PEL-NAS:搜索空间分区+提示协同进化,彻底解决LLM-NAS模式崩溃
ICLR 2026 | PEL-NAS:搜索空间分区+提示协同进化,彻底解决LLM-NAS模式崩溃
- 会议:ICLR 2026(International Conference on Learning Representations)
- 状态:Under review(在审会议论文)
- 年份:2026 年
- arXiv 版本:2025 年 10 月公开(arXiv:2510.01472)
摘要
硬件感知神经网络架构搜索(HW-NAS)需要在端侧设备约束下同时优化精度与推理延迟。
传统超网方法(如FairNAS、OFA)需要数GPU天才能完成搜索;
基于大语言模型(LLM)的NAS虽然无需训练超网、反馈更快,但存在严重的探索偏置(模式崩溃)——LLM只会在极小的搜索空间内重复生成相似结构,无法覆盖全延迟区间的最优架构。
为此,本文提出 PEL-NAS:
Partitioned(搜索空间分区)+ Evolutionary(架构-提示协同进化)+ LLM-driven(LLM驱动)的硬件感知NAS框架。
核心包含三大模块:
- 复杂度驱动搜索空间分区:强制多样性,从根源解决探索偏置;
- LLM架构-提示协同进化:知识库迭代+进化生成,越搜越强;
- 零成本代理预测:无需训练大量候选网络,搜索从天级降到分钟级。
实验结果:在HW-NAS-Bench上,PEL-NAS实现更高HV、更低IGD,同等精度下延迟最高降低 54%,搜索成本从GPU天 → 3分钟。
一、引言:LLM做NAS到底卡在哪?
1.1 传统HW-NAS的痛点
- 超网方法:精度高,但成本爆炸(FairNAS需10 GPU天);
- 免训练NAS:速度快,但搜索引导能力弱;
- LLM-NAS:不用训超网,但模式崩溃、探索偏置、静态提示无记忆。
1.2 本文要解决的两个核心问题
- LLM探索偏置:只生成熟悉结构,覆盖不全,类似GAN模式崩溃;
- 静态提示无进化:不会从历史结果学习,无法逼近真实帕累托前沿。
二、相关工作
- HW-NAS:多目标优化问题,目标是精度↑、延迟↓,常用基准HW-NAS-Bench;
- 零成本NAS:用SynFlow、JacobCov等代理指标免训练评估;
- LLM-NAS:直接生成结构,但多样性差、易无效;
- 进化算法+小生境:保持种群多样性,防止早熟收敛。
三、PEL-NAS 方法详解
3.1 整体总览:三大部分
PEL-NAS =
复杂度驱动搜索空间分区 +
LLM架构-提示协同进化 +
零成本目标评估
3.2 图片解读
图1:三种生成策略在HW-NAS-Bench的覆盖对比
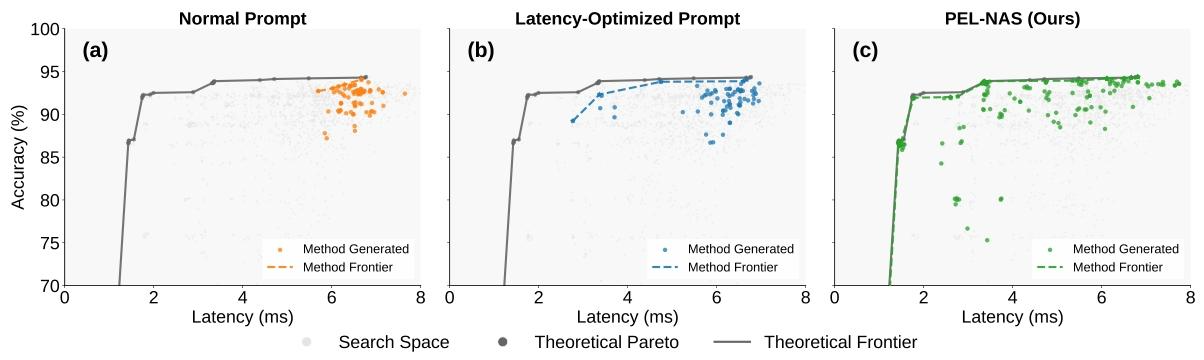
- 橙色(Normal Prompt):普通提示,LLM严重扎堆,只覆盖极小区域;
