型能够从不确定的样本中学习,同时抑制冲突数据上的梯度。在数学、医学和智能体领域,我们对 Qwen 和 GLM 系列(参数量从 4B 到 32B 不等)进行了广泛的实验,结果证实了我们的假设。EAFT 在显著降低通用能力下降的同时,始终保持与标准 SFT 相同的下游性能。
1.介绍
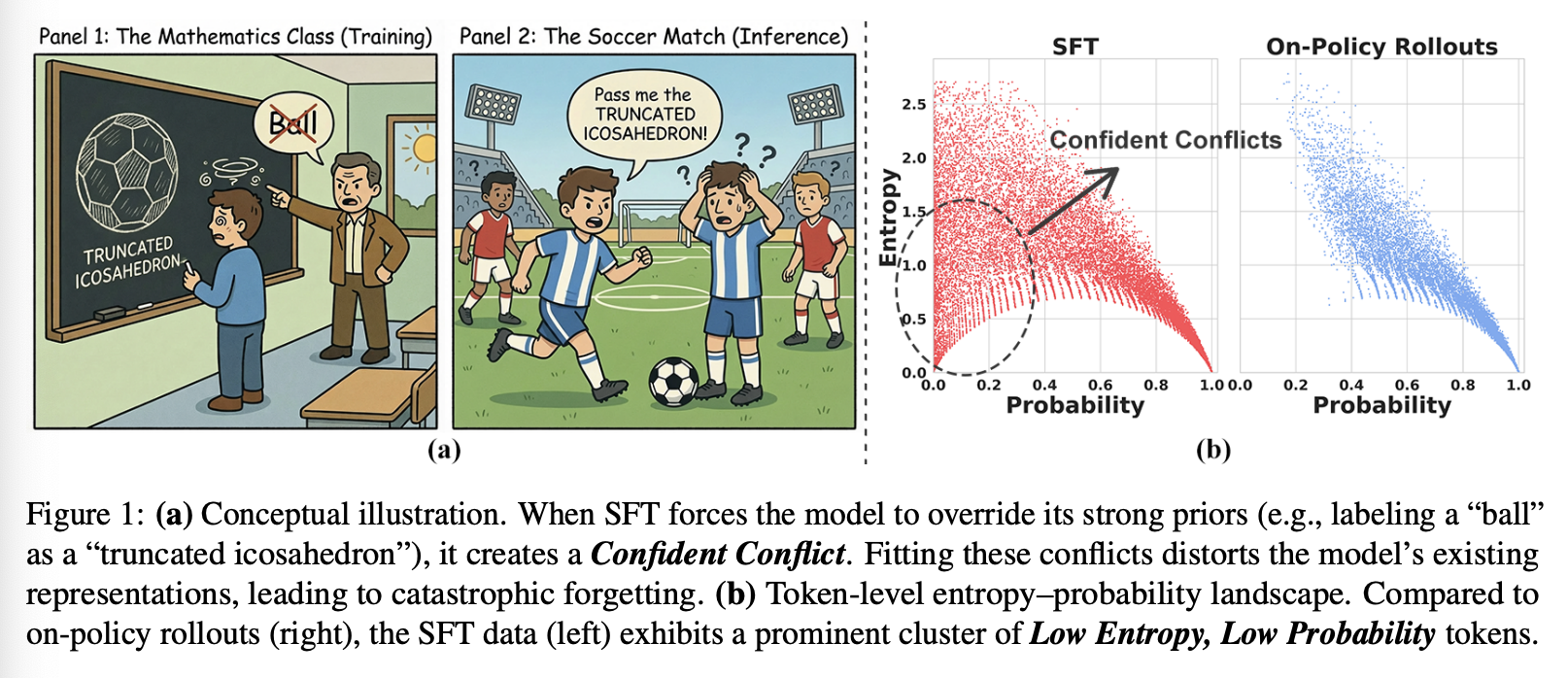
有监督微调 (SFT) 是将大语言模型 (LLM) 适配到特定领域(例如数学或智能工具使用)的标准方法。然而,这种范式通常会带来一个显著的代价,即灾难性遗忘。以往的研究已充分证明,在拟合特定目标分布时,模型的通用能力经常会下降。相比之下,基于策略的强化学习(RL)展现出了显著的能力,能够在有效保持基础模型鲁棒性的同时,显著提升特定领域的性能。这种鲜明的对比引出了一个根本性的问题:
Why does SFT frequently degrade general abilities, while on-policy RL preserves them?
