【影像+影像融合+信息保存加权通道空间注意力模型ICS】MMI-Fuse:多模脑影像融合与多注意力模块
论文总结
1、提出了一种新的模型用于多模态脑影像融合,使用了巢式网络结构、自编码器-解码器和ICS信息保存加权通道空间注意力,其中ICS由通道注意力、空间注意力和信息加权保持三部分组成;
2、有开源代码,https://github.com/shizhenghe/MMI-fuse
摘要
医学影像在脑部疾病的临床诊断中起着关键作用。有许多成像方法可以检测大脑组织的状态。虽然这些成像方法有优点,但也存在不足。例如,磁共振成像(MRI)包含组织结构信息但没有组织的功能特征,而正电子发射断层扫描(PET)则具有功能特征但没有结构信息。该注意力机制已被广泛应用于图像融合任务,如红外与可见光图像及医学图像的融合。然而,这些注意力模型缺乏多模态图像特征的平衡机制,影响最终的融合性能。本文提出了一个端到端多模态脑影像融合框架MMI-fuse。具体来说,我们首先应用自编码器提取源图像的特征。随后,提出了一个信息保存加权通道空间注意力模型(ICS)以融合图像特征。我们根据特征的信息保持程度设定自适应权重。最后,我们使用解码器模型重构融合后的医学图像。该方法通过改进的注意力模型和编码器-解码器结构,提高了融合图像的质量并有效缩短了融合时间。为验证该方法的性能,我们从哈佛数据集中收集了1590对多模态脑图像,并进行了大量实验。比较实验中选定了七种方法和五项指标。结果表明,所提方法在这七种方法中,在视觉质量和客观指标得分上均取得了显著表现。此外,所提方法在所有比较方法中所需时间最少。
引言
图像融合旨在将来自不同图像源的信息整合到单一图像中。该技术广泛应用于军事、医疗和民用行业。在临床诊断领域,医学影像在癌症和肿瘤的诊断中起着关键作用。另一方面,医学图像的成像机制和表达格式非常多样。例如,计算机断层扫描(CT)和磁共振成像(MRI)都是带有结构信息的灰色图像:前者关注骨骼和植入物等致密结构;后者主要关注软组织,如内脏和脂肪。位置发射断层扫描(PET)和信号-光子发射计算机断层扫描(SPECT)是伪彩色图像,且功能信息:前者根据疾病状态提供组织信息;后者包含器官代谢信息,用于检测。在不同影像间切换可能降低诊断效率,增加医生在推断临床诊断结果时的错误。随着图像处理的发展,多模态医学图像融合已成为一种有前景且有意义的手术,能够提供关键的图像信息。在过去几十年里,提出了一些用于医学图像融合的方法。我们将简要总结这些方法。基于多尺度分解(MSD)的方法[1]–[3]遵循分解-重建范式。它们将源图像划分为多个层,从不同角度表达信息。这些方法首先使用变换函数,如锥形变换[5]、小波变换、轮廓变换[2],或Shearlet变换[7],将输入图像分解为多尺度系数。然后,采用手动设计的融合策略来融合这些系数。最后,通过逆变换重建融合系数。MSD方法可以在PET和SPECT中保留伪色,但限制图像分辨率。