- 蓝色(Latency-optimized Prompt):加了延迟提示,稍微好一点,但依然不均匀,低延迟结构极少;
- 绿色(PEL-NAS):全延迟区间近乎完美覆盖,无空白、无聚集。
结论:只有分区策略能真正解决LLM的探索偏置,单纯优化提示词无效。
图2:PEL-NAS 整体框架图
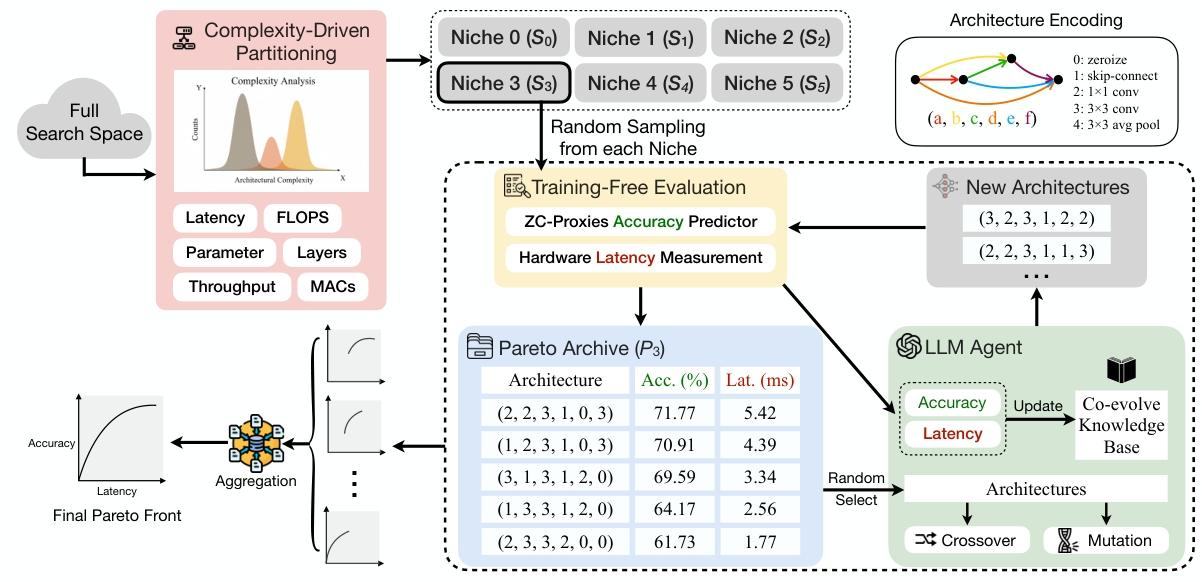
1. 左侧:复杂度驱动分区(Complexity-Driven Partitioning)
这是解决 LLM-NAS 模式崩溃的核心入口:
- 输入:完整搜索空间(Full Search Space)
- 输出:6 个互不重叠的子空间(Niche 0~Niche 5,记为 S₀~S₅)
- 分区依据:
基于架构复杂度分析(图中柱状图),以 3×3 卷积数量 为核心指标,结合延迟、FLOPs、参数量、层数、吞吐量、MACs 等硬件相关指标,将巨大的无序搜索空间切分为 6 个复杂度梯度明确的子空间。 - 作用:强制 LLM 必须在每个复杂度区间独立搜索,从结构上杜绝「扎堆生成相似结构」的模式崩溃。
2. 顶部:子空间采样(Random Sampling from each Niche)
- 从每个 Niche(子空间)中随机采样初始架构,保证每个复杂度区间都有初始种群。
- 右侧给出了架构编码方式:
- 用元组
(a,b,c,d,e,f)表示网络结构 - 每个位置对应一种操作:
0: zeroize(零操作)1: skip-connect(跳连)2: 1×1 conv(1×1卷积)3: 3×3 conv(3×3卷积)4: 3×3 avg pool(3×3平均池化)
- 例:
(3,2,3,1,2,2)代表一个由 3×3卷积、1×1卷积、跳连等组合而成的网络。
- 用元组
3. 中间偏右:免训练评估(Training-Free Evaluation)
这是 PEL-NAS 实现分钟级搜索的效率核心:
- 精度预测:用 13 个零成本代理(ZC-Proxies) 集成 XGBoost 预测模型精度,无需训练网络,直接从初始化状态评估性能。
- 延迟测量:直接查询 HW-NAS-Bench 硬件延迟表,秒级获取真实硬件延迟,无噪声、无额外计算开销。
- 输出:将每个架构的
Acc.(%)和Lat.(ms)存入 帕累托归档库(Pareto Archive, P₃)。
4. 中间偏左:帕累托归档库(Pareto Archive, P₃)
- 存储所有被评估过的架构及其精度、延迟。
- 表中示例:
架构编码 Acc.(%) Lat.(ms) (2,2,3,1,0,3) 71.77 5.42 (1,2,3,1,0,3) 70.91 4.39 (3,1,3,1,2,0) 69.59 3.34 (1,3,3,1,2,0) 64.17 2.56 (2,3,3,2,0,0) 61.73 1.77 - 这些数据会作为 LLM Agent 的历史经验,用于后续协同进化。
