【MIT 6.824】LEC 4 VMware FT
LEC4 VMware FT
课堂
复制(Replication)
用最简单的方法来描述复制能处理的故障,那就是,单台计算机的fail-stop故障。
但是复制不能处理软件中的bug和硬件设计中的缺陷。以MapReduce的Master节点为例,如果我们复制并将其运行在两台计算机上,但是在Master程序里面有一个bug,那么复制对我们没有任何帮助,因为我们在两台计算机上的MapReduce Master都会计算出相同的错误结果,其他组件都会接受这个错误的结果。所以我们不能通过复制软件(为软件构建多副本)来抵御软件的bug,我们不能通过任何的复制的方案来抵御软件的bug。类似的,如我之前所说的,我们也不能期望复制可以处理硬件的漏洞,当硬件有漏洞的时候会计算出错误的结果,这时我们就无能为力了,至少基于复制这种技术,我们就无能为力了。

当然,如果你足够幸运的话,肯定也有一些硬件和软件的bug是可以被复制处理掉的。比如说,如果有一些不相关的软件运行在你的服务器上,并且它们导致了服务器崩溃,例如kernel panic或者服务器重启,虽然这些软件与你服务的副本无关,但是这种问题对于你的服务来说,也算是一种fail-stop。kernel panic之后,当前服务器上的服务副本会停止运行,备份副本会取而代之。一些硬件错误也可以转换成fail-stop错误,例如,当你通过网络发送了一个包,但是网络传输过程中,由于网络设备故障,导致数据包中的一个bit被翻转了,这可以通过数据包中的校验和检测出来,这样整个数据包会被丢弃。对于磁盘也可以做类似的事情,如果你往磁盘写了一些数据,过了一个月又读出来,但是磁盘的磁面或许不是很完美,导致最重要的几个数据bit读出来是错误的。通过纠错代码,在一定程度上可以修复磁盘中的错误,如果你足够幸运,随机的硬件错误可以被转换成正确的数据,如果没有那么幸运,那么至少可以检测出这里的错误,并将随机的错误转换成检测到的错误,这样,软件就知道发生了错误,并且会将错误转换成一个fail-stop错误,进而停止软件的运行,或者采取一些补救措施。总的来说,我们还是只能期望复制能够处理fail-stop错误。
对于复制,还有一些其他的限制。如果我们有两个副本,一个Primay和一个Backup节点,我们总是假设两个副本中的错误是相互独立的。但是如果它们之间的错误是有关联的,那么复制对我们就没有帮助。例如,我们要构建一个大型的系统,我们从同一个厂商买了数千台完全一样的计算机,我们将我们的副本运行在这些同一时间,同一地点购买的计算机上,这还是有一点风险的。因为如果其中一台计算机有制造缺陷,那么极有可能其他的计算机也有相同的缺陷。例如,由于制造商没有提供足够的散热系统,其中一台计算机总是过热,那么很有可能这一批计算机都有相同的问题。所以,如果其中一台因为过热导致宕机,那么其他计算机也很有可能会有相同的问题。这是一种关联错误。
状态转移和复制状态机(State Transfer and Replicated State Machine)
在VMware FT论文的开始,介绍了两种复制的方法,一种是状态转移(State Transfer),另一种是复制状态机(Replicated State Machine)。这两种我们都会介绍,但是在这门课程中,我们主要还是介绍后者。
如果我们有一个服务器的两个副本,我们需要让它们保持同步,在实际上互为副本,这样一旦Primary出现故障,因为Backup有所有的信息,就可以接管服务。状态转移背后的思想是,Primary将自己完整状态,比如说内存中的内容,拷贝并发送给Backup。Backup会保存收到的最近一次状态,所以Backup会有所有的数据。当Primary故障了,Backup就可以从它所保存的最新状态开始运行。所以,状态转移就是发送Primary的状态。虽然VMware FT没有采用这种复制的方法,但是假设采用了的话,那么转移的状态就是Primary内存里面的内容。这种情况下,每过一会,Primary就会对自身的内存做一大份拷贝,并通过网络将其发送到Backup。为了提升效率,你可以想到每次同步只发送上次同步之后变更了的内存。
复制状态机基于这个事实:**我们想复制的大部分的服务或者计算机软件都有一些确定的内部操作,不确定的部分是外部的输入。**通常情况下,如果一台计算机没有外部影响,它只是一个接一个的执行指令,每条指令执行的是计算机中内存和寄存器上确定的函数,只有当外部事件干预时,才会发生一些预期外的事。例如,某个随机时间收到了一个网络数据包,导致服务器做一些不同的事情。所以,复制状态机不会在不同的副本之间发送状态,相应的,它只会从Primary将这些外部事件,例如外部的输入,发送给Backup。通常来说,如果有两台计算机,如果它们从相同的状态开始,并且它们以相同的顺序,在相同的时间,看到了相同的输入,那么它们会一直互为副本,并且一直保持一致。
所以,状态转移传输的是可能是内存,而复制状态机会将来自客户端的操作或者其他外部事件,从Primary传输到Backup。
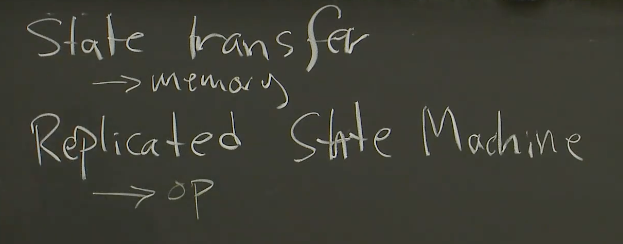
人们倾向于使用复制状态机的原因是,通常来说,外部操作或者事件比服务的状态要小。如果是一个数据库的话,它的状态可能是整个数据库,可能到达GB这个级别,而操作只是一些客户端发起的请求,例如读key27的数据。所以操作通常来说比较小,而状态通常比较大。所以复制状态机通常来说更吸引人一些。复制状态机的缺点是,它会更复杂一些,并且对于计算机的运行做了更多的假设。而状态转移就比较简单粗暴,我就是将我整个状态发送给你,你不需要再考虑别的东西。
有关这些方法有什么问题吗?
学生提问:如果这里的方法出现了问题,导致Primary和Backup并不完全一样,会有什么问题?
Robert教授:假设我们对GFS的Master节点做了多副本,其中的Primary对Chunk服务器1分发了一个租约。但是因为我们这里可能会出现多副本不一致,所以Backup并没有向任何人发出租约,它甚至都不知道任何人请求了租约,现在Primary认为Chunk服务器1对于某些Chunk有租约,而Backup不这么认为。当Primary挂了,Backup接手,Chunk服务器1会认为它对某些Chunk有租约,而当前的Primary(也就是之前的Backup)却不这么认为。当前的Primary会将租约分发给其他的Chunk服务器。现在我们就有两个Chunk服务器有着相同的租约。这只是一个非常现实的例子,基于不同的副本不一致,你可以构造出任何坏的场景和任何服务器运算出错误结果的情形。我之后会介绍VMware的方案是如何避免这一点的。
学生提问:随机操作在复制状态机会怎么处理?
