基于YOLOv8/YOLOv10/YOLOv11/YOLOv12与SpringBoot的猫狗品种检测系统(DeepSeek智能分析+web交互界面+前后端分离+YOLO数据)
摘要
本项目旨在设计并实现一个功能完备、高效精准的精细化猫狗品种智能检测与分析平台。系统核心采用目前最前沿的YOLO系列目标检测模型(包括YOLOv8、YOLOv10、YOLOv11及YOLOv12),构建了一个能够对37种特定猫狗品种(涵盖12种猫品种与25种狗品种)进行高精度识别的深度学习引擎。系统后端基于SpringBoot框架构建,遵循前后端分离的现代化架构模式,前端提供直观的Web交互界面,确保了系统的可维护性、可扩展性及良好的用户体验。
该系统不仅仅是一个基础的检测工具,更是一个集成了数据管理、智能分析与用户交互的综合平台。核心功能包括:支持图像、视频流及摄像头实时流的全方位检测模式;集成DeepSeek大型语言模型的智能分析模块,为检测结果提供丰富的背景解读;完整的数据可视化看板,直观展示检测统计与模型性能;以及一个健全的用户管理体系,涵盖用户注册登录、个人信息管理及管理员后台管控。所有检测记录与用户数据均持久化存储于MySQL数据库中,实现了全流程的数据追溯与管理。
通过对比集成多个迭代版本的YOLO模型,本项目不仅提供了一个实用的宠物识别应用,也为目标检测模型在细粒度分类任务上的性能比较与选型提供了实践依据。系统最终实现了一个从算法到应用、从数据到洞察的完整闭环,展示了深度学习技术与Web工程化开发相结合解决实际问题的巨大潜力。
详细功能展示视频
基于YOLO和千问|DeepSeek的猫狗品种检测系统(web+YOLOv8/YOLOv10/YOLOv11/YOLOv12+深度学习+python)_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1hwctzUECV/
目录
一、引言
1.1 项目背景与研究意义
随着社会经济的发展与人们生活水平的提高,宠物(尤其是猫和狗)在家庭中的陪伴角色日益重要,宠物相关产业呈现出蓬勃发展的态势。在此背景下,对宠物品种的精准识别需求应运而生,其应用场景广泛,包括:宠物智能护理、宠物保险定损、流浪动物管理、宠物社交平台、以及兽医辅助诊断等。传统的人工识别方式依赖专业知识,效率低下且存在主观性,难以满足大规模、实时化的应用需求。
近年来,深度学习,特别是基于卷积神经网络的目标检测技术,在图像识别领域取得了革命性突破。YOLO系列算法以其“单阶段”检测、速度快、精度高的特点,成为实时目标检测的标杆。从YOLOv8到最新提出的YOLOv12,每一代都在网络结构、训练策略和损失函数上进行了优化,追求精度与速度的更好平衡。然而,将这些前沿算法从实验室研究转化为稳定、易用的实际应用,仍面临工程化集成、系统构建和用户交互等多重挑战。
同时,通用大语言模型的发展为人工智能应用增添了新的维度。将目标检测模型的“感知”能力与大语言模型的“认知”与“解释”能力相结合,可以创造出更具洞察力和交互性的智能系统。
因此,本研究项目“基于多版本YOLO模型与SpringBoot的精细化猫狗品种智能检测与分析系统” 具有重要的理论价值与实践意义:
-
技术实践意义:通过整合YOLOv8至YOLOv12四个版本的先进模型,项目为细粒度目标检测(Fine-Grained Visual Categorization)提供了一个可比较、可切换的实战平台,有助于探索不同模型在特定任务上的优劣。
-
工程应用价值:采用SpringBoot前后端分离架构,将深度学习模型成功封装为可远程调用的Web服务,完成了从算法模型到企业级应用的完整工程化落地,为同类AI应用开发提供了可复用的框架。
-
