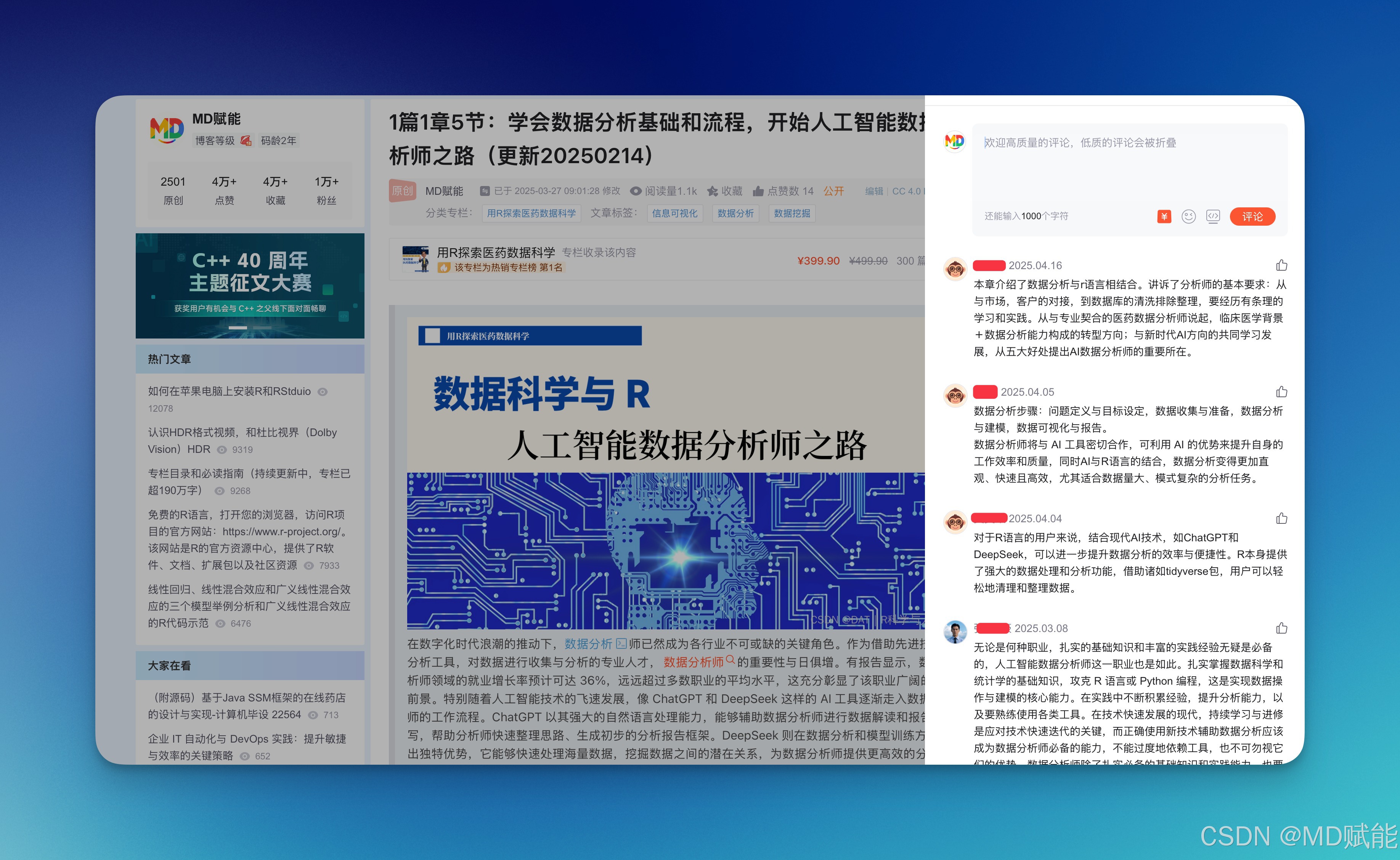
2026年,学R语言,为什么399元的专栏真的很值,你只需要这一份资料,其它图文资料不再需要买了!我们现在是全网最丰富的R语言工具库了!


