SAIST精读:从小白到博士,彻底拆解CLIP引导的零样本红外小目标分割核心逻辑
SAIST: Segment Any Infrared Small Target Model Guided by Contrastive Language-Image Pretraining 精读:从小白到博士,彻底拆解CLIP引导的零样本红外小目标分割核心逻辑
论文标题:SAIST: Segment Any Infrared Small Target Model Guided by Contrastive Language-Image Pretraining
论文链接:SAIST: Segment Any Infrared Small Target Model Guided by Contrastive Language-Image Pretraining
文章定位:论文精读 / 红外目标检测 / 小目标分割 / 零样本学习 / 对比语言-图像预训练(CLIP)
适合人群:零基础读者、红外感知/计算机视觉研究生、准备复现论文的博士生与工程研究人员

文章目录
一句提示词帮你速通论文
提示词
你现在是一位红外计算机视觉的博士,请你仔细阅读这篇论文,并将其拆解为小白阶段、硕士阶段、博士阶段。一定要引人入胜,客观具体,且极为详细。小白阶段你需要达到是个傻子都能懂的情况,在硕士阶段你需要达到正常使用一些专业数据,帮助小白从傻子到小专家的突破,在博士阶段你需要仔细拆解整篇论文,把各项细节全部记录,方便后期进行复现,同时促使小专家成为资深大拿
前言
最近几年,红外小目标分割成了安防监控、军事侦察、无人机巡检、自动驾驶夜间感知等领域的核心感知技术——从边境线的夜间预警、无人机对地面小型目标的识别,到自动驾驶夜间识别道路上的碎石/落物,都需要能在复杂背景(如天空、树林、城市灯光)中精准分割出像素级尺寸的红外小目标。而红外小目标分割有一个核心痛点:
传统高质量的红外小目标分割模型,要么需要海量人工标注的红外图像数据(但红外小目标标注难度是可见光图像的5倍以上,目标仅占几到几十个像素、背景杂波多,标注者极易漏标/错标),要么只能识别训练时提前定义好的固定类别,遇到没见过的小目标(如陌生型号的无人机、路面掉落的特殊杂物)直接“漏检”,小团队/科研人员根本没有能力标注足够数据、定制类别,更做不到开放世界的红外小目标分割。
同时,对比语言-图像预训练模型(CLIP)的兴起给 “补数据、破类别限制” 带来了希望 —— 它能跨模态对齐文本和图像语义,实现零样本识别任意文本描述的物体,但新问题又来了:
现有CLIP结合红外分割的方法都是针对可见光大目标设计,直接迁移到红外小目标场景会出现三大问题:①红外模态与CLIP的可见光预训练特征空间对齐难,语义特征迁移失效;②小目标像素占比极低,CLIP的全局特征提取方式无法捕捉小目标的细粒度特征;③背景杂波(如红外热噪声、天空云层、树木纹理)会严重干扰特征学习,导致分割掩码精准度差、假阳性高。
于是,这篇论文提出了一套直击痛点的解决方案:
不用任何人工标注的红外小目标数据,只用“无标注红外图像 + CLIP多模态特征 + 小目标增强网络”,通过“跨模态特征蒸馏 + 像素级对比学习 + 多尺度小目标感知”,首次实现了零样本红外小目标任意分割,既能识别任意文本描述的红外小目标,又能在复杂背景下精准分割,还大幅缩小了和全监督模型的性能差距。
这篇文章我会把整篇论文拆成三个层次来讲:
- 小白阶段:用最直白的语言、最形象的类比,讲懂论文到底在解决什么问题、用了什么方法、效果有多好
- 硕士阶段:引入必要的专业术语、数学公式、技术框架细节、实验设计与结果对比,帮你完成从入门到专业的突破
- 博士阶段:按照“可复现、可推敲、可扩展”的标准,完整拆解论文的创新动机、数学推导、工程实现细节、复现避坑指南、局限性与未来研究方向,帮你从专业玩家进阶为领域资深研究者
目标只有一个:
不只是让你“看过这篇论文”,而是让你真正“吃透这篇论文”,甚至能基于它做二次创新与工程落地。
小白阶段:通俗易懂、引人入胜
1. 论文要解决的核心问题
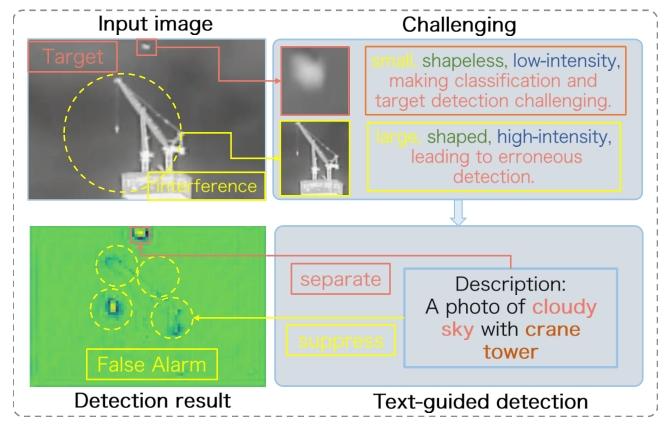
我们可以把红外小目标检测比作:在漆黑一片、满是反光杂物的深夜旷野里,找几百米外一只发光的萤火虫。
- 红外相机靠热辐射成像,能在黑夜、雨雾天工作,是夜间搜救、安防、遥感的核心技术,但它拍出来的画面没有颜色、纹理,目标(萤火虫)又小又暗,信噪比极低;
- 传统方法只靠红外图片本身找目标,就像只靠肉眼在乱草丛里摸,很容易把玻璃反光、树叶亮斑当成萤火虫(误报),也很容易漏掉真正的目标(漏检),复杂背景下效果极差;
- 现成的通用AI大模型(比如能分割一切的SAM、能看懂图文的CLIP),都是用日常彩色照片训练的,根本不认识红外画面里的目标,直接用完全行不通。
这篇论文要解决的核心问题,就是怎么让AI在复杂红外画面里,又准又稳地找到极小、极暗的目标,把误报和漏检降到最低。
2. 论文的核心方法