Robert教授:我待会会再说这个问题,但是这是个好问题。只有当没有外部的事件时,Primary和Backup都执行相同的指令,得到相同的结果,复制状态机才有意义。对于ADD这样的指令来说,这是正确的。如果寄存器和内存都是相同的,那么两个副本执行一条ADD指令,这条指令有相同的输入,也必然会有相同的输出。但是,**如你指出的一样,有一些指令,或许是获取当前的时间,因为执行时间的略微不同,会产生不同的结果。**又或者是获取当前CPU的唯一ID和序列号,也会产生不同的结果。对于这一类问题的统一答案是,Primary会执行这些指令,并将结果发送给Backup。Backup不会执行这些指令,而是在应该执行指令的地方,等着Primary告诉它,正确的答案是什么,并将监听到的答案返回给软件。
有趣的是,或许你已经注意到了,VMware FT论文讨论的都是复制状态机,并且只涉及了单核CPU,目前还不确定论文中的方案如何扩展到多核处理器的机器中。在多核的机器中,两个核交互处理指令的行为是不确定的,所以就算Primary和Backup执行相同的指令,在多核的机器中,它们也不一定产生相同的结果。VMware在之后推出了一个新的可能完全不同的复制系统,并且可以在多核上工作。这个新系统从我看来使用了状态转移,而不是复制状态机。因为面对多核和并行计算,状态转移更加健壮。如果你使用了一台机器,并且将其内存发送过来了,那么那个内存镜像就是机器的状态,并且不受并行计算的影响,但是复制状态机确实会受并行计算的影响。但是另一方面,我认为这种新的多核方案代价会更高一些。
如果我们要构建一个复制状态机的方案,我们有很多问题要回答,我们需要决定要在什么级别上复制状态,我们对状态的定义是什么,我们还需要担心Primary和Backup之间同步的频率。因为很有可能Primary会比Backup的指令执行更超前一些,毕竟是Primary接收了外部的输入,Backup几乎必然是要滞后的。这意味着,有可能Primary出现了故障,而Backup没有完全同步上。但是,让Backup与Primary完全同步执行又是代价很高的操作,因为这需要大量的交互。所以,很多设计中,都关注同步的频率有多高。
如果Primary发生了故障,必须要有一些切换的方案,并且客户端必须要知道,现在不能与服务器1上的旧Primary通信,而应该与服务器2上的新Primary通信。所有的客户端都必须以某种方式完成这里的切换。几乎不可能设计一个不出现异常现象的切换系统。在理想的环境中,如果Primary故障了,系统会切换到Backup,同时没有人,没有一个客户端会注意到这里的切换。这在实际上基本不可能实现。所以,在切换过程中,必然会有异常,我们必须找到一种应对它们的方法。
如果我们的众多副本中有一个故障了,我们需要重新添加一个新的副本。如果我们只有两个副本,其中一个故障了,那我们的服务就命悬一线了,因为第二个副本随时也可能故障。所以我们绝对需要尽快将一个新的副本上线。但是这可能是一个代价很高的行为,因为副本的状态会非常大。我们喜欢复制状态机的原因是,我们认为状态转移的代价太高了。但是对于复制状态机来说,其中的两个副本仍然需要有完整的状态,我们只是有一种成本更低的方式来保持它们的同步。如果我们要创建一个新的副本,我们别无选择,只能使用状态转移,因为新的副本需要有完整状态的拷贝。所以创建一个新的副本,代价会很高。
以上就是人们主要担心的问题。我们在讨论其他复制状态机方案时,会再次看到这些问题。
让我们回到什么样的状态需要被复制这个话题。VMware FT论文对这个问题有一个非常有趣的回答。它会复制机器的完整状态,这包括了所有的内存,所有的寄存器。这是一个非常非常详细的复制方案,Primary和Backup,即使在最底层也是完全一样的。对于复制方案来说,这种类型是非常少见的。总的来说,大部分复制方案都跟GFS更像。GFS也有复制,但是它绝对没有在Primary和Backup之间复制内存中的每一个bit,它复制的更多是应用程序级别的Chunk。应用程序将数据抽象成Chunk和Chunk ID,GFS只是复制了这些,而没有复制任何其他的东西,所以也不会有复制其他东西的代价。对于应用程序来说,只要Chunk的副本的数据是一致的就可以了。基本上除了VMware FT和一些屈指可数的类似的系统,其他所有的复制方案都是采用的类似GFS的方案。也就是说基本上所有的方案使用的都是应用程序级别的状态复制,因为这更加高效,并且我们也不必陷入这样的困境,比如说需要确保中断在Primary和Backup的相同位置执行,GFS就完全不需要担心这种情况。但是VMware FT就需要担心这种情况,因为它从最底层就开始复制。所以,大多数人构建了高效的,应用程序级别的复制系统。这样做的后果是,复制这个行为,必须构建在应用程序内部。如果你收到了一系列应用程序级别的操作,你确实需要应用程序参与到复制中来,因为一些通用的复制系统,例如VMware FT,理解不了这些操作,以及需要复制的内容。总的来说,大部分场景都是应用程序级别的复制,就像GFS和其他这门课程中会学习的其他论文一样。

VMware FT的独特之处在于,它从机器级别实现复制,因此它不关心你在机器上运行什么样的软件,它就是复制底层的寄存器和内存。你可以在VMware FT管理的机器上运行任何软件,只要你的软件可以运行在VMware FT支持的微处理器上。这里说的软件可以是任何软件。所以,它的缺点是,它没有那么的高效,优点是,你可以将任何现有的软件,甚至你不需要有这些软件的源代码,你也不需要理解这些软件是如何运行的,在某些限制条件下,你就可以将这些软件运行在VMware FT的这套复制方案上。VMware FT就是那个可以让任何软件都具备容错性的魔法棒。
VMware FT 工作原理
让我来介绍一下VMware FT是如何工作的。
首先,VMware是一个虚拟机公司,它们的业务主要是售卖虚拟机技术。虚拟机的意思是,你买一台计算机,通常只能在硬件上启动一个操作系统。但是如果在硬件上运行一个虚拟机监控器(VMM,Virtual Machine Monitor)或者Hypervisor,Hypervisor会在同一个硬件上模拟出多个虚拟的计算机。所以通过VMM,可以在一个硬件上启动一到多个Linux虚机,一到多个Windows虚机。
这台计算机上的VMM可以运行一系列不同的操作系统,其中每一个都有自己的操作系统内核和应用程序。
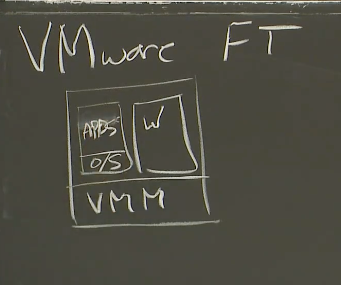
这是VMware发家的技术,这里的硬件和操作系统之间的抽象,可以有很多很多的好处。首先是,我们只需要购买一台计算机,就可以在上面运行大量不同的操作系统,我们可以在每个操作系统里面运行一个小的服务,而不是购买大量的物理计算机,每个物理计算机只运行一个服务。所以,这是VMware的发家技术,并且它有大量围绕这个技术构建的复杂系统。
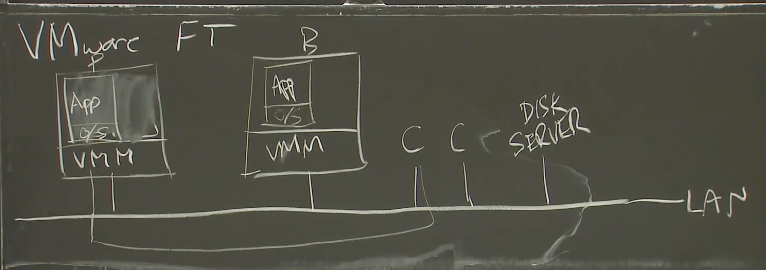
VMware FT需要两个物理服务器。将Primary和Backup运行在一台服务器的两个虚拟机里面毫无意义,因为容错本来就是为了能够抵御硬件故障。所以,你至少需要两个物理服务器运行VMM,Primary虚机在其中一个物理服务器上,Backup在另一个物理服务器上。在其中一个物理服务器上,我们有一个虚拟机,这个物理服务器或许运行了很多虚拟机,但是我们只关心其中一个。这个虚拟机跑了某个操作系统,和一种服务器应用程序,或许是个数据库,或许是MapReduce master或者其他的,我们将之指定为Primary。在第二个物理服务器上,运行了相同的VMM,和一个相同的虚拟机作为Backup。它与Primary有着一样的操作系统。
两个物理服务器上的VMM会为每个虚拟机分配一段内存,这两段内存的镜像需要完全一致,或者说我们的目标就是让Primary和Backup的内存镜像完全一致。所以现在,我们有两个物理服务器,它们每一个都运行了一个虚拟机,每个虚拟机里面都有我们关心的服务的一个拷贝。我们假设有一个网络连接了这两个物理服务器。
除此之外,在这个局域网(LAN,Local Area Network),还有一些客户端。实际上,它们不必是客户端,可以只是一些我们的多副本服务需要与之交互的其他计算机。其中一些客户端向我们的服务发送请求。在VMware FT里,多副本服务没有使用本地盘,而是使用了一些Disk Server(远程盘)。尽管从论文里很难发现,这里可以将远程盘服务器也看做是一个外部收发数据包的源,与客户端的区别不大。
所以,基本的工作流程是,我们假设这两个副本,或者说这两个虚拟机:Primary和Backup,互为副本。某些我们服务的客户端,向Primary发送了一个请求,这个请求以网络数据包的形式发出。
这个网络数据包产生一个中断,之后这个中断送到了VMM。VMM可以发现这是一个发给我们的多副本服务的一个输入,所以这里VMM会做两件事情:
- 在虚拟机的guest操作系统中,模拟网络数据包到达的中断,以将相应的数据送给应用程序的Primary副本。
- 除此之外,因为这是一个多副本虚拟机的输入,VMM会将网络数据包拷贝一份,并通过网络送给Backup虚机所在的VMM。
Backup虚机所在的VMM知道这是发送给Backup虚机的网络数据包,它也会在Backup虚机中模拟网络数据包到达的中断,以将数据发送给应用程序的Backup。所以现在,Primary和Backup都有了这个网络数据包,它们有了相同的输入,再加上许多细节,它们将会以相同的方式处理这个输入,并保持同步。
当然,虚机内的服务会回复客户端的请求。在Primary虚机里面,服务会生成一个回复报文,并通过VMM在虚机内模拟的虚拟网卡发出。之后VMM可以看到这个报文,它会实际的将这个报文发送给客户端。
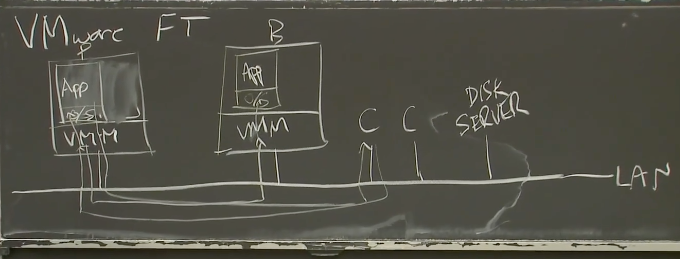
另一方面,由于Backup虚机运行了相同顺序的指令,它也会生成一个回复报文给客户端,并将这个报文通过它的VMM模拟出来的虚拟网卡发出。但是它的VMM知道这是Backup虚机,会丢弃这里的回复报文。所以这里,Primary和Backup都看见了相同的输入,但是只有Primary虚机实际生成了回复报文给客户端。
这里有一个术语,VMware FT论文中将Primary到Backup之间同步的数据流的通道称之为Log Channel。虽然都运行在一个网络上,但是这些从Primary发往Backup的事件被称为Log Channel上的Log Event/Entry。
当Primary因为故障停止运行时,FT(Fault-Tolerance)就开始工作了。从Backup的角度来说,它将不再收到来自于Log Channel上的Log条目。实际中,Backup每秒可以收到很多条Log,其中一个来源就是来自于Primary的定时器中断。每个Primary的定时器中断都会生成一条Log条目并发送给Backup,这些定时器中断每秒大概会有100次。所以,如果Primary虚机还在运行,Backup必然可以期望从Log Channel收到很多消息。如果Primary虚机停止运行了,那么Backup的VMM就会说:天,我都有1秒没有从Log Channel收到任何消息了,Primary一定是挂了或者出什么问题了。当Backup不再从Primary收到消息,VMware FT论文的描述是,Backup虚机会上线(Go Alive)。这意味着,Backup不会再等待来自于Primary的Log Channel的事件,Backup的VMM会让Backup自由执行,而不是受来自于Primary的事件驱动。Backup的VMM会在网络中做一些处理(猜测是发GARP),让后续的客户端请求发往Backup虚机,而不是Primary虚机。同时,Backup的VMM不再会丢弃Backup虚机的输出。当然,它现在已经不再是Backup,而是Primary。所以现在,左边的虚机直接接收输入,直接产生输出。到此为止,Backup虚机接管了服务。
类似的一个场景,虽然没那么有趣,但是也需要能正确工作。如果Backup虚机停止运行,Primary也需要用一个类似的流程来抛弃Backup,停止向它发送事件,并且表现的就像是一个单点的服务,而不是一个多副本服务一样。所以,只要有一个因为故障停止运行,并且不再产生网络流量时,Primary和Backup中的另一个都可以上线继续工作。
学生提问:Backup怎么让其他客户端向自己发送请求?
