深度学习入门:从基础概念到核心逻辑,一篇读懂
人工智能的浪潮中,深度学习无疑是最耀眼的分支之一,它让机器拥有了类似人类的 “学习能力”,在图像识别、语音助手、自然语言处理等领域落地生根。很多人觉得深度学习高深难懂,其实它的核心逻辑源于对人脑的简单模拟,今天我们就从基础出发,拆解深度学习的核心概念与运行原理,带你走进这个有趣的领域。
一、深度学习的 “家族关系”:它从哪里来?
想要理解深度学习,首先要理清它和人工智能、机器学习的关系:人工智能是大范畴,机器学习是人工智能的实现手段,而深度学习是机器学习的一个重要研究方向。
简单来说,深度学习是基于人工神经网络发展而来的机器学习方法,它的核心思路是模拟人脑神经元的连接方式,通过多层网络结构从数据中提取特征、学习规律,最终实现对复杂问题的建模和判断。比如让机器识别一张猫的图片,深度学习会通过多层网络一步步提取图片的边缘、纹理、轮廓等特征,最终判断出这是猫,这就是它模仿人脑 “层层分析” 的过程。
二、深度学习的核心:人工神经网络到底是什么?
人脑的思考依赖神经元之间的信号传递,人工神经网络就是对这一过程的简化模拟,它的基本组成单元是神经元,多个神经元按层级连接,就构成了神经网络的基本结构:输入层、中间层、输出层。
1. 神经元:神经网络的 “最小单元”
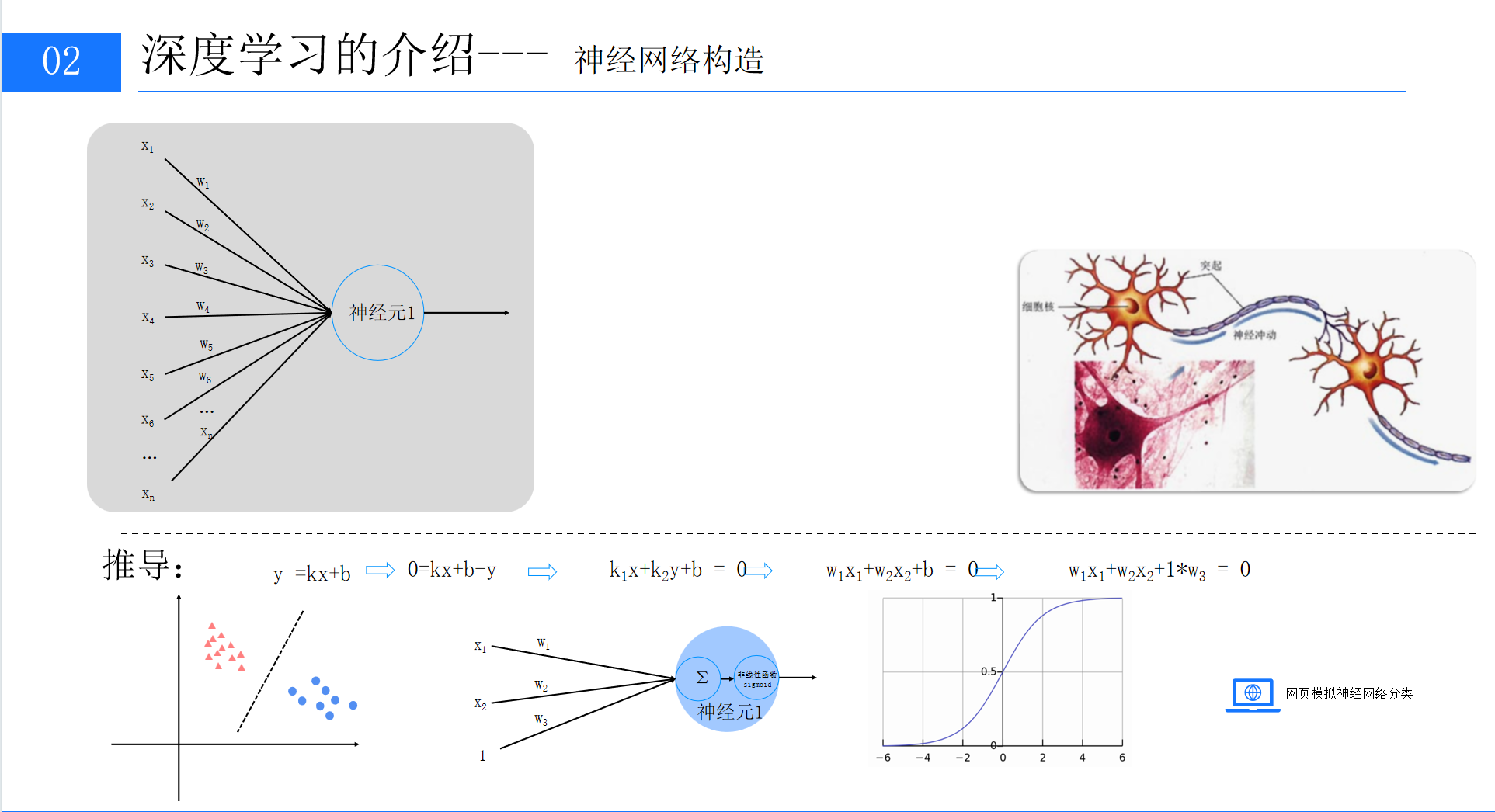
神经元的工作逻辑可以用我们熟悉的一次函数y=kx+b来推导。把外界的输入信号看作x1、x2、x3,每个输入信号传递时会有 “损耗”,这个损耗系数就是权重 w(比如 w1、w2、w3),而b就是偏置项,我们可以把偏置项看作一个恒为 1 的输入信号对应的权重 w3,这样神经元的输入计算就变成了w1x1+w2x2+1*w3。
这些输入信号会先经过求和计算,再通过激活函数(比如经典的 sigmoid 函数)处理,最终输出结果。激活函数的作用是为线性的计算结果加入 “非线性”,这是神经网络能解决复杂非线性问题的关键,就像人脑不会对所有信号做简单的线性判断,而是会有复杂的处理逻辑。
2. 神经网络的三层结构:各有分工
- 输入层:负责接收外界的原始数据,节点数和数据的特征维度完全匹配。比如识别一张图片,若图片有 100 个特征,输入层就有 100 个节点;
