QwenVL(2、2.5、3版本)多模型大模型训练中的数据集构造总结
qwen2vl累计处理了 1400B token(预计为3.5B规模的数据,假设每条数据400个token),其特点在于qwen团队为了将Qwen2-VL开发为一种通用的VL-Agent,收集了各种代理任务,如UI操作、机器人控制、游戏和导航,视为顺序决策问题数据。这里预估对开源数据的收集不够充分,毕竟InternVL仅基于开源数据就获取了6B数据。
qwen2.5将训练token扩展到4万亿(4000B)(预计为10B规模的数据,假设每条数据400个token),数据可分为:清理的网络数据、合成数据(均为多模态数据)。合成数据涉及到表格、图表、公式、自然/合成图像、乐谱、化学公式等,还有Agent Data,这大幅度增强模型的OCR能力,UI代理操作能力。
qwen3vl将训练数据token又降低到2000B的规模(SFT阶段仅使用了120w数据),这表明训练数据量可能不是制约模型性能的关键,训练数据的分阶段配比利用才是多模态模型性能提升的关键。同时期InternVL3.5仅训练了1160M 样本(250B token,仅约InternVL1的1/5,约为qwen3vl的1/10)SFT阶段使用了600M(6亿条,是qwen3vl的500倍,但该阶段训练成本较低)。这表明面向刷榜构造数据集是可以大幅度降低训练成本,同时论证了面向特定业务构造数据训练模型成本是低于强泛化能力基模研发的。InternVL(1~3.5版本)多模型大模型训练中的数据集构造总结-CSDN博客