Robert教授:魔法。。。取决于是哪种网络技术。从论文中看,一种可能是,所有这些都运行在以太网上。每个以太网的物理计算机,或者说网卡有一个48bit的唯一ID(MAC地址)。下面这些都是我(Robert教授)编的。每个虚拟机也有一个唯一的MAC地址,当Backup虚机接手时,它会宣称它有Primary的MAC地址,并向外通告说,我是那个MAC地址的主人。这样,以太网上的其他人就会向它发送网络数据包。不过这只是我(Robert教授)的解读。
学生提问:随机数生成器这种操作怎么在Primary和Backup做同步?
Robert教授:VMware FT的设计者认为他们找到了所有类似的操作,对于每一个操作,Primary执行随机数生成,或者某个时间点生成的中断(依赖于执行时间点的中断)。而Backup虚机不会执行这些操作,Backup的VMM会探测这些指令,拦截并且不执行它们。VMM会让Backup虚机等待来自Log Channel的有关这些指令的指示,比如随机数生成器这样的指令,之后VMM会将Primary生成的随机数发送给Backup。
论文有暗示说他们让Intel向处理器加了一些特性来支持这里的操作,但是论文没有具体说是什么特性。
非确定性事件(Non-Deterministic Events)
好的,目前为止,我们都假设只要Backup虚机也看到了来自客户端的请求,经过同样的执行过程,那么它就会与Primary保持一致,但是这背后其实有很多很重要的细节。就如其他同学之前指出的一样,其中一个问题是存在非确定性(Non-Deterministic)的事件。虽然通常情况下,代码执行都是直接明了的,但并不是说计算机中每一个指令都是由计算机内存的内容而确定的行为。这一节,我们来看一下不由当前内存直接决定的指令。如果我们不够小心,这些指令在Primary和Backup的运行结果可能会不一样。这些指令就是所谓的非确定性事件。所以,设计者们需要弄明白怎么让这一类事件能在Primary和Backup之间同步。
非确定性事件可以分成几类。
- 客户端输入。假设有一个来自于客户端的输入,这个输入随时可能会送达,所以它是不可预期的。客户端请求何时送达,会有什么样的内容,并不取决于服务当前的状态。我们讨论的系统专注于通过网络来进行交互,所以这里的系统输入的唯一格式就是网络数据包。所以当我们说输入的时候,我们实际上是指接收到了一个网络数据包。而一个网络数据包对于我们来说有两部分,一个是数据包中的数据,另一个是提示数据包送达了的中断。当网络数据包送达时,通常网卡的DMA(Direct Memory Access)会将网络数据包的内容拷贝到内存,之后触发一个中断。操作系统会在处理指令的过程中消费这个中断。对于Primary和Backup来说,这里的步骤必须看起来是一样的,否则它们在执行指令的时候就会出现不一致。所以,这里的问题是,中断在什么时候,具体在指令流中的哪个位置触发?**对于Primary和Backup,最好要在相同的时间,相同的位置触发,否则执行过程就是不一样的,进而会导致它们的状态产生偏差。**所以,我们不仅关心网络数据包的内容,还关心中断的时间。
- 另外,如其他同学指出的,有一些指令在不同的计算机上的行为是不一样的,这一类指令称为怪异指令,比如说:
- 随机数生成器
- 获取当前时间的指令,在不同时间调用会得到不同的结果
- 获取计算机的唯一ID
- 另外一个常见的非确定事件,在VMware FT论文中没有讨论,就是多CPU的并发。我们现在讨论的都是一个单进程系统,没有多CPU多核这种事情。之所以多核会导致非确定性事件,是因为当服务运行在多CPU上时,指令在不同的CPU上会交织在一起运行,进而产生的指令顺序是不可预期的。所以如果我们在Backup上运行相同的代码,并且代码并行运行在多核CPU上,硬件会使得指令以不同(于Primary)的方式交织在一起,而这会引起不同的运行结果。假设两个核同时向同一份数据请求锁,在Primary上,核1得到了锁;在Backup上,由于细微的时间差别核2得到了锁,那么执行结果极有可能完全不一样,这里其实说的就是(在两个副本上)不同的线程获得了锁。所以,多核是一个巨大的非确定性事件来源,VMware FT论文完全没有讨论它,并且它也不适用与我们这节课的讨论。

学生提问:如何确保VMware FT管理的服务只使用单核?
Robert教授:服务不能使用多核并行计算。硬件几乎可以肯定是多核并行的,但是这些硬件在VMM之下。在这篇论文中,VMM暴露给运行了Primary和Backup虚机操作系统的硬件是单核的。我猜他们也没有一种简单的方法可以将这里的内容应用到一个多核的虚拟机中。
所有的事件都需要通过Log Channel,从Primary同步到Backup。有关日志条目的格式在论文中没有怎么描述,但是我(Robert教授)猜日志条目中有三样东西:
- 1.(instruction #)事件发生时的指令序号。因为如果要同步中断或者客户端输入数据,最好是Primary和Backup在相同的指令位置看到数据,所以我们需要知道指令序号。这里的指令号是自机器启动以来指令的相对序号,而不是指令在内存中的地址。比如说,我们正在执行第40亿零79条指令。所以日志条目需要有指令序号。对于中断和输入来说,指令序号就是指令或者中断在Primary中执行的位置。对于怪异的指令(Weird instructions),比如说获取当前的时间来说,这个序号就是获取时间这条指令执行的序号。这样,Backup虚机就知道在哪个指令位置让相应的事件发生。
- 2.(type)日志条目的类型,可能是普通的网络数据输入,也可能是怪异指令。
- 3.(data)最后是数据。如果是一个网络数据包,那么数据就是网络数据包的内容。如果是一个怪异指令,数据将会是这些怪异指令在Primary上执行的结果。这样Backup虚机就可以伪造指令,并提供与Primary相同的结果。
举个例子,Primary和Backup两个虚机内部的guest操作系统需要在模拟的硬件里有一个定时器,能够每秒触发100次中断,这样操作系统才可以通过对这些中断进行计数来跟踪时间。因此,这里的定时器必须在Primary和Backup虚机的完全相同位置产生中断,否则这两个虚机不会以相同的顺序执行指令,进而可能会产生分歧。所以,在运行了Primary虚机的物理服务器上,有一个定时器,这个定时器会计时,生成定时器中断并发送给VMM。在适当的时候,VMM会停止Primary虚机的指令执行,并记下当前的指令序号,然后在指令序号的位置插入伪造的模拟定时器中断,并恢复Primary虚机的运行。之后,VMM将指令序号和定时器中断再发送给Backup虚机。虽然Backup虚机的VMM也可以从自己的物理定时器接收中断,但是它并没有将这些物理定时器中断传递给Backup虚机的guest操作系统,而是直接忽略它们。当来自于Primary虚机的Log条目到达时,Backup虚机的VMM配合特殊的CPU特性支持,会使得物理服务器在相同的指令序号处产生一个定时器中断,之后VMM获取到这个中断,并伪造一个假的定时器中断,并将其送入Backup虚机的guest操作系统,并且这个定时器中断会出现在与Primary相同的指令序号位置。
学生提问:这里的操作依赖硬件的定制吗?(实际上我听不清,猜的)
Robert教授:是的,这里依赖于CPU的一些特殊的定制,这样VMM就可以告诉CPU,执行1000条指令之后暂停一下,方便VMM将伪造的中断注入,这样Backup虚机就可以与Primary虚机在相同的指令位置触发相同的中断,执行相同的指令。之后,VMM会告诉CPU恢复执行。这里需要一些特殊的硬件,但是现在看起来所有的Intel芯片上都有这个功能,所以也不是那么的特殊。或许15年前,这个功能还是比较新鲜的,但是现在来说就比较正常了。现在这个功能还有很多其他用途,比如说做CPU时间性能分析,可以让处理器每1000条指令中断一次,这里用的是相同的硬件让微处理器每1000条指令产生一个中断。所以现在,这是CPU中非常常见的一个小工具。
学生提问:如果Backup领先了Primary会怎么样?
