CVPR 2024论文Koala介绍
Koala:关键帧条件长视频大语言模型
一、现有方法的问题
现有 vLLMs 虽在数百万秒级短视频上完成预训练,具备多模态感知和常识推理的涌现能力,但面对分钟级长视频时存在两大关键缺陷:
- 粗采样关键帧会丢失细粒度时空信息,导致长时时间推理性能差;
- 分段输入关键帧的方式,仅能聚合段内时空信息,无法建立段间的上下文关联,难以对长视频形成整体理解。
二、本文创新点
- 首次提出稀疏关键帧条件化的长视频理解范式
- 进一步引入了条件片段(CS)和条件视频(CV)分词器函数
- 提出任务无关的视觉令牌生成方法,兼容基础 LLM 的语义空间

Koala 方法的核心可视化对比示例,直观展示了它在长视频理解上的优势:
- 输入场景
长视频:一段 3 分钟的手工制作视频,图中截取了 4 个关键时间点的画面(45s、90s、135s、180s),内容是人物在制作笔记本封面。
选择题:要求根据视频动作判断人物的总体目标,并给出 5 个候选答案。
结果
- Koala(本文方法)
- 注意力可视化:右侧上方热力图显示,模型的注意力高度集中在核心操作区域(手、纸张 / 笔记本、关键工具),能精准捕捉到 “制作笔记本封面” 的完整流程信息。
- 预测结果:成功的选出了正确选项”制作笔记本封面“
- 传统短视频vLLM
- 注意力可视化:右侧下方热力图显示,注意力分散在无关区域(如桌面、背景物品),无法聚焦到核心动作和长期目标上。
- 预测结果:错误选择了”绘制一幅详细草图“
- 这张图直观证明了 Koala 方法的两大优势:
- 全局上下文感知:通过稀疏采样的关键帧,模型能建立 3 分钟长视频的整体逻辑,理解 “制作笔记本封面” 的最终目标,而非局限于局部 “画画” 动作。
- 精准注意力聚焦:相比传统短视频模型,Koala 的注意力更集中在与任务相关的视觉区域,避免了背景干扰,从而做出更准确的推理。
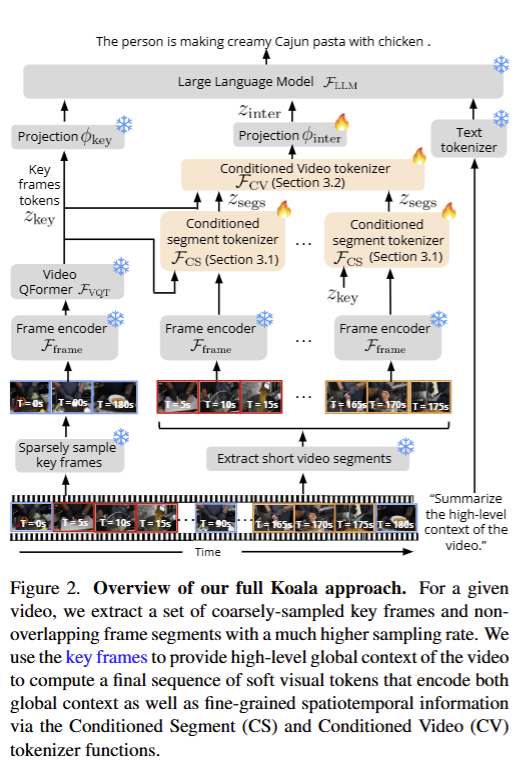
Koala 模型的整体架构流程图
- 输入视频与预处理
- 长视频输入:一段完整的长视频(示例为 “制作奶油卡真鸡肉意面” 的烹饪视频),时间轴从 T=0s 到 T=180s。
- 两路采样策略:
稀疏关键帧采样:从长视频中粗粒度采样少量关键帧(如 T=0s、T=90s、T=180s),用于提供全局上下文。
短片段提取:将长视频切分为多个非重叠的短视频段(如 T=5s15s、T=165s175s),每个片段采用高采样率提取帧,用于补充细粒度时空信息。
- 视觉特征编码(中间层)
- 关键帧编码
稀疏采样的关键帧先经过 Frame encoder(帧编码器)提取视觉特征,再输入 Video QFormer FVQT\mathcal{F}_{VQT}FVQT 生成关键帧令牌 zkeyz_{key}zkey
