EdgeSight:跨平台视觉伺服系统的边缘端极致优化与工程实现
摘要
针对嵌入式边缘设备上实时视觉伺服系统面临的算力受限、推理延迟高、系统资源占用大的核心痛点,本文设计并实现了EdgeSight——一套跨平台的实时目标检测与视觉伺服系统。该系统基于PySide6构建统一图形化交互框架,兼容Windows与树莓派Linux双平台,集成了实时监控、目标深度分析、在线参数标定三大核心功能模块,支持ONNX Runtime与NCNN双推理引擎,适配YOLOv5/YOLOv8系列轻量化检测模型。通过模型量化、推理引擎替换、系统参数调优、模型适配全链路优化,系统在树莓派4B边缘端实现了1.8~2.0 FPS的端到端稳定检测,CPU占用稳定控制在30%~50%;在x86 Windows平台实现16.5 FPS的高性能推理,为嵌入式边缘视觉伺服应用提供了可落地、可复现的完整工程方案。所有代码已开源至 GitHub
关键词:边缘计算;视觉伺服;目标检测;YOLO;NCNN;ONNX Runtime;嵌入式系统;跨平台开发
一、引言
随着智能制造、机器人、智能监控等领域的快速发展,基于边缘设备的实时视觉伺服技术成为研究与工程落地的热点。视觉伺服系统通过实时图像采集、目标检测与状态分析,实现对被控对象的闭环控制,其核心需求是低延迟推理、高检测稳定性、低系统资源占用,同时需具备友好的人机交互与参数调试能力。
当前主流的目标检测模型(如YOLO系列)在x86高性能平台上已实现成熟应用,但在ARM架构的嵌入式边缘设备(如树莓派)上,面临算力不足、推理框架优化不足、端到端系统开销大等问题,难以同时满足实时性与稳定性要求。现有方案大多仅关注纯推理性能优化,缺乏完整的视觉伺服闭环功能与跨平台适配能力,工程落地性不足。
针对上述问题,本文开展了以下工作:
- 设计了一套模块化、跨平台的视觉伺服系统架构,实现了Windows与树莓派Linux平台的统一核心逻辑与差异化硬件适配;
- 构建了包含实时监控、深度分析、参数配置的全功能交互系统,支持目标状态在线分析、阈值动态调节与一键标定功能;
- 开展了从模型、推理引擎到系统参数的全链路优化实验,量化分析了不同优化手段在x86与ARM平台的差异化效果,解决了嵌入式端模型适配、置信度异常等工程问题;
- 实现了树莓派4B上低负载、高稳定的视觉伺服部署,形成了完整的边缘端视觉系统工程化落地方法论。
二、系统总体设计
EdgeSight采用分层模块化设计,自上而下分为交互层、核心逻辑层、硬件适配层三层架构,确保跨平台兼容性与功能可扩展性。系统针对高性能x86平台与低功耗ARM边缘平台分别做了推理引擎与模型的针对性适配,在保证核心逻辑统一的前提下,最大化发挥不同硬件的性能潜力。
