Open-World Deepfake Attribution via Confidence-Aware Asymmetric Learning
这里的 “原型(Prototype)” 既不是模型,也不是单纯的脸型,而是 **“某一类样本的特征中心”**
以深度伪造归因任务为例:
- 假如有 100 张 “Facedancer 算法生成的伪造人脸”,这些人脸的特征(比如纹理、边缘、频率域模式)会呈现相似性,模型会把这些相似特征聚合成一个 “Facedancer 原型”;
- 同理,“基于扩散模型生成的伪造人脸” 也会形成对应的 “扩散伪造原型”
目录
一、ACR 的核心目标:让模型对 “已知类型” 和 “未知类型” 都能输出高置信度预测
二、ACR 的实现手段:“非对称筛选 + 针对性强化” 高置信度样本
三、ACR 和 CCR 的互补效果:形成 “样本质量→置信度→样本质量” 的正循环
DPP 是动态原型剪枝(Dynamic Prototype Pruning)
2. 动态原型剪枝的 “剪枝”,剪的是 “冗余的新类型原型”
摘要
该摘要围绕开放世界 DeepFake 归因(OW-DFA)展开,针对现有方法的两大缺陷(置信度偏差导致伪标签不可靠、预设未知伪造类型数量),提出了置信度感知非对称学习(CAL)框架与动态原型剪枝(DPP)策略,并通过实验验证其性能优于现有方法。
关键模块解析
CAL 框架
- 包含置信度感知一致性正则化(CCR):基于归一化置信度动态调整样本损失,将训练焦点从高置信度样本向低置信度样本转移,缓解伪标签偏差。
- 包含非对称置信度增强(ACR):通过高置信度样本的选择性学习,分别校准已知类与新类的置信度,利用置信度差距优化模型。
- CCR 与 ACR 形成互增强循环,提升 OW-DFA 性能。
DPP 策略
- 以 “粗到细” 的方式自动估计新伪造类型的数量,消除对未知类型数量的预设,增强方法在真实开放世界场景中的可扩展性。
研究价值
该方法在标准 OW-DFA 基准与包含高级篡改操作的扩展基准上均实现了已知 / 新伪造类型归因的 SOTA 性能,解决了开放世界 DeepFake 检测中 “未知类型数量不可知”“置信度偏差” 等实际问题。
OW-DFA(不足)
现有开放世界深度伪造归因(OW-DFA)方法存在两个关键局限:
1)置信度偏差—— 导致新伪造类型的伪标签不可靠,进而造成训练偏差;
2)不现实假设—— 预先已知未知伪造类型的数量。为解决这些挑战,我们提出了置信度感知非对称学习(CAL)框架。
引入-性能差异源于置信度偏斜 (给予没见过的新标签赋予较低的值,导致伪标签不可靠
这些不准确的标签会误导训练目标,通过负反馈循环强化偏差,开始进一步偏斜) ->
新颖的置信度CPL
CPL(总称)
置信度感知一致性正则化CCR
“降低低置信度样本权重” 是为了规避 “噪声标签污染模型”,而非因为低置信度样本数量多 —— 即使已知类型的低置信度样本数量少,只要伪标签不可靠,就需要暂时降低其影响。
学 “已知类型低置信度样本”:解决 “已知类型难例的鲁棒识别” 问题。
训练初期:
- 优先用 DL 有标签样本(已知类型,标签可靠)快速建立 “已知类型的特征模板”;
- 对 DU 无标签样本,仅用 高置信度样本(伪标签相对可靠,多为特征清晰的已知类型样本)补充训练,降低低置信度样本(伪标签噪声大,含未知类型 + 已知类型噪声样本)的干扰,避免模型被带偏。
训练后期:
- 模型已学好已知类型的特征,对 DU 中已知类型的预测置信度稳定,低置信度样本基本只剩 “未知类型”;
- 通过 CCR 的动态权重(Ee 增大),逐步将学习焦点转移到低置信度的未知类型样本上,同时也会学好 DU 中剩余的已知类型低置信度样本(此时伪标签已可靠)。