这些方法的性能主要依赖于手动设计的聚变策略,而该策略可能无法实现良好的生成能力。基于子空间和成分替换(SCS)的方法可分为两类:基于统计的方法[8]、[9]和基于颜色的方法[11]、[12]。基于统计的方法试图通过高阶统计量(如主成分分析和贝叶斯框架)确定隐藏的显著结构。然而,这些方法耗时且噪声较大。基于颜色的方法首先将一个源图像转换为另一个色彩空间。然后,某个元件被替换或融合到另一个源图像。虽然它们可以保留结构信息,但医学图像的功能信息会丢失。稀疏表征(SR)源自神经科学的突破,即人类视觉系统具有选择性。基于SR的方法在医学图像融合方面取得了有前景的表现[14], [15], [16], [38]。Xiaosong Li等人[14]提出了一个融合框架,用于解决无噪声图像融合和噪声扰动图像融合问题,并根据噪声水平自适应地设计了稀疏重建误差参数。该范式高效减少了超参数数量,增强了模型的泛化能力。然而,基于SR的方法仍然存在缺点。基于SR的方法的性能高度依赖词典学习,而学习完整词典非常耗时。为了改善词典学习的低计算效率,Zhou 等人[4]提出了一种方法,通过提取并添加图像的多层细节来强化其弱信息,生成有信息的补丁。此外,基于模糊逻辑的方法[17]、形态学方法[18]和浅层机器学习方法[19]也取得了显著的性能。尽管上述方法取得了进展,但特征提取的主要短缺线。此外,多尺度分解和SR应用手工特征提取导致生成能力较差。近年来,深度学习(DL)因其卓越的特征提取和表示能力,在自然语言处理(NLP)和计算机视觉(CV)领域取得了巨大进展。因此,基于DL的医学图像融合方法比传统方法具有更好的特征提取能力。生成网络和对抗网络(GAN)将图像融合视为一种博弈过程。他们使用生成器和判别器来制造假数据,并将图像当作真实图像进行分类,从而生成图像。马等人[20] 首次将GAN引入红外和可见光图像融合技术。姜等人[21] 提出了一种组织感知条件生成对抗网络(TA-cGAN),通过连接光谱和结构损失,聚焦于PET中颜色信息与MRI中解剖信息之间的平衡。此外,TA-cGAN的作者将图像融合视为生成器和判别器的Mix-Max优化问题。尽管GAN的性能突出,但训练挑战,如良好的初始化,仍限制融合结果。循环神经网络(RNN)主要应用于语音识别和文本分析。然而,局部和全局上下文依赖性检索能力帮助RNN模型学习了每个像素表示之间的关系,并增强了每个像素的表示。受自然图像局部和非局部自相似性的启发,赵等人[10]提出了基于RNN的多焦点图像融合模型。该模型利用了RNN模型检索远距离依赖关系的能力,减轻了模型深入时的信息丢失。卷积神经网络(CNN)自LeCun等人提出以来,在医学图像分析领域取得了显著成就[41]。许多方法[42]、[43]基于CNN被提出。基于CNN的第一个融合方法由Liu等人[13]于2017年提出。他们认为图像融合是分类任务。参考文献[6]提出了一种基于加权参数自适应双通道PCNN(WPADCPCNN)的融合方法。