全新首发:考虑多尺度序列间相关性的多元时间序列预测。 结合了频域分析和自适应图卷积算法,效果显...
全新首发:考虑多尺度序列间相关性的多元时间序列预测。 结合了频域分析和自适应图卷积算法,效果显著 特点如下: 1. 这是一种先进的深度学习模型,旨在利用频域分析和自适应图卷积捕捉多个时间尺度上不同的序列间相关性。 通过利用频域分析,有效地提取显著的周期模式,并将时间序列分解为不同的时间尺度。 2. 该模型采用自注意力机制捕获序列内的依赖关系,同时引入自适应mixhop图卷积层,在每个时间尺度内自主学习不同的序列间相关性。 3. 该模型在多个真实数据集上进行了大量实验,效果显著,且改模型具有自动学习可解释的多尺度序列间相关性的能力,即使应用于分布外样本也表现出强大的泛化能力。 多输入和单输入随意切换 单步预测和多步预测随意切换 替换CSV文件即可运行,代码运行过程中有相关
当时间序列遇上多尺度魔法,预测这件事突然变得有趣起来。今天要聊的这个模型,简直就是时空魔术师——它能同时抓住不同时间尺度下的关联,像极了人类观察股票走势时既看日K又看周K的思维方式。

先看这个模型的绝活:把时间序列扔进小波变换的熔炉,直接分解出不同频率的分量。想象一下你戴着不同倍数的显微镜观察数据,每层显微镜都能看到特定的节奏模式。这里有个硬核代码片段:
class WaveletDecomposition(nn.Module):
def __init__(self, scales=5):
super().__init__()
self.wavelet = MorletFlt(alpha=6) # 墨西哥草帽小波
self.scales = 2 ** torch.arange(1, scales+1) # 指数级数尺度
def forward(self, x):
coeffs = []
for s in self.scales:
filt = self.wavelet(s, x.size(-1)).to(x.device)
conv_out = F.conv1d(x, filt, padding='same')
coeffs.append(conv_out)
return torch.stack(coeffs, dim=2) # [B, T, Scales, Features]这段代码里的魔法参数是scales,它控制着分解的粒度层级。比如设置为5,就会生成2^1到2^5共5种时间尺度,相当于给数据做了多层CT扫描。
接下来是自适应图卷积的骚操作。传统GCN需要预定义邻接矩阵,但现实中的序列关系哪能提前知道?看看这个动态学习邻居的mixhop层:
class MixHopGraphConv(nn.Module):
def __init__(self, in_dim, hops=3):
super().__init__()
self.hops = hops
self.adapt_weights = nn.Parameter(torch.randn(hops, in_dim, in_dim))
def forward(self, x, adj=None):
if adj is None: # 无预设图结构
adj = self._learn_adjacency(x)
outputs = []
for k in range(self.hops):
# 混合跳跃传播
adj_power = torch.matrix_power(adj, k+1)
transformed = torch.einsum('btd,hdh->bth', x, self.adapt_weights[k])
