基于YOLOv8/YOLOv10/YOLOv11/YOLOv12与SpringBoot的船舶类型检测系统(DeepSeek智能分析+web交互界面+前后端分离+YOLO数据)
摘要
随着全球航运业的蓬勃发展和海洋安全监管需求的日益提升,对海上船舶进行快速、准确的自动类型识别变得至关重要。传统的视觉监测方法效率低下,且严重依赖人工经验,难以满足现代海事管理、港口调度、安防预警等场景的实时性要求。为解决此问题,本项目设计并实现了一个基于前沿YOLO系列目标检测算法与SpringBoot全栈框架的智能化船舶类型检测系统。
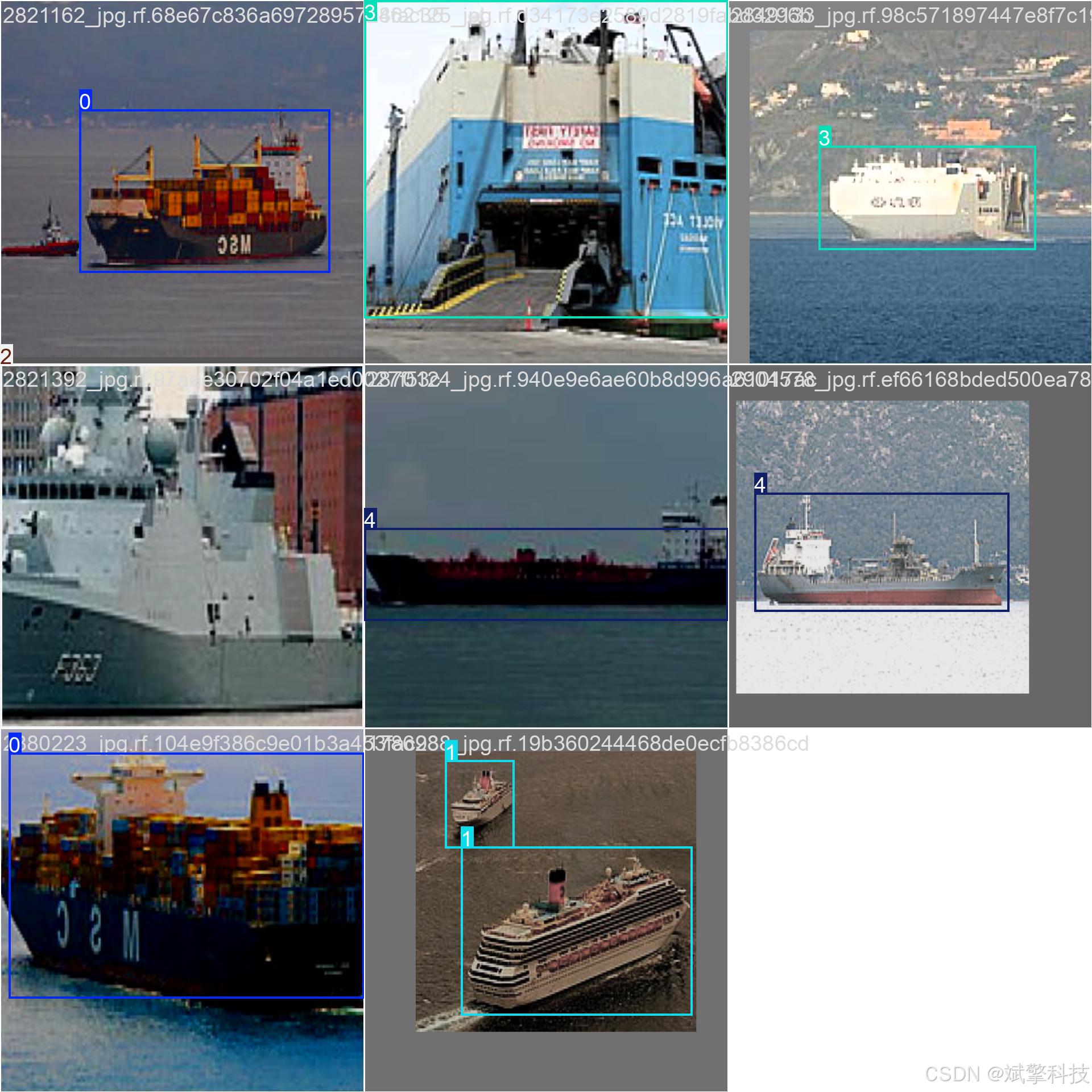
本系统以最新一代的YOLOv8、YOLOv10、YOLOv11及YOLOv12算法为核心,构建了一个高性能的船舶检测与分类模型。模型专门针对五类主要船舶(集装箱船、邮轮、军用舰船、滚装船、油轮)进行训练,数据集包含总计3721张高质量标注图像。系统采用前后端分离的现代化架构,后端基于SpringBoot构建,提供稳定、可扩展的RESTful API服务;前端则提供直观友好的Web交互界面。核心功能涵盖:1)多模态检测:支持图像、视频文件及摄像头实时流媒体中的船舶检测;2)多模型切换:允许用户在后端动态选择并使用不同版本的YOLO模型进行推理,便于性能对比与算法评估;3)AI深度分析:集成DeepSeek智能分析模块,对检测结果提供更深入的洞察与解读;4)全方位数据管理:所有检测记录(包括图片、视频、实时流)均结构化存储于MySQL数据库,并辅以强大的信息可视化仪表盘进行展现;5)完整的用户体系:包含用户注册登录(含密码安全检测)、个人中心管理以及管理员后台管理模块,实现了系统级的权限控制与数据隔离。
测试表明,该系统能够有效识别复杂海况下的各类船舶,识别准确率高、响应速度快。它不仅为海事监管和研究人员提供了一个强大的技术工具,同时也为将先进目标检测算法工程化、产品化,并构建完整的数据驱动型Web应用提供了一个典型的实践范例,具有良好的应用价值与推广前景。
关键词:船舶类型检测;YOLO系列算法;深度学习;SpringBoot;前后端分离;Web应用;数据可视化;智能分析
详细功能展示视频
基于YOLO和千问|DeepSeek的船舶类型检测系统(web界面+YOLOv8/YOLOv10/YOLOv11/YOLOv12+深度学习+python)_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV15Zc4zpETo/
目录
引言
1. 研究背景与意义
21世纪是海洋的世纪,海上交通运输作为全球贸易的主动脉,其安全、高效、智能化的运营管理关乎国家经济命脉与战略安全。在此背景下,对广阔海域中航行的船舶进行自动识别与监控,是港口管理、航道规划、海上搜救、边境安防以及海洋环境保护等领域不可或缺的基础能力。传统的船舶识别主要依赖于船舶自动识别系统(AIS)和雷达,但AIS信息可能被关闭或篡改,雷达图像则解读专业门槛高,且二者在视觉细节识别上存在局限。因此,基于计算机视觉和深度学习的船舶光学图像识别技术,以其成本相对较低、信息直观丰富、可与非光学传感器信息融合等优势,成为海事感知领域的研究热点。
目标检测算法,特别是以YOLO(You Only Look Once)系列为代表的单阶段检测器,因其在精度与速度间取得的卓越平衡,已成为工业界落地应用的首选。从YOLOv8到最新提出的YOLOv10/YOLOv11/YOLOv12,算法在骨干网络设计、特征融合策略、损失函数优化等方面持续演进,性能不断提升。如何将这些学术界的最新成果快速转化为稳定可靠的业务系统,并提供一个便于非专业用户操作、能够沉淀与分析数据的平台,是当前面临的主要工程挑战。