,最后通过 Projection ϕkey\phi_{key}ϕkey 投影,为后续模块提供全局上下文。 - 短视频段编码
每个短视频段也经过各自的 Frame encoder 提取特征,然后输入 Conditioned Segment tokenizer FCS\mathcal{F}_{CS}FCS(段级条件化分词器)。
- 跨段时空聚合
所有段令牌 zsegsz_{segs}zsegs 会输入 Conditioned Video tokenizer FCV\mathcal{F}_{CV}FCV(视频级条件化分词器):
- FCV\mathcal{F}_{CV}FCV 引入可学习的时间查询向量和概念查询向量,在视频级别建模不同片段之间的时空关联,生成融合了全局上下文 + 局部细粒度 + 段间逻辑的段间令牌 zinterz_{inter}zinter
- zinterz_{inter}zinter 再经过 Projection ϕinter\phi_{inter}ϕinter 投影,准备输入大语言模型。
- 文本交互与推理
- 文本指令(如 “Summarize the high-level context of the video.”)通过 Text tokenizer 编码为文本令牌。
- 最终将 文本令牌 + 关键帧令牌 zsegsz_{segs}zsegs + 段间令牌 zinterz_{inter}zinter 拼接后,输入 Large Language Model FLLM\mathcal{F}_{LLM}FLLM
进行推理。 - 模型输出自然语言答案(示例中为 “The person is making creamy Cajun pasta with chicken.”),完成长视频问答 / 总结任务。
三、具体方法
3.1. 条件片段分词器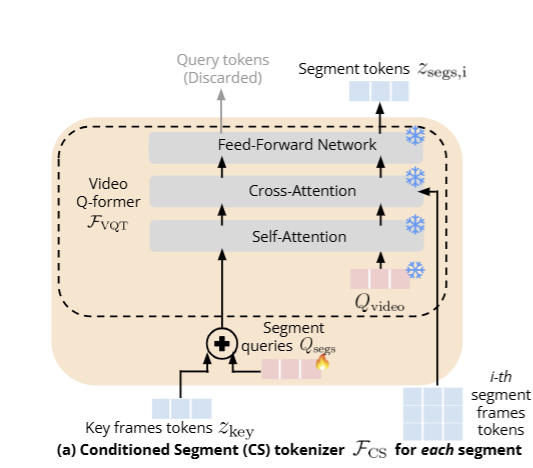
CS分词器的内部结构
- 输入
- 关键帧令牌zkeyz_{key}zkey 来自稀疏采样的全局关键帧,提供视频的全局上下文(告诉模型 “视频在做什么”
- 第 i 个片段帧令牌:来自当前短视频段的高采样率帧特征,提供局部细粒度时空信息,告诉模型 “这一步在做什么”
- 片段查询 QsegsQ_{segs}Qsegs:可学习的查询向量(火焰图标表示可训练),用于提取当前片段的核心视觉概念。
- 冻结视频查询 :来自预训练 Video QFormer 的固定查询(雪花图标表示参数冻结),复用预训练的时空聚合能力。
- 核心融合步骤
- 将关键帧令牌 与 片段查询相加,得到以全局上下文为条件的片段查询。目的:让局部查询在提取视觉概念时,始终对齐视频的全局目标,避免关注无关细节。
- Video QFormer 处理流程
Self-Attention(自注意力):让条件化片段查询内部建模关系,学习如何聚焦局部关键信息。