2.1 系统核心功能模块
EdgeSight包含三大核心功能界面,覆盖视觉伺服系统从数据采集、目标分析到参数调试的全流程需求。
2.1.1 实时监控模块(Monitor Tab)
该模块为系统主交互界面,实现视觉伺服的基础闭环功能:
- 双视图实时显示:同步展示原始摄像头采集画面与算法处理后的检测结果画面,支持检测框、类别标签、置信度的实时渲染;
- 检测信息实时面板:在线输出目标检测框中心点坐标(X/Y)、检测置信度、目标类别等核心参数;
- 双帧率性能监控:分别统计并显示模型推理FPS(纯算法推理速度)与画面采集FPS(摄像头采集+画面渲染全链路速度),实现全链路性能可视化;
- 在线参数调节:支持运行中实时修改置信度阈值与NMS阈值,参数修改后立即生效,无需重启系统,适配不同场景的快速调试需求。

图1 EdgeSight系统实时监控主界面
2.1.2 深度分析模块(Deep Analysis Tab)
该模块为视觉伺服提供闭环控制的数据分析能力,通过实时曲线绘制与状态预警,实现目标运动趋势与系统状态的全维度监控,具体功能如下表所示:
表1 深度分析模块核心功能
| 分析子模块 | 核心功能与技术实现 |
|---|---|
| 目标位置分析 | 实时绘制检测框X/Y坐标的时域变化曲线;基于画面边界阈值,实现目标越界预警(如“即将从左侧丢失”),为伺服控制提供位置反馈 |
| 目标尺寸与距离分析 | 实时绘制检测框宽高变化曲线;基于用户标定的基准宽度,通过相似三角形原理计算目标相对距离,绘制距离变化趋势曲线,实现目标靠近/远离状态的实时感知 |
| 置信度分析 | 实时绘制目标检测置信度曲线,与用户设定的置信度阈值做实时对比;当置信度持续低于阈值时,触发检测异常预警,保障伺服系统的稳定性 |
| 系统性能分析 | 实时绘制推理FPS时域曲线,同步显示CPU与内存占用率的进度条与数值,实现边缘端系统资源占用的可视化监控,避免系统过载 |
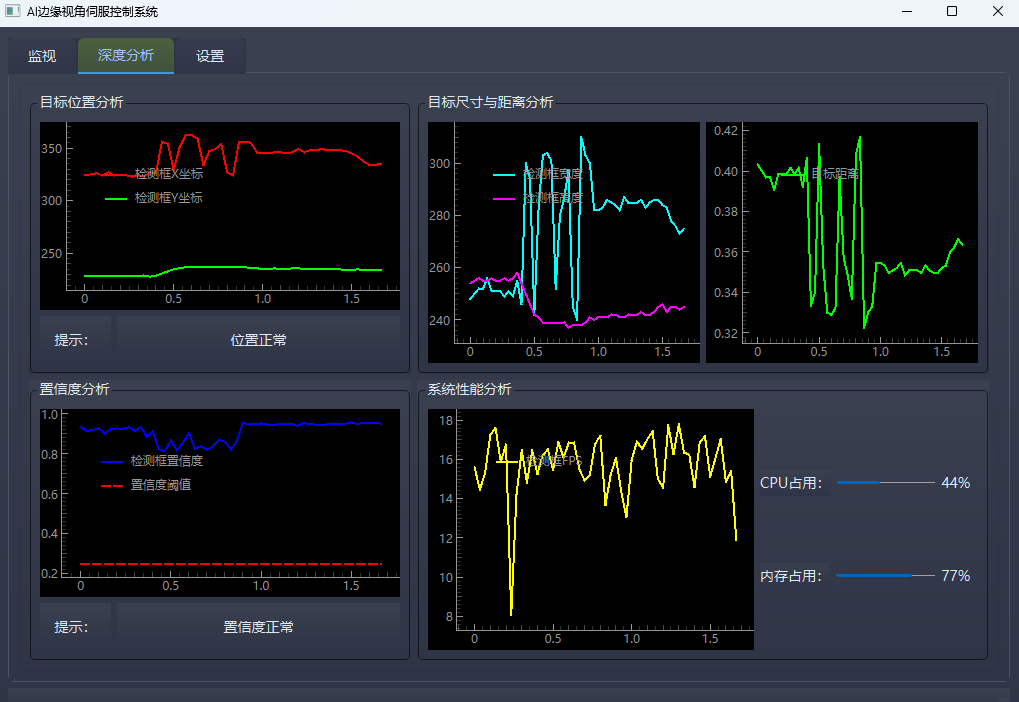
图2 EdgeSight系统深度分析界面
2.1.3 参数配置模块(Settings Tab)
该模块为系统提供全参数可配置能力,支持模型、检测逻辑、系统标定的全维度自定义,核心功能包括:
- 模型配置单元:支持用户自主选择模型文件与对应标签文件,Windows平台仅支持ONNX格式模型,树莓派平台兼容ONNX与NCNN格式模型;支持CPU/GPU/NPU硬件加速后端的自主选择(根据平台硬件能力自适应显示可用选项)。
