Adaptive deep physics-informed neural network with dual-nestedactivation for solving complex partia
A B S T R A C T
物理信息神经网络(PINNs)在求解偏微分方程方面具有潜力,但在实现高精度方面常常面临挑战,尤其是在复杂的真实世界场景中。本文提出了一种自适应深度物理信息神经网络(ad-PINN)框架,旨在提升激活函数和损失函数的效率。所提出的 ad-PINN 引入了两项主要创新:(1)一种具有双嵌套机制的自适应激活函数,称为双曲正切对偶函数(dual-tanh),该函数能够动态调整其斜率和形状,以优化超越传统激活函数的学习能力;(2)一种自适应 Huber 损失函数,该函数能够自动调整其参数,无需手动调参。激活函数与损失函数的这种双重自适应性提升了模型的灵活性和性能。理论上,我们证明了在适当的初始化和学习率下,最小化损失函数的梯度下降算法能够避免收敛到次优临界点或局部极小值。ad-PINN 的有效性通过实际应用得以展示,包括冲击波传播与反射、不可压缩固体力学、双材料问题以及流体动力学。对比实验表明,ad-PINN 相较于现有的一些 PINN 方法取得了显著更高的精度,突显了其处理具有高梯度解、捕捉隐式不可压缩性、处理位移不连续性、应对具有复杂几何与物理特征的高维系统,以及求解部分已知物理定律所支配的系统等复杂问题的能力。
1. Introduction
近几十年来,深度神经网络(DNNs)已成为科学与工程领域数据驱动应用中的核心工具。这类网络以全连接人工神经网络(ANNs)为核心架构,展现出强大的学习能力,在识别问题、动态分析及时间序列预测等任务中均取得显著成效——尤其当基于高质量数据或其他信息性输入进行训练时,其表现更为突出。
物理信息神经网络(PINNs)通过将已知物理定律直接嵌入网络训练过程,为解决复杂系统提供了创新性计算方法,从而降低对标注数据的依赖性。与传统监督学习模型不同,PINNs采用无监督学习方式,利用控制方程指导学习过程。这使得PINNs在数据稀缺但物理定律已被充分理解的场景中展现出独特优势。
与传统数值方法[1,2]相比,PINNs 展现出一些优势。(1)传统数值方法需要离散的网格或网格划分来近似求解,而 PINNs 不需要预定义网格,因为它们学习的是解的连续函数表示。(2)在处理高维问题时,传统数值方法的计算成本随维数增加呈指数级增长。相比之下,PINNs 利用神经网络的函数逼近能力有效处理高维问题,计算复杂度仅呈多项式级增长。(3)传统数值方法通常需要复杂的迭代过程来求解逆问题,如参数估计或未知边界条件。而 PINN 可以通过将未知参数作为可训练变量嵌入神经网络来自然地处理逆问题,实现直接优化和求解。(4)传统数值方法在数据稀缺场景下难以有效执行。而 PINN 通过将物理方程作为额外约束纳入,即使在数据有限的情况下也能产生合理的解。