该方法将源图像分解为高通子带和低通子带。随后,低通子带采用加权多尺度形态梯度规则融合,高通子带则采用WPADCPCNN。然而,双通道PCNN的融合性能受限于参数和层数。此外,高计算成本限制了其应用范围。尽管基于RNN和CNN的方法取得了进步,但这些融合方法需要对高效深度模型的精心设计。聚变模型的性能受到模型深度的极大影响。本文提出了一种名为MMI-Fuse的无监督端到端框架,用于多模态医学脑图像融合。该框架通过使用自编码-解码器网络,有效避免了神经网络深度对性能的影响。为了保留信息,我们设计了注意力模型的自适应权重,根据特征梯度计算。提出的MMI融合包括自编码-解码器模型和多注意力融合模型。关于拟议融合网络的主要贡献总结如下:
(1)我们提出了一种新型多模态脑图像融合框架MMI-Fuse,采用巢状连接架构[22]提取源图像特征,并采用改进的多注意力模型融合特征。
(2)我们提出了一个信息保持加权信道空间注意力模块(ICS)以融合特征信息保存程度,更有效地、更合理。
(3)我们在广泛使用的医学图像数据集哈佛数据集上进行了与其他杰出融合方法的高效比较实验,结果显示该方法促进了医学图像融合的质量和效率。论文的其余部分结构如下。我们在第二部分简要介绍相关工作。拟议的MMI-Fuse细节见第3节,实验分析在第4节进行。最后,结论在第五节中呈现。
相关工作
巢式连接
跳跃连接的理论和实践早已为人所知。他等人[23]应用跳跃连接以避免消失和爆炸梯度,使CNN架构更为深邃。然而,Zhou 等人[22]提出,CNN架构中的长程跳跃连接可能导致语义缺口。基于这一观察,他们于2018年首次引入了用于医学图像分割的巢状连接Unet++。UNet++ 应用了上采样和短跳跃连接来替代长距离跳跃连接。不同尺度特征之间的上采样有效地释放了语义间隙。随后,Li等人[24]将巢状连接引入红外和可见光图像融合任务,并取得了显著的性能。因此,我们将巢状结构引入多模脑图像融合领域,并提出了新的融合框架。
注意力机制
注意力机制源自变换器模型,该模型多年来在自然语言处理中取得了优异表现[25]。许多研究者将这一机制引入了视觉,因为注意力具有卓越的全局和局部信息整合能力。在图像融合中,采用了注意力机制来设计融合策略。Vibashan等人[26]提出了一种具有空间分支和轴向注意力分支的时空变换器融合策略。前者捕捉局部特征,后者学习全局语境特征。Li 等人[24]设计了一种两阶段注意力融合策略用于深度特征融合。该策略包括空间注意力模型和通道注意力模型,分别用于聚焦局部特征和全局特征。受这些作品启发,我们设计了一个单阶段多关注模型。具体细节将在下一节中展示。
图像融合的性能评估