5. 右侧:LLM Agent(核心大脑)
这是 PEL-NAS 的智能进化模块,实现「架构-提示词协同进化」:
- 知识更新:
- 从帕累托归档库中读取精度、延迟数据,更新协同进化知识库(Co-evolve Knowledge Base)。
- LLM 会总结设计规律,例如「3×3卷积多则延迟高、精度高」「skip-connect 能显著降低延迟」。
- 父代选择:
- 从帕累托归档库中随机选择优秀架构作为父代。
- 进化操作:
- 交叉(Crossover):融合两个父代架构的组件,生成新结构。
- 变异(Mutation):对单个架构进行局部修改(如将 3×3卷积替换为 skip-connect),探索新结构。
- 输出新架构:
- 生成一批新架构编码(如
(3,2,3,1,2,2)),送回「免训练评估」模块,完成一轮进化闭环。
- 生成一批新架构编码(如
6. 底部:聚合与最终帕累托前沿(Aggregation & Final Pareto Front)
- 每个 Niche 独立进化完成后,聚合所有子空间的帕累托最优架构。
- 最终生成完整精度-延迟帕累托前沿(左下角曲线):
- 横轴:延迟(Latency)
- 纵轴:精度(Accuracy)
- 曲线上的每个点代表「无法再找到一个同时更准、更快」的架构,即硬件约束下的最优解。
图3:搜索空间复杂度分析(分区的科学依据)
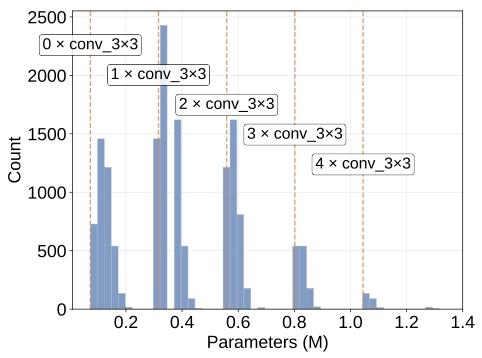
作者统计发现:
模型参数量、延迟 与 3×3卷积数量呈极强的阶梯式相关。
因为3×3卷积参数量是1×1的9倍,是决定硬件开销的核心因素。
所以按3×3卷积数量分区,科学且有效。
表1:6个niche分区规则(核心设计)
| Niche | 3×3卷积数 | 1×1卷积数 | 定位 |
|---|---|---|---|
| S0 | 0 | 0 | 无卷积架构 |
| S1 | 0 | ≥1 | 超低延迟轻量模型 |
| S2 | 1 | 任意 | 入门复杂度 |
| S3 | 2 | 任意 | 中等复杂度 |
| S4 | 3 | 任意 | 高复杂度 |
| S5 | ≥4 | 任意 | 最高复杂度 |
作用:强制LLM在6个难度区间都搜索,杜绝模式崩溃。
图4:LLM提示-架构协同进化(论文大脑)
分为两个强耦合阶段,形成闭环进化: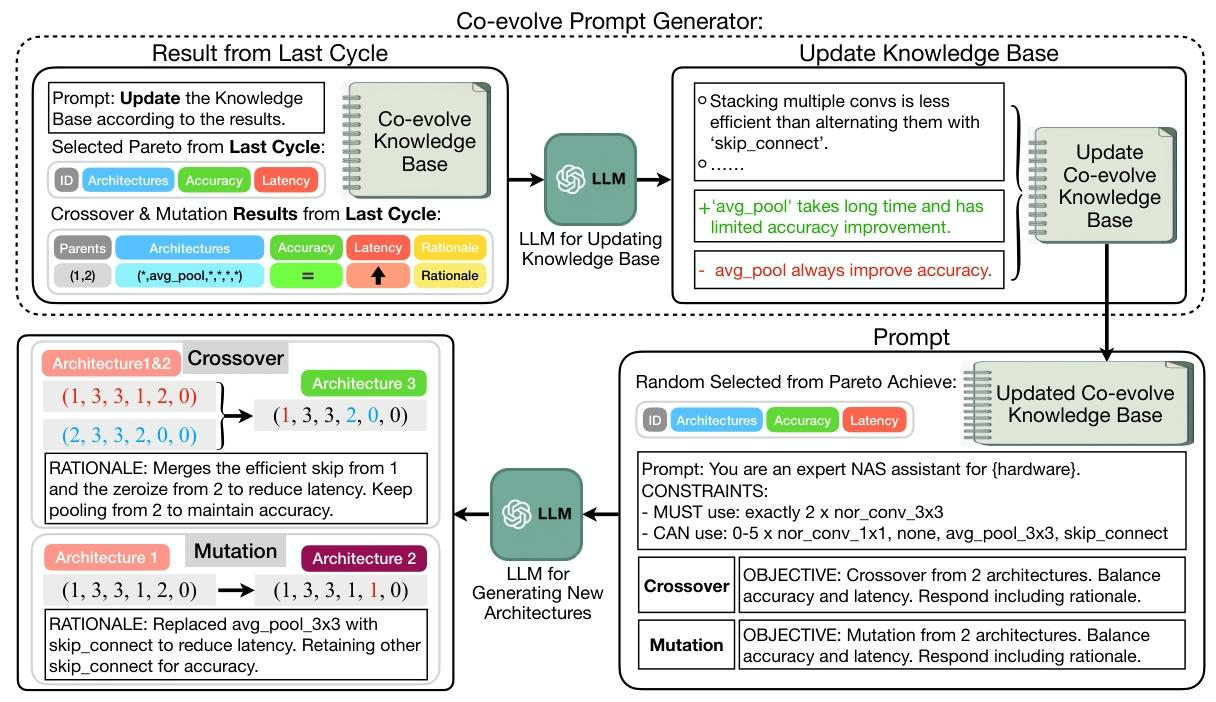
阶段1:知识库更新
LLM当“分析师”,复盘上一轮精度、延迟、结构,更新设计启发式知识库。
例如:
- “avg_pool3x3延迟高、精度提升小”
- “skip_connect能有效降延迟”
阶段2:理性化生成
LLM当“架构师”,用更新后的知识库做:
- Crossover(交叉):融合两个父结构;
