Python入门
入门python
2. Python 基础语法 - 面向前端工程师
Python 是一个简洁而强大的编程语言,因其易于使用而非常适合初学者,也是人工智能学习的必备技能。本章节将从前端工程师的角度,结合 JavaScript(以下简称为 JS)的语法习惯,讲解 Python 的基本语法和常用核心功能。
2.1 基础数据类型 & 运算符
2.1.1 Python 数据类型(对比 JS)
Python 和 JS 的基础数据类型有很多相似之处,但 Python 的弱类型特性和强大的内置方法使它更加灵活。从前端工程师的角度来看,这些数据类型是你必须掌握的核心:
-
int(整数)-
Python:
int表示整数类型,可以执行任意大的数值计算,写法极其简单。a = 42 # Python 的 int -
JS: 类似
Number类型。let a = 42; // JS 的 Number
-
-
float(浮点数)-
Python:
float表示小数或带有小数点的数字。b = 3.14 # PI 值 -
JS: 依然使用
Number。let b = 3.14;
-
-
str(字符串)-
Python: 用单引号
'或双引号"包裹字符串。支持多行字符串(用三引号'''或""")。name = "Alice" multiline_text = '''这是一段 多行字符串。''' -
JS: 也支持字符串,但没有
'''多行写法,使用模板字符串代替。let name = "Alice"; let multiline_text = `这是一段 多行字符串。`;
-
-
bool(布尔型)-
Python: 布尔值为
True和False(注意首字母大写)。is_active = True -
JS: 布尔值为
true和false(全小写)。let is_active = true;
-
2.1.2 Python 的动态类型与类型检查
Python 是动态类型语言,不需要预定义变量类型;它可以随时更改为其他类型。例如:
x = 10 # x 是 int
x = "Hello" # 现在 x 是 str
JS 也是动态类型语言,但可以通过 TypeScript 提供静态类型检查。而 Python 提供类似的 Type Hint 静态检查(详见 2.3.2)。
2.1.3 运算符和逻辑
-
算术运算符:
+,-,*,/(除,结果总是浮点数),//(整除),%(取余),**(幂运算)。print(5 / 2) # 结果 2.5 print(5 // 2) # 整除,结果 2 print(2 ** 3) # 幂运算,2^3 = 8 -
逻辑运算符:Python 与 JS 略有不同。
-
Python 使用
and,or,not替代 JS 中的&&,||,!。True and False # False True or False # True not True # False
-
-
对比
==和===-
Python 的
==是值比较(类似于 JS 的==),但 Python 没有严格相等比较符。1 == 1.0 # True 1 is 1.0 # False,is 用于比较对象标识(引用地址)是否相同而在 JS 中:
1 == '1'; // true 1 === '1'; // false
-
2.2 常用集合 & 对应操作
2.2.1 列表(List)
Python 的列表类似 JS 的数组,但功能更加丰富。
# Python 列表
colors = ["red", "green", "blue"]
colors.append("yellow") # 添加元素
colors.pop() # 删除最后一个元素
colors.sort() # 按字典序排序
subcolors = colors[1:3] # 切片,获取索引 1 到 2 的子序列
在 JS 中类似:
// JS 数组
let colors = ["red", "green", "blue"];
colors.push("yellow"); // 添加元素
colors.pop(); // 删除最后一个元素
colors.sort(); // 按字典序排序
let subcolors = colors.slice(1, 3); // 获取子数组
2.2.2 字典(Dict)
Python 的字典类似于 JS 的对象键值对,但有更多功能。
# Python 字典
person = {"name": "Alice", "age": 25}
person["city"] = "Beijing" # 新增键值对
del person["age"] # 删除键值对
在 JS 中类似于:
// JS 对象
let person = { name: "Alice", age: 25 };
person.city = "Beijing"; // 新增键
delete person.age; // 删除键
2.2.3 元组(Tuple)与集合(Set)
- 元组 是不可变的列表,例如
(1, 2, 3);它更类似于不可变的数组。 - 集合 是没有重复值的元素集,例如
{1, 2, 3}。JS 中用Set表示。
# Python 元组和集合
coordinates = (1, 2) # 元组
unique_values = {1, 2, 3} # 集合
类似于 JS 中的 Set:
const uniqueValues = new Set([1, 2, 3]);
2.2.4 解构赋值 & 列表推导式
# 解构赋值
a, b = [1, 2]
# 列表推导式
squared = [x**2 for x in range(5)]
print(squared) # [0, 1, 4, 9, 16]
在 JS 中:
// 解构赋值
let [a, b] = [1, 2];
// 类似数组映射
let squared = Array.from({ length: 5 }, (_, i) => i ** 2);
console.log(squared); // [0, 1, 4, 9, 16]
2.3 函数与类型提示
2.3.1 定义和调用函数
def add(a, b):
return a + b
result = add(2, 3) # 调用函数
在 JS 中:
function add(a, b) {
return a + b;
}
let result = add(2, 3);
2.3.2 Type Hints 类型提示
Python 的类型提示类似于 TypeScript,通过在函数参数和返回值中指定类型来进行静态检查。
def greet(name: str) -> str:
return f"Hello, {name}"
配合工具(如 mypy),可检测类型错误。
2.3.3 Lambda 表达式
# Python
square = lambda x: x ** 2
print(square(4)) # 输出 16
JS 中的箭头函数类似:
// JS
const square = x => x ** 2;
console.log(square(4)); // 输出 16
2.4 异步编程简介
Python 的异步部分借鉴了 JS 的 Promise 和 async/await 模式,但在实现机制上有所不同。
import asyncio
async def fetch_data():
print("Fetching...")