功能创新性:引入DeepSeek大模型进行AI分析,将单纯的品种标签输出升级为包含品种特性、习性介绍等内容的智能报告,极大提升了系统的实用价值和用户体验。
-
管理智能化:通过完整的数据可视化与记录管理功能,系统能够积累宝贵的检测数据,为后续的数据分析、模型迭代优化及商业决策提供支持。
1.2 项目主要内容与目标
本项目旨在构建一个集“前沿算法、工程实践、智能交互、数据管理”于一体的综合性猫狗品种检测系统。主要目标与内容如下:
-
核心检测引擎构建:基于包含37个具体猫狗品种(总计13983张图像)的专业数据集,分别训练、优化并集成YOLOv8、YOLOv10、YOLOv11及YOLOv12标准版模型,形成系统可切换的核心检测能力池。
-
全栈Web系统开发:采用前后端分离架构。后端使用SpringBoot构建RESTful API,负责模型推理、业务逻辑处理、用户认证与数据持久化(MySQL)。前端使用现代Web技术(如Vue.js或React)开发响应式界面,提供友好的用户交互体验。
-
多元化检测模式支持:系统需支持三种输入模式:
-
图片检测:用户上传图片进行异步识别。
-
视频检测:对上传的视频文件进行逐帧分析,并生成标注后的结果视频。
-
实时摄像头检测:通过浏览器调用用户摄像头,实现实时流媒体检测与反馈。
-
-
DeepSeek智能分析增强:在检测到目标并识别出品种后,系统调用DeepSeek API,自动生成关于该品种的起源、体型、性格特点、护理要点等扩展性文本描述,使结果更具信息量和趣味性。
-
全面的数据管理与可视化:
-
记录管理:所有检测任务(图片、视频、实时)的结果、时间、使用模型等信息均保存至数据库,并提供按时间、模型、品种等条件的查询、浏览与删除功能。
-
数据看板:通过图表可视化,为系统运营提供直观洞察。
-
-
完善的用户系统:
-
实现用户注册、登录、个人中心(修改个人信息、头像、密码)。
-
实现管理员后台,对系统所有用户进行增删改查(CRUD)管理,确保系统的可管控性。
-
二、 系统核心特性概述
功能模块
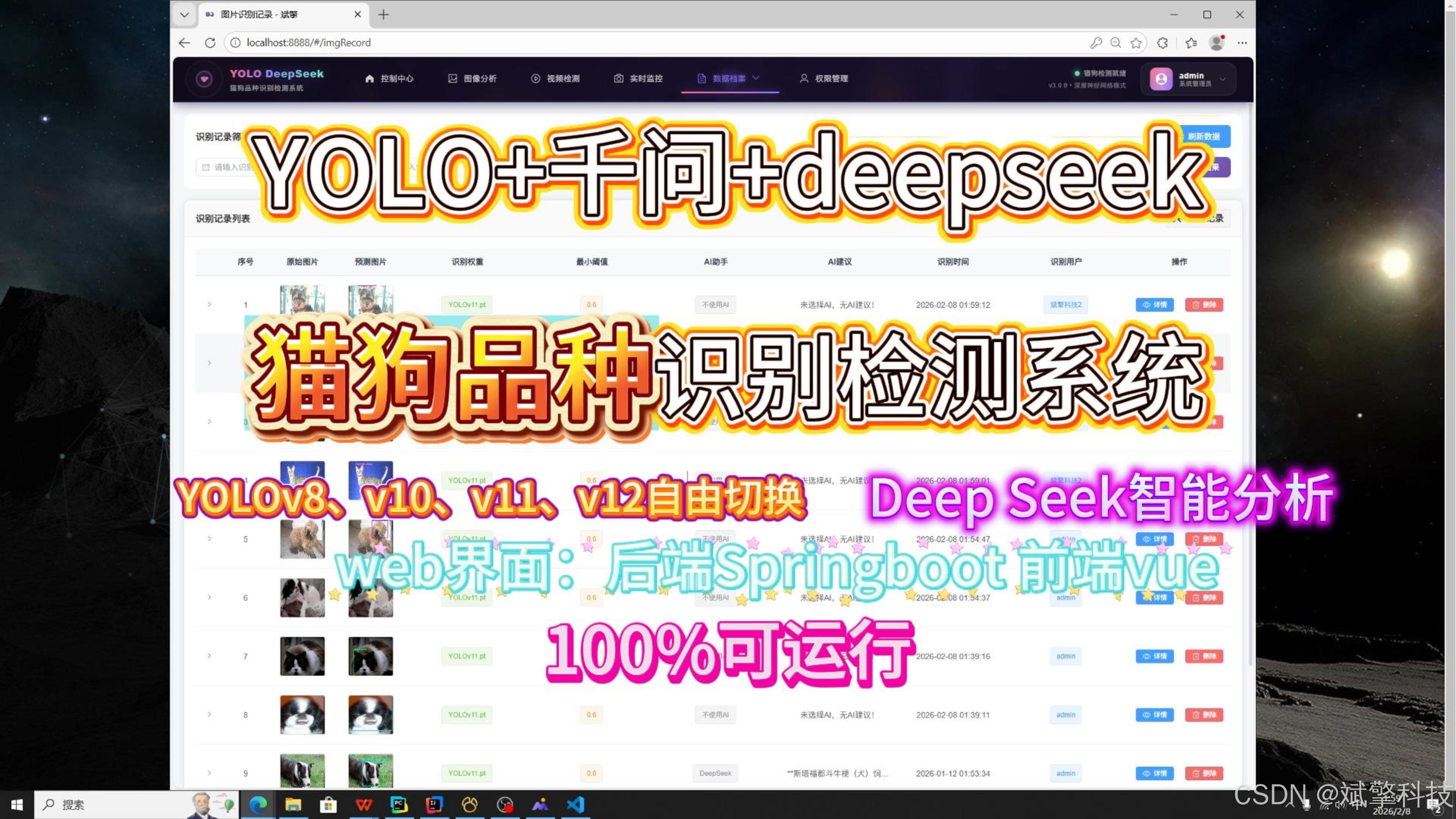
✅ 用户登录注册:支持密码检测,保存到MySQL数据库。
✅ 支持四种YOLO模型切换,YOLOv8、YOLOv10、YOLOv11、YOLOv12。
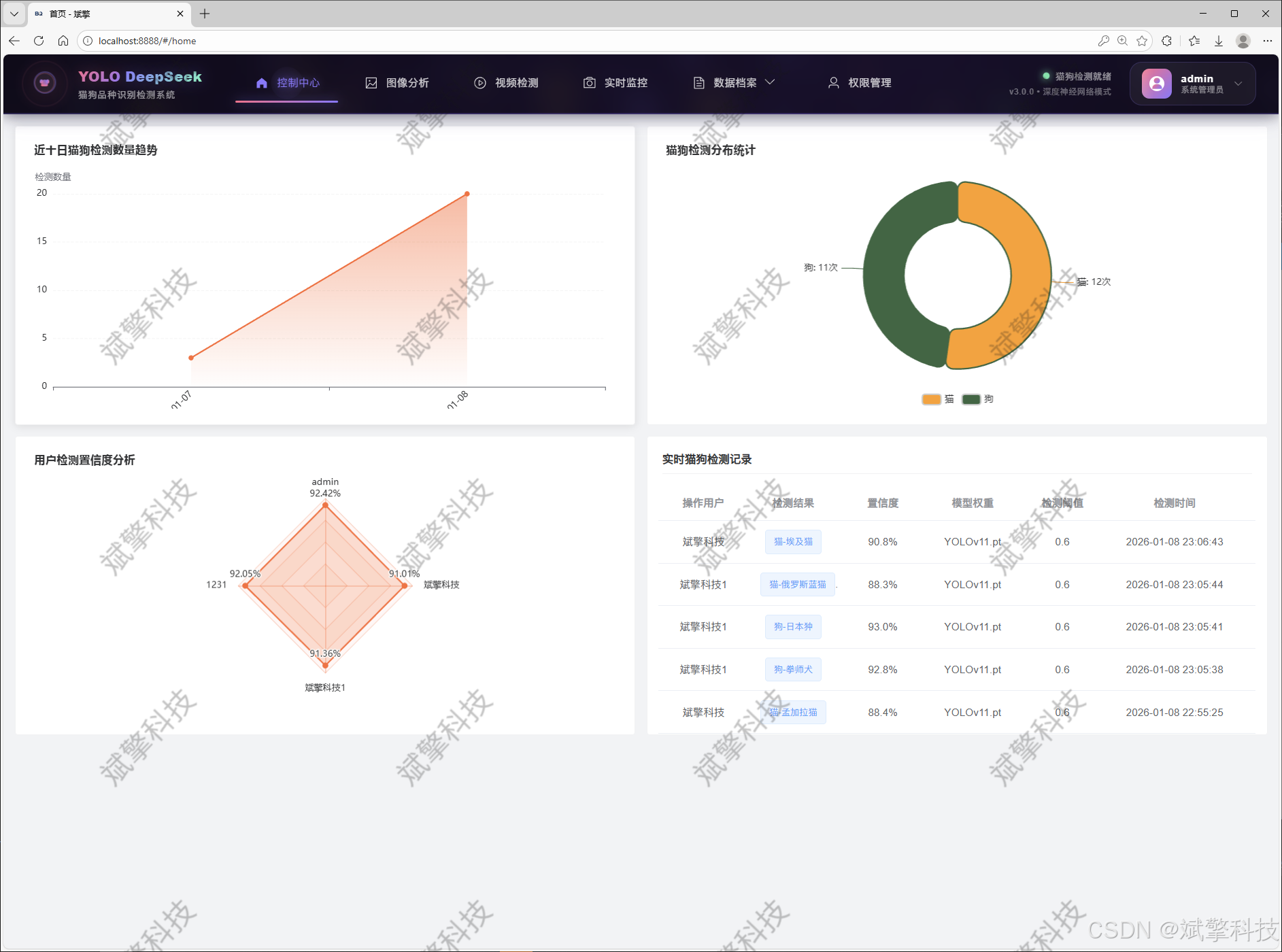
✅ 信息可视化,数据可视化。
✅ 图片检测支持AI分析功能,deepseek
✅ 支持图像检测、视频检测和摄像头实时检测,检测结果保存到MySQL数据库。
✅ 图片识别记录管理、视频识别记录管理和摄像头识别记录管理。
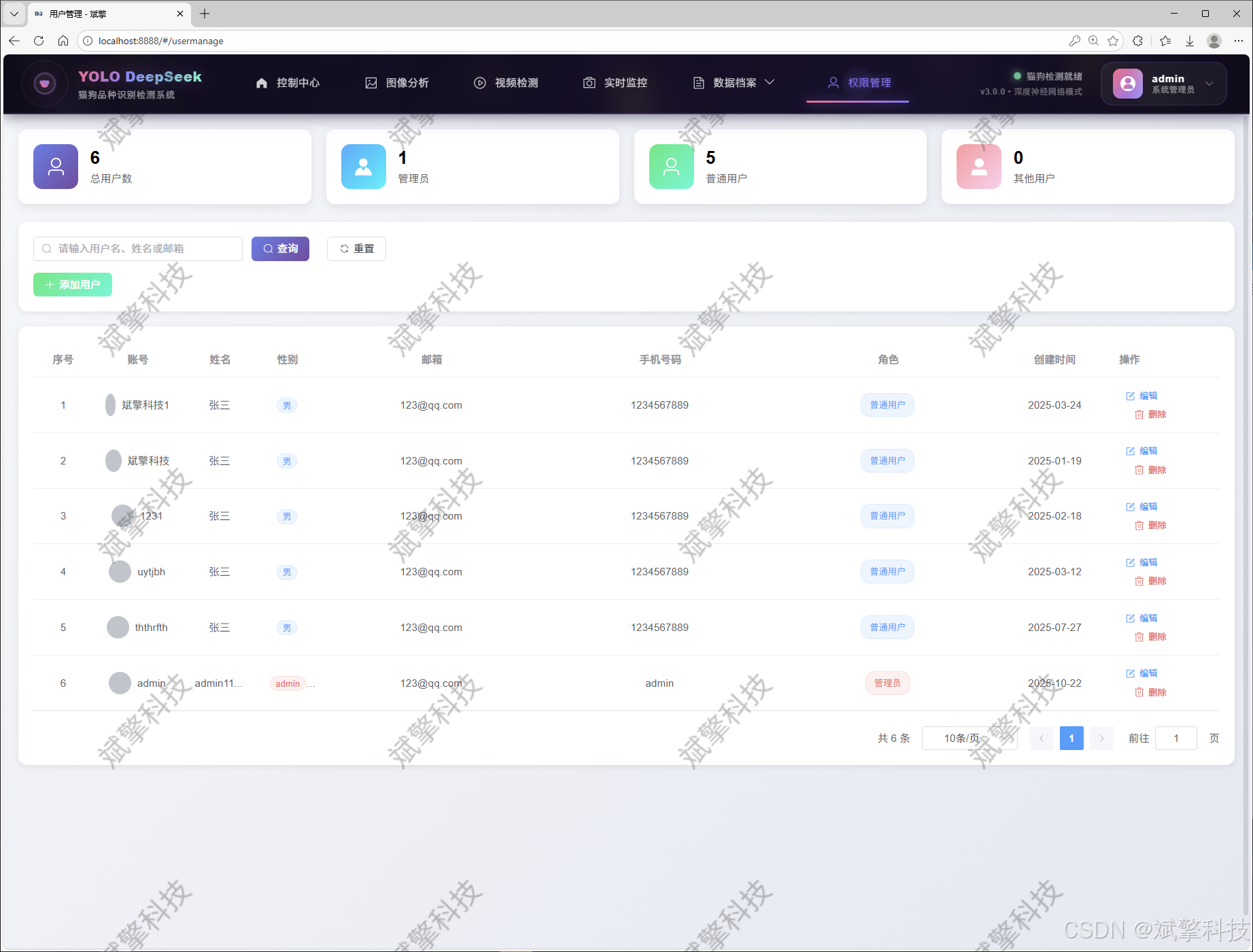
✅ 用户管理模块,管理员可以对用户进行增删改查。
✅ 个人中心,可以修改自己的信息,密码姓名头像等等。
登录注册模块
可视化模块
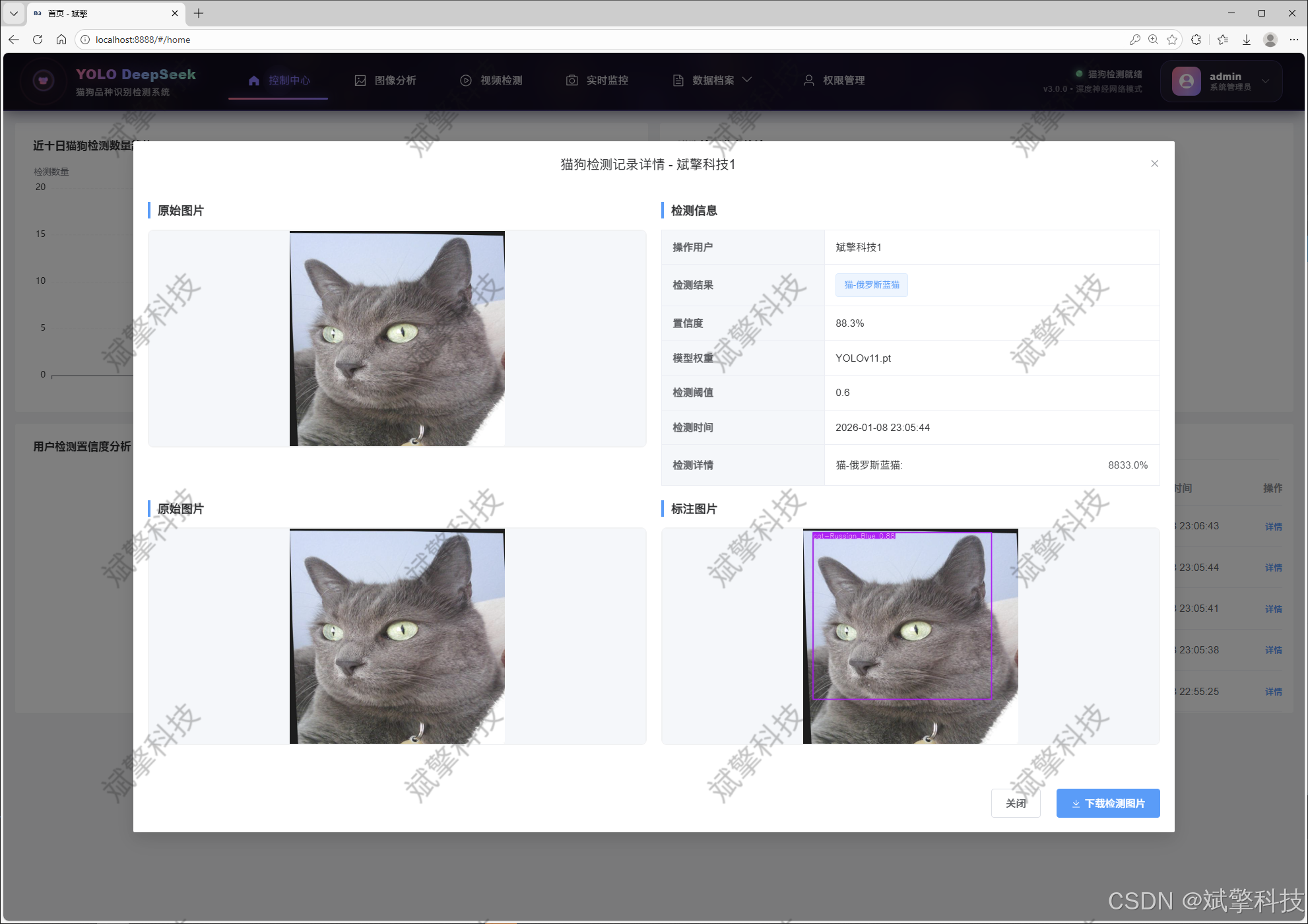
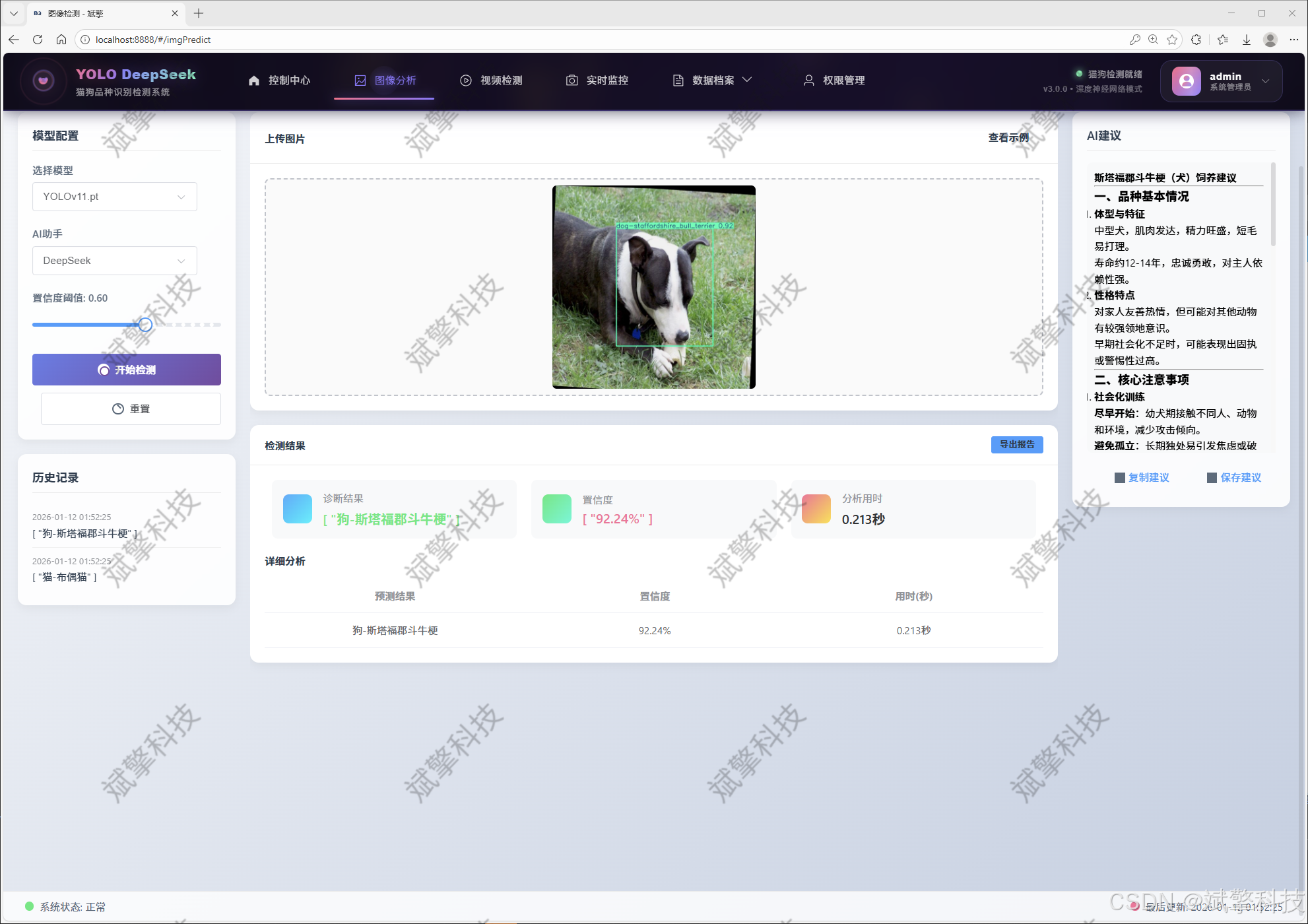
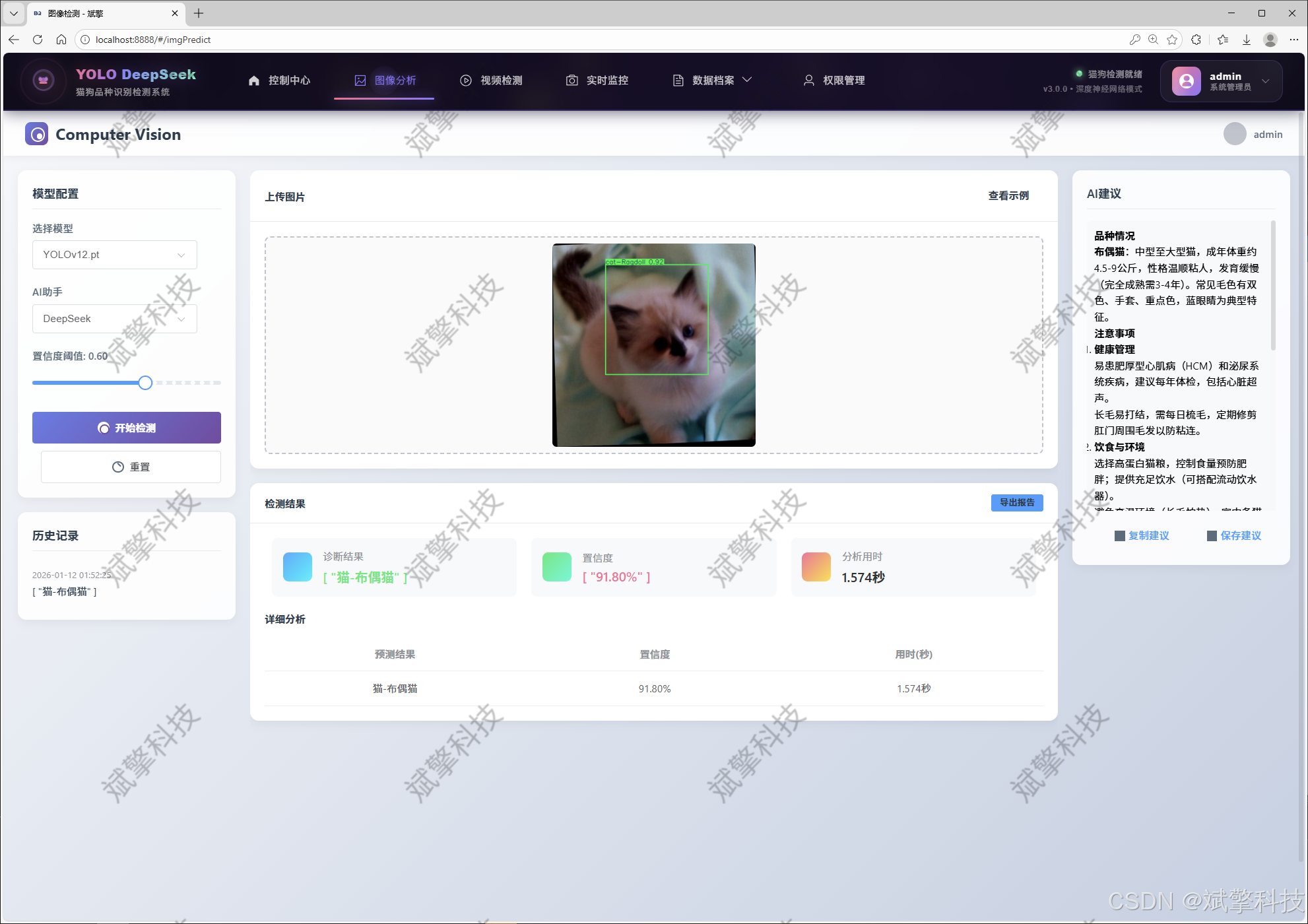
图像检测模块
-
YOLO模型集成 (v8/v10/v11/v12)
-
DeepSeek多模态分析
-
支持格式:JPG/PNG/MP4/RTSP
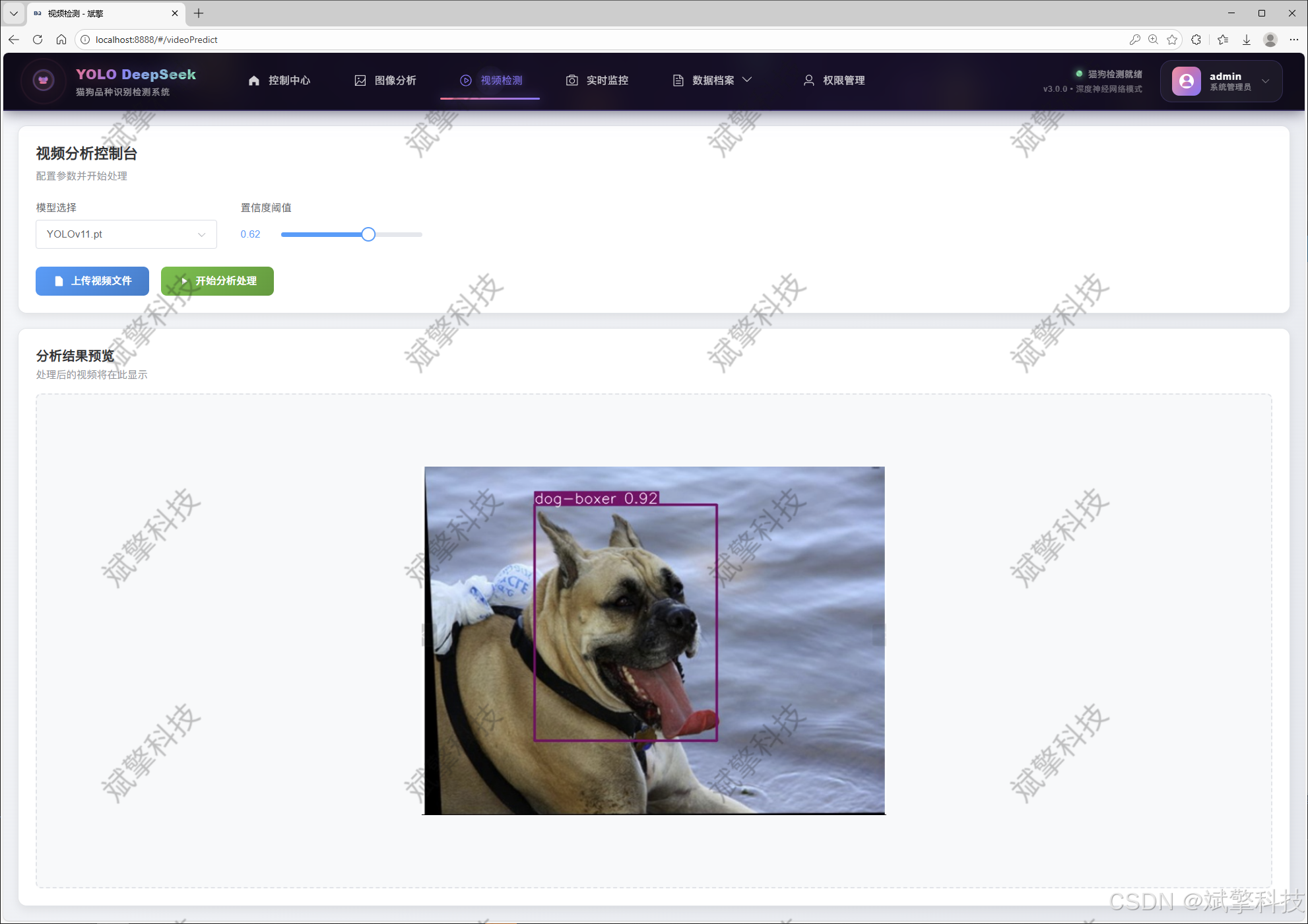
视频检测模块
实时检测模块
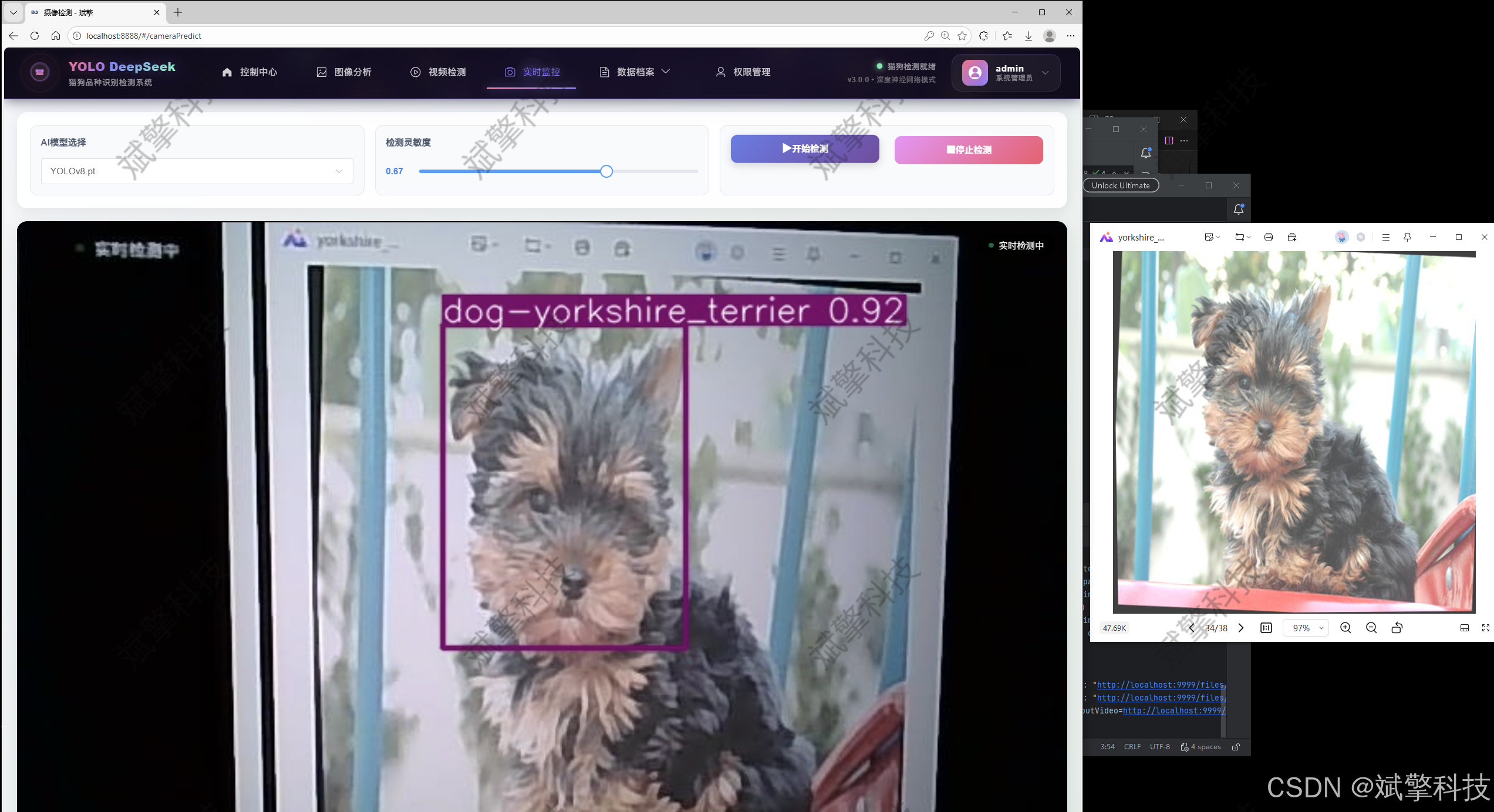
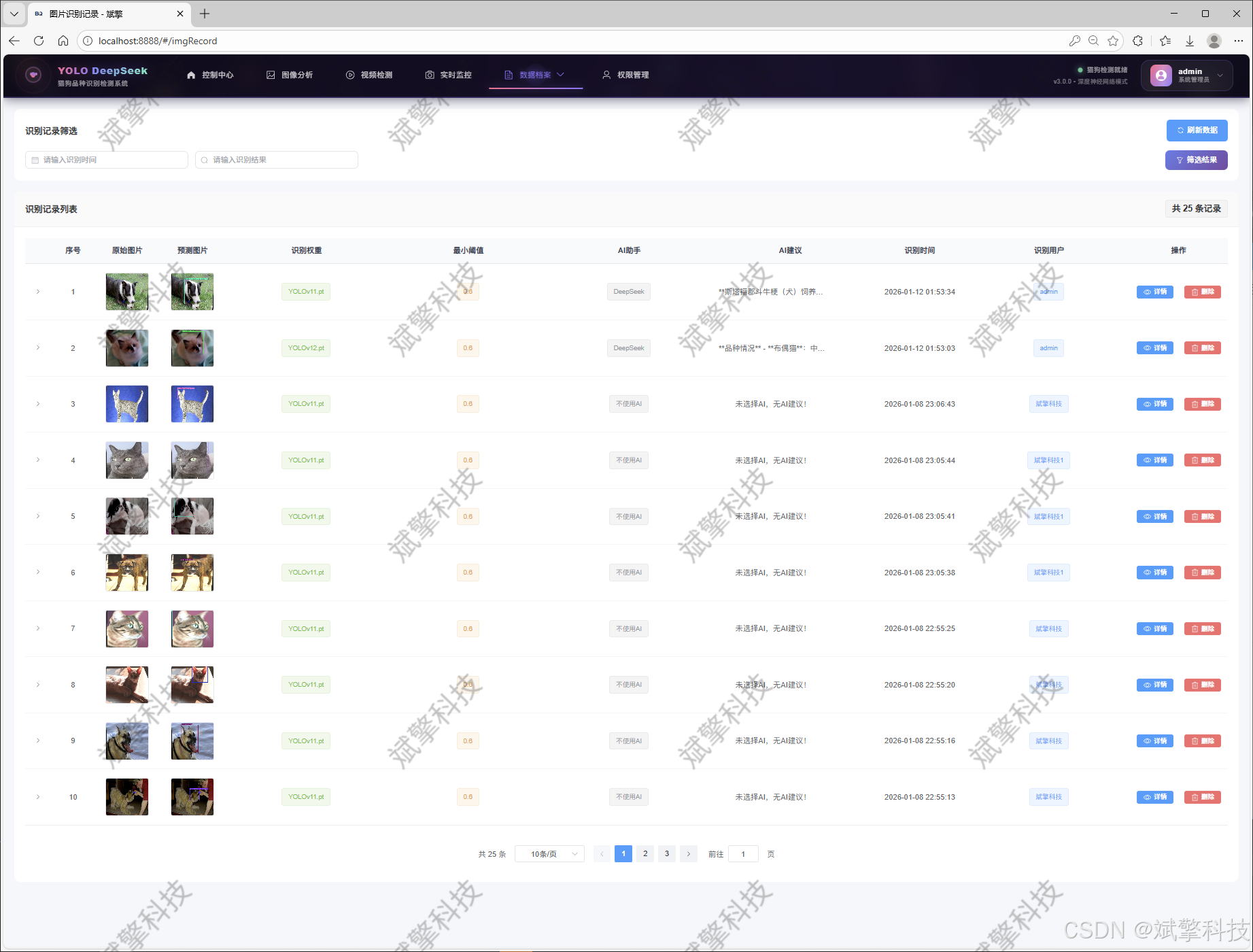
图片识别记录管理