2. 国内外研究现状
目前,基于深度学习的船舶检测研究已取得显著进展。大量工作聚焦于改进特定算法(如Faster R-CNN, SSD, YOLO及其变体)在船舶数据集上的性能,通过引入注意力机制、优化锚框设计、改进损失函数等方式提升对小型、密集或遮挡船舶的检测效果。然而,现有研究大多停留在算法模型本身的训练与测试阶段,或局限于简单的本地脚本演示,缺乏一个将先进检测模型、健壮的后端服务、交互式前端界面以及系统的数据管理融为一体的完整解决方案。此外,对于多种最新版YOLO模型在统一平台上进行便捷比较与切换的需求,现有系统也少有支持。
3. 本项目的主要内容与创新点
针对上述需求与空白,本项目旨在开发一个功能完备、架构先进、用户体验优良的“船舶类型检测系统”。本工作的核心内容与贡献主要体现在以下几个方面:
-
多模型集成与可配置检测引擎:系统核心创新性地集成了YOLOv8, v10, v11, v12共四个版本的先进检测模型。用户可通过Web界面灵活切换,实时体验和比较不同算法在相同输入下的性能差异,为模型选型提供直观依据。
-
全栈式Web系统实现:采用前后端分离的现代化Web开发范式。后端使用SpringBoot框架构建微服务,负责模型推理、业务逻辑处理与数据持久化(MySQL);前端负责渲染交互界面,实现了高内聚、低耦合的系统架构,确保了系统的可维护性与可扩展性。
-
深度融合AI智能分析:超越基础的边框绘制与类别标签,系统集成了DeepSeek智能分析模块。该模块可对检测场景进行更深层次的语义分析与描述生成。
-
全周期数据管理与可视化:系统对每一次检测任务(无论是图片上传、视频分析还是实时摄像头抓拍)均生成详细的识别记录,包括时间、所用模型、检测结果、原始文件路径等,并全部存入数据库。同时,通过图表、仪表盘等形式对用户行为、模型调用频率、检测结果分布等信息进行可视化展示,赋能数据驱动的决策分析。
-
完善的用户与权限管理体系:构建了完整的用户认证与授权机制。支持用户注册、登录,普通用户拥有个人中心管理检测记录和个人信息的权限;管理员则拥有用户管理、全局数据查看等高级权限,确保了系统的安全性与数据隔离性。
二、 系统核心特性概述
功能模块
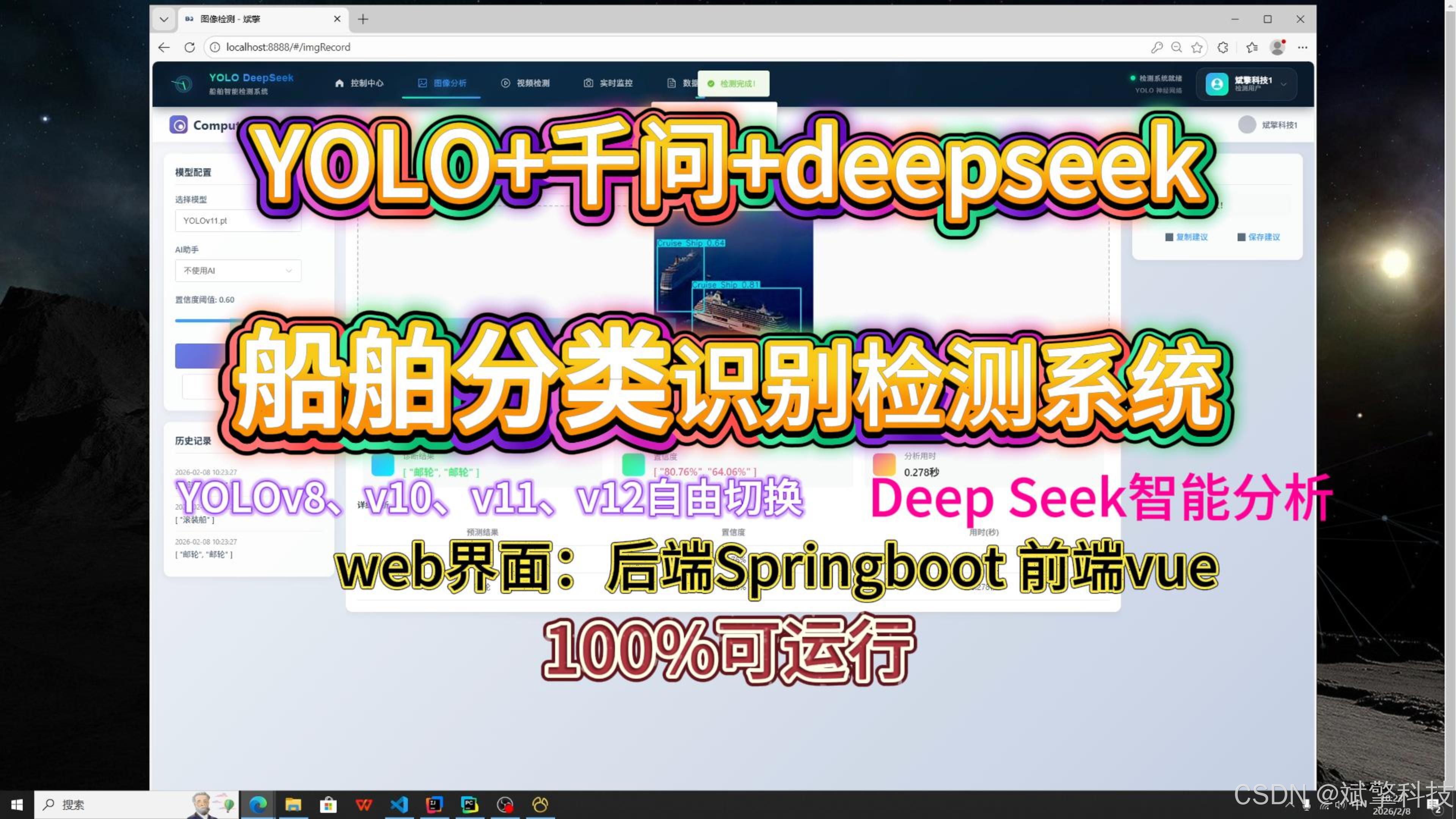
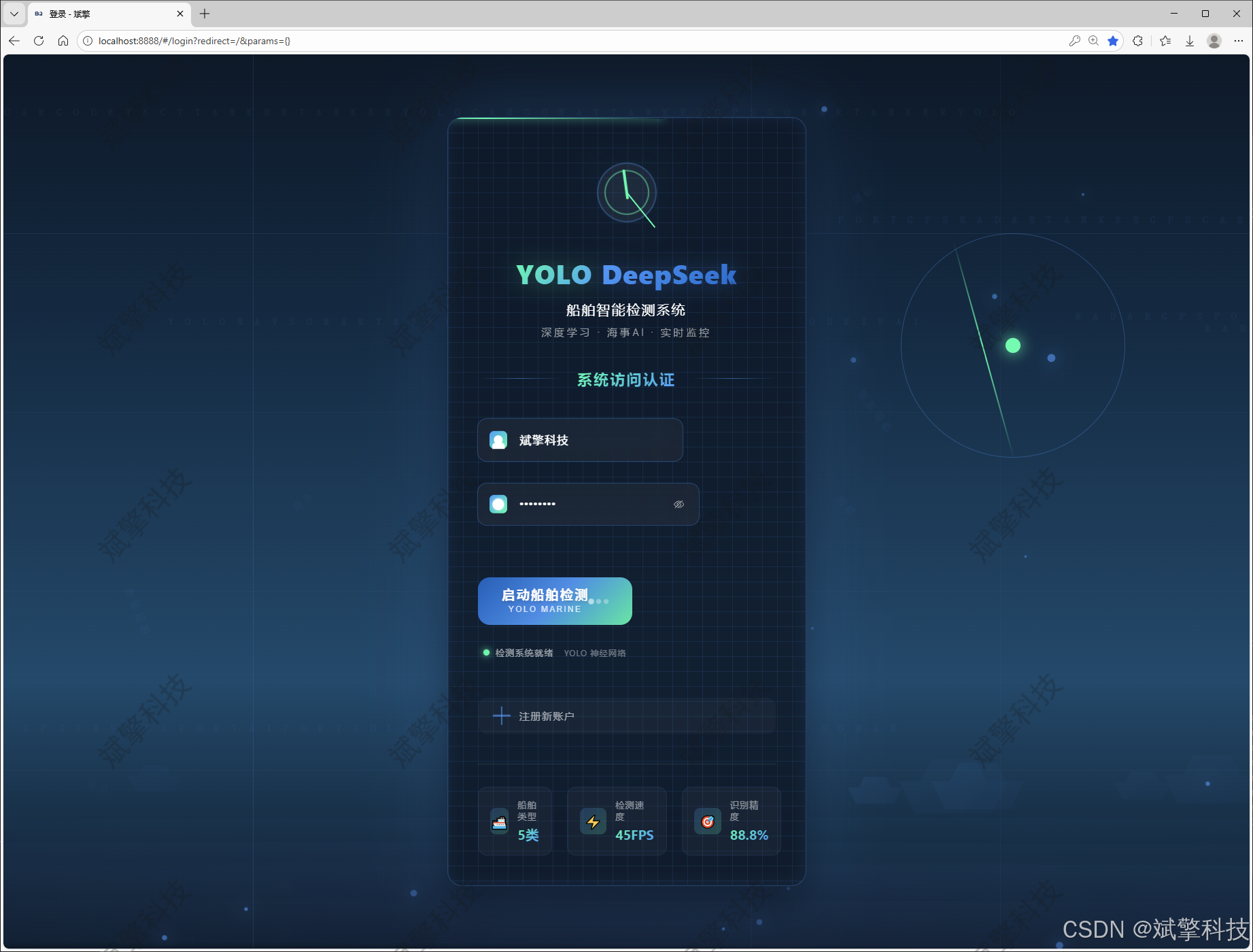
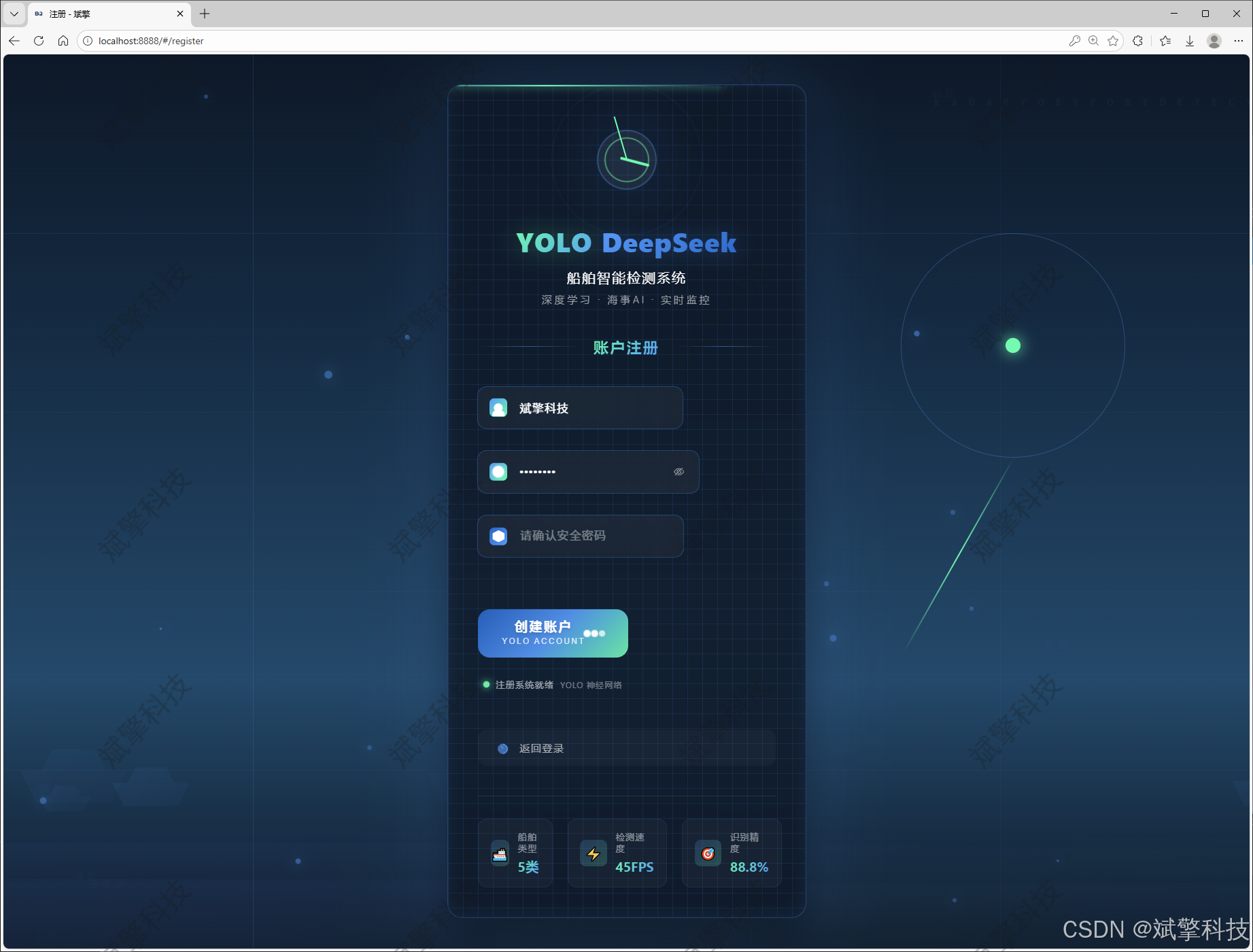
✅ 用户登录注册:支持密码检测,保存到MySQL数据库。
✅ 支持四种YOLO模型切换,YOLOv8、YOLOv10、YOLOv11、YOLOv12。
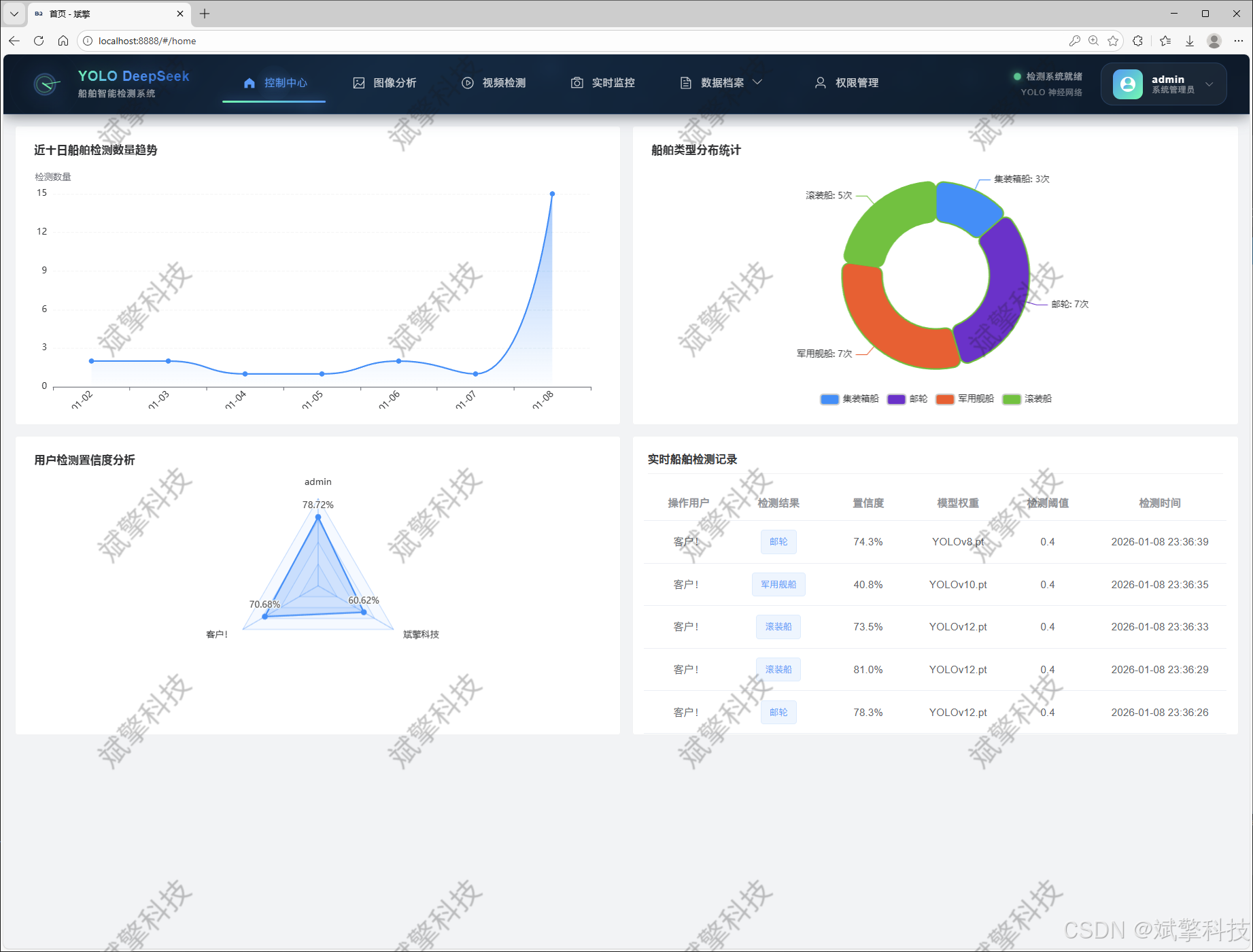
✅ 信息可视化,数据可视化。
✅ 图片检测支持AI分析功能,deepseek
✅ 支持图像检测、视频检测和摄像头实时检测,检测结果保存到MySQL数据库。
✅ 图片识别记录管理、视频识别记录管理和摄像头识别记录管理。
✅ 用户管理模块,管理员可以对用户进行增删改查。
✅ 个人中心,可以修改自己的信息,密码姓名头像等等。
登录注册模块
可视化模块
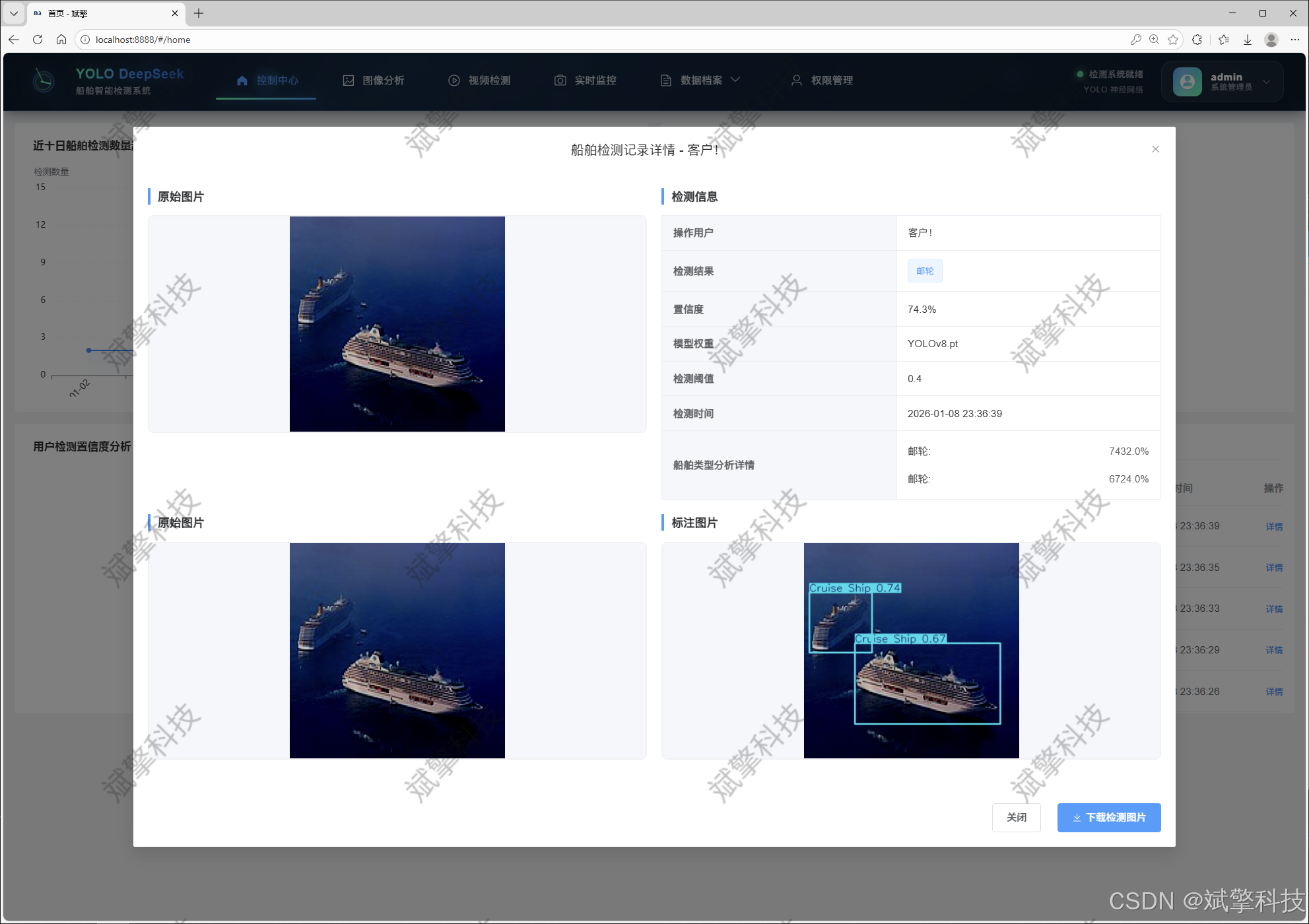