当前医药数据科学和R语言领域,网络上和书籍市面上一大堆资料,表面看起来琳琅满目,价格从几十元的书籍到动辄几千元一次的线下培训班都有。但绝大多数培训或书籍都受限于时间和篇幅,浅尝辄止,很多仅仅是基础入门,内容高度同质化、重复严重,无法真正结合医药数据场景深入讲解,更无法系统串联起实际科研工作的核心思路和应用流程。而本专栏不仅覆盖医药数据科学全流程,从工具基础到临床实践到机器学习、人工智能,再到医药数据库实战与高阶统计分析,逻辑链条清晰,真正做到“系统、实战、持续更新”,绝不是泛泛的“资料汇编”。
目前专栏已超190万字,包含超过300篇文章,每篇都达5000–9000字,内容覆盖试验统计、预测模型、科研绘图、数据库等热点领域,每周持续更新,追踪最新技术趋势、市面动态。与之相比,市面上医药数据相关书籍通常只有几十万字,视频课程受限于讲解时间,一次课程可能只有几小时,实际获得的干货和实际指导极为有限。
399元的定价,仅相当于一本专业书籍或一次普通技能讲座的价格。而市面线下或机构培训班,往往动辄就需要几千甚至上万元,一次学习仅限于特定时段,内容受限于老师的进度和水平,无法反复查阅。网上付费视频课程大多也在几百元,但内容零散且多为“零基础”,不够系统化。专栏不仅价位亲民,还能反复实操复现,比“毫无体系的碎片收费”更有价值。你以399元买到的不是一次性消耗品,而是一个不断丰富的知识库。
以第九篇的公共数据库挖掘为例,给大家分析!
第九篇“公共数据库挖掘”本身就足以让这个专栏的性价比显得非常夸张:从 NHANES 到 GBD 再到 FAERS/VigiBase,一整套从入门、下载、清洗、权重设计、抽样设计解读到真正能写出论文的分析路径,基本把目前几千元培训班都很难系统讲清楚的内容一次性覆盖了。
NHANES
在 NHANES 部分,先从什么是二次数据分析和 NHANES 设计思想讲起,让读者真正理解这类公共健康调查数据的结构和局限,而不是只会“下个表凑个回归”。紧接着,分多节详细拆解如何下载各年度数据、用 R 读取、追加合并、处理抽样权重与方差估计,并一步步复现美国成人抑郁症患病率研究,最后还带着读者搭建自己的 NHANES 读取函数,解决表不同、字段不一致、样本设计更新等一系列实战难题。