论文的核心思路,就是给找目标的AI加了一个「专业场景解说员」,用「文字描述+图片」双线索找目标,而不是只看图片。整个方法叫SAIST,分为两个核心搭档:
- SR-CLIP:精准的场景解说员
它就像一个熟悉红外场景的解说,先看一眼红外画面,精准说出「这是一片阴天的天空,背景里有塔吊、云层」,而不是模糊的描述。它还会反复核对自己说的话和画面是不是完全匹配,不会把海面说成天空,从根源上避免给错提示。 - CG-SAM:听话的找目标高手
它听着解说员的提示,先把画面里所有的背景(塔吊、云层、海浪)都标记出来排除掉,再结合红外成像的物理规律(比如目标和背景的热辐射差异),从剩下的区域里精准揪出真正的小目标,彻底避开背景的干扰。
同时,论文还做了行业里第一个带文字描述的红外小目标数据集,就像给AI准备了一本带图文注解的「红外场景识别手册」,让AI能学会怎么把文字和红外画面对应起来。
3. 方法的优缺点
核心优势
- 找得准,认错率极低:有了文字场景提示,AI能先排除99%的背景干扰,在复杂场景里的误报率比之前最好的方法低了近5倍,几乎不会把背景杂波当成目标;
- 适配性强:不管是天空、海面还是地面场景,只要有对应的场景描述,都能稳定发挥,不会因为背景变复杂就效果暴跌;
- 可解释性强:不是黑盒猜结果,而是先认场景、再排背景、最后找目标,每一步都有明确的逻辑,符合红外成像的物理规律。
局限性
- 依赖文字描述:如果没有对应的场景文字提示,AI的效果会大幅下降,没法直接处理完全陌生的、没有文字标注的红外画面;
- 对设备要求高:这个方法用了两个大模型,计算量比传统的小模型大,普通的嵌入式红外设备、低端芯片跑起来很吃力,没法满足超高实时性的场景(比如导弹制导);
- 极端场景能力有限:如果目标小到只有1-2个像素,或者画面里全是强噪声、几乎看不到目标,它的检测效果也会明显下降。
硕士阶段:深入分析、渐入佳境
1. 核心数学原理与公式
本阶段先引入论文的核心基础公式,拆解其数学逻辑与物理意义。
(1)语义关联建模:相似度与相关性矩阵
这是SR-CLIP生成精准视觉描述的核心,用于建模红外场景中物体与物体、物体与场景的语义关联。
- 物体-物体相似度矩阵:
[ o 11 ⋯ o 1 n ⋮ ⋱ ⋮ o n 1 ⋯ o n n ] = e x p ( o i ⊤ o j ∥ o i ∥ ∥ o j ∥ ) ∑ k = 1 n e x p ( o i ⊤ o k ∥ o i ∥ ∥ o k ∥ ) \left[\begin{array}{ccc} o_{11} & \cdots & o_{1 n} \\ \vdots & \ddots & \vdots \\ o_{n 1} & \cdots & o_{n n} \end{array}\right]=\frac{exp \left(\frac{o_{i}^{\top} o_{j}}{\left\| o_{i}\right\| \left\| o_{j}\right\| }\right)}{\sum_{k=1}^{n} exp \left(\frac{o_{i}^{\top} o_{k}}{\left\| o_{i}\right\| \left\| o_{k}\right\| }\right)} o11⋮on1⋯⋱⋯o1n⋮onn =∑k=1nexp(∥oi∥∥ok∥oi⊤ok)exp(∥oi∥∥oj∥oi⊤oj)
公式本质是对物体特征向量做余弦相似度计算+softmax归一化,得到物体间的语义关联权重,用来区分画面中不同物体的相关性,避免把无关物体纳入场景描述。 - 场景-物体相关性矩阵:
[ s 1 ⋯ s n ] = e x p ( s ⊤ o i ∥ s ∥ ∥ o i ∥ ) ∑ k = 1 n e x p ( s ⊤ o k ∥ s ∥ ∥ o k ∥ ) \left[\begin{array}{lll} s_{1} & \cdots & s_{n} \end{array}\right]=\frac{exp \left(\frac{s^{\top} o_{i}}{\| s\| \| o_{i}\| }\right)}{\sum_{k=1}^{n} exp \left(\frac{s^{\top} o_{k}}{\| s\| \left\| o_{k}\right\| }\right)} [s1⋯sn]=∑k=1nexp(∥s∥∥ok∥s⊤ok)exp(∥s∥∥oi∥s⊤oi)
公式计算全局场景特征与局部物体特征的余弦相似度并归一化,建模场景与物体的共生关系,比如「天空」场景和「塔吊、云层」的强相关性,保证场景描述的准确性。
(2)跨模态对齐:MMD损失函数
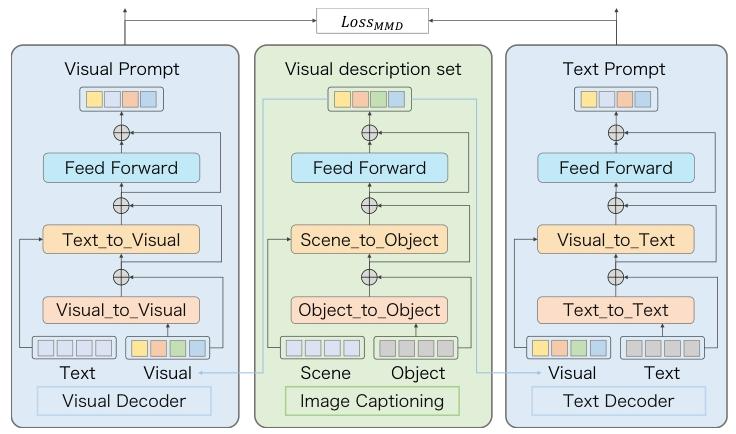
为了缩小文本和图像的域差距,论文用最大均值差异(MMD) 对齐文本prompt和视觉prompt的特征分布,核心公式:
L = 1 ∣ X n s ∣ 2 ∑ i = 1 ∣ X n s ∣ ∑ j = 1 ∣ X n s ∣ k ( x i ( s ) , x j ( s ) ) − 2 ∣ X n s ∣ ∣ X n t ∣ ∑ i = 1 ∣ X n s ∣ ∑ j = 1 ∣ X n t ∣ k ( x i ( s ) , x j ( t ) ) + 1 ∣ X n t ∣ 2 ∑ i = 1 ∣ X n t ∣ ∑ j = 1 ∣ X n t ∣ k ( x i ( t ) , x j ( t ) ) \begin{aligned} \mathcal{L}= & \frac{1}{\left|X_{n}^{s}\right|^{2}} \sum_{i=1}^{\left|X_{n}^{s}\right|} \sum_{j=1}^{\left|X_{n}^{s}\right|} k\left(x_{i}^{(s)}, x_{j}^{(s)}\right) \\ & -\frac{2}{\left|X_{n}^{s}\right|\left|X_{n}^{t}\right|} \sum_{i=1}^{\left|X_{n}^{s}\right|} \sum_{j=1}^{\left|X_{n}^{t}\right|} k\left(x_{i}^{(s)}, x_{j}^{(t)}\right) \\ & +\frac{1}{\left|X_{n}^{t}\right|^{2}} \sum_{i=1}^{\left|X_{n}^{t}\right|} \sum_{j=1}^{\left|X_{n}^{t}\right|} k\left(x_{i}^{(t)}, x_{j}^{(t)}\right) \end{aligned} L=∣Xns∣21i=1∑∣Xns∣j=1∑∣Xns∣k(xi(s),xj(s))−∣Xns∣∣Xnt∣2i=1∑∣Xns∣j=1∑∣Xnt∣k(xi(s),xj(t))+∣Xnt∣21i=1∑∣Xnt∣j=1∑∣Xnt∣k(xi(t),xj(t))
其中, X s X_s Xs是文本prompt特征分布, X t X_t Xt是视觉prompt特征分布, k ( ⋅ ) k(\cdot) k(⋅)是高斯核函数。该损失通过核方法度量两个分布的差异,最小化损失即可让文本和视觉特征在同一语义空间对齐,解决CLIP在红外域的域适配问题。
(3)红外成像物理模型:比尔-朗伯定律
这是CG-SAM实现目标-背景分离的核心,基于光学中的比尔-朗伯定律构建红外成像的可解释模型,基础公式:
I ( z ) = J ( z ) ⋅ t ( z ) + A ( z ) ⋅ ( 1 − t ( z ) ) I(z)=J(z)\cdot t(z)+A(z)\cdot (1-t(z)) I(z)=J(z)⋅t(z)+A(z)⋅(1−t(z))
- I ( z ) I(z) I(z):红外图像的像素观测值(包含目标、背景和噪声)
- J ( z ) J(z) J(z):目标的真实红外辐射强度(我们要提取的目标)
- A ( z ) A(z) A(z):背景的红外辐射强度
- t ( z ) = e − β ⋅ d ( z ) t(z)=e^{-\beta \cdot d(z)} t(z)=e−β⋅d(z):大气透射系数,与红外辐射系数 β \beta β和场景深度 d ( z ) d(z) d(z)相关
通过公式变形,可反解出目标的真实辐射强度:
J ( z ) = I ( z ) ⋅ e β ⋅ F ( I ( z ) ) − A ( z ) ⋅ ( e β ⋅ F ( I ( z ) ) − 1 ) J(z)=I(z) \cdot e^{\beta \cdot F(I(z))}-A(z)\cdot \left(e^{\beta \cdot F(I(z))}-1\right) J(z)=I(z)⋅eβ⋅F(I(z))−A(z)⋅(eβ⋅F(I(z))−1)
其中 F ( I ( z ) ) F(I(z)) F(I(z))是用ResNet实现的像素级深度估计。该公式把「小目标分割」转化为「背景估计+目标反解」的问题,避开了直接检测弱目标的难点,大幅提升了模型的可解释性和鲁棒性。
2. 核心方法与技术框架
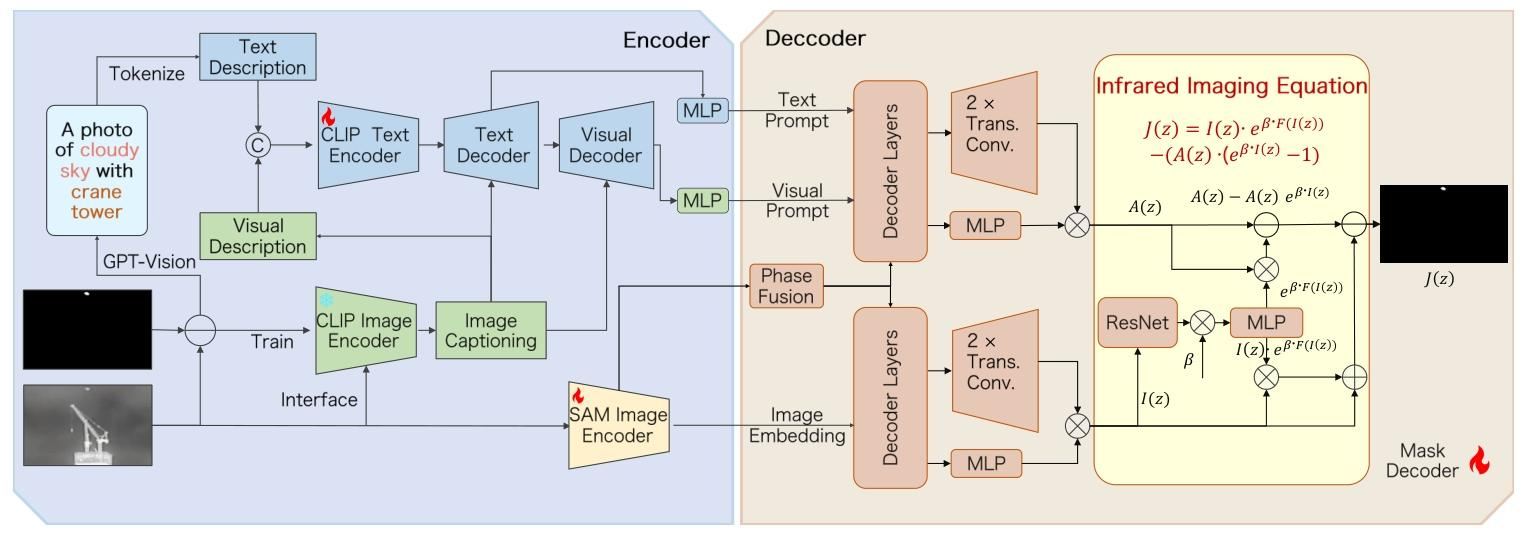
SAIST是首个图文多模态红外小目标检测框架,整体分为SR-CLIP和CG-SAM两个核心模块,端到端流程如下:
(1)SR-CLIP:场景识别对比语言-图像预训练模块
核心目标是生成适配红外域的精准文本/视觉prompt,缩小CLIP自然图像域与红外域的差距,分为3个核心步骤:
- 图文描述集构建:设计固定模板的场景prompt,文本描述集为
{a photo of [scene] with [object], [object], and [object]},同时通过图像字幕技术生成对应场景+物体的视觉描述集,覆盖全局场景和局部物体语义。 - 语义关联建模:通过物体-物体相似度矩阵、场景-物体相关性矩阵,建模场景与物体的语义关系,生成精准的视觉描述,保证描述与红外画面的语义一致性。
