计算机毕业设计:拉勾招聘数据分析与智能推荐系统 Spark Hadoop Django框架 TensorFlow 内容推荐 爬虫(建议收藏)✅
·
1、项目介绍
一、技术栈
Python语言、Spark、Hive、Hadoop、Django框架、Echarts可视化、Selenium爬虫技术、基于内容推荐算法、TensorFlow预测算法、拉钩招聘网站数据
二、功能模块
· 可视化分析大屏
· 注册登录
· 薪资分析
· 经验学历分析
· 行业分析
· 城市分析
· 招聘数据中心
· 个人中心
· 我的收藏
· 词云图分析
· 职位推荐
· 薪资预测
· 后台数据管理
· Spark数据分析
· 数据采集
三、项目介绍
本系统基于Python语言开发,结合Spark、Hive、Hadoop构建大数据处理框架,采用Django框架搭建Web应用,利用Selenium爬虫技术从拉钩招聘网站采集招聘数据。系统通过Echarts实现数据可视化展示,涵盖城市平均薪资、工资区间、经验学历分布、行业招聘情况等多维度分析。核心功能包括基于内容推荐算法的职位推荐模块与基于TensorFlow预测算法的薪资预测模块,能够根据用户特征输入输出个性化推荐与薪资预估结果。系统覆盖数据采集、Spark统计分析、Web展示、推荐预测及后台管理全流程,为求职者与招聘管理人员提供全面的招聘数据分析服务。
2、项目界面
1、可视化分析大屏(城市平均薪资Top10、工资区间分析、工资经验薪资分析、各省市招聘数据分布、公司人数分析、薪资Top10工作、最高薪资岗位)
该页面为招聘数据可视化大屏模块,集成了城市平均薪资top10、工资区间分析、工资经验薪资分析、省市分布数据、公司人数分析及薪资top10等可视化功能,可直观呈现招聘数据的多维度特征,同时系统还具备数据采集、处理、分析及后台管理等相关功能模块。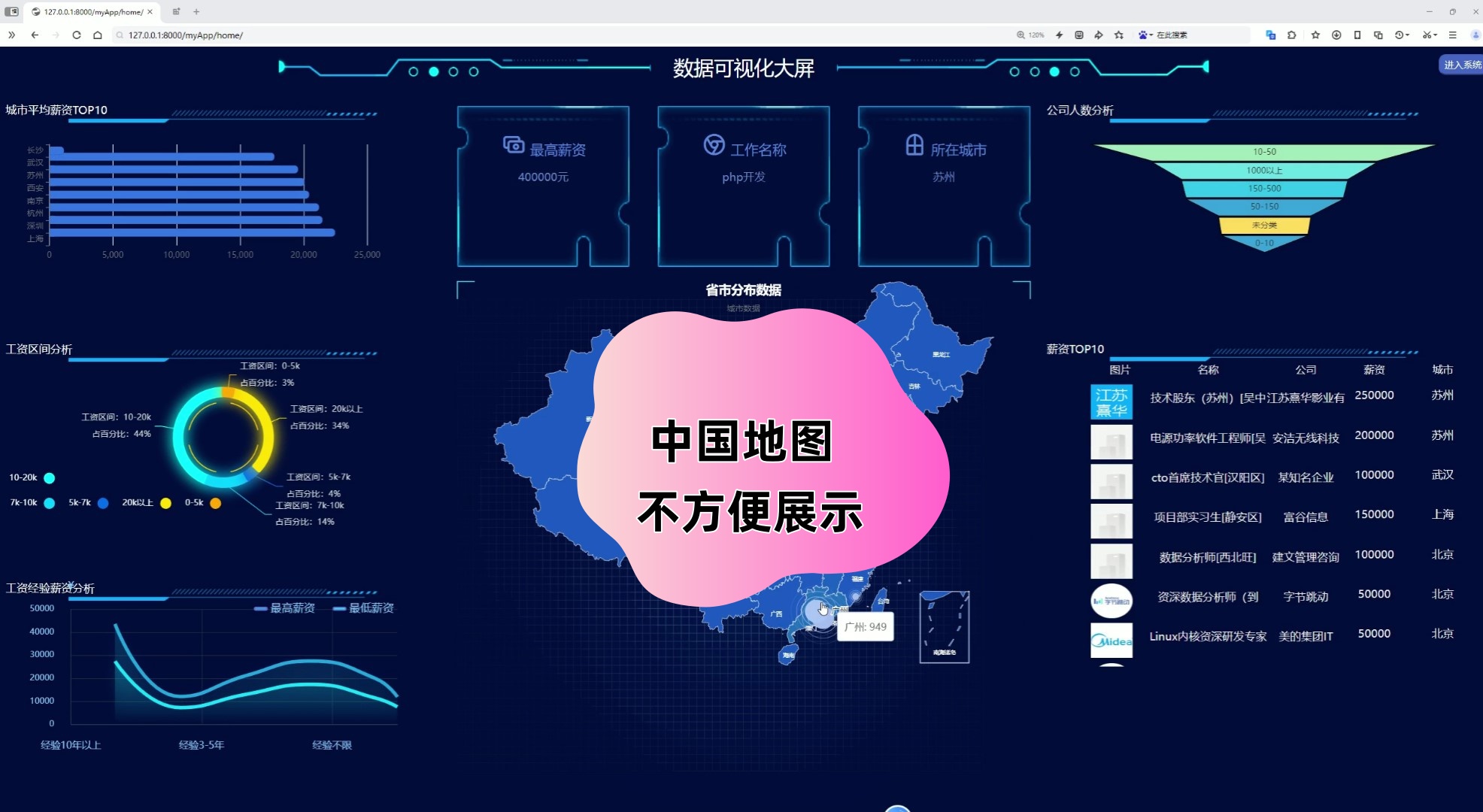
2、薪资分析(各行业薪资区间、各行业平均薪资)
该页面为招聘数据分析可视化系统的薪资分析模块,包含各行业薪资区间柱状图与各行业平均薪资饼图,可直观展示不同岗位在各薪资区间的分布及行业平均薪资情况,同时系统还具备经验学历分析、行业分析、城市分析、数据中心、个人中心、词云图分析、职位推荐、薪资预测及后台管理等功能模块。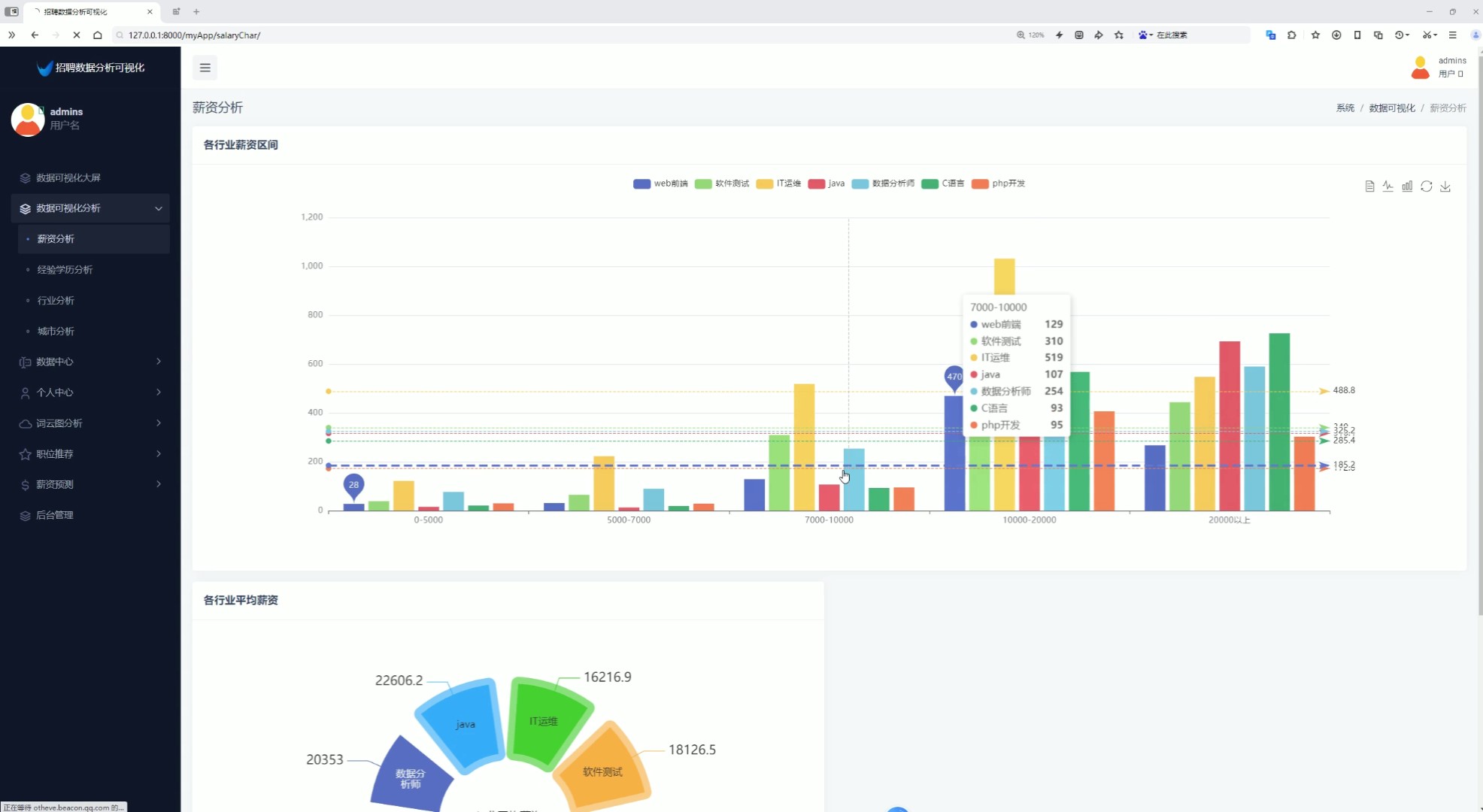
3、经验学历分析(工作经验薪资人数分析、学历招聘人数分析)
该页面为招聘数据分析可视化系统的经验学历分析模块,包含工作经验薪资人数双轴图与学历招聘人数环形图,可直观呈现不同工作经验对应的平均薪资和招聘人数分布,以及各学历层次的招聘占比,同时系统还具备薪资分析、行业分析、城市分析、数据中心、个人中心、词云图分析、职位推荐、薪资预测及后台管理等功能模块。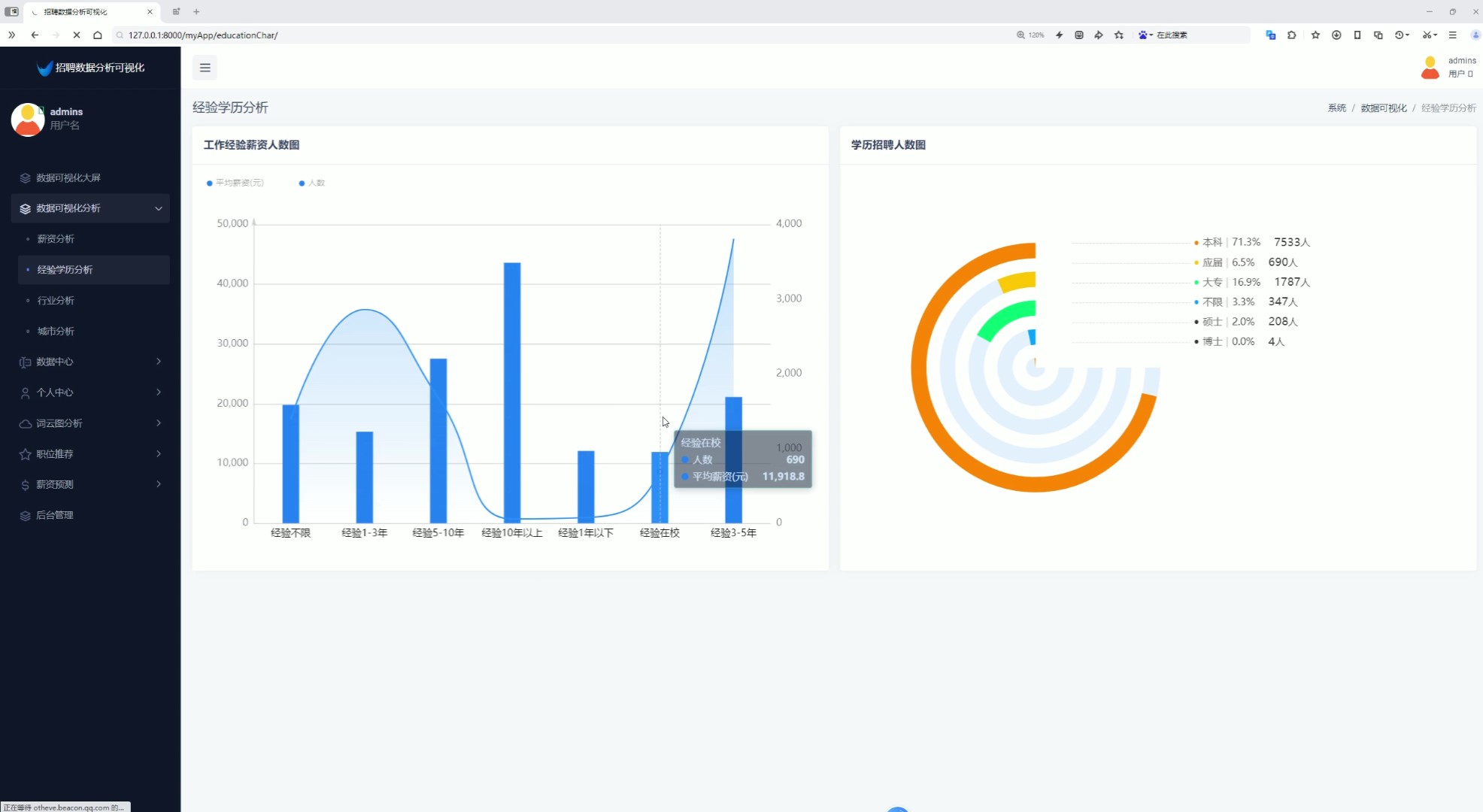
4、行业分析(行业招聘个数柱状图、行业最高薪资玫瑰图)
该页面为招聘数据分析可视化系统的行业分析模块,包含行业招聘个数柱状图与行业最高薪资玫瑰图,可直观展示各行业招聘数量分布及不同岗位的最高薪资情况,同时系统还具备薪资分析、经验学历分析、城市分析、数据中心、个人中心、词云图分析、职位推荐、薪资预测及后台管理等功能模块。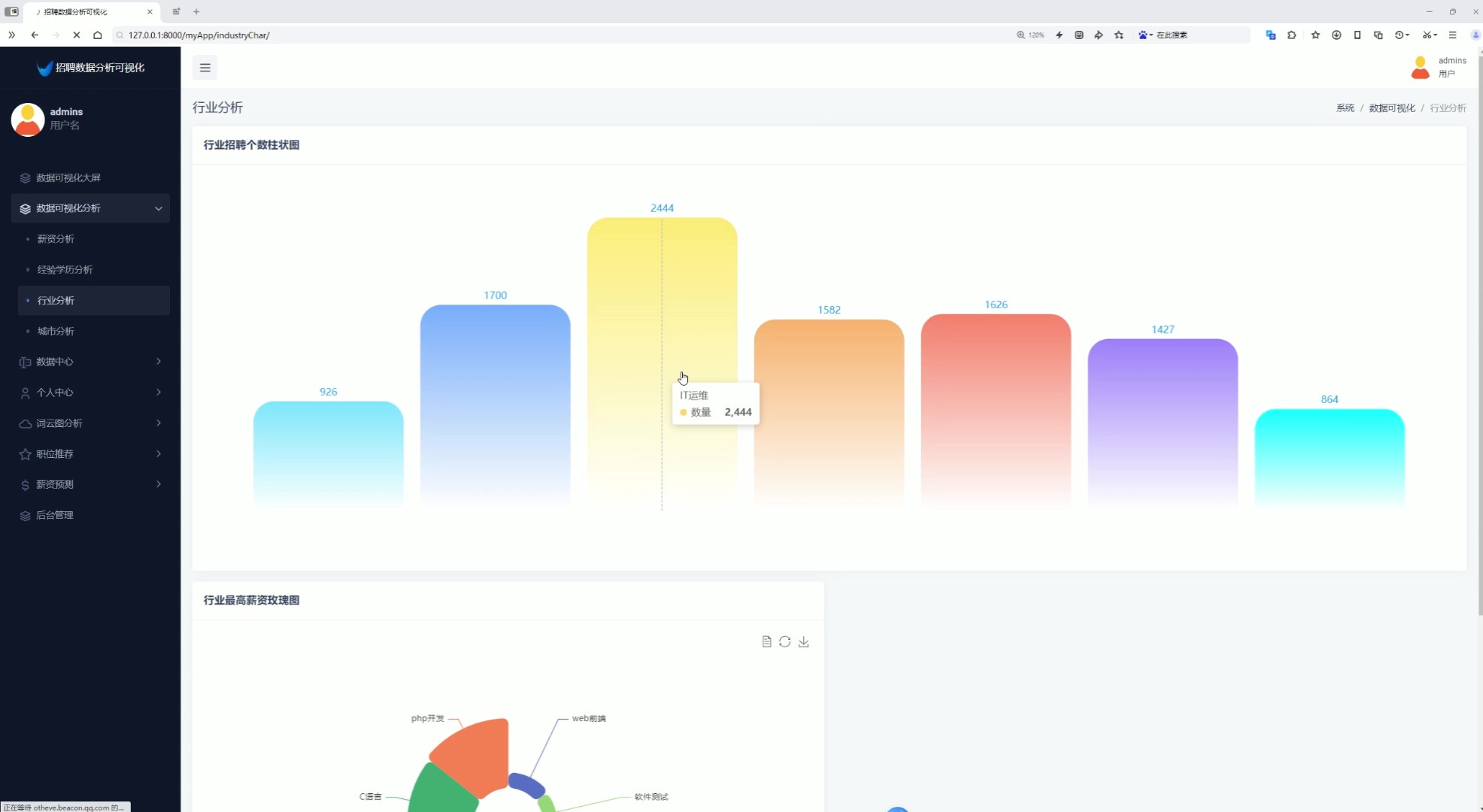
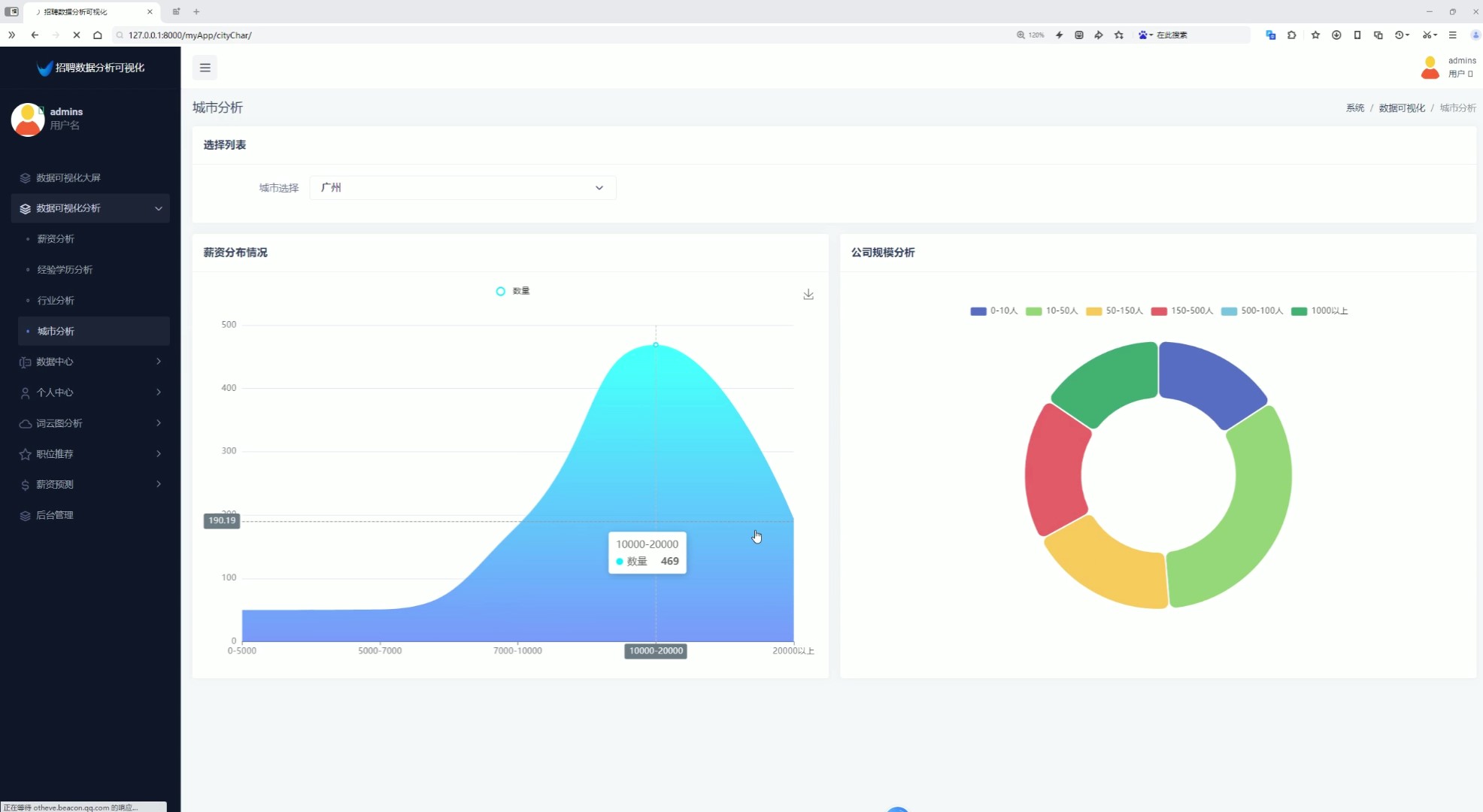
5、城市分析(城市选择查看薪资分布情况、公司规模分析
该页面为招聘数据分析可视化系统的城市分析模块,支持选择目标城市,可通过薪资分布面积图与公司规模环形图,直观展示所选城市的薪资区间分布及不同规模公司的占比情况,同时系统还具备薪资分析、经验学历分析、行业分析、数据中心、个人中心、词云图分析、职位推荐、薪资预测及后台管理等功能模块。