为了探究这一现象背后的机制,我们系统地分析了训练数据的 token 级概率和熵。如图 1 所示,该分析揭示了不同数据源造成的明显分布差异。在 on-policy RL 中,训练序列通过 self-rollout 生成;因此,token 本质上与模型当前的概率分布相符,要么落入高概率置信区,要么落入高熵探索区。相反,有监督微调 (SFT) 依赖于外部监督(例如,人类或强教师模型),从而引入了不匹配,表现为低概率、低熵的 token。这一特定区域对应于模型对其自身预测高度自信(低熵)但被迫拟合一个与其预测相悖的真实标签(低概率)的情况。我们将这些情况称为“Confident Conflicts”。参见附录 A 中的代表性词云。
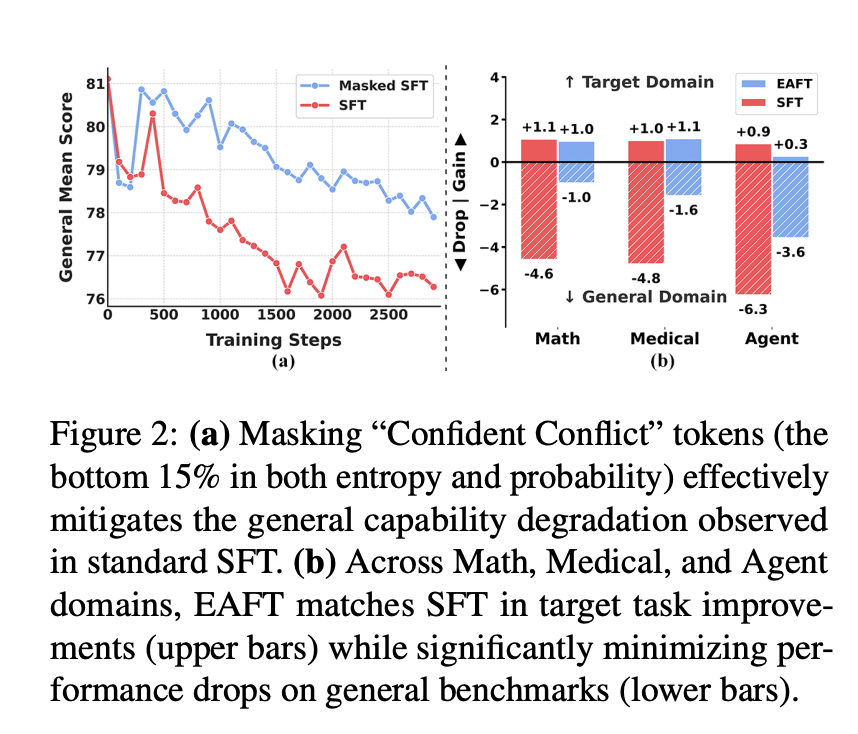
为了验证这些冲突是否确实是导致遗忘的原因,我们进行了一项试点实验。实验中,我们简单地在训练过程中屏蔽了这些 “Confident Conflicts” token(图 2)。我们观察到,与标准 SFT 相比,灾难性遗忘显著减少。这证实了强制更新这些冲突样本是导致能力下降的主要原因。
基于此,我们提出了 EntropyAdaptive Fine-Tuning (EAFT)。EAFT 不使用离散阈值,而是采用一种软门控机制,根据 token 级熵动态调节训练损失。
至关重要的是,这种方法使 EAFT 区别于标准的交叉熵或基于概率的重加权策略。这些方法仅依赖于预测概率,因此有可能放大 “Confident Conflicts” 上的破坏性梯度。相比之下,EAFT 利用熵来区分刚性和不确定性。通过降低低熵 token 的权重以抑制冲突梯度,同时将监督重点放在高熵 token 上以促进适应,EAFT有效地平衡了领域熟练度和通用能力的保留。
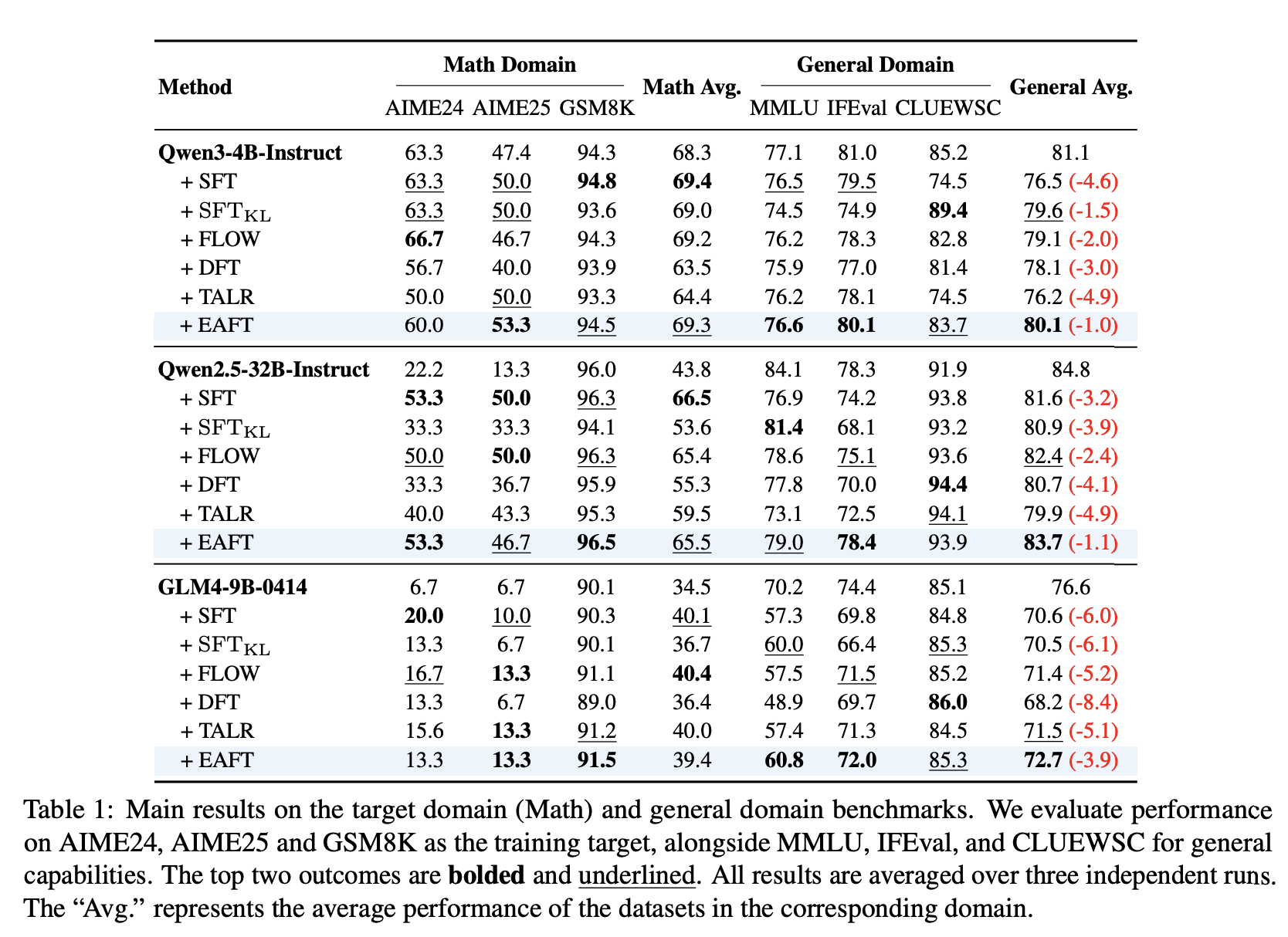
为了验证我们方法的有效性和普适性,我们通过大量的数学实验验证了EAFT,并将其扩展到医学和智能体领域。我们的全面评估涵盖了多种模型类别(Qwen、GLM)以及从 4B 到 32B 参数的规模。结果如图2和表1所示。
定量结果(第 4.2 节)表明,EAFT 的性能始终优于标准 SFT 和现有的缓解策略。它实现了帕累托改进:在目标任务上达到或超过基线水平,同时显著缓解了通用基准测试中的灾难性遗忘。
除了性能之外,我们还对该方法的内在特性进行了深入分析。我们通过实证验证了熵自适应机制能够成功地针对“置信冲突”(第 4.3 节),并进一步证明 EAFT 对超参数变化具有鲁棒性(第 5.1 节),且计算效率高(第 5.2 节)。
总而言之,我们的贡献如下:
- 我们揭示了 SFT 和 on-policy RL 数据之间明显的分布差异。通过可视化和初步实验,我们确定“置信冲突”(低熵、低概率的 token)是灾难性遗忘的主要原因。
- 我们提出了一种基于熵自适应的微调(EAFT)算法,该算法利用 token 级熵来调节训练损失。这种机制能够自动降低来自冲突数据的破坏性更新的权重。
- 我们通过在数学、智能体和医学领域进行的大量实验验证了我们的方法。结果表明,EAFT 是一种有效且通用的解决方案,能够成功缓解不同模型系列和规模(4B–32B)的灾难性遗忘。