- 中间层:介于输入层和输出层之间,是处理特征的 “核心层”,负责从输入的原始特征中提取更抽象、更有价值的特征。隐藏层可以有一层或多层,层数越多,网络的 “深度” 越深,这也是 “深度学习” 名字的由来;
- 输出层:负责输出最终的预测结果,节点数和目标的维度匹配。比如做二分类(猫 / 狗),输出层就有 2 个节点;做多分类,节点数则和分类类别数一致。
这里有个小知识点:除了输出层,输入层和隐藏层都会默认存在偏置节点,它是一个恒为 1 的单元,没有输入信号,作用是调整模型的拟合能力,让模型能更好地匹配数据规律。
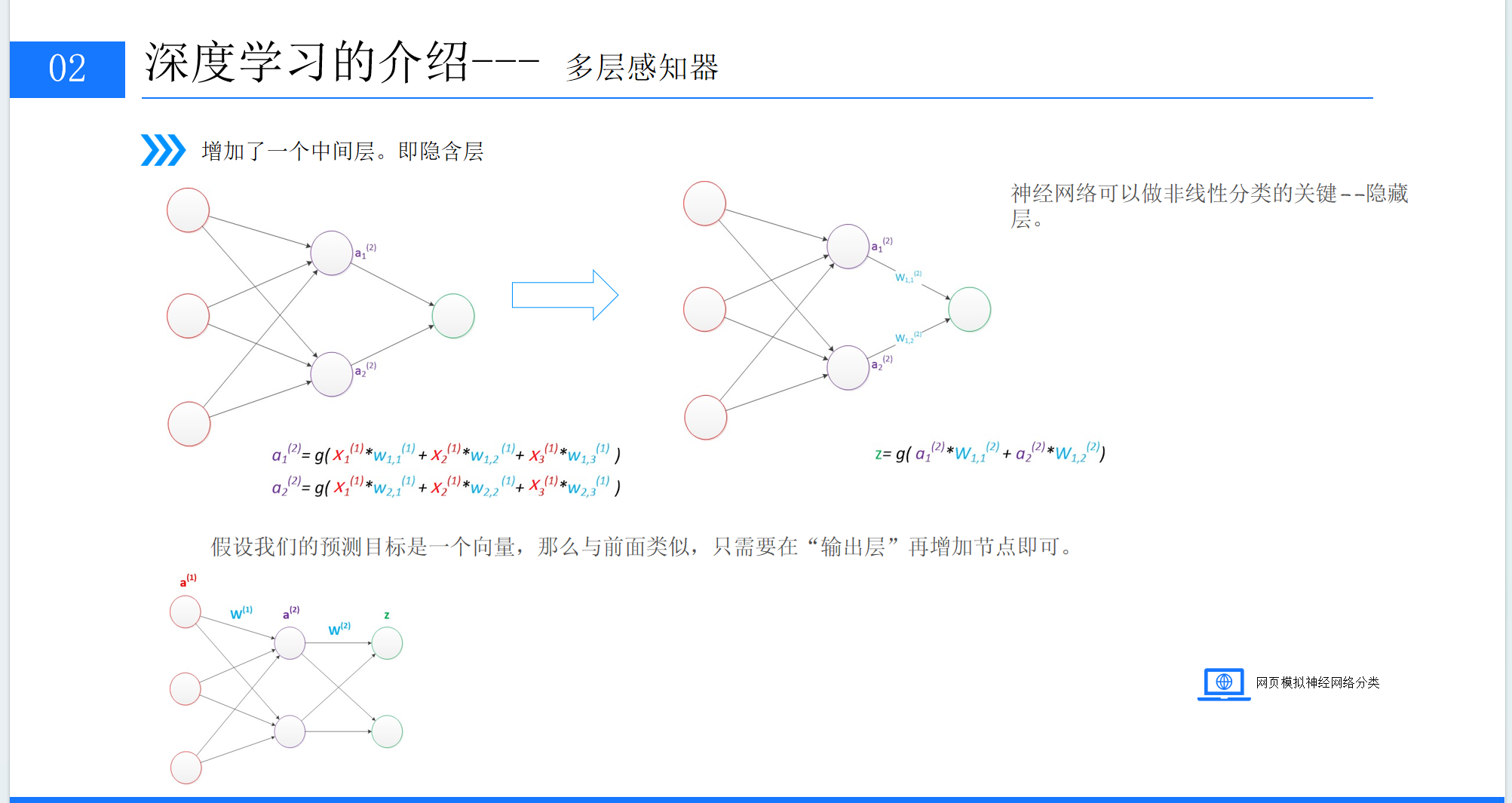
3. 感知器与多层感知器:从简单到复杂

最基础的神经网络是感知器,由两层神经元组成,只能对数据做线性划分,比如用一条直线区分两类数据,能力有限。
而多层感知器在感知器的基础上增加了隐藏层,这也是深度学习的基础结构。隐藏层的加入,让神经网络拥有了非线性分类的能力,能处理更复杂的问题,比如用曲线、曲面区分数据,这也是为什么隐藏层是神经网络实现复杂学习的关键。
三、神经网络的设计:节点数该怎么定?