6、招聘数据中心(查看招聘数据、搜索、用户可以点击收藏岗位)
该页面为招聘数据分析可视化系统的数据中心模块,以表格形式展示职位的类型、名称、公司、薪资、经验、学历、标签、人数、内容、福利及城市等信息,支持搜索与收藏操作,同时系统还具备数据可视化大屏、薪资分析、经验学历分析、行业分析、城市分析、个人中心、词云图分析、职位推荐、薪资预测及后台管理等功能模块。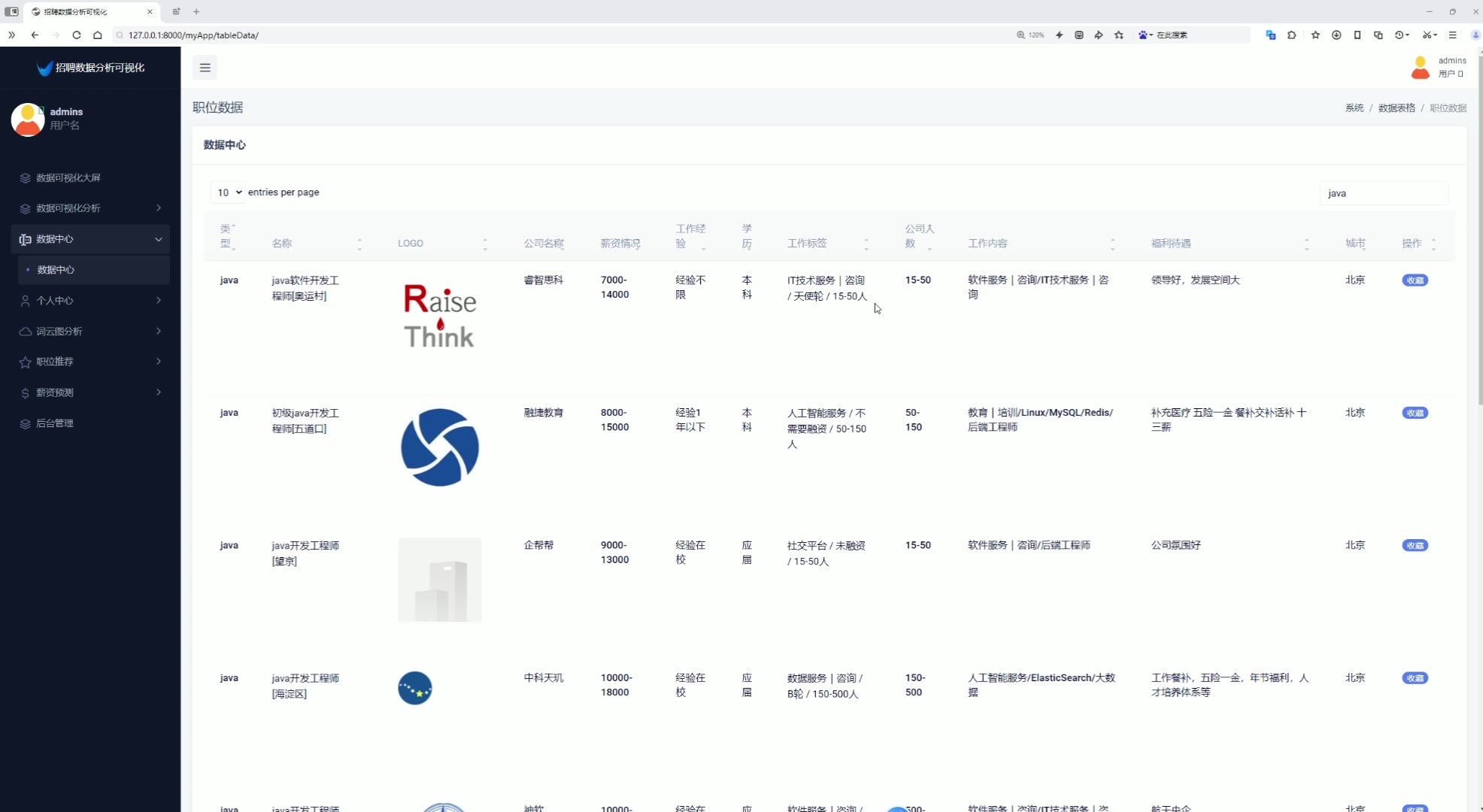
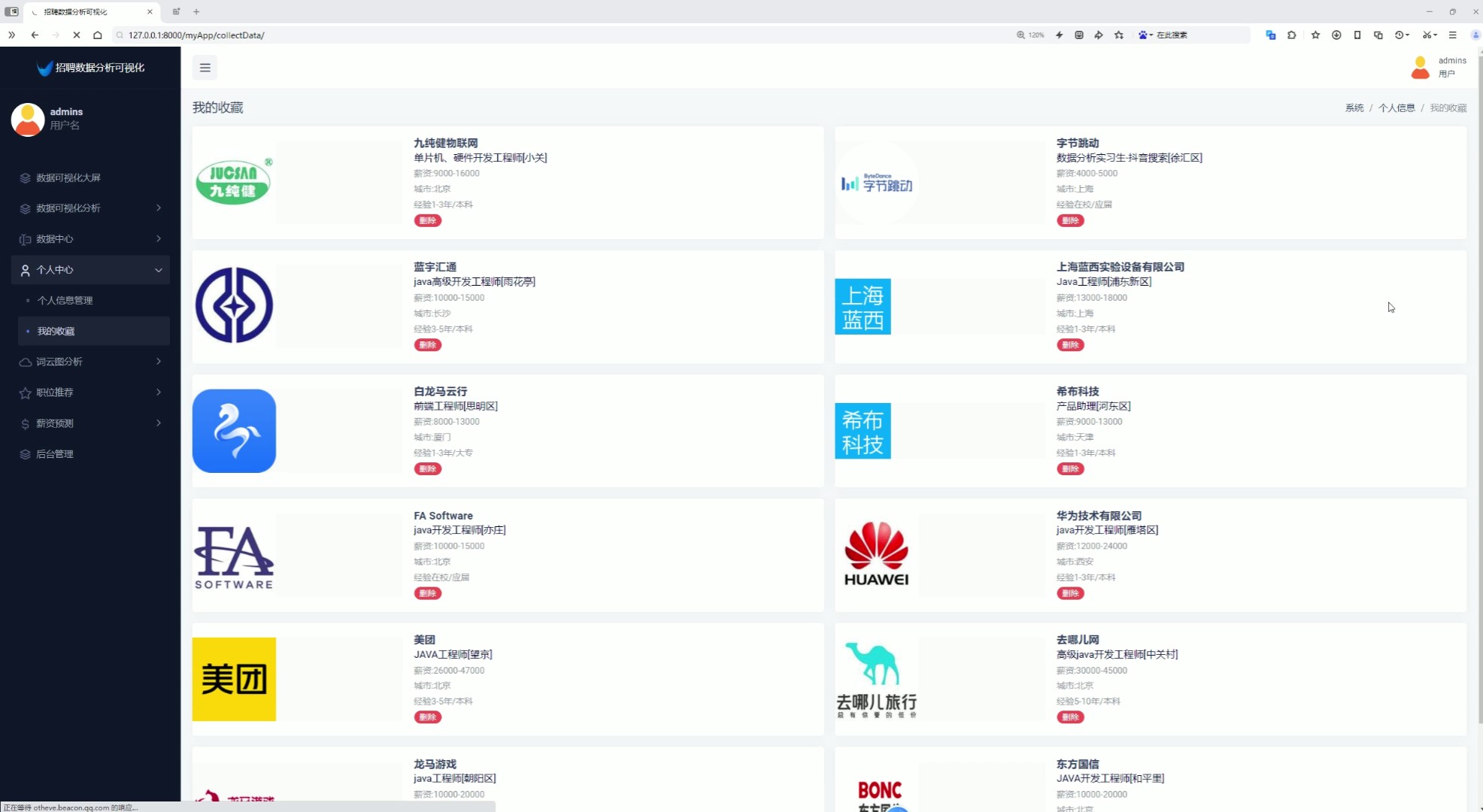
7、我的收藏
该页面为招聘数据分析可视化系统的个人收藏模块,以卡片形式展示用户收藏的职位信息,包含职位名称、薪资、城市、经验、学历等内容,支持删除收藏操作,同时系统还具备数据可视化大屏、薪资分析、经验学历分析、行业分析、城市分析、数据中心、词云图分析、职位推荐、薪资预测及后台管理等功能模块。
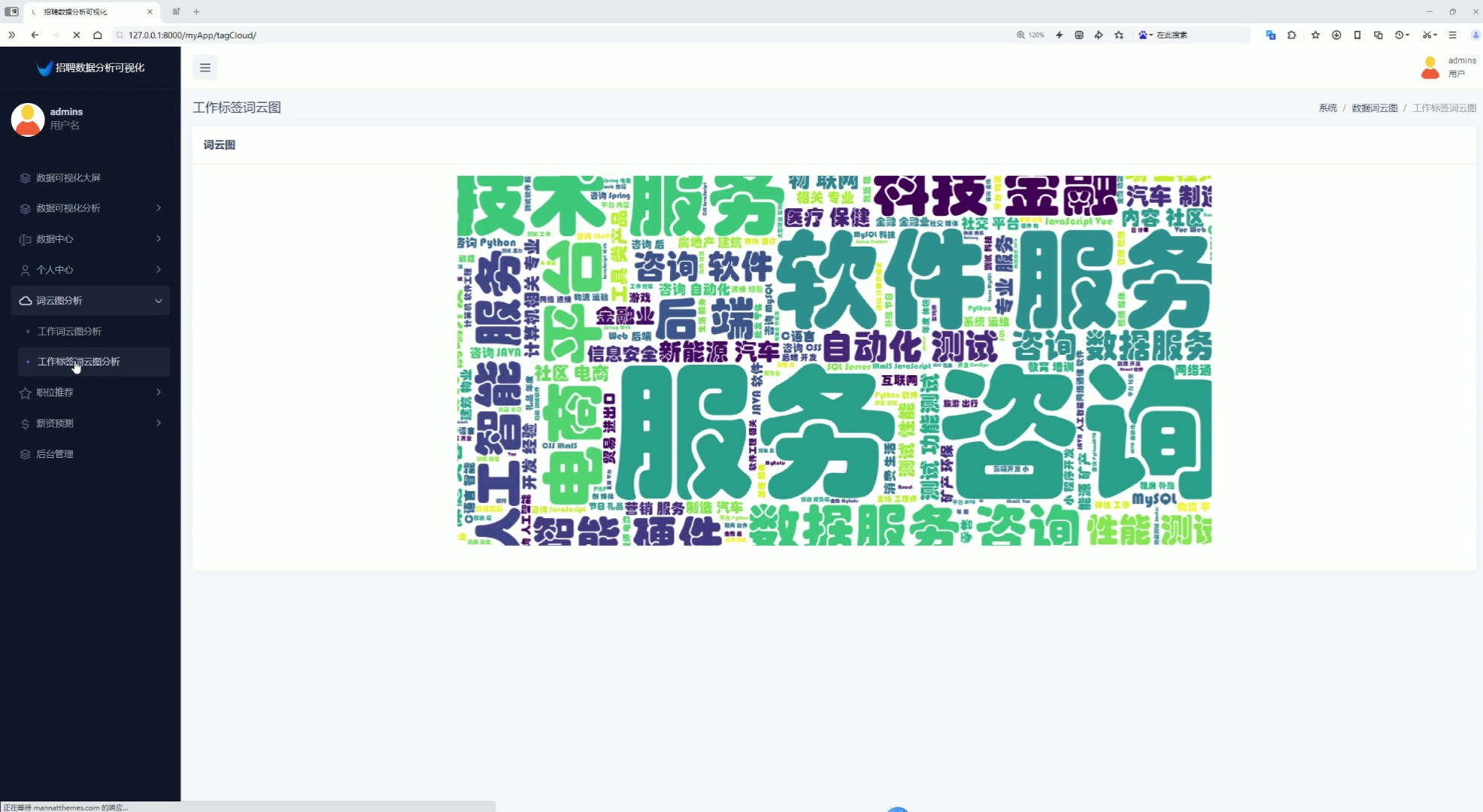
7、词云图分析(工作词云图分析、工作标签词云图分析)
该页面为招聘数据分析可视化系统的工作标签词云图分析模块,以词云图形式直观展示招聘职位高频工作标签的分布特征,同时系统还具备数据可视化大屏、薪资分析、经验学历分析、行业分析、城市分析、数据中心、个人中心、职位推荐、薪资预测及后台管理等功能模块。
8、职位推荐(采用基于内容推荐算法为用户推荐岗位)
该页面为招聘数据分析可视化系统的职位推荐模块,以卡片形式展示推荐职位的公司、名称、薪资、城市等信息,支持收藏操作,同时系统还具备数据可视化大屏、薪资分析、经验学历分析、行业分析、城市分析、数据中心、个人中心、词云图分析、薪资预测及后台管理等功能模块。

9、薪资预测(输入特征值,城市、工作经验、学历,预测薪资,根据TensorFlow预测算法)
该页面为招聘数据分析可视化系统的薪资预测模块,支持选择目标城市、工作经验及学历后提交查询,可得到对应的薪资预测结果,同时系统还具备数据可视化大屏、薪资分析、经验学历分析、行业分析、城市分析、数据中心、个人中心、词云图分析、职位推荐及后台管理等功能模块。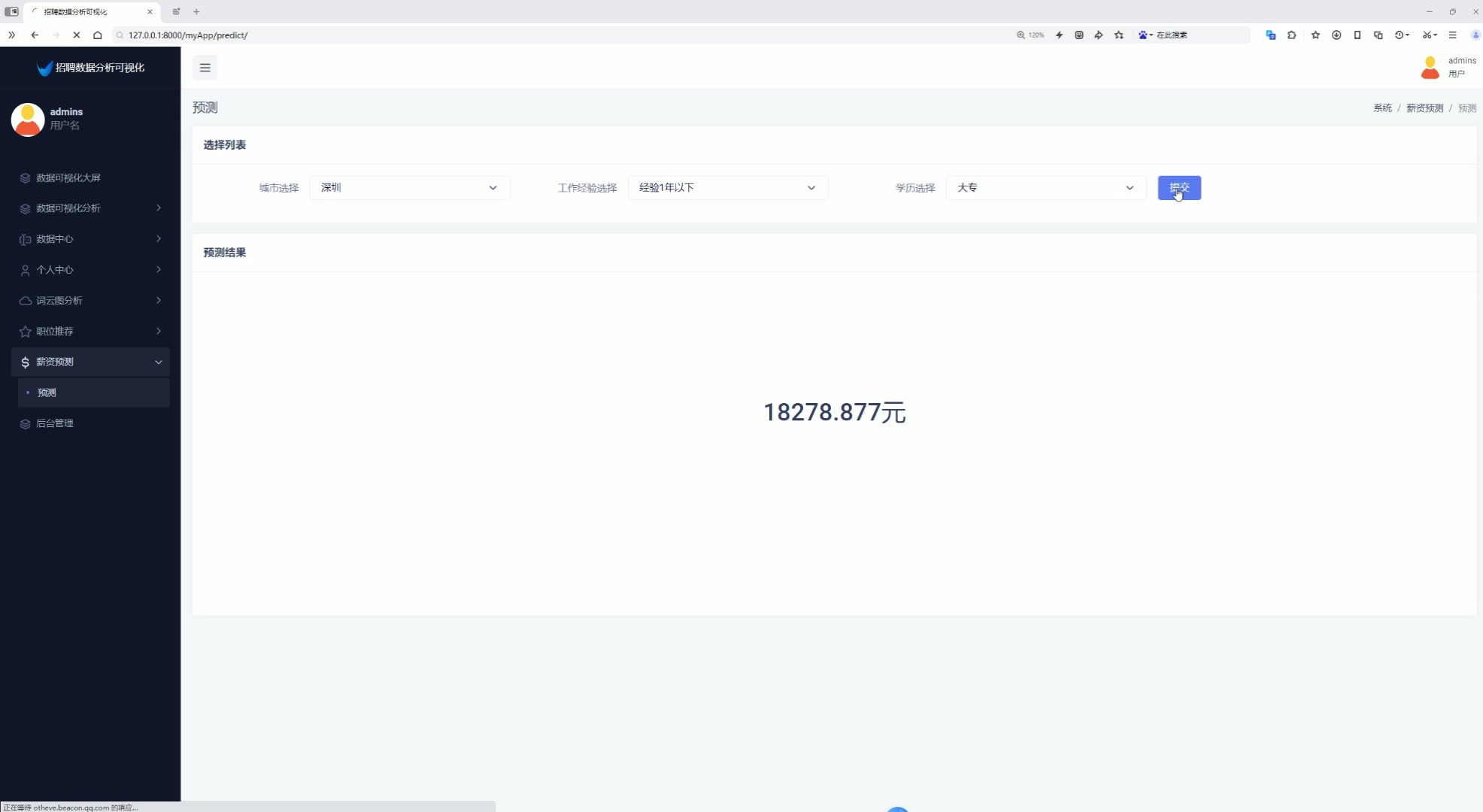
10、后台数据管理(用户数据管理、用户收藏记录管理)
该页面为招聘数据分析可视化系统的Django后台管理模块,可查看历史记录表与用户表信息,支持对历史记录和用户数据进行增加、删除等操作,同时系统还具备数据可视化大屏、薪资分析、经验学历分析、行业分析、城市分析、数据中心、个人中心、词云图分析、职位推荐及薪资预测等功能模块。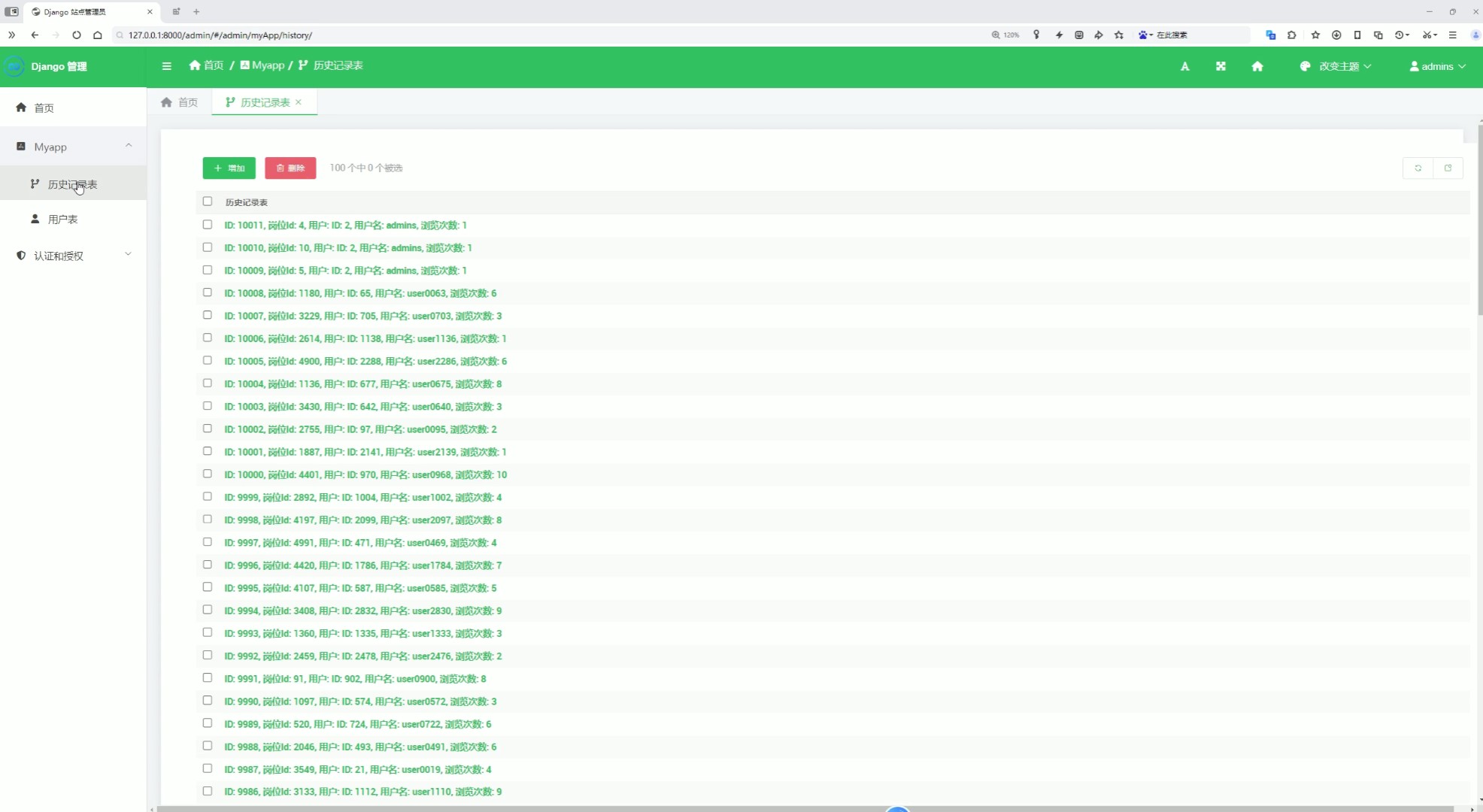
11、注册登录
该页面为招聘数据分析可视化系统的登录模块,提供用户名和密码输入框,支持记住我选项及登录操作,还可跳转至注册页面,同时系统还具备数据可视化大屏、薪资分析、经验学历分析、行业分析、城市分析、数据中心、个人中心、词云图分析、职位推荐、薪资预测及后台管理等功能模块。
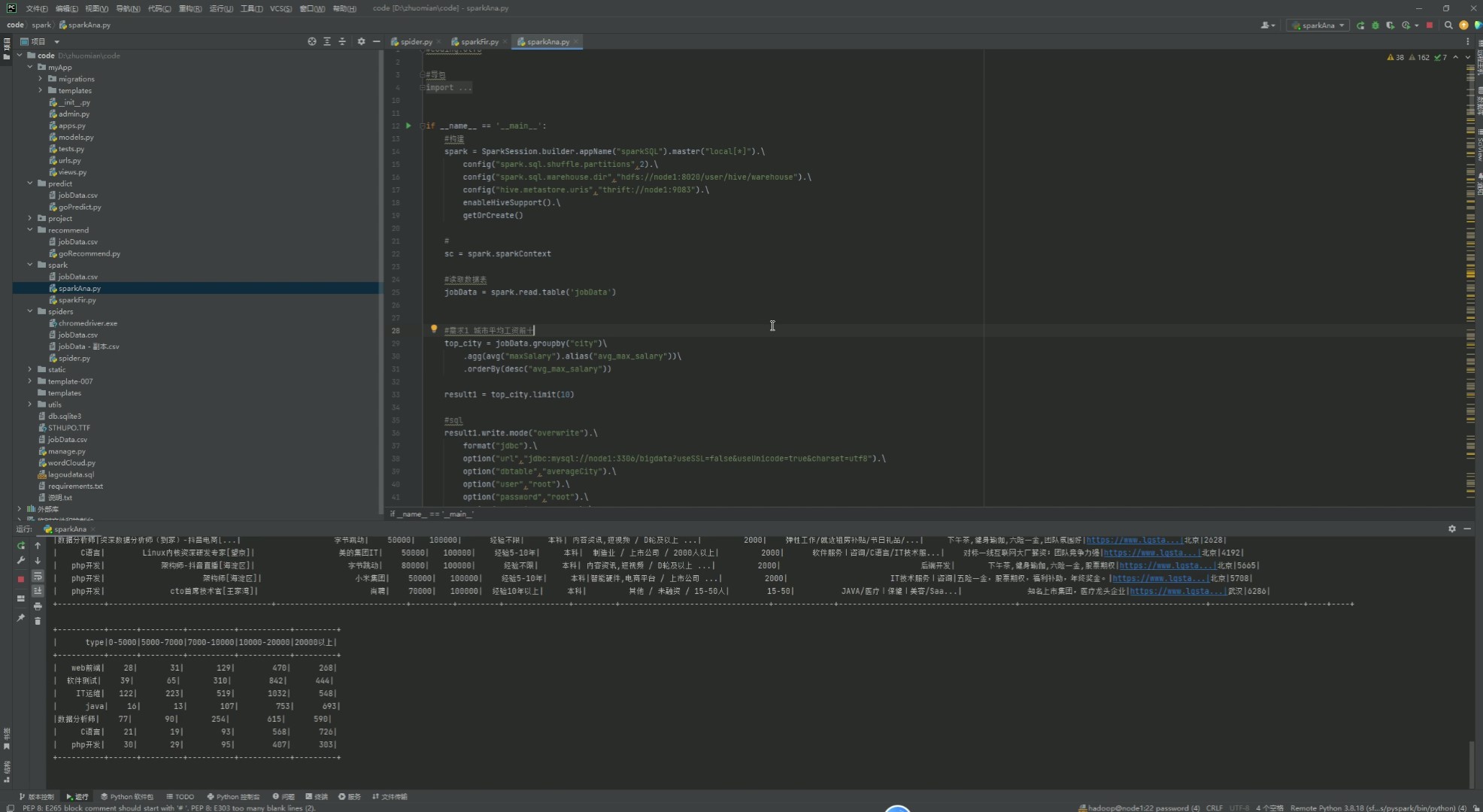
12、Spark数据分析
该页面为招聘数据分析项目的Spark分析代码开发界面,包含基于Spark的招聘数据统计分析模块,可实现城市平均薪资、行业薪资分布等多维度分析,并将结果存储到数据库,同时项目还包含爬虫数据采集、Web应用、可视化展示、职位推荐、薪资预测及后台管理等功能模块。
13、数据采集: selenuim爬虫技术、拉钩招聘网站
