【VLM】HopChain视觉语言推理多跳数据合成框架
note
- 【数据合成方案进展】讲得是多跳视觉语言推理数据合成框架,用于应对视觉语言模型(VLMs)在长思维链(CoT)推理中的错误累积以及大多数 RLVR 视觉语言训练数据缺乏全程依赖视觉证据的复杂推理链的问题。看核心几个点:
- 1)数据定义:VLMs 以图像 + 文本查询为输入,生成思维链并输出可验证答案;
- 2)多跳数据合成框架步骤:
- step1.类别识别:使用 Qwen3-VL-235B-A22B-Thinking 枚举图像中的语义类别(如汽车、人),生成类别列表;
- step2.实例分割:通过 SAM3 对识别出的类别进行实例分割,生成分割掩码与边界框,得到带空间定位的独立实例;
- step3.多跳查询生成:对 3-6 个实例组合,通过 Qwen3-VL-235B-A22B-Thinking 生成多跳查询,施加多项约束(如包含所有实例、仅用视觉属性描述、数值答案),避免语言捷径;
- step4.真值标注与难度校准:4 名标注员独立解答查询,仅保留答案一致的样本;用较弱模型评估查询,移除准确率 100% 的简单查询。
- 这篇论文通过提出HopChain框架,成功解决了VLMs在长链式推理任务中的弱点。HopChain通过合成多跳视觉语言推理数据,增强了模型在细粒度视觉语言推理任务中的表现。实验结果表明,多跳数据在20个基准测试上取得了显著的进步,且这些进步具有广泛的泛化能力。未来的工作将进一步减少对实例分割的依赖,以处理更多没有可检测对象的图像。
- 论文核心:长链视觉推理的瓶颈,不只是“模型不会推理”,而是“模型不会在多步推理中持续、可靠地回到视觉证据本身”。HopChain 通过合成一种“步步依赖、步步看图”的训练数据。
文章目录
一、研究背景
- 研究问题:这篇文章要解决的问题是如何通过多跳数据合成来增强视觉语言模型(VLMs)在细粒度视觉语言推理任务中的表现。尽管VLMs在多模态基准测试中取得了显著进展,但在长链式推理(CoT)任务中仍存在困难,这些任务要求模型仔细关注图像中的多个视觉元素及其关系。
- 研究难点:该问题的研究难点包括:VLMs在长CoT推理过程中表现出多样化的失败模式,包括感知、推理、知识和幻觉错误,这些错误会在中间步骤中累积。此外,现有的视觉语言训练数据大多不涉及复杂的推理链,导致这些弱点在训练过程中未被充分暴露。
- 相关工作:该问题的研究相关工作包括:LLaVA系列工作通过将视觉特征投影到语言模型的嵌入空间来引入视觉指令调优范式;DeepSeek-R1展示了纯RL可以诱导强链式推理;最近的研究还表明,多模态推理依赖于细粒度的观察和重复的图像检查。
二、HopChain框架
这篇论文提出了HopChain,一个可扩展的框架,用于合成多跳视觉语言推理数据,以改进VLMs的可验证奖励强化学习(RLVR)训练。具体来说:
1、多跳视觉语言推理定义