高效的图像融合方法应尽可能保留融合结果中的互补信息,使融合图像看起来更自然。评估融合方法的性能有两种方式:主观和客观质量指标[40]。在医学图像融合领域,前者方法包括对畸变和空间细节的观察,简单且可靠。然而,评估结果受多种因素影响,导致结果不稳定。后者通过精确的数学计算和统一标准评估聚变结果。虽然复杂,但结果稳定可靠。因此,许多研究者致力于提出更普遍、客观的质量指标。Sengupta等人[39]提出了基于边缘信息的图像融合算法的三种度量指标。作者利用分数阶微分获得了边信息。通过分数阶微分获得的边缘信息被用来估计融合图像及对应源图像的三个归一化加权指标的值。
所提出的方法
在本节中,我们展示了提出的多模脑影像融合框架MMI-fuse的详细介绍。该框架可用于融合两张医学图像(如伪彩色SPECT或PET与黑白MRI图像),或三张医学图像(如SPECT和MR-T2以及MR-Gad)。我们在图1中展示了拟议框架的整体结构。具体来说,该框架包括三部分:编码模块、融合策略和解码模块。首先,先用头块预处理源图像,将通道从3增加到64。然后,这些64通道特征被输入四个编码模块以提取特征。从源图像中提取的特征随后被ICS模块融合。然后,融合后的特征被送入解码模块,重建融合后的图像。以下将介绍这三部分的细节。
自编码器-解码器网络
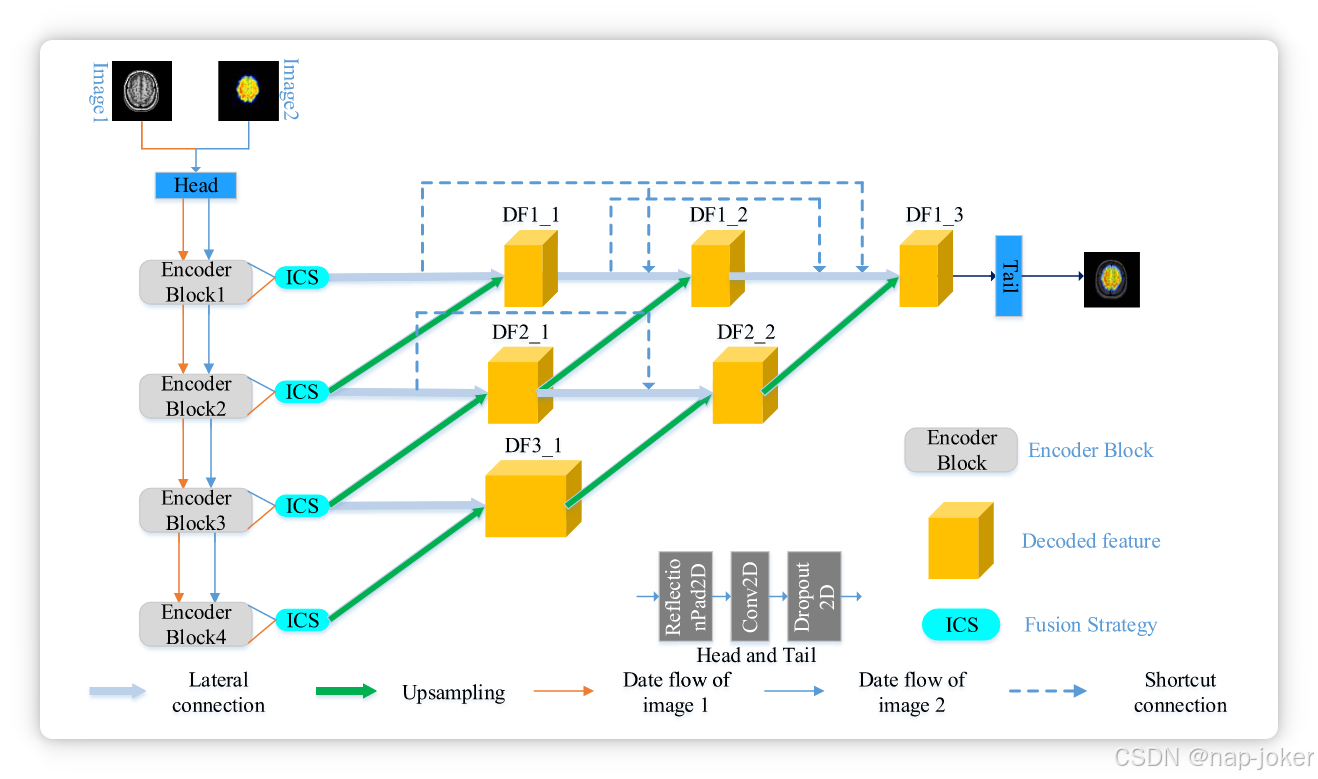
图1,所提多模脑影像融合框架概述
自编码-解码网络(AED)的主要目标是生成融合模块的特征,即信息保持加权通道空间注意力(ICS),如图1所示。在编码器中,四个编码模块叠加以从输入图像中提取具有四种不同尺度特征的特征。每个编码模块包含两个卷积层用于下采样特征。同样,解码模块也由两个卷积层组成。解码器的唯一区别是,丢弃层被ReLu层取代。每个解码模块同时接收该层的特征和下一层的上采样特征。
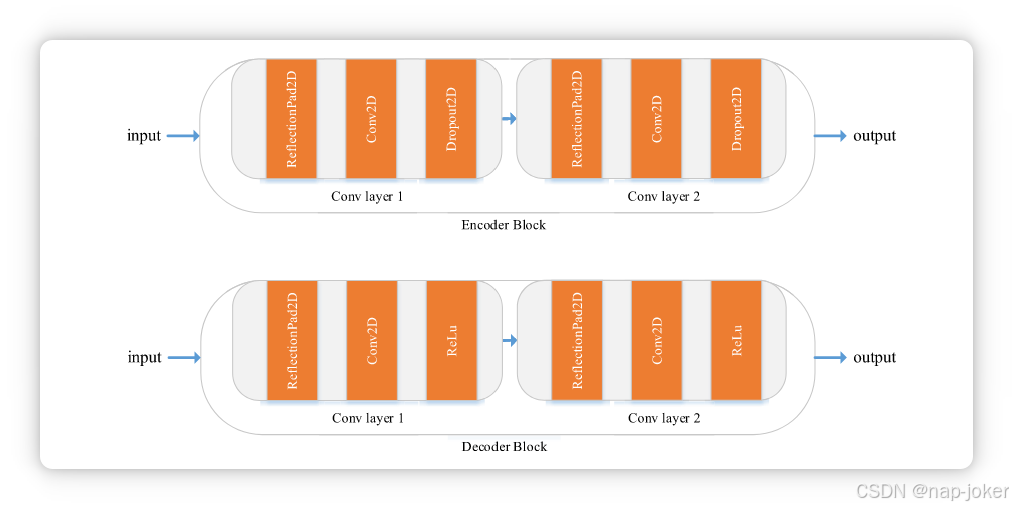
编码模块和解码模块的结构。
我们在图2中展示了编码块和解码块的详细信息。卷积层1的卷积核大小为3,汇聚层2的卷积核大小为1。特征的通道在变形层1中降采样为一半,在变形层2中被上采样到预定义的输出信道。在训练阶段,受DenseFuse[27]启发,ICS模块与主框架分离。根据PET和MRI图像的特性,损失函数包含两部分:
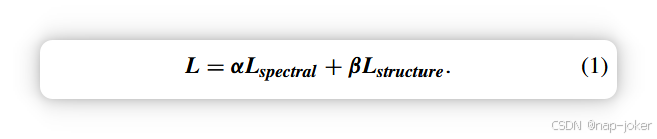
其中光谱损失(Lspectral)关注PET和SPECT图像的色彩信息,结构损失Lstructure关注MRI图像的纹理信息。α和β分别是光谱损失和结构损失的权重因子。两个损失函数的数学表达式如下所述。
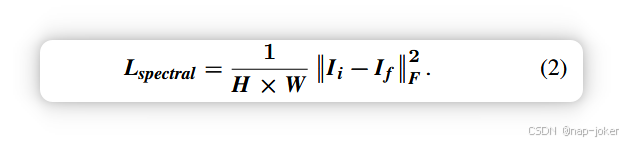
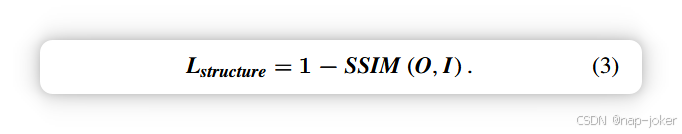
其中H和W分别是源图像的高度和宽度。Ii和If分别是输入的原始伪彩色图像和融合图像。‖·‖F是弗罗贝尼乌斯范数。其中SSIM表示结构相似度度[28]。I和O分别表示输入图像和输出图像。考虑到收集医学图像数据集的难度,我们在COCO2014上训练了自编码-解码器网络[29]。在训练期间,我们将参数α设为1,β为100。然后,将融合特征重构以获得融合图像。