该页面为招聘数据分析项目的爬虫开发界面,包含拉勾网招聘数据爬虫模块,可自动采集职位名称、公司、薪资、经验、学历等信息并保存为csv文件,同时项目还包含Spark数据分析、Web应用、可视化展示、职位推荐、薪资预测及后台管理等功能模块。
3、项目说明
一、技术栈简要说明
本系统基于大数据技术体系构建,采用Spark、Hive、Hadoop实现海量招聘数据的分布式存储与高效计算。后端使用Python语言结合Django框架搭建Web应用,数据采集通过Selenium爬虫技术从拉勾招聘网站自动获取招聘信息。前端利用Echarts完成数据可视化展示,推荐模块采用基于内容推荐算法实现岗位个性化推荐,预测模块基于TensorFlow框架构建薪资预测模型。
二、功能模块详细介绍
· 可视化分析大屏
该页面为系统数据总览入口,集成城市平均薪资Top10、工资区间分析、工作经验薪资分析、各省市招聘数据分布、公司人数分析、薪资Top10工作及最高薪资岗位等可视化图表,多维度呈现招聘数据整体特征。
· 注册登录
系统提供用户注册与登录功能,支持记住密码选项,用户通过身份验证后可享受个性化数据分析服务,保障用户信息安全与使用体验。
· 薪资分析
该模块包含各行业薪资区间柱状图与各行业平均薪资饼图,直观展示不同行业在各薪资区间的分布情况以及行业间的平均薪资对比,帮助用户了解薪资水平差异。
· 经验学历分析
页面采用双轴图展示工作经验与薪资人数的关系,通过环形图呈现学历招聘人数占比,帮助用户评估不同经验与学历背景下的就业机会与薪资水平。
· 行业分析
该模块包含行业招聘个数柱状图与行业最高薪资玫瑰图,展示各行业招聘需求数量及最高薪资分布,为用户选择行业方向提供数据参考。
· 城市分析
支持用户选择目标城市,通过薪资分布面积图与公司规模环形图,展示所选城市的薪资区间分布及不同规模公司的占比情况,便于用户进行地域选择决策。
· 招聘数据中心
以表格形式展示职位类型、名称、公司、薪资、经验、学历、标签、城市等详细信息,支持关键词搜索与岗位收藏功能,方便用户查询与管理招聘信息。
· 个人中心
用户可在此模块修改个人密码,确保账号安全性,同时可查看和管理个人收藏记录,实现个性化信息维护。
· 我的收藏
以卡片形式展示用户收藏的职位信息,包含职位名称、薪资、城市、经验、学历等内容,支持取消收藏操作,方便用户管理意向岗位。
· 词云图分析
通过词云图直观呈现招聘职位的高频工作标签,帮助用户快速把握招聘市场的热点技能与关键词分布特征。
· 职位推荐
基于内容推荐算法,根据用户浏览行为与岗位特征,为用户生成个性化职位推荐列表,以卡片形式展示推荐岗位的公司、名称、薪资、城市等信息。
· 薪资预测
用户可选择目标城市、工作经验及学历等特征值,系统基于TensorFlow预训练模型输出对应的薪资预测结果,为求职者提供薪资预期参考。
· 后台数据管理
采用Django后台管理界面,支持对用户数据、用户收藏记录进行增删改查操作,为管理员提供便捷的系统数据维护工具。
· Spark数据分析
该模块为代码开发界面,包含基于Spark的招聘数据统计分析代码,可实现城市平均薪资、行业薪资分布等多维度统计分析,并将结果存储至数据库。
· 数据采集
内置Selenium爬虫代码编辑与运行界面,从拉勾招聘网站自动采集职位名称、公司、薪资、经验、学历等信息,支持数据保存为CSV文件,为系统提供持续更新的数据源。
三、项目总结
本系统实现了从数据采集、Spark大数据处理到Web可视化展示与机器学习应用的全流程闭环。通过Spark、Hive、Hadoop构建的大数据处理能力,系统能够高效处理海量招聘数据。多维度分析模块从薪资、经验学历、行业、城市等角度深入挖掘招聘市场规律,职位推荐模块基于内容推荐算法实现个性化岗位推荐,薪资预测模块利用TensorFlow模型提供可靠的薪资预估。系统各模块协同工作,为求职者与招聘管理人员提供了全面的招聘数据分析与智能决策支持。