Robert教授: 场景可能是这样,Primary即将在第100万条指令处中断,但是Backup已经执行了100万零1条指令了。如果我们让这种场景发生,那么Primary的中断传输就太晚了。如果我们允许Backup执行领先Primary,就会使得中断在Backup中执行位置落后于Primary。所以我们不能允许这种情况发生,我们不能允许Backup在执行指令时领先于Primary。
VMware FT是这么做的。它会维护一个来自于Primary的Log条目的等待缓冲区,如果缓冲区为空,Backup是不允许执行指令的。如果缓冲区不为空,那么它可以根据Log的信息知道Primary对应的指令序号,并且会强制Backup虚机最多执行指令到这个位置。所以,Backup虚机的CPU总是会被通知执行到特定的位置就停止。Backup虚机只有在Log缓冲区中有数据才会执行,并且只会执行到Log条目对应的指令序号。在Primary产生的第一个Log,并且送达Backup之前,Backup甚至都不能执行指令,所以Backup总是落后于Primary至少一个Log。如果物理服务器的资源占用过多,导致Backup执行变慢,那么Backup可能落后于Primary多个Log条目。
网络数据包送达时,有一个细节会比较复杂。当网络数据包到达网卡时,如果我们没有运行虚拟机,网卡会将网络数据包通过DMA的方式送到计算机的关联内存中。现在我们有了虚拟机,并且这个网络数据包是发送给虚拟机的,在虚拟机内的操作系统可能会监听DMA并将数据拷贝到虚拟机的内存中。因为VMware的虚拟机设计成可以支持任何操作系统,我们并不知道网络数据包到达时操作系统会执行什么样的操作,有的操作系统或许会真的监听网络数据包拷贝到内存的操作。
我们不能允许这种情况发生。如果我们允许网卡直接将网络数据包DMA到Primary虚机中,我们就失去了对于Primary虚机的时序控制,因为我们也不知道什么时候Primary会收到网络数据包。所以,实际中,物理服务器的网卡会将网络数据包拷贝给VMM的内存,之后,网卡中断会送给VMM,并说,一个网络数据包送达了。这时,VMM会暂停Primary虚机,记住当前的指令序号,将整个网络数据包拷贝给Primary虚机的内存,之后模拟一个网卡中断发送给Primary虚机。同时,将网络数据包和指令序号发送给Backup。Backup虚机的VMM也会在对应的指令序号暂停Backup虚机,将网络数据包拷贝给Backup虚机,之后在相同的指令序号位置模拟一个网卡中断发送给Backup虚机。这就是论文中介绍的Bounce Buffer机制。
学生提问:怪异的指令(Weird instructions)会有多少呢?
Robert教授:怪异指令非常少。只有可能在Primary和Backup中产生不同结果的指令,才会被封装成怪异指令,比如获取当前时间,或者获取当前处理器序号,或者获取已经执行的的指令数,或者向硬件请求一个随机数用来加密,这种指令相对来说都很少见。大部分指令都是类似于ADD这样的指令,它们会在Primary和Backup中得到相同的结果。每个网络数据包未做修改直接被打包转发,然后被两边虚拟机的TCP/IP协议栈解析也会得到相同的结果。所以我预期99.99%的Log Channel中的数据都会是网络数据包,只有一小部分是怪异指令。
所以对于一个服务于客户端的服务来说,我们可以通过客户端流量判断Log Channel的流量大概是什么样子,因为它基本上就是客户端发送的网络数据包的拷贝。
输出控制(Output Rule)
对于VMware FT系统的输出,也是值得说一下的。在这个系统中,唯一的输出就是对于客户端请求的响应。客户端通过网络数据包将数据送入,服务器的回复也会以网络数据包的形式送出。我之前说过,Primary和Backup虚机都会生成回复报文,之后通过模拟的网卡送出,但是只有Primary虚机才会真正的将回复送出,而Backup虚机只是将回复简单的丢弃掉。
好吧,真实情况会复杂一些。假设我们正在跑一个简单的数据库服务器,这个服务器支持一个计数器自增操作,工作模式是这样,客户端发送了一个自增的请求,服务器端对计数器加1,并返回新的数值。假设最开始一切正常,在Primary和Backup中的计数器都存了10。
现在,局域网的一个客户端发送了一个自增的请求给Primary,这个请求在Primary虚机的软件中执行,Primary会发现,现在的数据是10,我要将它变成11,并回复客户端说,现在的数值是11。
这个请求也会发送给Backup虚机,并将它的数值从10改到11。Backup也会产生一个回复,但是这个回复会被丢弃,这是我们期望发生的。
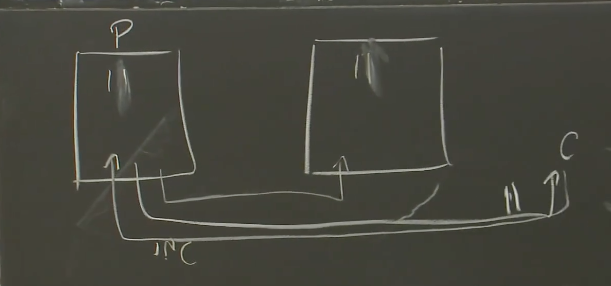
但是,你需要考虑,如果在一个不恰当的时间,出现了故障会怎样?在这门课程中,你需要始终考虑,故障的最坏场景是什么,故障会导致什么结果?在这个例子中,假设Primary确实生成了回复给客户端,但是之后立马崩溃了。更糟糕的是,现在网络不可靠,Primary发送给Backup的Log条目在Primary崩溃时也丢包了。那么现在的状态是,客户端收到了回复说现在的数据是11,但是Backup虚机因为没有看到客户端请求,所以它保存的数据还是10。
现在,因为察觉到Primary崩溃了,Backup接管服务。这时,客户端再次发送一个自增的请求,这个请求发送到了原来的Backup虚机,它会将自身的数值从10增加到11,并产生第二个数据是11的回复给客户端。
如果客户端比较前后两次的回复,会发现一个明显不可能的场景(两次自增的结果都是11)。
因为VMware FT的优势就是在不修改软件,甚至软件都不需要知道复制的存在的前提下,就能支持容错,所以我们也不能修改客户端让它知道因为容错导致的副本切换触发了一些奇怪的事情。在VMware FT场景里,我们没有修改客户端这个选项,因为整个系统只有在不修改服务软件的前提下才有意义。所以,前面的例子是个大问题,我们不能让它实际发生。有人还记得论文里面是如何防止它发生的吗?
论文里的解决方法就是控制输出(Output Rule)。直到Backup虚机确认收到了相应的Log条目,Primary虚机不允许生成任何输出。让我们回到Primary崩溃前,并且计数器的内容还是10,Primary上的正确的流程是这样的:
- 1.客户端输入到达Primary。
- 2.Primary的VMM将输入的拷贝发送给Backup虚机的VMM。所以有关输入的Log条目在Primary虚机生成输出之前,就发往了Backup。之后,这条Log条目通过网络发往Backup,但是过程中有可能丢失。
- 3.Primary的VMM将输入发送给Primary虚机,Primary虚机生成了输出。现在Primary虚机的里的数据已经变成了11,生成的输出也包含了11。但是VMM不会无条件转发这个输出给客户端。
- 4.Primary的VMM会等到之前的Log条目都被Backup虚机确认收到了才将输出转发给客户端。所以,包含了客户端输入的Log条目,会从Primary的VMM送到Backup的VMM,Backup的VMM不用等到Backup虚机实际执行这个输入,就会发送一个表明收到了这条Log的ACK报文给Primary的VMM。当Primary的VMM收到了这个ACK,才会将Primary虚机生成的输出转发到网络中。
所以,这里的核心思想是,确保在客户端看到对于请求的响应时,Backup虚机一定也看到了对应的请求,或者说至少在Backup的VMM中缓存了这个请求。这样,我们就不会陷入到这个奇怪的场景:客户端已经收到了回复,但是因为有故障发生和副本切换,新接手的副本完全不知道客户端之前收到了对应的回复。
如果在上面的步骤2中,Log条目通过网络发送给Backup虚机时丢失了,然后Primary虚机崩溃了。因为Log条目丢失了, 所以Backup节点也不会发送ACK消息。所以,如果Log条目的丢失与Primary的崩溃同一时间发生,那么Primary必然在VMM将回复转发到网络之前就崩溃了,所以客户端也就不会收到任何回复,所以客户端就不会观察到任何异常。这就是输出控制(Output rule)。
学生提问:VMM这里是具体怎么实现的?
