用Bash脚本构建AI编码助手:learn-claude-code项目技术解析
·
最近GitHub上出现了一个有趣的项目learn-claude-code,仅用Bash脚本就实现了一个完整的AI编码助手。这个项目迅速登上热门榜单,引发了开发者社区的广泛讨论。本文将深入解析这个项目的技术实现,分享实际应用场景。
项目概述
基本信息
- 项目地址:https://github.com/shareAI-lab/learn-claude-code
- 核心技术:纯Bash脚本实现
- 主要功能:AI编码助手,支持代码生成、审查、执行
- 依赖:Bash、curl、jq、Docker(可选)
项目特点
- 零依赖:无需Python环境
- 极速启动:几秒内可用
- 透明可控:每个组件都可调试
- 资源占用低:内存小于10MB
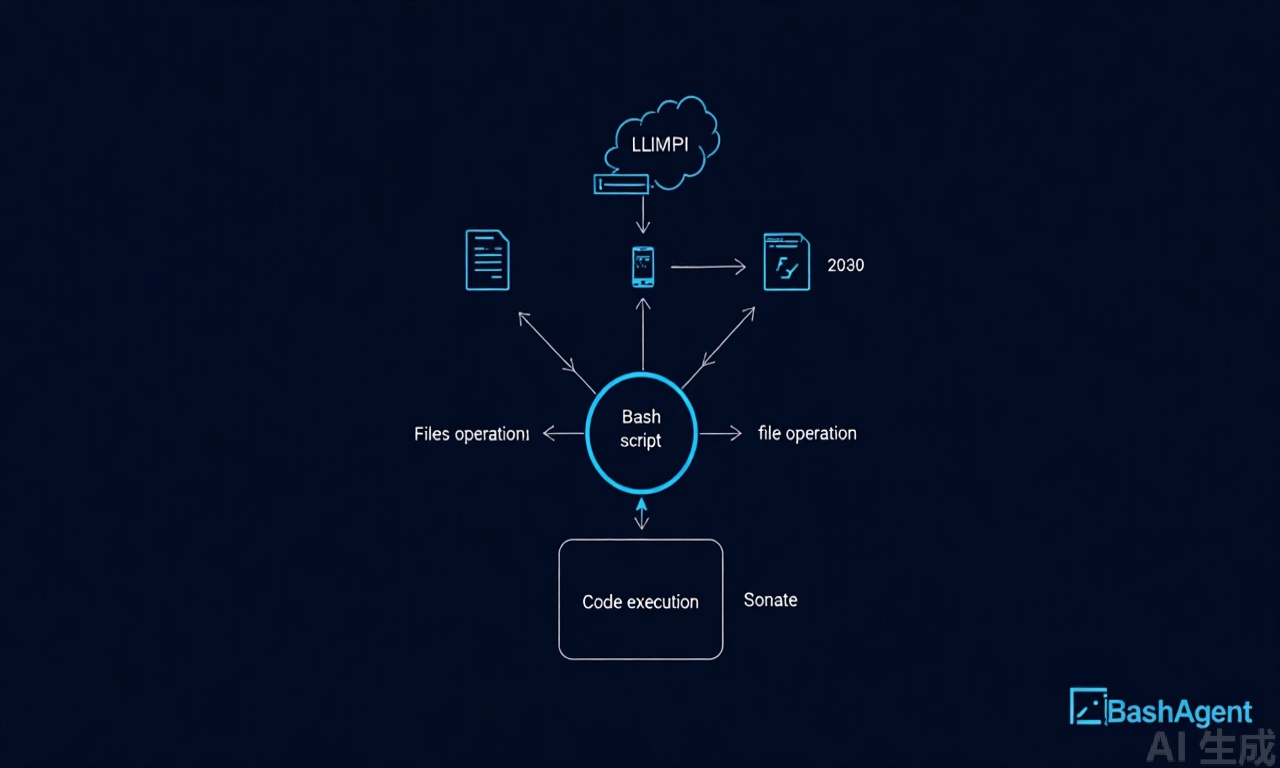
技术架构解析
整体架构设计
learn-claude-code采用模块化设计,严格遵循Unix哲学:
├── agent.sh # 主控制脚本
├── llm_call.sh # AI模型调用
├── code_analysis.sh # 代码分析
├── execution.sh # 安全执行
└── history.sh # 历史记录
核心组件详解
1. 主控制脚本(agent.sh)
负责协调各个组件的工作流程:
#!/bin/bash
# agent.sh 简化示例
main() {
local user_input="$1"
local target_file="${2:-output.py}"
# 1. 提取代码上下文
local context=$(./code_analysis.sh "$target_file")
# 2. 构建提示词
local prompt=$(build_prompt "$user_input" "$context")
# 3. 调用AI模型
local llm_response=$(./llm_call.sh "$prompt")
# 4. 提取代码
local code=$(extract_code "$llm_response")
# 5. 验证并执行
if validate_syntax "$code"; then
local result=$(./execution.sh "$code")
if [ $? -eq 0 ]; then
save_to_file "$code" "$target_file"
echo "代码生成成功,已保存到 $target_file"
fi
fi
}
2. AI模型调用(llm_call.sh)
支持多种AI模型的API调用:
#!/bin/bash
# llm_call.sh 核心函数
call_claude() {
local prompt="$1"
local model="${2:-claude-3-sonnet}"
# 构造API请求
local request=$(jq -n \
--arg model "$model" \
--arg prompt "$prompt" \
'{
model: $model,
messages: [{role: "user", content: $prompt}],
max_tokens: 4000
}')
# 发送请求
local response=$(curl -s -X POST "https://api.anthropic.com/v1/messages" \
-H "Content-Type: application/json" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d "$request")
# 提取回复
echo "$response" | jq -r '.content[0].text'
}
3. 代码分析(code_analysis.sh)
智能分析代码结构,提取关键信息:
#!/bin/bash
# code_analysis.sh 文件类型识别
analyze_file() {
local file_path="$1"
# 检测文件类型
if [[ -f "$file_path" ]]; then
local extension="${file_path##*.}"
case "$extension" in
"py")
extract_python_info "$file_path"
;;
"js"|"ts")
extract_js_info "$file_path"
;;
"java")
extract_java_info "$file_path"
;;
*)
extract_generic_info "$file_path"
;;
esac
else
echo "文件不存在: $file_path"
fi
}
extract_python_info() {
local file="$1"
# 提取函数定义
echo "=== 函数列表 ==="
grep -n "def " "$file" | head -10
# 提取类定义
echo -e "\n=== 类列表 ==="
grep -n "class " "$file" | head -10
# 提取导入
echo -e "\n=== 导入模块 ==="
grep -E "^(import|from)" "$file" | head -10
}
4. 安全执行(execution.sh)
使用Docker容器确保代码安全执行:
#!/bin/bash
# execution.sh 安全执行机制
safe_execute() {
local code="$1"