图像检测模块
-
YOLO模型集成 (v8/v10/v11/v12)
-
DeepSeek多模态分析
-
支持格式:JPG/PNG/MP4/RTSP
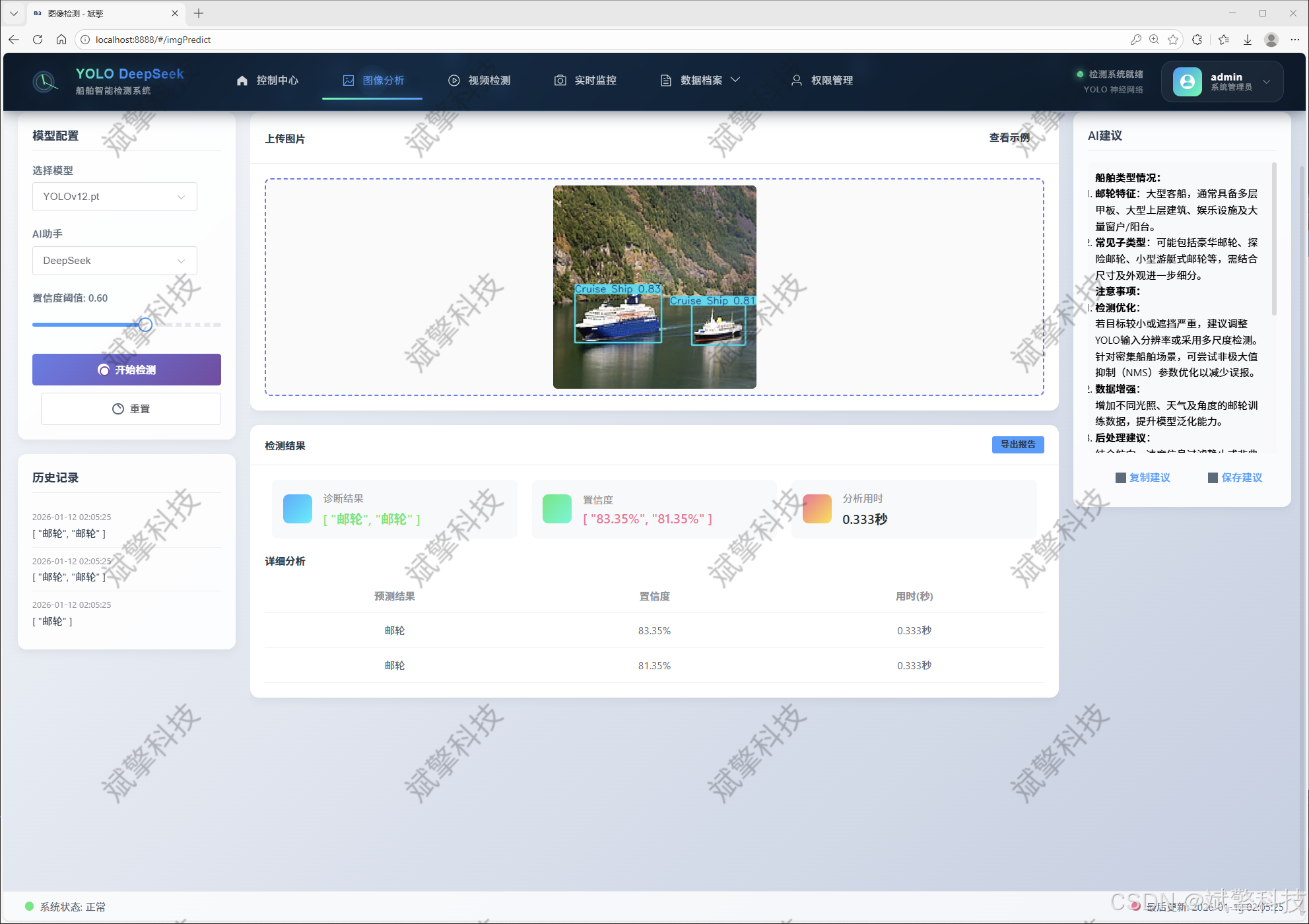
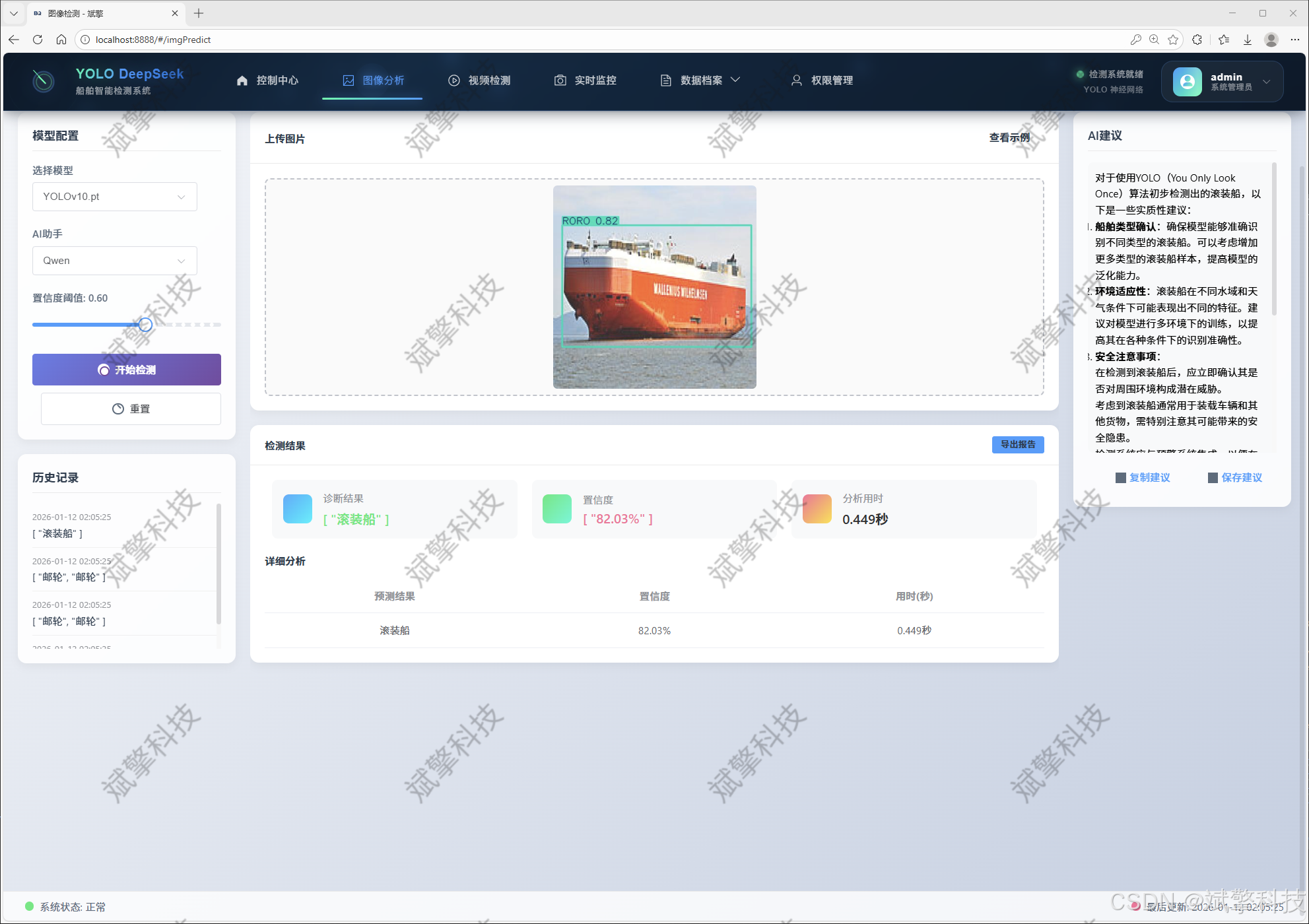
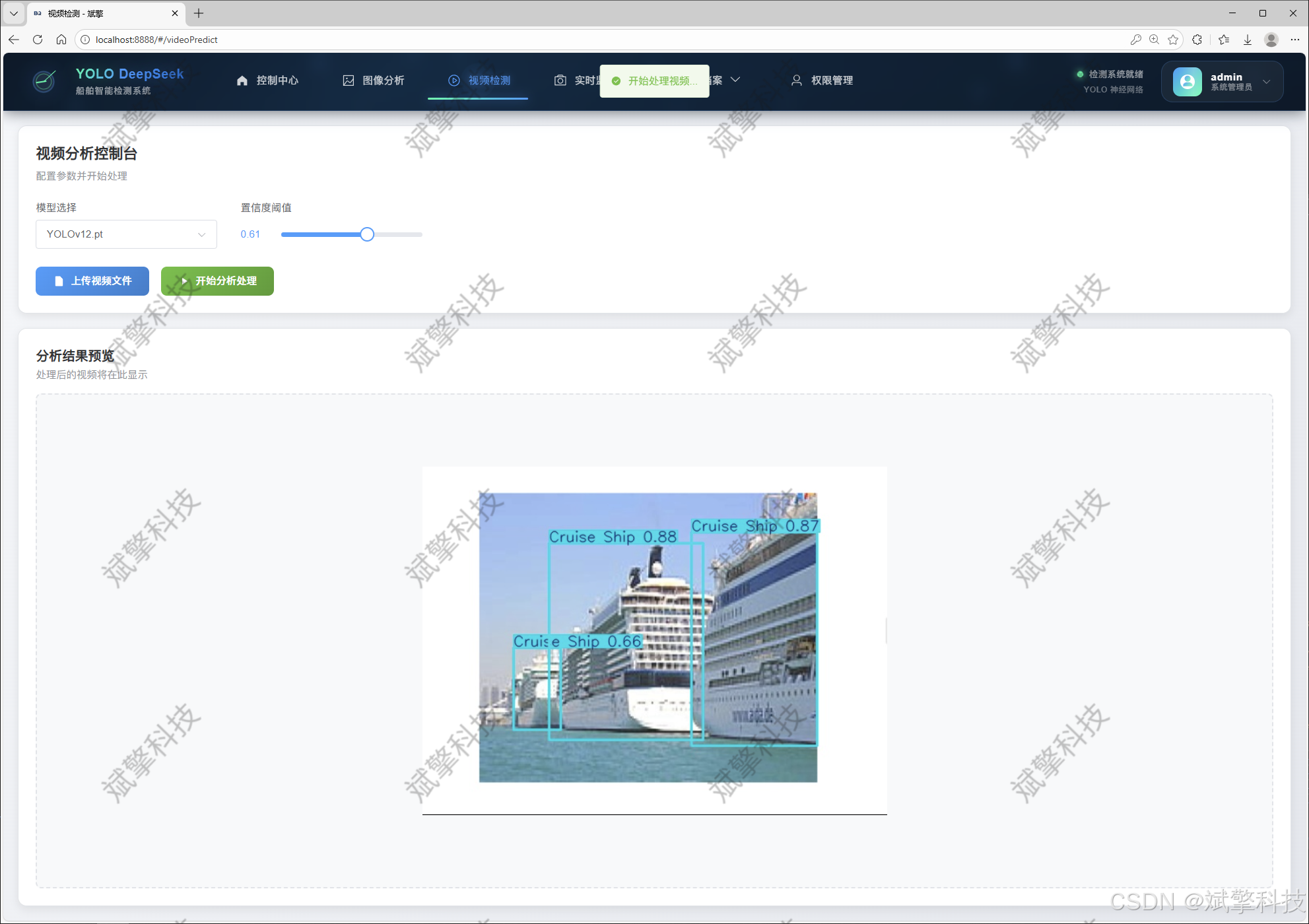
视频检测模块
实时检测模块
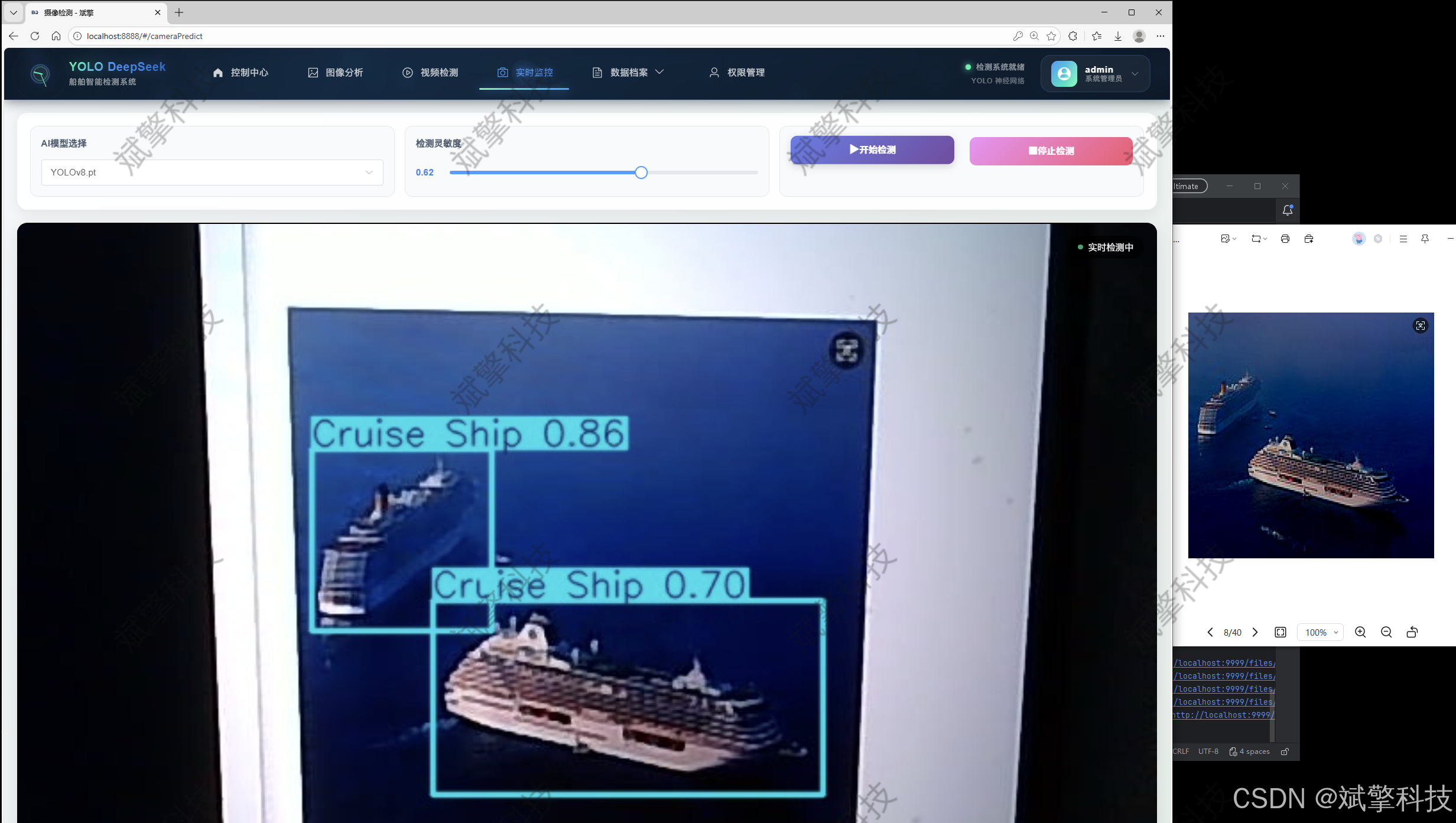
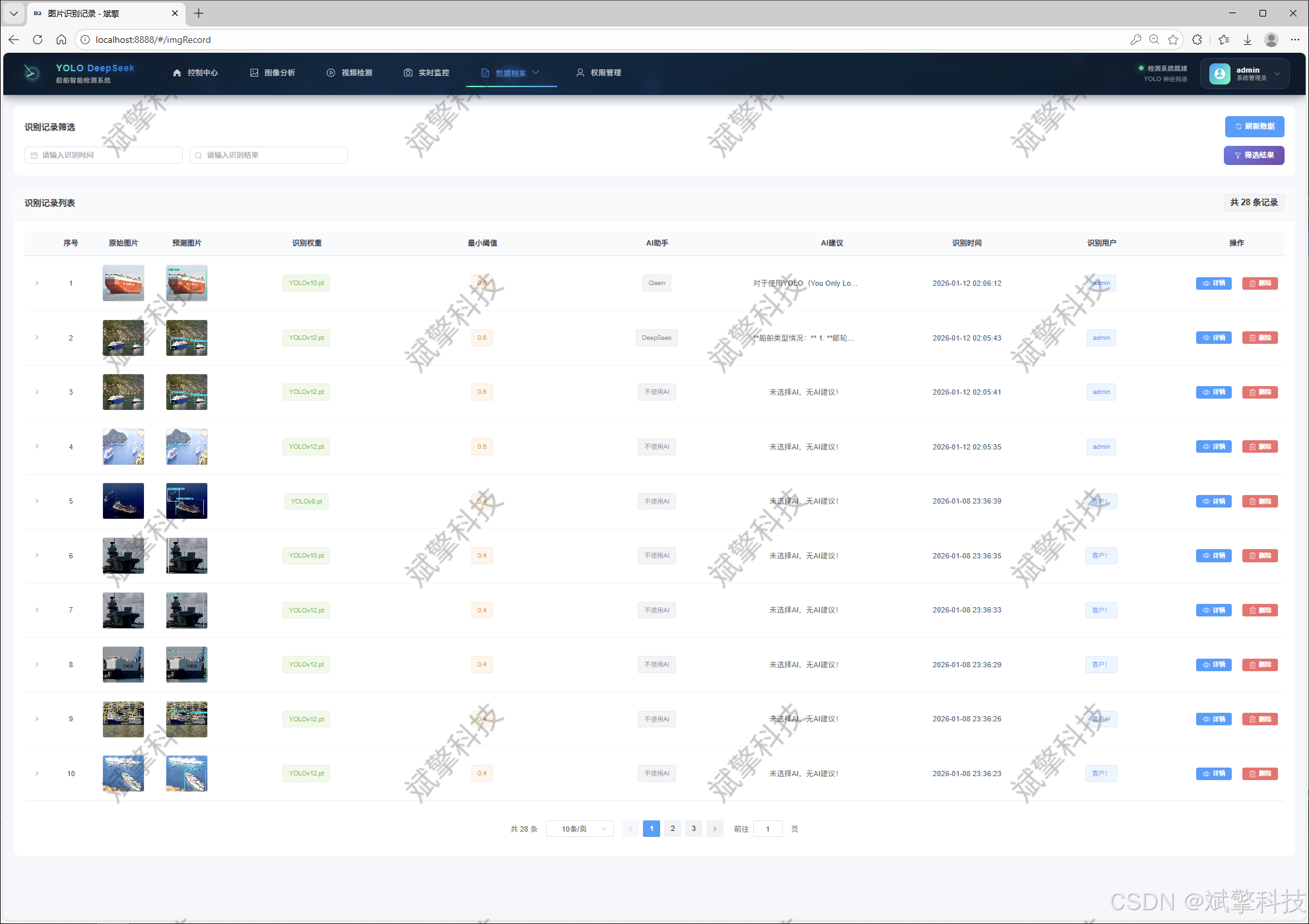
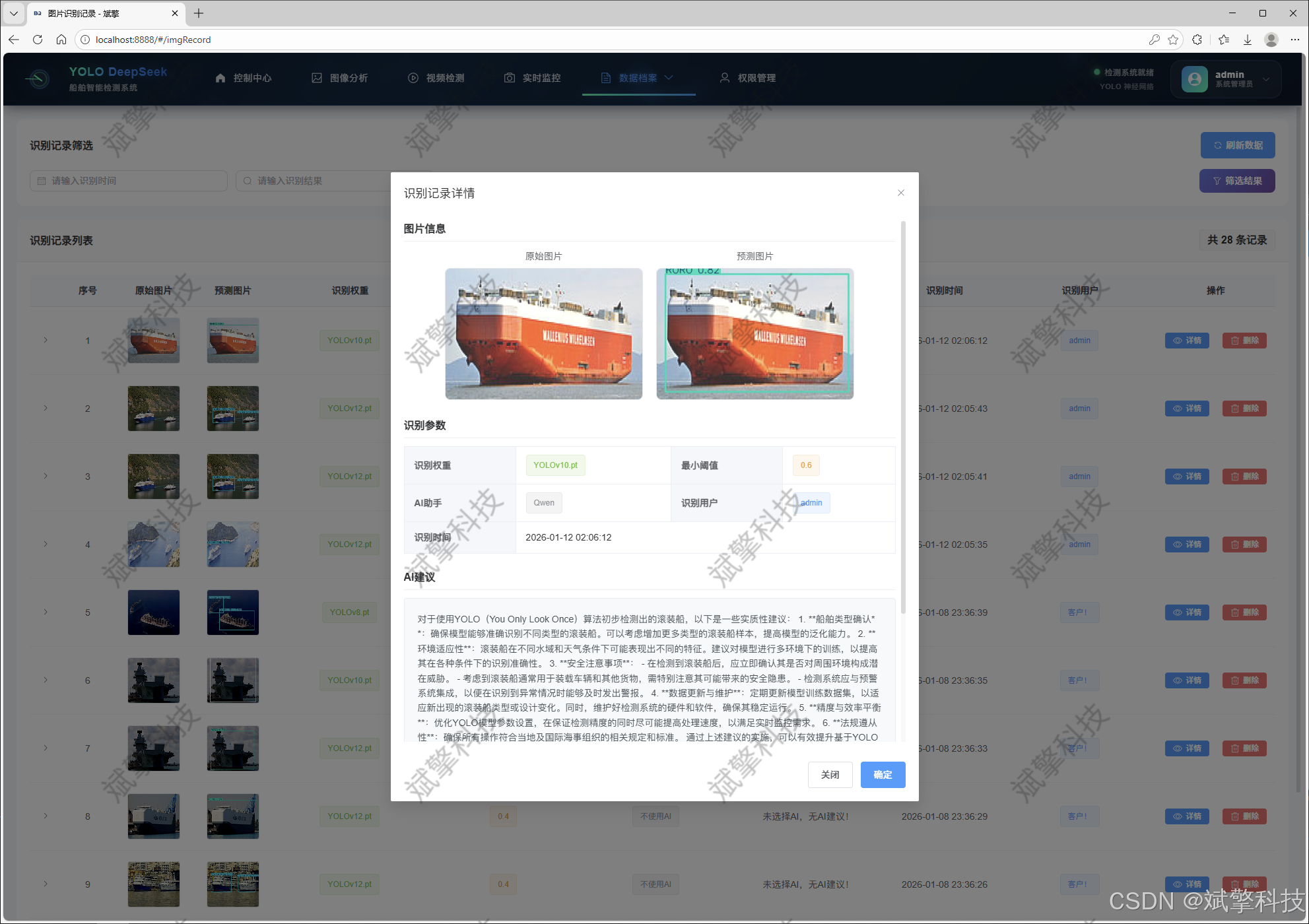
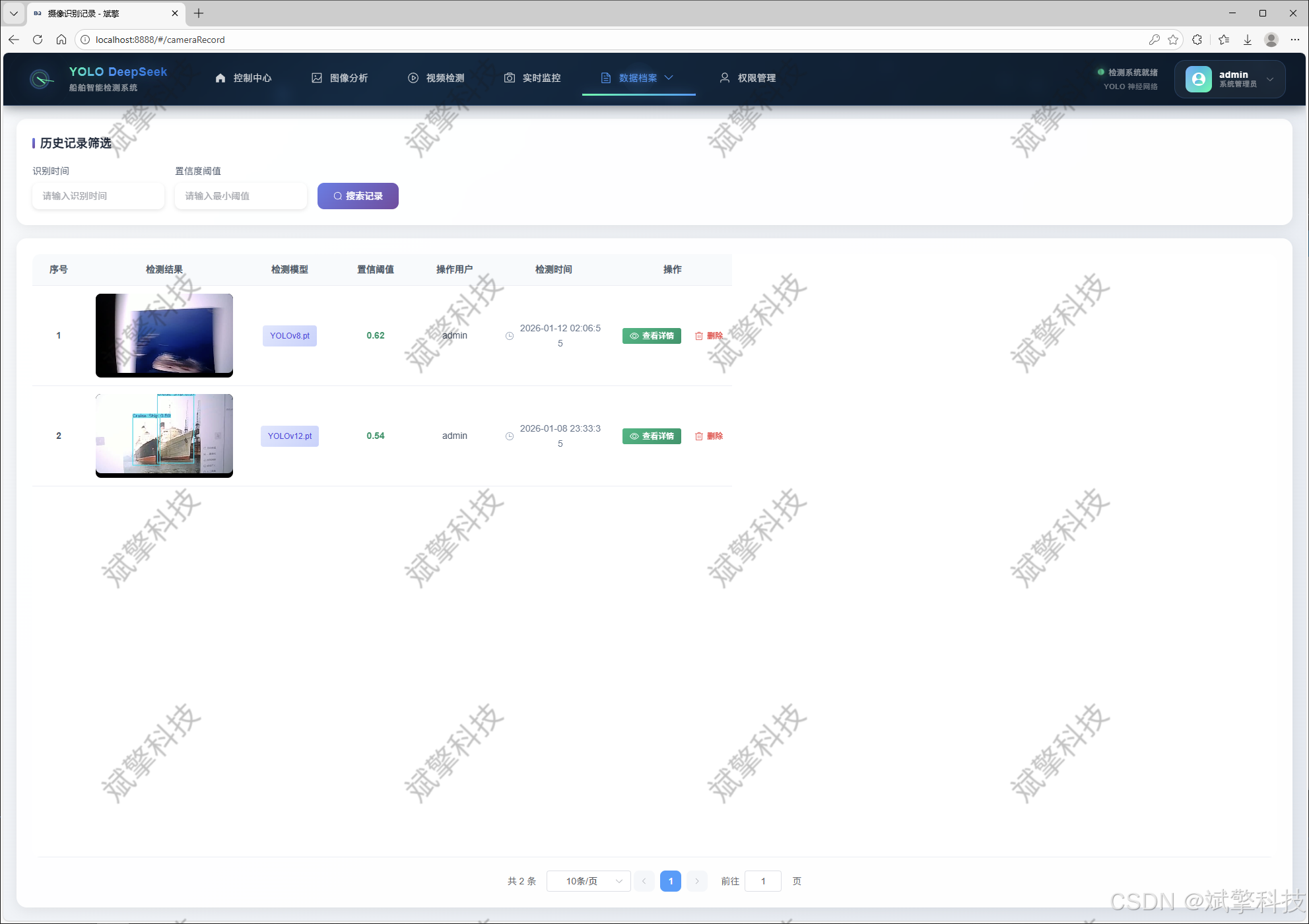
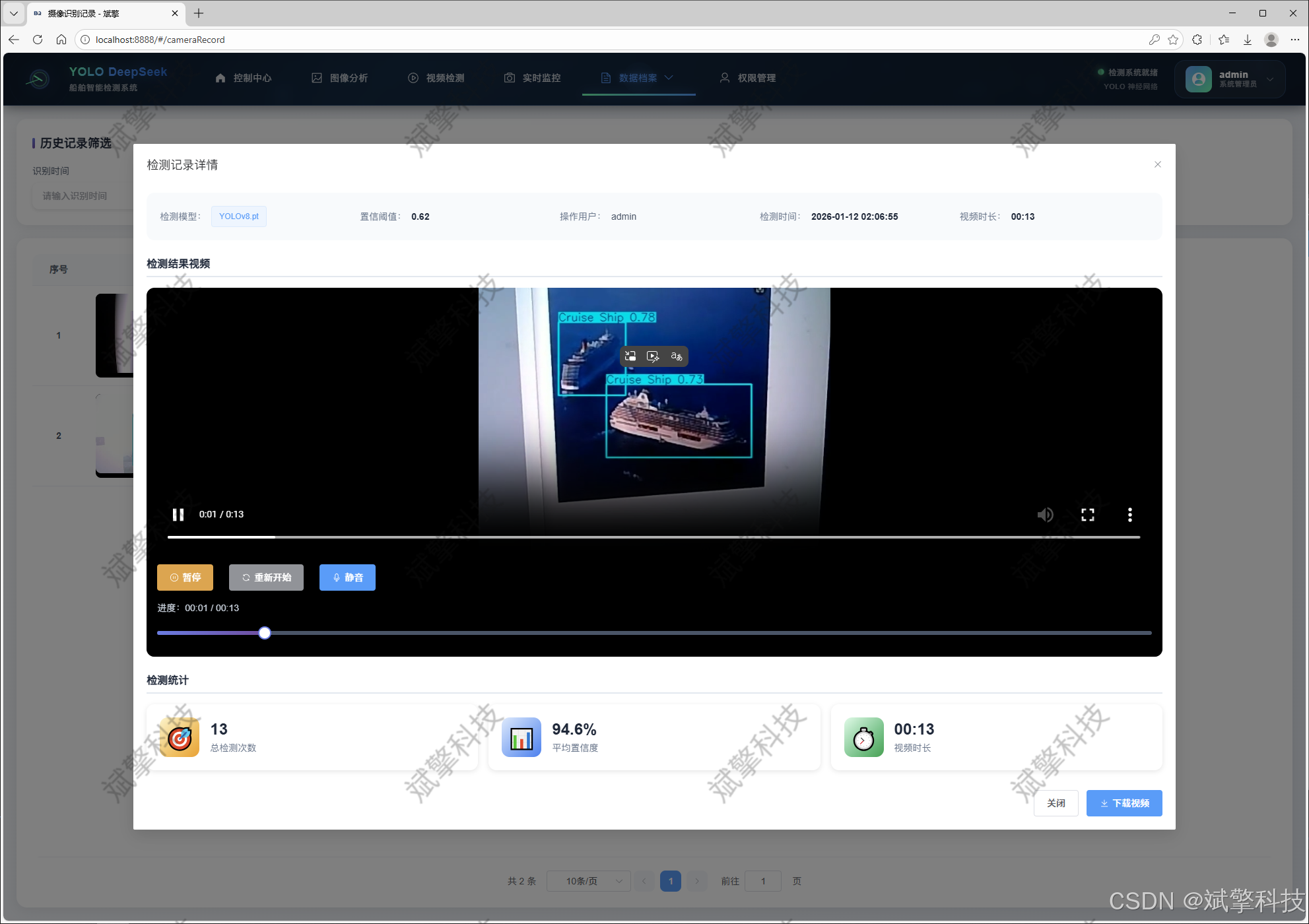
图片识别记录管理
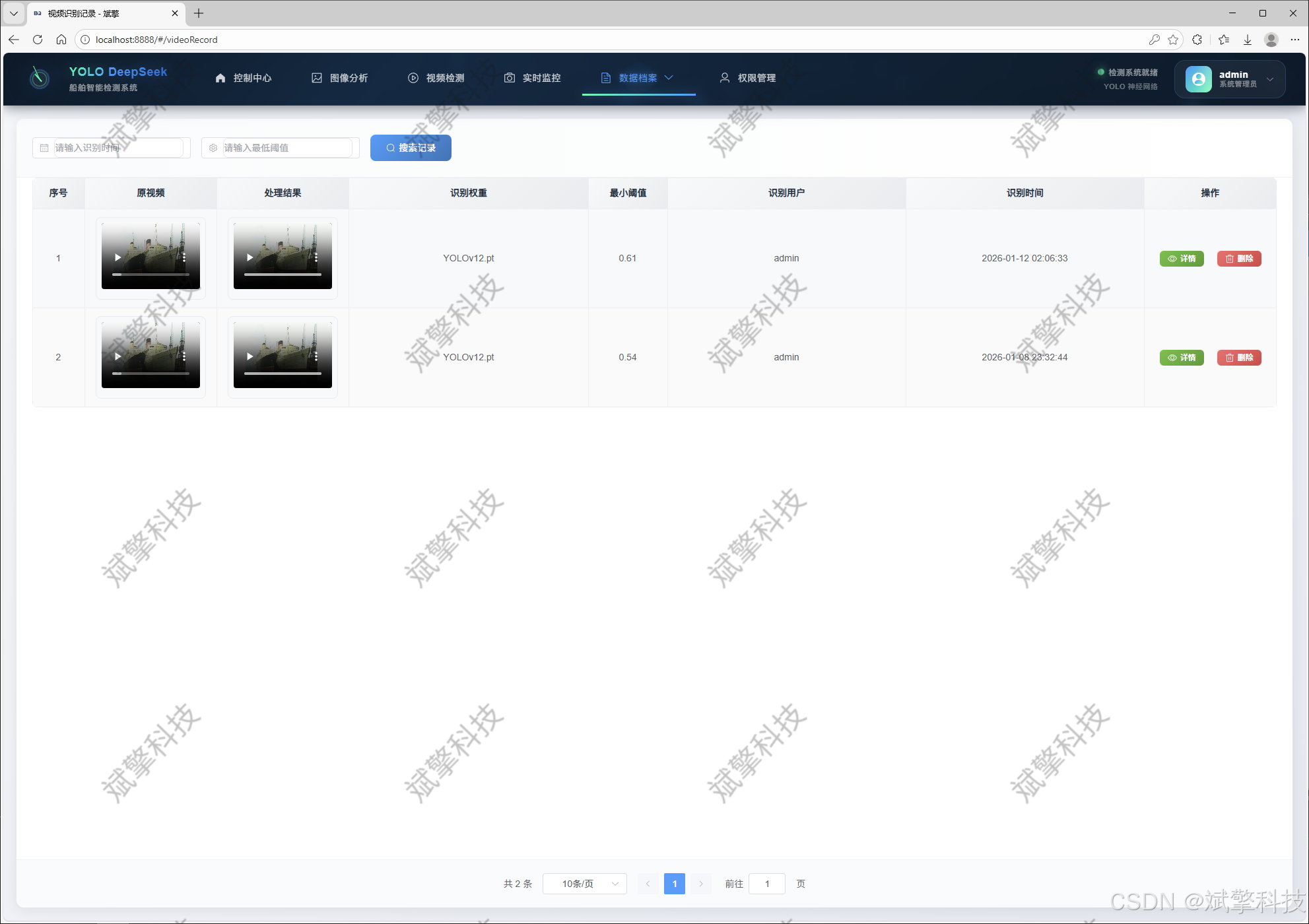
视频识别记录管理
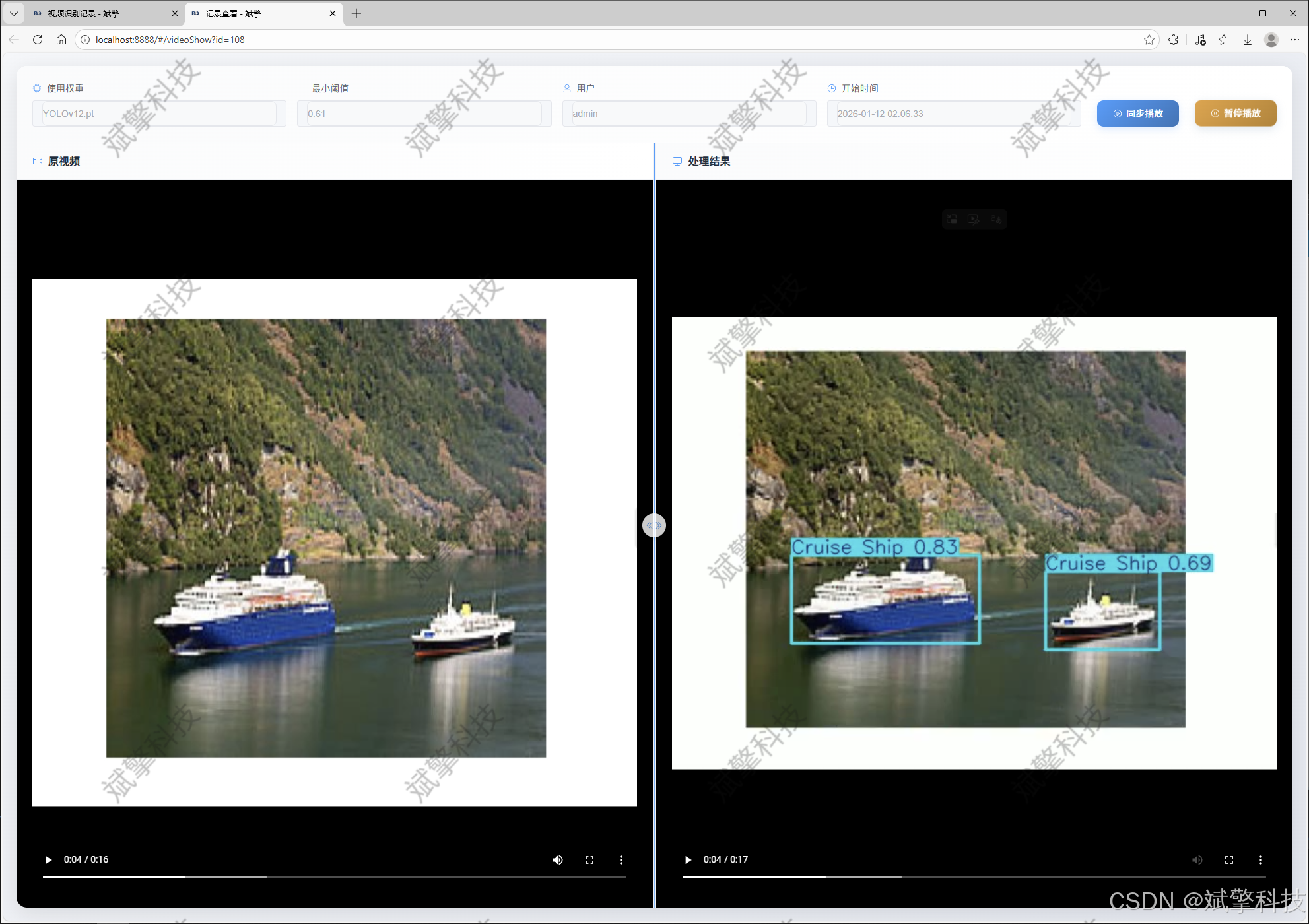
摄像头识别记录管理
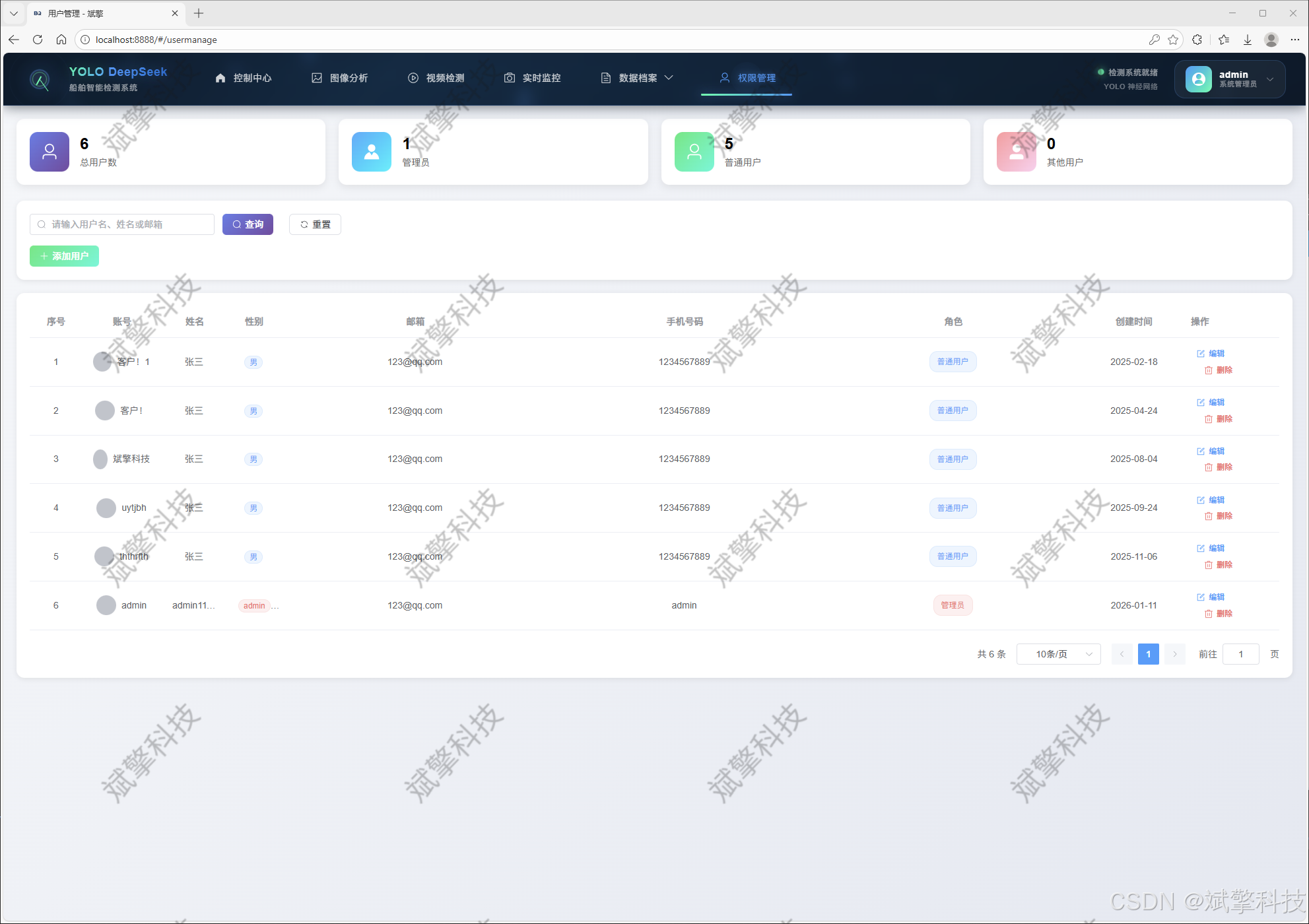
用户管理模块
数据管理模块(MySQL表设计)
-
users- 用户信息表

-
imgrecords- 图片检测记录表
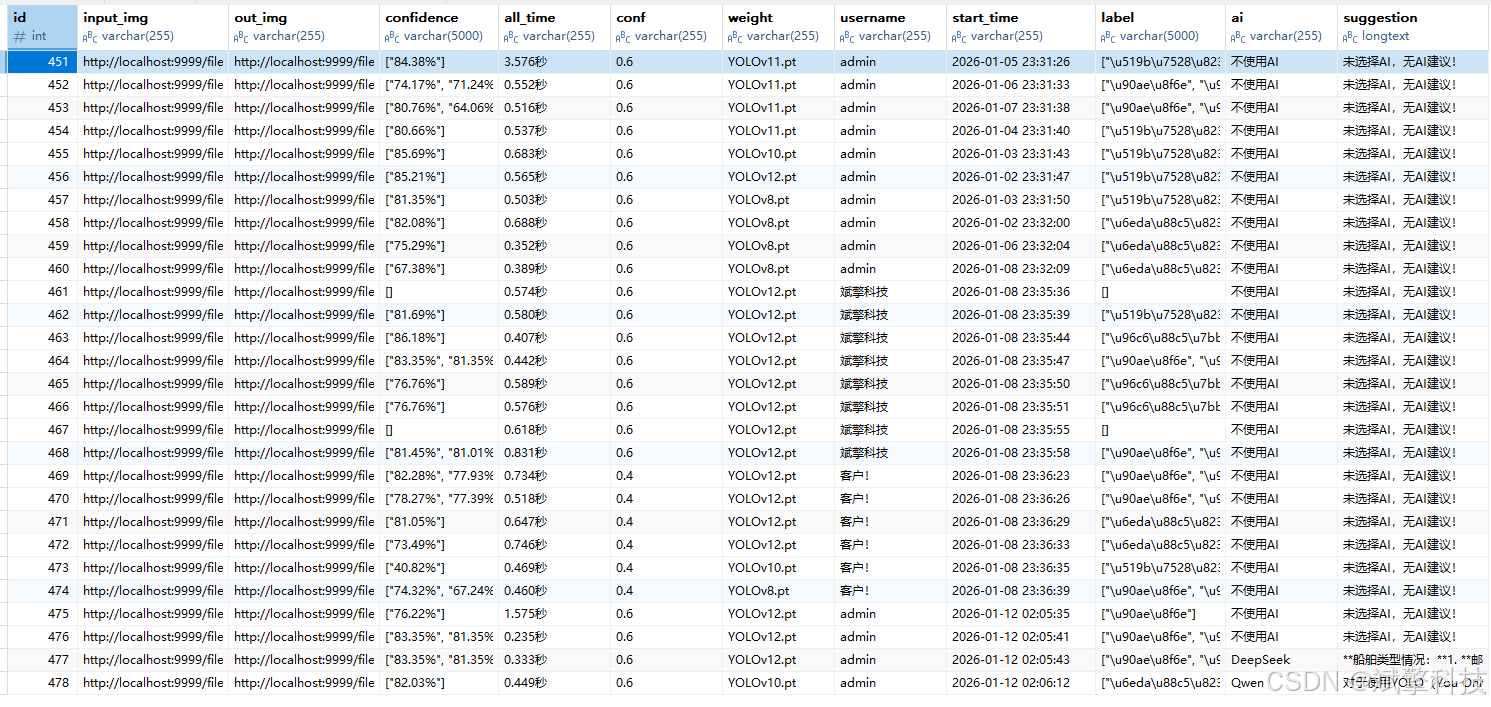
-
videorecords- 视频检测记录表

-
camerarecords- 摄像头检测记录表

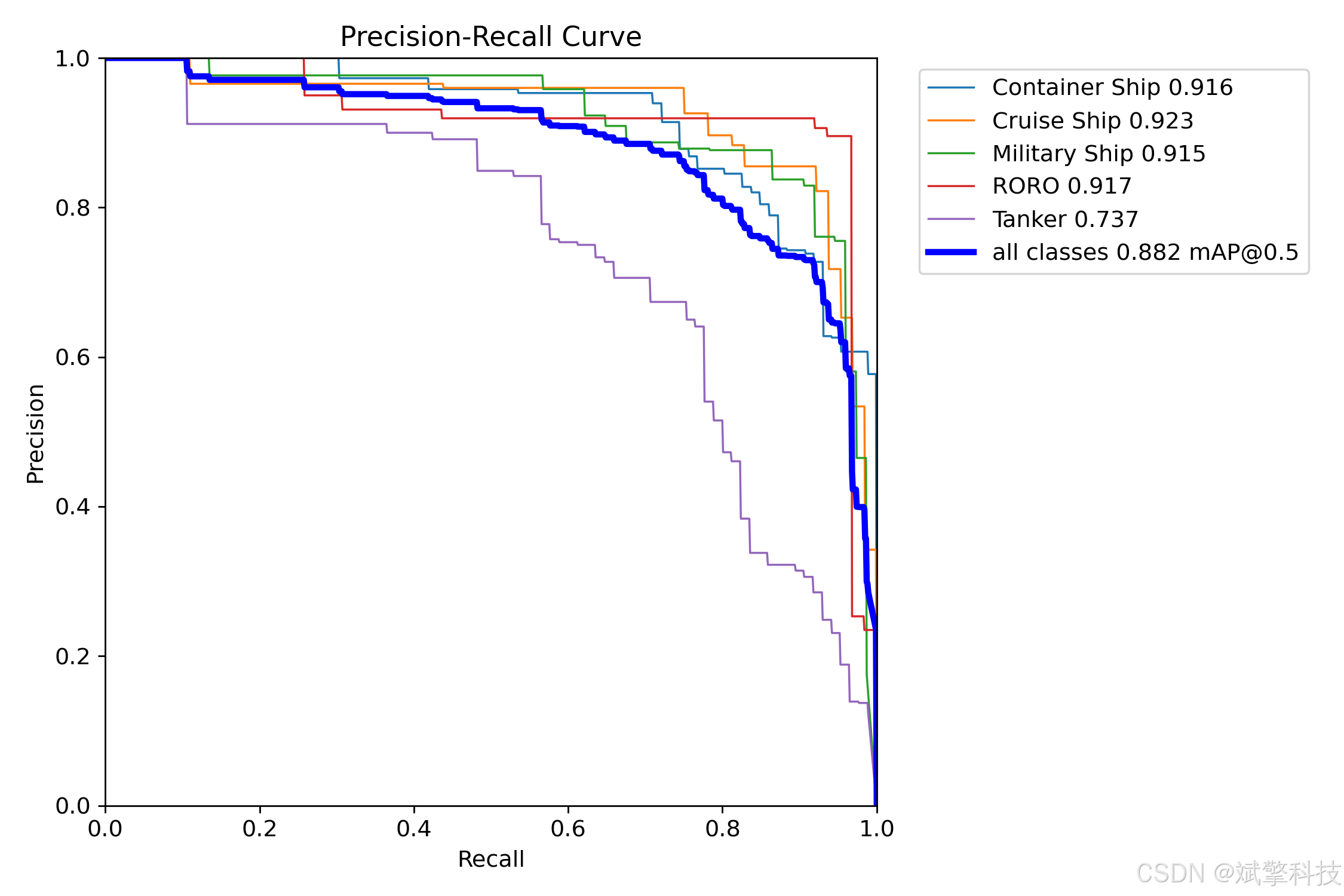
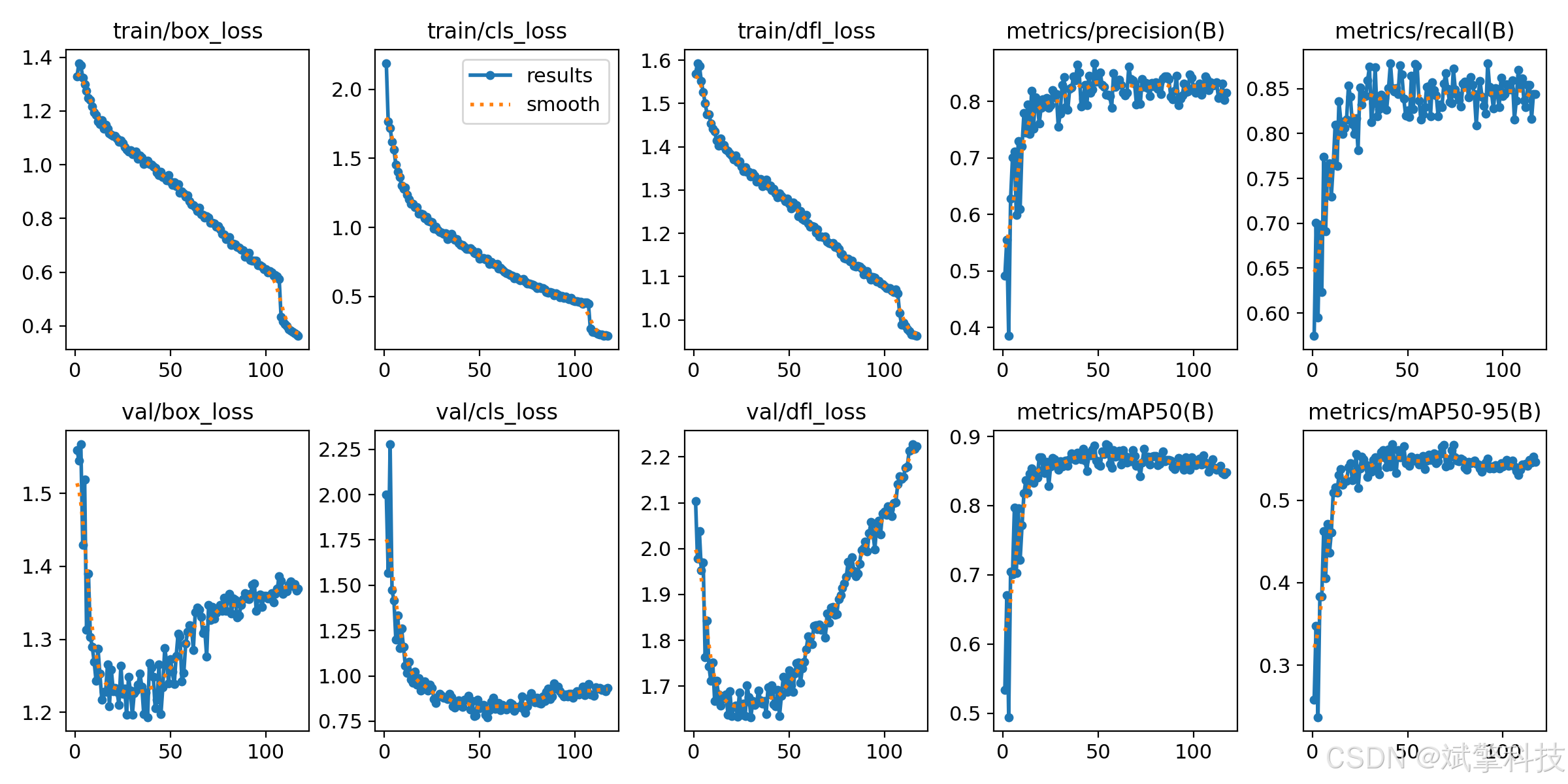
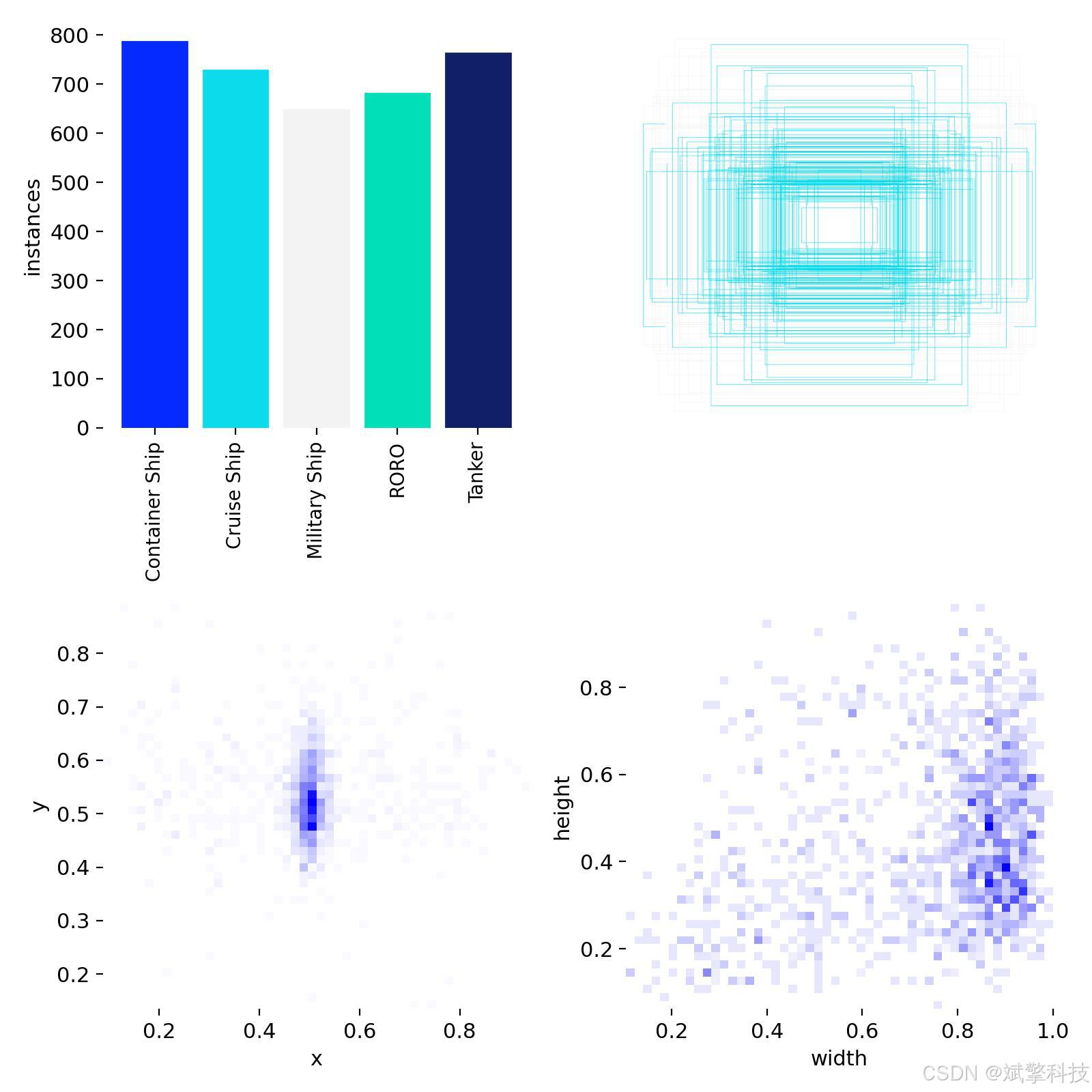
模型训练结果
#coding:utf-8
#根据实际情况更换模型
# yolon.yaml (nano):轻量化模型,适合嵌入式设备,速度快但精度略低。
# yolos.yaml (small):小模型,适合实时任务。
# yolom.yaml (medium):中等大小模型,兼顾速度和精度。
# yolob.yaml (base):基本版模型,适合大部分应用场景。
# yolol.yaml (large):大型模型,适合对精度要求高的任务。
from ultralytics import YOLO
model_path = 'pt/yolo12s.pt'
data_path = 'data.yaml'
if __name__ == '__main__':
model = YOLO(model_path)
results = model.train(data=data_path,
epochs=500,
batch=64,
device='0',
workers=0,
project='runs',
name='exp',
)



YOLO概述
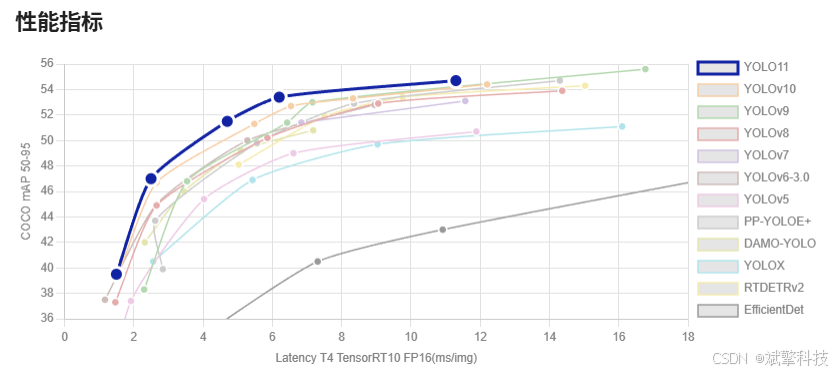
YOLOv8
YOLOv8 由 Ultralytics 于 2023 年 1 月 10 日发布,在准确性和速度方面提供了尖端性能。基于先前 YOLO 版本的进步,YOLOv8 引入了新功能和优化,使其成为各种应用中目标检测任务的理想选择。
YOLOv8 的主要特性
