《动手学深度学习》-68transformer实现
一、transformer
1. 核心思想与历史地位
-
诞生背景: 在 Transformer 之前,处理序列数据(如文本)主要用 RNN 或 LSTM。RNN 必须按顺序一个词一个词地处理,导致无法并行计算,且在长文本中存在信息遗忘问题。
-
Transformer 的革命性: 彻底抛弃了 RNN 的循环结构,完全依赖注意力机制(Attention)。
-
两大核心优势:
-
高度并行化: 一次性看懂整句话,训练速度极快。
-
全局视野: 无论两个词隔得多远,在模型眼里的距离都是O(1),完美解决长依赖问题。
-
这份笔记是前一篇《多头注意力机制》的进阶篇。如果说多头注意力是汽车的发动机,那么 Transformer 就是整辆汽车。
它由 Google 在 2017 年的神作论文 Attention Is All You Need 中提出,不仅彻底颠覆了 NLP(自然语言处理)领域,现在也成为了 CV(计算机视觉)、音频等领域的绝对霸主。
2. 宏观架构:Encoder-Decoder
Transformer 最初是为了机器翻译设计的,因此采用了经典的“编码器-解码器”架构。
-
Encoder (编码器): 负责阅读源语言(如英文输入),提取出包含深层语义和上下文信息的特征向量。
-
Decoder (解码器): 根据 Encoder 提取的特征,结合之前已经生成的词,一个接一个地预测出目标语言(如中文输出)。
(注:现在的很多大模型不再用完整的 Encoder-Decoder 架构,比如 ChatGPT 只用了 Decoder,BERT 只用了 Encoder,但它们的内部组件是完全一样的。)
3. 庖丁解牛:Transformer 的四大核心组件
组件 A:输入处理层 (Input & Positional Encoding)
因为模型没有了 RNN,所有词是同时喂给模型的,模型根本不知道词的先后顺序(对它来说,“狗咬人”和“人咬狗”是一样的)。
-
Word Embedding (词嵌入): 将离散的单词映射成连续的高维向量(比如 512 维)。
-
Positional Encoding (位置编码) : 给每个单词的向量加上一个位置标签。
-
论文中使用正弦和余弦函数生成位置向量:
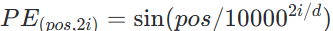
-
输入 = 词向量 + 位置向量。这样模型不仅知道“是什么词”,还知道“词在哪里”。
-
组件 B:编码器 (Encoder Block)
Encoder 由N个相同的层堆叠而成。每层包含两个子层:
(1)Multi-Head Self-Attention (多头自注意力):
让句子中的每个词都和其他词进行交互。比如“The animal didn't cross the street because it was too tired.”,Attention 会让 "it" 对 "animal" 产生极高的注意力权重。
(2)Feed Forward Network (前馈神经网络 - FFN):
包含两个线性层和一个 ReLU 激活函数。如果说 Attention 是在做信息的聚合,那么 FFN 就是在每个词的独立维度上做特征的非线性变换与记忆提取。
Add (残差连接): ![]()
防止网络太深导致梯度消失。
Norm (层归一化 Layer Normalization): 将数据标准化,让模型训练更稳定、收敛更快。
组件 C:解码器 (Decoder Block)
Decoder 同样由N个相同的层堆叠而成。相比 Encoder,它多了一个子层:
-
Masked Multi-Head Self-Attention (掩码多头自注意力):
-
为什么加 Mask? Decoder 是做生成任务的(预测下一个词)。在训练时,我们不能让模型“偷看”到未来的词。
-
做法: 利用一个下三角矩阵,把当前词之后的词的注意力权重全部设为负无穷(Softmax 后变成 0)。
-
-
Cross-Attention (交叉注意力) 🔑:
-
这是 Encoder 和 Decoder 沟通的桥梁。
-
Query (Q): 来自 Decoder 的上一层输出(代表“我已经生成了这些,我现在需要什么信息?”)。
-
Key (K) 和 Value (V): 来自 Encoder 的最终输出(代表“源文本的所有信息都在这,你随便查”)。
-
-
Feed Forward Network (前馈神经网络): 同 Encoder。
组件 D:输出层 (Output Layer)
Linear 层: 将 Decoder 的最后输出映射到词汇表大小的维度(比如有 3 万个汉字,输出维度就是 30000)。
Softmax 层: 将上述向量转化为概率分布,概率最大的那个字就是当前预测出的字。
二、代码
import torch
import math
import d2l
from torch import nn
import pandas as pd
import test_68Multihead
import test_67selfattention
from test_60en_decorder import EncoderDecoder
import test_62seq2seq
import test_60translate
#基于位置的前馈网络
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_output, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dese1=nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dese2=nn.Linear(ffn_num_hiddens, ffn_num_output)
def forward(self, x):
return self.dese2(self.relu(self.dese1(x)))
class AddNorm(nn.Module):
def __init__(self, normalized_shape, dropout,**kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X,Y):
return self.ln(X+self.dropout(Y))
class EncoderBlock(nn.Module):
def __init__(self,key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,use_bias=False,**kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention=test_68Multihead.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout,use_bias)
self.addnorm1=AddNorm(norm_shape,dropout)
self.ffn=PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)
self.addnorm2=AddNorm(norm_shape,dropout)
def forward(self,X,valid_lens):
Y=self.addnorm1(X,self.attention(X,X,X,valid_lens))
return self.addnorm2(Y,self.ffn(Y))
class TransformerEncoder(nn.Module):
def __init__(self,vocab_size,key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,
num_heads,num_layers,dropout,use_bias=False,**kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens=num_hiddens
self.embedding=nn.Embedding(vocab_size,num_hiddens)
self.post_encoding=test_67selfattention.PositionalEncoding(num_hiddens,dropout)