Qwen2-VL
训练数据
在第一阶段,关注于训练视觉转换器(ViT)组件的对齐能力,利用大量的图像 - 文本对语料库来增强大型语言模型(LLM)中的语义理解。Qwen2-VL 暴露在大约 600B token 的语料库中。这个训练前阶段主要集中于学习图像 - 文本关系,通过 OCR 识别图像中的文本内容,以及图像分类任务。
在第二阶段,解冻所有参数,并训练更广泛的数据,以进行更全面的学习。涉及额外的 800B 图像相关数据的 token。这一阶段引入了更多数量的混合图像 - 文本内容,促进了对视觉和文本信息之间的相互作用的更微妙的理解。
在最后一个阶段,锁定 ViT 参数,并使用教学数据集对 LLM 进行独占微调。使用了 ChatML(Openai,2024)格式来构造指令跟踪数据。该数据集不仅包含纯基于文本的对话数据,还包括多模态对话数据。多模态组件包括图像问答、文档解析、多图像比较、视频理解、视频流对话和基于代理的交互。我们对数据构建的全面方法旨在增强模型理解和执行跨各种模式的各种指令的能力。通过合并不同的数据类型,我们寻求开发一个更通用和更健壮的语言模型,除了传统的基于文本的交互之外,还能够处理复杂的、多模态的任务。