- 高级骨干和颈部架构: YOLOv8 采用最先进的骨干和颈部架构,从而改进了特征提取和目标检测性能。
- 无锚点分离式 Ultralytics Head: YOLOv8 采用无锚点分离式 Ultralytics head,与基于锚点的方法相比,这有助于提高准确性并提高检测效率。
- 优化的准确性-速度权衡: YOLOv8 专注于在准确性和速度之间保持最佳平衡,适用于各种应用领域中的实时对象检测任务。
- 丰富的预训练模型: YOLOv8提供了一系列预训练模型,以满足各种任务和性能要求,使您更容易为特定用例找到合适的模型。
YOLOv10
YOLOv10 由 清华大学研究人员基于 Ultralytics Python构建,引入了一种新的实时目标检测方法,解决了先前 YOLO 版本中存在的后处理和模型架构缺陷。通过消除非极大值抑制 (NMS) 并优化各种模型组件,YOLOv10 以显著降低的计算开销实现了最先进的性能。大量实验表明,它在多个模型尺度上都具有卓越的精度-延迟权衡。
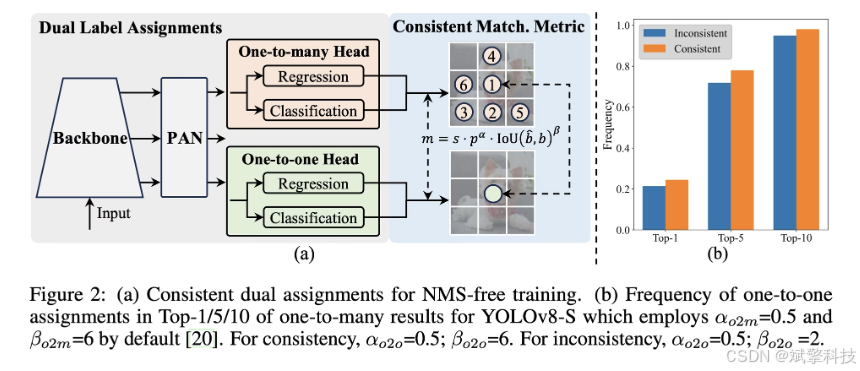
概述
实时目标检测旨在以低延迟准确预测图像中的对象类别和位置。YOLO 系列因其在性能和效率之间的平衡而一直处于这项研究的前沿。然而,对 NMS 的依赖和架构效率低下阻碍了最佳性能。YOLOv10 通过引入用于无 NMS 训练的一致双重分配和整体效率-准确性驱动的模型设计策略来解决这些问题。
架构
YOLOv10 的架构建立在之前 YOLO 模型优势的基础上,同时引入了几项关键创新。该模型架构由以下组件组成:
- 骨干网络:负责特征提取,YOLOv10 中的骨干网络使用增强版的 CSPNet (Cross Stage Partial Network),以改善梯度流并减少计算冗余。
- Neck:Neck 的设计目的是聚合来自不同尺度的特征,并将它们传递到 Head。它包括 PAN(路径聚合网络)层,用于有效的多尺度特征融合。
- One-to-Many Head:在训练期间为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
- 一对一头部:在推理时为每个对象生成一个最佳预测,以消除对NMS的需求,从而降低延迟并提高效率。
主要功能
- 免NMS训练:利用一致的双重分配来消除对NMS的需求,从而降低推理延迟。
- 整体模型设计:从效率和准确性的角度对各种组件进行全面优化,包括轻量级分类 Head、空间通道解耦下采样和秩引导块设计。
- 增强的模型功能: 结合了大内核卷积和部分自注意力模块,以提高性能,而无需显着的计算成本。
YOLOv11
YOLO11 是 Ultralytics YOLO 系列实时目标检测器的最新迭代版本,它以前沿的精度、速度和效率重新定义了可能性。YOLO11 在之前 YOLO 版本的显著进步基础上,在架构和训练方法上进行了重大改进,使其成为各种计算机视觉任务的多功能选择。
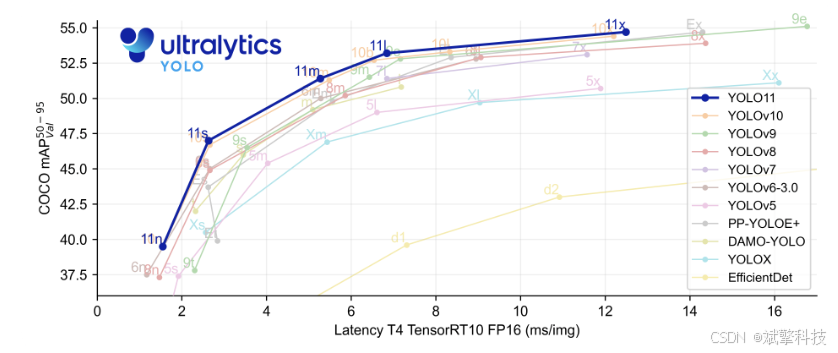
主要功能
- 增强的特征提取: YOLO11 采用改进的 backbone 和 neck 架构,从而增强了特征提取能力,以实现更精确的目标检测和复杂的任务性能。
- 优化效率和速度: YOLO11 引入了改进的架构设计和优化的训练流程,从而提供更快的处理速度,并在精度和性能之间保持最佳平衡。