self.blks=nn.Sequential()
for i in range(num_layers):
self.blks.add_module('block'+str(i),EncoderBlock(key_size,query_size,value_size,num_hiddens,norm_shape,
ffn_num_input,ffn_num_hiddens,num_heads,dropout,False))
def forward(self,X,valid_lens,*args):
X=self.post_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))
self.attention_weight=[None]*len(self.blks)
for i,blk in enumerate(self.blks):
X=blk(X,valid_lens)
self.attention_weight[i]=blk.attention.attention_weight
return X
class DecoderBlock(nn.Module):
def __init__(self,key_size,query_size,value_size,num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,i,**kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i=i
self.attention1=test_68Multihead.MultiHeadAttention(key_size,query_size,value_size,num_hiddens,num_heads,dropout)
self.addnorm1=AddNorm(norm_shape,dropout)
self.attention2 = test_68Multihead.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads,
dropout)
self.ffn=PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)
self.addnorm2=AddNorm(norm_shape,dropout)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self,X,state):
enc_outputs,enc_valid_lens=state[0],state[1]
if state[2][self.i] is None:
key_values=X
else:
key_values=torch.cat((state[2][self.i],X),axis=1)
state[2][self.i]=key_values
if self.training:
batch_size,num_steps,_=X.shape
dec_valid_lens=torch.arange(1,num_steps+1,device=X.device).repeat(batch_size,1)
else:
dec_valid_lens=None
X2=self.attention1(X,key_values,key_values,dec_valid_lens)
Y=self.addnorm1(X,X2)
Y2=self.attention2(Y,enc_outputs,enc_outputs,enc_valid_lens)
Z=self.addnorm2(Y,self.Y2)
return self.addnorm3(Z,self.ffn(Z)),state
class TransformerDecoder(nn.Module):
def __init__(self,vocab_size,key_size,query_size,value_size,
num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout,**kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens=num_hiddens
self.layers=num_layers
self.embedding=nn.Embedding(vocab_size,num_hiddens)
self.post_encoding=test_67selfattention.PositionalEncoding(num_hiddens,dropout)
self.blks=nn.Sequential()
for i in range(num_layers):
self.blks.add_module('block' + str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads,dropout,i))
self.dense=nn.Linear(num_hiddens,vocab_size)
def init_state(self,enc_outputs,enc_valid_lens,*args):
return [enc_outputs,enc_valid_lens,[None]*self.num_layers]
def forward(self,X,state):
X=self.post_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))
self.attention_weights=[[None]*len(self.blks) for _ in range(2)]
for i,blk in enumerate(self.blks):
X,state=blk(X,state)
self.attention_weights[0][i]=blk.attention1.attention.attention_weights
self._attention_weights[1][i]=blk.attention2.attention.attention_weights
return self.dens(X),state
@property
def attention_weight(self):
return self._attention_weights
num_hiddens,num_layers,dropout,batch_size,num_steps=32,2,0.1,64,10
lr,num_epochs,device=0.005,200,d2l.try_gpu()
ffn_num_input,ffn_num_hiddens,num_heads=32,64,4
key_size,query_size,value_size=32,32,32
norm_shape=[32]
train_iter,src_vocab,tgt_vocab=test_60translate.load_data_nmt(batch_size,num_steps)
encoder=TransformerEncoder(len(src_vocab),key_size,query_size,value_size,num_hiddens,
norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout)
decoder=TransformerDecoder(len(tgt_vocab),key_size,query_size,value_size,num_hiddens,
norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,num_layers,dropout)
if __name__ == "__main__":
net=EncoderDecoder(encoder,decoder)
test_62seq2seq.train_seq2seq(net,train_iter,lr,num_epochs,tgt_vocab,device)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)