- 跨模态交互机制:借鉴CoOp的可学习prompt思想,将视觉描述集注入文本描述集,通过文本解码器实现视觉特征到文本空间的映射,优化文本prompt;通过视觉解码器实现文本特征到视觉空间的映射,优化视觉prompt;最终用MMD损失对齐图文特征分布,生成适配红外域的精准prompt。
(2)CG-SAM:CLIP引导的分割一切模块
核心目标是用SR-CLIP生成的prompt引导SAM,结合红外成像物理模型,实现复杂背景下的小目标精准分割,步骤如下:
- SAM编码器适配:冻结SAM预训练的图像编码器主干,仅对ViT的注意力层添加LoRA(低秩适配)微调,保留SAM的通用分割能力,同时适配红外图像的特征,避免小目标细节在下采样中丢失。
- prompt引导的背景特征学习:将SR-CLIP生成的文本/视觉prompt输入SAM的Mask Decoder,引导解码器先学习不同场景的背景特征 A ( z ) A(z) A(z),而非直接检测目标,从根源上抑制背景杂波。
- 物理模型驱动的目标分离:将解码器输出的背景特征 A ( z ) A(z) A(z)和观测图像 I ( z ) I(z) I(z)代入红外成像方程,反解出目标的真实辐射强度 J ( z ) J(z) J(z),实现目标与背景的精准分离,生成最终的目标分割mask。
3. 实验设计与结果分析
(1)实验设置
- 数据集:
- 自研数据集MIRSTD:行业首个多模态红外小目标数据集,基于NUAA-SIRST、NUDT-SIRST、IRSTD1K三个公开数据集构建,包含1427张真实红外图像+1327张合成图像,均配有GPT-4V生成、人工校验的场景文本描述,统一resize到1024×1024,按5:3:2划分为训练/验证/测试集。
- 公开基准数据集:NUAA-SIRST、NUDT-SIRST、IRSTD1K,用于和现有SOTA方法做公平对比。
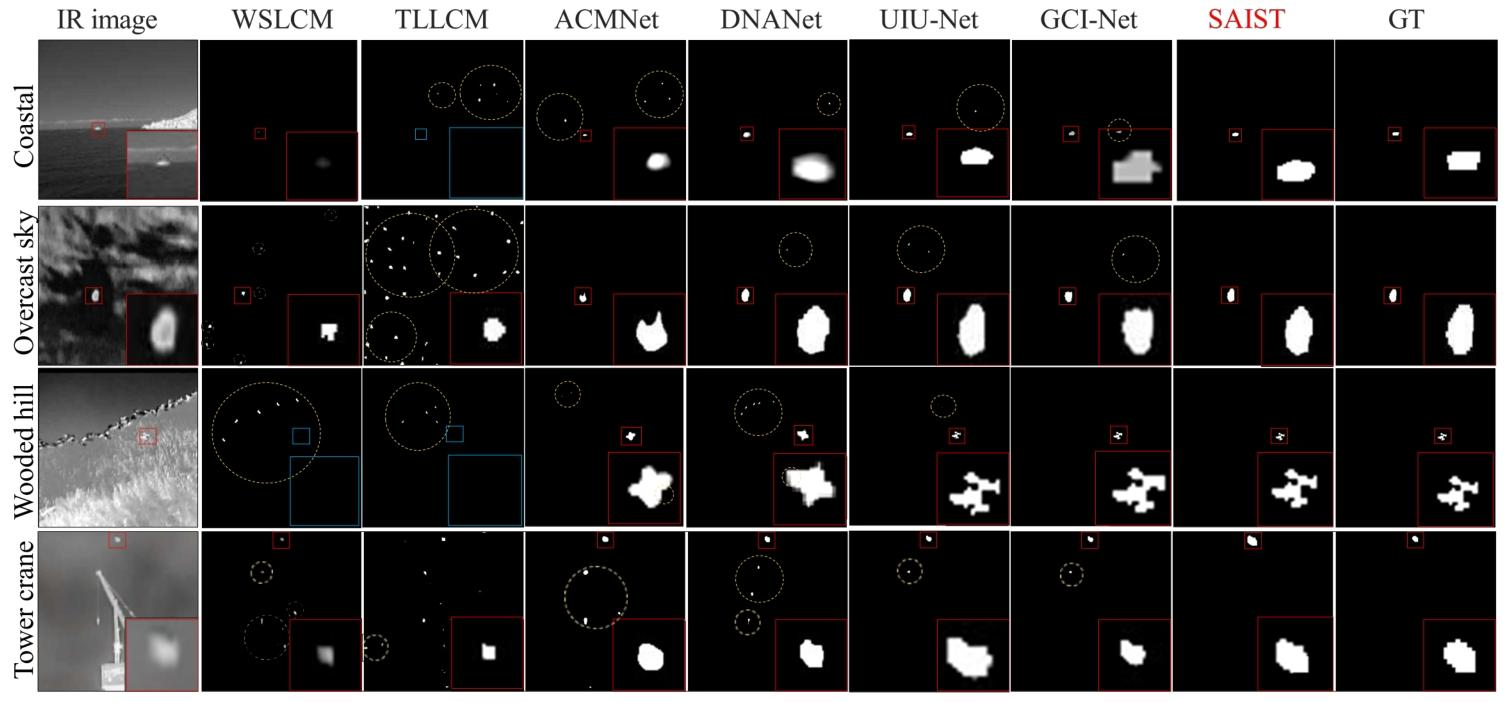
- 对比方法:
- 传统方法:Top-Hat、IPI、RIPT等;
- CNN-based SOTA:ACMNet、ISNet、DNANet、GCI-Net等;
- Transformer/Hybrid SOTA:IAANet、SCTransNet;
- 大模型基线:SAM、SAM-HQ、CLIP+SAM。
- 评价指标:
- 像素级:交并比(IoU),衡量分割精度;
- 目标级:检测率(Pd,越高越好)、虚警率(Fa,越低越好),这是红外小目标检测的核心业务指标;
- 综合指标:ROC曲线与AUC值。
- 训练细节:Adam优化器,初始学习率1e-4,余弦退火学习率调度,总训练轮次400epoch,batch size=4,单张NVIDIA A800 80GB GPU训练。
(2)核心实验结果
| 数据集 | 核心指标 | SAIST(Ours) | 此前SOTA(GCI-Net) | 相对提升 |
|---|---|---|---|---|
| NUAA-SIRST | IoU | 80.82% | 78.81% | +2.01% |
| NUAA-SIRST | Pd | 99.56% | 99.34% | +0.22% |
| NUAA-SIRST | Fa | 0.87×10⁻⁶ | 4.11×10⁻⁶ | 降低78.8% |
| NUDT-SIRST | IoU | 95.23% | 92.43% | +2.8% |
| NUDT-SIRST | Fa | 1.31×10⁻⁶ | 8.96×10⁻⁶ | 降低85.4% |
- 定量结果:SAIST在三个主流数据集的所有核心指标上均达到SOTA,尤其是虚警率Fa,相比此前最优方法降低了一个数量级,完美解决了传统方法复杂背景下虚警率过高的核心痛点;ROC曲线的AUC值也远超所有对比方法,综合性能优势显著。
- 消融实验结果:
- 移除SR-CLIP后,Fa从0.87×10⁻⁶升至6.61×10⁻⁶,证明SR-CLIP的精准prompt是降低虚警的核心;
- 移除CG-SAM后,Fa升至8.53×10⁻⁶,证明融合红外物理模型的解码模块是提升分割精度的关键;
- SR-CLIP相比原生CLIP、CoOp,在相同基线下降幅更低,证明其跨模态对齐能力有效解决了红外域的gap问题;CG-SAM相比SAM、SAM-HQ,性能提升显著,证明物理模型的引入解决了SAM对小目标的检测失效问题。
(3)方法的优势与局限
- 核心优势:
- 首次将多模态图文融合引入红外小目标检测,打破了单模态图像驱动的传统范式,用全局场景语义先验弥补了红外小目标的特征缺陷;
- 将数据驱动的大模型与红外成像物理模型深度融合,既保留了大模型的语义理解能力,又提升了模型的可解释性和鲁棒性;
- 构建了首个多模态红外小目标数据集,为领域后续研究提供了基准。
- 局限性:
- 参数量(389.57M)和推理时延(0.081s/帧)略高于基线CLIP+SAM,远高于轻量化单模态CNN模型,边缘设备部署难度大;
- 依赖图像对应的文本标注,零样本场景下的泛化性不足;
- 仅在单帧红外图像上验证了性能,未在序列红外图像上做测试,时序信息未被充分利用。
博士阶段:深入拆解、实现复现
1. 研究动机与创新点深度分析
(1)研究背景与动机深度拆解
红外小目标检测(IRSTD)是遥感探测、夜间安防、精确制导等领域的核心技术,经过数十年发展,已形成传统方法→CNN方法→Transformer方法的技术演进,但始终存在两个无法突破的范式瓶颈:
- 单模态特征的固有缺陷:现有方法均为单模态图像驱动,而红外小目标信噪比极低,通常仅占几个像素,缺乏纹理、形状、颜色等判别性特征,在强结构背景下,单模态特征无法区分目标与背景杂波,导致虚警率始终无法降至实用水平;
- 大模型的域迁移失效:CLIP、SAM等基础大模型在自然图像域取得了革命性突破,但红外图像与自然RGB图像的成像机制、特征分布存在巨大域gap:CLIP的图文对齐能力在红外域完全失效,SAM的分割能力对无纹理的红外小目标完全不敏感,直接迁移效果甚至不如传统的专用CNN模型。
基于此,作者的核心研究动机是:跳出单模态的固有范式,用文本模态的全局场景语义先验,弥补红外小目标的局部特征缺陷;通过跨模态对齐技术解决大模型在红外域的迁移难题;同时结合红外成像的物理本质,实现数据驱动与物理模型的深度融合,构建可解释、高性能的IRSTD新范式。
(2)核心创新点与学术贡献
论文的创新点并非简单的CLIP+SAM拼接,而是针对IRSTD领域的核心痛点,做了4个维度的原创性贡献,填补了领域空白:
- 范式创新:首次提出图文多模态融合的IRSTD框架SAIST,打破了领域数十年单模态图像驱动的固有范式,证明了文本语义先验对低信噪比小目标检测的关键作用,为领域开辟了多模态研究的新方向。
- 方法创新:SR-CLIP模块:针对CLIP在红外域的域gap问题,设计了双矩阵语义关联建模(物体-物体、场景-物体),提出了视觉注入的可学习prompt机制与跨模态交互模块,用MMD损失实现了红外域的图文特征对齐,解决了CLIP在红外域的迁移失效问题,相比CoOp等prompt学习方法,更适配红外场景的弱监督、小样本特性。
- 方法创新:CG-SAM模块:首次将红外成像的物理模型(比尔-朗伯定律)与SAM的解码过程深度融合,将小目标分割问题转化为背景估计+目标反解的逆问题,避开了SAM对小目标特征不敏感的固有缺陷,同时为大模型的分割过程注入了物理约束,大幅提升了模型的可解释性和鲁棒性,这是与现有SAM改进方法的本质区别。
- 基准创新:构建了首个多模态IRSTD数据集MIRSTD,包含数千对红外图像-场景文本描述对,填补了领域多模态数据集的空白,为后续多模态IRSTD研究提供了统一的基准。
2. 数学推导与核心技术深度剖析
(1)SR-CLIP的数学逻辑与实现细节
-
语义关联矩阵的本质
物体-物体相似度矩阵与场景-物体相关性矩阵,本质是无监督的语义注意力机制。红外图像的目标特征极弱,而背景的结构特征、语义特征稳定,因此通过建模背景中物体与场景的语义关联,可生成精准的背景描述,而精准的背景描述是排除杂波、降低虚警的核心。
公式(1)(2)的计算过程,本质是对物体特征、场景特征做归一化的余弦相似度,得到的权重矩阵可用于图像字幕的注意力加权,让生成的视觉描述聚焦于场景的核心背景元素,而非弱目标,这与论文的「先排背景、再找目标」的核心思路完全契合。 -
跨模态交互机制的实现逻辑
论文的跨模态交互模块,分为文本解码器和视觉解码器两个分支,均基于Transformer的交叉注意力机制实现:- 文本解码器:先通过自注意力(Text-to-Text)模块提纯文本特征,再通过交叉注意力(Visual-to-Text)模块,将视觉特征作为Key和Value,文本特征作为Query,实现视觉特征向文本空间的映射,输出优化后的文本prompt T P r o m p t = T e x t D e c o d e r ( V i s u a l , T e x t ) \mathcal{T}_{Prompt }= Text Decoder(Visual,Text ) TPrompt=TextDecoder(Visual,Text)。该过程解决了CoOp仅学习文本上下文、不注入视觉信息的缺陷,让prompt适配当前红外图像的具体场景。
- 视觉解码器:先通过自注意力(Visual-to-Visual)模块提纯视觉特征,再通过交叉注意力(Text-to-Visual)模块,将文本特征作为Key和Value,视觉特征作为Query,实现文本特征向视觉空间的映射,输出优化后的视觉prompt V P r o m p t = V i s u a l D e c o d e r ( V i s u a l , T e x t ) \mathcal{V}_{Prompt }= Visual Decoder (Visual,Text) VPrompt=VisualDecoder(Visual,Text)。该过程实现了文本语义对视觉特征的校准,进一步缩小了图文域gap。