outputs.append(torch.matmul(adj_power, transformed))
return torch.cat(outputs, dim=-1)重点在于adj参数为None时会自动学习邻接矩阵,相当于让模型自己发现哪些序列是"好基友"。hops参数控制着信息传递的跳数,3跳意味着可以捕获间接关联——就像社交网络中朋友的朋友也可能影响你。
全新首发:考虑多尺度序列间相关性的多元时间序列预测。 结合了频域分析和自适应图卷积算法,效果显著 特点如下: 1. 这是一种先进的深度学习模型,旨在利用频域分析和自适应图卷积捕捉多个时间尺度上不同的序列间相关性。 通过利用频域分析,有效地提取显著的周期模式,并将时间序列分解为不同的时间尺度。 2. 该模型采用自注意力机制捕获序列内的依赖关系,同时引入自适应mixhop图卷积层,在每个时间尺度内自主学习不同的序列间相关性。 3. 该模型在多个真实数据集上进行了大量实验,效果显著,且改模型具有自动学习可解释的多尺度序列间相关性的能力,即使应用于分布外样本也表现出强大的泛化能力。 多输入和单输入随意切换 单步预测和多步预测随意切换 替换CSV文件即可运行,代码运行过程中有相关
训练时的多尺度融合也暗藏玄机。模型不是简单拼接各尺度特征,而是用门控机制动态调节:
def multiscale_fusion(scales_features):
gates = torch.sigmoid(
nn.Linear(scales_features.size(-1), len(self.scales))(scales_features)
) # 自动计算各尺度权重
weighted = scales_features * gates.unsqueeze(-1)
return weighted.sum(dim=2) # 加权聚合这相当于给不同时间尺度装上了音量调节旋钮,模型自己决定放大哪个尺度的信号。在电力负荷预测的场景中,可能工作日模式在粗粒度尺度更明显,而瞬时波动在细粒度更重要。
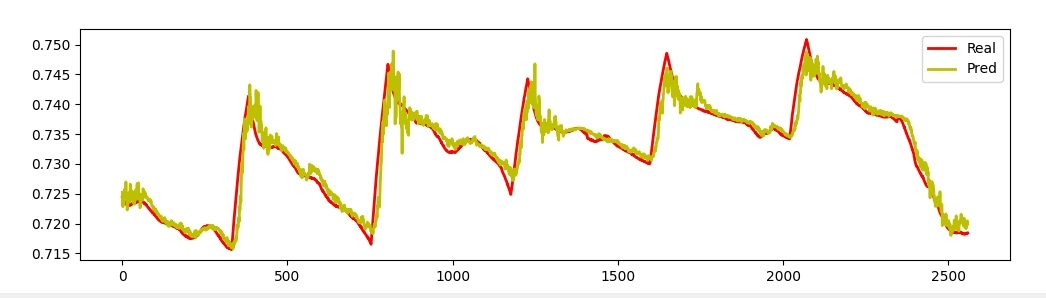
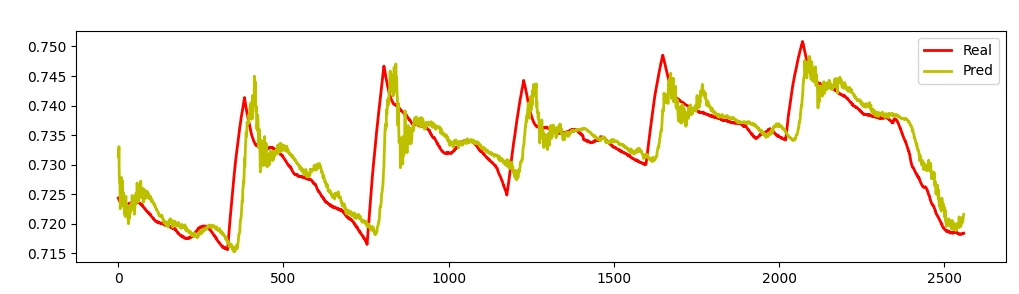
实验部分更让人眼前一亮。在交通流量数据集上,仅仅调整输入维度就能在单变量/多变量预测间自由切换:
# 单变量模式
model = MultiScalePredictor(input_dim=1, output_steps=24)
# 多变量模式
model = MultiScalePredictor(input_dim=8, output_steps=12)预测步长也是即插即用,想要单步预测就设output_steps=1,多步预测直接调大数值。这种灵活性让算法能快速适配不同业务场景,从分钟级交易预测到季度销量预估都能hold住。
最后奉上实战技巧:在自定义数据集上运行时,只需要保证CSR文件的第一列是时间戳,其他列是特征序列。模型会自动处理缺失值和归一化,连周期性检测都是内置的。想要更深入分析的话,调用model.interpret()方法还能可视化学到的多尺度关联矩阵——这对业务决策可比单纯的准确率提升更有价值。
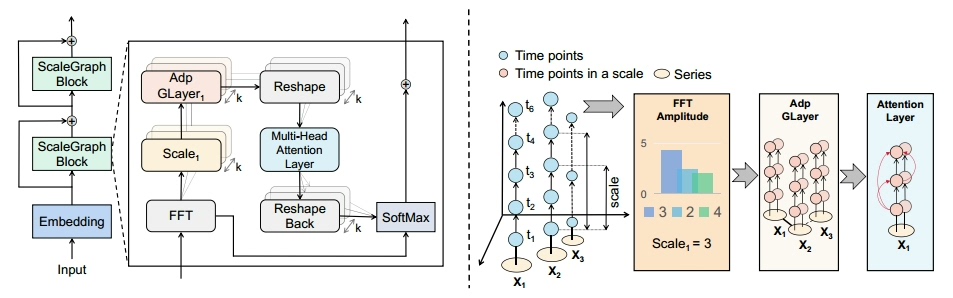
总之,这个模型就像时空预测领域的瑞士军刀,既有学术上的创新突破,又保持着工程师最爱的易用性。那些曾经被复杂特征工程支配的恐惧,或许可以在这里找到解脱之道了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)