在整个训练前阶段,Qwen2-VL 累计处理了 1400B token。具体来说,这些 token 不仅包含文本 token,还包含图像 token。然而,在训练过程中,只对文本 token 提供监督。
数据格式
与Qwen-VL相一致,Qwen2-VL还使用了特殊的token来区分视觉和文本输入。在图像特征序列的开始和结尾插入<|vision_start|>和<|vision_end|>,以划分图像内容。
Dialogue Data. 在对话格式方面,使用ChatML格式构建指令调优数据集,其中每个交互的语句都用两个特殊的标记(<|im_start|>和<|im_end|>)标记,以促进对话终止。用蓝色标记的部分表示被监督的部分。


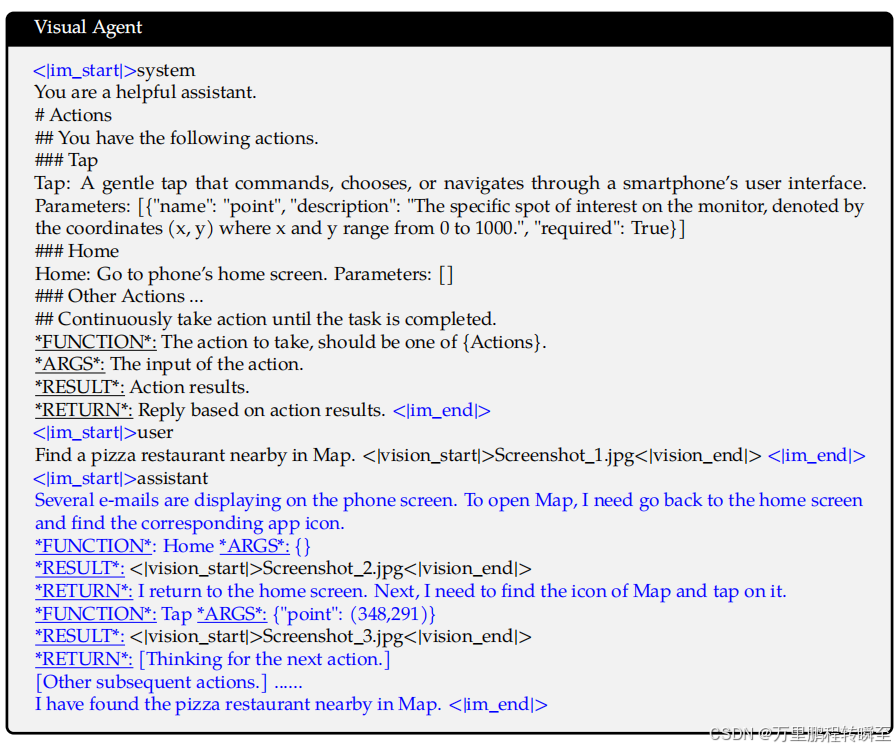
Visual Agent. 为了将Qwen2-VL开发为一种通用的VL-Agent,将各种代理任务,如UI操作、机器人控制、游戏和导航,视为顺序决策问题,使Qwen2-VL能够通过多步骤的动作执行来完成任务。对于每个任务,首先为函数调用定义一组允许的操作和关键字模式(下划线)(QwenTeam,2024)。然后,Qwen2-VL分析观察结果,执行推理和计划,执行所选的动作,并与环境进行交互,以获得新的观察结果。这个循环反复重复,直到任务成功完成。通过集成各种工具并利用大型视觉语言模型(LVLMs)的视觉感知能力,Qwen2-VL能够迭代地执行涉及现实世界视觉交互的越来越复杂的任务。