在基础上,又专门有多节写 2017–2023 新一轮 NHANES 的样本设计变更、无应答偏倚评估与分析说明,帮读者避开“沿用旧套路就错”的隐形雷区。同时,还教你如何直接显示变量 codebook、按关键词检索变量并一键拿到对应数据 URL、批量下载数据清单和变量汇总表,等于把一整套 NHANES 数据探索工具链打包交给你,节省大量自己摸索的时间和踩坑成本。
GBD
GBD 部分从“认识 GBD”到数据申请流程、核心指标含义,再到高血压等具体病种的分析策略和 SDI 指数使用,都是围绕“如何从 GBD 做出严谨、站得住脚的科研”来设计的。
后面几节不仅讲全球疾病负担可视化、关键在线工具系统的使用,还拆解 2025 年基于 GBD 的柳叶刀子刊研究,提炼出一套“GBD 六步成文法”,并给出按不同临床科室可落地的数据挖掘方向,这部分在常规培训班中几乎是看不到的深度。
FAERS
在 FAERS 部分,并不是停留在“哪里下数据、打开看看”这种浅层级,而是从 FDA 官方对 FAERS 的定位及投稿限制讲起,帮读者形成对数据库优缺点和适用场景的清晰认识。
随后几节分层解析公共仪表板的检索逻辑、单药报告的核心字段和数据来源,再到官网下载 ASCII 七大模块、用 R 进行结构化提取与合并,最后延伸到与 VigiBase 的联合挖掘思路,实现从监管方公开数据到国际药物警戒数据库的完整视野。
SEER
美国国家癌症研究所(National Cancer Institute, NCI)自 1973 年起建立了“监测、流行病学和最终结局”(Surveillance, Epidemiology, and End Results,简称 SEER)项目,用于系统性收集和报告美国人群的恶性肿瘤发病与生存情况。 SEER 的核心目标是通过高质量、标准化的癌症登记数据,为肿瘤流行病学研究、癌症防控政策制定以及临床实践提供可靠证据。
与传统的单中心病例系列相比,SEER 采用人群为基础(population‑based)的登记方式,覆盖特定地理区域内的全部癌症新发病例,因此其结果具有较好的代表性和外推性。 目前,SEER 数据已经广泛应用于肿瘤负担评估、时间趋势分析、生存率比较、健康服务研究以及指南制定等多个领域,在国际癌症流行病学研究中具有标杆意义。