- 检测配置单元:提供三种目标选择规则——最高置信度优先、最接近画面中心优先、指定类别优先,适配不同的视觉伺服跟踪场景;支持检测类别过滤、基准宽度滑动调节,为距离估算提供标定参数。
- 系统标定单元:支持系统采样频率(10~100Hz)在线调节、深度分析功能开关;提供一键标定功能,可自动获取当前目标检测框宽度作为基准宽度,并实时显示标定状态,简化现场标定流程。
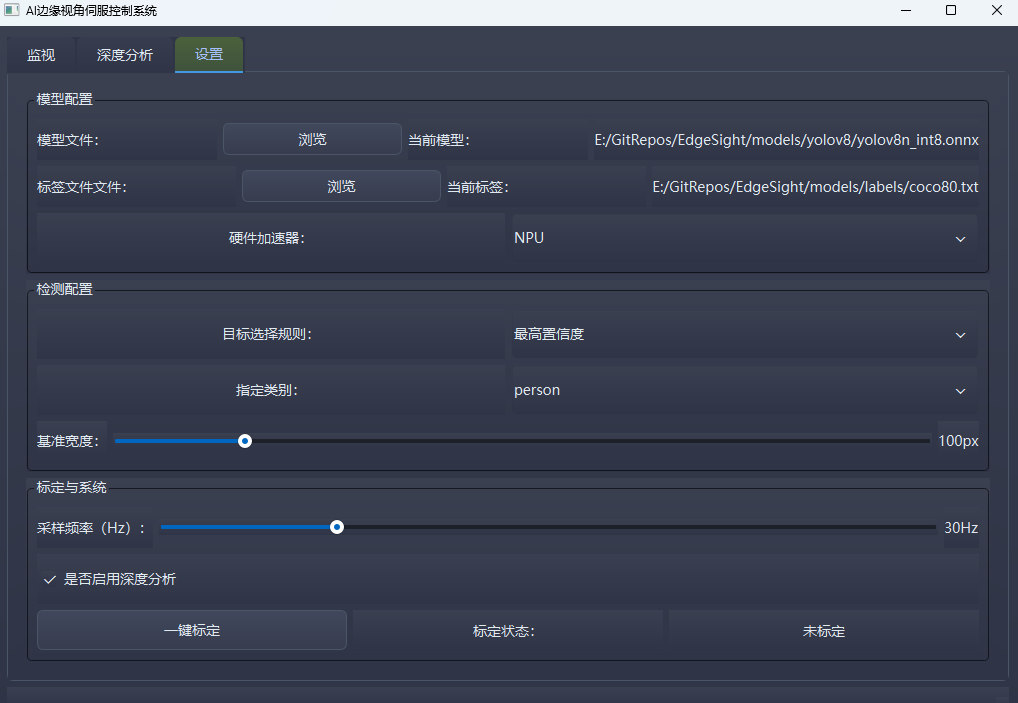
图3 EdgeSight系统参数配置界面
2.2 平台适配与支持矩阵
系统针对x86 Windows与ARM Linux(树莓派)两大平台做了深度适配,核心逻辑完全复用,仅在推理引擎与模型支持上做差异化优化,具体适配矩阵如下:
表2 系统平台与模型支持矩阵
| 运行平台 | 支持推理引擎 | 模型格式 | 适配模型版本 | 量化精度支持 |
|---|---|---|---|---|
| Windows x86_64 | ONNX Runtime | .onnx | YOLOv5、YOLOv8 | FP32/INT8 |
| 树莓派 Linux ARM64 | ONNX Runtime、NCNN | .onnx、.param+.bin | YOLOv5、YOLOv8 | FP32/INT8(ONNX)、INT8(NCNN) |
2.3 核心技术栈
- 前端GUI框架:PySide6,实现跨平台图形界面与实时曲线渲染
- 视觉处理库:OpenCV,实现摄像头采集、图像预处理与结果渲染
- 推理引擎:ONNX Runtime(跨平台通用推理)、NCNN(ARM平台极致优化推理)
- 数据可视化:pyqtgraph,实现低延迟的实时时域曲线绘制
- 核心算法:YOLOv5/YOLOv8轻量化目标检测算法,实现实时目标感知
三、实验环境与优化基线建立
3.1 实验环境说明
为保证优化实验的可复现性与对比公平性,本文所有实验均在固定的软硬件环境下开展,具体配置如下:
表3 实验硬件环境配置
| 平台类型 | 硬件配置 | 操作系统 |
|---|---|---|
| Windows x86平台 | Intel Core i5 移动端处理器,8GB内存 | Windows 11 64位 |
| 边缘端ARM平台 | 树莓派4B(Broadcom BCM2711 四核Cortex-A72 1.5GHz,2GB LPDDR4 RAM) | Raspberry Pi OS(Debian Bookworm)64位 |
表4 实验软件环境配置
| 软件组件 | 版本号 |
|---|---|
| Python | 3.9 |
| PySide6 | 6.5.2 |