Cross-Attention(交叉注意力):从片段帧特征中,筛选出与全局上下文最相关的细粒度时空信息,同时复用预训练的聚合逻辑。
Feed-Forward Network(前馈网络):对注意力结果做非线性变换,进一步提炼视觉概念。
- 输出与丢弃
- 有效输出:Segment tokens zsegs,iz_{segs , i}zsegs,i
—— 融合了全局上下文的当前片段视觉令牌,用于后续跨片段建模。 - 丢弃输出:上方的 Query tokens —— 这是查询本身的更新结果,不再需要,直接丢弃。
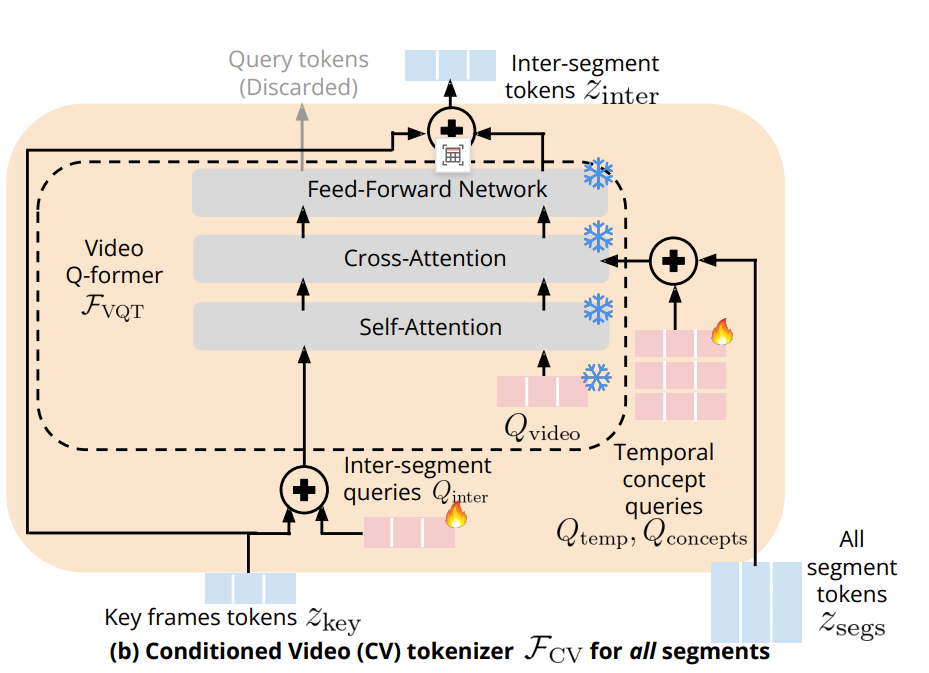
Conditioned Video (CV) 分词器负责对所有视频片段进行跨段时空聚合,是实现长视频理解的核心模块。
输入:
- 关键帧令牌zkeyz_{key}zkey:来自稀疏采样的全局关键帧,提供视频的高层语义与全局上下文。
- 所有片段令牌zsegsz_{segs}zsegs:来自 CS 分词器的输出,已融合全局上下文和各片段的细粒度视觉信息。
- 段间查询QinterQ_{inter}Qinter:用于引导跨片段的信息聚合。
- 时序 / 概念查询:分别建模片段间的时序关系与视觉概念关联。
- 冻结视频查询QvideoQ_{video}Qvideo 来自预训练 Video QFormer,复用其时空聚合能力
核心计算流程
1. 条件化查询生成
- 将zkeyz_{key}zkey 与可学习的段间查询QinterQ_{inter}Qinter 相加,得到以全局上下文为条件的段间查询。
- 将 zsegsz_{segs}zsegs与可学习的时序/概念查询 ( Q_{\text{temp}}, Q_{\text{concepts}} ) 相加,得到融合局部视觉、时序与概念信息的查询。
2. Video QFormer 处理
冻结的 Video QFormer FVQT\mathcal{F}_{VQT}FVQT依次执行:
- Self-Attention(自注意力):让条件化查询内部建模关系,学习跨片段的关联模式。
- Cross-Attention(交叉注意力):以条件化查询为引导,与 QinterQ_{inter}Qinter 做交叉注意力,聚合所有片段的时空信息,同时对齐全局上下文。
- Feed-Forward Network(前馈网络):对注意力结果做非线性变换,提炼最终的跨段视觉概念。
3. 输出与丢弃
- 有效输出:段间令牌zinterz_{inter}zinter —— 融合了全局上下文、局部片段、时序关系与概念关联的最终视觉令牌,用于输入 LLM 进行长视频推理。
- 丢弃输出:上方的 Query tokens —— 查询本身的更新结果,不再需要,直接丢弃。
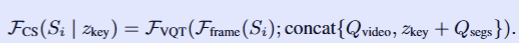