Qwen2.5-VL
预训练数据
相比于上一版本模型预训练数据从 1.2万亿token 扩展至约 4万亿token;数据可分为:清理的网络数据、合成数据(均为多模态数据)。
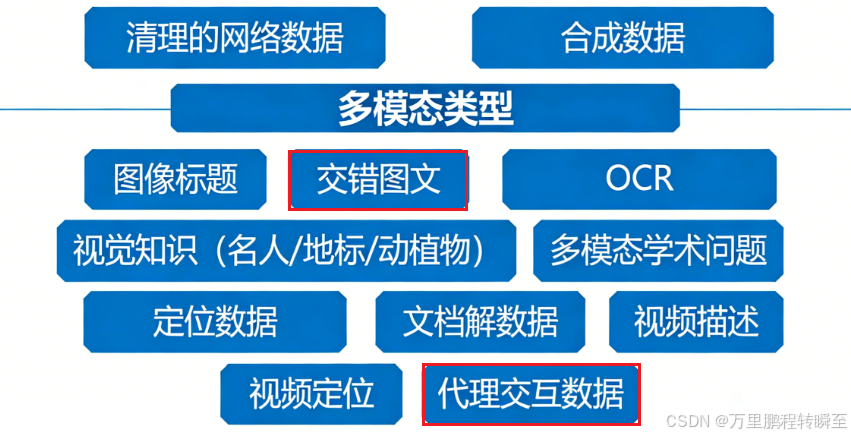
不同训练阶段动态调整数据比例,优化学习效果。
交错式图文数据处理
开发现代化数据清洗与评分流水线,确保高质量图文关联;
流程包含:标准清洗 + 四阶段内部模型评分,评估维度:
- 文本质量
- 图文相关性(Image-text Relevance):高分表示图像有意义补充或解释文本,非装饰性;
- 信息互补性(Information Complementarity):图像与文本提供独特细节,共同构成完整语义;
- 信息密度均衡(Balance of Information Density):避免单模态信息过载,实现图文平衡。
基于绝对坐标的定位数据
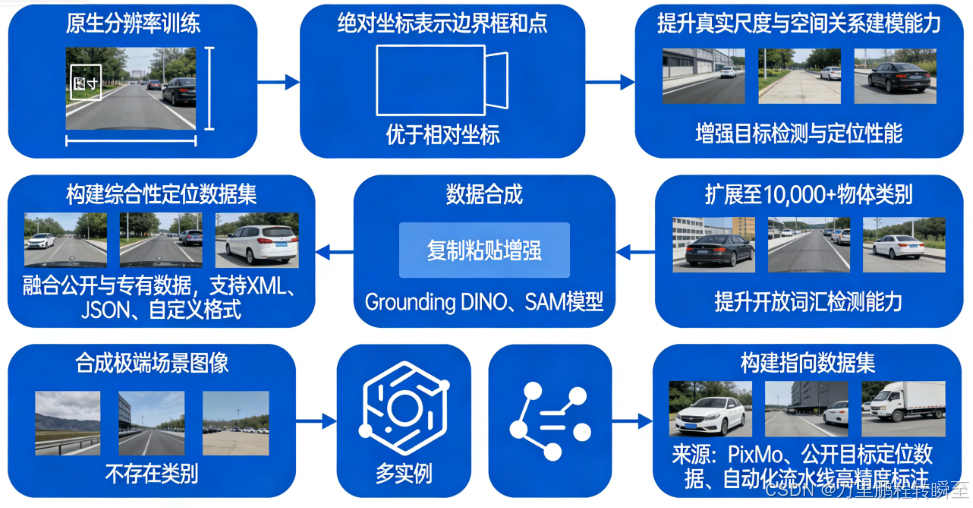
Document Omni-Parsing Data
- 合成大规模多元素文档数据,支持:表格、图表、公式、自然/合成图像、乐谱、化学公式;
- 统一表示为 HTML 格式,嵌入布局框坐标与插图描述至标签结构;
- 按典型阅读顺序组织布局,并标注各模块(段落、图表等)的空间坐标;
- 实现文档的布局、文本、视觉内容的标准化整合,支持端到端文档理解与转换。