| OpenCV | 4.8.0 |
| ONNX Runtime | 1.16.3 |
| NCNN | 20260113 |
| Ultralytics | 8.0.200 |
| 模型输入分辨率 | 640×320 |
3.2 优化基线建立
本文以ONNX Runtime + YOLOv8n FP32作为初始基线方案,该方案为YOLO官方推荐的跨平台部署方案,具备良好的通用性与易用性。在带完整UI系统、开启深度分析功能的条件下,测试两大平台的端到端推理性能,结果如图4所示。
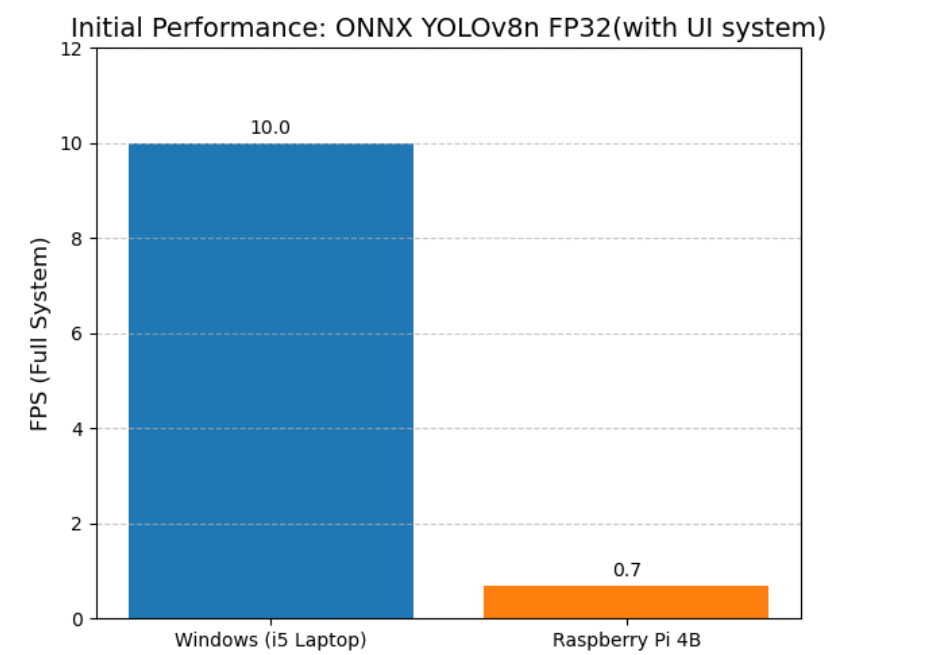
图4 基线方案(ONNX YOLOv8n FP32+UI系统)在不同平台的推理FPS
实验结果表明:
- Windows x86平台下,基线方案可实现10.0 FPS的端到端推理,基本满足实时调试需求;
- 树莓派4B边缘端,基线方案仅能实现0.7 FPS的推理速度,远低于视觉伺服系统的最低实时性要求,同时CPU占用率达到99%,系统完全处于过载状态,无额外算力承载伺服控制逻辑。
基于此,本文的核心优化目标为:在树莓派4B平台上,最大化提升端到端推理FPS,同时将CPU占用率控制在50%以内,保证系统具备伺服控制的算力余量。
四、全链路优化迭代与实验分析
本文按照模型量化→模型选型→系统参数调优→推理引擎替换→最终方案收敛的技术路径,开展了全链路的优化实验,量化分析每一种优化手段的实际效果与平台适配性,最终形成边缘端最优部署方案。
4.1 INT8模型量化优化:x86与ARM平台的差异化效果
模型量化是降低推理计算量、提升推理速度的主流工程手段。本文采用INT8线性量化,将YOLOv8n模型从FP32浮点精度量化为INT8整型精度,在相同的软硬件环境下,对比量化前后的端到端推理性能,结果如图5所示。
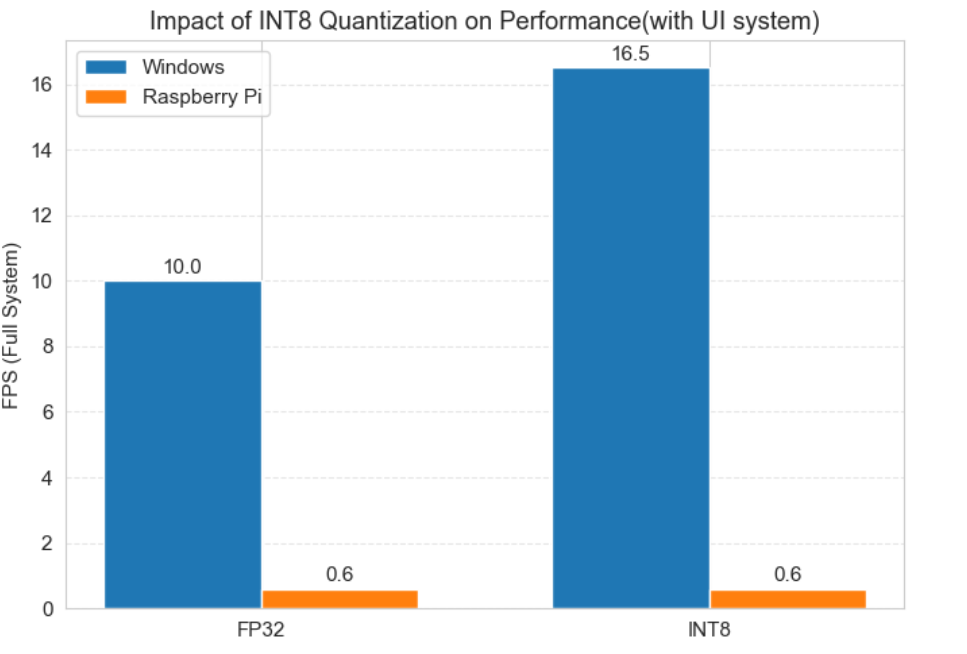
图5 INT8量化对不同平台推理性能的影响(带UI系统)
实验结果与分析:
- Windows x86平台下,INT8量化后推理FPS从10.0提升至16.5,性能提升幅度达65%,同时检测精度损失在可接受范围内,量化优化效果显著;
- 树莓派ARM平台下,INT8量化后推理FPS仍为0.6,无任何性能提升。其核心原因在于:ONNX Runtime与OpenCV DNN模块在ARM架构下对INT8量化的算子优化不足,无法发挥整型计算的性能优势,量化带来的计算量降低无法弥补硬件与框架的适配短板。
基于此,本文得出结论:INT8量化并非边缘端通用的优化手段,其效果高度依赖推理引擎与硬件架构的深度适配,在ARM平台上需更换针对性优化的推理引擎,才能发挥量化的性能优势。