FCSF_{CS}FCS:Conditioned Segment 分词器,负责从单个视频片段提取融合全局上下文的视觉令牌
SiS_{i}Si:第 i 个短视频片段(高采样率,提供细粒度时空信息)
zkeyz_{key}zkey:关键帧令牌,来自稀疏采样的全局关键帧,提供视频的全局上下文
FVQT\mathcal{F}_{VQT}FVQT:预训练的 Video QFormer,整个模块参数冻结,仅复用其时空聚合能力
Fframe(Si)\mathcal{F}_{frame}(S_{i})Fframe(Si) :对第 i个片段 SiS_{i}Si 提取的帧级视觉特征
concat:拼接操作,将两个序列在特征维度拼接
QvideoQ_{video}Qvideo:预训练 Video QFormer 自带的冻结视频查询向量,用于聚合时空信息
QsegsQ_{segs}Qsegs:可学习的片段查询向量,用于将zkeyz_{key}zkey 适配到 Video QFormer 的查询空间
设计意图
- 只需训练少量可学习参数
- 全局约束局部,让片段特征提取始终对齐视频的整体目标
- 复用预训练知识:直接复用预训练 Video QFormer 的时空聚合能力,无需重新设计编码器
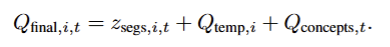
Qfinal,i,tQ_{final,i,t}Qfinal,i,t:最终查询向量,用于 CV 分词器的跨片段时空聚合,下标 i 表示第 i 个片段,t 表示时间 / 概念位置
zsegs,i,tz_{segs,i,t}zsegs,i,t:片段令牌,来自 CS 分词器的输出,已融合全局上下文和第 i 个片段的局部细粒度信息
Qtemp,iQ_{temp,i}Qtemp,i :可学习时间查询向量,用于建模片段间的时序关系
Qconcepts,tQ_{concepts,t}Qconcepts,t:可学习概念查询向量,用于建模跨片段的视觉概念关联
把三类信息 “加” 在一起,形成一个同时包含局部、时序、概念的查询向量,会作为 CV 分词器的查询,引导 Video QFormer 去跨片段聚合时空信息,最终生成能理解整个长视频的段间令牌 zinterz_{inter}zinter。
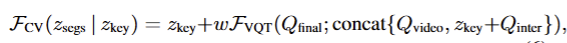
CV分词器
输入:
- 来自CS分词器的片段令牌,已经融合了全局上下文和各片段的细粒度信息
- 全局上下文zkeyz_{key}zkey:来自稀疏关键帧,提供视频的整体目标与高层语义
查询端:QfinalQ_{final}Qfinal 融合了片段视觉、时序位置和概念类别信息,用于引导 Video QFormer 关注跨片段的关键关联