Robert教授:我不太清楚,论文也没有说VMM是如何实现的。我的意思是,这里涉及到非常底层的内容,因为包括了内存分配,页表(page table)分配,设备驱动交互,指令拦截,并理解guest操作系统正在执行的指令。这些都是底层的东西,它们通常用C或者C++实现,但是具体的内容我就不清楚了。
所以,Primary会等到Backup已经有了最新的数据,才会将回复返回给客户端。这几乎是所有的复制方案中对于性能产生伤害的地方。这里的同步等待使得Primary不能超前Backup太多,因为如果Primary超前了并且又故障了,对应的就是Backup的状态落后于客户端的状态。
 所以,几乎每一个复制系统都有这个问题,在某个时间点,Primary必须要停下来等待Backup,这对于性能是实打实的限制。即使副本机器在相邻的机架上,Primary节点发送消息并收到回复仍然需要0.5毫秒的延时。如果我们想要能承受类似于地震或者城市范围内的断电等问题,Primary和Backup需要在不同的城市,之间可能有5毫秒的差距。如果我们将两个副本放置在不同的城市,每次生成一个输出时,都需要至少等待5毫秒,等Backup确认收到了前一个Log条目,然后VMM才能将输出发送到网络。对于一些低请求量的服务,这不是问题。但是如果我们的服务要能够每秒处理数百万个请求,那就会对我们的性能产生巨大的伤害。
所以,几乎每一个复制系统都有这个问题,在某个时间点,Primary必须要停下来等待Backup,这对于性能是实打实的限制。即使副本机器在相邻的机架上,Primary节点发送消息并收到回复仍然需要0.5毫秒的延时。如果我们想要能承受类似于地震或者城市范围内的断电等问题,Primary和Backup需要在不同的城市,之间可能有5毫秒的差距。如果我们将两个副本放置在不同的城市,每次生成一个输出时,都需要至少等待5毫秒,等Backup确认收到了前一个Log条目,然后VMM才能将输出发送到网络。对于一些低请求量的服务,这不是问题。但是如果我们的服务要能够每秒处理数百万个请求,那就会对我们的性能产生巨大的伤害。
所以如果条件允许,人们会更喜欢使用在更高层级做复制的系统(详见4.2 最后两段)。这样的复制系统可以理解操作的含义,这样的话Primary虚机就不必在每个网络数据包暂停同步一下,而是可以在一个更高层级的操作层面暂停来做同步,甚至可以对一些只读操作不做暂停。但是这就需要一些特殊的应用程序层面的复制机制。
学生提问:其实不用暂停Primary虚机的执行,只需要阻止Primary虚机的输出就行吧?
Robert教授:你是对的。所以,这里的同步等待或许没有那么糟糕。但是不管怎么样,在一个系统中,本来可以几微秒响应一个客户端请求,而现在我们需要先更新另一个城市的副本,这可能会将一个10微秒的操作变成10毫秒。
学生提问:这里虽然等待时间比较长,如果提高请求的并发度,是不是还是可以有高性能?
Robert教授:如果你有大量的客户端并发的发送请求,那么你或许还是可以在高延时的情况下获得高的吞吐量,但是就需要你有足够聪明的设计和足够的幸运。
学生提问:可以不可以将Log保留在Primary虚机对应的物理服务器内存中,这样就不用长时间的等待了。
Robert教授:这是一个很好的想法。但是如果你这么做的话,物理服务器宕机,Log就丢失了。通常,如果服务器故障,就认为服务器中的所有数据都没了,其中包括内存的内容。如果故障是某人不小心将服务器的电源拔了,即使Primary对应的物理服务器有电池供电的RAM,Backup也没办法从其获取Log。实际上,系统会在Backup的内存中记录Log。为了保证系统的可靠性,Primary必须等待Backup的ACK才真正输出。你这里的想法很好,但是我们还是不能使用Primary的内存来存Log。
学生提问:能不能输入送到Primary,输出从Backup送出?
Robert教授:这是个很聪明的想法。我之前完全没有想到过这点。它或许可以工作,我不确定,但是这很有意思。
重复输出(Duplicated Output)
还有一种可能的情况是,回复报文已经从VMM发往客户端了,所以客户端收到了回复,但是这时Primary虚机崩溃了。而在Backup侧,客户端请求还堆积在Backup对应的VMM的Log等待缓冲区(详见4.4倒数第二个学生提问),也就是说客户端请求还没有真正发送到Backup虚机中。当Primary崩溃之后,Backup接管服务,Backup首先需要消费所有在等待缓冲区中的Log,以保持与Primay在相同的状态,这样Backup才能以与Primary相同的状态接管服务。假设最后一条Log条目对应来自客户端的请求,那么Backup会在处理完客户端请求对应的中断之后,再上线接管服务。这意味着,Backup会将自己的计数器增加到11(原来是10,处理完客户端的自增请求变成11),并生成一个输出报文。因为这时,Backup已经上线接管服务,它生成的输出报文会被它的VMM发往客户端。这样客户端会收到两个内容是11的回复。如果这里的情况真的发生了,那么明显这也是一个异常行为,因为不可能在运行在单个服务器的服务上发生这种行为。好消息是,几乎可以肯定,客户端通过TCP与服务进行交互,也就是说客户端请求和回复都通过TCP Channel收发。当Backup接管服务时,因为它的状态与Primary相同,所以它知道TCP连接的状态和TCP传输的序列号。当Backup生成回复报文时,这个报文的TCP序列号与之前Primary生成报文的TCP序列号是一样的,这样客户端的TCP栈会发现这是一个重复的报文,它会在TCP层面丢弃这个重复的报文,用户层的软件永远也看不到这里的重复。
这里可以认为是异常的场景,并且被意外的解决了。但是事实上,对于任何有主从切换的复制系统,基本上不可能将系统设计成不产生重复输出。为了避免重复输出,有一个选项是在两边都不生成输出,但这是一个非常糟糕的做法(因为对于客户端来说就是一次失败的请求)。当出现主从切换时,切换的两边都有可能生成重复的输出,这意味着,某种程度上来说,所有复制系统的客户端需要一种重复检测机制。这里我们使用的是TCP来完成重复检测,如果我们没有TCP,那就需要另一种其他机制,或许是应用程序级别的序列号。
在lab2和lab3中,基本上可以看到我们前面介绍的所有内容,例如输出控制,你会设计你的复制状态机。
学生提问:太长了,听不太清,直接看回答吧。
Robert教授:第一部分是对的。当Backup虚机消费了最后一条Log条目,这条Log包含了客户端的请求,并且Backup上线了。从这个时间点开始,我们不需要复制任何东西,因为Primary已经挂了,现在没有任何其他副本。
如果Primary向客户端发送了一个回复报文,之后,Primary或者客户端关闭了TCP连接,所以现在客户端侧是没有TCP连接的。Primary挂了之后,Backup虚机还是有TCP连接的信息。Backup执行最后一条Log,Backup会生成一个回复报文,但是这个报文送到客户端时,客户端并没有相应的TCP连接信息。客户端会直接丢弃报文,就像这个报文不存在一样。哦不!这里客户端实际会发送一个TCP Reset,这是一个类似于TCP error的东西给Backup虚机,Backup会处理这里的TCP Reset,但是没关系,因为现在只有一个副本,Backup可以任意处理,而不用担心与其他副本有差异。实际上,Backup会直接忽略这个报文。现在Backup上线了,在这个复制系统里面,它不受任何人任何事的限制。
学生提问:Backup接手服务之后,对于之前的TCP连接,还能用相同的TCP源端口来发送数据吗(因为源端口一般是随机的)?
Robert教授:你可以这么认为。因为Backup的内存镜像与Primary的完全一致,所以它们会以相同的TCP源端口来发送数据,它们在每一件事情上都是一样的。它们发送的报文每一bit都是一样的。
学生提问:甚至对于IP地址都会是一样的吗,毕竟这里涉及两个物理服务器?