- 训练后期,模型已能正确识别 “模糊 Facedancer 样本”(伪标签可靠),此时DU 里的低置信度样本,基本是 “从未见过的新伪造类型”(比如 Blendface)—— 它们的低置信度,是因为模型没学过这类伪造模式,而非伪标签不可靠。
非对称置信度强化ACR
一、ACR 的核心目标:让模型对 “已知类型” 和 “未知类型” 都能输出高置信度预测
开放世界任务中,模型天然会对 “已知类型”(学过的)预测置信度高,对 “未知类型”(没学过的)置信度低 —— 这种 “置信度失衡” 会导致:
- 已知类型:置信度过高→可能把 “类似已知类型的未知样本” 误判为已知类型;
- 未知类型:置信度过低→伪标签不可靠,无法有效学习。
ACR 的目标就是打破这种失衡,让模型对两类样本都能给出 “既准确又自信” 的预测。
二、ACR 的实现手段:“非对称筛选 + 针对性强化” 高置信度样本
ACR 的核心是 “不搞‘一刀切’的置信度筛选”,而是给已知类型和未知类型 “定制不同的高置信度样本筛选规则”,具体分两步:
- 计算 “置信度差距系数”:先统计模型当前对 “已知类型” 和 “未知类型” 的平均置信度(比如已知类型平均置信度 0.9,未知类型 0.5,差距是 0.4),基于这个差距设计一个 “个性化系数”。
- 按类别筛选高置信度样本:
- 对已知类型:用 “较高的置信度阈值” 筛选样本(比如只选置信度 > 0.85 的)—— 因为已知类型本身置信度高,要选 “最可靠的样本” 强化;
- 对未知类型:用 “较低的置信度阈值” 筛选样本(比如选置信度 > 0.6 的)—— 因为未知类型本身置信度低,不能用已知类型的高阈值 “卡掉所有样本”。
- 强化这些筛选出的高置信度样本:让模型重点学习这些样本,强制模型对它们输出更稳定的高置信度预测。
三、ACR 和 CCR 的互补效果:形成 “样本质量→置信度→样本质量” 的正循环
ACR 不是孤立的,它是 CCR 的 “辅助器”:
- CCR 的作用是 “动态调整样本权重,让模型学更多难样本”;
- ACR 的作用是 “筛选出两类样本中最可靠的高置信度样本,提升这些样本的置信度稳定性”;→ 最终,ACR 筛选的 “高质量高置信样本” 能让 CCR 的正则化更有效,而 CCR 优化后的模型又能让 ACR 筛选出更多可靠样本 —— 二者互相促进,最终缩小已知 / 未知类型的置信度差距。
一句话总结 ACR
ACR 是 “给已知和未知类型‘量身定制’高置信度样本的筛选规则,让模型对两类样本都能自信地预测,同时帮 CCR 把正则化做得更好”。
这个图表示一个置信度失衡的情况 (左边是占比的意思)
Protocol-1 下的对比(左图)
- CPL(上图):已知类型样本集中在高置信区间(0.9-1.0 占比近 0.4),而新类型样本分散在中低置信区间(0.5-0.9 均有分布),二者置信度分布差异极大。
- CAL(下图):已知类型样本仍集中在高置信区间(0.9-1.0 占比接近 1.0),但新类型样本的置信度大幅向高区间聚拢(0.9-1.0 占比显著提升),已知与新类型的置信度分布更接近。
3. Protocol-2 下的对比(右图)
- CPL(上图):已知类型样本高度集中在 0.9-1.0 区间,新类型样本则分散在 0.4-0.8 区间,置信度差距明显。
- CAL(下图):新类型样本的置信度向高区间(0.9-1.0)集中的趋势更显著,已知与新类型的置信度分布重叠度大幅提升。
结论:CAL 有效缓解了置信度失衡
DPP 是动态原型剪枝(Dynamic Prototype Pruning)
DPP 可以在训练过程中自动、动态地确定新伪造类型的数量。
1. 先明确:这里的 “原型” 是什么?