await asyncio.sleep(2) # 模拟 I/O 操作
return "Data fetched"
async def main():
result = await fetch_data()
print(result)
# 运行异步代码
asyncio.run(main())
JS 中类似:
async function fetchData() {
console.log("Fetching...");
await new Promise(resolve => setTimeout(resolve, 2000)); // 模拟 I/O 操作
return "Data fetched";
}
async function main() {
const result = await fetchData();
console.log(result);
}
main();
通过以上介绍,前端工程师可以快速上手 Python,进而为后续的 AI 学习打下基础。Python 的语法既简单又直观,适合快速实现复杂的人工智能算法和数据运算任务。
作为习惯了 JavaScript 生态的前端工程师,刚刚进入 Python 的世界时,最容易感到“水土不服”的地方往往不是语法,而是代码组织方式和包管理机制。
在 Node.js 中,你习惯了 node_modules 黑洞,习惯了 import/export,习惯了 package.json 一把梭。转到 Python,你会发现它既相似又不同。别担心,这篇教程将用你最熟悉的“前端语言”来翻译 Python 的模块化世界,助你无缝迁移。
3. 模块 & 包管理
3.1 使用模块:从 CommonJS/ESM 到 Python Import
在前端,我们经历了从 AMD/CMD 到 CommonJS,再到如今一统天下的 ES Modules (ESM)。Python 的模块系统相对稳定,但在引入机制上与 JS 有微妙的区别。
1. Python 模块 vs Node.js 模块
你可以把 Python 的一个 .py 文件看作一个 Module,把一个包含 __init__.py 的文件夹看作一个 Package(类似于 npm 包)。
| 功能场景 | Node.js (ESM/TS) | Python | 核心差异点 |
|---|---|---|---|
| 导入默认 | import a from './a' |
import a |
Python 导入的是模块对象本身,调用需用 a.func()。 |
| 导入部分 | import { func } from './a' |
from a import func |
语法结构非常像,但 Python 不需要花括号。 |
| 重命名 | import { a as b } from './mod' |
from mod import a as b |
逻辑完全一致,关键词不同。 |
| 导入所有 | import * as tools from './mod' |
from mod import * |
警告:Python 极不推荐 import *,因为会污染命名空间,且不知道变量来源。 |
代码对比实战:
Node.js 写法:
// utils.js export const add = (a, b) => a + b; // main.js import { add } from './utils'; console.log(add(1, 2));
Python 写法:
# utils.py def add(a, b): return a + b # main.py from utils import add print(add(1, 2))
2. 标准库:Python 的 “Batteries Included” 哲学
Node.js 的内置库很精简(fs, path, http),很多功能需要求助于 npm。而 Python 号称“自带电池”,标准库极其丰富。作为 AI 工程师,以下四个库是你必须掌握的“瑞士军刀”:
-
os&pathlib(对应 Node 的fs+path)- 做 AI 数据处理时,你需频繁遍历文件夹读取图片或文本。不要再手拼路径了!
import os from pathlib import Path # 获取当前文件路径 (类似于 __dirname) current_dir = os.path.dirname(os.path.abspath(__file__)) # 更好的方式:使用 Pathlib (面向对象风格,强烈推荐) base_dir = Path(__file__).resolve().parent data_path = base_dir / "data" / "dataset.csv" # 像拼接字符串一样拼接路径,且跨平台兼容 print(f"数据路径: {data_path}") -
time&datetime(对应 Node 的Date+performance.now)- 在 AI 模型训练中,计算耗时是家常便饭。
import time from datetime import datetime start_time = time.time() # 获取时间戳 # 模拟一个耗时操作 time.sleep(1.5) end_time = time.time() print(f"训练耗时: {end_time - start_time:.2f} 秒") print(f"当前时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}") -
math(对应 JS 的Math)- 虽然做 AI 我们主要用
numpy和torch,但基础数学计算仍离不开它。
import math # 计算 Sigmoid 函数的某一部分: 1 / (1 + e^-x) x = 2 sigmoid_val = 1 / (1 + math.exp(-x)) print(f"Sigmoid({x}) = {sigmoid_val}") - 虽然做 AI 我们主要用
-
logging(对应console.log的进化版)- 金牌讲师敲黑板:做后端和 AI 开发,请戒掉到处
print()的习惯。print是同步阻塞的 stdout 输出,且无法分级。logging可以帮你记录日志到文件、控制输出级别(Debug/Info/Error),这在长时间的模型训练任务中至关重要。
import logging # 配置日志格式 logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s' ) logging.info("开始加载模型...") try: # 模拟错误 x = 1 / 0 except Exception as e: logging.error(f"模型训练崩溃: {e}") - 金牌讲师敲黑板:做后端和 AI 开发,请戒掉到处
3.2 第三方库与依赖管理
前端有 npm/yarn/pnpm,Python 的生态也有对应的工具。
1. pip install:Python 界的 npm
pip 是 Python 的包安装器。它默认从 PyPI (Python Package Index) 下载包,类似于 npm registry。
- 安装包:
pip install requests(等同npm install axios) - 卸载包:
pip uninstall requests - 查看已安装:
pip list
⚠️ 重要区别: Node.js 默认将包安装在项目目录下的 node_modules。Python pip 默认将包安装在全局环境或当前激活的虚拟环境中。这就是为什么 Python 开发必须使用虚拟环境(Virtual Environment)的原因,否则不同项目的依赖版本会打架。
2. 依赖管理进阶:requirements.txt vs Poetry
这里是前端同学最容易感到困惑的地方,我们来做个映射:
-
方案 A:传统派 (
requirements.txt)这是 Python 的老传统。它只是一个简单的文本文件,列出了依赖包及其版本。
- 生成依赖文件:
pip freeze > requirements.txt - 安装依赖文件:
pip install -r requirements.txt
缺点:它没有区分
dependencies和devDependencies,也没有锁文件(Lock file)的概念,容易导致“在我机器上能跑,在你机器上跑不起来”。 - 生成依赖文件:
-
方案 B:现代派 (
Poetry) —— 强烈推荐给前端开发者 🌟如果你喜欢
package.json的管理方式,你一定会爱上Poetry。它集成了虚拟环境管理、依赖解析、构建发布于一身。前端概念 package.json / npm Poetry / pyproject.toml 初始化 npm initpoetry init安装依赖 npm install axiospoetry add requests开发依赖 npm install jest -Dpoetry add pytest --group dev运行脚本 npm run startpoetry run python main.py锁文件 package-lock.jsonpoetry.lock配置文件 package.jsonpyproject.tomlPoetry 使用示例:
# 1. 初始化项目 poetry init # 2. 添加 AI 常用库 poetry add numpy pandas openai # 3. 进入虚拟环境 Shell poetry shell
3.3 组织代码的最佳实践
当你开始写复杂的 AI Agent 或后端服务时,把所有代码塞进 app.py 是绝对不行的。作为前端,你可能熟悉 Vue/React 的组件化目录,或者 NestJS 的模块化架构。我们可以把 NestJS 的优秀思想带入 Python。
1. __init__.py 的魔法
在 Python 目录中放入一个 __init__.py 文件(哪怕是空的),Python 就会将该目录视为一个 Package。
- 它类似于 JS 文件夹里的
index.js。 - 你可以在里面通过
from .module import Service暴露对外的接口,简化导入路径。
2. 仿 NestJS 架构组织 Python AI 项目
假设我们要开发一个 “AI 文章摘要生成器” 的后端服务,我们可以模仿 NestJS 的 Controller-Service 分层架构来组织 FastAPI 或 Flask 项目:
my-ai-project/
├── pyproject.toml # 类似于 package.json
├── poetry.lock # 类似于 package-lock.json
├── README.md
├── .env # 环境变量 (API Keys)
└── src/ # 源码目录
├── __init__.py
├── main.py # 入口文件 (类似于 index.ts)
├── common/ # 公共模块
│ ├── utils.py
│ └── logger.py
└── modules/ # 业务模块 (类似于 NestJS modules)
├── summary/
│ ├── __init__.py # 暴露 Service 给外部
│ ├── controller.py # 处理 HTTP 请求 (Router)
│ ├── service.py # 核心业务逻辑 (调用 OpenAI/LLM)
│ └── dtos.py # 数据传输对象 (类似于 Interface/Type)
└── user/
├── ...