4、核心代码
#导包
from pyspark.sql import SparkSession
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.types import StructType,StructField,IntegerType,StringType,FloatType
from pyspark.sql.functions import count,avg,regexp_extract,max
from pyspark.sql.functions import col,sum,when
from pyspark.sql.functions import desc,asc
if __name__ == '__main__':
#构建
spark = SparkSession.builder.appName("sparkSQL").master("local[*]").\
config("spark.sql.shuffle.partitions",2).\
config("spark.sql.warehouse.dir","hdfs://node1:8020/user/hive/warehouse").\
config("hive.metastore.uris","thrift://node1:9083").\
enableHiveSupport().\
getOrCreate()
#
sc = spark.sparkContext
#读取数据表
jobData = spark.read.table('jobData')
#需求1 城市平均工资前十
top_city = jobData.groupby("city")\
.agg(avg("maxSalary").alias("avg_max_salary"))\
.orderBy(desc("avg_max_salary"))
result1 = top_city.limit(10)
#sql
result1.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","averageCity").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result1.write.mode("overwrite").saveAsTable("averageCity","parquet")
spark.sql("select * from averageCity").show()
#需求二 工资区间
jobData_classfiy = jobData.withColumn("salary_category",
when(col("maxSalary").between(0,5000),"0-5k")
. when(col("maxSalary").between(5000,7000),"5k-7k")
. when(col("maxSalary").between(7000,10000),"7k-10k")
. when(col("maxSalary").between(10000,20000),"10-20k")
. when(col("maxSalary")>20000,"20k以上")
. otherwise("未分类"))
result2 = jobData_classfiy.groupby("salary_category").agg(count('*').alias("count"))