融合技巧
注意力机制在人类视觉系统中起着关键作用。视觉信号在大脑中转发时被划分为多个通道。随后,大脑的注意力系统根据任务需求过滤掉这些输入信号中的关键通道,同时对其他无关紧要通道的注意力较少。Sanghyun Woo等人[30]提出了一个简单但高效的注意力模块,以提升CNN的性能,专注于通道和空间轴特征的信息。受此启发,我们设计了一个用于医学图像融合的注意力模块——信息保存加权通道空间注意力(ICS)模块,该模块同时执行注意力操作,并将通道与空间分支的输出融合在一起。图3详细展示了ICS的结构。该结构主要包括三个部分:通道注意力、空间注意力和信息保持加权(IPW)。
通道注意模块
该模块侧重于通道间关系信息,同时融合两个输入特征。我们首先对输入特征进行卷积。然后利用全局池化计算初始全局权重 W c(Ik)。数学表达式见式(4)
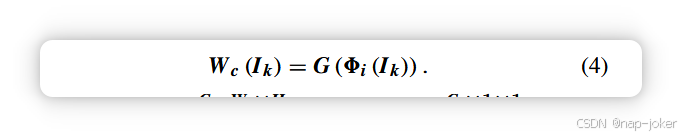
其中8i∈RCi×Wi×Hi,W c (Ik) ∈ RCi×1×1,Ik (k ∈ {1, 2})分别代表编码器提取的四个尺度特征和两个源输入图像。G (·) 表示全局池化操作。我们选择平均算子来平均所有信道。池化算子按信道进行。即池化核大小与输入特征的 w 和 h 维数相同。图3中,平衡策略1是一个加权平均运算,执行于 W c(Ik)。加权均值后的 W c(Ik)作为输入特征在 w 和 h 维度下重复,大小相同。然后,通道注意模 8f ci 的输出融合特征由方程(5)计算,
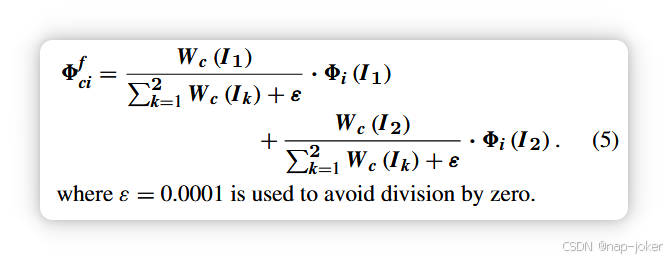
空间注意模块
该模块关注两个源图像特征融合时的空间关系信息。与通道注意模块不同,我们使用通道维度的平均值来探索空间信息。初始空间权重 W Isk (x, y) 使用方程 (6) 计算,

C 表示信道号。方程(6)中参数的含义与方程(4)中相同。然后,我们引入平衡策略2,计算两个源图像特征的空间注意力权重。空间注意力模型8f的输出si由方程(7)计算,

信息加权保持
特征梯度易于计算和存储[31]。为了融合通道注意力模型和空间注意力模型的输出特征,我们引入了一种信息保持加权策略,根据这两个特征的梯度评估信息内容。输出特征的信息保持程度定义在方程(8)中,
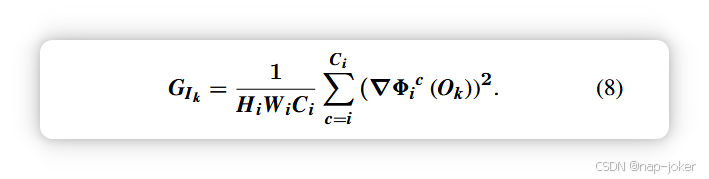
其中8i(Ok)∈RCi×Wi×Hi表示通道或空间注意模块第k个输入源图像的输出特征。Hi、W i和Ci分别表示高度、宽度和通道。∇是拉普拉斯算符。我们将通道和空间注意力模块处理的特征与自适应信息保持权重融合。我们用W Ik表示该自适应权重。W Ik的数学表达式为方程(9),
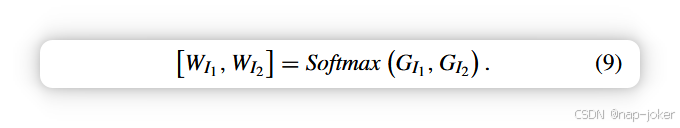