- Mutation(变异):局部修改(如avg_pool→skip)。
关键:提示词和架构一起进化,LLM从“瞎猜机”变成“有记忆专家”。
图9:LLM原生模式崩溃现象
- 无分区时,LLM生成结构高度聚集;
- 帕累托前沿残缺、稀疏;
- 即便提示“追求多样性”也没用。
结论:必须用结构性分区,单纯提示工程无效。
3.3 零成本评估(速度的关键)
- 延迟:直接查表HW-NAS-Bench;
- 精度:13个零成本代理集成XGBoost,相关系数≈0.9;
- 完全免训练 → 搜索从几天变几分钟。
3.4 实验算法解析
核心符号/术语
| 符号/函数 | 通俗解释(NAS场景) |
|---|---|
| 输入 | |
| GGG | 进化迭代的总轮数(比如设为50/100轮) |
| LLL | LLM大模型引擎(如GPT/LLaMA等) |
| {S0,...,S5}\{S_0,...,S_5\}{S0,...,S5} | 6个复杂度子空间(按3×3卷积数量划分,核心防崩溃设计) |
| 输出 | |
| PfinalP_{final}Pfinal | 最终的全局帕累托前沿(所有「又准又快」的最优架构集合) |
| 其他关键项 | |
| MpredM_{pred}Mpred | 零成本(ZC)集成预测器:用13个免训练指标+XGBoost预测精度 |
| zpredz_{pred}zpred | MpredM_{pred}Mpred预测的架构精度(%) |
| lll | 架构的真实硬件延迟(ms),直接查表HW-NAS-Bench得到 |
| PkP_kPk | 第kkk个分区的帕累托归档库(只存该分区的最优架构) |
| HardwareLookup(A)\text{HardwareLookup}(A)HardwareLookup(A) | 延迟查表函数:输入架构AAA,输出对应硬件的延迟 |
| Non-Dominated-Sort()\text{Non-Dominated-Sort}()Non-Dominated-Sort() | 非支配排序:筛选出「没有更优解能支配它」的帕累托解 |
完整伪代码逐行解读(按阶段拆分)
第一步:输入输出定义(1-2行)
1: Input: Number of generations G, LLM engine L, niche definitions {S0, . . . , S5}
2: Output: Final Pareto front Pfinal
- 第1行(输入):算法需要3个核心输入:
- GGG:进化迭代次数(控制搜索轮数,越多越优但耗时稍长);
- LLL:LLM引擎(负责生成/优化网络架构);
- {S0,...,S5}\{S_0,...,S_5\}{S0,...,S5}:6个分区的定义规则(比如S1S_1S1=「3×3卷积数=0」)。