4.2 模型选型对比:YOLOv8n与YOLOv5n的性能实测
为验证轻量化模型选型对边缘端性能的影响,本文在ONNX Runtime + INT8量化的条件下,对比了YOLOv8n与YOLOv5n两大轻量化模型的端到端推理性能,结果如图6所示。
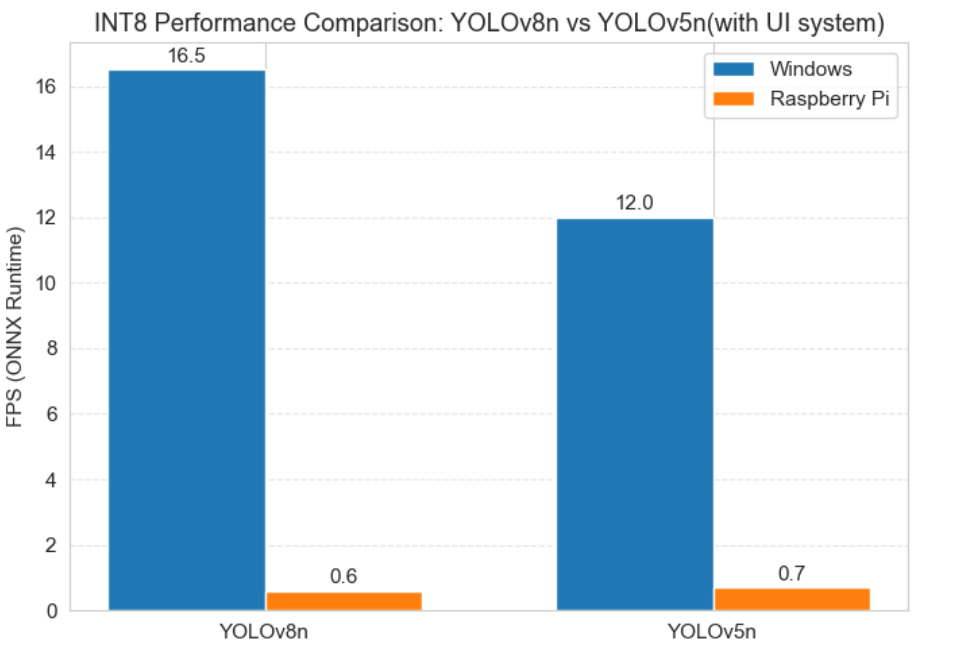
图6 YOLOv8n与YOLOv5n INT8模型在不同平台的性能对比(带UI系统)
实验结果与分析:
- 无论Windows平台还是树莓派平台,YOLOv5n的推理性能均未超过YOLOv8n,仅存在微小的性能差异;
- 其核心原因在于:ONNX Runtime对YOLOv8的算子做了针对性的融合与优化,抵消了YOLOv5n理论计算量更低的优势。
该实验表明:在固定推理引擎的前提下,单纯更换轻量化模型无法实现边缘端性能的质变,推理引擎与硬件架构的适配性是决定边缘端推理性能的核心因素。
4.3 系统参数调优:边缘端算力的精细化调度
在更换推理引擎之前,本文先通过系统参数调优,实现树莓派端CPU算力的精细化调度,核心优化手段包括:降低摄像头采集帧率、增大推理帧间隔、降低模型输入分辨率,具体参数对比如下: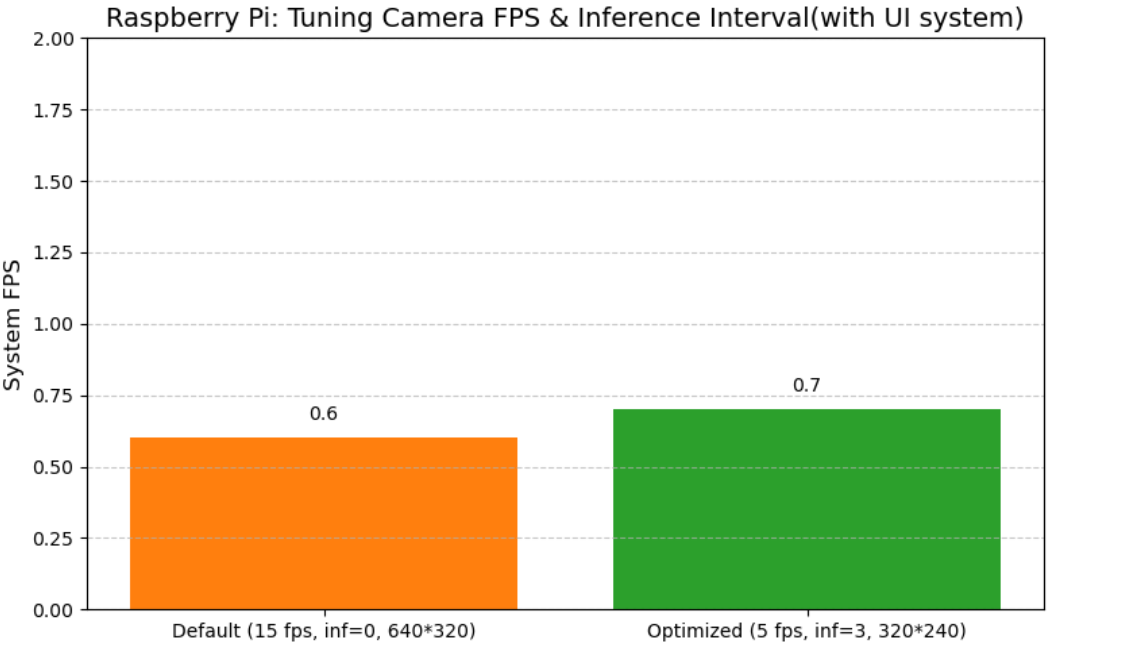
图7 不同参数对推理频率的影响
优化后,树系统过载问题得到一定缓解,但端到端推理FPS仅实现小幅提升,仍未达到可用水平。该结果表明:系统参数调优仅能缓解边缘端算力过载问题,无法解决推理引擎本身的性能瓶颈,需从推理引擎层面实现架构级优化。
4.4 推理引擎替换:NCNN在ARM平台的性能质变
NCNN是腾讯开源的、专为移动端ARM架构深度优化的神经网络推理引擎,其基于ARM NEON指令集做了汇编级优化,无第三方依赖,内存占用极低,在嵌入式边缘设备上具备显著的性能优势。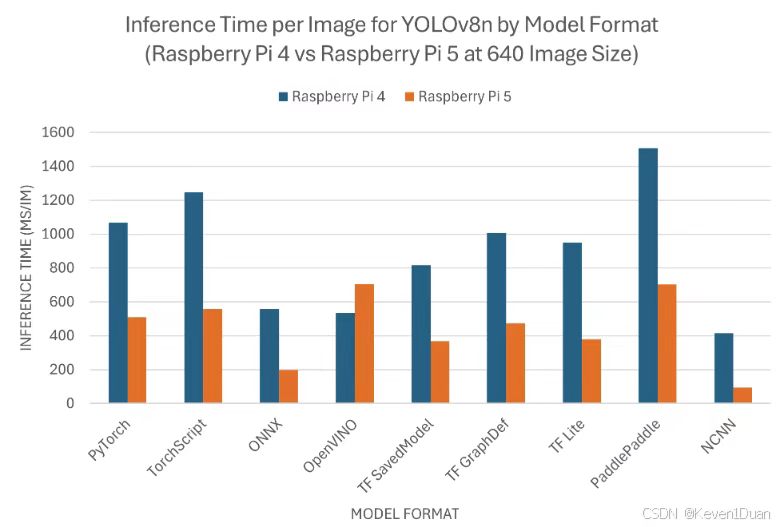
图8 不同引擎在树莓派上的推理时间
本文基于NCNN引擎,在树莓派4B平台上测试了YOLOv8n INT8模型的纯推理性能(无UI与系统开销),并与ONNX Runtime做对比,结果如图7所示。
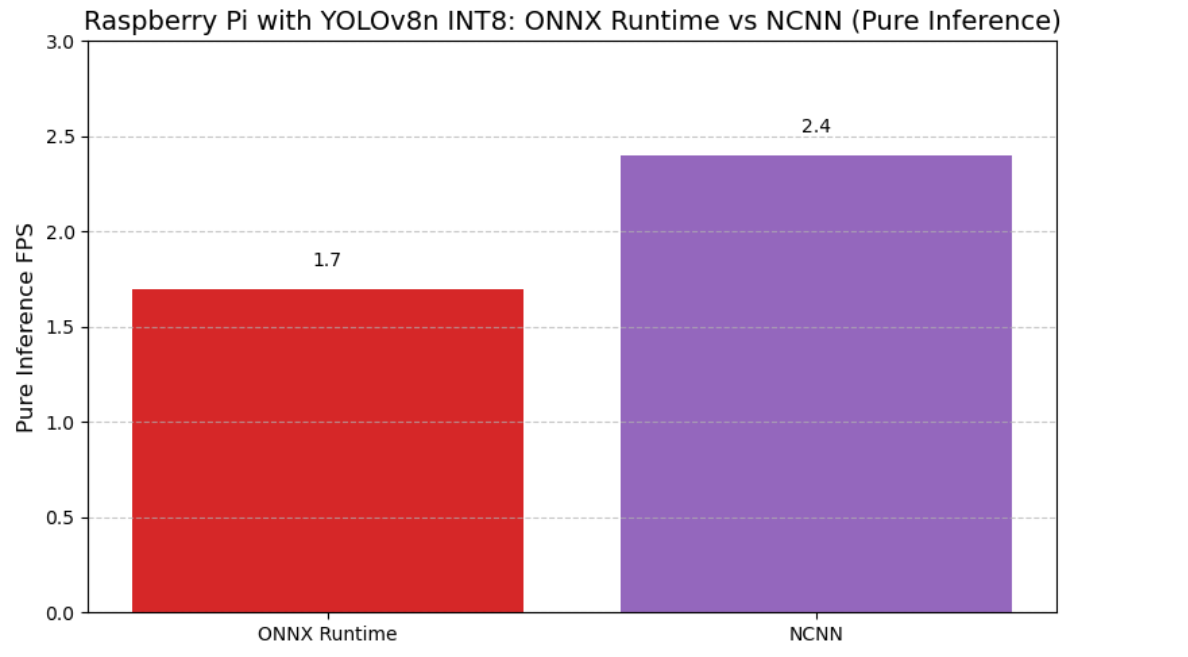
图9 ONNX Runtime与NCNN在树莓派上的纯推理FPS对比(YOLOv8n INT8)
实验结果表明:
- 纯推理场景下,NCNN引擎实现了2.4 FPS的推理速度,较ONNX Runtime的1.7 FPS提升了41%,验证了NCNN在ARM架构上的显著性能优势。
