从一到无穷大 #64:思考Google、Anthropic、OpenAI 的 Skill 设计方法论
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
最近我的一项工作内容是负责团队内AIops体系的建设,简单来讲就是用Agent去串平时运营的过程,这个过程主要涉及到Agent框架的选择(海马体),可观测性的重构(工作记忆),SOP的沉淀(长期记忆),skill完善(流程框架),Agent触发点(眼睛)和Agent执行(手)。
以我的实践经验来看,这其中最麻烦的在记忆管理和Skill,记忆的难点主要是记忆演进,记忆压缩和记忆冲突,不过今天我们不讨论这里,后续专门放做一篇文章来讲。
Skill的难点主要是上下文爆炸后的模型幻觉(包括tools的封装,确定性步骤的workflow分装),执行流程确定性和skill漏调或频繁调用的排障过程。
这个时候问题已经不是提示词怎么写,而是Skill怎么设计。
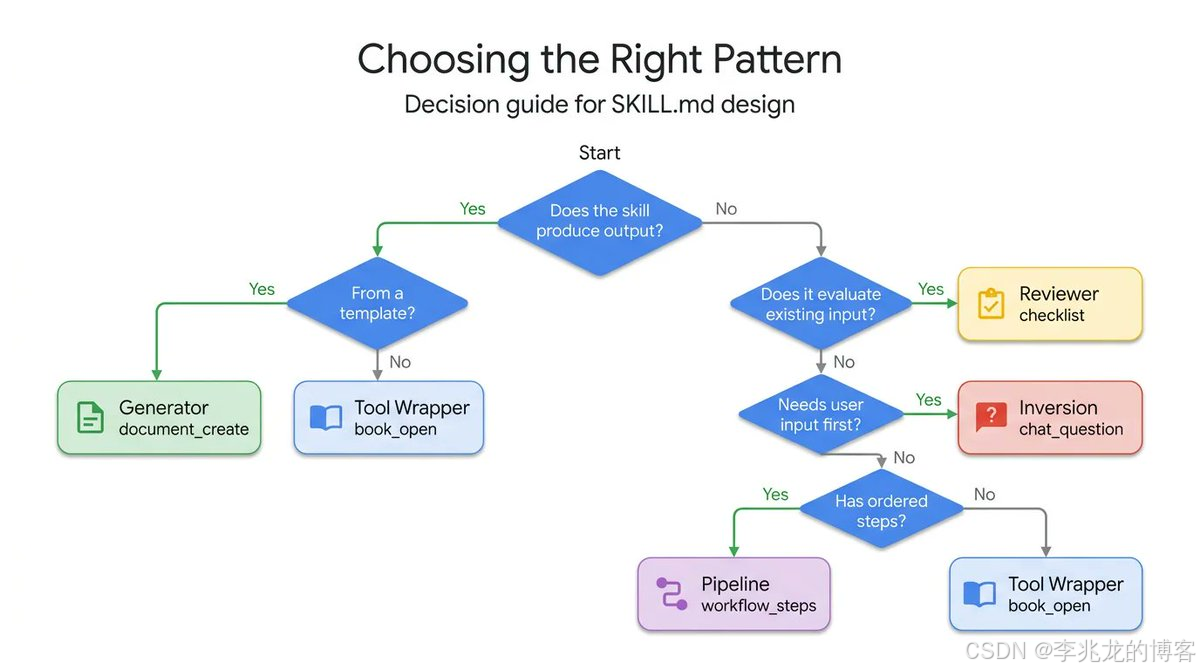
最近 Google Cloud Tech 推荐的那篇 《5 Agent Skill design patterns every ADK developer should know》[1] 很有代表性。它提醒开发者:SKILL.md 的重点不在格式本身,而在于你怎样组织 agent 的行为逻辑。从公开摘要可见,这篇文章把 Skill 总结成五种典型模式:Tool Wrapper、Generator、Reviewer、Inversion、Pipeline。
如果把这篇 Google 文章,和 Anthropic 的 《The Complete Guide to Building Skills for Claude》[2]、OpenAI 的 prompt guidance [3]放在一起看,会看到一个非常清晰的趋势:
Prompt 是一句指令,Skill 是一种组织行为的方法。
Google 更强调 skill 的结构形态,Anthropic 更强调工作流与排障,OpenAI 更强调输出契约、工具边界和完成定义。
这篇文章想回答的是:一个成熟的 Agent Skill,到底应该怎样被设计出来?