在开放世界归因任务中,模型会为每个 “类别” 学习一个 **“原型”(Prototype)**—— 可以理解为 “某类样本的特征中心”(比如所有 Facedancer 伪造样本的特征会聚类成一个 “Facedancer 原型”)。
- 已知类型的原型:由有标签数据训练得到,数量固定(等于已知类型数);
- 新类型的原型:由无标签数据聚类得到,初期会生成大量 “临时原型”(因为模型会把相似但略有差异的新样本聚成不同原型)。
2. 动态原型剪枝的 “剪枝”,剪的是 “冗余的新类型原型”
算法剪枝是 “剪模型的参数 / 结构”,而 DPP 的 “剪枝” 是 **“剪去新类型的冗余原型”**,流程是 “先多生成、后精简”:
- 步骤 1:生成初始原型训练初期,模型会对无标签数据做聚类,生成大量 “临时原型”(包括重复、相似的原型)—— 比如把同一类新伪造样本,因特征略有差异聚成了 3 个原型。
- 步骤 2:粗到细剪枝模型会动态评估这些原型的 “使用率” 和 “相似度”:
- 低使用率原型:几乎没有样本匹配的原型(可能是噪声聚类的结果);
- 冗余原型:特征高度相似的原型(本质属于同一类新伪造类型);然后将这些原型合并 / 删除,最终剩下的原型数量,就是 “自动估计出的新伪造类型数量”。
3. “动态” 体现在哪里?
剪枝过程不是 “一次性完成”,而是随训练过程持续调整:
- 训练初期:原型数量多(覆盖所有可能的新样本聚类);
- 训练中期:随模型对新类型特征的理解加深,逐步合并相似原型;
- 训练后期:原型数量稳定,对应最终估计的新类型数量。
总结:DPP 和算法剪枝的区别
对比维度 算法剪枝 动态原型剪枝(DPP) 剪的对象 模型的参数 / 网络结构 新类型的 “特征中心(原型)” 目的 压缩模型体积、提升推理速度 自动估计新类型数量、精简类别中心 适用场景 所有模型优化场景 开放世界任务(新类别数量未知) 简单说:DPP 的 “剪枝” 是给 “新类型的特征聚类结果” 做 “去重精简”,最终得到准确的新类型数量,和算法剪枝(优化模型本身)是完全不同的技术方向。
CAL流程图
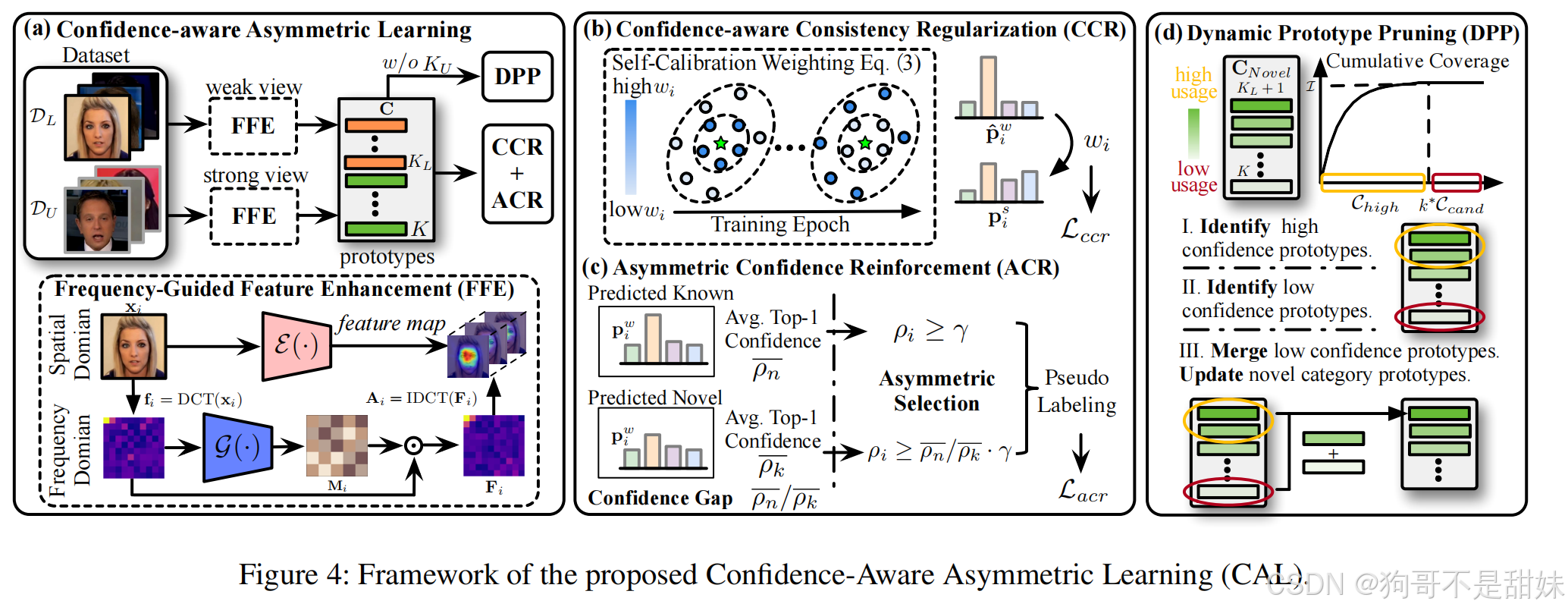
1. (a) 整体框架:置信度感知非对称学习
- 输入:
- D(L):有标签的已知伪造类型数据;
- D(U):无标签的已知 + 新伪造类型混合数据。
- 特征增强(FFE):通过 “空间 - 频率域双分支”(DCT/IDCT 变换)增强伪造特征的区分度 —— 先将图像转换到频率域,突出伪造痕迹的高频特征,再融合回空间域,提升特征表征能力。
- 原型生成:模型为已知类型(橙色,KL个)和新类型(绿色,K个)生成特征原型,后续通过 DPP、CCR、ACR 优化。
weak view(弱增强视图):对样本施加轻微的数据增强(比如小幅裁剪、亮度微调),保留样本的核心特征(伪造痕迹、类别信息),用于生成 “相对稳定的基准特征”。
strong view(强增强视图):对样本施加较强的数据增强(比如随机翻转、大尺度裁剪、噪声添加),样本的表面特征会发生较大变化,但核心伪造特征仍存在,用于测试模型对 “干扰样本” 的特征鲁棒性。
2. (b) CCR:置信度感知一致性正则化