代码组织示例 (Service 层):
# src/modules/summary/service.py
# 这是一个纯粹的业务逻辑类,类似于 NestJS 的 Provider
class SummaryService:
def __init__(self, api_key: str):
self.api_key = api_key
def generate(self, text: str) -> str:
# 这里模拟调用 AI 模型的逻辑
if not text:
raise ValueError("文本不能为空")
return f"这是对文本的摘要处理结果... (长度: {len(text)})"
# src/modules/summary/__init__.py
from .service import SummaryService
from .controller import router
# 这样外部只需要 from modules.summary import SummaryService 即可
总结:
不要因为 Python 语法简单就写出“面条代码”。利用好 poetry 管理依赖,利用好目录结构分层,你将发现,优秀的工程化思维在任何语言中都是通用的。
如果说前面的模块管理是搭建房子的脚手架,那么面向对象编程 (OOP) 就是我们构建摩天大楼的蓝图和砖块。在 AI 开发中,你会发现几乎所有的主流框架(PyTorch, TensorFlow, LangChain)都是基于类(Class)构建的。
别担心,作为熟悉 ES6+ 的前端工程师,你其实已经掌握了 80% 的概念。我们今天的任务,就是把那剩下的 20% 差异补齐,并学会 Python 特有的“语法糖”。
4. 面向对象编程(OOP)
4.1 基本概念 & JS 对比
在 ES6 之前,JavaScript 是通过原型链(Prototype)模拟类的,而 Python 从诞生之初就是基于类的语言。虽然现在两者看起来很像,但“底层味道”完全不同。
1. 类与对象:语法对对碰
我们将创建一个简单的 AI 模型类来对比两者。
JavaScript (ES6+) 写法:
class Model { // 构造函数 constructor(name) { this.name = name; } // 方法 predict(inputData) { return `${this.name} 正在预测: ${inputData}`; } } // 实例化 (必须用 new) const myModel = new Model("GPT-4"); console.log(myModel.predict("Hello"));
Python 写法:
class Model: # 构造函数 (__init__) def __init__(self, name): self.name = name # 方法 (注意第一个参数必须是 self) def predict(self, input_data): # f-string 类似于 JS 的模板字符串 `${}` return f"{self.name} 正在预测: {input_data}" # 实例化 (不需要 new 关键字!) my_model = Model("GPT-4") print(my_model.predict("Hello"))
核心差异点:
- 没有
new:Python 实例化类就像调用函数一样简单,少敲三个键,效率 Up。 this变成了self:这是前端同学最容易报错的地方,我们在下一节细说。- 命名规范:类名依然是大驼峰(PascalCase),但方法名和变量名 Python 强制推荐蛇形命名(snake_case),而不是 JS 的小驼峰(camelCase)。
4.2 self 的用法及初始化器 __init__
这是 Python OOP 中最大的“坑”,也是最大的“显式特性”。
1. __init__ 是什么?
它完全等同于 JS 中的 constructor。当你调用 Model() 时,Python 会自动执行 __init__ 方法。我们通常在这里初始化实例属性。
2. 为什么每个方法都要写 self?
在 JS 中,this 是一个隐式上下文,它的指向非常灵活(有时也很让人抓狂,比如在回调函数中丢失 this)。
在 Python 中,显式优于隐式。
- Python 规定:类方法的第一个参数,永远代表实例本身。习惯上我们将它命名为
self(虽然你叫它me也可以,但会被同事打)。 - 当你调用
my_model.predict("data")时,Python 解释器在后台其实是这样执行的:Model.predict(my_model, "data")
看,my_model自动作为第一个参数传给了self。
❌ 常见错误示范(前端同学请注意):
class Robot:
def __init__(self, name):
self.name = name
# 错误!忘记加 self
def say_hello():
print("Hello")
r = Robot("Wall-E")
r.say_hello()
# 报错: TypeError: Robot.say_hello() takes 0 positional arguments but 1 was given
# 原因:你调用时系统自动传了 self 进去,但你的函数定义里没坑位接它。
4.3 类的继承和多态性
在 AI 开发中,我们经常需要继承基础模型类并修改其行为。
1. 继承 (Inheritance)
假设我们要基于通用的 Model 创建一个 LLMModel。
# 父类
class Model:
def __init__(self, name):
self.name = name
def train(self):
print(f"{self.name} 开始基础训练...")
# 子类 (继承语法直接写在括号里)
class LLMModel(Model):
def __init__(self, name, context_window):
# 调用父类构造函数,类似 JS 的 super(name)
super().__init__(name)
self.context_window = context_window
# 重写 (Override) 父类方法
def train(self):
# 可以在重写中调用父类逻辑
super().train()
print(f"--> 正在进行大规模语言预训练,上下文窗口: {self.context_window}")
gpt = LLMModel("GPT-Mini", 128000)
gpt.train()
2. 多态 (Polymorphism) 与鸭子类型
Python 是动态强类型语言,它推崇“鸭子类型”(Duck Typing):如果它走起来像鸭子,叫起来像鸭子,那它就是鸭子。
这意味着你不需要像 Java 或 TypeScript 那样定义严格的 Interface。只要不同类的对象都有 train() 方法,它们就可以被同等地对待。
3. 多继承 (Multiple Inheritance) —— JS 做不到的事
JS 的类只能 extends 一个父类。但 Python 支持多继承。
场景:你有一个 Transformer 架构类,又有一个 VisionModule 视觉模块类,你想造一个“多模态模型”,你可以同时继承这两个类。
class Flyer:
def fly(self): print("I can fly")
class Swimmer:
def swim(self): print("I can swim")
# 同时继承两个爹
class Seaplane(Flyer, Swimmer):
pass
plane = Seaplane()
plane.fly()
plane.swim()
金牌讲师提醒:多继承虽然强大,但容易导致“菱形继承”问题(代码逻辑混乱)。在 AI 实战中,通常使用 Mixin(混入)模式 也就是多继承的一种应用,来给主类添加额外功能。
4.4 dataclass 数据类:轻量对象设计
这是 Python 送给全栈工程师最好的礼物。 🎁
在 AI 和数据处理中,我们经常需要定义一堆只用来“存数据”的对象(类似于 TypeScript 的 interface 或 type 定义的数据结构)。
如果用普通类写,太啰嗦了:
# 传统的笨重写法
class TrainingConfig:
def __init__(self, batch_size, learning_rate, epoch):
self.batch_size = batch_size
self.learning_rate = learning_rate
self.epoch = epoch
def __repr__(self):
return f"Config(lr={self.learning_rate}, ...)" # 还要自己写打印格式,烦死
使用 @dataclass (Python 3.7+):
这就好比你写了 TypeScript 的 Interface,Python 自动帮你把 Constructor、Print 格式、对比函数全部生成好了!