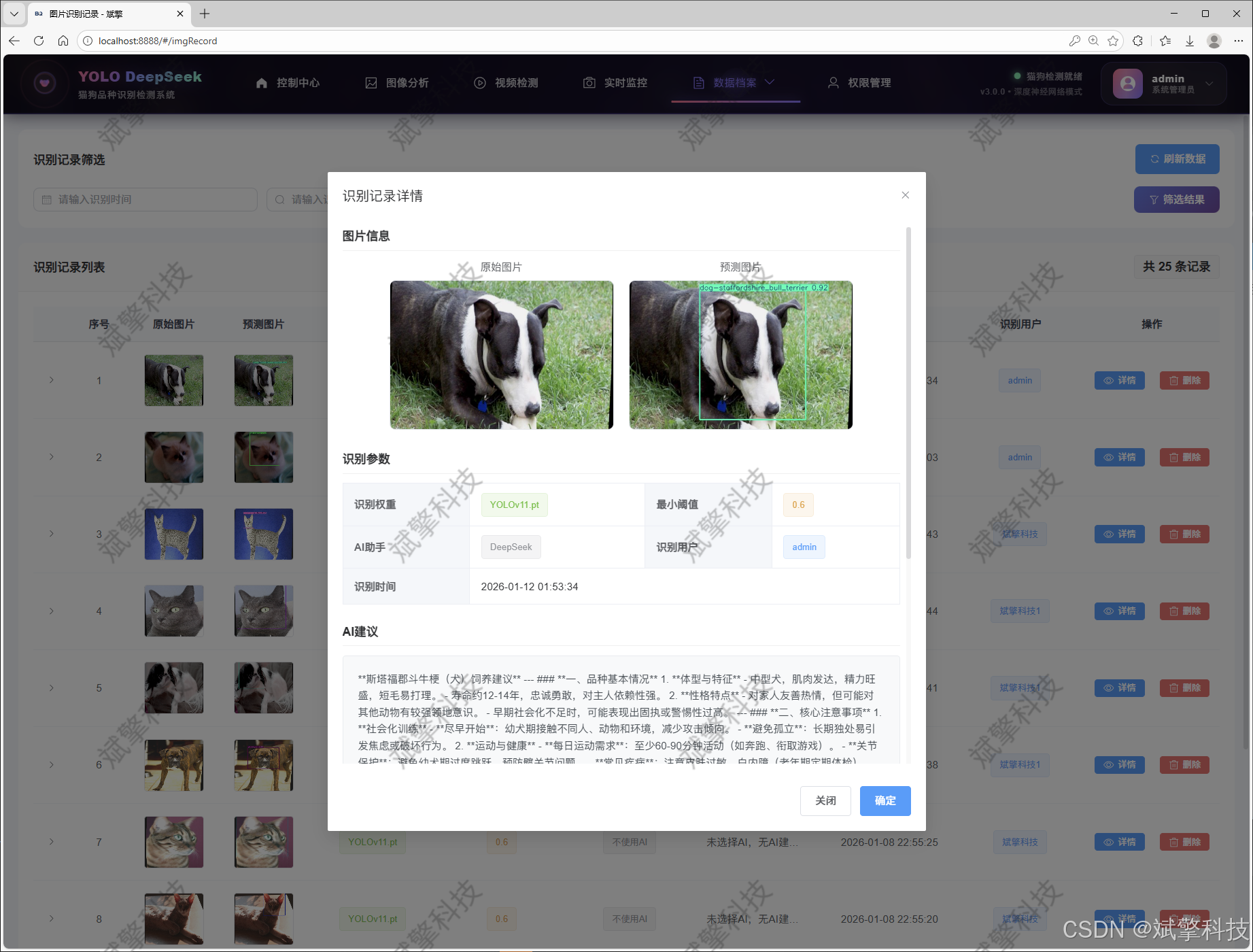
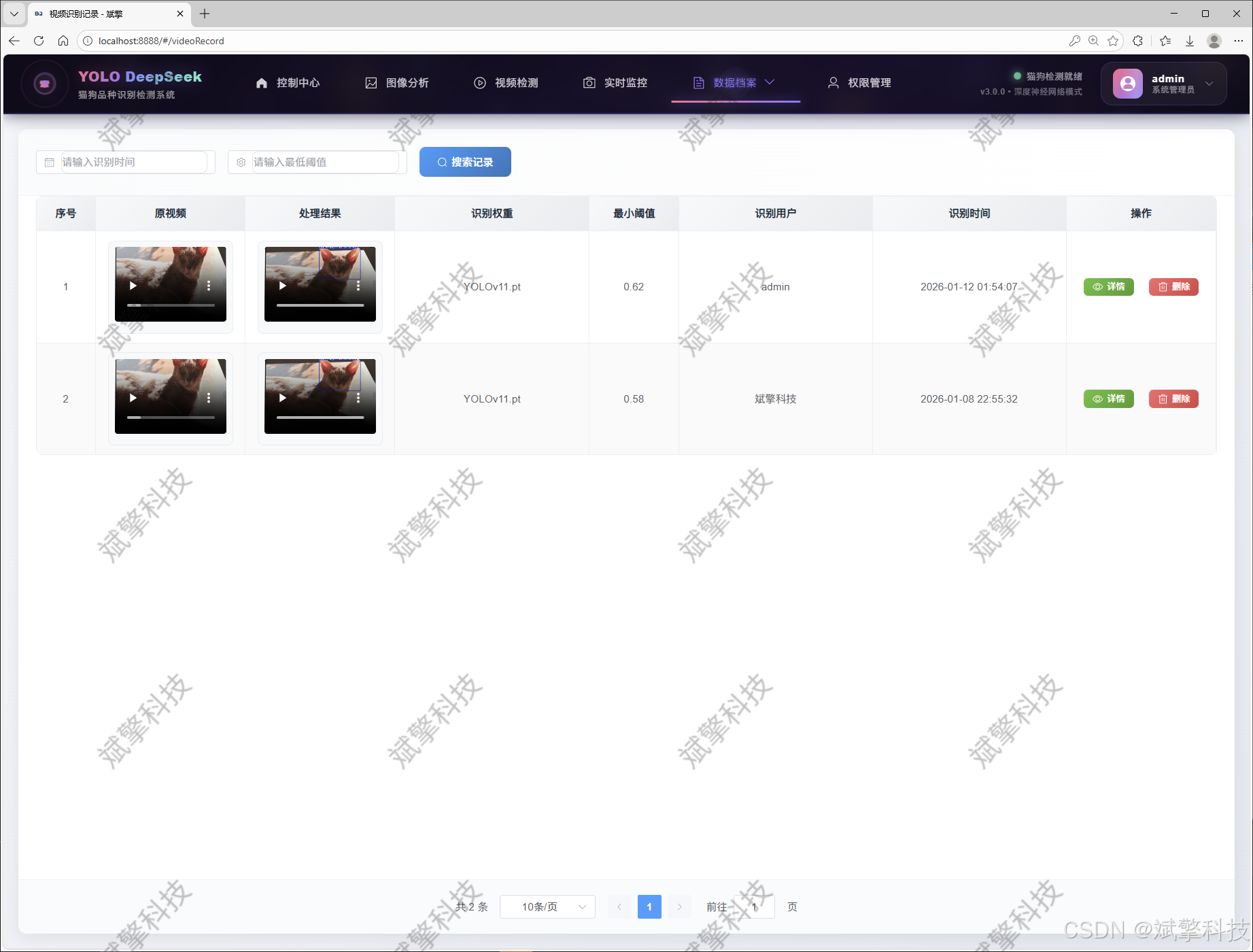
视频识别记录管理
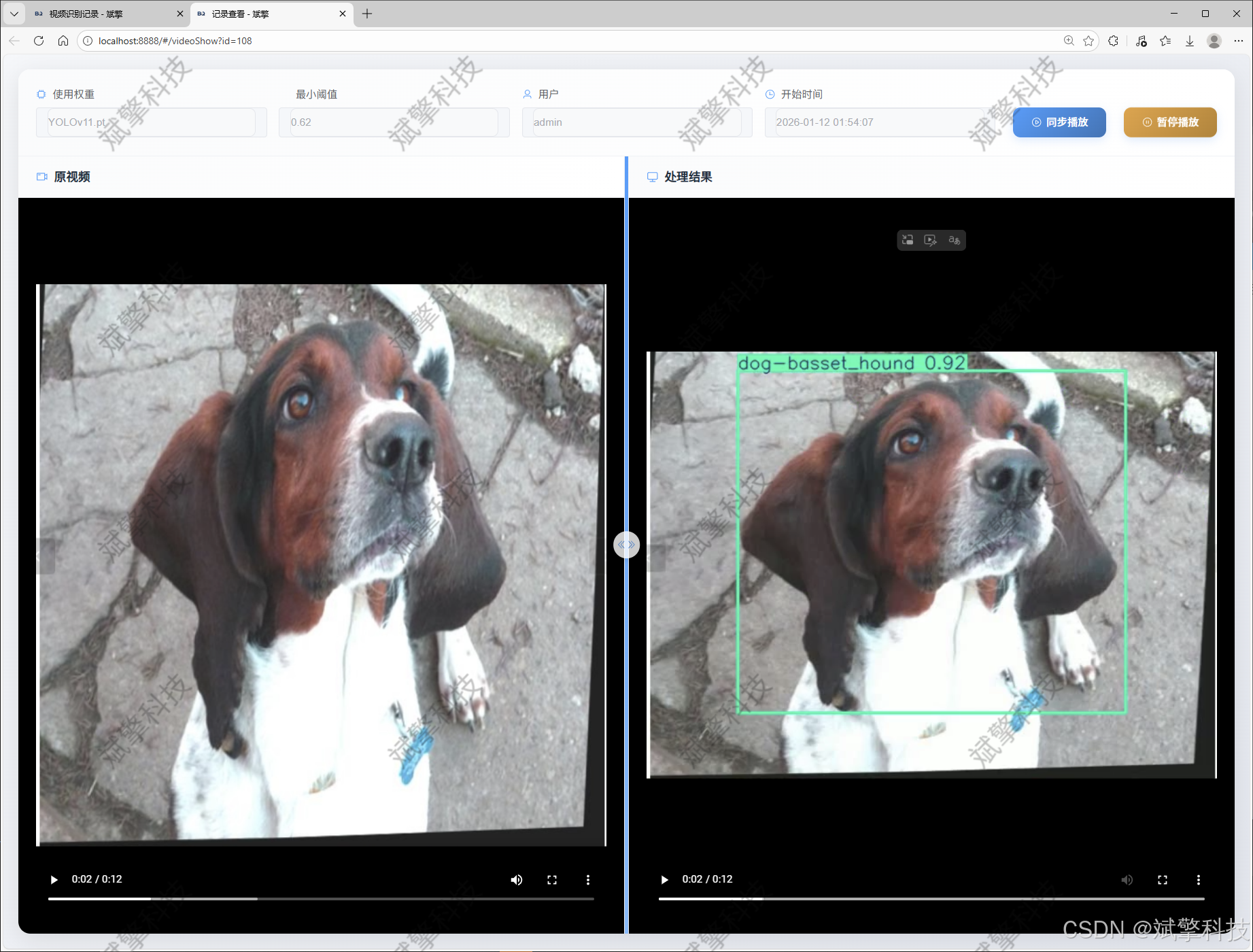
摄像头识别记录管理
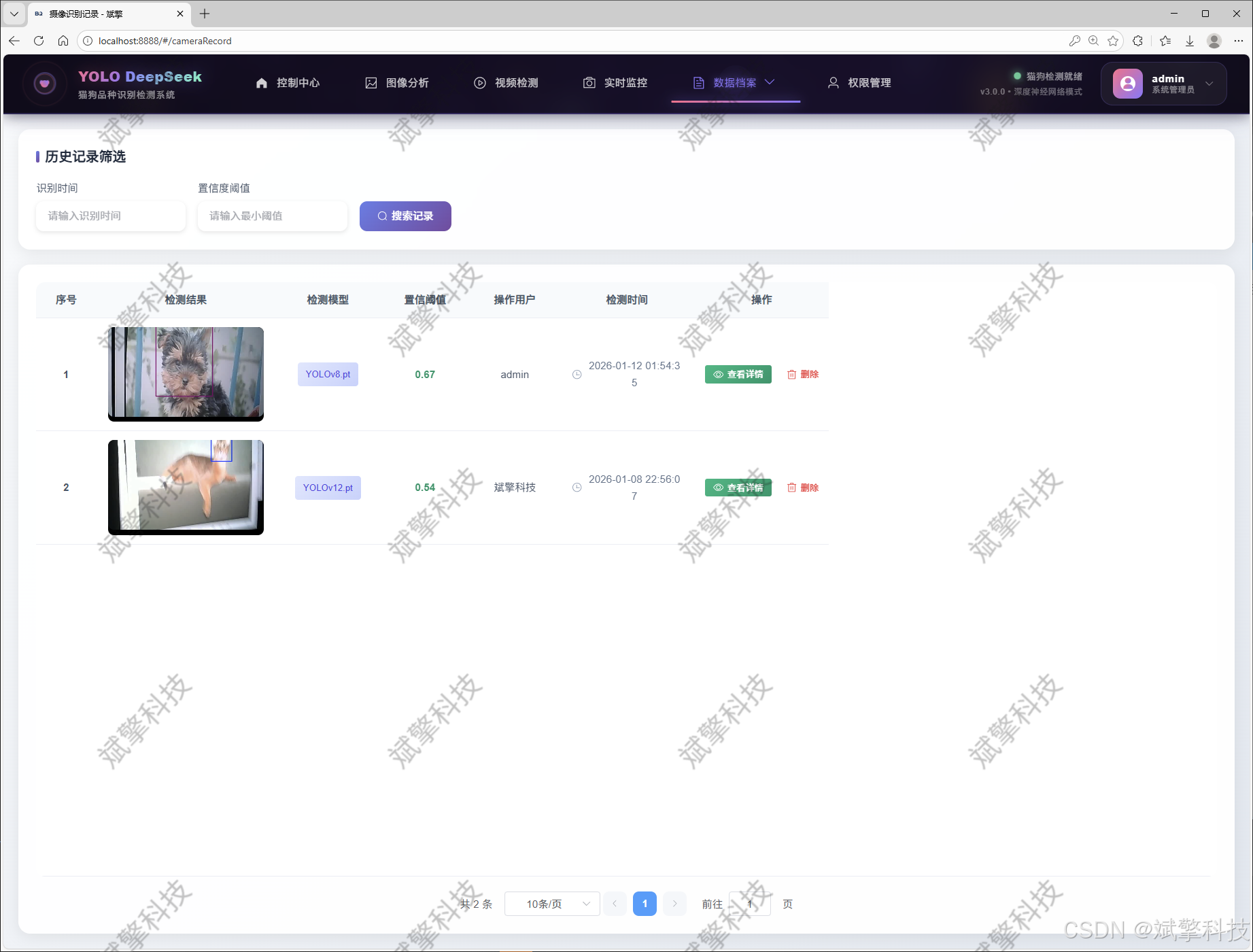
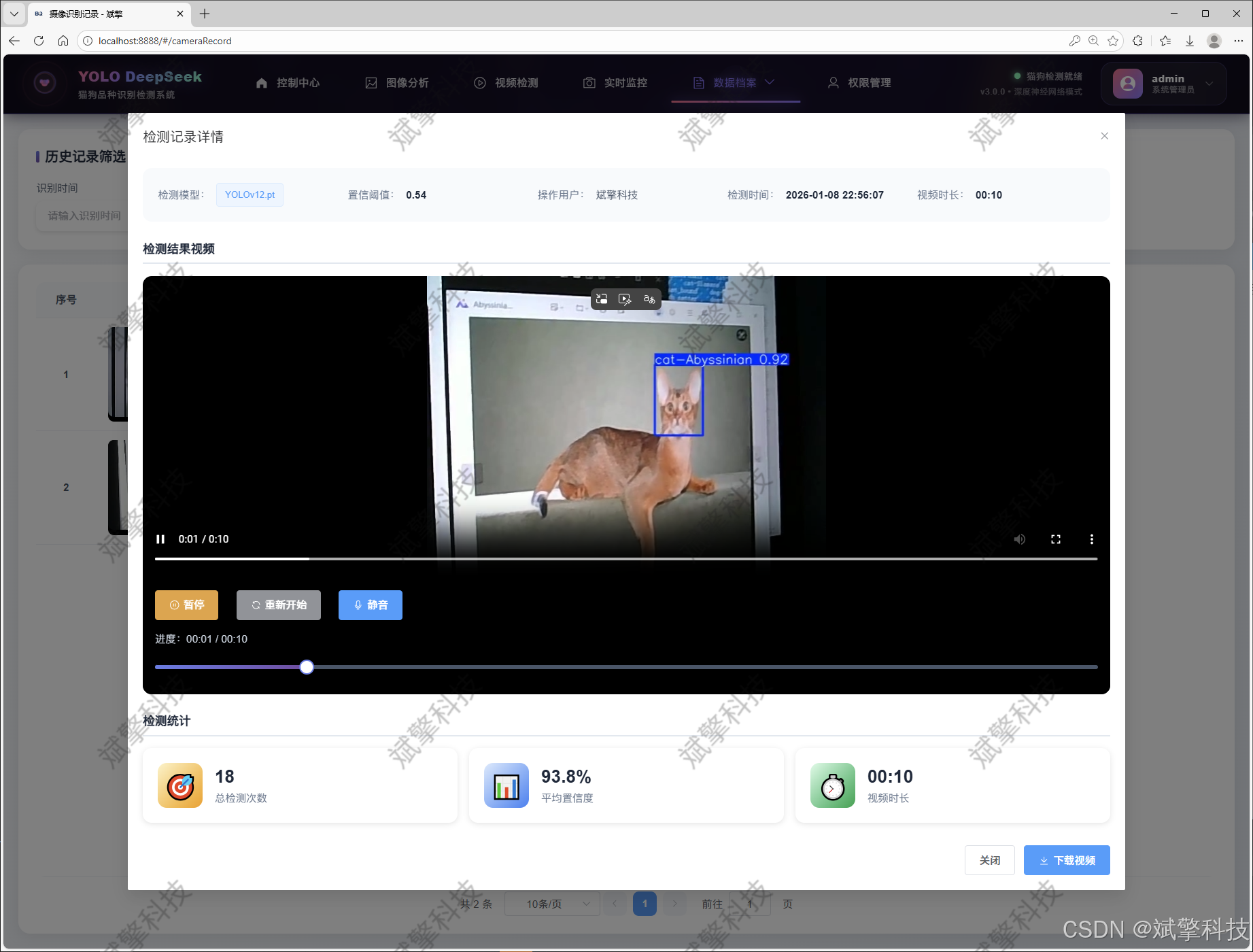
用户管理模块
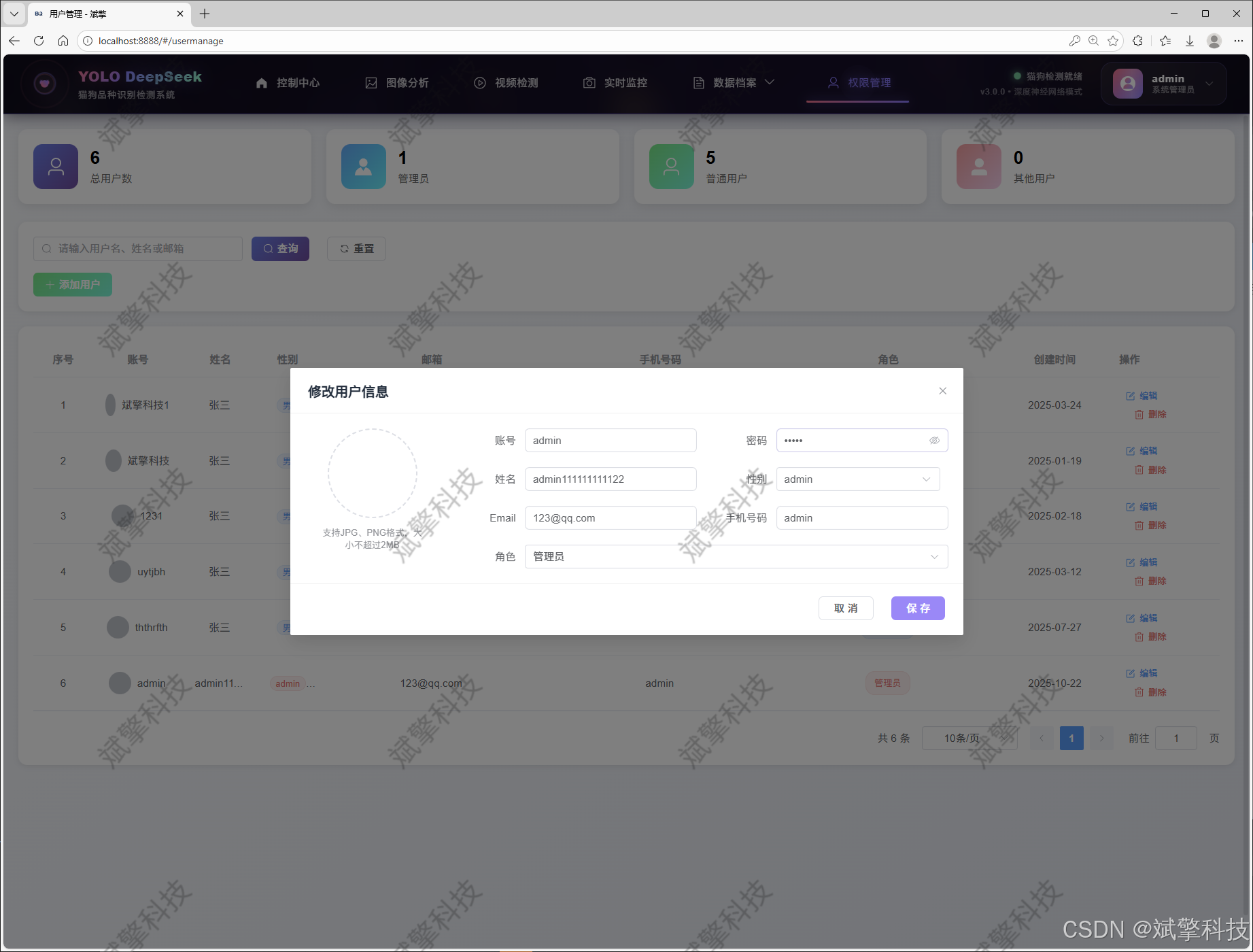
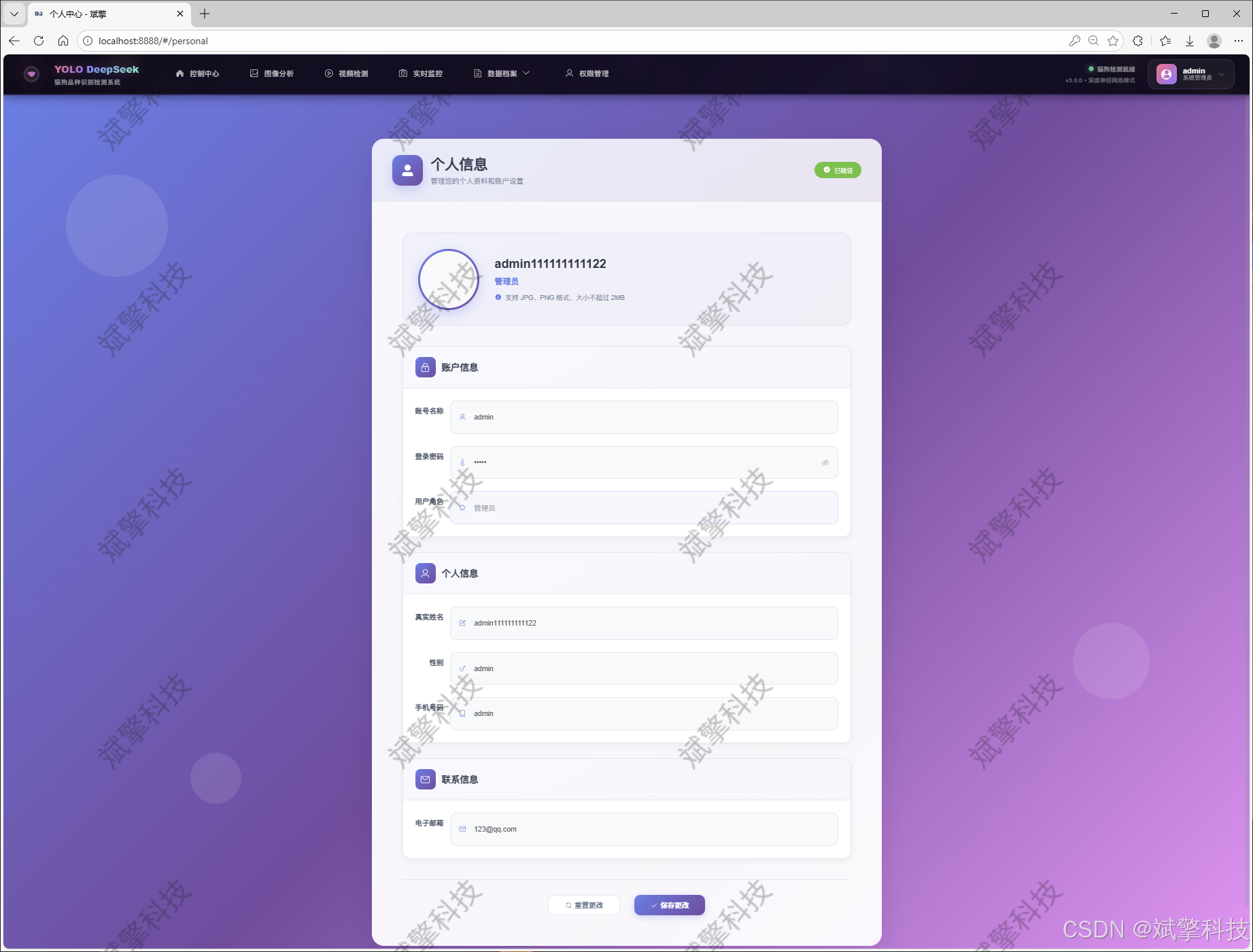
数据管理模块(MySQL表设计)
-
users- 用户信息表

-
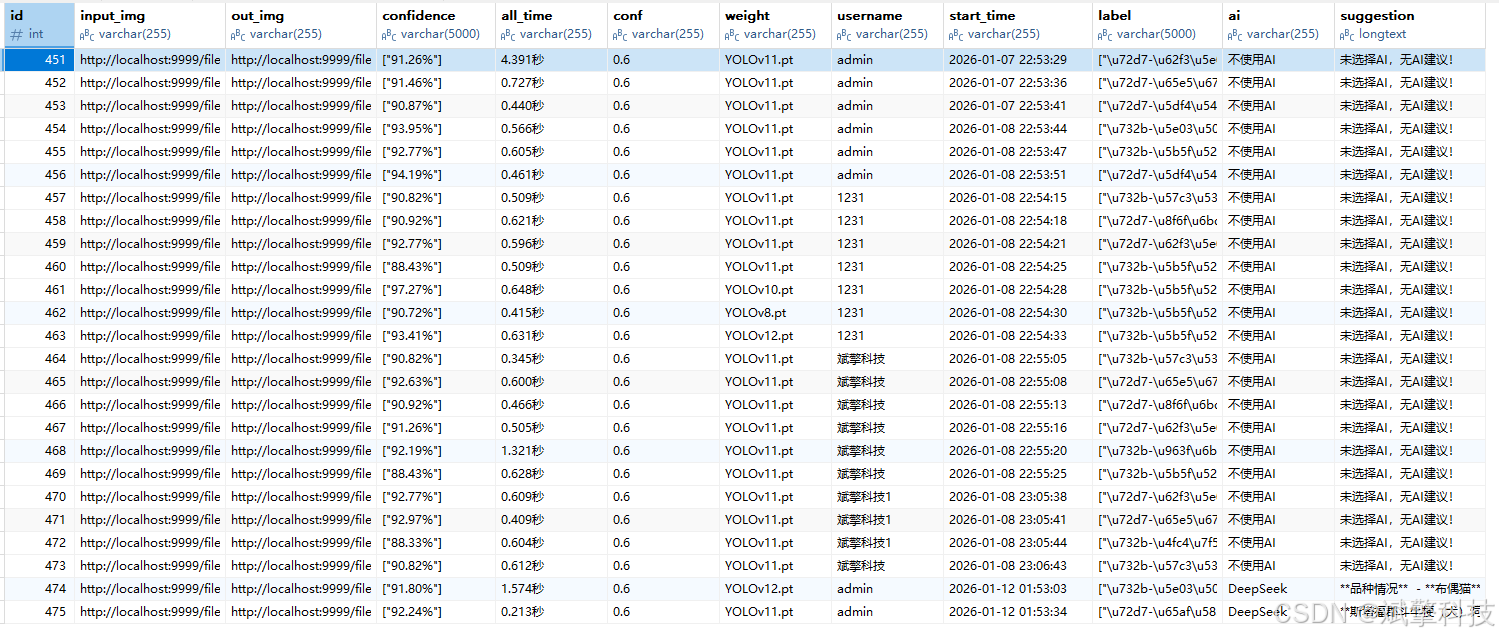
imgrecords- 图片检测记录表
-
videorecords- 视频检测记录表

-
camerarecords- 摄像头检测记录表

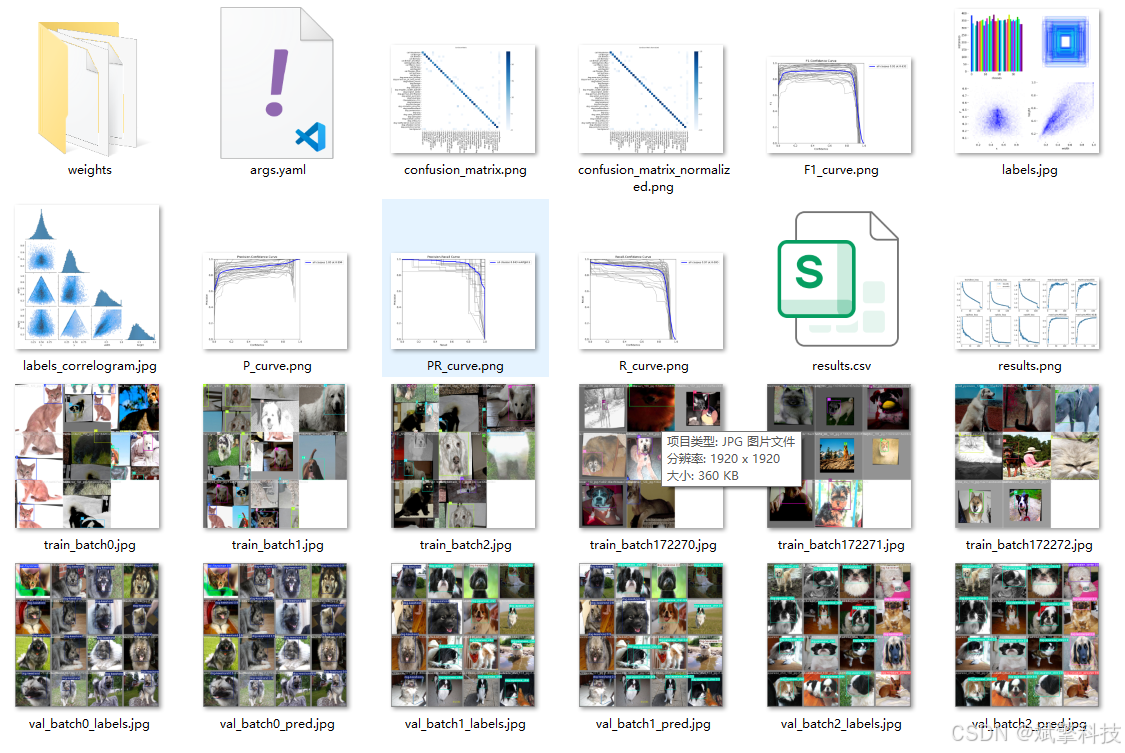
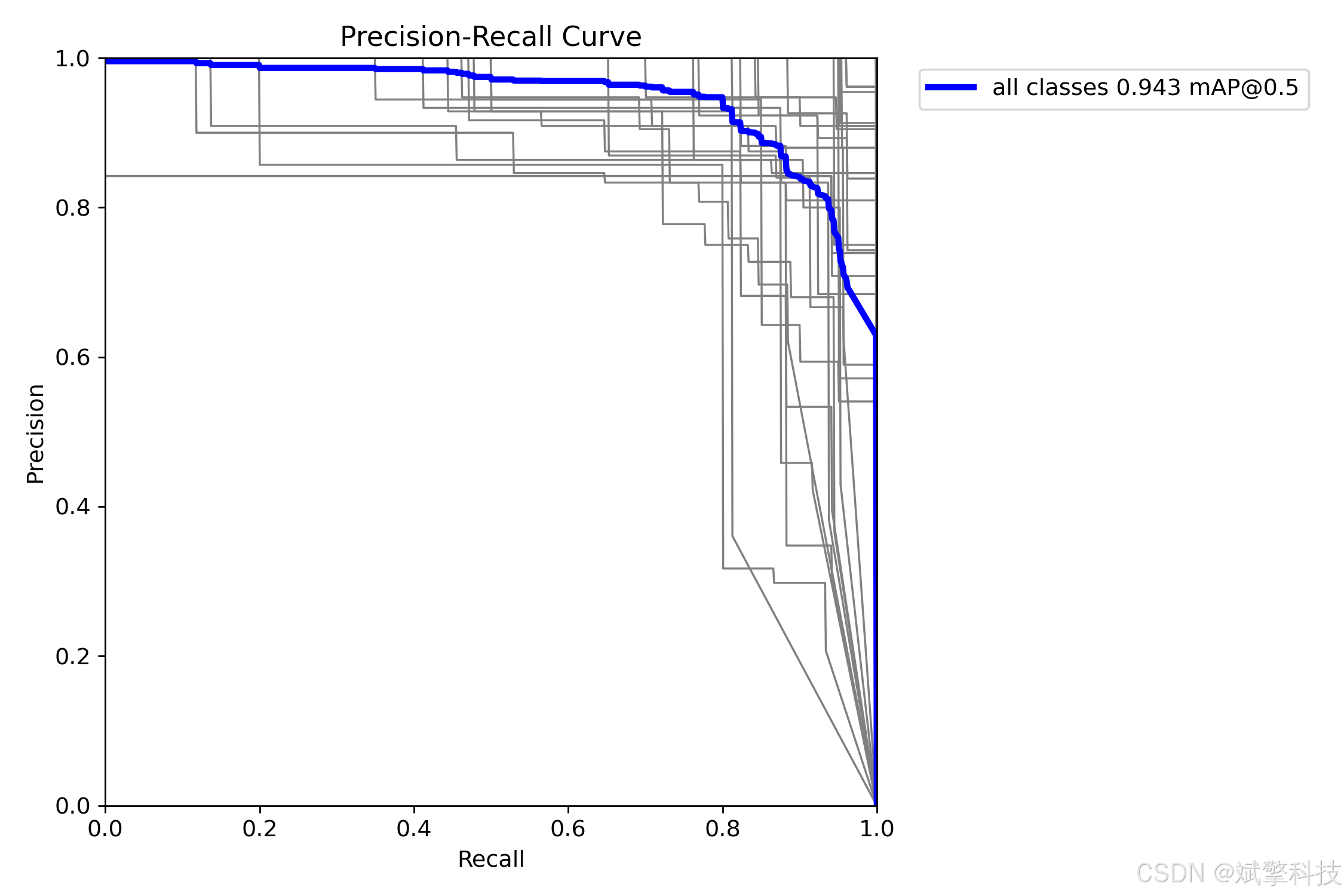
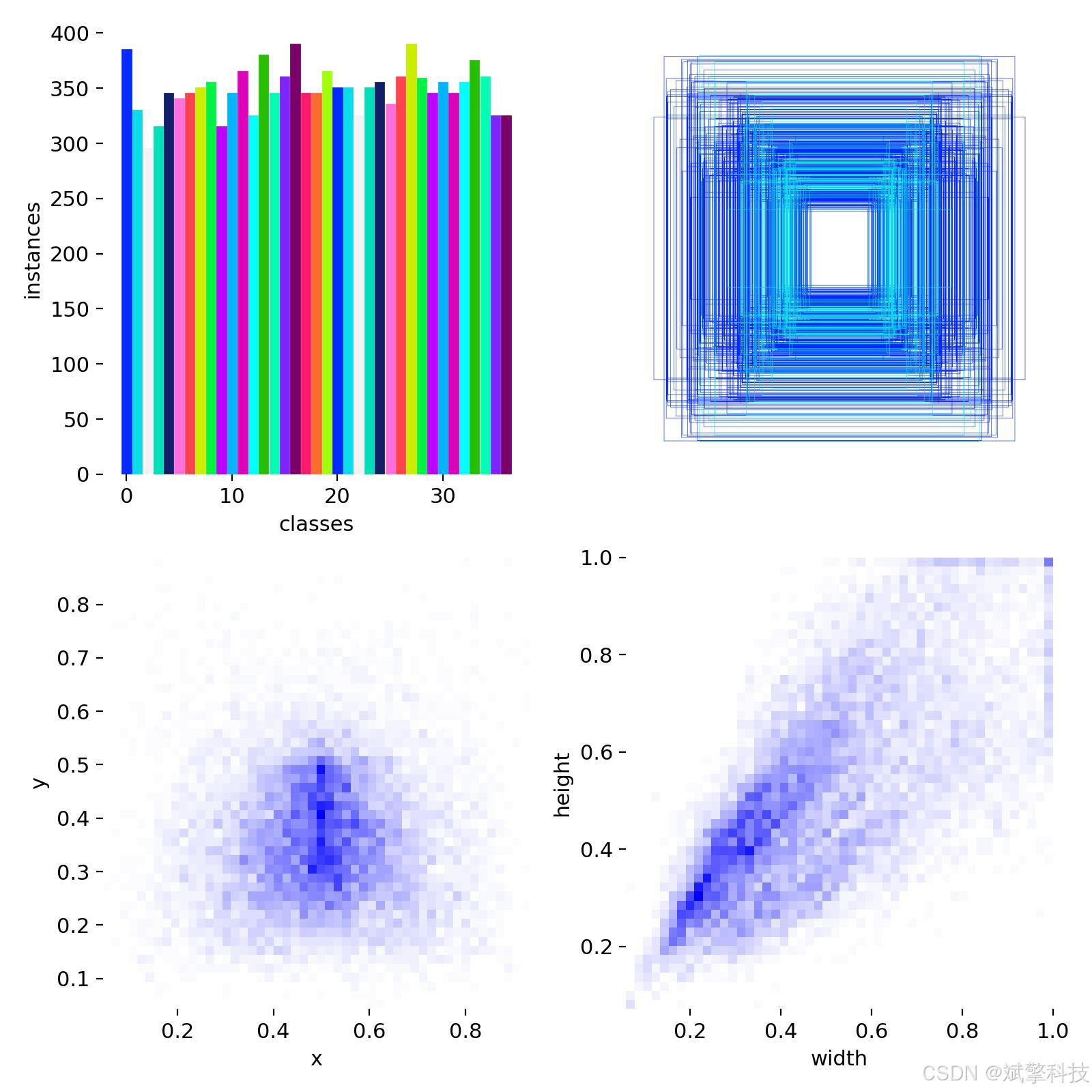
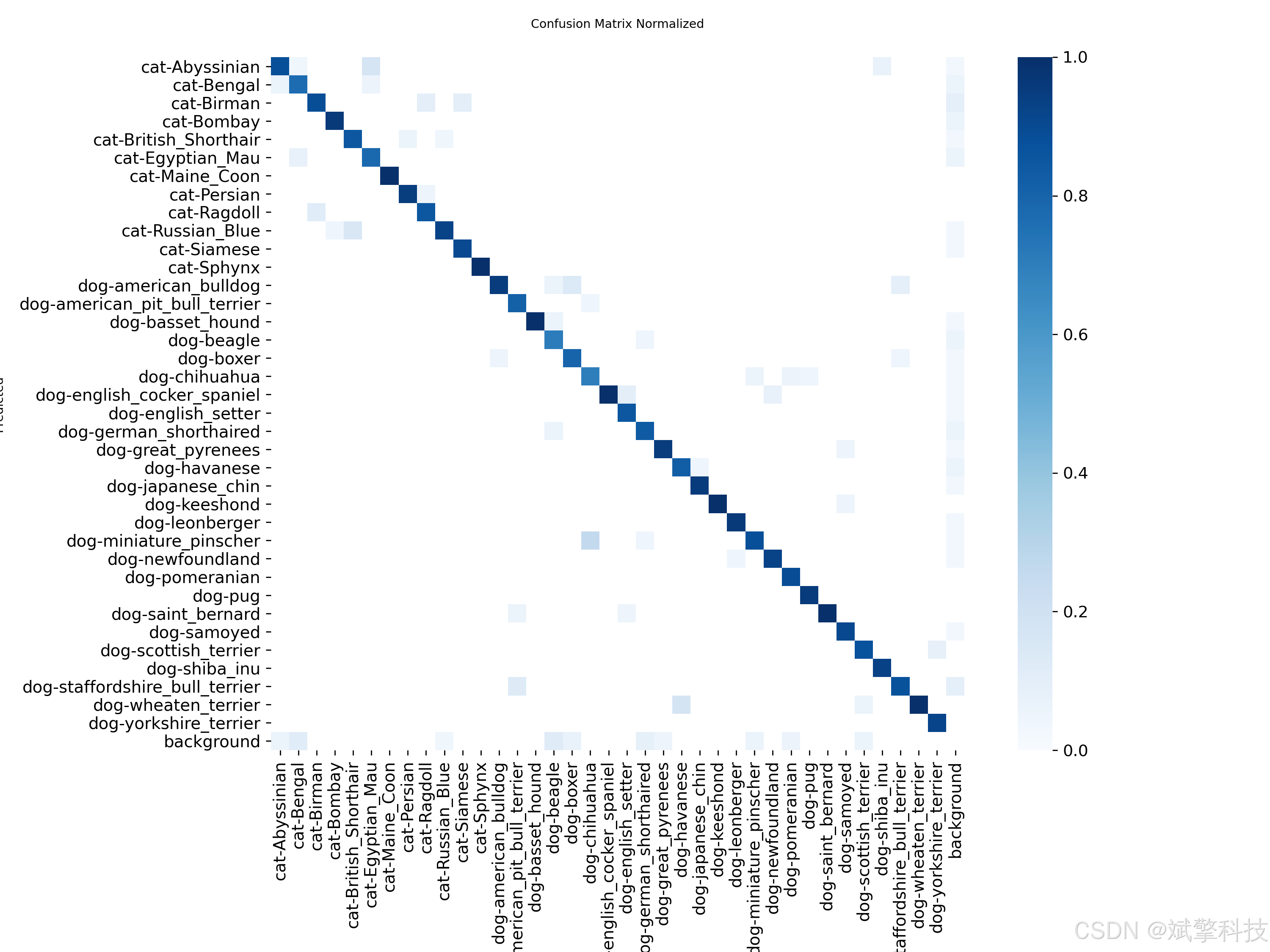
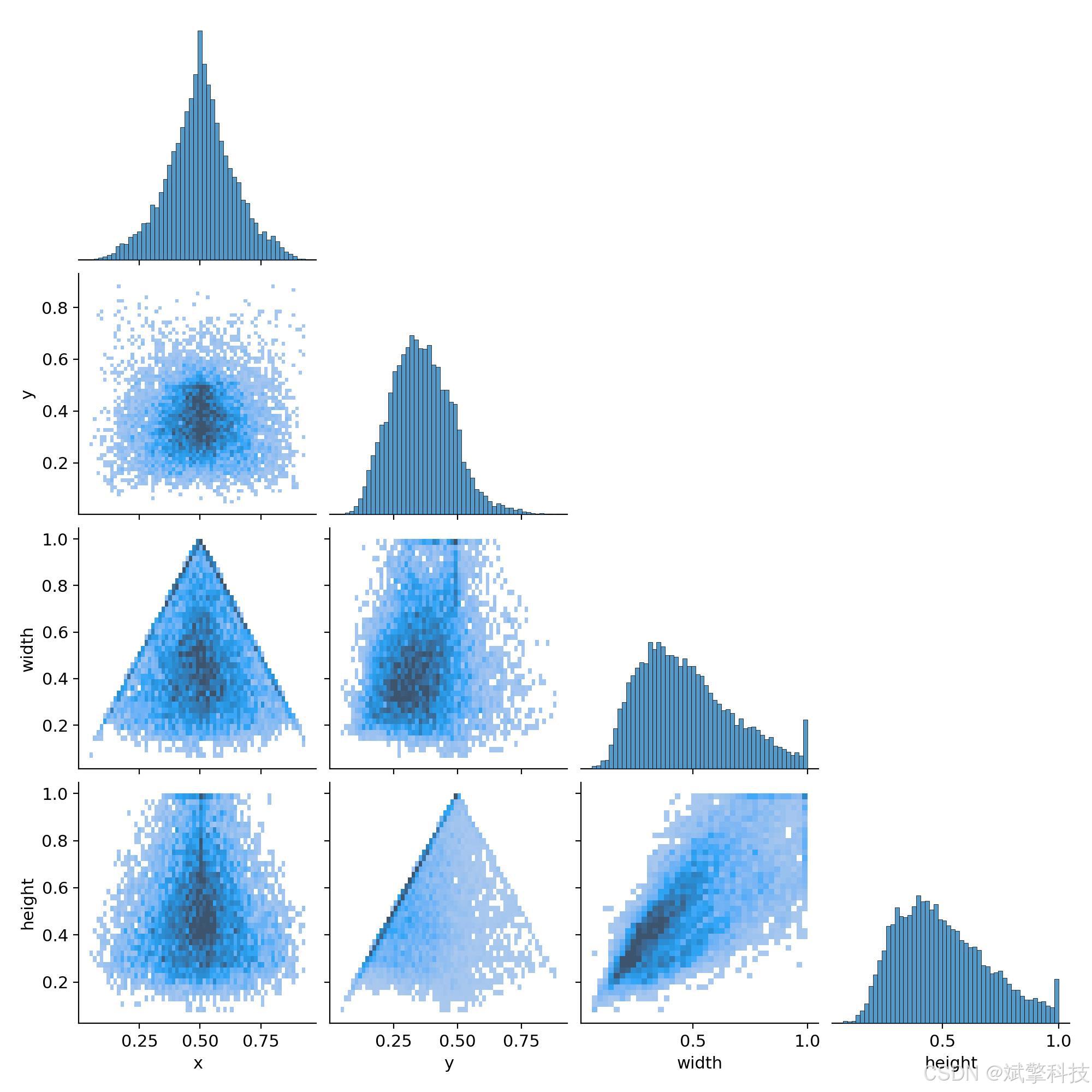
模型训练结果
#coding:utf-8
#根据实际情况更换模型
# yolon.yaml (nano):轻量化模型,适合嵌入式设备,速度快但精度略低。
# yolos.yaml (small):小模型,适合实时任务。
# yolom.yaml (medium):中等大小模型,兼顾速度和精度。
# yolob.yaml (base):基本版模型,适合大部分应用场景。
# yolol.yaml (large):大型模型,适合对精度要求高的任务。
from ultralytics import YOLO
model_path = 'pt/yolo12s.pt'
data_path = 'data.yaml'
if __name__ == '__main__':
model = YOLO(model_path)
results = model.train(data=data_path,
epochs=500,
batch=64,
device='0',
workers=0,
project='runs',
name='exp',
)


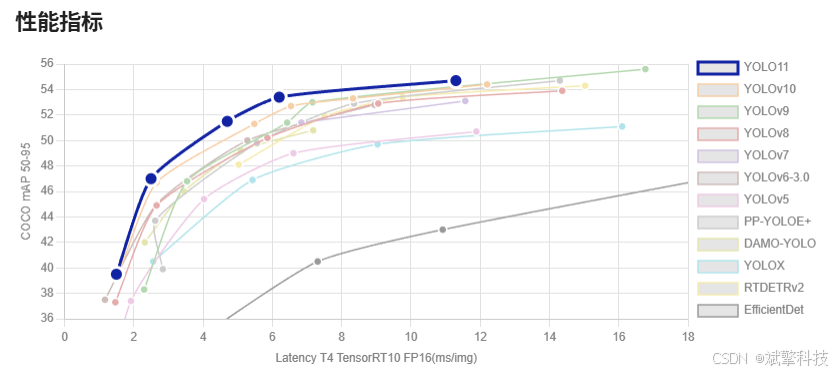
YOLO概述
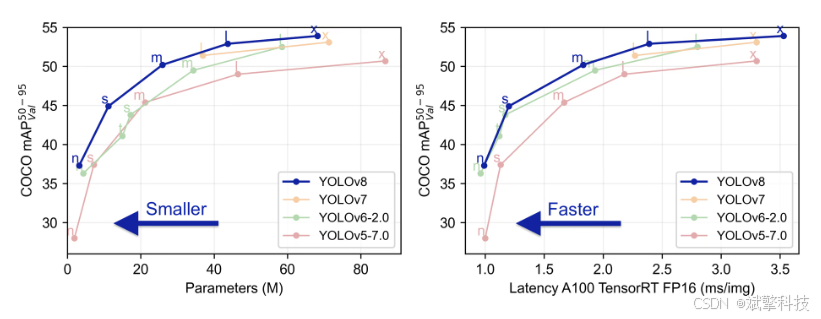
YOLOv8
YOLOv8 由 Ultralytics 于 2023 年 1 月 10 日发布,在准确性和速度方面提供了尖端性能。基于先前 YOLO 版本的进步,YOLOv8 引入了新功能和优化,使其成为各种应用中目标检测任务的理想选择。
YOLOv8 的主要特性
- 高级骨干和颈部架构: YOLOv8 采用最先进的骨干和颈部架构,从而改进了特征提取和目标检测性能。
- 无锚点分离式 Ultralytics Head: YOLOv8 采用无锚点分离式 Ultralytics head,与基于锚点的方法相比,这有助于提高准确性并提高检测效率。
- 优化的准确性-速度权衡: YOLOv8 专注于在准确性和速度之间保持最佳平衡,适用于各种应用领域中的实时对象检测任务。
- 丰富的预训练模型: YOLOv8提供了一系列预训练模型,以满足各种任务和性能要求,使您更容易为特定用例找到合适的模型。