我们应用Softmax函数将W I1, W I2设在0和1之间。然后,这两个权重用于融合由注意力模块处理的特征。
实验
实验条件
源图像
我们从哈佛医学院发布的广泛认可的哈佛数据集中收集了106对多模态医学图像。这些图像对包括四种脑部疾病:AISD、阿尔茨海默病、胶质瘤和亨廷顿舞蹈症。这些图像中包括20对质子密度加权MRI(MRI-PD)和T2加权MRI(MRI)图像,50对MRI(质子密度加权和T2加权)及SPECT图像,16对钆加权MRI和SPECT图像,以及20对MRI(T1加权和T2加权)和氟脱氧葡萄糖PET图像,均包含在我们的收藏中。所有源图像均为256×256像素,且注册良好。鉴于数据量较小,我们扩展了收集的数据。我们采用了两种数据增强方法:翻转和裁剪。首先,我们将所有图像从右向左、从上到下翻转两遍。此操作使图像对数增加到318对。然后,我们将图像大小裁剪为64×64;即从每256×256图像中生成四个子图像。最终,我们获得了1590对图像。
对比方法
为展示该方法的表现,我们将其与七种近期方法进行了比较。这些方法包括LLF-IOI[5]、CNNs[32]、PAPCNN[7]、CTD-SR[33]、MRNDM [34]、TA-cGAN [21]和U2Fuse [31]。
评估指标
最初,我们对所有方法进行了主观比较,但这不足以评估融合方法的性能。因此,我们应用了五个指标来分析融合图像的质量。具体来说,这些指标包括熵(EN)[35]、基于梯度的指数(QAB/F)[36]、融合视觉信息保真度(VIFF)[37]、并集结构相似度测量(SSIMu)和标准差(SD)。鉴于有两张可视为参考图像的源图像,本文中的结构相似度测量被修改为SSIMu。SSIMu的表达式见式(10),

伪彩色与灰度图像的融合
SPECT和PET成像生成带有3通道的RGB格式伪彩色图像,而磁共振成像生成1通道灰度图像。这种通道编号上的不兼容限制了多模态医学图像的融合。将输入图像融合为不同数量的通道,我们首先将RGB图像转换为YCbCr空间。YCbCr色彩空间编码带有照明分量(Y)、蓝色色调分量(Cb)和红色调分量(Cr)的彩色图像。然后,YCbCr空间中的Y部分与灰阶源图像融合。最后,融合后的图像可以通过逆转换函数转换为RGB空间。图4展示了我们框架中RGB和灰度源图像的处理过程。蓝色线条表示图像数据的流动。
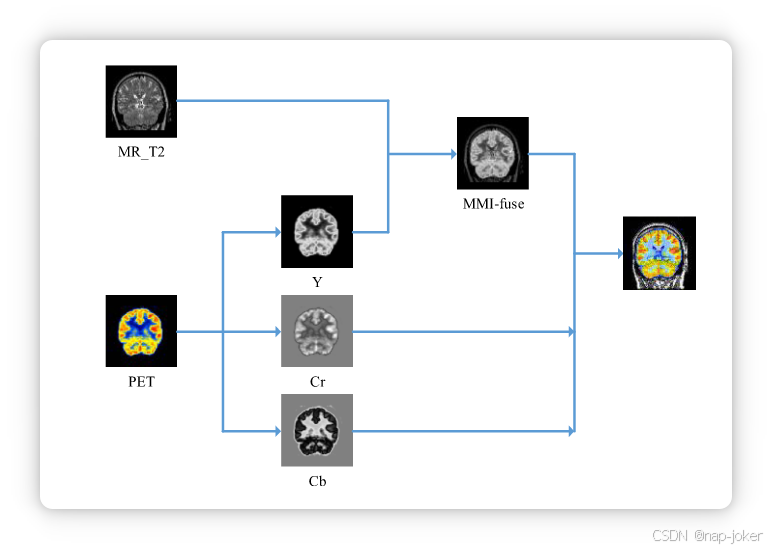
图4:编码器模块的结构
主观的视觉评估
我们分析了该方法的结果以及其他广泛使用的方法的结果。融合后的医学图像由五个不同的图像组成包括MRI-PD和MRI-T2、MRI-PD和SPECT-Tc、钆基MRI和SPECT-Tc、钆基MRI和SPECT-Tc、钆基MRI和SPECT-Tl,以及MRI和氟脱氧葡萄糖PET。图5展示了T1加权MRI和氟脱氧葡萄糖PET影像融合的结果,用于视觉比较。