- 核心逻辑:通过 “自校准权重” 动态调整样本损失 —— 训练初期降低低置信度样本权重(避免噪声),训练后期提升低置信度样本权重(聚焦新类型)。
- 实现方式:基于样本的预测置信度计算权重wi,并通过 “弱视图 - 强视图” 的特征一致性损失Lccr,让模型对同一样本的不同增强视图输出一致的预测。
- 上排(弱增强):有一根 明显最高 的柱(不管它是浅蓝、浅紫还是浅黄)→ 说明:弱增强视图的预测,绝大多数都集中在这一个置信度区间里 → 预测结果 稳定、可靠。
- 下排(强增强):所有柱的高度 都差不多,没有特别突出的 → 说明:强增强视图的预测,分散在好几个置信度区间里 → 预测结果 波动大、不稳定。
3. (c) ACR:非对称置信度增强
- 核心逻辑:为已知 / 新类型设置不同的置信度筛选阈值(利用 “已知 - 新类型置信度差距” 调整),筛选高置信度样本生成伪标签。
- 实现方式:
- 已知类型:筛选条件为 “样本置信度ρi≥γ”(γ是基础阈值)—— 用较高的阈值筛选高置信样本。
- 新类型:筛选条件为 “样本置信度ρi≥ρn/ρk⋅γ”—— 通过 “置信度差距” 缩小基础阈值,避免因新类型本身置信度低而被全部过滤。
ACR 根据 “已知 - 新类型的置信度差距(ρn/ρk)”,为两类样本设置不同的筛选条件
4. (d) DPP:动态原型剪枝
- 核心逻辑:通过 “使用率评估 + 原型合并” 自动估计新类型数量。
- 三步剪枝流程:
- 步骤 I:识别高置信度原型筛选 “使用率高、置信度高” 的原型(黄色框选部分),保留为有效新类型原型。
- 步骤 II:识别低置信度原型筛选 “使用率低、置信度低” 的原型(红色框选部分),这类原型多为冗余 / 噪声聚类结果。
- 步骤 III:合并低置信度原型将低置信度原型合并(或删除),并更新新类型原型集合,最终得到准确的新类型数量。
- CNovel:新类型原型集合(包含已知类型原型KL外的新原型);
- Usage(使用率):原型对应的样本数量(绿色越深代表使用率越高,红色代表使用率越低);
- Cumulative Coverage(累计覆盖):原型覆盖样本的比例(曲线趋于平稳时,代表原型已覆盖绝大多数样本)。
频率引导特征增强(FFE)
这是 CAL 框架中的特征预处理模块,核心是通过 “空间域 + 频率域” 双分支融合,增强深度伪造图像的特征区分度(伪造痕迹通常在频率域更明显),具体流程分 3 步:
1. 双域分支输入
- 空间域分支:输入原始图像xi,通过编码器E(⋅)提取空间域特征图(保留图像的直观纹理信息)。
- 频率域分支:将原始图像xi通过离散余弦变换(DCT)转换为频率域特征fi(伪造操作会在频率域引入异常高频 / 低频成分)。
2. 频率域特征增强
频率域特征fi输入解码器G(⋅),生成掩码Mi—— 该掩码会突出频率域中 “伪造相关的异常特征”(比如换脸操作导致的频率分布不一致区域)。
3. 双域特征融合
将掩码Mi与原始频率域特征fi融合,得到增强后的频率域特征Fi;再通过逆离散余弦变换(IDCT)将Fi转换回空间域特征Ai,最终与空间域分支的特征图结合,输出 “伪造痕迹更突出” 的增强特征。
核心作用
深度伪造的痕迹(如边缘不自然、纹理拼接瑕疵)在空间域可能不明显,但在频率域会呈现独特的异常模式。FFE 通过双域融合,放大伪造相关的特征差异,帮助后续模块(CCR、ACR)更精准地识别已知 / 新伪造类型。