#sql
result2.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","salarycategory").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result2.write.mode("overwrite").saveAsTable("salarycategory","parquet")
spark.sql("select * from salarycategory").show()
#需求3 工资经验分析
result3 = jobData.groupby("workExperience")\
.agg(avg("maxSalary").alias("avg_max_salary"),
avg("minSalary").alias("avg_min_salary"))\
.orderBy("workExperience")
#sql
result3.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","expSalary").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result3.write.mode("overwrite").saveAsTable("expSalary","parquet")
spark.sql("select * from expSalary").show()
#城市分布
result4 = jobData.groupby("city").count()
#sql
result4.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","addresssum").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result4.write.mode("overwrite").saveAsTable("addresssum","parquet")
spark.sql("select * from addresssum").show()
#需求5 人口区间
job_df = jobData.withColumn("people_num",when(col("companyPeople").rlike(r'-'),
regexp_extract(col("companyPeople"),r'(\d+)-(\d+)',1).cast("int"))
.otherwise(col("companyPeople").cast("int")))
people_classify = job_df.withColumn("people_category",
when(col("people_num").between(0,10),"0-10")
. when(col("people_num").between(10,50),"10-50")
. when(col("people_num").between(50,150),"50-150")
. when(col("people_num").between(150,500),"150-500")
.when(col("people_num").between(500, 1000), "500-1000")
. when(col("people_num")>1000,"1000以上")
. otherwise("未分类"))