- 第2行(输出):最终返回全局最优的帕累托前沿PfinalP_{final}Pfinal(所有精度-延迟权衡最优的架构)。
阶段1:初始化(3-12行)—— 给每个分区搭好「初始最优库」
3: # Phase 1: Initialization
4: Train ZC ensemble predictor Mpred on a sample of architectures // Offline, one-time step
5: for k ∈{0, 1, . . . , 5} do
6: Initialize Pareto archive Pk ←∅
7: Sample an initial population Popinit ⊂Sk
8: for each architecture A ∈Popinit do
9: (zpred, l) ←(Mpred(A), HardwareLookup(A))
10: Update Pk with (A, zpred, l) // Add if not dominated
11: end for
12: end for
逐行拆解:
- 第4行:离线训练零成本集成预测器MpredM_{pred}Mpred(仅需执行1次)。
→ 核心价值:不用训练网络,直接通过初始化指标预测精度,让搜索从「天级」变「分钟级」。 - 第5行:遍历6个分区(S0S_0S0到S5S_5S5),每个分区独立初始化。
→ 核心价值:保证6个复杂度区间都有起点,避免「一上来就扎堆」。 - 第6行:初始化第kkk个分区的帕累托归档库PkP_kPk为空(后续存该分区最优架构)。
- 第7行:从第kkk个分区随机采样一批初始架构PopinitPop_{init}Popinit。
→ 核心价值:每个分区的初始架构都符合该分区的复杂度约束(比如S2S_2S2只能有1个3×3卷积)。 - 第8-9行:遍历每个初始架构AAA,用MpredM_{pred}Mpred预测精度、查表得延迟。
- 第10行:把(A,zpred,l)(A, z_{pred}, l)(A,zpred,l)加入PkP_kPk(仅保留「非支配解」—— 即没有更优架构能同时比它准、比它快)。
- 第11-12行:结束内层/外层循环,完成6个分区的初始化。
阶段1核心目标:
为每个分区建立「初始优质架构库」,保证后续进化有「好起点」,且6个分区全覆盖。
阶段2:分区协同进化(13-27行)—— 让每个分区「独立进化+智能优化」
13: # Phase 2: Partitioned Co-evolution
14: for generation g = 1, . . . , G do
15: # Parallel evolution across all niches
16: for k ∈{0, 1, . . . , 5} do
17: Select parent(s) Aparent from Pk