- 更高精度,更少参数: 随着模型设计的进步,YOLO11m 在 COCO 数据集上实现了更高的 平均精度均值(mAP),同时比 YOLOv8m 少用 22% 的参数,在不牺牲精度的情况下提高了计算效率。
- 跨环境的适应性: YOLO11 可以无缝部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统,从而确保最大的灵活性。
- 广泛支持的任务范围: 无论是目标检测、实例分割、图像分类、姿势估计还是旋转框检测 (OBB),YOLO11 都旨在满足各种计算机视觉挑战。
Ultralytics YOLO11 在其前代产品的基础上进行了多项重大改进。主要改进包括:
- 增强的特征提取: YOLO11 采用了改进的骨干网络和颈部架构,增强了特征提取能力,从而实现更精确的目标检测。
- 优化的效率和速度: 改进的架构设计和优化的训练流程提供了更快的处理速度,同时保持了准确性和性能之间的平衡。
- 更高精度,更少参数: YOLO11m 在 COCO 数据集上实现了更高的平均 精度均值 (mAP),同时比 YOLOv8m 少用 22% 的参数,在不牺牲精度的情况下提高了计算效率。
- 跨环境的适应性: YOLO11 可以部署在各种环境中,包括边缘设备、云平台和支持 NVIDIA GPU 的系统。
- 广泛支持的任务范围: YOLO11 支持各种计算机视觉任务,例如目标检测、实例分割、图像分类、姿势估计和旋转框检测 (OBB)。
YOLOv12
YOLO12引入了一种以注意力为中心的架构,它不同于之前YOLO模型中使用的传统基于CNN的方法,但仍保持了许多应用所需的实时推理速度。该模型通过在注意力机制和整体网络架构方面的新颖方法创新,实现了最先进的目标检测精度,同时保持了实时性能。尽管有这些优势,YOLO12仍然是一个社区驱动的版本,由于其沉重的注意力模块,可能表现出训练不稳定、内存消耗增加和CPU吞吐量较慢的问题,因此Ultralytics仍然建议将YOLO11用于大多数生产工作负载。
主要功能
- 区域注意力机制: 一种新的自注意力方法,可以有效地处理大型感受野。它将 特征图 分成 l 个大小相等的区域(默认为 4 个),水平或垂直,避免复杂的运算并保持较大的有效感受野。与标准自注意力相比,这大大降低了计算成本。
- 残差高效层聚合网络(R-ELAN):一种基于 ELAN 的改进的特征聚合模块,旨在解决优化挑战,尤其是在更大规模的以注意力为中心的模型中。R-ELAN 引入:
- 具有缩放的块级残差连接(类似于层缩放)。
- 一种重新设计的特征聚合方法,创建了一个类似瓶颈的结构。
- 优化的注意力机制架构:YOLO12 精简了标准注意力机制,以提高效率并与 YOLO 框架兼容。这包括:
- 使用 FlashAttention 来最大限度地减少内存访问开销。
- 移除位置编码,以获得更简洁、更快速的模型。
- 调整 MLP 比率(从典型的 4 调整到 1.2 或 2),以更好地平衡注意力和前馈层之间的计算。
- 减少堆叠块的深度以改进优化。
- 利用卷积运算(在适当的情况下)以提高其计算效率。
- 在注意力机制中添加一个7x7可分离卷积(“位置感知器”),以隐式地编码位置信息。
- 全面的任务支持: YOLO12 支持一系列核心计算机视觉任务:目标检测、实例分割、图像分类、姿势估计和旋转框检测 (OBB)。
- 增强的效率: 与许多先前的模型相比,以更少的参数实现了更高的准确率,从而证明了速度和准确率之间更好的平衡。
- 灵活部署: 专为跨各种平台部署而设计,从边缘设备到云基础设施。
主要改进
-