近期研究表明,PINNs 在求解复杂偏微分方程方面展现出潜力[3,4]。例如,Yuan 等人提出了 A-PINN 框架,这是一种多输出神经网络,能够同时近似控制方程中的变量和积分项[5]。Ji 等人将准稳态假设应用于 PINNs 中以求解刚性化学动力学问题,拓宽了 PINNs 在具有刚性动力学的反应-扩散系统中的适用性[6]。Pu 等人开发了一种改进的 PINN,采用神经元局部自适应激活函数,用于捕获复杂空间中的局部波动解[7]。Wang 等人实现了一种多层 PINN 算法,用于学习时变势场下散焦非线性薛定谔方程中的参数[8]。Bai 等人提出了物理信息径向基网络(PIRBN),该网络在整个训练过程中保持局部逼近特性,在处理具有高频特征和不适定区域的非线性 PDE 方面优于 PINN[9]。Sharma 等人提出了 DT-PINN,将现代科学计算技术与机器学习相结合。DT-PINN 的训练方法包括用基于无网格径向基函数有限差分(RBF-FD)计算的高阶精度数值离散格式替换精确的空间导数,然后通过稀疏矩阵-向量乘法进行计算[10]。
尽管取得了这些进展,PINNs 在处理复杂的非线性问题(如不可压缩材料、多材料相互作用、大变形梯度系统以及具有复杂边界的系统)时仍面临挑战[11–15]。此外,PINNs 的精度高度依赖于嵌入物理约束的精确性和完整性,约束不足会导致对真实系统的次优表示。为解决这些局限性,研究人员提出了多种优化框架来提升 PINN 的性能[16–24]。例如,Yadav 等人证明 DPINN 能够处理固体力学中的体积锁死和不连续性问题,无需特殊处理[14];而 Wandel 等人为 CNN 引入了 Hermit 样条核,仅使用物理信息损失函数,即可实现无需预计算数据的连续网格状态插值[15]。Wang 等人提出了 PirateNets,引入了一种新颖的自适应残差连接,在多项基准测试中取得了最先进的结果[25]。Cooley 等人提出了 HyResPINNs,该网络通过引入自适应混合残差块来增强传统 PINN。该方法通过在每个残差块中引入自适应组合参数,动态学习平衡神经网络与 RBF 网络输出的贡献,从而提高了精度并减少了训练时间[26]。