18: Construct Prompt using Aparent, their scores, and the constraint for niche Sk
19: Generate a new child architecture Achild ←L(Prompt)
20: if Achild is valid, is novel, and satisfies constraint of Sk then
21: (zpred, l) ←(Mpred(Achild), HardwareLookup(Achild))
22: Let Anew ←(Achild, zpred, l)
23: // Update archive by adding the new solution and removing any it dominates
24: Pk ←{A′ ∈Pk | Anew does not dominate A′} ∪{Anew}
25: end if
26: end for
27: end for
逐行拆解:
- 第14行:迭代GGG轮进化(每轮都让架构更优)。
- 第16行:6个分区并行进化(核心!避免某分区挤占资源)。
- 第17行:从PkP_kPk选「父代架构」AparentA_{parent}Aparent(选该分区当前最优的架构)。
→ 核心价值:子代架构的起点是「该分区最优」,进化效率更高。 - 第18行:构建LLM提示词——包含「父代架构+精度/延迟分数+分区SkS_kSk的约束」。
→ 核心价值:提示词绑定分区规则(比如S1S_1S1不能有3×3卷积),LLM不会瞎生成,实现「提示-架构协同进化」。 - 第19行:LLM根据提示词生成「子代架构」AchildA_{child}Achild。
→ 核心价值:LLM利用历史经验+分区约束,生成的架构天然符合复杂度要求。 - 第20行:校验子代架构:
- valid:架构编码合法(比如操作符是0~4);
- novel:未生成过(避免重复);
- satisfies constraint:符合SkS_kSk的复杂度约束(比如S2S_2S2必须有1个3×3卷积)。
- 第21-22行:预测子代精度、查表得延迟,封装为AnewA_{new}Anew。
- 第24行:更新PkP_kPk:
- 移除被AnewA_{new}Anew支配的旧架构(比如AnewA_{new}Anew又准又快,旧架构就没用了);
- 加入AnewA_{new}Anew;
→ 核心价值:PkP_kPk永远只存该分区的最优解,无冗余。
- 第25-27行:结束条件判断/循环,完成GGG轮进化。
阶段2核心目标:
通过「分区并行+LLM智能生成+硬约束校验」,让每个分区都能独立优化,既保证多样性,又根治模式崩溃。
阶段3:最终聚合(28-31行)—— 合并所有分区的最优解