做 Agent 不能只停留在 Prompt
Google 在 Gemini 的 prompt design 文档里说得很明确:高质量提示依赖于清晰、具体的指令,复杂任务要拆分,prompt engineering 本身是迭代过程;同时,Gemini 的工具文档强调,工具让模型可以访问实时信息、执行计算与采取行动,而多步目标导向系统则应结合工具和代理式组织方式来构建。
Anthropic 对这件事的定义更接近系统设计。在它的 Skills 指南里,skill 被定义为一个简单文件夹中的一组打包指令,用来教 Claude 稳定处理特定任务或工作流;它还特别提出了 progressive disclosure:前置信息用于判断何时调用,完整正文在 skill 被认定相关时再加载,附加文件按需探索,从而兼顾 token 效率与专业性。Anthropic 还把 skills 描述为 MCP 之上的“知识层”:MCP 提供连接与工具,skill 提供如何把这些工具用成可复制工作流的配方。
OpenAI 则把这件事进一步工程化。它的 prompt guidance 直接指出:GPT-5.4 这类生产级 assistant 和 agent,在长任务里会明显受益于三种明确约束——output contract、tool-use expectations、completion criteria。换句话说,好的 agent 不只是会回答,而是知道输出长什么样、什么时候该调用什么工具、做到什么程度算完成。OpenAI 的 prompt engineering 文档还进一步建议把提示做成可复用资产,而不是把所有内容硬编码在集成逻辑里。
所以今天再谈 Agent,如果还只停留在提示词写法,其实已经落后了一步。真正要设计的,是一套能被反复调用、持续维护、稳定生效的能力单元,也就是 Skill。
Skill 的皮与骨
Google Cloud Tech 那篇文章之所以有价值,是因为它不再只谈prompt 要清楚,而是开始谈skill 应该长成什么结构。这五种模式分别是:
- Tool Wrapper:把工具或框架的最佳实践包装成按需调用的知识
- Generator:把生成任务做成稳定模板
- Reviewer:让 agent 充当评审器而不是创作者
- Inversion:先反问澄清,再执行
- Pipeline:把复杂任务拆成多阶段工作流
但 Google 更像是在给你外形分类,真正把这些结构拆到执行层面的,是 Anthropic。
Anthropic 在 Patterns and troubleshooting 章节先做了一个特别重要的区分:problem-first 与 tool-first。
- problem-first:用户描述目标,skill 负责编排工具和步骤
- tool-first:用户已经有工具接入,skill 负责教模型怎样按最佳实践使用它们
实际上大多数 skill 都会偏向其中一边。
Anthropic 总结了五种经过内部团队和早期用户验证的模式:
- Sequential workflow orchestration:
- Multi-MCP coordination
- Iterative refinement
- Context-aware tool selection
- Domain-specific intelligence
如果说 Google 告诉你Skill 可以有哪些样子,那 Anthropic 告诉你的就是这些样子里面,真正有效的执行逻辑是什么。而 OpenAI 则补上最后一环:这些逻辑最终必须写成清晰的输入协议、输出协议和完成标准,否则系统再聪明,也会在实际运行时幻觉频出。
五种核心 Skill 模式: Google & Anthropic
Tool Wrapper / Context-aware tool selection:不是会调用工具,而是会选对工具
Google 的 Tool Wrapper 很适合作为第一种模式来理解。它的核心不是把一个 API 接进去,而是把某个库、某种框架或者某套工具使用方式,包装成模型可以随时调用的专业知识。这种 skill 的价值在于让 agent 在需要时加载一整套最佳实践,而不是每次从零摸索。
## Smart File Storage
--# Decision Tree
1. Check file type and size
2. Determine best storage location:
- Large files (>10MB): Use cloud storage MCP
- Collaborative docs: Use Notion/Docs MCP