from dataclasses import dataclass
# @dataclass 是一个装饰器(类似于 TS 的 Decorator)
@dataclass
class TrainingConfig:
batch_size: int = 32 # 支持类型提示和默认值
learning_rate: float = 0.001
epoch: int = 100
optimizer: str = "Adam"
# 使用
conf = TrainingConfig(batch_size=64, epoch=200)
# 1. 自动生成了漂亮的打印格式 (__repr__)
print(conf)
# 输出: TrainingConfig(batch_size=64, learning_rate=0.001, epoch=200, optimizer='Adam')
# 2. 像对象一样访问
print(conf.learning_rate)
# 3. 甚至可以直接对比数据内容 (__eq__)
conf2 = TrainingConfig(batch_size=64, epoch=200)
print(conf == conf2) # True (普通类对比的是内存地址,dataclass 对比的是值)
对于前端同学的理解映射:
- 普通 Class ≈ 包含业务逻辑的 Service / Component。
- Dataclass ≈ DTO (Data Transfer Object) / TypeScript Interface / Redux State。
学会 dataclass,你在处理 AI 模型繁杂的配置参数(Hyperparameters)时,代码会变得极其优雅、清晰。
上一章我们搭建了面向对象的骨架,现在我们要往里面填充“血肉”了。在 AI 开发中,你 90% 的时间其实不是在写模型架构,而是在处理数据:读取数据集文件、解析 JSON 配置、处理日志时间戳。
这部分内容虽然基础,但 Python 的处理方式极其优雅,尤其是“上下文管理器”这个概念,绝对会让你眼前一亮。
5. Python 中的常见工具
5.1 文件读写与数据处理
在 Node.js 中,我们要么使用 fs.readFile 的回调地狱,要么使用 fs/promises 配合 async/await。Python 的文件操作则显得更加同步和“线性”,同时通过一种特殊的语法结构保证了安全性。
1. 文件操作:告别 fs.close() 的烦恼——上下文管理器 (with)
在操作文件时,最怕的就是打开了文件却忘记关闭(Memory Leak)。Node.js 的垃圾回收机制虽然强大,但文件描述符泄露依然是个问题。
Python 引入了 with 关键字(Context Manager),它保证了无论代码是否报错,文件都会在退出缩进块时自动关闭。这有点像 React 的 useEffect 清理函数,或者 try-finally 的语法糖,但更简洁。
对比实战:读取文本文件
Node.js (Async) 写法:
const fs = require('fs').promises; async function readData() { try { const data = await fs.readFile('./data.txt', 'utf-8'); console.log(data); } catch (err) { console.error("读取失败", err); } // 实际上你很难在这里显式控制 file close,完全依赖 runtime }
Python 写法(推荐):
# 不需要 async,不需要 try-catch 来关闭文件 try: # 'r' 表示 read (只读), encoding='utf-8' 必加! with open('./data.txt', 'r', encoding='utf-8') as f: content = f.read() # 也可以逐行读取,适合大文件 # lines = f.readlines() print(content) # 出了这个缩进,文件自动关闭 (f.close() 被自动调用) except FileNotFoundError: print("文件找不到")
2. JSON 数据解析与生成:前端最熟悉的陌生人
JSON 是前后端和 AI 配置文件的通用语言。Python 内置了 json 模块,用法与 JS 的 JSON 对象有一一对应的关系,但有两组 API 需要区分:处理字符串和处理文件。
| 操作 | JavaScript | Python (处理字符串) | Python (处理文件流) |
|---|---|---|---|
| 反序列化 (Parse) | JSON.parse(str) |
json.loads(str) |
json.load(file_obj) |
| 序列化 (Stringify) | JSON.stringify(obj) |
json.dumps(obj) |
json.dump(obj, file_obj) |
金牌讲师记忆口诀:
- 带
s的 (loads,dumps) 是处理 String 的(和 JS 一样)。 - 不带
s的 (load,dump) 是直接对接文件流的(这是 Python 特色,少写一步读取/写入操作)。
实战代码:
import json
# 1. 模拟从 API 拿到的 JSON 字符串
json_str = '{"name": "DeepSeek", "type": "LLM", "version": 2}'
# JS: JSON.parse(json_str)
data = json.loads(json_str)
print(data['name']) # 输出: DeepSeek
# 2. 将字典保存为 JSON 文件
config = {
"batch_size": 64,
"learning_rate": 0.001,
"model_path": "./checkpoints",
"notes": "这是中文注释"
}
# 写入文件
with open('config.json', 'w', encoding='utf-8') as f:
# ensure_ascii=False 是关键!
# 否则中文会被转义成 \uXXXX 这种乱码,前端看着会很难受
# indent=4 相当于 JS 的 JSON.stringify(obj, null, 4)
json.dump(config, f, ensure_ascii=False, indent=4)
print("配置已保存!")
5.2 日期与时间处理
JS 的原生 Date 对象可谓是“臭名昭著”,月份从 0 开始(0 是 1 月),格式化日期还得手写或者求助 moment.js / day.js。
Python 的 datetime 模块虽然稍显复杂,但逻辑非常严密,且不依赖第三方库也能做很多事。
1. 基础时间操作:datetime vs Date
Python 的 datetime 模块下有几个核心类:datetime (日期+时间), date (只含日期), time (只含时间), timedelta (时间差)。
from datetime import datetime, timedelta
# 获取当前时间
now = datetime.now()
print(f"当前时间: {now}")
# 格式化时间 (String Format Time) -> JS 的 moment().format('YYYY-MM-DD')
# 注意:Python 用的是 %Y %m %d 这种占位符
formatted = now.strftime("%Y-%m-%d %H:%M:%S")
print(f"格式化后: {formatted}")
# 解析时间字符串 (String Parse Time)
str_time = "2023-10-01 12:00:00"
dt_obj = datetime.strptime(str_time, "%Y-%m-%d %H:%M:%S")
print(f"解析回对象: {dt_obj.year}年{dt_obj.month}月") # 月份是 10!不是 9!👏
# 时间计算:推算 3 天后的时间
# JS 需要: new Date(now.getTime() + 3 * 24 * 60 * 60 * 1000) ... 心累
future = now + timedelta(days=3, hours=2)
print(f"三天两小时后: {future}")
2. 时区处理:pytz 的应用
在 AI 训练日志和后端服务中,时区(Timezone)非常重要。默认的 datetime.now() 经常是“Naive”(无时区信息的),这在跨国服务器部署时是灾难。
虽然 Python 3.9+ 引入了 zoneinfo,但在很多老项目和教程中,pytz 依然是王者。
前端痛点解决:JS 里的时区处理通常很头大,Python 通过显式指定 tzinfo 来解决。
import pytz
from datetime import datetime
# 1. 获取 UTC 时间 (标准做法)
utc_now = datetime.now(pytz.utc)
print(f"UTC 时间: {utc_now}")
# 2. 转换为北京时间 (Asia/Shanghai)
beijing_tz = pytz.timezone('Asia/Shanghai')
local_time = utc_now.astimezone(beijing_tz)
print(f"北京时间: {local_time}")
# 3. 创建特定时区的时间
# 警告:不要直接用 datetime(..., tzinfo=beijing_tz),容易出 Bug
# 推荐用 localize 方法
naive_dt = datetime(2023, 1, 1, 12, 0, 0)