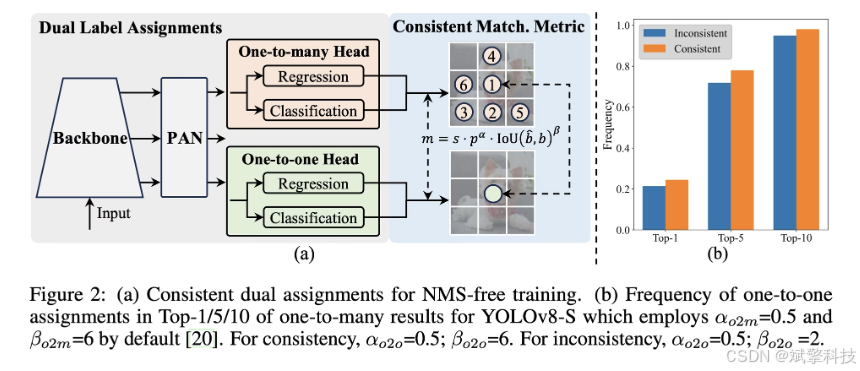
YOLOv10
YOLOv10 由 清华大学研究人员基于 Ultralytics Python构建,引入了一种新的实时目标检测方法,解决了先前 YOLO 版本中存在的后处理和模型架构缺陷。通过消除非极大值抑制 (NMS) 并优化各种模型组件,YOLOv10 以显著降低的计算开销实现了最先进的性能。大量实验表明,它在多个模型尺度上都具有卓越的精度-延迟权衡。
概述
实时目标检测旨在以低延迟准确预测图像中的对象类别和位置。YOLO 系列因其在性能和效率之间的平衡而一直处于这项研究的前沿。然而,对 NMS 的依赖和架构效率低下阻碍了最佳性能。YOLOv10 通过引入用于无 NMS 训练的一致双重分配和整体效率-准确性驱动的模型设计策略来解决这些问题。
架构
YOLOv10 的架构建立在之前 YOLO 模型优势的基础上,同时引入了几项关键创新。该模型架构由以下组件组成:
- 骨干网络:负责特征提取,YOLOv10 中的骨干网络使用增强版的 CSPNet (Cross Stage Partial Network),以改善梯度流并减少计算冗余。
- Neck:Neck 的设计目的是聚合来自不同尺度的特征,并将它们传递到 Head。它包括 PAN(路径聚合网络)层,用于有效的多尺度特征融合。
- One-to-Many Head:在训练期间为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
- 一对一头部:在推理时为每个对象生成一个最佳预测,以消除对NMS的需求,从而降低延迟并提高效率。
主要功能
- 免NMS训练:利用一致的双重分配来消除对NMS的需求,从而降低推理延迟。
- 整体模型设计:从效率和准确性的角度对各种组件进行全面优化,包括轻量级分类 Head、空间通道解耦下采样和秩引导块设计。
- 增强的模型功能: 结合了大内核卷积和部分自注意力模块,以提高性能,而无需显着的计算成本。
YOLOv11
YOLO11 是 Ultralytics YOLO 系列实时目标检测器的最新迭代版本,它以前沿的精度、速度和效率重新定义了可能性。YOLO11 在之前 YOLO 版本的显著进步基础上,在架构和训练方法上进行了重大改进,使其成为各种计算机视觉任务的多功能选择。
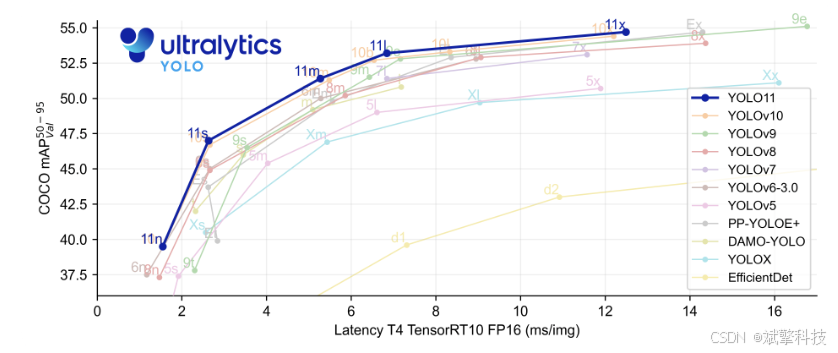
主要功能
- 增强的特征提取: YOLO11 采用改进的 backbone 和 neck 架构,从而增强了特征提取能力,以实现更精确的目标检测和复杂的任务性能。
- 优化效率和速度: YOLO11 引入了改进的架构设计和优化的训练流程,从而提供更快的处理速度,并在精度和性能之间保持最佳平衡。
- 更高精度,更少参数: 随着模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的 平均精度均值(mAP),同时比 YOLOv8m 少用 22% 的参数,在不牺牲精度的情况下提高了计算效率。
- 跨环境的适应性: YOLO11 可以无缝部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统,从而确保最大的灵活性。
- 广泛支持的任务范围: 无论是目标检测、实例分割、图像分类、姿势估计还是旋转框检测 (OBB),YOLO11 都旨在满足各种计算机视觉挑战。
Ultralytics YOLO11 在其前代产品的基础上进行了多项重大改进。主要改进包括:
- 增强的特征提取: YOLO11 采用了改进的骨干网络和颈部架构,增强了特征提取能力,从而实现更精确的目标检测。