另外,SEER 数据主要来自美国各州和地区的肿瘤登记处,这些登记处按照统一的技术规范和质量控制要求,持续报告辖区内新诊断的恶性肿瘤病例。 SEER 项目最初仅包括少数州和大城市,但经过多次扩展,目前已纳入若干州级和区域性癌症登记处,如康涅狄格州、夏威夷州、加利福尼亚州部分地区、乔治亚州等,整体覆盖约四分之一到三分之一的美国人口,并在种族与地域上具备较强多样性。 各登记处每年向 SEER 提交经过汇总和质量核查的数据,内容涵盖所有报告范围内的原发恶性肿瘤及部分脑和中枢神经系统肿瘤等。 通过精心选择地区和持续扩展覆盖,SEER 在保证数据质量的前提下,尽可能提高了对美国总体人群结构和肿瘤谱的代表性。
GEO
GEO 由美国国家生物技术信息中心(NCBI)于 2000 年正式创建,最初的目标是为全球基因表达芯片研究提供一个统一的数据存档平台,实现数据的长期保存与开放共享。目前,GEO 已收录来自全球数十万项研究的数据,涵盖数百万个实验样本,涉及上百种疾病模型、组织类型和处理条件。这些数据既包括健康与疾病状态下的基础表达谱,也包含药物干预、基因编辑、免疫刺激等多种实验设计。另外,对于多个数据库联合挖掘,目前确实已有使用 NHANES 和 GEO 联合分析的成功案例,它们展示了公共数据库整合对疾病机制研究、流行病学关联、潜在生物标志物 /靶点发现的重要价值。对于你关注公共数据挖掘与转化应用,这条思路非常有意义:它将 “群体水平 / 流行病学” 与 “分子 / 基因表达” 联系起来,是通往精准 /转化医学的重要桥梁。

未来,我们还会更新孟德尔随机化的章节,大家赶紧订阅学习吧!
NHIS
NHIS采用以家庭为基础的调查方式,主要通过保密的面对面访谈收集数据。每年大约有2.7万名成年人参与调查,其中不少受访者还会提供其家庭中儿童的相关健康信息。调查对象为不居住在机构中的美国平民人口,即不包括现役军人以及居住在监狱、专业护理机构或精神病院等机构中的人群。
NHIS的公共使用数据文件可免费下载,所有可能用于识别个人身份的信息均已被删除,以确保参与者及其家庭的隐私安全。对于需要更高精度数据的研究人员,NHIS还通过国家卫生统计中心研究数据中心(RDC)提供受限数据文件,研究者需通过标准申请流程并支付相应费用,方可在严格监管的环境下使用这些数据。
此外,NHIS数据还与其他数据来源进行了关联整合,形成更为丰富的综合数据集,用于分析不同数据源之间的复杂关系。这些高质量数据被广泛应用于官方国家健康指标的编制,其突出优势在于能够对美国人口中的众多子群体进行可靠估计,例如按年龄、婚姻状况、地区类型、就业状况和贫困水平等维度进行分析。