result5 = people_classify.groupby("people_category").agg(count('*').alias("count"))
#sql
result5.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","peoplecategory").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result5.write.mode("overwrite").saveAsTable("peoplecategory","parquet")
spark.sql("select * from peoplecategory").show()
#top10
top_10_salary = jobData.orderBy(col("maxSalary").desc()).limit(10)
#sql
top_10_salary.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","salaryTop").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
top_10_salary.write.mode("overwrite").saveAsTable("salaryTop","parquet")
spark.sql("select * from salaryTop").show()
#需求6 薪资分析 行业薪资
result6 = jobData.groupBy("type").agg(
sum(when(col("maxSalary") <= 5000, 1).otherwise(0)).alias("0-5000"),
sum(when((col("maxSalary") > 5000) & (col("maxSalary") <= 7000), 1).otherwise(0)).alias("5000-7000"),
sum(when((col("maxSalary") > 7000) & (col("maxSalary") <= 10000), 1).otherwise(0)).alias("7000-10000"),
sum(when((col("maxSalary") > 10000) & (col("maxSalary") <= 20000), 1).otherwise(0)).alias("10000-20000"),
sum(when(col("maxSalary") > 20000, 1).otherwise(0)).alias("20000以上")
)
#sql
result6.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","typeSalary").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result6.write.mode("overwrite").saveAsTable("typeSalary","parquet")
spark.sql("select * from typeSalary").show()
#需求7 行业平均薪资
result7 = jobData.groupby("type").agg(avg(col("maxSalary")).alias("avg_max_salary"))
#sql