1、多跳视觉语言推理定义:首先,定义了目标多跳查询的结构。多跳查询结合了感知级跳变和实例链跳变两种类型。感知级跳变在不同感知级别之间切换,而实例链跳变沿显式依赖链移动。每个查询必须满足三个结构条件:必须是多跳查询、结合两种跳变类型、并且跳变形成一个逻辑依赖链。
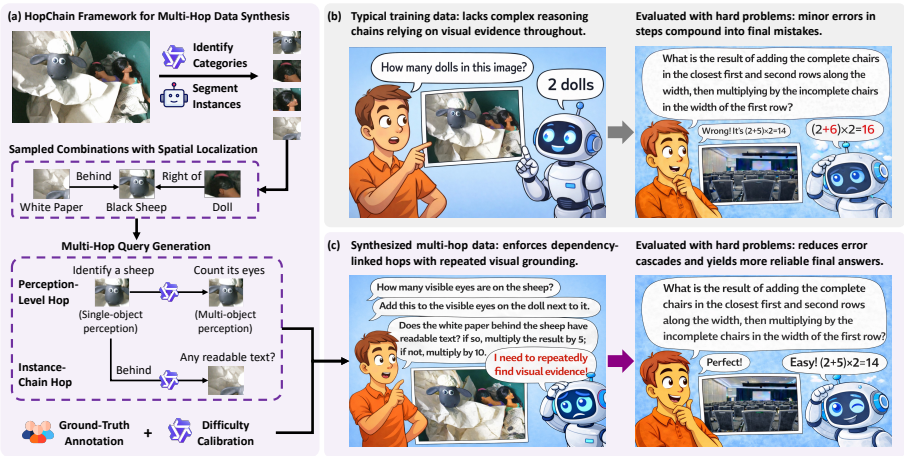
第一种:perception-level hop
就是感知层级切换,比如:
- 先识别单个物体属性
- 再做多个物体关系判断
- 再回到某个局部目标继续读字/数数
第二种:instance-chain hop
就是实例链依赖,比如:先找到 A,再根据 A 找到 B,再根据 B 找到 C
一个合格的 query 必须同时满足:
- 是多步 Level-3 推理
- 同时包含上面两种 hop
- 每一步都依赖前面建立的实例、集合或条件
- 最后输出一个唯一数字答案
这样设计的目的就是:
阻止模型走语言捷径,逼它做“逐跳视觉定位 + 逐跳推理”。
2、HopChain pipeline
2、数据合成管道:HopChain采用了一个可扩展的四阶段数据合成管道:
- 类别识别:使用Qwen3-VL-235B-A22B-Thinking识别图像中的语义类别。
- 实例分割:使用SAM3对识别的类别进行实例分割,生成具有空间定位的个体实例。
- 多跳查询生成:使用Qwen3-VL-235B-A22B-Thinking构建多跳查询,每个查询组合3-6个实例。
- 人工验证:多个标注者独立解决每个查询,只有最终数值答案相同的查询才保留为有效训练样本。
3、SAPO
3、软自适应策略优化(SAPO):在多跳数据上应用RLVR,使用SAPO算法进行训练。SAPO通过温度控制的软门替换硬裁剪,优化以下目标:
J ( θ ) = E ( I , q , a ) ∼ D , { o i } i = 1 G ∼ π old ( ⋅ ∣ I , q ) [ 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ f i , t ( r i , t ( θ ) ) A ^ i , t ] , \mathcal{J}(\theta) = \mathbb{E}_{(I, q, a) \sim \mathcal{D}, \{o_i\}_{i=1}^G \sim \pi_{\text{old}}(\cdot \mid I, q)} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} f_{i,t} \left( r_{i,t}(\theta) \right) \hat{A}_{i,t} \right], J(θ)=E(I,q,a)∼D,{oi}i=1G∼πold(⋅∣I,q) G1i=1∑G∣oi∣1t=1∑∣oi∣fi,t(ri,t(θ))A^i,t ,