现在,很多几千元的培训班,往往只会选一个数据库点到为止,要么只教 NHANES 的“下几个表+跑个模型”,要么只展示 GBD 的在线图表,几乎不会在同一体系下连通 NHANES、GBD、FAERS/VigiBase、GEO 和 NHIS,并从抽样设计、权重、偏倚评估到实际论文路径都讲到可操作。
而在这个专栏中,“公共数据库挖掘”作为第九篇,却已经把主流公共数据库拆解到能直接落地科研选题、完成完整数据流程并撰写论文的程度,这种深度与广度本身就远超大多数动辄几千元的短期培训班,因此单看这一篇,就已经足以让整个专栏显得极其划算。
并且,我们后面会不断更新,未来会有更多医学公共数据库挖掘技术,并且我们前面的很多统计挖掘方法也会不断更新,给大家更多方法,我们已经超过220万字,未来更多精彩内容,大家赶紧订阅学习吧!整个专栏不是“一次性卖内容”,而是一个会持续进化的医学数据科学“工具箱”。 后面会不断根据最新的研究热点、新发布的医学公共数据库、以及官方指南和统计方法的更新节奏,持续补充更多公共数据库挖掘的实战案例和技术细节,让大家手里的这套方法论始终不过时,而是越用越“值钱”。
除了公共数据库,前面几大篇里的统计分析、机器学习、可视化、临床试验设计、文献挖掘、因果推断等方法板块也都会持续更新,把新出现的分析思路、R 包工具链和科研范式,陆续整理成可直接上手的项目级教程,帮助大家不断拓展“工具带”,而不是只停留在最初买专栏时的那点内容。

市面上的 R 语言培训班和书籍(包括网络上的文章或视频),由于受限于培训时间或书籍篇幅,往往难以深入探讨 R 语言在数据科学或人工智能中的具体应用场景,内容泛泛而谈,最终无法真正解决实际工作中的问题。同时,它们也缺乏针对医药领域的深度结合与讨论。为了解决这些痛点,我们推出了《用 R 探索医药数据科学》专栏。该专栏将持续更新,不仅为您提供系统化的学习内容,更致力于成为您掌握最新、最全医药数据科学技术的得力助手。
- 每篇文章篇幅在5000字 至9000字之间。
- 内容涵盖试验统计、预测模型、科研绘图、数据库、机器学习等热点领域。
重要更新
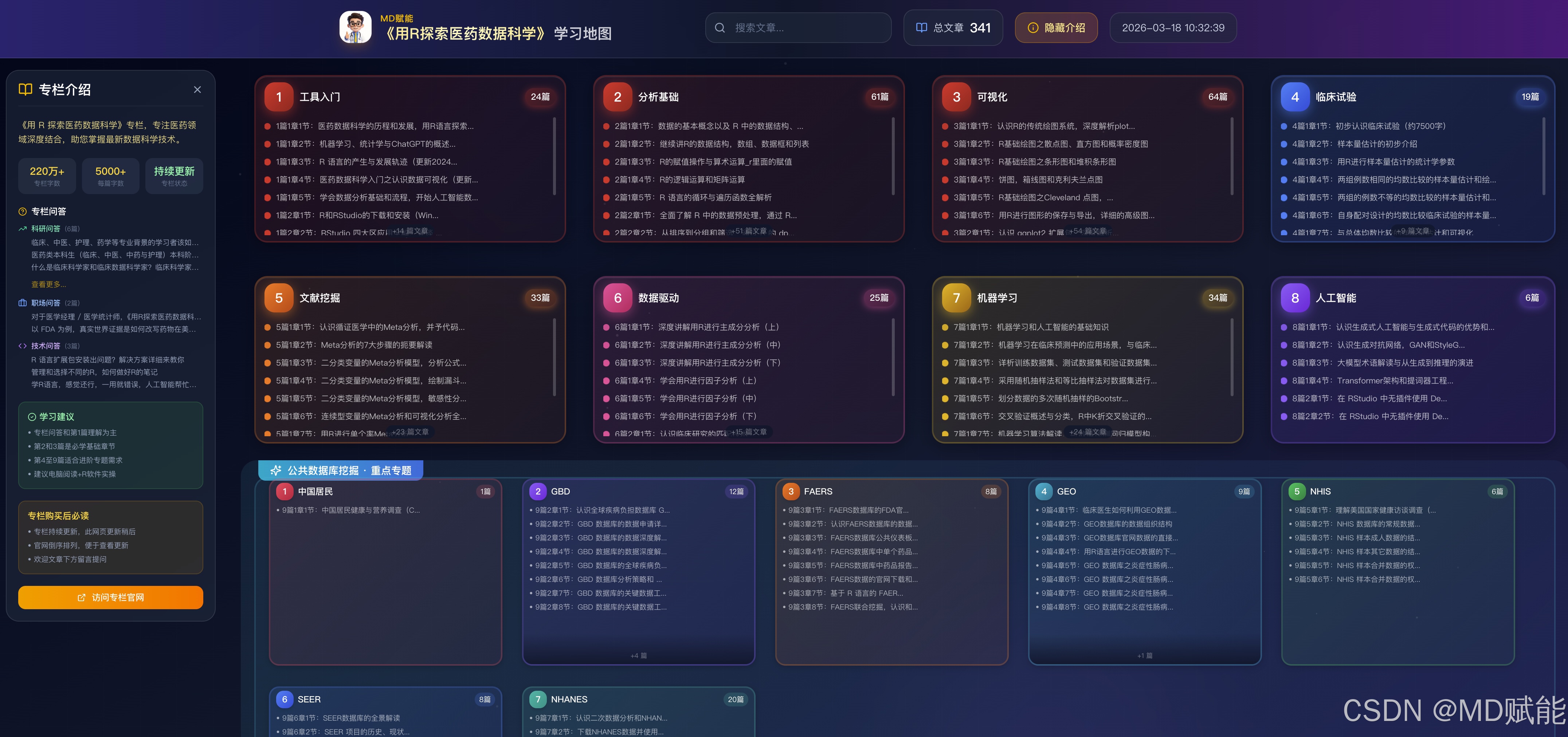
我们精心构建的《用R探索医药数据科学》学习地图,已于2026年3月中旬正式完成部署并上线。我们将专栏的核心内容重构为结构化的可视化知识图谱,不仅替代了原有的线性列表,更为学习者提供了清晰的进阶路径,订阅后的同学可以在PC端点击链接,查看目录:https://bestmd.coze.site/
专栏购买后的 6 点必读