- Code files: Use GitHub MCP
- Temporary files: Use local storage
--# Execute Storage
Based on decision:
- Call appropriate MCP tool
- Apply service-specific metadata
- Generate access link
--# Provide Context to User
Explain why that storage was chosen
Anthropic 在自己的模式里,把这件事说得更具体:Context-aware tool selection。适用场景是“目标一样,但要根据上下文选不同工具”。它给的例子是文件存储:大文件进云存储、协作文档进 Notion/Docs、代码文件进 GitHub、临时文件走本地。关键技巧包括:清晰的决策标准、fallback 选项,以及对选择理由的透明说明。
Anthropic 的另一篇工具设计文章又把这个原则往前推了一步:工具应该边界清晰、命名自然、功能尽量少重叠,返回值应该是高信号信息,而不是大量对模型后续决策没有帮助的底层字段。它的核心判断非常直接:如果连人都说不清两个工具在什么场景下该分别使用,那 agent 大概率也选不好。
所以这一类 Skill 的本质,不是“告诉模型有哪些 API”,而是:
把工具从裸接口,变成带有决策边界、场景上下文和最佳实践的能力封装。
Generator / Iterative refinement:生成不是一次性写完,而是一个可收敛的过程
Google 的第二种模式是 Generator。它适合 PRD、邮件、报告、方案、设计稿说明这类“最终交付物形态很明确”的任务。Generator 的关键不是让模型自由发挥,而是先把输出骨架定义清楚,再让模型在骨架内生成内容。
## Iterative Report Creation
--# Initial Draft
1. Fetch data via MCP
2. Generate first draft report
3. Save to temporary file
--# Quality Check
1. Run validation script: `scripts/check_report.py`
2. Identify issues:
- Missing sections
- Inconsistent formatting
- Data validation errors
--# Refinement Loop
1. Address each identified issue
2. Regenerate affected sections
3. Re-validate
4. Repeat until quality threshold met
--# Finalization
1. Apply final formatting
2. Generate summary
3. Save final version
Anthropic 对应的补充模式是 Iterative refinement。它明确指出:很多输出质量不是一次生成就能达到,而是要通过“初稿—校验—修订—复验”的循环逐渐提高。它给出的技巧包括:显式质量标准、验证脚本、迭代式改进,以及“知道什么时候停止”。
OpenAI 在这里给出的概念是最适合拿来落地的:output contract 和 completion criteria。前者要求你提前规定输出长什么样,后者要求你提前定义什么叫完成。这两点很重要,因为没有输出契约,生成结果会漂移;没有完成标准,迭代就会变成无止境润色。
所以 Generator 真正成熟的写法,不是“让模型写一份报告”,而是:
先定义目录和交付结构;
再定义检查标准;
再定义修订机制;
最后定义停在哪。
生成从来不是放权,而是约束。
Reviewer:让模型做审稿人,往往比让它做作者更稳
Google 单独把 Reviewer 拎出来,其实非常有洞察力。因为很多业务场景里,模型最适合扮演的角色不是创作者,而是评审者。比如代码审查、合同检查、品牌风格审核、规范打分、论文或方案评阅,这些任务天然更适合 Reviewer。
## Payment Processing with Compliance
--# Before Processing (Compliance Check)
1. Fetch transaction details via MCP
2. Apply compliance rules:
- Check sanctions lists
- Verify jurisdiction allowances