具体方法
FFE 模块的工作流程,核心是通过 “空间 - 频率域转换 + 注意力掩码” 增强深度伪造特征的区分度,具体分为 5 个步骤:
1. 频率域转换
对输入人脸图像xi做离散余弦变换(DCT),得到频率域表示fi=DCT(xi)—— 深度伪造的痕迹(如纹理拼接、边缘异常)在频率域会呈现独特的模式。
2. 生成频率域注意力掩码
用随机初始化的卷积网络G(⋅)对fi处理,生成掩码Mi=G(fi)—— 该掩码会突出频率域中 “能区分不同伪造方法的关键模式”。
3. 加权频率特征
通过逐元素乘法,将掩码Mi与频率特征fi融合,得到加权频率表示Fi=Mi⊙fi—— 强化伪造相关的频率特征,弱化无关噪声。
4. 转换回空间域
用逆离散余弦变换(IDCT)将Fi转换为空间域的注意力图Ai=IDCT(Fi)—— 该图能定位到空间中 “伪造痕迹对应的频率响应区域”。
5. 融合空间特征
将Ai与原始图像的空间特征E(xi)逐元素相乘,再通过 1×1 池化得到最终的频率感知特征hi—— 该特征同时包含 “空间纹理” 和 “频率域伪造模式”,提升后续归因任务的准确性。
核心作用
FFE 的本质是利用频率域的独特信息,放大不同深度伪造方法的特征差异,解决 “空间域中伪造痕迹不明显” 的问题,为后续的 CCR、ACR 模块提供更具区分度的输入特征。
Fi=Mi⊙fi 这个是哈达玛积
这里的⊙符号表示的就是哈达玛积(Hadamard Product),也就是两个同维度矩阵 / 向量的逐元素乘法—— 对应到公式Fi=Mi⊙fi,就是把注意力掩码Mi和频率域特征fi的每个对应位置元素相乘,以此实现 “对频率特征的加权增强”。
置信度感知非对称学习(CCR),鉴于无标签数据缺乏真实标签,采用基于一致性正则化的训练策略,鼓励对同一图像的扰动版本做出相似预测
CCR:实现方法

将原型相似性转换为概率分布,并通过弱 / 强增强视图定义一致性损失,具体分为 3 个部分:
1. 预测概率的计算
- 首先将图像与所有原型的相似性组成向量si=[si→1,...,si→K];
- 用 softmax 函数σ将相似性向量转换为概率分布pi=σ(si)—— 该概率代表图像属于对应伪造类型的置信度。
2. 图像的增强视图
3. 一致性正则化损失
参考 FixMatch 方法,损失定义为:
其中:
- ∣B∣是批次大小;
- 1(⋅)是指示函数:仅当弱增强视图的预测最大概率max(p^iw)大于阈值δ时,才计算该样本的损失(保证用高置信的弱增强预测来约束强增强预测);
- ℓ(⋅)是损失函数(通常为交叉熵),用于衡量弱增强预测p^iw与强增强预测pis的差异。
- 问题 1:已知类别偏见新类别缺乏真实标签,模型的预测会偏向已知类别;而一致性正则化会进一步强化这种偏见(让模型对新类别的预测更倾向于已知类)。
- 问题 2:阈值超参敏感损失Lws中基于阈值δ的筛选,对超参数δ的选择非常敏感;训练过程中预测置信度会变化,但固定的δ无法灵活适配,影响模型稳定性。

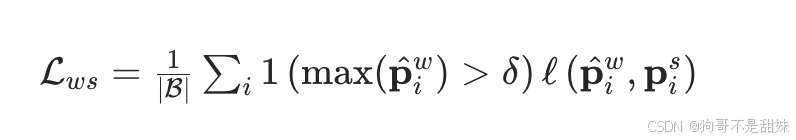
解决问题
针对 CCR 的两个局限性,该策略通过动态调整样本权重实现:
- 初期:侧重高置信样本(多属于已知伪造类型),学习可靠的归因特征;