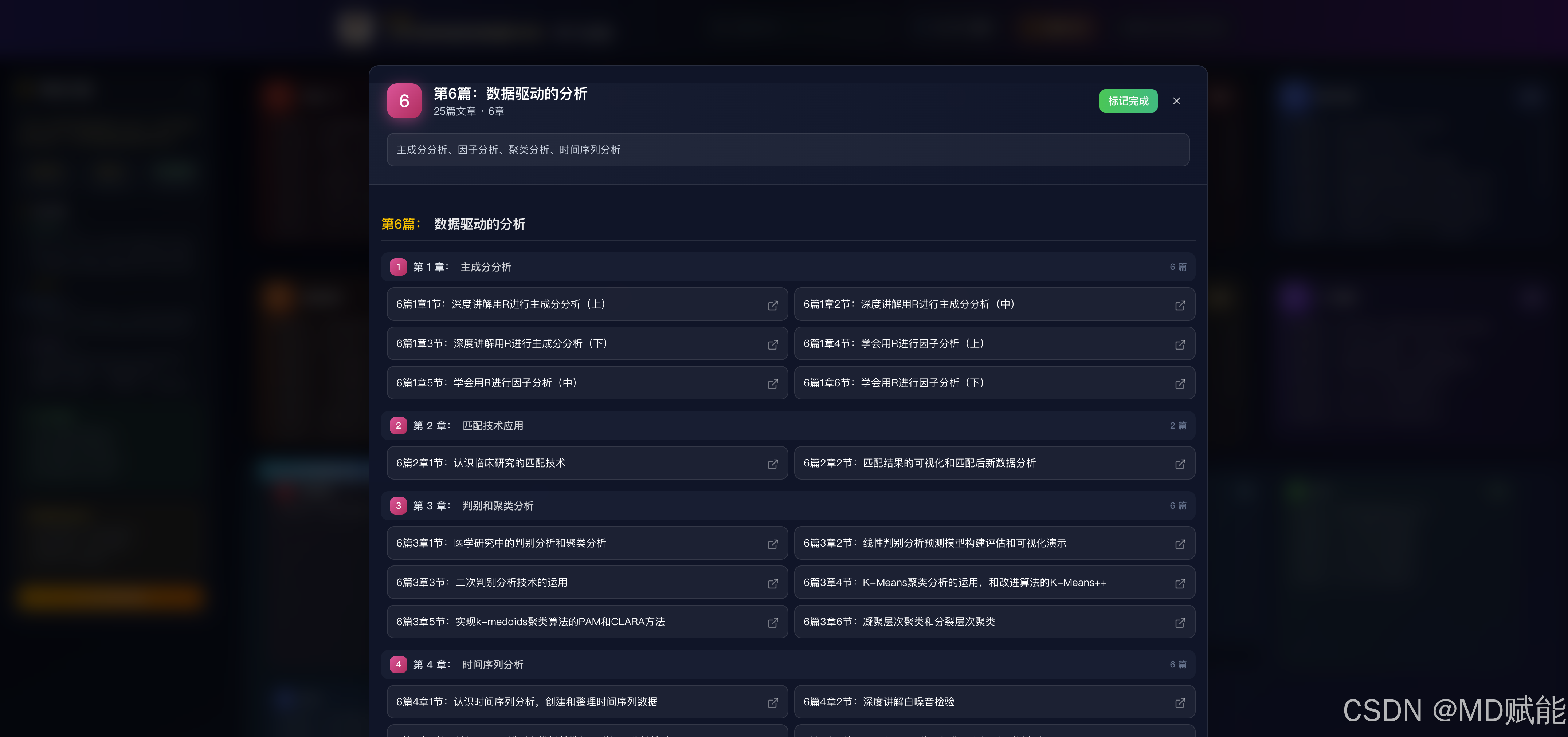
1、本专栏目前共包含 10 个模块,核心内容由 9 大篇章构成。专栏内容将持续更新,更新节奏不严格遵循固定目录顺序,而是结合团队实际工作进展,灵活选择对应章节发布。后续我们也会根据新技术发展与行业动态持续补充内容;若新增技术与现有体系差异较大,将酌情增设全新篇章。
2、建议大家按照以下路径高效学习:以专栏问答和第1篇作为理论基础重点理解,将第2篇和第3篇作为必修的核心操作基础,待基础夯实后,可根据科研需求针对性学习第4至9篇的进阶专题。为了保证最佳学习效果,建议大家在电脑端配合R软件进行同步实操练习。
3、结合当前临床数据科学的研究热点,在学习完前 3 篇内容后,可按自身需求选择后续学习方向:1)若用于自有课题数据,建议重点学习第二章 常规分析技术、第六篇 数据驱动分析及第七篇 机器学习与预测建模;2)若希望快速上手、尽早产出成果,且不介意稿件可能被期刊归类为综述,可选择第五篇 文献挖掘相关技术;3)若开展临床公共数据挖掘,建议结合自身研究方向与兴趣,从第九篇所列数据库中选取其一进行深度学习与实践;如有其他新技术需求,也欢迎在文章评论区留言。
4、本文目录支持直接点击跳转至具体文章,内容按 “篇 - 节” 正向顺序排列,方便按需学习。专栏问答板块以解答疑惑为主,若从基础入门,可直接从第一篇第一章第一节开始系统学习。

5、专栏官网地址(https://blog.csdn.net/2301_79425796/category_12729892.html)的内容显示为倒序排列,便于快速查看最新更新章节。需注意,专栏更新不严格遵循章节顺序,会结合技术热度灵活追加内容,可能连续数周更新已有篇章的补充内容,虽页面显示无明显章节变动,但每周都会有新文章上线,专栏处于持续更新状态。同时,每新增一篇文章后,会第一时间同步更新本文目录,确保目录与专栏内容实时匹配。
6、建议大家优先用电脑阅读(而非手机),同时打开 R 软件,直接复制文中代码实操练习、模仿复现,再一步步拆解理解背后的逻辑。学习完每篇文章后,也推荐大家写下学习感悟:一来可作为笔记留存,清晰记录学习进度与核心重点;二来能梳理思路、加深对技术知识点的理解,还能和其他学习者交流分享心得、互相启发。若学习过程中遇到具体问题,欢迎直接在文章下方留言评论。我们会及时关注你的疑问,结合问题场景与细节给出针对性解答和指导,帮你顺畅掌握专栏中的技术内容。