- 优化的效率和速度: 改进的架构设计和优化的训练流程提供了更快的处理速度,同时保持了准确性和性能之间的平衡。
- 更高精度,更少参数: YOLO11m 在 COCO 数据集上实现了更高的平均 精度均值 (mAP),同时比 YOLOv8m 少用 22% 的参数,在不牺牲精度的情况下提高了计算效率。
- 跨环境的适应性: YOLO11 可以部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统。
- 广泛支持的任务范围: YOLO11 支持各种计算机视觉任务,例如目标检测、实例分割、图像分类、姿势估计和旋转框检测 (OBB)。
YOLOv12
YOLO12引入了一种以注意力为中心的架构,它不同于之前YOLO模型中使用的传统基于CNN的方法,但仍保持了许多应用所需的实时推理速度。该模型通过在注意力机制和整体网络架构方面的新颖方法创新,实现了最先进的目标检测精度,同时保持了实时性能。尽管有这些优势,YOLO12仍然是一个社区驱动的版本,由于其沉重的注意力模块,可能表现出训练不稳定、内存消耗增加和CPU吞吐量较慢的问题,因此Ultralytics仍然建议将YOLO11用于大多数生产工作负载。
主要功能
- 区域注意力机制: 一种新的自注意力方法,可以有效地处理大型感受野。它将 特征图 分成 l 个大小相等的区域(默认为 4 个),水平或垂直,避免复杂的运算并保持较大的有效感受野。与标准自注意力相比,这大大降低了计算成本。
- 残差高效层聚合网络(R-ELAN):一种基于 ELAN 的改进的特征聚合模块,旨在解决优化挑战,尤其是在更大规模的以注意力为中心的模型中。R-ELAN 引入:
- 具有缩放的块级残差连接(类似于层缩放)。
- 一种重新设计的特征聚合方法,创建了一个类似瓶颈的结构。
- 优化的注意力机制架构:YOLO12 精简了标准注意力机制,以提高效率并与 YOLO 框架兼容。这包括:
- 使用 FlashAttention 来最大限度地减少内存访问开销。
- 移除位置编码,以获得更简洁、更快速的模型。
- 调整 MLP 比率(从典型的 4 调整到 1.2 或 2),以更好地平衡注意力和前馈层之间的计算。
- 减少堆叠块的深度以改进优化。
- 利用卷积运算(在适当的情况下)以提高其计算效率。
- 在注意力机制中添加一个7x7可分离卷积(“位置感知器”),以隐式地编码位置信息。
- 全面的任务支持: YOLO12 支持一系列核心计算机视觉任务:目标检测、实例分割、图像分类、姿势估计和旋转框检测 (OBB)。
- 增强的效率: 与许多先前的模型相比,以更少的参数实现了更高的准确率,从而证明了速度和准确率之间更好的平衡。
- 灵活部署: 专为跨各种平台部署而设计,从边缘设备到云基础设施。
主要改进
-
增强的 特征提取:
- 区域注意力: 有效处理大型感受野,降低计算成本。
- 优化平衡: 改进了注意力和前馈网络计算之间的平衡。
- R-ELAN:使用 R-ELAN 架构增强特征聚合。
-
优化创新:
- 残差连接:引入具有缩放的残差连接以稳定训练,尤其是在较大的模型中。
- 改进的特征集成:在 R-ELAN 中实现了一种改进的特征集成方法。
- FlashAttention: 整合 FlashAttention 以减少内存访问开销。
-
架构效率:
- 减少参数:与之前的许多模型相比,在保持或提高准确性的同时,实现了更低的参数计数。
- 简化的注意力机制:使用简化的注意力实现,避免了位置编码。
- 优化的 MLP 比率:调整 MLP 比率以更有效地分配计算资源。
前端代码展示
前端图片检测界面一小部分代码:
<template>
<div class="brain-detection-container" id="id" v-loading="state.loading">