增强的 特征提取:
- 区域注意力: 有效处理大型感受野,降低计算成本。
- 优化平衡: 改进了注意力和前馈网络计算之间的平衡。
- R-ELAN:使用 R-ELAN 架构增强特征聚合。
-
优化创新:
- 残差连接:引入具有缩放的残差连接以稳定训练,尤其是在较大的模型中。
- 改进的特征集成:在 R-ELAN 中实现了一种改进的特征集成方法。
- FlashAttention: 整合 FlashAttention 以减少内存访问开销。
-
架构效率:
- 减少参数:与之前的许多模型相比,在保持或提高准确性的同时,实现了更低的参数计数。
- 简化的注意力机制:使用简化的注意力实现,避免了位置编码。
- 优化的 MLP 比率:调整 MLP 比率以更有效地分配计算资源。
前端代码展示
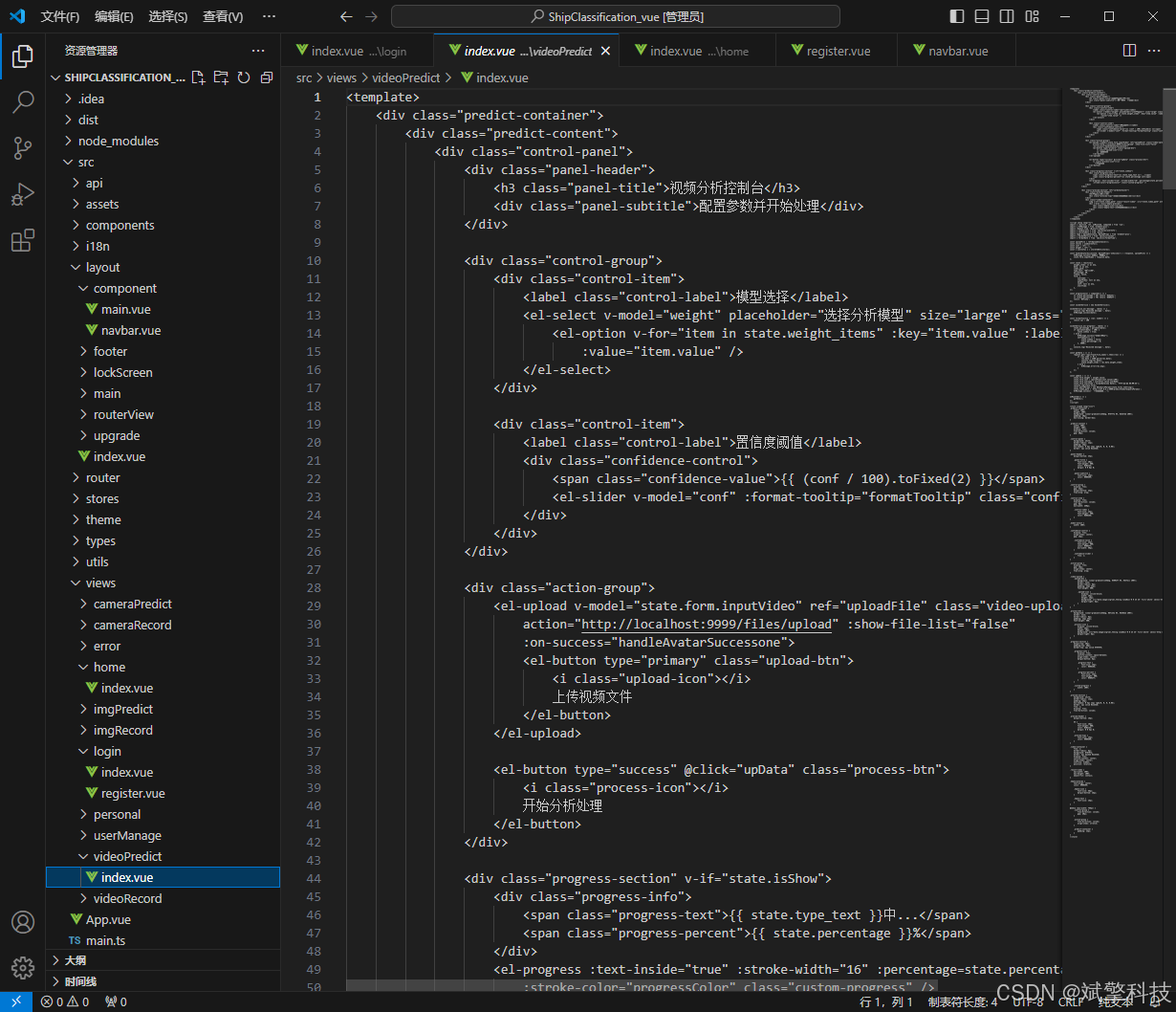
视频检测界面一小部分代码:
<template>
<div class="predict-container">
<div class="predict-content">
<div class="control-panel">
<div class="panel-header">
<h3 class="panel-title">视频分析控制台</h3>
<div class="panel-subtitle">配置参数并开始处理</div>
</div>
<div class="control-group">
<div class="control-item">
<label class="control-label">模型选择</label>
<el-select v-model="weight" placeholder="选择分析模型" size="large" class="model-select">
<el-option v-for="item in state.weight_items" :key="item.value" :label="item.label"
:value="item.value" />
</el-select>
</div>
<div class="control-item">
<label class="control-label">置信度阈值</label>
<div class="confidence-control">
<span class="confidence-value">{{ (conf / 100).toFixed(2) }}</span>
<el-slider v-model="conf" :format-tooltip="formatTooltip" class="confidence-slider" />
</div>
</div>
</div>
<div class="action-group">
<el-upload v-model="state.form.inputVideo" ref="uploadFile" class="video-upload"
action="http://localhost:9999/files/upload" :show-file-list="false"
:on-success="handleAvatarSuccessone">
<el-button type="primary" class="upload-btn">
<i class="upload-icon"></i>
上传视频文件