local language="${2:-python}"
local timeout="${3:-10}"
# 创建临时文件
local temp_file=$(mktemp /tmp/code_XXXXXX)
case "$language" in
"python")
echo "$code" > "${temp_file}.py"
execute_python "${temp_file}.py" "$timeout"
;;
"javascript")
echo "$code" > "${temp_file}.js"
execute_javascript "${temp_file}.js" "$timeout"
;;
*)
echo "不支持的编程语言: $language"
return 1
;;
esac
# 清理
rm -f "${temp_file}"*
}
execute_python() {
local file="$1"
local timeout="$2"
# 在限制资源的容器中执行
local result=$(timeout "$timeout" \
docker run --rm \
--memory=256m \
--cpus="0.5" \
--network="none" \
-v "$file:/tmp/code.py" \
python:3.11-slim \
python /tmp/code.py 2>&1)
echo "$result"
}
工作流程详解
完整的代码生成流程
-
输入解析
./agent.sh "写一个快速排序的Python实现" -
上下文提取
- 检查当前目录的代码文件
- 提取相关代码结构和模式
- 构建包含上下文的提示词
-
AI代码生成
- 调用Claude/OpenAI API
- 获取生成的代码
- 提取代码块并清理
-
代码验证
- 语法检查
- 安全执行测试
- 错误捕获和反馈
-
结果保存
- 保存有效代码到文件
- 记录生成历史
- 提供使用反馈
错误处理机制
项目实现了基本的错误处理:
#!/bin/bash
# 错误处理示例
handle_error() {
local error_message="$1"
local error_code="$2"
case "$error_code" in
1)
echo "语法错误: $error_message"
# 尝试自动修复
attempt_fix "$error_message"
;;
2)
echo "API调用失败: $error_message"
# 重试或使用备用API
retry_or_fallback
;;
3)
echo "执行超时: $error_message"
# 调整超时设置
adjust_timeout
;;
*)
echo "未知错误: $error_message"
;;
esac
# 记录错误到日志
log_error "$error_message" "$error_code"
}
实际应用场景
场景一:快速原型开发
使用步骤:
-
克隆项目
git clone https://github.com/shareAI-lab/learn-claude-code cd learn-claude-code -
配置API密钥
export ANTHROPIC_API_KEY="your_key_here" -
开始使用
./agent.sh "写一个读取CSV文件并计算统计信息的Python脚本"
优势:
- 免去复杂的Python环境配置
- 几秒内即可开始编码
- 适合快速验证想法
场景二:代码审查助手
自定义审查脚本:
#!/bin/bash
# code_review.sh
review_directory() {
local dir="$1"
for file in "$dir"/*.py; do
if [[ -f "$file" ]]; then
echo "审查文件: $file"
review_file "$file"
echo ""
fi
done
}
review_file() {
local file="$1"
local code=$(cat "$file")
# 构建审查提示
local prompt="请对以下Python代码进行审查,指出:
1. 潜在的安全问题
2. 性能优化建议
3. 代码风格问题
4. 可能的bug
代码:
$code"
# 调用AI审查
local feedback=$(./llm_call.sh "$prompt")
# 生成审查报告
echo "## 审查报告" > "${file}.review.md"
echo "文件: $file" >> "${file}.review.md"
echo "时间: $(date)" >> "${file}.review.md"
echo "" >> "${file}.review.md"
echo "$feedback" >> "${file}.review.md"
echo "审查完成,报告已保存到 ${file}.review.md"
}
场景三:教育资源
教学用途:
-
AI Agent原理教学
- 通过简单代码理解复杂概念
- 逐步添加功能,渐进学习
-
Bash高级用法示范
- JSON处理、API调用、进程管理
- 脚本编程最佳实践
-
开源项目贡献
- 代码简单易懂,适合新手贡献
- 良好的模块化设计
性能与资源分析
资源使用情况
内存占用:
- 基本运行:5-10MB
- 执行代码时:20-50MB(包含Docker)
- 峰值内存:小于100MB
启动时间:
- 冷启动:2-3秒
- 热启动:<1秒
- API响应时间:依赖网络和模型