<!-- 顶部导航栏 -->
<div class="top-nav">
<div class="logo">
<i class="icon-brain"></i>
<span>Computer Vision</span>
</div>
<div class="user-info">
<el-avatar :size="32" :src="userInfos.avatar" />
<span class="username">{{ userInfos.userName }}</span>
</div>
</div>
<div class="main-content">
<!-- 左侧功能区 -->
<div class="left-panel">
<div class="panel-section">
<h3 class="section-title">模型配置</h3>
<div class="config-item">
<label>选择模型</label>
<el-select v-model="weight" placeholder="请选择模型" size="large">
<el-option v-for="item in state.weight_items" :key="item.value" :label="item.label"
:value="item.value" />
</el-select>
</div>
<div class="config-item">
<label>AI助手</label>
<el-select v-model="ai" placeholder="请选择AI助手" size="large" @change="getData">
<el-option v-for="item in state.ai_items" :key="item.value" :label="item.label"
:value="item.value" />
</el-select>
</div>
<div class="config-item">
<label>置信度阈值: {{ (conf/100).toFixed(2) }}</label>
<el-slider v-model="conf" :format-tooltip="formatTooltip" show-stops :max="100" :step="5" />
</div>
<div class="action-buttons">
<el-button type="primary" @click="upData" class="predict-btn">
<i class="icon-scan"></i>
开始检测
</el-button>
<el-button @click="resetForm" class="reset-btn">
<i class="icon-reset"></i>
重置
</el-button>
</div>
</div>
<div class="panel-section">
<h3 class="section-title">历史记录</h3>
<div class="history-list">
<div v-for="(item, index) in state.history" :key="index" class="history-item">
<div class="history-time">{{ item.time }}</div>
<div class="history-result">{{ item.result }}</div>
</div>