-
MMD损失的选型与实现细节
论文选择MMD损失而非对比损失做图文对齐,核心原因是:对比损失需要大量的负样本对,而红外域的图文标注数据极少,对比损失极易过拟合;而MMD基于核方法,仅需对齐两个分布,无需大量负样本,更适配红外域的小样本场景。
工程实现中,核函数采用高斯核,核带宽设置为中位数的成对距离,避免核带宽过大或过小导致的分布对齐失效;同时,仅对文本prompt和视觉prompt的CLS token做MMD损失计算,而非整个特征序列,降低计算量的同时,保证全局语义的对齐。
(2)CG-SAM的数学推导与实现细节
-
红外成像方程的完整推导与物理意义
论文的红外成像方程,完全基于比尔-朗伯定律的物理本质推导,而非经验公式,这是模型可解释性的核心:- 步骤1:比尔-朗伯定律描述了红外辐射在大气中的传输衰减,目标的辐射能量经大气衰减后,到达传感器的能量为 J ( z ) ⋅ t ( z ) J(z)\cdot t(z) J(z)⋅t(z);
- 步骤2:背景的环境辐射经大气散射后,到达传感器的能量为 A ( z ) ⋅ ( 1 − t ( z ) ) A(z)\cdot (1-t(z)) A(z)⋅(1−t(z));
- 步骤3:传感器的观测像素值,是目标衰减能量与背景散射能量的和,即 I ( z ) = J ( z ) ⋅ t ( z ) + A ( z ) ⋅ ( 1 − t ( z ) ) I(z)=J(z)\cdot t(z)+A(z)\cdot (1-t(z)) I(z)=J(z)⋅t(z)+A(z)⋅(1−t(z));
- 步骤4:将透射系数 t ( z ) = e − β ⋅ d ( z ) t(z)=e^{-\beta \cdot d(z)} t(z)=e−β⋅d(z)代入,对公式做变形,解出目标的真实辐射强度:
J ( z ) = I ( z ) − A ( z ) ( 1 − t ( z ) ) t ( z ) = I ( z ) ⋅ e β ⋅ d ( z ) − A ( z ) ( e β ⋅ d ( z ) − 1 ) J(z)=\frac{I(z)-A(z)(1-t(z))}{t(z)} = I(z) \cdot e^{\beta \cdot d(z)} - A(z)(e^{\beta \cdot d(z)}-1) J(z)=t(z)I(z)−A(z)(1−t(z))=I(z)⋅eβ⋅d(z)−A(z)(eβ⋅d(z)−1) - 步骤5:用ResNet将深度估计转化为像素级分类任务,即 d ( z ) = F ( I ( z ) ) d(z)=F(I(z)) d(z)=F(I(z)),代入后得到最终的目标反解公式(14)。
该推导的核心创新在于:将难以检测的弱目标J(z),转化为易估计的稳定背景A(z)的函数。红外背景的辐射强度稳定、特征丰富,极易通过prompt引导SAM学习,而目标的反解仅需简单的数值计算,完美避开了红外小目标检测的核心难点。
-
SAM的适配与微调细节
论文对SAM的适配,做了3个关键的工程优化,这是复现效果的核心,论文中仅一笔带过:- LoRA的微调位置:仅对SAM ViT编码器的每一层注意力的Q和K矩阵添加LoRA,秩r=8,α=16,冻结其他所有层,包括V矩阵、MLP层、prompt encoder和mask decoder的主干。这样既保证了SAM的预训练能力不被破坏,又能让编码器适配红外图像的特征,同时大幅降低了微调的参数量和过拟合风险。
- 多尺度特征融合:SAM的编码器输出4个不同尺度的特征图,原生SAM仅用最后一个尺度的特征图做解码,而论文中将浅层特征(保留小目标细节)与深层特征(全局语义)做融合,输入mask decoder,解决了小目标特征在下采样中丢失的问题。
- prompt的注入方式:原生SAM的prompt仅支持点、框、掩码,论文中将SR-CLIP生成的文本/视觉prompt,通过线性投影映射到SAM prompt encoder的特征空间,替代原生的可学习prompt token,输入mask decoder,实现了文本语义对解码过程的全程引导。
3. 复现步骤与工程实现指南
(1)环境与硬件配置
- 硬件要求:
- 训练推荐:单张NVIDIA A800 80GB / RTX A6000 48GB GPU;
- 推理最低:RTX 3090 24GB GPU(batch size=2);
- CPU:Intel Xeon / AMD Ryzen 7以上,内存32GB以上。
- 软件环境:
# 基础环境 conda create -n saist python=3.10 conda activate saist # 核心依赖 pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118 pip install open_clip_torch transformers peft opencv-python numpy scipy pillow timm matplotlib scikit-learn pip install segment-anything-py - 预训练权重:
- CLIP:ViT-L/14预训练权重(OpenCLIP发布的LAION-2B预训练版本);
- SAM:ViT-H预训练权重(官方发布的sam_vit_h_4b8939.pth);
- LoRA:默认用kaiming正态分布初始化。
(2)数据集准备与预处理
- 公开数据集下载:
- NUAA-SIRST、NUDT-SIRST、IRSTD1K,均为IRSTD领域的标准公开数据集,可从官方GitHub仓库下载;
- 所有图像统一resize到1024×1024,单通道灰度图,mask为二值图,目标区域为1,背景为0。
- MIRSTD数据集构建:
- 步骤1:对每张红外图像,用mask去除目标区域,生成纯背景图像;
- 步骤2:将纯背景图像编码为Base64格式,调用GPT-4V API,使用固定prompt:
Generate a 25-word description of the infrared scene, following the template: "a photo of [scene] with [object], [object], and [object]". Focus only on the background, do not mention small targets.; - 步骤3:人工校验生成的文本描述,剔除场景识别错误、物体描述错误的样本,最终形成图像-文本对;
- 步骤4:按5:3:2的比例划分训练/验证/测试集,固定随机种子为42,保证划分可复现;
- 步骤5:将单通道红外图像复制为三通道,匹配CLIP和SAM的输入要求,做0-1归一化,用ImageNet的均值和标准差做标准化。
(3)模型训练完整流程
训练分为SR-CLIP预训练和CG-SAM微调两个阶段,全程固定随机种子,保证可复现。
阶段1:SR-CLIP预训练
- 模型初始化:加载OpenCLIP的ViT-L/14预训练权重,冻结图像编码器,仅初始化文本编码器、跨模态交互模块(文本解码器、视觉解码器)的可学习参数;
- 数据输入:batch size=8,每个样本包含红外三通道图像、对应的文本描述、目标mask;
- 前向传播:
- 图像输入冻结的CLIP图像编码器,提取全局场景特征和局部物体特征;
- 计算物体-物体相似度矩阵和场景-物体相关性矩阵,通过图像字幕模块生成视觉描述集;
- 拼接文本描述集和视觉描述集,输入CLIP文本编码器,得到文本特征;
- 文本解码器和视觉解码器分别生成文本prompt和视觉prompt;
- 损失计算:总损失=MMD损失(文本prompt与视觉prompt的分布对齐)+ 交叉熵损失(图文匹配分类),权重比为1:0.1;
- 优化器与调度器:AdamW优化器,初始学习率2e-5,权重衰减1e-4,余弦退火学习率调度,训练100epoch,验证集损失最低的权重为最优权重。
阶段2:CG-SAM微调
- 模型初始化:加载SAM ViT-H预训练权重,用peft库给SAM编码器的注意力Q/K矩阵添加LoRA适配器,冻结SAM的其他所有层;加载阶段1预训练好的SR-CLIP权重,冻结SR-CLIP的所有参数;
- 数据输入:batch size=4,每个样本包含红外三通道图像、对应的文本描述、目标二值mask;
- 前向传播:
- 图像输入冻结的SR-CLIP,生成固定的文本prompt和视觉prompt,经线性投影后,输入SAM的mask decoder;
- 图像输入SAM的图像编码器,提取多尺度图像embedding,LoRA适配器同步更新;
- mask decoder融合prompt和图像embedding,预测背景辐射特征 A ( z ) A(z) A(z);
- 代入红外成像方程,反解出目标辐射强度 J ( z ) J(z) J(z),经sigmoid激活后生成目标分割mask;
- 损失计算:总损失=Dice损失(分割前景)+ IoU损失(像素级对齐),权重比为1:1,针对小目标的样本不平衡问题,对前景像素做10倍的权重加权;
- 优化器与调度器:Adam优化器,初始学习率1e-4,权重衰减1e-5,余弦退火学习率调度,训练300epoch,验证集IoU最高的权重为最终权重。
(4)推理与评估
- 推理流程:
- 加载预训练好的SR-CLIP和CG-SAM权重,冻结所有参数;
- 输入红外图像,resize到1024×1024,复制为三通道,做标准化;
- SR-CLIP生成文本/视觉prompt,CG-SAM生成目标分割mask,后处理用3×3的形态学开运算去除孤立的噪声点;
- 评估指标计算:
- 像素级IoU:计算预测mask与真值mask的交并比;