correct_dt = beijing_tz.localize(naive_dt)
print(f"正确的带时区时间: {correct_dt}")
小结:
- 文件读写必用
with open。 - JSON 处理记住
loads(String) 和load(File) 的区别,中文记得关掉ensure_ascii。 - 时间计算用
timedelta,跨时区转换请认准pytz或zoneinfo。
6. 用 FastAPI 构建简单项目
在这一章,我们要把 Python 变成你手中的瑞士军刀。我们将采用企业级分层架构(Controller-Service-Data Layer),这与你熟悉的 NestJS 或大型 React 项目的组织方式是一致的。
📂 企业级项目目录结构
首先,别把代码全写在一个文件里。一个标准的 AI 后端服务应该是这样的:
my_ai_project/
├── app/
│ ├── main.py # [入口] 类似于 index.ts / App.tsx
│ ├── api/ # [路由层] 类似于 routes / controllers
│ │ └── v1/
│ │ └── endpoints/
│ │ └── user.py # 用户模块的接口
│ ├── schemas/ # [数据模型] 类似于 TS Interfaces / DTOs
│ │ └── user.py
│ ├── core/ # [配置] 环境变量、安全设置
│ └── db/ # [数据库] ORM设置
└── requirements.txt # [依赖] 类似于 package.json
6.1 FastAPI 快速上手
1. 入口文件:启动你的“服务端 App”
我们先看 app/main.py。这是整个后端的枢纽。
# app/main.py
from fastapi import FastAPI
from app.api.v1.endpoints import user # 导入我们需要挂载的路由模块
# 1. 初始化应用
app = FastAPI(
title="AI Backend Service",
description="为前端赋能的 Python 服务",
version="1.0.0"
)
# 2. 注册路由
# include_router 类似于 Express 的 app.use('/users', userRouter)
# tags=["users"] 会在 Swagger 文档中把这些接口归类到一个折叠面板下
app.include_router(user.router, prefix="/api/v1/users", tags=["users"])
# 3. 根路由
@app.get("/")
async def root():
return {"message": "Hello Front-End Developers!"}
👨💻 前端视角解读:
app = FastAPI()就像const app = express()或const app = await NestFactory.create(AppModule)。- Python 的装饰器
@app.get("/")就像 NestJS 的@Get('/'),它把下面的函数绑定到了 HTTP GET 请求上。
2. 路由系统:路径参数与查询参数
接下来进入核心业务层 app/api/v1/endpoints/user.py。前端最关心的就是:怎么接 URL 里的参数?
# app/api/v1/endpoints/user.py
from fastapi import APIRouter, Query, HTTPException
from typing import Optional
# 创建一个路由实例,相当于 express.Router()
router = APIRouter()
# 模拟数据库数据
fake_users_db = [{"id": 1, "name": "Tony"}, {"id": 2, "name": "Jack"}]
# === 场景 A:获取单个用户 (路径参数) ===
# URL: GET /api/v1/users/1
@router.get("/{user_id}")
async def read_user(user_id: int): # <--- 重点看这里
"""
获取特定用户信息
"""
# 逻辑解析:
# 1. user_id: int -> FastAPI 会自动读取 URL 中的 user_id。
# 2. 它是强类型的!如果你传 /users/abc,FastAPI 直接报错,不会进入函数。
# 3. 这里 user_id 已经是数字类型,不用像 JS 那样 parseInt(id) 了。
# 模拟查询
user = next((u for u in fake_users_db if u["id"] == user_id), None)
if not user:
# 抛出异常,类似于 throw new Error(),但会直接转为 404 HTTP 响应
raise HTTPException(status_code=404, detail="User not found")
return user
# === 场景 B:搜索用户 (查询参数) ===
# URL: GET /api/v1/users/?keyword=jack&limit=10
@router.get("/")
async def search_users(
keyword: Optional[str] = None, # 默认是 None,表示可选
limit: int = Query(10, gt=0, le=100) # 默认10,且必须 0 < limit <= 100
):
"""
搜索用户列表
"""
# 逻辑解析:
# 1. 函数参数中,没有在路径里声明的变量(如 keyword),自动被视为 ?query= 参数。
# 2. Query(...) 是一个强大的校验器。如果前端传 limit=200,API 会直接拒绝请求。
# 3. 这里的校验逻辑,如果在 Node.js 里写,可能需要好几行 if/else。
return {"keyword": keyword, "limit": limit, "data": fake_users_db[:limit]}
👨💻 前端视角解读:
- 不再需要手动写
const { id } = req.params或const { limit } = req.query。- 你只需要在函数参数里定义好变量名和类型,FastAPI 帮你完成取值、转换、校验三步走。
3. 异步数据库操作(对标 ORM)
在 AI 项目中,数据库操作必须是异步的(Async),否则一个慢查询会卡死整个服务。这里我们用 SQLAlchemy(Python 版的 TypeORM)的异步模式。
# 假设这是 app/services/user_service.py
from sqlalchemy.future import select
from sqlalchemy.ext.asyncio import AsyncSession
from app.models.user import User # 导入 ORM 模型
async def get_user_by_email(db: AsyncSession, email: str):
# 1. 构建查询语句 (类似于 TypeORM 的 QueryBuilder)
# SQL: SELECT * FROM users WHERE email = '...'
stmt = select(User).where(User.email == email)
# 2. 执行查询 (注意 await)
# 这完全等同于 JS 的: const result = await db.query(...)
result = await db.execute(stmt)
# 3. 获取结果
# scalars().first() 相当于取数组的第一个元素
return result.scalars().first()
6.2 使用 Pydantic:更优雅的参数校验
这是 Python 后端最让前端羡慕的功能。
在 Node.js 中,你可能需要用 Joi、Zod 或 class-validator 来校验 POST 请求的 Body。
在 FastAPI 中,这叫做 Pydantic。
1. 定义 DTO (Data Transfer Object)
我们创建一个 app/schemas/user.py。这不仅仅是类型定义,它是运行时校验规则。
# app/schemas/user.py
from pydantic import BaseModel, EmailStr, Field
from typing import Optional
# === 接收前端 POST 数据的模型 (Request DTO) ===
class UserCreate(BaseModel):
# EmailStr: Pydantic 会自动正则校验这是否是个邮箱
email: EmailStr
# Field: 类似于 Zod 的 .min(6).max(20)
password: str = Field(..., min_length=6, max_length=20, description="密码")
# Optional: 可选字段
age: Optional[int] = Field(None, ge=18, description="年龄必须大于18")
# === 返回给前端的数据模型 (Response DTO) ===
class UserResponse(BaseModel):
id: int
email: EmailStr
is_active: bool
# Config: 允许 Pydantic 直接读取 ORM 对象的数据
class Config:
from_attributes = True
2. 在 Controller 中使用 Pydantic
回到 app/api/v1/endpoints/user.py,看看如何处理 POST 请求。
from app.schemas.user import UserCreate, UserResponse
# response_model=UserResponse:
# 告诉 FastAPI,不论我的函数里 return 了什么乱七八糟的对象,
# 最终返回给前端 JSON 时,只保留 UserResponse 里定义的字段。
# (这一步自动帮你把 password 等敏感字段过滤掉了!)
@router.post("/", response_model=UserResponse)
async def create_user(
user_in: UserCreate # <--- 核心魔法
):
"""
注册新用户
"""
# 逻辑解析:
# 1. 在进入这个函数之前,FastAPI 已经拿到了 Request Body。
# 2. 它依照 UserCreate 的规则进行了严格校验(邮箱格式?密码长度?)。
# 3. 如果校验失败,直接返回 422 错误,函数体根本不会执行。
# 4. 如果成功,user_in 就是一个对象,你可以用 user_in.email 直接访问。
# 模拟数据库保存操作
# db_user = await service.create(user_in)
# 模拟返回数据
fake_db_obj = {
"id": 88,
"email": user_in.email,
"password": "hashed_secret", # 注意:这个字段会被 response_model 自动过滤掉
"is_active": True
}
return fake_db_obj
👨💻 金牌教师总结:
- Type Hints (类型提示) 不仅仅是像 TypeScript 那样给 IDE 看的,在 FastAPI 里,它们是真实生效的逻辑。
- Pydantic 让你告别了代码里到处充斥的
if (!body.email) return error这种防御性代码。- Response Model 则是你的安全守门员,防止后端不小心把整个 User 对象(包含密码)直接
JSON.stringify给前端。
掌握了这一节,你就拥有了构建 AI 业务逻辑(比如接收用户 Prompt,调用 OpenAI,返回结果)的坚实骨架。下一步,我们就可以往这个架构里填充 AI 代码了!
好的,收到!作为金牌讲师,我深知**“光说不练假把式”**。代码写得再漂亮,跑不起来也是白搭。
这一节,我们补全最后一块拼图:如何安装依赖、启动服务,并进行真实的 API 调用测试。
我们将沿用上一节定义的 企业级目录结构。
6.3 项目启动与接口实测
1. 准备依赖环境
在 Node.js 中,你有 package.json;在 Python 中,我们通常使用 requirements.txt。
在项目根目录下创建一个 requirements.txt 文件:
fastapi==0.109.0
uvicorn[standard]==0.27.0 # ASGI 服务器,相当于 Node
pydantic==2.6.0 # 数据校验
pydantic-settings==2.1.0 # 配置管理
sqlalchemy==2.0.25 # ORM
asyncpg==0.29.0 # 异步 PostgreSQL 驱动
安装依赖命令(终端执行):
# 建议先创建虚拟环境 (类似于在项目里放一个独立的 node_modules)
python -m venv venv
# 激活虚拟环境 (Mac/Linux)
source venv/bin/activate
# 激活虚拟环境 (Windows)
# venv\Scripts\activate
# 安装包
pip install -r requirements.txt
2. 启动服务
在 Node.js 中,你可能会用 npm run dev (底层可能是 nodemon server.js)。
在 FastAPI 中,我们需要使用 Uvicorn 这个高性能 ASGI 服务器来运行我们的 App。
启动命令(在项目根目录执行):
# app.main:app 解析:
# app.main -> 对应 app/main.py 文件
# :app -> 对应文件中创建的 app = FastAPI() 对象
# --reload -> 开启热更新(改代码自动重启),开发必备!
uvicorn app.main:app --reload
当看到如下输出,说明服务启动成功:
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [12345] using WatchFiles
INFO: Application startup complete.
3. 接口实测(Request Examples)
现在服务跑在 http://127.0.0.1:8000。我们来看看如何请求上一节写的那些接口。
为了方便演示,我提供了 curl 命令,你可以直接在终端粘贴运行。当然,你也可以用 Postman 或 Apifox。
场景 A: 获取根路径
- 方法:
GET - URL:
http://127.0.0.1:8000/
curl -X 'GET' \
'http://127.0.0.1:8000/' \
-H 'accept: application/json'
预期响应:
{
"message": "Hello Front-End Developers!"
}
场景 B: 获取特定用户(路径参数)
- 方法:
GET - URL:
http://127.0.0.1:8000/api/v1/users/1
curl -X 'GET' \
'http://127.0.0.1:8000/api/v1/users/1' \
-H 'accept: application/json'
预期响应:
{
"id": 1,
"name": "Tony"
}
测试错误情况(类型检查):
如果你传字符串 abc 给需要 int 的接口:curl -X 'GET' 'http://127.0.0.1:8000/api/v1/users/abc'
预期响应 (FastAPI 自动处理):
{
"detail": [
{
"type": "int_parsing",
"loc": ["path", "user_id"],
"msg": "Input should be a valid integer",
"input": "abc"
}
]
}
场景 C: 创建用户(POST + JSON Body + Pydantic 校验)
这是最能体现 FastAPI 强大的地方。
- 方法:
POST - URL:
http://127.0.0.1:8000/api/v1/users/ - Header:
Content-Type: application/json
请求命令:
curl -X 'POST' \
'http://127.0.0.1:8000/api/v1/users/' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"email": "frontend@example.com",
"password": "mysecretpassword",
"age": 25
}'
预期响应:
注意看!password 字段不见了,因为我们在 UserResponse 里把它过滤了。而且自动添加了 id 和 is_active。
{
"id": 88,
"email": "frontend@example.com",
"is_active": true
}
测试校验失败(密码太短):
如果把 "password" 改成 "123" (我们在代码里限制了 min_length=6):
预期响应:
{
"detail": [
{
"type": "string_too_short",
"loc": ["body", "password"],
"msg": "String should have at least 6 characters",
"ctx": {"min_length": 6}
}
]
}
4. 终极神器:Swagger UI 文档
作为前端,最烦的就是后端改了接口不告诉我们,或者文档更新不及时。
FastAPI 内置了 Swagger UI。服务启动后,直接在浏览器访问:
👉 http://127.0.0.1:8000/docs
你会看到一个交互式的文档页面:
- 所见即所得:所有 API 自动列出。
- Schema 可视化:点开 Schemas,可以看到
UserCreate和UserResponse的具体字段定义。 - 在线调试:点击 “Try it out” 按钮,直接在浏览器里发送请求,连
curl都不用写!