result7.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","averageType").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result7.write.mode("overwrite").saveAsTable("averageType","parquet")
spark.sql("select * from averageType").show()
##需求 经验平均薪资和个数
result8 = jobData.groupby("workExperience").agg(
avg(col("maxSalary")).alias("avg_max_salary"),
count('*').alias("count")
)
#sql
result8.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","averageExperience").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result8.write.mode("overwrite").saveAsTable("averageExperience","parquet")
spark.sql("select * from averageExperience").show()
#需求9 学历
result9 = jobData.groupby("education").agg(
count('*').alias("count")
)
#sql
result9.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","educationCount").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result9.write.mode("overwrite").saveAsTable("educationCount","parquet")
spark.sql("select * from educationCount").show()
#行业个数
result10 = jobData.groupby("type").agg(
count('*').alias("count")
)
#sql
result10.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","typeCount").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result10.write.mode("overwrite").saveAsTable("typeCount","parquet")
spark.sql("select * from typeCount").show()
#需求11 各类型最大值
result11 = jobData.groupby("type").agg(
max(col("maxSalary")).alias("max_salary")
)
#sql
result11.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","typeMax").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result11.write.mode("overwrite").saveAsTable("typeMax","parquet")
spark.sql("select * from typeMax").show()
#各城市薪资情况
conditions = [