键 / 值端:concat(Qvideo,zkey+Qinter)\text{concat}(Q_{video}, z_{key} + Q_{inter})concat(Qvideo,zkey+Qinter)将预训练视频查询与适配后的全局上下文拼接,让模型在聚合时始终以全局目标为约束
最终输出:段间令牌zinterz_{inter}zinter
CV 分词器是 Koala 长视频理解的最后一步: - CS 分词器:让每个片段 “看懂自己,并对齐全局”
- CV 分词器:让所有片段 “看懂彼此,形成完整长视频逻辑”
- 最终输出 :融合了全局 + 局部 + 时序 + 概念,让 LLM 能理解分钟级长视频的完整故事
我们将所引入的分词器函数FCSF_{CS}FCS和FCVF_{CV}FCV以及全局仿射变换ϕinter\phi_{inter}ϕinter的参数优化学习目标定义为预测时长至少几分钟的教学视频的高级任务标签。这一目标类似于对长视频进行简洁总结。鉴于预训练vLLM的指令微调特性,我们通过手动设计一组用于训练的查询和响应模板,将“修理汽车发动机”等高级任务标签转换为指令格式(参见补充材料)。设P为给定输入视频V的问题提示,R为其对应的响应,由M个词R={l^1,…,l^M}R = \{\hat{l}_1, \dots, \hat{l}_M\}R={l^1,…,l^M}组成(每个词均表示为独热向量)。我们最小化交叉熵损失:
L(V,P,R)=−∑j=1Ml^jlogp(lj∣l^<j,V,P)\mathcal{L}(V, P, R) = -\sum_{j=1}^M \hat{l}_j \log p(l_j | \hat{l}_{<j}, V, P)L(V,P,R)=−∑j=1Ml^jlogp(lj∣l^<j,V,P)
其中,(p(lj∣l^<j,V,P)p(l_j | \hat{l}_{<j}, V, P)p(lj∣l^<j,V,P)) 表示给定前面的真实词(l^<j\hat{l}_{<j}l^<j)时,第j个词的概率。
- 学习目标:
任务形式:本质是长视频指令微调,把 “预测视频高层任务标签” 包装成 “问答 / 摘要任务”。
训练数据:使用无精细标注的长教学视频(如 HowTo100M),仅需要粗粒度的任务标签(如 “做意面”“修引擎”)。 - 将粗粒度任务标签(如 “fix a car engine”)通过模板包装成指令对:提示P 回复R 这样就可以直接复用预训练 vLLM 的指令微调能力,无需额外标注
四、实验
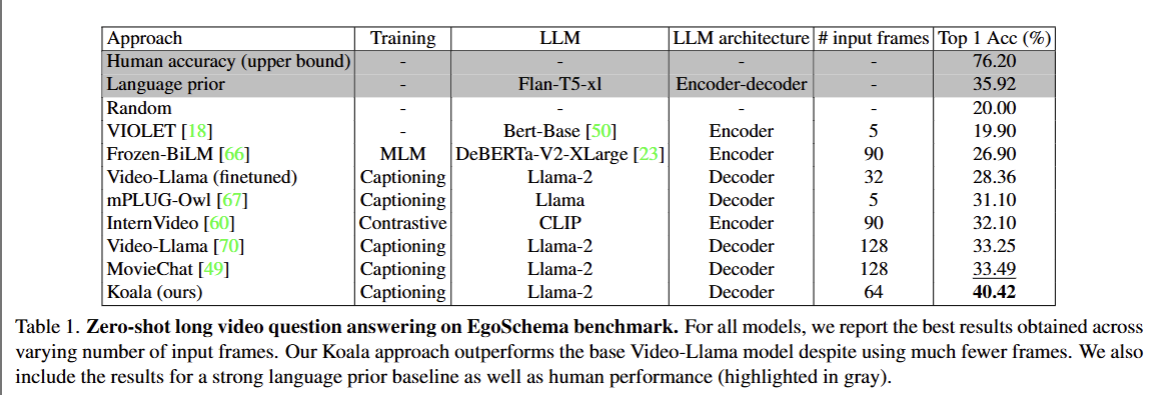
EgoSchema 长视频问答基准的零样本性能对比表,核心是展示 Koala(本文方法)在分钟级长视频理解上的优势。
Training:预训练任务类型(Captioning:字幕预训练;MLM:掩码语言建模;Contrastive:对比学习)
input frames:输入模型的视频帧数
Top 1 Acc (%):零样本问答的 Top-1 准确率