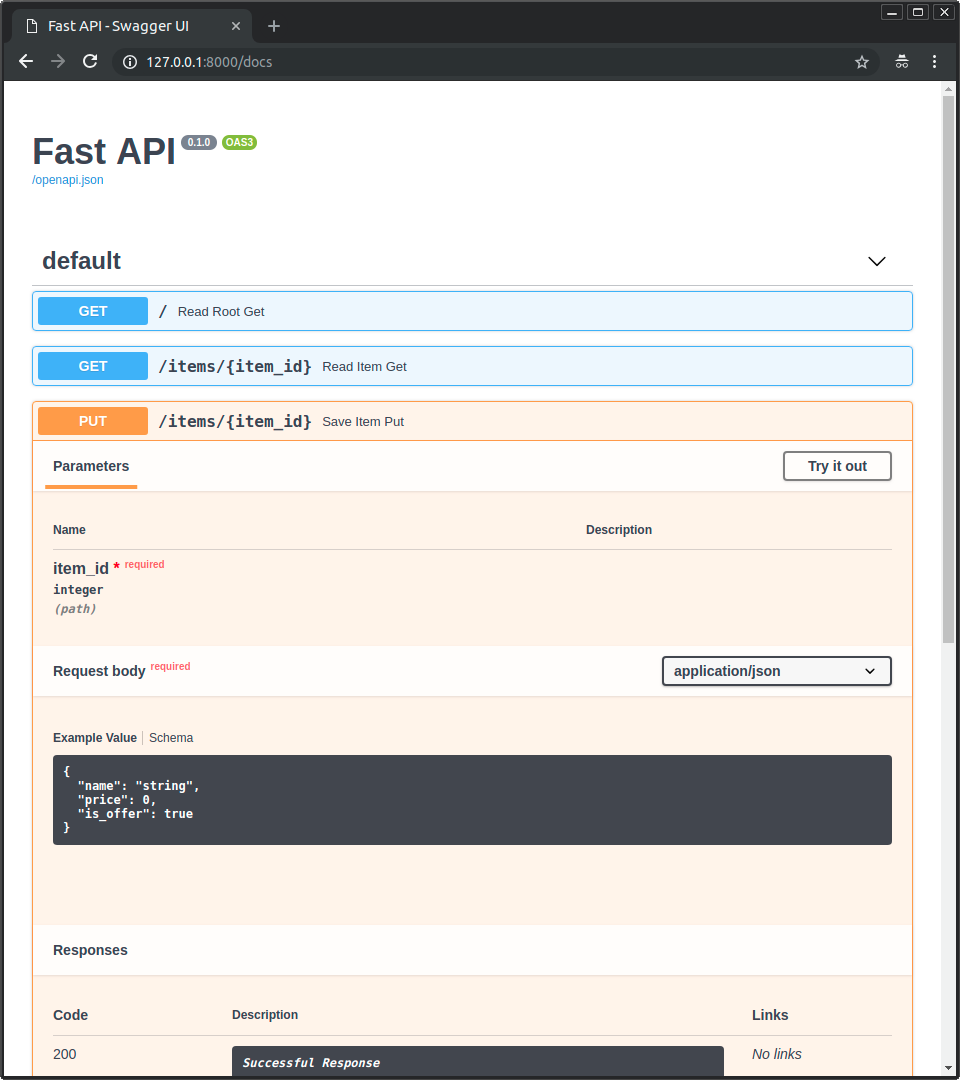
金牌教师总结
到现在为止,你已经完成了一个符合企业级规范的后端微服务雏形:
- 目录结构:分层清晰,拒绝面条代码。
- 依赖管理:
requirements.txt明确环境。 - 开发体验:
uvicorn热重载,写完代码直接生效。 - 接口测试:全自动的 Swagger 文档,前后端联调效率翻倍。
这就是为什么 AI 领域的开发(从 OpenAI 的官方示例到企业内部的中台)都首选 FastAPI 的原因。准备好进入下一阶段了吗?我们要开始往里面塞 AI 模型了!
❌ “做 AI 应用不就是前端直接 fetch OpenAI 的 API 吗?”
✅ 错!大错特错!
如果在前端直接调用:
- API Key 裸奔:你的 Key 会直接暴露在浏览器 Network 面板里,任何人都能拿去刷爆你的信用卡。
- 毫无记忆:原生 API 是无状态的,你必须在后端维护“对话历史(Context)”。
- 没有大脑:你没法做 Prompt Engineering(提示词工程)、没法挂载知识库(RAG),也没法做权限控制。
今天我们要用 FastAPI + Poetry 构建一个企业级 AI 中台服务。这不仅仅是转发请求,而是构建一个AI 系统。
7. 构建 AI 核心服务:从调用到系统
7.1 环境治理:使用 Poetry 管理依赖
在上一节我们用了 requirements.txt,那属于“老派”做法。在企业级 Python 项目中,Poetry 才是王者。
👉 前端对标:
pip=npm(早期版本,没有 lock 文件,容易版本冲突)- Poetry =
npm/yarn+package.json+node_modules管理。它有清晰的依赖树和 Lock 文件。
1. 初始化 Poetry 项目
假设你已经在项目根目录:
# 1. 安装 Poetry (如果未安装)
curl -sSL https://install.python-poetry.org | python3 -
# 2. 初始化项目 (生成 pyproject.toml,类似 package.json)
poetry init
# 3. 安装 AI 相关依赖
# openai: 官方 SDK
# python-dotenv: 用于读取 .env 环境变量
# tiktoken: 计算 Token 数量(OpenAI 计费相关)
poetry add fastapi uvicorn[standard] pydantic pydantic-settings openai python-dotenv tiktoken
现在你的项目里多了一个 pyproject.toml,这比 txt 文件优雅多了。
7.2 企业级 AI 架构设计
我们需要在之前的架构上扩展 AI Service Layer。请注意,我们绝对不会在 Controller(路由层)里直接写 OpenAI 的调用代码。
📂 升级后的目录结构:
my_ai_project/
├── app/
│ ├── api/
│ │ └── v1/
│ │ └── endpoints/
│ │ └── chat.py # [Controller] 处理 HTTP 请求和流式响应
│ ├── core/
│ │ └── config.py # [Config] 统一管理 API KEY
│ ├── services/
│ │ └── llm_service.py # [Service] AI 核心逻辑封装 (Prompt/Model)
│ ├── schemas/
│ │ └── chat.py # [DTO] 定义对话的输入输出格式
│ └── main.py
├── .env # 存放 OPENAI_API_KEY
├── poetry.lock
└── pyproject.toml
7.3 编写核心 AI 服务层 (Service Layer)
我们需要封装一个 LLMService。这个类的作用是隔离底层模型差异。今天你用 GPT-4,明天老板想换 Claude 3 或者国产大模型,只需要改这个文件,Controller 层完全不用动。
文件:app/services/llm_service.py
import os
from openai import AsyncOpenAI
from typing import AsyncGenerator
# 加载环境变量
from dotenv import load_dotenv
load_dotenv()
class LLMService:
def __init__(self):