显然,CTD-SR、PA-PCNN和TA-cGAN的融合结果丢失了MRI-T1图像中的结构信息(bi、ei和fi、i∈(1, 2, 3))。CNN、NDM和LLF-IOI在结构信息保存方面表现更好。然而,在伪色明显的结构信息(ai、ci、di,i ∈ (1, 2, 3))方面表现不佳。U2fuse在颅内区域的结构信息和伪色彩信息保存方面表现更好,但在颅骨和颌面区域对比度较低(gi, i ∈ (1, 2, 3))。与上述方法相比,所提方法实现了解剖结构与功能代谢之间的准确对应。此外,灰质、白质、沟和脑回的解剖结构比上述现有方法更为清晰。将相应的功能代谢反映在清晰的解剖结构上,更有利于全面的临床判断(hi, i ∈ (1, 2, 3))。图6展示了MRI-T2和MRI-PD图像融合的视觉比较结果。CTD-SR的结果(见(bi)在MRI-T2和MRI-PD图像中保留的结构信息较少。U2fuse的结果在保存脑组织(gi)细节方面表现更好。与CNN、LLF-IOI、PA-PCNN、NDM和TA-cGAN相比,所提方法在更短时间内几乎能获得相同的性能,如表2所示。然而,U2fuse在对比度(gi)方面的性能优于拟议方法。图7展示了MRI-PD和SPECTTc图像的融合结果。LLF-IOI、CTD-SR和PA-PCNN的结果在SPECT图像(BI、CI和EI)中包含更多伪色彩信息,因此MRI-PD的结构信息被很好地覆盖。U2fuse的结果对比度低,导致眼睛轮廓、头皮贴合度和颅骨模糊(gi)。所提方法的结果(hi)表明,伪色彩信息和结构细节均被考虑在内。尽管拟议方法的视觉质量与CNN、NDM和TA-cGAN相似,但我们的方法所需时间更短。图8展示了MRI-Gad和SPECT-Tc/Tl图像的融合结果。显然,CTD-SR、LLF-IOI和NDM融合结果中的回形成已被伪色覆盖。相比之下,所提方法的结果在回细节方面比其他方法更为清晰。最后两行展示了MRI-Gad和SPECT-Tl的融合结果。SPECT-Tl 的色彩信息在 CNN、CTD-SR、LLF-IOI、NDM 和 TA-cGAN 的融合结果中表现较少,因此颜色看起来较浅。PA-PCNN 实现了最佳的视觉表现。
客观质量评估
不同方法的客观质量通过五个指标量化,如表1所示。我们计算了每种融合组合的五个指标的平均值。对于每个指标,我们显示了八个指标中最高的值。包括所提方法,红色加粗显示。很容易看出,该方法在8种方法中报告最佳表现,这意味着该方法在8种方法中排名第一。TA-cGAN以6次得分排名第二,PA-PCNN和U2fuse以4次得分位列第三。特别是,该方法在SD和SSIMu上表现最佳。TA-cGAN在五项指标中的表现总体上非常出色。U2fuse在EN方面始终名列前茅。其他方法中没有明显的优势分数。
效率比较
表2报告了8种方法的运行时间。我们拍摄了10对MRI-T1和PET图像进行评估。最佳分数以加粗红色显示。表2中的数据代表了该方法融合10对图像所花费的总时间。我们可以看到,拟议方法融合10张图像所需时间更短(仅6.97秒),同时也实现了最佳的融合效果。