对应的QwenVL HTML 格式
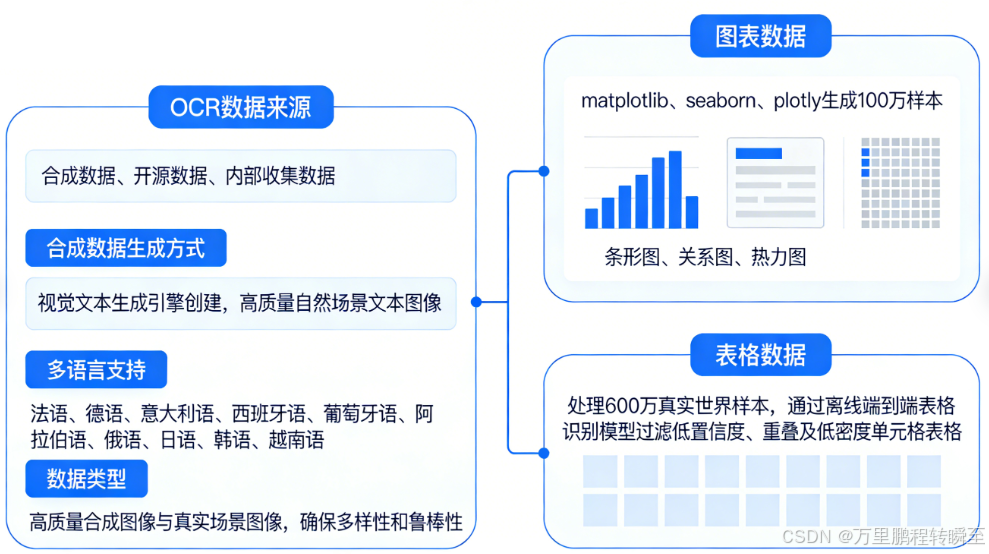
OCR Data
Video Data
- 训练中采用动态FPS采样,实现训练集内帧率的均匀分布,提升对不同FPS视频的鲁棒性;
- 针对超过半小时的长视频,通过目标合成流程生成长视频字幕;
- 视频时间戳标注采用秒级和小时-分-秒(hmsf)格式,确保模型能准确理解与输出多种时间表示。
Agent Data
代理能力构建涵盖感知与决策两方面;
- 感知:收集移动、网页、桌面平台的截图,使用合成数据引擎生成字幕与UI元素标注,提升对图形界面的理解与外观-功能对齐;
- 决策:将跨平台操作统一为共享动作空间的函数调用格式;
多步轨迹数据来自开源数据与代理框架合成数据(Wang et al., 2025, 2024b,c),重格式化为函数调用序列;
每个操作步骤配备人工与模型标注的推理过程:基于操作前后截图与全局查询,编写意图解释;
使用基于模型的过滤器剔除低质量推理,防止过拟合真实操作,增强现实场景中的泛化性与鲁棒性。
指令微调数据
数据量
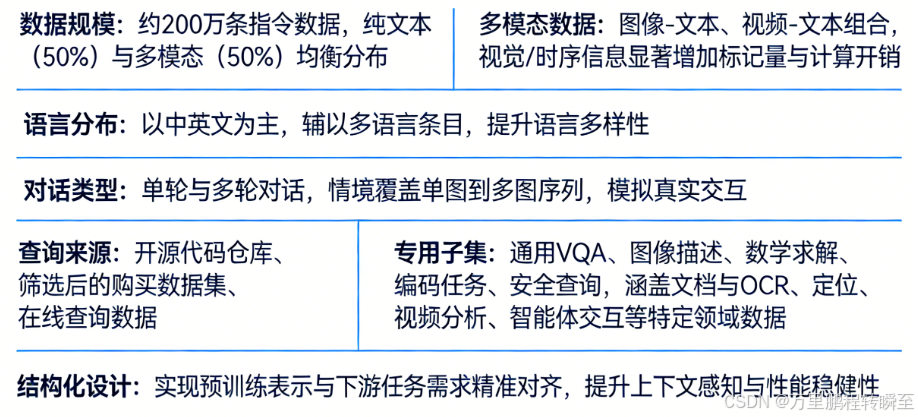
数据清洗流程
训练数据质量直接影响模型性能。我们实施两阶段过滤流程以系统性提升SFT数据质量:
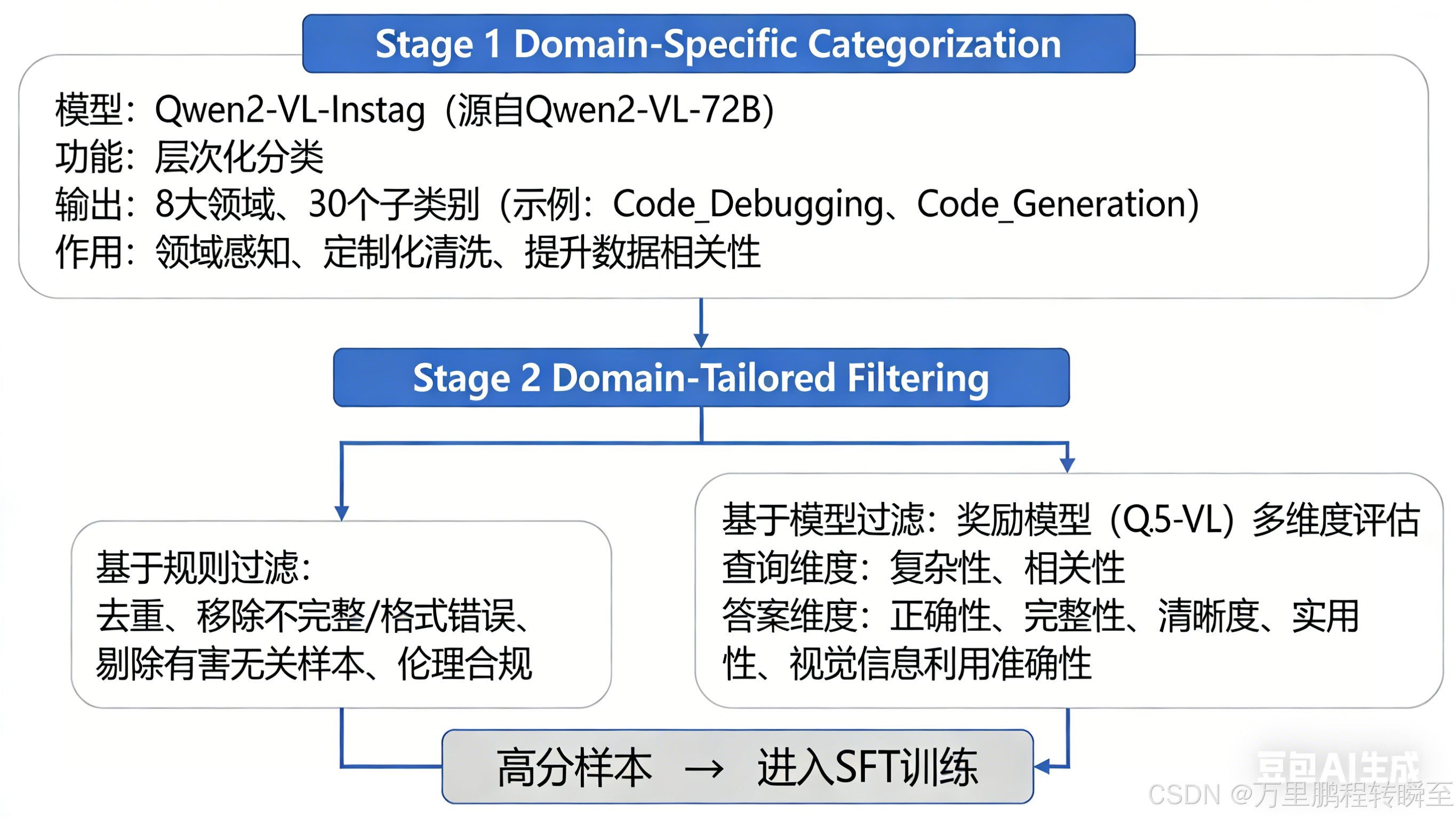