PINN 模型的精度与神经网络的结构密切相关,其中激活函数在决定解的质量方面起着至关重要的作用[27]。激活函数没有确定性的选择,通常是问题依赖或物理依赖的。近年来,研究者们提出了多种使用不同激活函数的 PINN 模型。例如,Jagtap 等人提出了局部自适应激活函数以增强基于物理的神经网络的性能[28];Guo 等人在激活函数中引入超参数来对抗梯度消失问题,从而提高了计算效率和训练速度[29]。类似地,Salah A. Faroughi 等人证明了周期激活函数在使用 PINN 求解多孔介质中溶质输运问题时的有效性[30]。Bai 等人开发了鲁棒的 RPIM-NNS 框架,该框架将径向点插值方法与神经网络求解器相结合,用于高度非线性的固体力学问题[31]。然而,许多激活函数仍然表现出 S 型“饱和”特性,即神经元在极端值处对小输入变化变得不敏感,导致分析动态系统特征时的分辨率降低。改进的自适应激活函数有助于解决这一问题,但需要最优的参数调优,使得激活函数的选择在理论和应用中都是一个具有挑战性的问题。


在本工作中,我们提出了一个自适应深度物理信息神经网络(ad-PINN)框架,通过同时优化激活函数和损失函数,来应对复杂的非线性问题、高维系统以及部分物理定律已知的系统。我们的贡献体现在三个方面:(1)引入了一种具有双嵌套机制的新型自适应激活函数,以实现最优性能;(2)采用了一种基于 Huber 损失的自适应函数,其超参数在训练过程中动态调整以最小化误差;(3)在多个实际问题中评估了 ad-PINN 的性能,这些实际问题包括 Burgers 方程、不可压缩材料、叠合梁问题以及具有未知参数的非线性 Navier-Stokes 方程。这些贡献展示了 ad-PINN 在实现高精度解、提升收敛性以及为复杂现实世界系统中的 PINN 提供更深入理论见解方面的潜力。
2. Physics-informed neural networks (PINN)


3. Adaptive deep physics-informed neural network (ad-PINN)
在神经网络模型中,激活函数对实现输入数据的非线性转换起着关键作用,这对捕捉复杂模式至关重要。然而传统激活函数(如Sigmoid和Tanh)在深度网络训练过程中常会出现梯度消失或梯度爆炸等问题。这些问题会显著影响训练过程的稳定性和效率,阻碍学习进程并限制模型性能。因此,选择合适的激活函数对于获得可靠的训练结果具有决定性意义。
3.1. Adaptive dual-nested activation function (dual-tanh)
我们构建了一个具有双重嵌套机制的激活函数 𝑑𝑢𝑎𝑙 - 𝑡𝑎𝑛ℎ(.),其表达式为:
![]()
其中tanh(.)表示双曲正切函数, 𝛽 为可在线训练的参数。
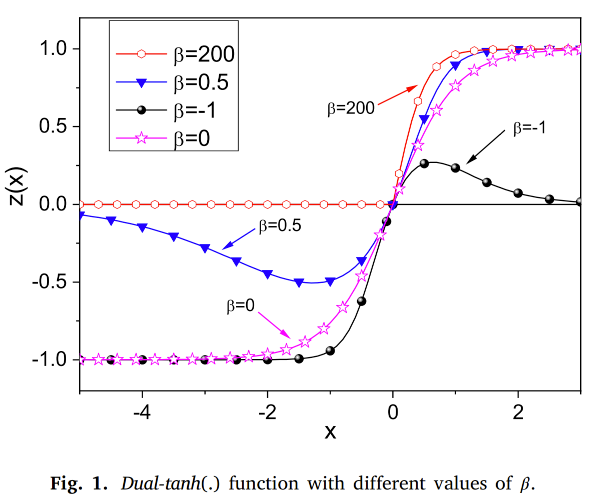