Robert教授:在这个层面,物理服务器并没有IP地址。在我们的例子中,Primary虚机和Backup虚机都有IP地址,但是物理服务器和VMM在网络上基本是透明的。物理服务器上的VMM在网络上并没有自己的唯一标识。虚拟机有自己独立的操作系统和独立的TCP栈,但是对于IP地址和其他的关联数据,Primary和Backup是一样的(类似于HA VIP)。当虚机发送一个网络报文,它会以虚机的IP地址和MAC地址来发送,这些信息是直接透传到局域网的,而这正是我们想要的。所以Backup会生成与Primary完全一样的报文。这里有一些tricky,因为如果物理服务器都接在一个以太网交换机上,那么它们必然在交换机的不同端口上,在发生切换时,我们希望以太网交换机能够知道当前主节点在哪,这样才能正常的转发报文,这会有一些额外的有意思的事情。大部分时候,Primary和Backup都是生成相同的报文,并送出。
(注:早期的VMware虚机都是直接以VLAN或者Flat形式,通过DVS接入到物理网络,所以虚拟机的报文与物理机无关,可以直接在局域网发送。以太网交换机会维护MAC地址表,表明MAC地址与交换机端口的对应,因为Primary和Backup虚机的MAC地址一样,当主从切换时,这个表需要更新,这样同一个目的MAC地址,切换前是发往了Primary虚机所在的物理服务器对应的交换机端口,切换之后是发往了Backup虚机所在的物理服务器对应的交换机端口。交换机MAC地址表的切换通常通过虚机主动发起GARP来更新。)
Test-and-Set 服务
最后还有一个细节。我一直都假设Primary出现的是fail-stop故障(详见4.1最开始),但是这不是所有的情况。一个非常常见的场景就是,Primary和Backup都在运行,但是它们之间的网络出现了问题,同时它们各自又能够与一些客户端通信。这时,它们都会以为对方挂了,自己需要上线并接管服务。所以现在,我们对于同一个服务,有两个机器是在线的。因为现在它们都不向彼此发送Log条目,它们自然就出现了分歧。它们或许会因为接收了不同的客户端请求,而变得不一样。
因为涉及到了计算机网络,那就可能出现上面的问题,而不仅仅是机器故障。如果我们同时让Primary和Backup都在线,那么我们现在就有了脑裂(Split Brain)。这篇论文解决这个问题的方法是,向一个外部的第三方权威机构求证,来决定Primary还是Backup允许上线。这里的第三方就是Test-and-Set服务。
Test-and-Set服务不运行在Primary和Backup的物理服务器上,VMware FT需要通过网络支持Test-and-Set服务。这个服务会在内存中保留一些标志位,当你向它发送一个Test-and-Set请求,它会设置标志位,并且返回旧的值。Primary和Backup都需要获取Test-and-Set标志位,这有点像一个锁。为了能够上线,它们或许会同时发送一个Test-and-Set请求,给Test-and-Set服务。当第一个请求送达时,Test-and-Set服务会说,这个标志位之前是0,现在是1。第二个请求送达时,Test-and-Set服务会说,标志位已经是1了,你不允许成为Primary。对于这个Test-and-Set服务,我们可以认为运行在单台服务器。当网络出现故障,并且两个副本都认为对方已经挂了时,Test-and-Set服务就是一个仲裁官,决定了两个副本中哪一个应该上线。
对于这种机制有什么问题吗?
学生提问:只有在网络故障的时候才需要询问Test-and-Set服务吗?
Robert教授:即使没有网络分区,在所有情况下,两个副本中任意一个觉得对方挂了,哪怕对方真的挂了,想要上线的那个副本仍然需要获得Test-and-Set服务的锁。在6.824这门课程中,有个核心的规则就是,你无法判断另一个计算机是否真的挂了,你所知道的就是,你无法从那台计算机收到网络报文,你无法判断是因为那台计算机挂了,还是因为网络出问题了导致的。所以,Backup看到的是,我收不到来自Primary的网络报文,或许Primary挂了,或许还活着。Primary或许也同时看不到Backup的报文。所以,如果存在网络分区,那么必然要询问Test-and-Set服务。但是实际上没人知道现在是不是网络分区,所以每次涉及到主从切换,都需要向Test-and-Set服务进行查询。所以,当副本想要上线的时候,Test-and-Set服务必须要在线,因为副本需要获取这里的Test-and-Set锁。现在Test-and-Set看起来像是个单点故障(Single-Point-of-Failure)。虽然VMware FT尝试构建一个复制的容错的系统,**但是最后,主从切换还是依赖于Test-and-Set服务在线,这有点让人失望。我强烈的认为,Test-and-Set服务本身也是个复制的服务,并且是容错的。**几乎可以肯定的是,VMware非常乐意向你售卖价值百万的高可用存储系统,系统内使用大量的复制服务。因为这里用到了Test-and-Set服务,我猜它也是复制的。
你们将要在Lab2和Lab3构建的系统,会帮助你们构建容错的Test-and-Set服务,所以这个问题可以轻易被解决。
FAQ
Q: The introduction says that it is more difficult to ensure deterministic execution on physical servers than on VMs. Why is this the case? 原文说在物理服务器上确保决定性执行比虚拟机上要困难,为什么?
A: Ensuring determinism is easier on a VM because the hypervisor emulates and controls many aspects of the hardware that might differ between primary and backup executions, for example the precise timing of interrupt delivery. 在VM上hypervisor可以进行仿真和控制硬件来保证主从一致,例如竞逐控制中断时间。
Q: What is a hypervisor?
A: A hypervisor is part of a Virtual Machine system; it’s the same as the Virtual Machine Monitor (VMM). The hypervisor emulates a computer, and a guest operating system (and applications) execute inside the emulated computer. The emulation in which the guest runs is often called the virtual machine. In this paper, the primary and backup are guests running inside virtual machines, and FT is part of the hypervisor implementing each virtual machine. 是虚拟机系统的一部分,与VMM相同。控制电脑中的子系统。原文中的主从节点即虚拟机,FT是hypervisor对每个虚拟机实现的一部分。
Q: Both GFS and VMware FT provide fault tolerance. How should we think about when one or the other is better? GFS和VM-FT的容错性哪个更好?
A: FT replicates computation; you can use it to transparently add fault-tolerance to any existing network server. FT provides fairly strict consistency and is transparent to server and client. You might use FT to make an existing mail server fault-tolerant, for example. GFS, in contrast, provides fault-tolerance just for storage. Because GFS is specialized to a specific simple service (storage), its replication is more efficient than FT. For example, GFS does not need to cause interrupts to happen at exactly the same instruction on all replicas. GFS is usually only one piece of a larger system to implement complete fault-tolerant services. For example, VMware FT itself relies on a fault-tolerant storage service shared by primary and backup (the Shared Disk in Figure 1), which you could use something like GFS to implement (though at a detailed level GFS wouldn’t be quite the right thing for FT). FT冗余了计算,你可用它来透明地添加容错性。FT提供了对服务器和客户端透明的强一致性。可以用FT来保证已有邮件服务的容错性。而GFS只为存储提供容错性,GFS是一种特定简单服务,其副本比FT更高效。如GFS不需要控制中断指令执行点,只用整个系统的一部分来部署容错。而VM-FT本身依赖于主从共享的容错存储服务,这种服务也可用GFS保证(尽管细节不一定正确)。
Q: How do Section 3.4’s bounce buffers help avoid races? Bounce Buffer(回弹缓冲区)如何帮助避免竞争?
A: The problem arises when a network packet or requested disk block arrives at the primary and needs to be copied into the primary’s memory. Without FT, the relevant hardware copies the data into memory while software is executing. Guest instructions could read that memory during the DMA; depending on exact timing, the guest might see or not see the DMA’d data (this is the race). It would be bad if the primary and backup both did this, but due to slight timing differences one read just after the DMA and the other just before. In that case they would diverge. 当网络包或硬盘块请求到达主节点并需要复制进主节点内存时会出现问题。没有FT,相关硬件会在软件执行时将数据拷贝进内存。子指令会在DMA时读到内存,根据实际时间,子指令会看到DMA数据(这便是竞争)。主从节点都发生这种现象并不好,但由于一个是在DMA前读,一个是在DMA后读,就会发生分歧。
FT avoids this problem by not copying into guest memory while the primary or backup is executing. FT first copies the network packet or disk block into a private “bounce buffer” that the primary cannot access. When this first copy completes, the FT hypervisor interrupts the primary so that it is not executing. FT records the point at which it interrupted the primary (as with any interrupt). Then FT copies the bounce buffer into the primary’s memory, and after that allows the primary to continue executing. FT sends the data to the backup on the log channel. The backup’s FT interrupts the backup at the same instruction as the primary was interrupted, copies the data into the backup’s memory while the backup is into executing, and then resumes the backup. FT通过禁止在主从节点执行时拷贝数据进入来解决这一问题。首先将网络包或硬盘块复制到主节点无法访问的bounce buffer。拷贝完毕后中断prim,记录中断时间点,然后将bounce buffer传入prim内存,再让prim继续执行。FT通过log通道将数据发送给备份。备份在同样时间点中断并执行像中指令,传入内存。
The effect is that the network packet or disk block appears at exactly the same time in the primary and backup, so that no matter when they read the memory, both see the same data.