Qwen3
训练方法
Qwen3-VL模型采用三模块架构:视觉编码器、基于MLP的视觉-语言合并模块、Qwen3大语言模型(LLM)骨干网络。预训练分为四个阶段(S0-S3),概述见表1。
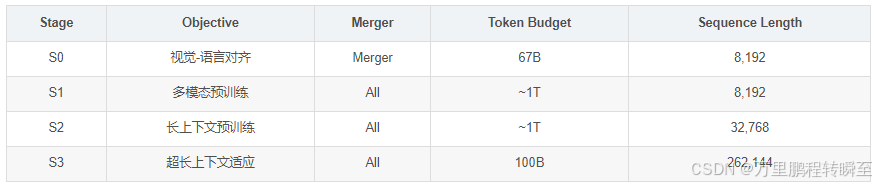
阶段0:视觉-语言对齐。 仅训练MLP合并模块,视觉编码器和LLM冻结。使用67B标记数据集,序列长度8,192。
阶段1:多模态预训练。 解冻所有组件进行端到端训练。使用~1T标记数据集,序列长度8,192。
阶段2:长上下文预训练。 序列长度扩展至32,768,所有参数可训练。使用~1T标记数据集。
阶段3:超长上下文适应。 序列长度提升至262,144。使用100B标记数据集,专为长视频和长文档理解优化。
预训练数据
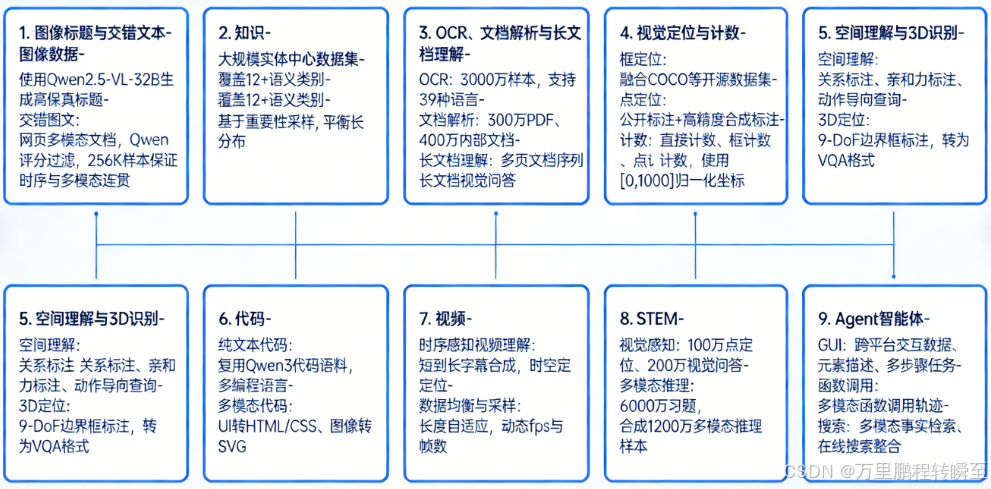
指令微调数据
训练流程
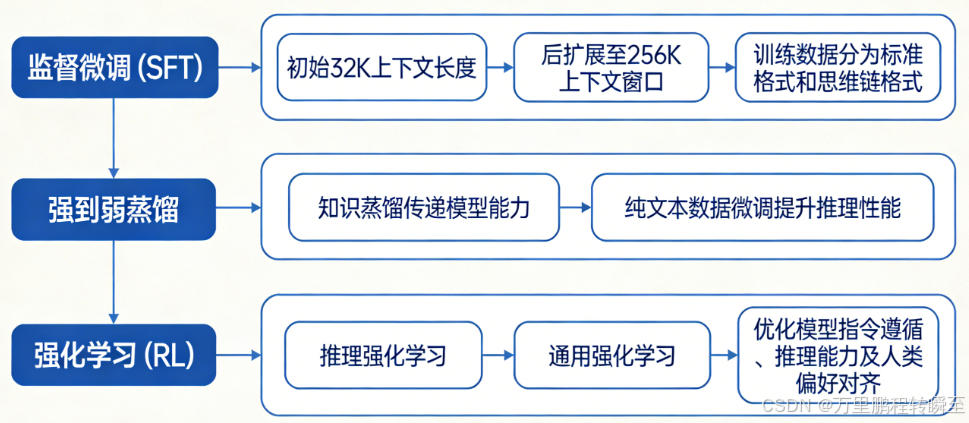
数据配比
关于SFT数据,使用Qwen2.5-VL奖励模型多维度评估(正确性、完整性、视觉信息利用),剔除不当语言混合或突兀文体转换的样本。
关于长思维链冷启动数据,重点增强STEM和智能体工作流任务;纯文本部分包含数学、代码生成等挑战性问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)