28: # Phase 3: Final Aggregation
29: Punion ←∪₅ₖ=₀ Pk
30: Pfinal ←Non-Dominated-Sort(Punion)
31: return Pfinal
逐行拆解:
- 第29行:合并6个分区的帕累托归档库PkP_kPk,得到「全空间候选最优解」。
- 第30行:对合并后的所有架构做「非支配排序」—— 筛选出全局最优的帕累托解(比如S3S_3S3的解可能支配S4S_4S4的解,需重新筛选)。
- 第31行:返回最终的全局帕累托前沿PfinalP_{final}Pfinal。
阶段3核心目标:
从「分区最优」升级为「全局最优」,得到覆盖全延迟区间的最终最优架构集合。
伪代码核心亮点
- 分区并行进化:6个分区独立迭代,从代码层面强制全空间覆盖,彻底解决LLM-NAS的模式崩溃;
- 零成本评估:全程无训练、无超网,仅用预测器+查表,搜索效率拉满(3分钟完成);
- LLM提示硬约束:提示词绑定分区规则,生成的架构天然符合复杂度要求,无需事后过滤;
- 动态更新归档库:每个分区只保留非支配解,进化效率高、无冗余;
- 全局聚合筛选:合并后重新排序,保证最终前沿是「全局最优」而非「分区最优」。
四、实验结果 + 图表解读
表2:最优架构精度-延迟对比
PEL-NAS找到:
- Edge GPU:1.78ms
- FPGA:1.65ms
比最强基线快 22%~54%。
表3:HV & IGD 全面领先
- HV越高:帕累托覆盖越全;
- IGD越低:越接近真实最优前沿;
PEL-NAS在6硬件×3数据集全部SOTA。
表4:搜索成本炸裂对比
| 方法 | 搜索成本 |
|---|---|
| LLMatic | 17 GPU天 |
| FairNAS | 10 GPU天 |
| DARTS | 4 GPU天 |
| PEL-NAS | 3分钟 |
表5:消融实验(证明每个组件都必不可少)
- 无分区:直接崩盘,HV暴跌、IGD暴增;
- 无LLM算子:性能明显下降;
- 无零成本集成:预测不准,搜索退化。
图5:ViT搜索空间泛化性
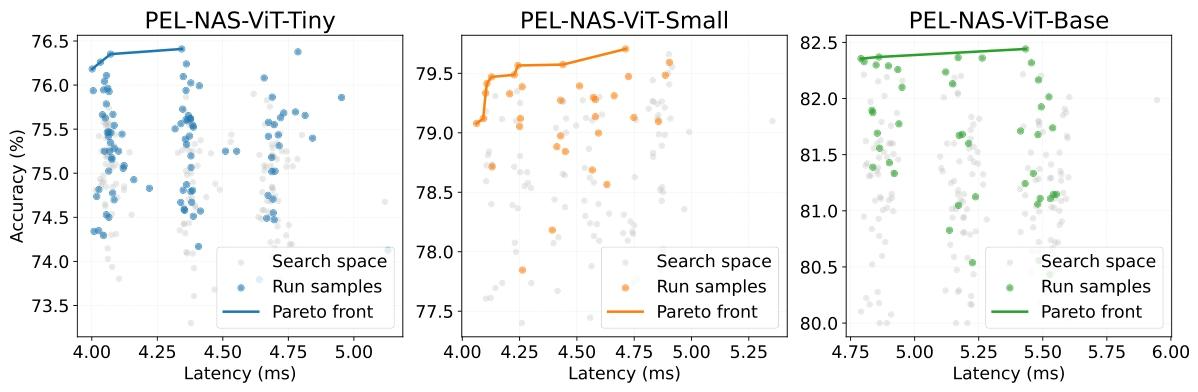
将分区迁移到Transformer:
- 复杂度核心:Embed Dim(O(D²))、Depth Num(O(L));
- 依然实现最优精度-延迟权衡;
- 延迟最低 4.0ms。
五、结论
PEL-NAS的核心贡献:
- 复杂度分区从结构上根除LLM模式崩溃;
- 提示-架构协同进化让LLM具备记忆与推理;
- 零成本评估实现分钟级搜索;
- 同时支持CNN与ViT,工业落地性极强。
六、标签
ICLR2026 NAS HW-NAS LLM 神经架构搜索 端侧部署 零成本NAS

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)