Q: What is “an atomic test-and-set operation on the shared storage”? 在共享存储上的“原子化测试置位”操作是什么?(其实感觉就是类似CAS)
A: The system uses a network disk server, shared by both primary and backup (the “shared disk” in Figure 1). That network disk server has a “test-and-set service”. The test-and-set service maintains a flag that is initially set to false. If the primary or backup thinks the other server is dead, and thus that it should take over by itself, it first sends a test-and-set operation to the disk server. The server executes roughly this code: 维护了一个默认为false的标志位,若主/从节点认为其它服务器宕机,应该接管该标志位。
test-and-set() {
acquire_lock()
if flag == true:
release_lock()
return false
else:
flag = true
release_lock()
return true
The primary (or backup) only takes over (“goes live”) if test-and-set returns true.
The higher-level view is that, if the primary and backup lose network contact with each other, we want only one of them to go live. The danger is that, if both are up and the network has failed, both may go live and develop split brain. If only one of the primary or backup can talk to the disk server, then that server alone will go live. But what if both can talk to the disk server? Then the network disk server acts as a tie-breaker; test-and-set returns true only to the first call. 更高层次的观点是,如果主/从节点与对方失联,只有其中一个go live,否则会脑裂。这里时引入了一个第三方解决脑裂。
Q: How much performance is lost by following the Output Rule? 由于遵循Output Rule损失了多少性能?
A: Table 2 provides some insight. By following the output rule, the transmit rate is reduced, but not hugely. 损失并不巨大
Q: What if the application calls a random number generator? Won’t that yield different results on primary and backup and cause the executions to diverge? 应用调用随机数操作导致主从分歧?
A: The primary and backup will get the same number from their random number generators. All the sources of randomness are controlled by the hypervisor. For example, the application may use the current time, or a hardware cycle counter, or precise interrupt times as sources of randomness. In all three cases the hypervisor intercepts the the relevant instructions on both primary and backup and ensures they produce the same values. 所有随机性的来源都被hypervisor控制。如应用会采用当前时间、应间循环计数或精确中断事件作随机性来源。这些场景中hypervisor都会拦截主从的相关指令保证输出相同值。
Q: How were the creators certain that they captured all possible forms of non-determinism? 作者如何保证他们捕获了所有可能形式的非确定性操作?
A: My guess is as follows. The authors work at a company where many people understand VM hypervisors, microprocessors, and internals of guest OSes well, and will be aware of many of the pitfalls. For VM-FT specifically, the authors leverage the log and replay support from a previous a project (deterministic replay), which must have already dealt with sources of non-determinism. I assume the designers of deterministic replay did extensive testing and gained experience with sources of non-determinism that the authors of VM-FT use. 我猜想是这样的:作者在一个很多人懂VM管理、微处理器、客户操作系统的公司工作,对许多缺陷很了解。对于VM-FT而言,作者必须已经处理好了非确定性操作才能充分利用log和replay。我假设作者作了充分的实验。
Q: What happens if the primary fails just after it sends output to the external world? 如果prim在刚给外部输出后的几秒钟内挂了怎么办?
A: The backup will likely repeat the output after taking over, so that it’s generated twice. This duplication is not a problem for network and disk I/O. If the output is a network packet, then the receiving client’s TCP software will discard the duplicate automatically. If the output event is a disk I/O, disk I/Os are idempotent (both write the same data to the same location, and there are no intervening I/Os). 从节点可能在接管后重复输出,因而会有两次输出。对于网络和硬盘IO来讲这不是问题。对于网络,TCP会丢掉重复包;而硬盘IO本身就符合幂等性保证。
Q: Section 3.4 talks about disk I/Os that are outstanding on the primary when a failure happens; it says “Instead, we re-issue the pending I/Os during the go-live process of the backup VM.” Where are the pending I/Os located/stored, and how far back does the re-issuing need to go? 原文3.4节讲到了故障发生时prim上未完成的磁盘io:“我们在备份虚拟机启动的过程中重新发起挂起的io”。挂起的io位于/存储在哪里,出行发起需要回溯多远?
A: The paper is talking about disk I/Os for which there is a log entry indicating the I/O was started but no entry indicating completion. These are the I/O operations that must be re-started on the backup. When an I/O completes, the I/O device generates an I/O completion interrupt. So, if the I/O completion interrupt is missing in the log, then the backup restarts the I/O. If there is an I/O completion interrupt in the log, then there is no need to restart the I/O. 原文谈论的是磁盘io,其中有一个条目表示io已经启动但是没有条目表示io已经完成。这些是在备份上必须重启的io。当io结束时,io设备生成io完成中断。所以如果log没有记录io完成中断,那么备份会重启io。
Q: How is the backup FT able to deliver an interrupt at a particular point in the backup instruction stream (i.e. at the same instruction at which the interrupt originally occured on the primary)? 备份FT为什么能在备份指令流中传递特定时间点的中断(与prim中相同的中断)。
A: Many CPUs support a feature (the “performance counters”) that lets the FT VMM tell the CPU a number of instructions, and the CPU will interrupt to the FT VMM after that number of instructions. 许多CPU都支持性能计数——让FT VMM能告知CPU指令数量,而CPU将在特定数量的指令后中断到FT VMM。
Q: How secure is this system? 这个系统是安全的吗?
A: The authors assume that the primary and backup follow the protocol and are not malicious (e.g., an attacker didn’t compromise the hypervisors). The system cannot handle compromised hypervisors. On the other hand, the hypervisor can probably defend itself against malicious or buggy guest operating systems and applications. 作者假设主从节点都根据协议执行(如,攻击者不会危及hypervisors)。系统无法处理被污染的hypervisors,另一方面,虚拟机监控程序可能可以保护自己免受恶意或有错误的客户操作系统和应用程序的攻击。
Q: Is it reasonable to address only the fail-stop failures? What are other type of failures? 只解决fail-stop 问题是合理的吗?其它类型的问题呢?
A: It is reasonable, since many real-world failures are essentially fail-stop, for example many network and power failures. Doing better than this requires coping with computers that appear to be operating correctly but actually compute incorrect results; in the worst case, perhaps the failure is the result of a malicious attacker. This larger class of non-fail-stop failures is often called “Byzantine”. There are ways to deal with Byzantine failures, which we’ll touch on at the end of the course, but most of 6.824 is about fail-stop failures. 是合理的,因为许多现实问题本质就是fail-stop,例如许多网络和电源故障。要做得更好意味着需要处理op正确但结果错误的电脑,最坏情况下,可能错误是由恶意攻击造成的。这类更大的non-fail-stop故障称为“拜占庭”。有方法能够处理拜占庭错误,我们会在课程的最后了解,但现在6.824的大多数问题是关于fail-stop。
讲义
复制
The topic is (still) fault tolerance
- to provide availability
- despite server and network failures
- using replication
What kinds of failures can replication deal with?(略)
Is replication worth the Nx expense?
状态转移和复制状态机
Two main replication approaches:
- State transfer
- Primary replica executes the service
- Primary sends [new] state to backups
- Replicated state machine
- Clients send operations to primary, primary sequences and sends to backups
- All replicas execute all operations
- If same start state,
- same operations,
- same order,
- deterministic,
- then same end state.
Big Questions:
- What state to replicate? 要复制什么状态
- Does primary have to wait for backup? 主节点需要等待备份吗?
- When to cut over to backup? 何时切换到备份?
- Are anomalies visible at cut-over? 切换时的异常可见吗?
- How to bring a replacement backup up to speed? 如何加速备份
At what level do we want replicas to be identical? 在哪一层面进行复制
- Application state, e.g. a database’s tables? 应用层面,如数据库的数据表
- GFS works this way 即GFS
- Can be efficient; primary only sends high-level operations to backup 是高效的,prim只发送高级op
- Application code (server) must understand fault tolerance, to e.g. forward op stream 应用层必须理解容错性
- Machine level, e.g. registers and RAM content? 机器层面,如寄存器和内存
- might allow us to replicate any existing server w/o modification!
- requires forwarding of machine events (interrupts, DMA, &c) 需要转发机器事件,如中断、DMA
- requires “machine” modifications to send/recv event stream… 需要硬件的改动来发送/接收事件流
Today’s paper (VMware FT) replicates machine-level state
- Transparent: can run any existing O/S and server software!
- Appears like a single server to clients
Overview
- [diagram: app, O/S, VM-FT underneath, disk server, network, clients]
- words:
- **hypervisor == monitor == VMM (virtual machine monitor) **
- O/S+app is the “guest” running inside a virtual machine
- two machines, primary and backup
- primary sends all external events (client packets &c) to backup over network
- “logging channel”, carrying log entries
- ordinarily, backup’s output is suppressed by FT 备份的输出被FT取消
- if either stops being able to talk to the other over the network 若一方无法与另一方通信
- “goes live” and provides sole service
- if primary goes live, it stops sending log entries to the backup
VMM emulates a local disk interface VMM模拟了一个本地硬盘接口
- but actual storage is on a network server 但实际上是存在网络服务器
- treated much like a client: 就像对待客户端一样
- usually only primary communicates with disk server (backup’s FT discards) 一般只有prim会与硬盘服务器通信
- if backup goes live, it talks to disk server 如果备份goes live,其会与硬盘服务器通信
- external disk makes creating a new backup faster (don’t have to copy primary’s disk) 外部硬盘可以更快的创建一个备份(而不需要拷贝prim的硬盘)
When does the primary have to send information to the backup? prim什么时候给备份发送信息
- Any time something happens that might cause their executions to diverge. 会造成分歧的执行
- Anything that’s not a deterministic consequence of executing instructions. 非确定性的指令执行
What sources of divergence must FT handle? FT应该处理什么样的分歧源?