- Assess risk level
3. Document compliance decision
--# Processing
IF compliance passed:
- Call payment processing MCP tool
- Apply appropriate fraud checks
- Process transaction
ELSE:
- Flag for review
- Create compliance case
--# Audit Trail
- Log all compliance checks
- Record processing decisions
- Generate audit report
Anthropic 的五种模式虽然没有直接使用 Reviewer 这个词,但它的 Domain-specific intelligence 和 Iterative refinement 两种模式都能很好支撑 Reviewer 的逻辑:前者强调把领域规则写进处理逻辑,后者强调通过校验和修订提升结果质量。比如金融合规这个例子里,skill 的价值不在会调用支付工具,而在会在调用前完成制裁名单检查、司法辖区核验、风险判断,并保留审计记录”。
Anthropic 在《Building Effective AI Agents》中也强调,很多复杂任务更适合拆成若干可验证阶段,而不是让一个完全自主的 agent 一路跑到底。评审,就是最关键的阶段之一。
这类 Skill 的经验非常简单:
让模型写时,它会发散;让模型审时,它往往更稳定。
所以在很多真实应用里,最有价值的 Skill 并不是一个生成器,而是一个审稿人。
Inversion:先把问题问清楚,再开始执行
Google 的 Inversion 模式,是五种模式里最容易被忽视、但对真实系统最重要的一种。它的思路是:不要让 agent 一上来就动手,而是先通过关键问题把需求澄清清楚。
为什么它重要?
因为很多 agent 失败,并不是模型不够强,而是一开始就基于含糊目标误启动。尤其是那种涉及个人偏好、复杂约束、高风险动作的任务,一旦没有先问清楚,后面的执行越快,错得越离谱。
Anthropic 的 problem-first framing 和 OpenAI 的 completion criteria,其实都能给 Inversion 提供理论支撑。Problem-first 强调用户描述的是目标,skill 要先把完成路径组织出来;而 completion criteria 则要求你先明确到底要交付什么、满足什么限制条件。
所以 Inversion 其实是在 skill 内部固化一个非常重要的流程:
先问清目标;
再确认边界;
再补足缺失约束;
最后才执行。
也就是说,Inversion 不是“多问一句”,而是把澄清需求本身做成 Skill 的标准动作。
Pipeline / Sequential workflow orchestration / Multi-MCP coordination:复杂任务一定要流程化
Google 的 Pipeline,是五种模式里最接近真正 agent 工作流的一种。它承认一件很朴素但经常被忽略的事:复杂任务根本不应该被写成一句万能 prompt。 它应该被分解成阶段、步骤、依赖和检查点。
Anthropic 在这里给了两种更细的模式。
# Workflow: Onboard New Customer
### Step 1: Create Account
Call MCP tool: `create_customer`
Parameters: name, email, company
### Step 2: Setup Payment
Call MCP tool: `setup_payment_method`
Wait for: payment method verification
### Step 3: Create Subscription
Call MCP tool: `create_subscription`
Parameters: plan_id, customer_id (from Step 1)
### Step 4: Send Welcome Email
Call MCP tool: `send_email`
Template: welcome_email_template
第一种是 Sequential workflow orchestration。适用场景是:用户需要按顺序完成多步流程。Anthropic 的例子是新客户开户,步骤包括创建账户、设置支付方式、创建订阅、发送欢迎邮件;关键技巧包括显式步骤顺序、步骤依赖、阶段校验和失败回滚。