图 1 展示了不同 \(\beta\) 取值下的 dual-tanh(.) 函数。当 \(\beta = 0\) 时,dual-tanh(.) 简化为标准的双曲正切函数。当 \(\beta\) 趋近于 \(\pm\infty\) 时,它分别类似于正 Sigmoid 或负 Sigmoid 激活函数。对于有限的 \(\beta\) 正值(或负值),dual-tanh(.) 的行为类似于正(或负)Leaky ReLu 函数。这表明 dual-tanh(.) 函数是一个光滑函数,能够在正负 ReLu 函数之间进行非线性插值,且幅度可调,参数 \(\beta\) 控制着这种插值的程度。显然,参数 \(\beta\) 可以同时修改激活函数的斜率和形状,这是神经网络训练中的一个关键因素。**
dual-tanh 激活函数通过将一个 tanh(.) 函数的变体堆叠在另一个之上而设计,产生了一种分层效应,显著影响神经网络的训练动态。与 ReLU、Sigmoid 和 Tanh 等传统激活函数相比,dual-tanh(.) 函数具有以下几个优势:
(1)嵌套结构: 通过组合两个 tanh(.) 函数,dual-tanh 函数实现了复杂的嵌套关系,能够更细致地表示深度神经网络中的动态行为。此外,dual-tanh 函数具有更简单的嵌套结构(仅组合两个 tanh(.)),最小化了嵌套层级,降低了计算复杂度。
(2)可训练参数: dual-tanh 函数的斜率和形状可以通过可训练参数 \(\beta\) 自动调整,增强了学习能力并可能提高收敛速度。这与改进的激活函数 [32] 形成鲜明对比,后者只能改变激活函数在零点处的斜率。
(3)关于原点不对称:与传统激活函数不同,dual-tanh 函数是非对称的,这更能贴合现实中往往缺乏对称性的真实系统。
(4)有界、光滑且非单调: dual-tanh 函数具有有界性和光滑性,同时具备非单调特性,这使其区别于常用的激活函数,能够对输入变化做出更细致的响应。
(5)负半轴有限响应:类似于 Leaky ReLU,dual-tanh 函数在负半轴上保持有限值,避免了负输入变为非活跃状态的“神经元冻结”问题。
(6)用更少的层捕捉复杂动态: 神经网络中输入与输出的关系通常通过堆叠多个标准激活函数来建立,如式(3)所示。这种堆叠关系是通过神经网络多个隐藏层之间的相互作用实现的。本文提出的 dual-tanh 激活函数通过将一个 tanh(.) 函数的变体堆叠在另一个之上来设计,产生了如式(5)所示的分层效应,从而无需使用过多隐藏层即可获得复杂的输入–输出关系。


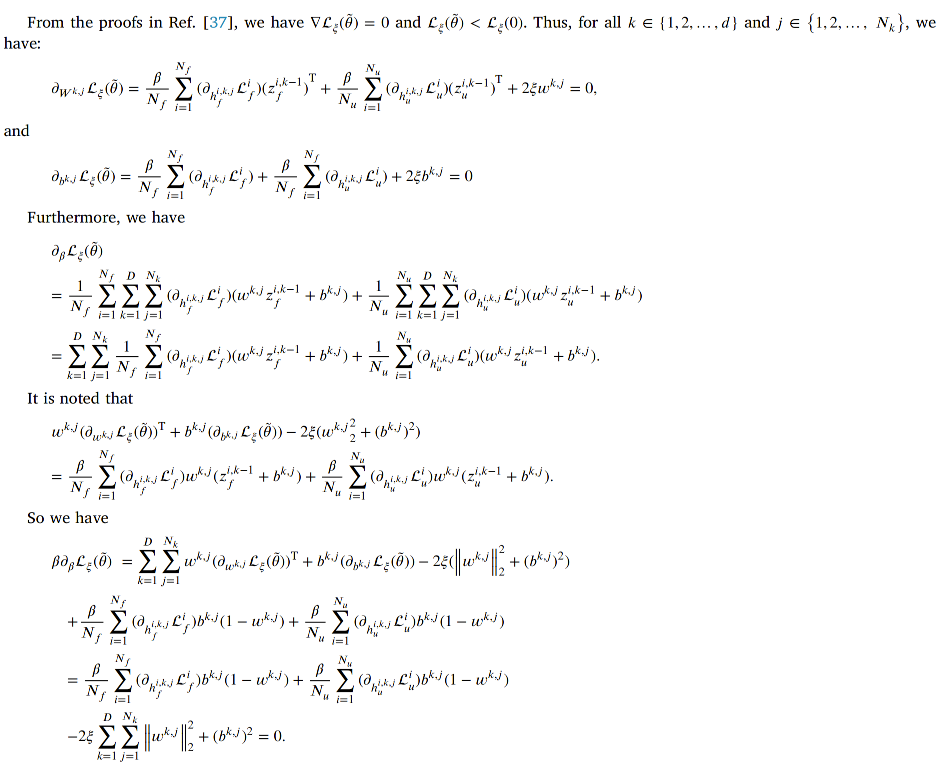

3.2. Adaptive loss function

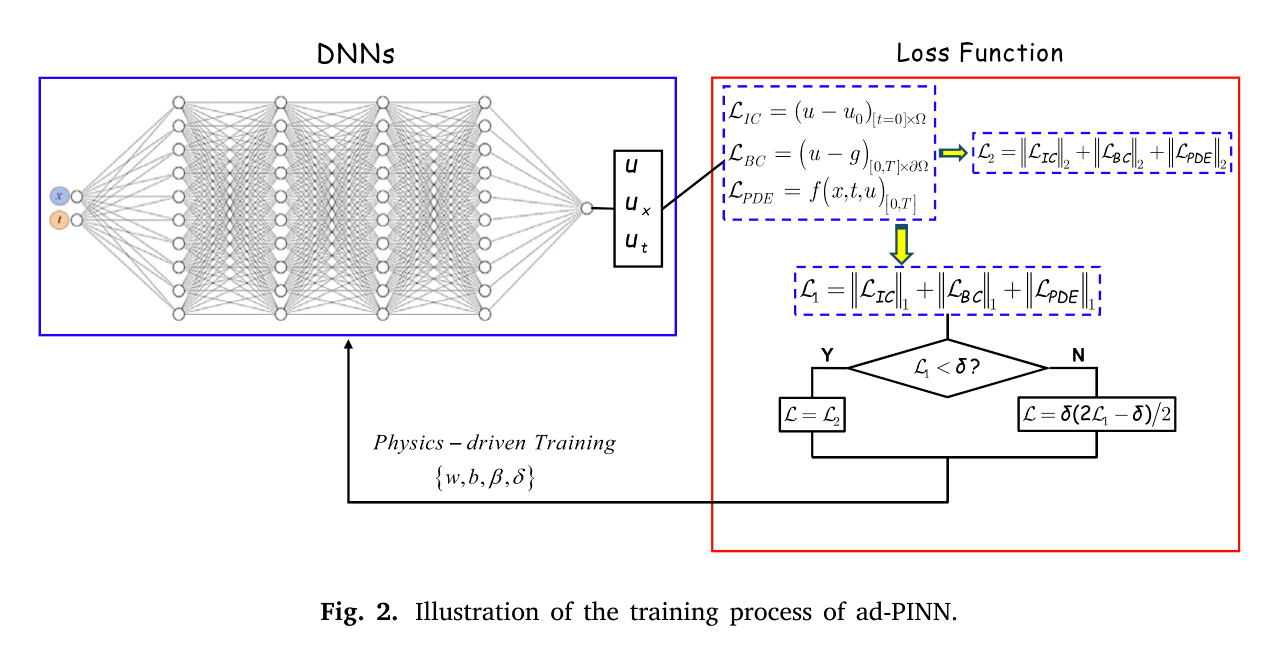
3.3. Adaptive deep PINN (ad-PINN)



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)