设计神经网络时,输入层和输出层的节点数是固定的,完全由数据的特征和预测目标决定,而隐藏层的节点数则没有统一的理论标准,业界主要靠经验和实验来确定:
最实用的方法是预先设定几个可选的节点数,分别训练模型,通过对比模型的预测效果,选择效果最好的那个值作为最终的隐藏层节点数。
另外要注意,神经网络结构图里的关键不是代表神经元的 “圆圈”,而是连接神经元的 “线”,每一条线都对应一个权重 w,这个权重是模型需要通过训练学习得到的 “记忆”,权重的好坏直接决定了模型的预测能力。
四、神经网络的训练:让模型 “学会” 规律
神经网络的初始权重都是随机赋值的,此时模型的预测结果误差很大,训练的核心就是不断调整权重,让模型的预测结果越来越接近真实值,整个过程就像我们学习新知识,从 “不会” 到 “会”,从 “错得多” 到 “错得少”。
1. 损失函数:判断模型的 “误差大小”
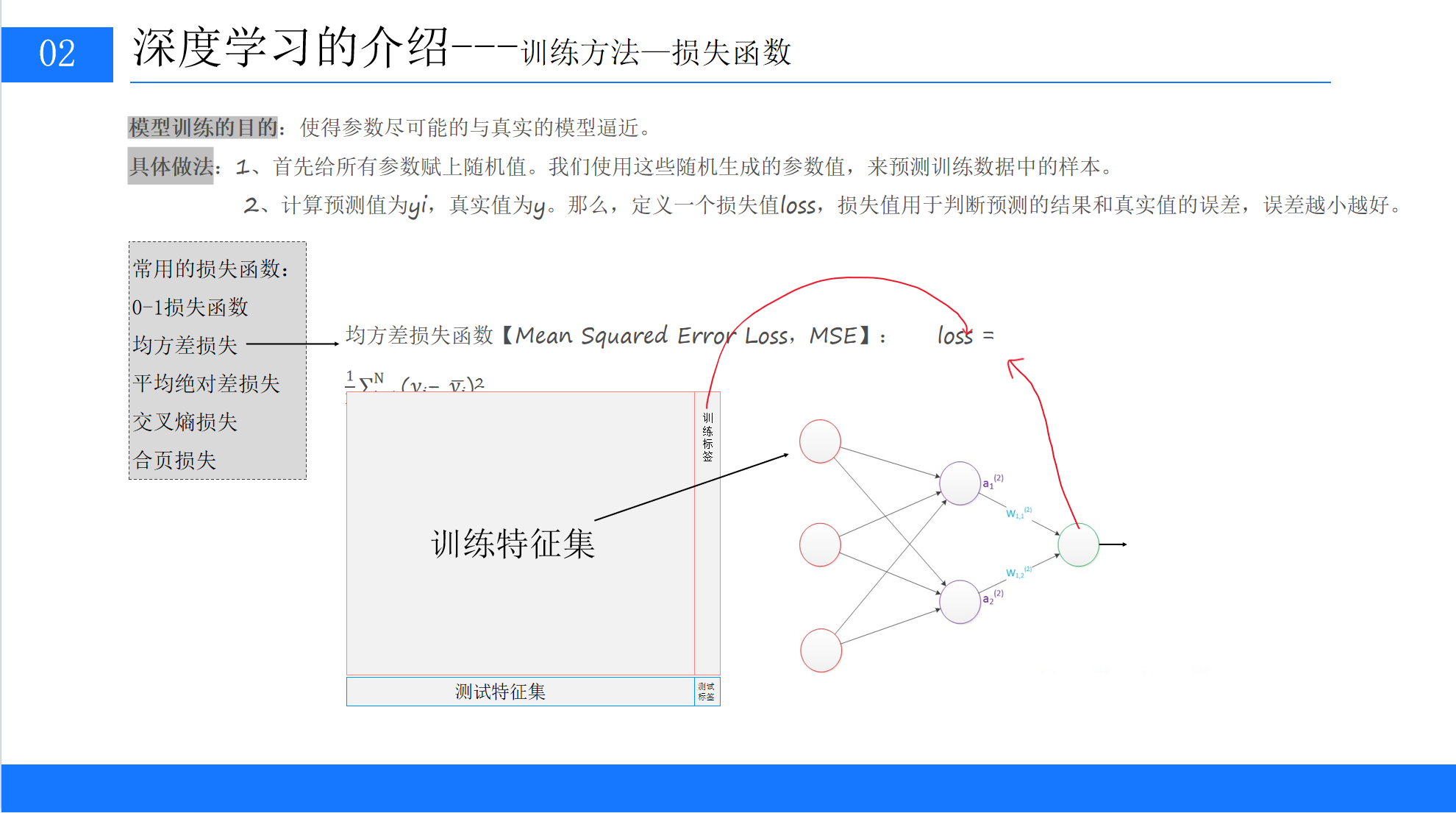
想要调整权重,首先要知道模型的预测误差有多大,损失函数就是用来量化预测值和真实值之间误差的工具,误差越小,损失值越低,模型的效果越好。
常用的损失函数有很多,比如适合回归问题的均方差损失、平均绝对差损失,适合分类问题的交叉熵损失,还有 0-1 损失函数、合页损失等,不同的问题需要选择对应的损失函数。