2.Related Work
Post-training Paradigms: SFT vs. RL。后训练方法,主要是有监督微调(SFT)和强化学习(RL),被广泛用于校准预训练的语言模型。SFT 优化模型以最大化其与真实标签的匹配度(off-policy)。相比之下,RL 基于模型自身生成的响应,并在奖赏信号的引导下进行优化(on-policy)。这些信号通常来源于参数化的奖赏模型或可验证信号。
新兴研究凸显了两种学习方法在学习行为上的根本差异。虽然 SFT 效率很高,但它本质上容易陷入记忆陷阱,并且通常会为了适应特定的训练样本而牺牲泛化能力。强化学习(RL)则展现出更强的鲁棒性:它能够从单个训练样本中获益而不会出现严重的过拟合,并且与 SFT 相比,它更新的参数子空间更小、更有效。这些研究结果的共同之处在于,强化学习的参数更新更加局部化和针对性更强。
我们的工作旨在探究 SFT 不稳定的根本原因。我们认为,与自然地在模型分布范围内运行的 on-policy 方法不同,标准 SFT 会不加区分地强制拟合“置信冲突”——即与模型预训练知识相矛盾的低熵样本。
Catastrophic forgetting。灾难性遗忘仍然是神经网络中的一个基础性挑战。最初缓解遗忘的努力集中在防止参数发生剧烈变化上。
在 LLM 后训练中,这表现为“对齐税”:针对特定领域能力(例如数学问题求解、工具利用或生物医学适应)的微调通常会显著降低模型的通用能力。
为了克服这些局限性,近期的研究探索了基于 token 级指标来调整优化的动态训练策略。TALR 根据 token 置信度动态调整学习率以加速收敛。DFT 根据预测概率重新加权 SFT 损失。其他方法,例如强化学习的 Razor,则采用 KL 散度作为正则化项来约束模型偏离其基准分布。
然而,现有的动态方法主要依赖概率或 KL 散度作为难度或漂移的代理指标。我们认为,仅凭概率不足以作为统计量:低概率的样本既可以代表认知不确定性(待学习的有效知识),也可以代表“置信冲突”(与模型强先验相矛盾的破坏性样本)。通过强制模型基于概率来拟合这些冲突,以往的方法可能会加速遗忘。我们的工作通过引入熵作为门控信号来改进这一方法。
3.Empirical Analysis & Methodology
本节系统地研究了 SFT 中灾难性遗忘的成因,并提出了一种针对性的解决方案。首先,我们在第 3.1 节中定义了问题设置和关键指标。然后,我们在第 3.2 节中通过实证分析,确定了“置信冲突”是破坏性梯度的主要来源。最后,基于这些发现,我们在第 3.3 节中介绍了我们的方法—— EntropyAdaptive Fine-Tuning (EAFT)。
3.1 Preliminaries
SFT 是将基础模型 θθθ(由其概率分布 PθP_θPθ 表示)适配到目标数据集 D={(x,y)i}i=1N\mathcal D = \{(\textbf x, \textbf y)_i\}^N_{i=1}D={(x,y)i}i=1N 的标准过程。对于每个样本,响应是一个 token 序列 y=(y1,...,yT)y = (y_1, . . . , y_T)y=(y1,...,yT),其中 TTT 表示序列长度。适配通常通过最小化交叉熵 (CE) 损失来实现,该损失最大化目标序列的似然性:
LCE(θ)=−∑t=1Tlog Pθ(yt∣x,y<t)(1)\mathcal L_{CE}(\theta)=-\sum^T_{t=1}log~P_{\theta}(y_t|\textbf x,\textbf y_{\lt t})\tag{1}LCE(θ)=−t=1∑Tlog Pθ(yt∣x,y<t)(1)
该目标的一个主要局限性在于它对所有 token 的处理方式相同。它会不考虑模型的先验知识或不确定性,而积极地更新模型参数以拟合每个token yty_tyt。
为了研究这一统一目标如何与模型的内部状态相互作用的动态过程,我们引入了两个 token 级指标,作为我们分析和方法的基础:
- Probability。pt=Pθ(yt∣x,y<t)p_t=P_{\theta}(y_t|\textbf x,\textbf y_{\lt t})pt=Pθ(yt∣x,y<t)表示模型在真实 token 上的置信度。
- Predictive Entropy。令 Pt(v)≜Pθ(v∣x,y<t)P_t(v) ≜ P_θ(v|\textbf x,\textbf y_{<t})Pt(v)≜Pθ(v∣x,y<t) 表示步骤 ttt 的分布。熵定义为:Ht=−∑v∈VPt(v)logPt(v)H_t = −\sum_{v∈\mathcal V} P_t(v) log P_t(v)Ht=−∑v∈VPt(v)logPt(v), 这衡量模型对词表 V\mathcal VV 的预测不确定性。
3.2 Analysis: The Origins of Forgetting
为了理解为什么 SFT 会导致遗忘而 on-policy 的强化学习不会,我们将标准 SFT 数据的 token 级统计数据与模型生成的 rollout(on-policy 的强化学习的数据来源)进行比较。图 1 可视化了两个数据集的概率 ptp_tpt 和熵 HtH_tHt 的分布。
Distributional Gap: Confident Conflicts。可视化结果揭示了一个关键的分布转变。on-policy 数据要么属于高概率(模型正确),要么属于高熵(模型正在探索)。与之形成鲜明对比的是,SFT 数据包含大量同时具有低熵和低概率的 token。我们将这些样本称为“置信冲突”。它们代表了模型持有强烈且固执的先验信念(低熵)与真实标签(低概率)直接矛盾的情况。
Pilot Study: Masking Confident Conflicts。我们假设这些“置信冲突”是导致遗忘的主要原因。为了验证这一假设,我们进行了一项试点实验,其中我们屏蔽了熵值和概率排名均处于后15%的 token的损失。如图 2 所示,这种简单的干预措施显著缓解了标准SFT中观察到的总体能力下降。
值得注意的是,屏蔽这些特定 token 几乎完全消除了基准测试中的灾难性遗忘现象。这一发现证实,通用能力的下降主要源于强制模型适应这些冲突样本,而非 SFT 过程本身。