# 初始化 OpenAI 异步客户端
# 为什么用异步?因为 LLM 响应很慢,同步会阻塞整个服务器线程!
self.client = AsyncOpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
# 如果用国内中转,这里可以配置 base_url
# base_url="https://api.openai-proxy.com/v1"
)
async def chat_stream(self, messages: list) -> AsyncGenerator[str, None]:
"""
流式对话生成器
前端最喜欢的 "打字机效果" 就是靠这个实现的
"""
try:
# 发起流式请求
stream = await self.client.chat.completions.create(
model="gpt-3.5-turbo", # 或者 gpt-4
messages=messages,
stream=True, # <--- 重点:开启流式模式
temperature=0.7, # 控制创造性
max_tokens=1000
)
# 逐块(chunk)返回数据
async for chunk in stream:
content = chunk.choices[0].delta.content
if content:
yield content # <--- Python 的 yield,相当于生成器
except Exception as e:
print(f"OpenAI API Error: {str(e)}")
yield f"Error: {str(e)}"
# 单例模式导出,避免重复实例化
llm_service = LLMService()
👨💻 金牌讲师解析:
- AsyncOpenAI: 必须用异步客户端。如果 100 个人同时请求,同步代码会排队,异步代码会并行处理。
- yield: 这里使用了 Python 的
AsyncGenerator。它就像一个水龙头,大模型吐出一个字,我们就往前端“流”一个字。
7.4 定义数据交互标准 (Schemas/DTO)
前端发给后端的 JSON 格式,必须严格定义。
文件:app/schemas/chat.py
from pydantic import BaseModel
from typing import List, Optional
class Message(BaseModel):
role: str # "user" | "assistant" | "system"
content: str
class ChatRequest(BaseModel):
messages: List[Message]
# 可以在这里加参数控制,比如 temperature
temperature: Optional[float] = 0.7
7.5 实现流式接口 (Controller Layer)
这是最关键的一步。普通的 return JSON 是等 AI 说完一整段话才返回,用户体验极差。我们要用 SSE (Server-Sent Events) 技术。
文件:app/api/v1/endpoints/chat.py
from fastapi import APIRouter
from fastapi.responses import StreamingResponse
from app.schemas.chat import ChatRequest
from app.services.llm_service import llm_service
router = APIRouter()
@router.post("/completions")
async def chat_completions(request: ChatRequest):
"""
AI 对话接口 (流式响应)
"""
# 1. 可以在这里做 Prompt Engineering (提示词注入)
# 比如:强制在用户消息前加一段 "你是一个金牌前端讲师..." 的 system prompt
# 2. 调用 Service 层获取生成器
generator = llm_service.chat_stream(
messages=[msg.model_dump() for msg in request.messages]
)
# 3. 返回流式响应
# media_type="text/event-stream" 是标准的 SSE 格式
return StreamingResponse(generator, media_type="text/event-stream")
7.6 启动与实战测试
确保你在 .env 文件里填好了 Key:
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxx
启动服务 (使用 Poetry 环境):
poetry run uvicorn app.main:app --reload
👉 如何测试流式响应?
普通的 curl 也能看到效果,你会看到字是一个个蹦出来的,而不是卡顿很久一次性显示。
curl -X 'POST' \
'http://127.0.0.1:8000/api/v1/users/completions' \
-H 'accept: text/event-stream' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{"role": "system", "content": "你是一个助手"},
{"role": "user", "content": "请用100字介绍一下FastAPI"}
]
}'
从“调用 AI”到“构建 AI 系统”的进化
作为架构师,我要提醒你,刚才的代码只是起点。真正的 AI 系统(这也是你下一阶段要学习的方向)是在 LLMService 里做文章:
-
Prompt Management (提示词管理):
- 你不会想把 Prompt 写死在代码里。你需要一个模板系统,比如
PromptTemplate。 - 例子:把用户的 “介绍 FastAPI” 包装成 “请以资深架构师的身份,用幽默的语气介绍 FastAPI”。
- 你不会想把 Prompt 写死在代码里。你需要一个模板系统,比如
-
Context Window (上下文管理):
- 大模型记不住你说过的话。你需要把历史聊天记录存在数据库(PostgreSQL/Redis)里,每次请求时取出来,塞进
messages列表发给 OpenAI。
- 大模型记不住你说过的话。你需要把历史聊天记录存在数据库(PostgreSQL/Redis)里,每次请求时取出来,塞进
-
RAG (检索增强生成):
- 当用户问 “我们公司的请假流程是什么?” GPT-4 不知道。
- 你需要先去向量数据库查文档,把相关段落作为 Context 塞给 AI。这就是目前最火的 RAG 架构。
总结
-
python是动态类型语言,变量定义直接用 变量名=xx即可。
-
python天然支持模块化,可以通过from 模块名 import 方法1,方法2等方法导入模块
-
fastApi相当于nest,其用法也很相像,也是MVC架构,使用类似于ts的装饰器,最简单的例子
一,创建根服务 (main.module.ts)
# app/main.py from fastapi import FastAPI from app.api.v1.endpoints import users from app.api.v1.endpoints import chat app = FastAPI( title="AI Backend Service", description="企业级 FastAPI 项目模板", version="1.0.0" ) # 注册路由,类似于 express 的 app.use('/users', userRouter) app.include_router(chat.router, prefix="/api/v1/chat", tags=["chat"]) @app.get("/") async def root(): return {"message": "Service is running correctly"}二 创建controller层
在app/api/v1/endpoints下创建chat.py文件
from fastapi import APIRouter from fastapi.responses import StreamingResponse from app.schemas.chat import ChatRequest from app.services.llm_service import llm_service router = APIRouter() @router.post("/completions") async def chat_completions(request: ChatRequest): """ AI 对话接口 (流式响应) """ # 1. 可以在这里做 Prompt Engineering (提示词注入) # 比如:强制在用户消息前加一段 "你是一个金牌前端讲师..." 的 system prompt # 2. 调用 Service 层获取生成器 generator = llm_service.chat_stream( messages=[msg.model_dump() for msg in request.messages] ) # 3. 返回流式响应 # media_type="text/event-stream" 是标准的 SSE 格式 return StreamingResponse(generator, media_type="text/event-stream")创建router,定义url参数,ChatRequest类似于nest的class_vate校验。
三 创建se rvice层
在app/services下创建llm_service.py文件
import os from openai import AsyncOpenAI from typing import AsyncGenerator # 加载环境变量 from dotenv import load_dotenv load_dotenv() class LLMService: def __init__(self): # 初始化 OpenAI 异步客户端 # 为什么用异步?因为 LLM 响应很慢,同步会阻塞整个服务器线程! self.client = AsyncOpenAI( api_key=os.getenv("OPENAI_API_KEY"), # 如果用国内中转,这里可以配置 base_url base_url="http://localhost:11434/v1" , ) async def chat_stream(self, messages: list) -> AsyncGenerator[str, None]: """ 流式对话生成器 前端最喜欢的 "打字机效果" 就是靠这个实现的 """ try: # 发起流式请求 stream = await self.client.chat.completions.create( model="llama3.2", # 或者 gpt-4 messages=messages, stream=True, # <--- 重点:开启流式模式 temperature=0.7, # 控制创造性 max_tokens=1000 ) # 逐块(chunk)返回数据 async for chunk in stream: content = chunk.choices[0].delta.content if content: yield content # <--- Python 的 yield,相当于生成器 except Exception as e: print(f"OpenAI API Error: {str(e)}") yield f"Error: {str(e)}" # 单例模式导出,避免重复实例化 llm_service = LLMService()写业务方法,供controller使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)