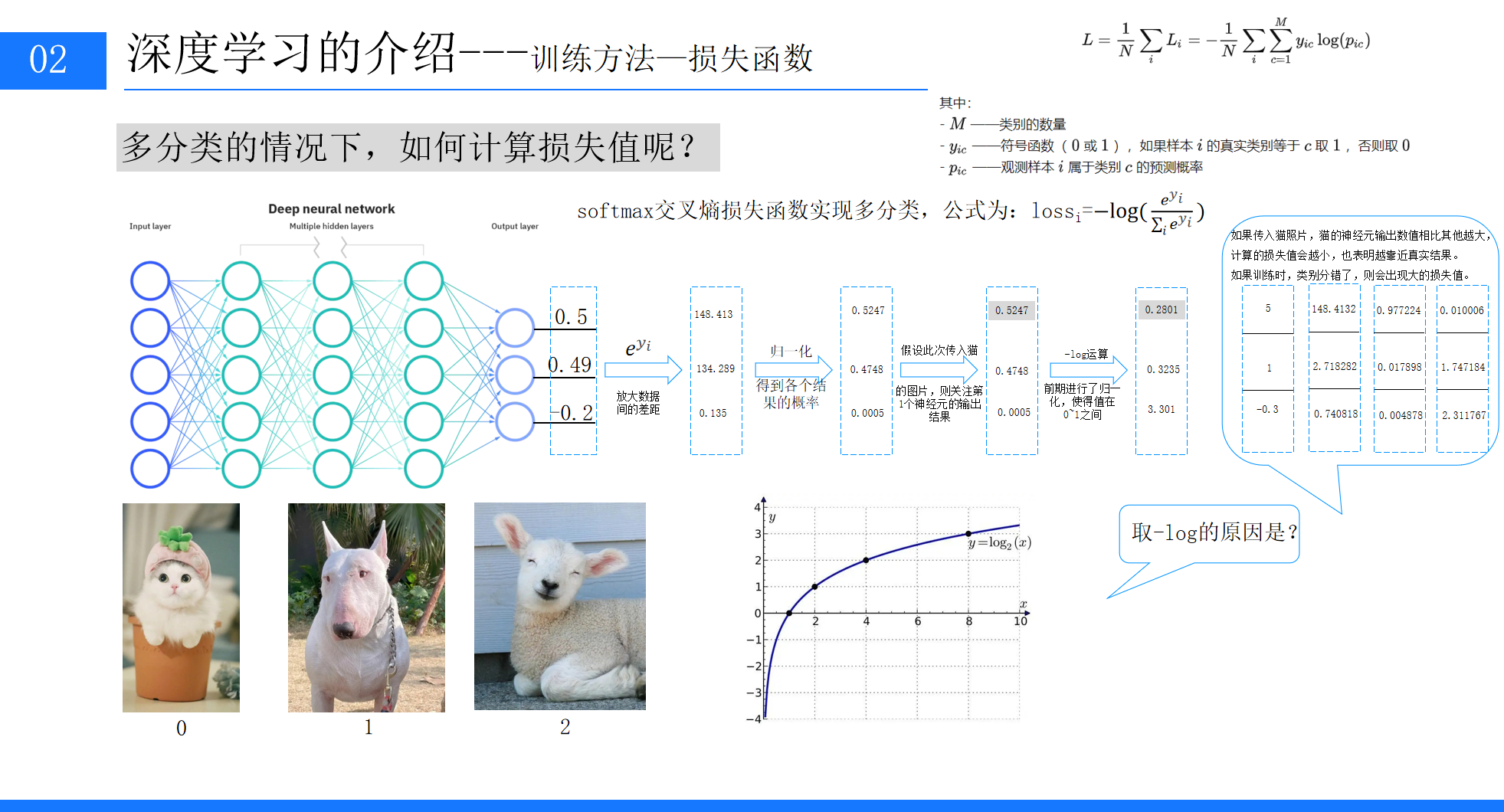
以分类问题为例,模型的输出会先经过归一化处理,转化为 0~1 之间的概率值,再通过取 - log 的方式计算损失值:如果模型正确识别了目标(比如识别出猫),对应的概率值会很大,取 - log 后的损失值就很小;如果识别错误,概率值会很小,损失值就会很大,这样我们就能清晰地判断模型的预测效果。
2. 正则化:防止模型 “学偏”

训练模型时,容易出现过拟合问题:模型在训练数据上表现极好,但在新的测试数据上表现很差,就像一个人死记硬背了题库,却不会做新的题目。
正则化就是解决过拟合的重要手段,核心是 “惩罚” 过大的权重参数,常用的有 L1 和 L2 正则化。它的逻辑很简单:让权重尽可能均匀地匹配所有特征,而不是只依赖少数几个特征,就像学习时要兼顾所有知识点,而不是只死记硬背个别内容,这样模型的泛化能力(适应新数据的能力)会更强。
3. 梯度下降:找到最优的权重
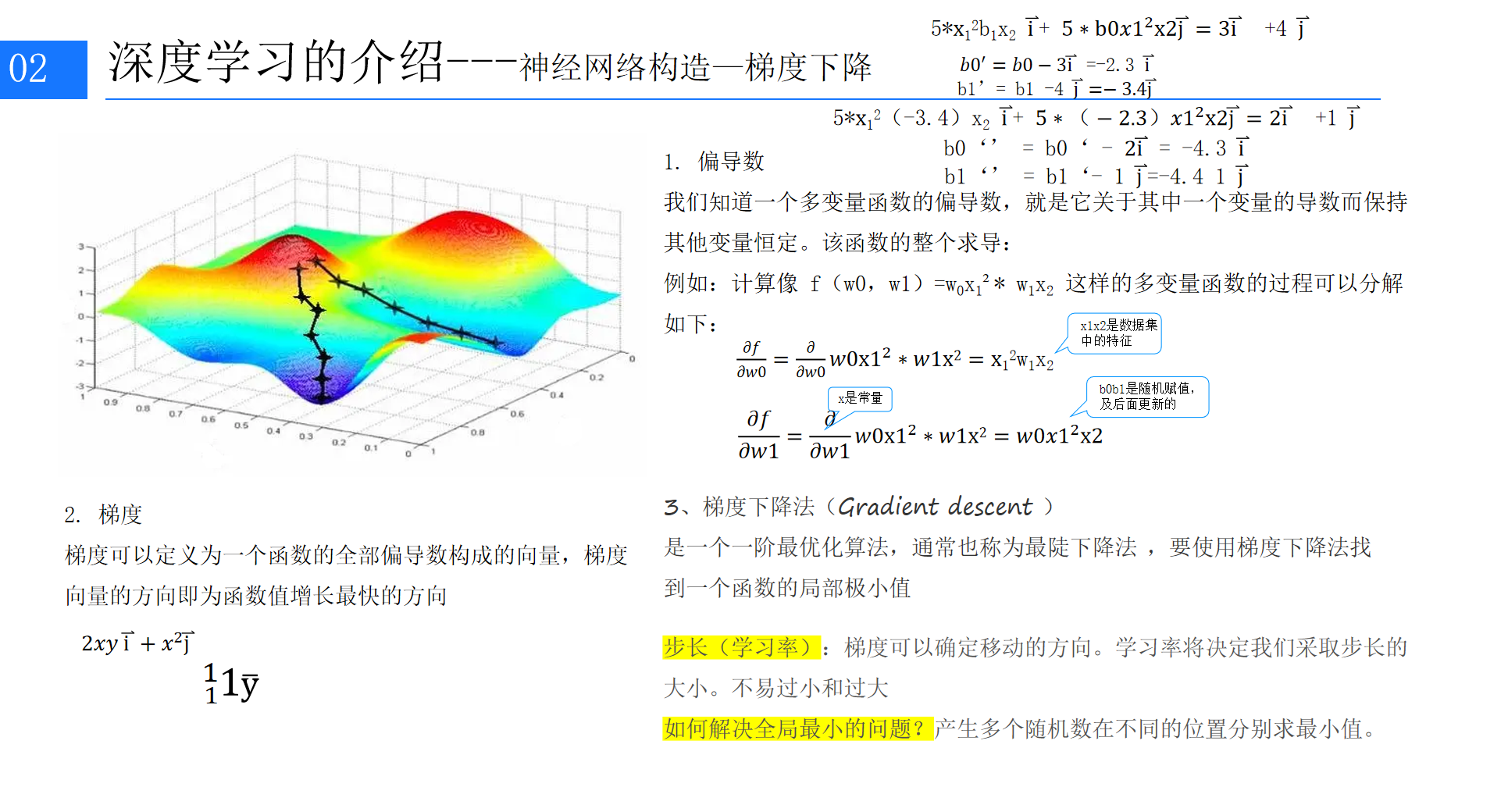
知道了误差大小,接下来就是调整权重,核心方法是梯度下降法,这是深度学习中最基础的优化算法。