Theoretical Insight。我们分析优化动态过程以理解这种损害。考虑 CE 损失(公式1)。当模型对与目标相矛盾的预测结果非常有信心时(低熵,低概率),CE 损失会导致非常大的梯度。由于模型强烈倾向于另一个 token,拟合目标需要大量的参数更新,这可能会覆盖基础模型中的一般表示。相反,当模型存在不确定性时(高熵),梯度较小,更新也更平缓,有助于保持模型的原始能力。
3.3 Entropy-Adaptive Fine-Tuning (EAFT)
虽然试点研究验证了我们的假设,但强制 MASK 策略存在两个局限性:它会丢弃训练数据,导致目标域学习效果不佳,并且依赖于敏感的超参数 (τ,δ)(τ, δ)(τ,δ)。为了解决这些问题,我们提出了 Entropy-Adaptive Fine-Tuning (EAFT),这是一种软门控机制,能够根据模型的不确定性动态调整学习信号。
The EAFT Objective。我们通过将标准有监督信息与归一化熵相结合来构建 EAFT 损失函数。该机制优先学习模型正在探索的样本,同时有效抑制模型判断有把握但结果相互矛盾时的梯度。目标函数分解如下:
LEAFT(θ)=−∑t=1TH~t⏟Adaptive Gating Signal⋅log Pθ(yt∣x,y<t)⏟Standard Supervision(2)\mathcal L_{EAFT}(\theta)=-\sum^T_{t=1}\underbrace{\tilde H_t}_{Adaptive~Gating~Signal}\cdot \underbrace{log~P_{\theta}(y_t|\textbf x,\textbf y_{\lt t})}_{Standard~Supervision}\tag{2}LEAFT(θ)=−t=1∑TAdaptive Gating Signal H~t⋅Standard Supervision log Pθ(yt∣x,y<t)(2)
这里,门控项 H~t\tilde H_tH~t 由 top-K 个 token 的熵导出。与使用完整词表相比,这种近似方法大大减少了计算量(详见 5.2 节的分析)。将熵归一化到 [0, 1] 范围内,并令 K=20K = 20K=20,我们计算如下:
H~t=Httop−Kln(K)≈Httop−203.0(3)\tilde H_t=\frac{H^{top-K}_t}{ln(K)}\approx \frac{H^{top-20}_t}{3.0}\tag{3}H~t=ln(K)Httop−K≈3.0Httop−20(3)
其中 Httop−KH^{top-K}_tHttop−K 表示基于 top-K 个概率分布计算的熵,ln(K)ln(K)ln(K) 作为归一化因子(K 个结果的最大熵)。这种归一化创建了一种自调节机制:
- Conflict Suppression (H~t→0\tilde H_t → 0H~t→0):当模型固执(低熵)时,权重会下降,从而有效地掩盖来自冲突标签的破坏性梯度。
- Knowledge Acquisition (H~t→1\tilde H_t → 1H~t→1):当模型不确定(高熵)或处于探索阶段时,权重保持较高,恢复了学习新模式的标准 SFT 目标。
4.Experiments

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)