消融研究
超参数alpha和beta
在我们的研究中,方程式(1)中的超参数α和β是自定义的。为了探索最佳α和β组合,我们将α设为0.1、0.5和1,消融研究中β为1、10、100和1000。图9展示了MRI-PD和SPECT图像融合结果,采用不同α和β组合作为示例。从左到右的四列表示β等于1、10、100、1000,从上到下的三列分别表示α等于0.1、0.5、1。主观上,当α值小于0.5、β小于100时,MMI引信的性能显然不理想。另一方面,当α等于1、β等于1000时,局部亮度的增加导致结构信息被覆盖。从上述结果来看,赋予更大的α和β有助于保留结构信息。为了做出更好的选择,我们比较了不同超参数组合的客观性质。表3展示了客观指标的结果。数据表明,尽管组合α=1和β=100在某些单一指标(如标准差和QAB/F)上低于组合α=1和β=1000,但前者的整体结果优于后者。
ICS注意力模块
融合策略在所提方法中起着关键作用。本节分析不同注意力模块组合对融合结果的影响。图10展示了若干融合结果以供视觉分析。通道注意力模块在降低不同密度组织(颅骨和脑组织)间对比度的同时,可以保留更多结构信息。空间注意力可以获得良好的对比度,但会模糊沟信息。通道和空间注意力改善了沟的模糊效果,但忽略了对比。相比之下,我们提出的ICS模块不仅提升了沟的情报,还改善了不同密度组织之间的对比度。我们在表4中展示了客观指标。从结果可以看出,所提ICS模块在EN、SD、VIFF和SSIMu方面表现最佳。与单注意力模块相比,具有信息保留权重的多注意力模块取得了更显著的效果。
总结
本文提出了基于改进的多通道注意力模型MMI-fuse的多模态脑图像融合框架。该框架采用嵌套架构进行特征提取和图像重构。在融合策略方面,我们提出了一种新型信息保持加权通道和空间注意力模块,能够自适应融合通道和空间注意力模块处理的特征。为验证MMI-fuse的性能,我们从哈佛数据集收集了1590对多模态医学图像,进行了广泛实验。选定了七种方法,包括CNN、CTD-SR、LLF-IOI、NDM、PA-PCNN、TA-CGAN和U2fuse,以及五项指标:EN、SD、QAB/F、VIFF和SSIMu进行验证。结果显示,虽然所提方法在某些指标上表现最佳,但在这七种方法中所耗时间最少。尽管MMI融合法取得了令人满意的结果,但仍有许多分数需要改进。例如,我们的方法在MRI和SPECT图像融合方面尚未取得显著成果。我们发现特征提取器是影响融合框架性能的另一个重要组成部分。此外,本研究侧重于多模态脑图像的融合,缺乏向其他多模态图像融合的推广。因此,我们将重点改进编码器和解码器以提取特征并重建融合图像,并开展更多水平实验以提升模型的泛化能力。最后,MMI融合的伪色保真度还需进一步提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)