### Phase 1: Design Export (Figma MCP)
1. Export design assets from Figma
2. Generate design specifications
3. Create asset manifest
### Phase 2: Asset Storage (Drive MCP)
1. Create project folder in Drive
2. Upload all assets
3. Generate shareable links
### Phase 3: Task Creation (Linear MCP)
1. Create development tasks
2. Attach asset links to tasks
3. Assign to engineering team
### Phase 4: Notification (Slack MCP)
1. Post handoff summary to #engineering
2. Include asset links and task references
第二种是 Multi-MCP coordination。适用场景是:一个任务跨越多个服务系统,比如设计导出、资产上传、项目管理、Slack 通知。Anthropic 特别强调,跨系统协同不是把工具堆在一起,而是要有清晰的 phase separation、跨服务的数据传递、阶段切换前验证,以及集中式错误处理。
Google 的 Pipeline 给了你产品直觉,Anthropic 的这两种模式给了你执行细节,而 OpenAI 则补上“done looks like what”这一层。三者合起来,才是真正成熟的多步骤 Skill 设计:
流程必须分阶段
- 阶段之间必须有依赖关系
- 每一步都要知道输入和输出
- 中间结果要可校验
- 失败要有处理策略
- 什么时候算完成要提前写清楚
排障
很多关于 agent 的文章,写到设计模式就结束了。
但真正做系统的人都知道:设计模式只是上半场,排障才是下半场。
Anthropic 在同一章节里给了一套非常实用的 troubleshooting 思路。最关键的一点是:不要只看结果好不好,还要看skill 的失败类型是什么。在它的指南里,触发与执行层面的问题可以被很清楚地分成几类:
- skill 不触发
- skill 触发太频繁
- skill 加载了,但 MCP 调用失败
- frontmatter 或命名不合法,导致上传失败
比如,当 skill 不触发 时,Anthropic 直接把矛头指向 description 字段:
- 是不是写得太泛?
- 有没有包含用户真实会说的话?
- 有没有写清适用文件类型、场景和触发条件?
甚至还给出一个调试方法:直接问 Claude“什么时候会使用这个 skill”,看它复述 description 时哪里缺信息。
当 skill 触发太频繁时,Anthropic 建议加入 negative triggers,或者把描述写得更具体,明确适用于什么,不适用于什么。这其实非常像传统软件里的路由条件收窄:问题不是模型太聪明,而是你的 skill 作用域写太宽。
当 skill 加载成功但工具调用失败 时,Anthropic 又提醒你分层排查:先确认 MCP 已连接、认证有效、权限范围正确,再让 Claude 不通过 skill 直接调用 MCP 测一次。这个思路非常工程化,它说明 Skill 并不只是文本规则,而是一个真正要依赖外部系统运行的组件。
我觉得这部分特别值得写进文章,因为它让 Skill 设计从创作 prompt变成了设计一个可以观察、可以诊断、可以修复的系统。
方法论
如果把 Google、Anthropic、OpenAI 放到同一张图里,我会把它们理解成三个层次。
第一层,Google 解决的是结构问题。
它告诉你,Skill 大概会落在几类稳定形态里:工具包装、内容生成、内容评审、需求反问、多阶段流水线。换句话说,它给你的是Skill 的形。
第二层,Anthropic 解决的是工作流问题。
它把这些外形进一步拆成执行逻辑:何时 problem-first,何时 tool-first;何时要顺序编排,何时要跨服务协同;何时要迭代收敛,何时要把领域规则写死;以及当 Skill 不触发、乱触发、调用失败时,应该怎么诊断。换句话说,它给你的是Skill 的骨。
第三层,OpenAI 解决的是协议问题。