- 后期:逐渐转向低置信样本(多对应新类别),增强对新伪造类型的学习。
p是置信度,例如
- 训练初期:模型对 “新类别样本” 不熟悉,预测时会偏向已知类,此时该样本的置信度ρ^i可能较高(但实际是错误的已知类预测);
- 训练后期:模型逐渐学习到新类别的特征,对该样本的预测会更接近真实类别,此时其置信度ρ^i可能降低(因为模型不再强行将它归为已知类)。

ACR:实现方法


DDP
原型使用次数uj(t):量化每个原型的被使用频率,作为剪枝的依据(使用次数低的原型会被判定为冗余)。


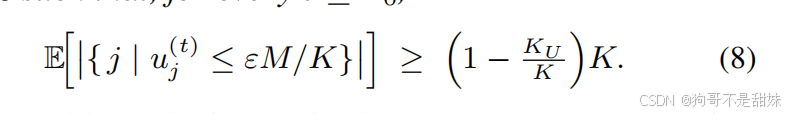
引理 4.1 是给 DPP 模块(动态原型剪枝)提供 “理论定心丸” —— 证明了 “预留足够多原型时,训练前期会自动出现大量冗余原型,这些冗余原型可以安全剪枝”,从而支撑 “自动估计未知类别数量” 的核心目标。
在训练前 50 轮(t≤T0),会出现这样的情况:
- 10 个 “真实住户”(未知伪造类型)会各自占据 1 个房间,这些房间的 “使用次数” 很高(比如每个房间被 80-100 张图片选中);
- 剩下的 90 个房间((1−10/100)×100=90)几乎没人住,使用次数极低(比如每个房间被≤1 张图片选中,满足 uj(t)≤0.1×10/1000/100=1);
- 这些低使用次数的房间,就是 “冗余原型”—— 证明了可以放心剪枝。
“≥” 就是说:实际出现的冗余房间数量,至少有 90 个,不会比 90 个少。
0.1*1000/100,意思就是比1小的集合大于等于理论的原型个数
| 符号 / 表达式 | 通俗含义 |
|---|---|
| K | 你预留的 “原型预算”(比如:提前准备 100 个 “空房间”) |
| KU | 真实的未知伪造类型数量(比如:实际只有 10 种未知伪造方法,对应 10 个 “真实住户”) |
| M | 训练的无标签样本总数(比如:有 1000 张未知伪造图片) |
| uj(t) | 第t轮训练时,第j个原型的 “使用次数”(比如:第 3 号房间被 10 张图片选中) |
| ε | 极小的正数(比如 0.1,用来定义 “低使用频率”) |
| T0 | 迭代次数上限(比如前 50 轮训练) |
| 公式 (8) | 平均来看,至少有 (1−KKU)K 个原型是 “低使用频率的冗余原型” |
二、用 “分配房间” 类比理解核心逻辑
场景设定:
- 你要给 10 种未知伪造方法(KU=10,10 个 “真实住户”)分配 “房间”(原型);
- 你不知道有多少住户,所以预留了 100 个房间(K=100,原型预算);
- 有 1000 张未知伪造图片(M=1000),每张图片要 “住进” 最匹配的房间(原型)。
引理 4.1 的结论:
在训练前 50 轮(t≤T0),会出现这样的情况:
- 10 个 “真实住户”(未知伪造类型)会各自占据 1 个房间,这些房间的 “使用次数” 很高(比如每个房间被 80-100 张图片选中);
- 剩下的 90 个房间((1−10010)×100=90)几乎没人住,使用次数极低(比如每个房间被≤1 张图片选中,满足 uj(t)≤0.1×1000/100=1);
- 这些低使用次数的房间,就是 “冗余原型”—— 证明了可以放心剪枝。
三、为什么这个引理很重要?