存储需求:
- 项目本身:<1MB
- 临时文件:<10MB
- 历史记录:可配置
性能优化技巧
-
缓存优化
# 实现简单的响应缓存 cache_response() { local key="$1" local value="$2" local cache_dir="/tmp/learn-claude-code-cache" mkdir -p "$cache_dir" echo "$value" > "$cache_dir/$(echo -n "$key" | md5sum | cut -d' ' -f1)" } -
并行处理
# 使用GNU parallel处理多个文件 process_files_parallel() { local files=("$@") printf '%s\n' "${files[@]}" | \ parallel -j 4 ./process_single_file.sh {} } -
资源限制
# 限制脚本资源使用 ulimit -v 100000 # 限制虚拟内存 ulimit -t 30 # 限制CPU时间
与传统框架对比
learn-claude-code优势
部署简单
- 无需Python环境
- 依赖少,兼容性好
- 适合各种环境
调试友好
- 每个步骤都可单独执行
- 输出信息清晰
- 错误定位容易
学习成本低
- Bash语法简单
- 代码量小,易理解
- 文档自解释
传统框架优势
功能丰富
- LangChain:工具链完整
- AutoGen:多Agent支持
- CrewAI:任务规划强大
企业特性
- 监控和日志
- 权限管理
- 高可用支持
社区生态
- 大量插件和扩展
- 活跃的社区支持
- 商业支持选项
扩展与定制
添加新功能
支持新编程语言:
#!/bin/bash
# 添加Rust语言支持
extract_rust_info() {
local file="$1"
echo "=== Rust模块信息 ==="
# 提取模块声明
grep -n "mod " "$file" | head -10
# 提取函数定义
grep -n "fn " "$file" | head -10
# 提取结构体定义
grep -n "struct " "$file" | head -10
# 提取trait定义
grep -n "trait " "$file" | head -10
}
集成新AI模型:
#!/bin/bash
# 添加DeepSeek支持
call_deepseek() {
local prompt="$1"
local request=$(jq -n \
--arg prompt "$prompt" \
'{
model: "deepseek-coder",
messages: [{role: "user", content: $prompt}],
max_tokens: 4000
}')
local response=$(curl -s -X POST "https://api.deepseek.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d "$request")
echo "$response" | jq -r '.choices[0].message.content'
}
性能监控
#!/bin/bash
# 性能监控脚本
monitor_performance() {
local start_time=$(date +%s.%N)
# 执行任务
"$@"
local end_time=$(date +%s.%N)
local duration=$(echo "$end_time - $start_time" | bc)
# 记录性能数据
echo "$(date): $* - 耗时: ${duration}秒" >> /var/log/learn-claude-code/perf.log
# 内存使用
local mem_usage=$(ps -o rss= -p $$ | awk '{print $1/1024 " MB"}')
echo "内存使用: $mem_usage" >> /var/log/learn-claude-code/perf.log
}
最佳实践建议
开发实践
-
代码组织
- 保持脚本短小专注
- 使用函数提高可读性
- 添加充分的注释
-
错误处理
- 检查所有外部命令返回值
- 提供有意义的错误信息
- 实现优雅降级
-
安全性
- 验证所有输入
- 安全执行用户代码
- 保护API密钥
部署建议
-
生产环境
- 使用Docker容器化部署
- 配置适当的资源限制
- 设置监控和告警
-
开发环境
- 使用版本控制
- 编写单元测试
- 配置CI/CD流水线
-
团队协作
- 制定代码规范
- 文档化接口
- 定期代码审查
总结
learn-claude-code项目展示了用最简单技术实现复杂功能的可能性。它不仅是AI编码助手,更是学习AI Agent原理、Bash高级用法和软件设计的好材料。
项目价值:
- 教育意义:极简实现帮助理解本质
- 实用价值:快速原型验证工具
- 技术示范:Bash高级用法最佳实践
适用场景:
- AI入门学习
- 快速原型开发
- 资源受限环境
- 教学演示材料
不建议场景:
- 企业级生产环境
- 复杂业务逻辑
- 高并发需求
通过这个项目,我们可以看到技术选择的多样性。在合适的场景使用合适的技术,这才是优秀工程师的标志。无论是Bash脚本还是Python框架,最重要的是解决问题,而不是追求技术栈的"高大上"。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)