其中, r i , t ( θ ) r_{i,t}(\theta) ri,t(θ) 表示策略 π \pi π 在状态 ( I , q , o i < t ) (I, q, o_{i<t}) (I,q,oi<t) 下的响应, A ^ i , t \hat{A}_{i,t} A^i,t 是期望奖励的归一化值, f i , t ( x ) f_{i,t}(x) fi,t(x) 是一个 sigmoid 函数, τ i , t \tau_{i,t} τi,t 根据正负令牌的温度进行调节。
三、实验设计
- 数据收集:从24个基准测试中评估两个模型Qwen3.5-35B-A3B和Qwen3.5-397B-A17B。这些基准测试涵盖STEM和拼图、通用VQA、文本识别和文档理解以及视频理解四个类别。
- 实验设置:在三种设置下评估模型:原始RLVR数据、仅原始RLVR数据和原始RLVR数据加上合成的多跳数据。每个模型在每个设置下运行1000个梯度步,使用mini-batch大小为64或128的随机梯度下降(SGD)优化器。
- 图像过滤:在多跳查询合成之前,过滤掉低质量的图像。使用Qwen3-VL-235B-A22B-Thinking和SAM3进行初始筛选,然后使用Qwen3-VL-30B-A3B-Thinking进行监督微调,最后使用Qwen3-VL-235B-A22B-Thinking进行二次筛选。
四、结果分析
- 主要基准测试结果:在24个基准测试中,添加多跳数据后,两个模型在20个基准测试上取得了进步。具体来说,Qwen3.5-35B-A3B在STEM和拼图、通用VQA、文本识别和文档理解以及视频理解类别中分别提高了6个、6个、3个和5个基准测试的成绩。Qwen3.5-397B-A17B在这些类别中也取得了类似的广泛进步。
- 跳变结构分析:比较了单跳、半多跳和多跳查询的效果。结果表明,多跳查询在所有五个代表性基准测试中的平均得分最高,其次是半多跳查询,单跳查询得分最低。这表明保留较长的跨跳依赖关系对性能提升至关重要。
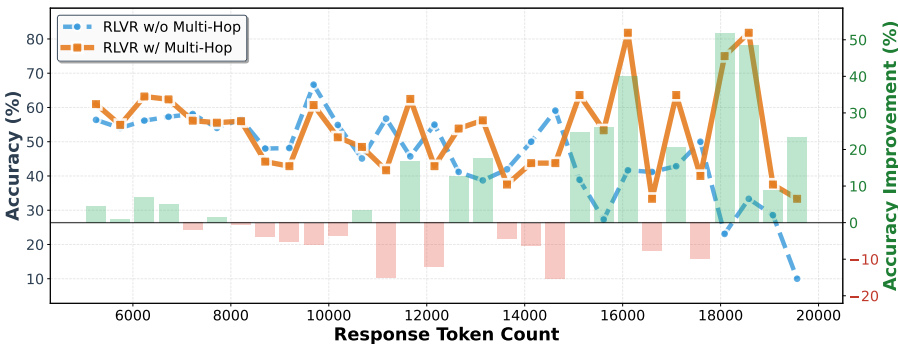
- 推理长度分析:随着响应链的增长,多跳查询的优势仍然存在。在Qwen3.5-397B-A17B上,按响应标记数量分组的优势在超长响应区间内更加明显。
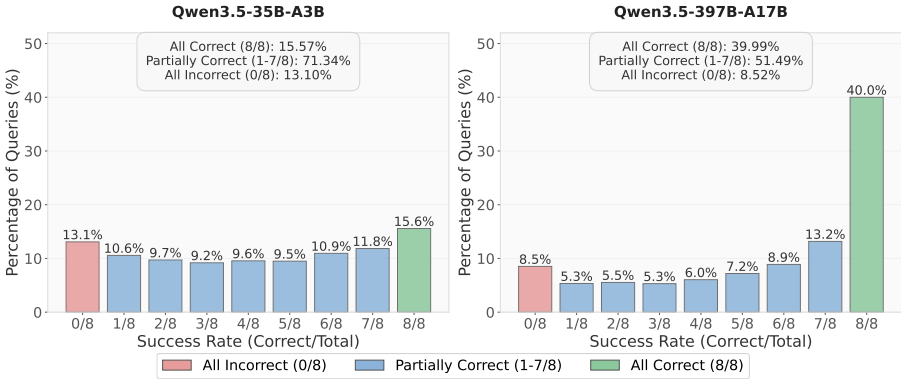
- 难度覆盖范围:超过一半的多跳查询属于部分正确区间,分布跨越多个成功桶。这表明合成的多跳数据覆盖了广泛的难度范围,可以为不同规模和能力的模型提供有用的RLVR训练信号。
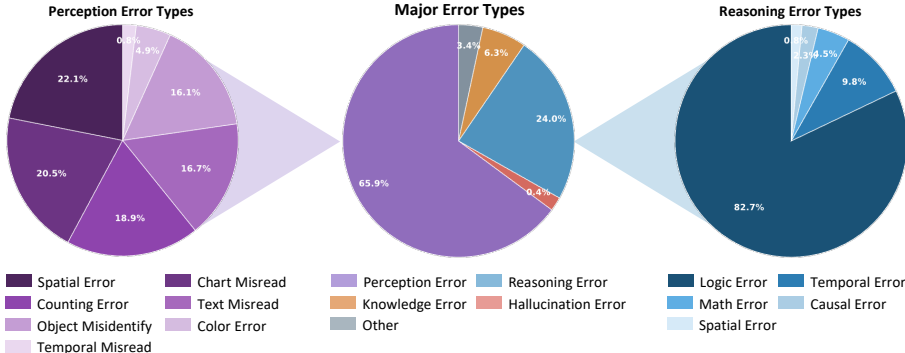
- 错误类型分析:多跳增强不仅修复了单一的窄错误类型,而且在广泛的错误类型上取得了进步。错误类型的分布与原始错误分布密切相关,表明多跳数据在长CoT视觉语言推理中的广泛改进。
五、论文评价
1、优点与创新
- 识别长链推理中的多种失败模式:论文识别了长链推理中存在的多样化且复合的失败模式,包括感知、推理、知识和幻觉错误,并展示了现有视觉语言训练数据在这些弱点上的不足。
- 提出HopChain框架:论文提出了HopChain,一个可扩展的框架,用于合成多跳视觉语言推理数据,以增强视觉语言模型的可泛化推理能力。