它要求你把所有这些结构和工作流,最终落成明确的 output contract、tool-use expectations 和 completion criteria。也就是说,Skill 不仅要逻辑上合理,还要接口上稳定。
所以,一个真正成熟的 Skill,至少应该同时具备四样东西:
- 清楚的执行结构:它是 Tool Wrapper、Generator、Reviewer、Inversion、Pipeline中哪一个
- 明确的触发边界:什么情况下该加载,什么情况下不该加载。
- 可靠的工具规则:何时用哪个工具,为什么这样选,失败怎么处理。
- 可验证的交付协议:输出格式、质量标准、完成条件必须清晰。
Example
以典型的RCA为例,一个SKILL应该怎么写?总体的设计规范是Multi-MCP coordination + Iterative refinement + completion criteria
# 根因分析 Skill
## Phase 1:问题归类与澄清
1. 识别问题类型
- 写入异常
- 查询异常
- 复制异常
- 数据缺失
- 资源异常
2. 确认分析范围
- 时间范围
- 影响对象
- 涉及组件
- 最近变更
**完成条件**
- 已明确问题类型、时间范围、影响范围
---
## Phase 2:初始证据收集
1. 通过 MCP 获取指标、日志、事件、变更信息
2. 收集关键观测项
- 延迟、错误率、吞吐
- CPU、内存、磁盘、网络
- 数据库内部状态
**完成条件**
- 已形成初始证据集,而不是只看单点指标
---
## Phase 3:异常时间线构建
1. 对齐指标、日志、事件、变更时间
2. 确定最早异常信号
3. 判断异常先后顺序
4. 请求量增加、单点故障、大查询、bug
**完成条件**
- 已形成清晰时间线
- 已避免把相关性直接当因果
---
## Phase 4:候选根因生成
1. 生成多个候选根因
2. 每个候选包含
- 支持证据
- 反向证据
- 影响范围
- 下一步验证动作
**完成条件**
- 已形成候选根因列表
- 未过早收敛为单一结论
---
## Phase 5:假设验证与缩圈
1. 验证候选根因是否能解释
- 主要症状
- 开始时间
- 影响范围
- 与变更关系
2. 排除解释不充分的候选
**找到根因的标准**
- 能解释主要症状
- 能解释异常开始时间
- 能解释影响范围
- 有清晰证据链
- 已说明为什么不是其他候选
---
## Phase 6:根因定稿与影响评估
1. 输出最终根因
2. 说明证据链
3. 评估影响范围
4. 标注置信度
**完成条件**
- 已有正式结论
- 已有影响评估与不确定性说明
---
## Phase 7:行动建议生成
1. 生成立即止血建议
2. 生成短期修复建议
3. 生成长期治理建议
**完成条件**
- 建议可执行
- 建议与根因直接对应
---
## Phase 8:复盘产物生成
1. 生成 RCA 摘要
2. 生成时间线
3. 生成证据表
4. 生成修复项清单
**完成条件**
- 已形成标准化复盘产物
---
## 总体 Completion Criteria
整个 Skill 完成时,应满足:
1. 已完成主要分析 phase
2. 已输出根因或待验证假设
3. 已包含证据链、影响评估、行动建议
4. 若证据不足,必须明确说明不能定稿
---
## 排障检查
1. 不要只看单点指标就下结论
2. 不要把时间相关性直接当因果
3. 不要跳过反证
4. 不要在证据不足时伪装成最终结论
这里的根本是phase和completion criteria,有两个层面,一个是每一步的完成标准和步骤完成后如何确定完成标准,这要求我们定义清楚一般导致异常的根因,比如请求突发、大查询、单点故障、时间线增加、引擎配置变更、外部接口失败、设计如此等,更近一步的,基于日志去分析代码是否存在bug;
所以SKILL完善的过程也是一个迭代的过程,我们的解决方案是通过去完善每次排查问题的过程,去反哺skill的流程,这里可以定期使用RCA skill去判断沉淀的事件是否可以被再次排查。
从原理来看,程序员依旧是兜底的机制,但是肉眼可见的,这件事情最大的意义其实在于量化工作经验,从机制上避免了防御性编程与文档构建。
结束语
如果只看过去的 prompt engineering,大家关注的是这一轮对话怎样让模型说得更像人、答得更像样。
但今天的 agent 系统不是一次性对话,而是一类任务的长期执行机制。
所以如果这篇文章最后只留一句话,我会留这句:
Skill 不是一段提示词,而是一套关于任务边界、工具边界、流程边界和输出边界的行为设计。
参考:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)