- 打破 “未知类别数量依赖”:之前的方法需要手动设定未知类别数,而引理 4.1 证明:只要预留足够多的原型(K≫KU),冗余原型会自动出现,剪枝后就能得到真实的未知类别数;
- 给 DPP 模块找理论依据:DPP 模块的核心是 “剪枝低使用原型”,这个引理从数学上证明了 “低使用原型就是冗余的”,不是随机剪枝,而是有理论支撑的;
- 保证剪枝安全性:引理 4.1 的前提(步长有界、噪声有界等)都是训练中容易满足的条件,说明这个结论在实际训练中是可靠的,不会剪枝掉有用的原型。
注意:这里面的降序,是有点东西的

累积覆盖率rk:衡量前k个原型的使用次数占所有未知原型总使用次数的比例,用于量化原型的 “覆盖能力”;
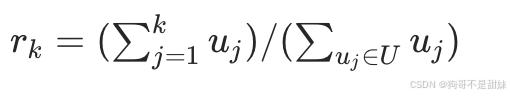



知识蒸馏的困惑
读到这里其实,我有一个困惑,我阅读完数据蒸馏后,教师模型和学生模型,这个不是大模型训练小模型的,给他知识蒸馏吗,为什么这里也用教师模型和学生模型呢
传统知识蒸馏的目的
- 模型压缩 :用大模型(教师)的知识训练小模型(学生)
- 性能提升 :让学生模型学习教师模型的软标签,获得更好的泛化能力
- 架构差异 :教师和学生通常是不同的模型架构
本文的应用目的
- 一致性约束 :让模型对同一张图片的不同增强版本输出一致的预测
- 半监督学习 :利用无标签数据,通过一致性约束提高模型性能
- 自训练 :模型自己生成伪标签,然后用这些伪标签监督自己
为什么使用教师-学生思想?
1. 一致性正则化的需要
在半监督学习中,核心假设是: 模型对输入的微小变化应该保持预测的一致性 。同一张图片
├── 弱增强(轻微变化)→ 教师 → 预测A
└── 强增强(较大变化)→ 学生 → 预测B
目标:让预测A和预测B尽可能一致# 教师(弱增强):低温度 → 硬分布
probs_teacher = F.softmax(logits_weak / teacher_temp, dim=-1) # teacher_temp较小# 学生(强增强):高温度 → 软分布
probs_student = F.softmax(logits_strong / student_temp, dim=-1) # student_temp较大- 低温度 :概率分布更尖锐,接近one-hot,信息熵低
- 高温度 :概率分布更平滑,保留更多类别关系信息
| 特性 | 传统知识蒸馏 | 本文的一致性正则化 |
|---|---|---|
| 模型数量 | 2 个(教师 + 学生) | 1 个(同一模型) |
| 参数共享 | 不共享 | 完全共享 |
| 训练目标 | 学生模仿教师 | 强增强模仿弱增强 |
| 应用场景 | 模型压缩 | 半监督学习 |
| 标签来源 | 教师模型预测 | 弱增强视图预测 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)