但在将NCNN YOLOv8n模型集成到完整UI系统后,出现了严重的工程问题:
- 检测框坐标异常:所有检测框集中在画面顶部,且尺寸严重偏小,无法实现正常的目标定位;
- 置信度输出异常:检测框置信度恒为1.0,出现大量误检,置信度分布完全不符合正常检测逻辑。
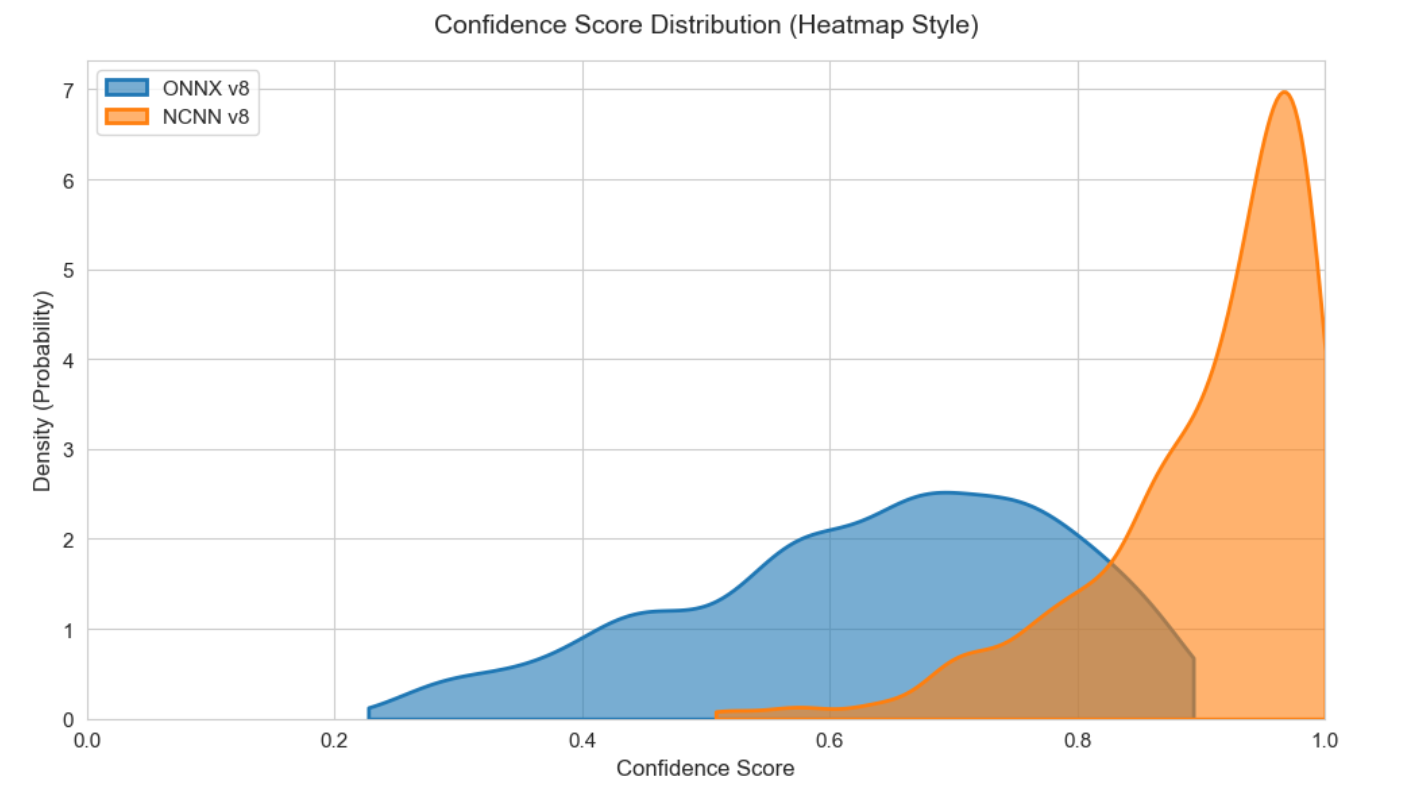
图10 两种推理引擎下的V8模型置信度分布情况
针对该问题,本文开展了深度诊断:
- 排查后处理逻辑,验证了坐标还原、置信度筛选、NMS流程的正确性;
- 打印模型输出张量,发现类别分数出现饱和现象,大量检测框的类别分数恒为1.0,其余类别分数接近0;
- 最终定位根本原因:YOLOv8的Detect检测头输出逻辑与NCNN的模型转换工具pnnx存在算子适配问题,pnnx在转换ONNX模型时,对YOLOv8的检测头自动插入了Softmax激活层,导致模型输出与后处理逻辑不匹配,最终出现置信度饱和与坐标异常问题。
由于该适配问题无法通过简单的后处理修改快速根治,且存在潜在的检测稳定性风险,本文决定更换适配性更成熟的YOLOv5n模型,开展NCNN引擎的工程落地。
4.5 最终方案收敛:NCNN + YOLOv5n INT8
本文基于NCNN引擎,完成了YOLOv5n INT8模型的转换、适配与全系统集成,开展了纯推理与带UI系统的全场景性能测试,同时验证了检测效果与系统资源占用情况。
纯推理场景下,该方案在树莓派4B上实现了4.5 FPS的推理速度,较ONNX Runtime YOLOv8n方案提升了165%;集成到完整UI系统、开启深度分析功能后,实现了1.8~2.0 FPS的稳定端到端推理,CPU占用率稳定控制在30%~50%,内存占用仅40%,系统具备充足的算力余量承载伺服控制逻辑,同时检测框稳定、置信度输出正常,完全满足边缘视觉伺服系统的工程落地要求。
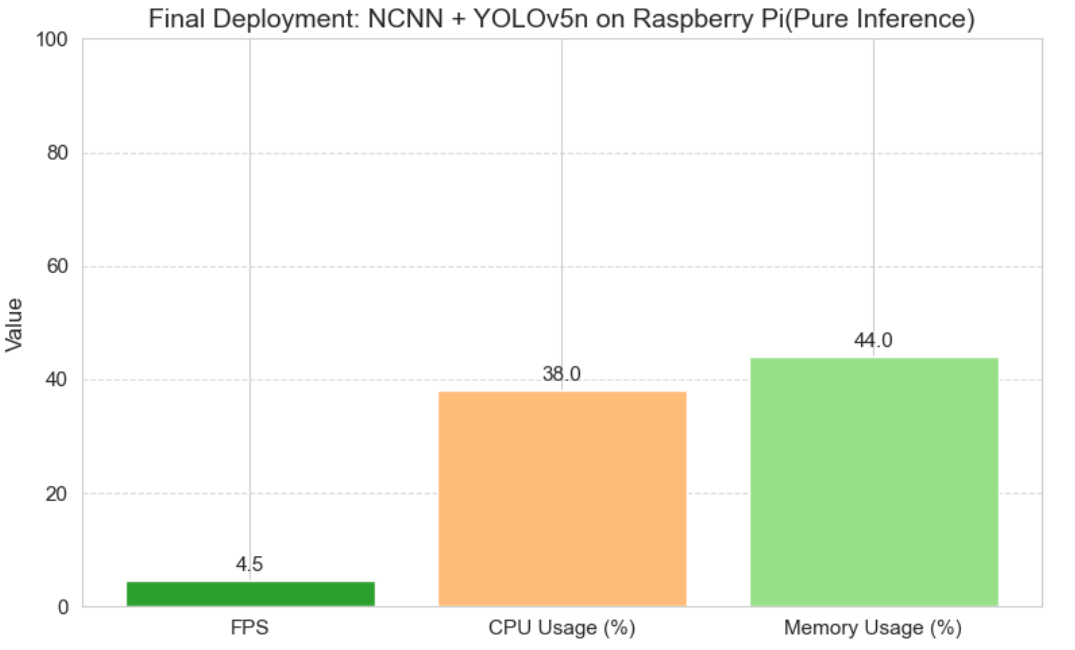
图11 最终方案(NCNN+YOLOv5n INT8)在树莓派上的性能与资源占用
五、全方案性能对比与优化成果总结
5.1 核心方案性能横向对比
本文对优化历程中的所有核心方案,在树莓派4B平台上开展了横向对比,量化分析推理速度、资源占用的变化,结果如下:
表6 不同方案在树莓派4B上的性能与资源占用对比(带UI系统)
| 优化方案 | 端到端推理FPS | 性能提升倍数 | CPU占用率 | 内存占用率 |
|---|---|---|---|---|
| 基线方案:ONNX YOLOv8n FP32 | 0.7 | 1.00x | 99% | 61% |