结论
- 高效利用帧数:Koala 仅用 64 帧 就取得了远超使用 128 帧的 Video-Llama 和 MovieChat 的性能,证明其稀疏关键帧 + 高采样片段的策略更高效。
- 轻量级微调优势:Koala 基于冻结的 Video-Llama 微调,仅训练 CS/CV 分词器和少量投影层,就能实现大幅性能提升。
- Koala 用更少的输入帧数,实现了当前最优的长视频零样本问答性能,是轻量级拓展预训练 vLLM 到长视频场景的成功范例
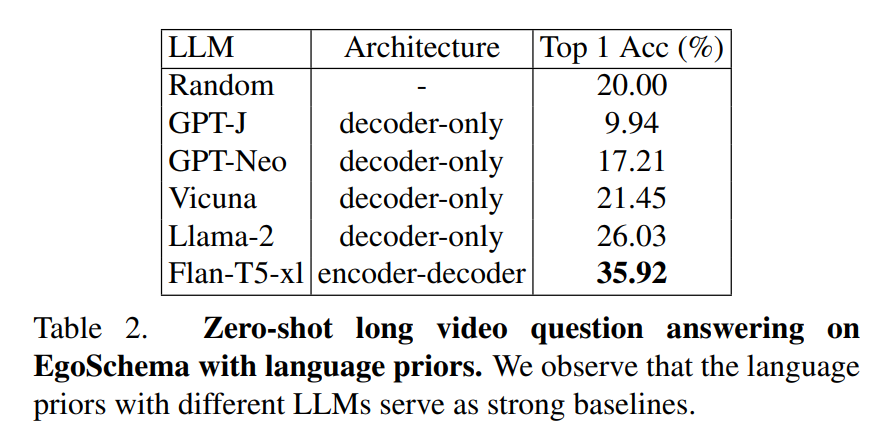
这是 EgoSchema 长视频问答任务的纯语言先验(Language prior)基线表,用于展示:在不输入任何视频信息的情况下,仅靠大语言模型(LLM)凭常识猜答案的性能。
任务:零样本长视频问答(和上一张表是同一个任务)
核心设定:不提供任何视频视觉信息,只给问题,让 LLM 直接猜答案
评价指标:Top 1 准确率(Top 1 Acc %)
- 强基线证明:纯语言模型(尤其是 Flan-T5-xl)已经能靠常识拿到 35.92% 的准确率,说明 EgoSchema 任务里有不少问题可以通过 “常识推理” 蒙对,这是一个非常强的 baseline。
- 在上一张表中,Koala 达到了 40.42%,超过了这个纯语言强基线,证明 Koala 提取的视觉信息确实有效,能给 LLM 带来额外增益,而不是只靠常识猜题
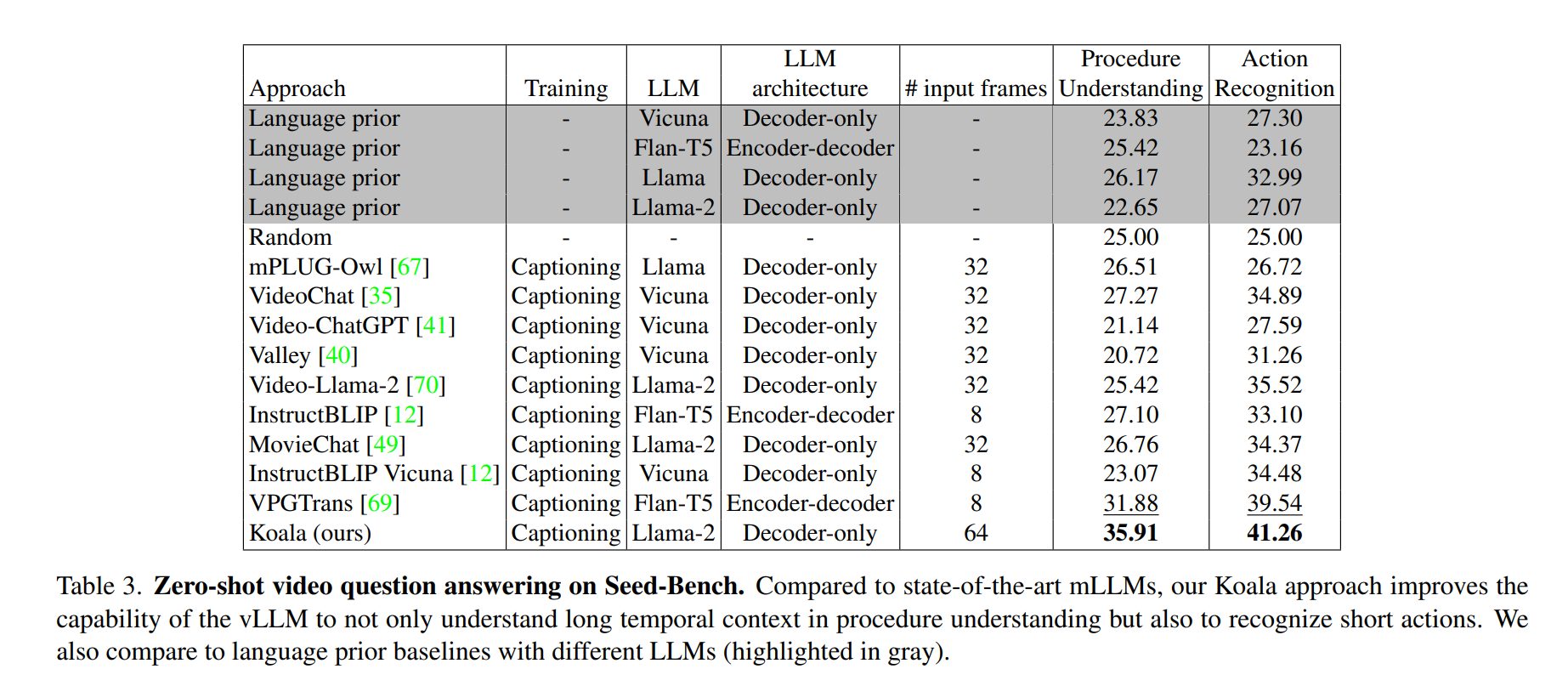
这是 Seed-Bench 视频问答基准的零样本性能对比表,用于验证 Koala 在 ** 流程理解(长时序)和动作识别(短时序)** 两个任务上的双重能力。
Procedure Understanding:理解长视频的流程 / 步骤(对应长时序能力)
Action Recognition:识别短视频中的动作(对应短时序能力)
input frames:输入模型的视频帧数
结论:发现不管是流程理解这种长时序还是动作识别这种短时序任务,koala都实现了突破;即使输入帧数(64 帧)多于部分模型(如 VPGTrans 仅 8 帧),但 Koala 的性能增益远大于帧数增加的影响,体现了其高效的时空信息聚合能力。
五、消融实验
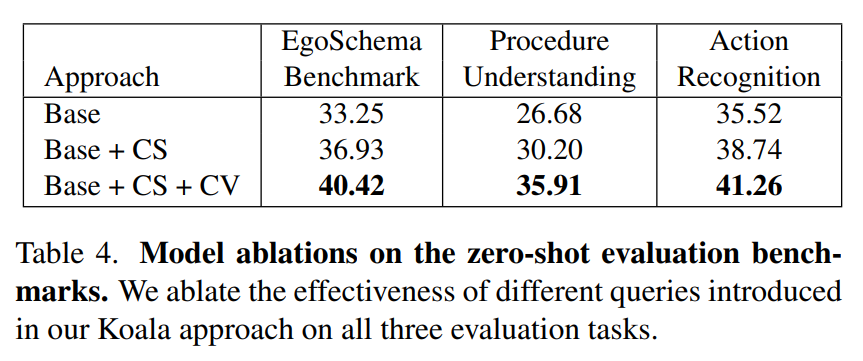
本图表验证 CS 分词器和 CV 分词器这两个核心模块的有效性,在三个任务上分别测试性能:
• EgoSchema Benchmark:长视频零样本问答(验证长时序理解)
• Procedure Understanding:长视频流程理解(验证步骤逻辑)
• Action Recognition:短视频动作识别(验证细粒度动作)
这张消融实验直观验证了 Koala 的设计有效性:
- CS 分词器:让局部片段信息对齐全局上下文,是性能提升的基础。
- CV 分词器:建模跨片段的时序与概念关联,是实现长视频理解的关键。
- 模块协同:CS + CV 共同作用,在长视频任务上实现了最大幅度的性能跃升,同时也保持了对短视频动作识别的增益。
 Koala 在 EgoSchema 长视频问答任务上的补充消融实验表,用于验证三个关键设计细节的有效性:
Koala 在 EgoSchema 长视频问答任务上的补充消融实验表,用于验证三个关键设计细节的有效性:
- 是否保留zkeyz_{key}zkey输出令牌
- CS 分词器是否以 QtempQ_{temp}Qtemp为条件
- 是否引入时序 / 概念查询QtempQ_{temp}Qtemp, QconceptsQ_{concepts}Qconcepts
结论: - 丢弃zkeyz_{key}zkey是必要的,保留会冗余,降低性能
- 用全局上下文 zkeyz_{key}zkey约束 CS 分词器是核心增益
- 引入时序/概念查询是长视频推理的关键
 这是 Koala 在 EgoSchema 长视频问答任务上的时序上下文聚合方式对比表,核心验证:在输入 LLM 之前先聚合视频令牌(pre-LLM 聚合),比直接把所有片段令牌丢给 LLM 让它自己处理(post-LLM 聚合)效果更好。
这是 Koala 在 EgoSchema 长视频问答任务上的时序上下文聚合方式对比表,核心验证:在输入 LLM 之前先聚合视频令牌(pre-LLM 聚合),比直接把所有片段令牌丢给 LLM 让它自己处理(post-LLM 聚合)效果更好。
- Base(原始模型):无聚合,直接用原始短视频建模方式
- Average(平均池化聚合):pre-LLM 聚合,对所有片段令牌做平均池化
- Memory module (MovieChat):pre-LLM 聚合,用记忆模块建模长时序
- Concatenation(直接拼接):不做 pre-LLM 聚合,直接把所有片段令牌拼接后输入 LLM(post-LLM 聚合
- Koala (ours):pre-LLM 聚合,用 CS + CV 分词器做条件化时空聚合
结论:
- pre-LLM 聚合更有效:Koala 和 Memory module 这类在输入 LLM 前先聚合的方法,整体表现优于直接拼接(Concatenation)。
- 智能聚合 > 简单聚合:Koala 的条件化时空聚合(CS + CV)远优于平均池化(Average)和记忆模块(MovieChat),证明了全局上下文 + 时序 / 概念建模的重要性。
- LLM 不是万能的:直接把长序列丢给 LLM 让它自己处理,效果不如先在视觉端做好高效聚合,这也是 Koala 轻量级微调的核心优势。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)