- Most instructions execute identically on primary and backup. 大部分指令在主从上同等执行
- As long as memory+registers are identical, 只要内存+寄存器相同
- which we’re assuming by induction. 这是我们用归纳法假设的
- As long as memory+registers are identical, 只要内存+寄存器相同
- Inputs from external world – just network packets. 外部输入——只有网络包
- These appear as DMA’d data plus an interrupt. 这些显示为DMA数据加上了中断
- Timing of interrupts. 中断时间点
- Instructions that aren’t functions of state, such as reading current time. 非状态函数指令,如读取当前时间
- Not multi-core races, since uniprocessor only. 由于只有单处理器,非多核竞争
Why would divergence be a disaster? 为什么分歧会是灾难
- b/c state on backup would differ from state on primary, 从节点状态会与主节点不同
- and if primary then failed, clients would see inconsistency.
- Example: GFS lease expiration 例如:GFA租约过期
- Imagine we’re replicating the GFS master 假设我们在复制GFSmaster
- Chunkserver must send “please renew” msg before 60-second lease expires Chunkserver在60s过期前必须发送请求更新的msg
- Clock interrupt drives master’s notion of time 时钟中断驱动着master
- Suppose chunkserver sends “please renew” just around 60 seconds 假设chunkserver在快到60s时才发送更新请求
- On primary, clock interrupt happens just after request arrives. 在prim,时钟中断在请求刚到达后发生
- Primary copy of master renews the lease, to the same chunkserver. master更新租约
- On backup, clock interrupt happens just before request. 在从节点
- Backup copy of master expires the lease. 备份的租约到期
- If primary fails, backup takes over, it will think there 若主从故障切换
- is no lease, and grant it to a different chunkserver. 没有租约,将其授予另一个chunkserver
- Then two chunkservers will have lease for same chunk. 然后两个chunkserver都有租约
- So: backup must see same events, 所以备份必须看到同样的事件
- in same order, 以同样的顺序
- at same points in instruction stream. 在同样的指令流的节点
Each log entry: instruction #, type, data.
FT’s handling of timer interrupts FT对于时钟终端的处理
- Goal: primary and backup should see interrupt at the same point in the instruction stream 目标:主从节点都应在指令流的同一时间中断
- Primary:
- FT fields the timer interrupt FT设置时间中断
- FT reads instruction number from CPU
- FT sends “timer interrupt at instruction X” on logging channel
- FT delivers interrupt to primary, and resumes it
- (this relies on CPU support to interrupt after the X’th instruction)
- Backup:
- ignores its own timer hardware 忽略器自己的时间硬件
- FT sees log entry before backup gets to instruction X
- FT tells CPU to interrupt (to FT) at instruction X
- FT mimics a timer interrupt to backup FT将模拟的时间中断交给备份
FT’s handling of network packet arrival (input) FT对于到达网络包的处理
- Primary:
- FT tells NIC to copy packet data into FT’s private “bounce buffer” FT告知网卡将包数据拷到FT的私有bounce buffer中
- At some point NIC does DMA, then interrupts 在一些节点网卡进行DMA,然后中断
- FT gets the interrupt FT获得中断
- FT pauses the primary FT暂停prim
- FT copies the bounce buffer into the primary’s memory 将bounce buffer拷贝到prim内存
- FT simulates a NIC interrupt in primary FT模拟了prim的网卡中断
- FT sends the packet data and the instruction # to the backup FT将包数据和包指令号发给备份
- Backup:
- FT gets data and instruction # from log stream
- FT tells CPU to interrupt (to FT) at instruction X
- FT copies the data to backup memory, simulates NIC interrupt in backup
Why the bounce buffer?
- We want the data to appear in memory at exactly the same point in execution of the primary and backup. 我们希望数据出现在主从节点内存的时间一致
- Otherwise they may diverge. 否则可能会出现分歧
Note that the backup must lag by one one log entry 注意由于log要一条条处理,备份会延迟
- Suppose primary gets an interrupt, or input, after instruction X
- If backup has already executed past X, it cannot handle the input correctly
- So backup FT can’t start executing at all until it sees the first log entry 备份FT直到获得第一个日志条目才能执行
- Then it executes just to the instruction # in that log entry
- And waits for the next log entry before resuming backup
非确定性指令
Example: non-deterministic instructions 非确定性指令
- some instructions yield different results even if primary/backup have same state
- e.g. reading the current time or cycle count or processor serial #
- Primary:
- FT sets up the CPU to interrupt if primary executes such an instruction
- FT executes the instruction and records the result
- sends result and instruction # to backup
- Backup:
- FT reads log entry, sets up for interrupt at instruction #
- FT then supplies value that the primary got
输出控制
What about output (sending network packets)?
- Primary and backup both execute instructions for output
- Primary’s FT actually does the output
- Backup’s FT discards the output
Output example: DB server (略)
But wait: (略)
Solution: the Output Rule (Section 2.2)
- before primary sends output,
- must wait for backup to acknowledge all previous log entries
Again, with output rule: (略)
The Output Rule is a big deal
- Occurs in some form in all replication systems
- A serious constraint on performance
- An area for application-specific cleverness
- Eg. maybe no need for primary to wait before replying to read-only operation 也许prim在回复只读操作前不需要等待
- FT has no application-level knowledge, must be conservative FT不了解应用层,必须保守
重复输出
Q: What if the primary crashes just after getting ACK from backup, but before the primary emits the output? Does this mean that the output won’t ever be generated? 如果prim在获得从节点的ACK后,自身输出前崩溃了,这意味着不应该产生输出吗?
A: Here’s what happens when the primary fails and the backup goes live.
- The backup got some log entries from the primary. 从节点获得主节点的log
- The backup continues executing those log entries WITH OUTPUT DISCARDED. 从节点继续执行log,忽略输出
- After the last log entry, the backup goes live – stops discarding output 最后一个log后,从节点goes live,可以输出
- In our example, the last log entry is arrival of client request 在本例中,最后一个log就是到达的客户端请求
- So after client request arrives, the client will start emitting outputs 所以
客户端从节点可以发出输出 - And thus it will emit the reply to the client 会回复客户端
Q: But what if the primary crashed after emitting the output? Will the backup emit the output a second time? 如果prim在输出后崩溃呢?从节点会输出第二次吗?
A: Yes. 是的
- OK for TCP, since receivers ignore duplicate sequence numbers. 对于TCP没问题
- OK for writes to disk, since backup will write same data to same block #. 对于硬盘写没问题
Duplicate output at cut-over is pretty common in replication systems 主从切换时的重复输出非常常见
- Clients need to keep enough state to ignore duplicates 忽略重复输出
- Or be designed so that duplicates are harmless 满足幂等性
Test-and-Set
Q: Does FT cope with network partition – could it suffer from split brain? 脑裂?
- E.g. if primary and backup both think the other is down.
- Will they both go live?
A: The disk server breaks the tie.
- Disk server supports atomic test-and-set.
- If primary or backup thinks other is dead, attempts test-and-set.
- If only one is alive, it will win test-and-set and go live.
- If both try, one will lose, and halt.
The disk server may be a single point of failure
- If disk server is down, service is down
- They probably have in mind a replicated disk server
Q: Why don’t they support multi-core?
Performance (table 1)
- FT/Non-FT: impressive!
- little slow down
- Logging bandwidth
- Directly reflects disk read rate + network input rate
- 18 Mbit/s for my-sql
- These numbers seem low to me
- Applications can read a disk at at least 400 megabits/second
- So their applications aren’t very disk-intensive
When might FT be attractive? 什么情况下FT有吸引力
- Critical but low-intensity services, e.g. name server. 关键却低强度的服务,如命名服务器
- Services whose software is not convenient to modify. 不方便修改软件的服务
What about replication for high-throughput services? 而高吞吐服务的复制呢?
- People use application-level replicated state machines for e.g. databases. 用应用层复制,如数据库
- The state is just the DB, not all of memory+disk. 状态只有DB,而非 内存+硬盘
- The events are DB commands (put or get), not packets and interrupts. 事件就是DB命令,而非包和中断
- Result: less fine-grained synchronization, less overhead. 更少的细粒度同步、更少的开销
- GFS use application-level replication, as do Lab 2 &c
Summary:
- Primary-backup replication
- VM-FT: clean example
- How to cope with partition without single point of failure?
- Next lecture
- How to get better performance?
- Application-level replicated state machines
VMware KB (#1013428) talks about multi-CPU support. VM-FT may have switched from a replicated state machine approach to the state transfer approach, but unclear whether that is true or not.
http://www.wooditwork.com/2014/08/26/whats-new-vsphere-6-0-fault-tolerance/
http://www-mount.ece.umn.edu/~jjyi/MoBS/2007/program/01C-Xu.pdf

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)