<div v-if="state.history.length === 0" class="empty-history">
暂无历史记录
</div>
</div>
</div>
</div>
<!-- 中间内容区 -->
<div class="center-panel">
<div class="upload-section">
<el-card class="upload-card">
<template #header>
<div class="card-header">
<span>上传图片</span>
<el-button type="text" @click="showExample">查看示例</el-button>
</div>
</template>
<el-upload v-model="state.img" ref="uploadFile" class="avatar-uploader"
action="http://localhost:9999/files/upload" :show-file-list="false"
:on-success="handleAvatarSuccessone" drag>
<div class="upload-area">
<el-icon v-if="!imageUrl" class="upload-icon">
<Plus />
</el-icon>
<img v-else :src="imageUrl" class="uploaded-image" />
<div v-if="!imageUrl" class="upload-text">
<p>将图片拖拽到此处,或<em>点击上传</em></p>
<p class="upload-tip">支持 JPG、PNG 格式,大小不超过 10MB</p>
</div>
</div>
</el-upload>
</el-card>
</div>
<div class="result-section" v-if="state.predictionResult.label">
<el-card class="result-card">
<template #header>
<div class="card-header">
<span>检测结果</span>
<el-button type="primary" @click="() => htmlToPDF('id', '检测报告')" size="small">
<i class="icon-download"></i>
导出报告
</el-button>
</div>
</template>
<div class="result-content">
<div class="result-overview">
<div class="result-item">
<div class="result-icon diagnosis"></div>
<div class="result-info">
<div class="result-label">诊断结果</div>
<div class="result-value highlight">{{ state.predictionResult.label || '-' }}</div>
</div>
</div>
<div class="result-item">
<div class="result-icon confidence"></div>
<div class="result-info">
<div class="result-label">置信度</div>
<div class="result-value accent">{{ state.predictionResult.confidence || '-' }}</div>