| 量化优化:ONNX YOLOv8n INT8 | 0.7 | 1.00x | 99% | 44% |
| 模型更换:ONNX YOLOv5n INT8 | 0.7 | 1.00x | 98% | 36% |
| 引擎更换:NCNN YOLOv8n INT8 | 1.7 | 2.43x | 61% | 40% |
| 最终方案:NCNN YOLOv5n INT8 | 2.0 | 2.86x | 44% | 40% |
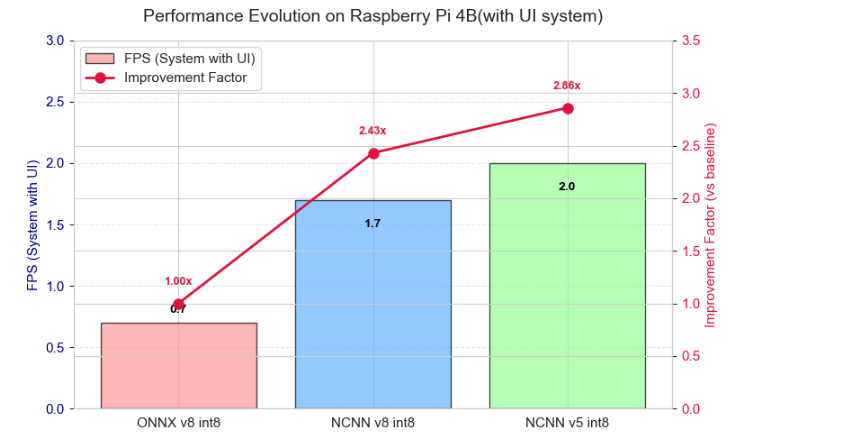
图12 树莓派端系统性能优化演进历程
5.2 关键影响因素量化分析
-
深度分析模块的性能影响:本文量化测试了深度分析模块对系统性能的影响,结果表明:开启深度分析模块后,系统推理FPS下降约20%,CPU占用率提升约15%,在工程落地中,可根据边缘端算力情况选择性开启该模块,进一步提升系统实时性。
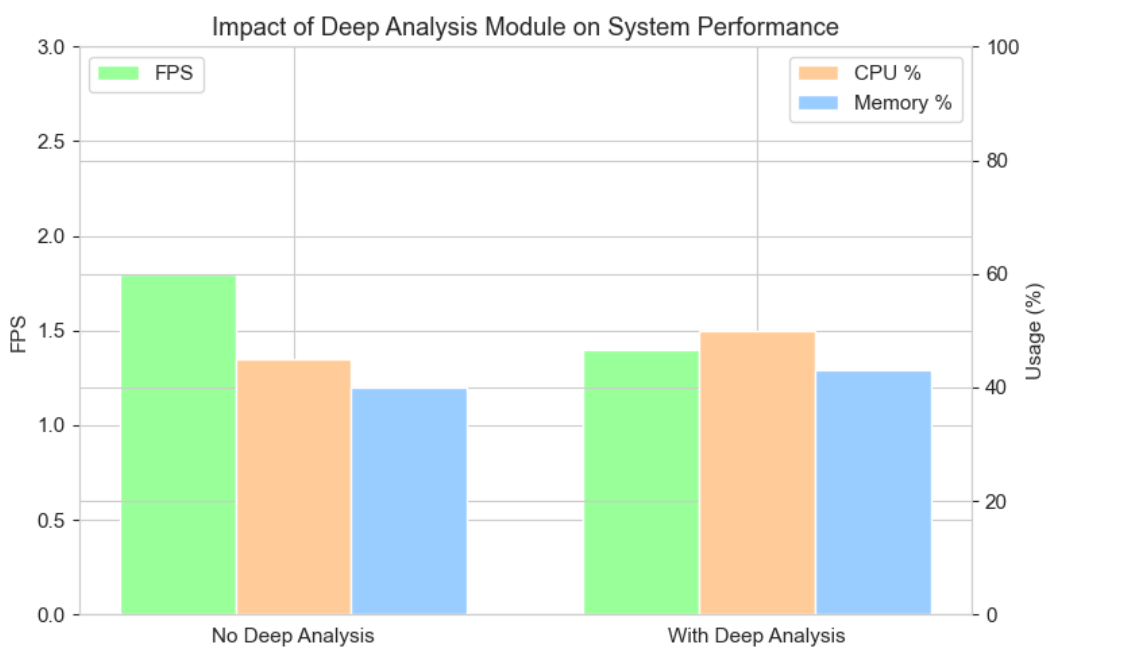
图13 深度分析模块的性能影响 -
UI系统的性能开销:纯推理与带UI系统的性能对比表明,UI界面与实时曲线渲染带来了约20%~30%的性能开销,在边缘端部署中,可通过关闭非必要的可视化界面,进一步释放CPU算力。
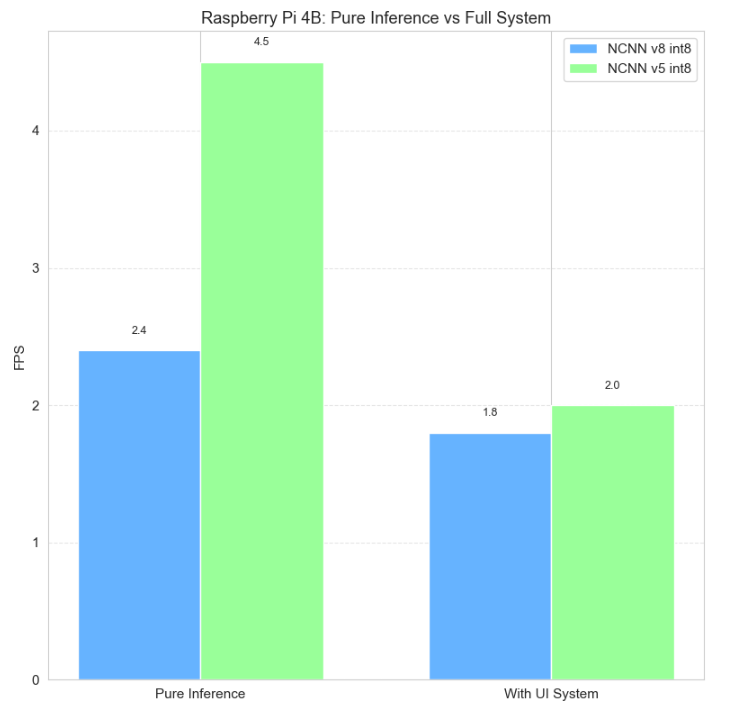
图14 UI系统的性能开销
- 模型置信度分布对比:ONNX YOLOv8n、NCNN YOLOv8n、NCNN YOLOv5n三大方案的置信度分布对比表明,NCNN YOLOv5n与 ONNX YOLOv8n的置信度分布最符合实际检测场景,无饱和与异常值,检测稳定性最优。
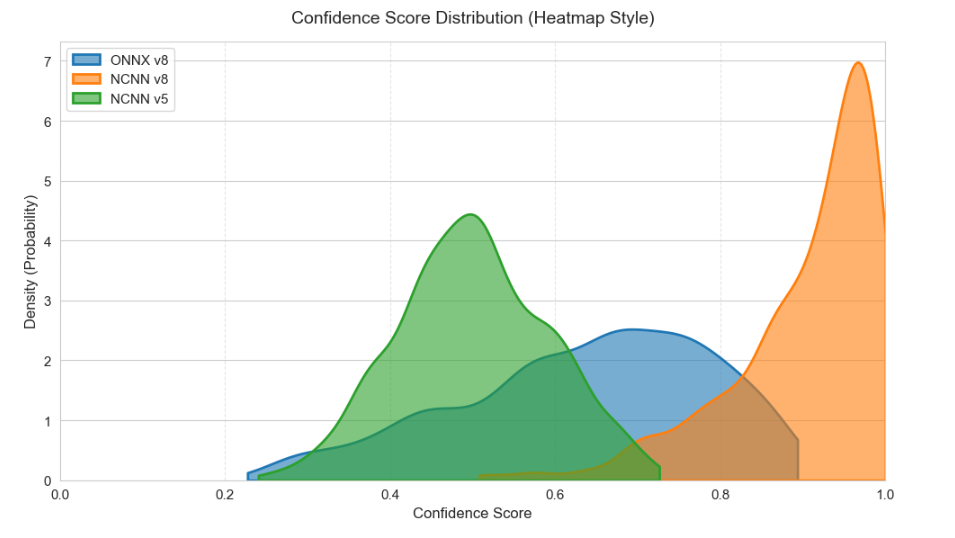
图15 模型置信度分布对比
六、工程实践经验与技术洞察
基于EdgeSight系统的全流程开发与优化迭代,本文提炼出边缘端视觉系统工程落地的核心技术原则与实践经验,为同类项目提供可复用的参考:
- 量化优化需结合硬件与推理引擎深度适配:INT8量化在x86平台效果显著,但在ARM平台上,其性能提升完全依赖推理引擎对整型算子的汇编级优化,盲目量化无法带来性能提升,甚至可能增加适配成本。
- 模型选型需结合部署框架实测,不可仅依赖理论计算量:YOLOv5n的理论计算量低于YOLOv8n,但在ONNX Runtime框架下,后者的实际推理性能更优。模型选型必须结合目标部署框架开展实测,理论参数仅能作为参考。