(col("maxSalary") <= 5000, '0-5000'),
((col("maxSalary") > 5000) & (col("maxSalary") <= 7000), '5000-7000'),
((col("maxSalary") > 7000) & (col("maxSalary") <= 10000), '7000-10000'),
((col("maxSalary") > 10000) & (col("maxSalary") <= 20000), '10000-20000'),
(col("maxSalary") > 20000, '20000以上')
]
result12 = jobData.groupby("city").agg(
*[count(when(condition,1)).alias(range_name) for condition,range_name in conditions]
)
#sql
result12.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","citySalary").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result12.write.mode("overwrite").saveAsTable("citySalary","parquet")
spark.sql("select * from citySalary").show()
#城市人数
conditionsTwo = [
(col("people_num") <= 10, '0-10'),
((col("people_num") > 10) & (col("people_num") <= 50), '10-50'),
((col("people_num") > 50) & (col("people_num") <= 150), '50-150'),
((col("people_num") > 150) & (col("people_num") <= 500), '150-500'),
((col("people_num") > 500) & (col("people_num") <= 1000), '500-1000'),
(col("people_num") > 1000, '1000以上')
]
result13 = job_df.groupby("city").agg(
*[count(when(condition,1)).alias(range_name) for condition,range_name in conditionsTwo]
)
#sql
result13.write.mode("overwrite").\
format("jdbc").\
option("url","jdbc:mysql://node1:3306/bigdata?useSSL=false&useUnicode=true&charset=utf8").\
option("dbtable","cityPeople").\
option("user","root").\
option("password","root").\
option("encoding","utf-8").\
save()
result13.write.mode("overwrite").saveAsTable("cityPeople","parquet")
spark.sql("select * from cityPeople").show()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)