- 多跳查询的结构化设计:HopChain通过感知级跳变和实例链跳变两种跳变类型来形式化多跳视觉语言推理,确保每一步都需要重新绑定视觉证据,并在最后终止于一个具体的、可验证的数字答案。
- 广泛的实验验证:通过在24个基准测试上进行广泛的实验,证明了HopChain合成的多跳数据在大多数基准上都能带来显著的改进,表明其具有广泛且通用的性能提升。
- 跨领域泛化:实验结果表明,HopChain合成的数据不仅在图像理解任务上有效,还能显著改善视频理解的性能,显示出显著的跨领域泛化能力。
2、不足与反思
- 依赖实例分割:当前的HopChain管道仍然依赖于成功的实例分割,因此无法处理没有可检测对象(即没有SAM3可分割实例)的图像,这些图像被排除在当前的综合工作流程之外。
- 下一步工作:论文建议未来的工作可以通过引入补充的数据构建路径来减少对实例分割的依赖,同时保留长链推理RLVR训练的核心设计原则,即链式视觉绑定。
六、相关问题
问题1:HopChain框架如何定义多跳视觉语言推理的结构?
HopChain框架定义的多跳视觉语言推理结构结合了感知级跳变和实例链跳变两种类型。感知级跳变在不同感知级别之间切换,例如从单一对象感知切换到多对象关系感知。实例链跳变则沿显式依赖链移动,例如从实例A到实例B再到实例C。每个多跳查询必须满足三个结构条件:必须是多跳查询、结合两种跳变类型、并且跳变形成一个逻辑依赖链。这种设计确保了每个查询在每一步都重新绑定到视觉证据,从而提高了长链式推理的鲁棒性。
问题2:HopChain的数据合成管道是如何设计的?
HopChain的数据合成管道包括四个阶段:
类别识别:使用Qwen3-VL-235B-A22B-Thinking识别图像中的语义类别。
实例分割:使用SAM3对识别的类别进行实例分割,生成具有空间定位的个体实例。
多跳查询生成:使用Qwen3-VL-235B-A22B-Thinking构建多跳查询,每个查询组合3-6个实例。查询通过组合不同的感知级别和实例依赖链来形成复杂的多跳推理任务。
人工验证:多个标注者独立解决每个查询,只有最终数值答案相同的查询才保留为有效训练样本。这一阶段确保了合成数据的质量和一致性。
问题3:HopChain在实验中表现如何?与其他设置相比有哪些改进?
在实验中,HopChain在24个基准测试中的20个基准测试上取得了显著进步。具体来说,Qwen3.5-35B-A3B在STEM和拼图、通用VQA、文本识别和文档理解以及视频理解类别中分别提高了6个、6个、3个和5个基准测试的成绩。Qwen3.5-397B-A17B在这些类别中也取得了类似的广泛进步。与仅使用原始RLVR数据的设置相比,添加多跳数据后,模型在大多数基准测试中的表现都有显著提升,表明HopChain合成的多跳数据在提高模型的泛化能力和鲁棒性方面具有显著效果。
Reference

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)