</div>
</div>
<div class="result-item">
<div class="result-icon time"></div>
<div class="result-info">
<div class="result-label">分析用时</div>
<div class="result-value">{{ state.predictionResult.allTime ? `${state.predictionResult.allTime}` : '-' }}</div>
</div>
</div>
</div>
<div class="detailed-results">
<h4>详细分析</h4>
<el-table :data="state.data" style="width: 100%">
<el-table-column prop="label" label="预测结果" align="center" />
<el-table-column prop="confidence" label="置信度" align="center" />
<el-table-column prop="allTime" label="用时(秒)" align="center" />
</el-table>
</div>
</div>
</el-card>
</div>
</div>
<!-- 右侧AI建议区 -->
<div class="right-panel" v-if="state.predictionResult.suggestion">
<div class="panel-section">
<h3 class="section-title">AI建议</h3>
<div class="ai-suggestion">
<div v-html="state.predictionResult.suggestion" class="markdown-body"></div>
</div>
<div class="suggestion-actions">
<el-button type="text" @click="copySuggestion">
<i class="icon-copy"></i>
复制建议
</el-button>
<el-button type="text" @click="saveSuggestion">
<i class="icon-save"></i>
保存建议
</el-button>
</div>
</div>
</div>
</div>
<!-- 底部状态栏 -->
<div class="status-bar">
<div class="status-item">
<i class="icon-status"></i>
<span>系统状态: 正常</span>
</div>
<div class="status-item">
<i class="icon-time"></i>
<span>最后更新: {{ currentTime }}</span>
</div>
</div>
</div>
</template>后端代码展示
详细功能展示视频
基于YOLO和千问|DeepSeek的猫狗品种检测系统(web+YOLOv8/YOLOv10/YOLOv11/YOLOv12+深度学习+python)_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1hwctzUECV/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)