</el-button>
</el-upload>
<el-button type="success" @click="upData" class="process-btn">
<i class="process-icon"></i>
开始分析处理
</el-button>
</div>
<div class="progress-section" v-if="state.isShow">
<div class="progress-info">
<span class="progress-text">{{ state.type_text }}中...</span>
<span class="progress-percent">{{ state.percentage }}%</span>
</div>
<el-progress :text-inside="true" :stroke-width="16" :percentage=state.percentage
:stroke-color="progressColor" class="custom-progress" />
</div>
</div>
<div class="preview-section" ref="cardsContainer">
<div class="preview-header">
<h4>分析结果预览</h4>
<div class="preview-tips">处理后的视频将在此显示</div>
</div>
<div class="video-container">
<img v-if="state.video_path" class="result-video" :src="state.video_path" alt="分析结果">
<div v-else class="empty-preview">
<div class="empty-icon">📹</div>
<div class="empty-text">等待视频处理结果</div>
</div>
</div>
</div>
</div>
</div>
</template>
<script setup lang="ts">
import { reactive, ref, onMounted, computed } from 'vue';
import { ElMessage } from 'element-plus';
import request from '/@/utils/request';
import { useUserInfo } from '/@/stores/userInfo';
import { storeToRefs } from 'pinia';
import type { UploadInstance, UploadProps } from 'element-plus';
import { SocketService } from '/@/utils/socket';
import { formatDate } from '/@/utils/formatTime';
const uploadFile = ref<UploadInstance>();
const stores = useUserInfo();
const conf = ref('');
const weight = ref('');
const { userInfos } = storeToRefs(stores);