想要理解梯度下降,先搞懂两个基础概念:
- 偏导数:多变量函数中,对其中一个变量求导,保持其他变量不变,用来衡量单个变量对函数结果的影响;
- 梯度:由函数的所有偏导数构成的向量,梯度的方向是函数值增长最快的方向,反之,梯度的反方向就是函数值下降最快的方向。
梯度下降的核心思路就是:沿着梯度的反方向调整权重,让损失函数的值不断降低,最终找到损失值最小的权重(局部最优解)。调整过程中,学习率(步长) 是关键:学习率太小,模型训练速度太慢;学习率太大,容易错过最优解,需要根据实际情况调整。
为了找到更接近全局的最优解,通常会用多个随机初始权重分别训练,再选择效果最好的结果。
4. BP 神经网络:反向传播,不断优化

多层神经网络的训练依赖BP(反向传播)神经网络,这是深度学习的核心训练框架,整个过程就是 “正向传播 + 反向传播” 的循环:
- 正向传播:将输入数据传入网络,通过权重计算和激活函数处理,得到最终的预测结果;
- 计算损失:用损失函数计算预测结果和真实值的误差,若有正则化需求,还需加入正则化惩罚项;
- 梯度计算:计算权重对应的梯度,确定权重的调整方向;
- 反向传播:从输出层往输入层反向调整权重,根据梯度和学习率更新每一个权重值;