- NCNN是ARM边缘端部署的核心利器:NCNN针对ARM NEON指令集的深度优化,在树莓派等嵌入式设备上,较ONNX Runtime可实现1.5倍以上的性能提升,同时内存占用更低,是ARM边缘端视觉模型部署的优先选择。
- 模型转换是边缘端部署的核心风险点:YOLOv8在NCNN转换中出现的置信度异常问题,本质是检测头算子与转换工具的适配问题。在边缘端部署中,需优先选择转换生态成熟、社区验证充分的模型,降低适配风险。
- 系统级优化是边缘端落地的关键环节:摄像头帧率、推理间隔、输入分辨率等系统参数的调优,可有效缓解边缘端算力过载问题,实现算力的精细化调度,是算法优化之外的重要补充手段。
- 性能测试必须保证场景真实性,避免虚假数据:纯推理性能仅能作为参考,端到端全系统的性能测试才是工程落地的核心依据。测试脚本需严格验证模型输出、完成硬件预热、采用多次测试取平均值的方式,避免虚假性能数据误导优化决策。
七、结论
本文设计并实现了EdgeSight跨平台视觉伺服系统,完成了从Windows高性能平台到树莓派边缘平台的全链路适配与优化。通过模型量化、推理引擎替换、模型选型、系统参数调优等全流程优化,解决了边缘端视觉系统推理延迟高、资源占用大、模型适配难的核心问题,最终在树莓派4B上实现了2.0 FPS的稳定端到端推理,CPU占用控制在30%~50%,在Windows上实现16.5FPS的稳定推理,为边缘视觉伺服应用提供了完整的、可落地的工程方案。
参考文献
[1] Tencent. ncnn: 为移动端极致优化的高性能神经网络前向计算框架[EB/OL]. https://github.com/Tencent/ncnn, 2023.
[2] Ultralytics. YOLOv8 Official Documentation[EB/OL]. https://docs.ultralytics.com/, 2023.
[3] Microsoft. ONNX Runtime: 跨平台机器学习推理加速器[EB/OL]. https://onnxruntime.ai/, 2024.
[4] Redmon J, Farhadi A. YOLOv3: An Incremental Improvement[EB/OL]. arXiv:1804.02767, 2018.
[5] Li C, Li L, Jiang H, et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications[EB/OL]. arXiv:2209.02976, 2022.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)