const handleAvatarSuccessone: UploadProps['onSuccess'] = (response, uploadFile) => {
ElMessage.success('视频上传成功!');
state.form.inputVideo = response.data;
};
const state = reactive({
weight_items: [] as any,
data: {} as any,
video_path: '',
type_text: "正在保存",
percentage: 50,
isShow: false,
form: {
username: '',
inputVideo: null as any,
weight: '',
conf: null as any,
startTime: ''
},
});
const progressColor = computed(() => {
if (state.percentage < 30) return '#e6a23c';
if (state.percentage < 70) return '#409eff';
return '#67c23a';
});
const socketService = new SocketService();
socketService.on('message', (data) => {
console.log('Received message:', data);
ElMessage.success(data);
});
const formatTooltip = (val: number) => {
return val / 100
}
socketService.on('progress', (data) => {
state.percentage = parseInt(data);
if (parseInt(data) < 100) {
state.isShow = true;
} else {
ElMessage.success("处理完成!");
setTimeout(() => {
state.isShow = false;
state.percentage = 0;
}, 2000);
}
console.log('Received message:', data);
});
const getData = () => {
request.get('/api/flask/file_names').then((res) => {
if (res.code == 0) {
res.data = JSON.parse(res.data);
console.log(res.data);
state.weight_items = res.data.weight_items;
} else {
ElMessage.error(res.msg);
}
});
};后端代码展示
详细功能展示视频
基于YOLO和千问|DeepSeek的船舶类型检测系统(web界面+YOLOv8/YOLOv10/YOLOv11/YOLOv12+深度学习+python)_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV15Zc4zpETo/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献236条内容
已为社区贡献236条内容

所有评论(0)