- 循环迭代:重复上述步骤,不断调整权重,直到损失值小于预设的范围,模型训练完成。
简单来说,正向传播是让模型 “做预测”,反向传播是让模型 “改错误”,通过一次次的预测和修正,模型最终能学到数据中的规律,实现准确的预测。
五、写在最后:深度学习的本质
看到这里,你可能会发现,深度学习看似复杂,实则核心很简单:通过矩阵运算实现神经元之间的信号传递,通过权重和激活函数拟合特征与目标之间的真实规律,通过梯度下降和反向传播不断优化权重,最终让模型拥有预测能力。
神经网络的程序里,其实没有实际的 “神经元” 和 “线”,本质上都是线性代数的矩阵运算,因此掌握线性代数的基础,能更好地理解深度学习的底层逻辑。
深度学习不是一门凭空出现的学科,它源于对人脑的模拟,扎根于数学和计算机科学,从简单的感知器到深度神经网络,它的发展始终围绕着 “让机器更好地学习数据规律” 这一核心。对于刚接触的人来说,不用急于追求复杂的模型和算法,先把基础概念和核心逻辑理解透彻,就是最好的开始。
接下来,你可以尝试了解一些经典的深度学习框架,结合简单的案例动手实践,从 “看懂” 到 “会用”,一步步走进深度学习的世界。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)