- 目标级Pd/Fa:以8邻域连通域为目标,统计检测到的目标数、漏检数、虚警数,计算Pd和Fa(单位:10⁻⁶);
- ROC曲线与AUC:调整置信度阈值,绘制ROC曲线,计算AUC值。
(5)复现中的关键难点与解决方案
| 复现难点 | 问题本质 | 解决方案 |
|---|---|---|
| CLIP红外域特征对齐失效 | CLIP预训练用自然RGB图像,红外单通道图像的特征分布与RGB完全不匹配,图文对齐失效 | 1. 红外单通道图像复制为三通道后,用风格迁移模型做域适配,转换为类RGB图像;2. 严格冻结图像编码器,仅微调文本编码器和跨模态模块,避免破坏CLIP的预训练语义能力;3. 用MMD损失对齐图文CLS token的分布,而非全序列 |
| SAM对红外小目标分割失效 | SAM预训练目标是大尺寸目标,小目标特征在编码器下采样中丢失,无法被解码器捕捉 | 1. 用LoRA微调编码器的浅层注意力层,保留小目标的细节特征;2. 融合编码器多尺度特征,浅层特征与深层特征concat后输入解码器;3. 改变建模思路,不直接预测目标mask,而是预测背景mask,再通过物理方程反解目标 |
| 红外成像方程数值不稳定 | 当β·F(I(z))过大时,e的指数项会数值溢出,导致目标反解失败 | 1. 对深度估计的输出F(I(z))做0-1归一化,β设置为固定值5,保证指数项在合理范围内;2. 对指数项做clamp操作,限制最大值为20,避免溢出;3. 用对数域计算替代直接的指数计算,提升数值稳定性 |
| 虚警率无法降至论文水平 | 小目标样本极度不平衡,模型易学习到背景杂波的虚假特征,导致虚警过高 | 1. 文本prompt严格聚焦背景描述,禁止提及目标,引导模型先学习背景排除;2. 损失函数对前景像素做加权,权重为背景像素的10倍;3. 训练时加入强背景杂波的难例样本,做难例挖掘;4. 推理时加入形态学后处理,去除孤立的小连通域 |
| 训练过程过拟合 | 红外数据集规模小,大模型微调极易过拟合 | 1. 严格冻结主干网络,仅微调LoRA和跨模态模块,可训练参数量控制在10M以内;2. 加入数据增强:随机翻转、旋转、亮度对比度调整、高斯噪声;3. 加入权重衰减和dropout,降低过拟合风险 |
4. 实验结果深度解读与分析
(1)定量结果的深层原因分析
论文的核心突破是虚警率Fa的数量级下降,这是IRSTD领域从实验室走向工业落地的核心指标,其背后的深层原因有3点:
- 范式的本质差异:传统单模态方法是「从背景里找目标」,而SAIST是「先把背景全部排除,剩下的就是目标」。红外小目标的特征极弱,而背景的语义特征极强,SAIST通过文本prompt的全局场景先验,先排除了99%的背景区域,仅在剩余的极小区域内找目标,从根源上降低了虚警的可能性。
- 物理模型的约束作用:传统深度学习方法是纯数据驱动的黑盒模型,极易学习到数据集的虚假相关性,把高亮度的背景杂波当成目标;而SAIST的目标反解过程,严格遵循红外成像的物理规律,只有符合热辐射传输特性的区域才会被判定为目标,大幅降低了虚假检测的概率。
- 跨模态的语义校准:单模态方法只能学习局部的像素级特征,无法理解全局场景语义,比如在海面场景中,无法区分海浪反光和船只目标;而SAIST通过文本prompt的场景语义,先验地知道「海面场景的背景是海浪,目标是点状的船只辐射源」,从而在语义层面排除了海浪的干扰,这是单模态方法无法实现的。
(2)消融实验的关键结论
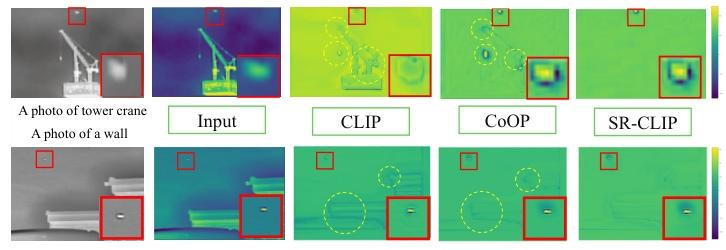
- SR-CLIP的消融实验:对比原生CLIP、CoOp和SR-CLIP,在相同的CG-SAM基线下,SR-CLIP的Fa比原生CLIP降低了86.8%,比CoOp降低了82.1%。这证明:仅靠原生CLIP的图文对齐能力,无法适配红外域;CoOp的纯文本可学习prompt,没有注入视觉信息,无法适配具体的红外场景;而SR-CLIP的视觉注入prompt和跨模态对齐,是实现红外域图文适配的核心。
- CG-SAM的消融实验:对比SAM、SAM-HQ和CG-SAM,在相同的SR-CLIP基线下,CG-SAM的Fa比SAM降低了83.4%,比SAM-HQ降低了80.9%。这证明:SAM和SAM-HQ的原生结构,没有针对红外小目标做优化,即使有prompt引导,也无法精准区分小目标和背景噪声;而红外物理模型的引入,改变了SAM的建模逻辑,从直接分割目标转为背景估计+目标反解,是提升小目标检测能力的核心。
- 模块互补性分析:同时移除SR-CLIP和CG-SAM后,模型退化为原生CLIP+SAM基线,Fa升至12.37×10⁻⁶,是完整SAIST模型的14倍。这证明两个模块是强互补的:SR-CLIP负责提供精准的语义先验,CG-SAM负责实现精准的像素级分割,二者缺一不可。
(3)实验设计的局限性
- 数据集的局限性:MIRSTD数据集的文本描述均为GPT-4V生成,仅经过人工校验,没有大规模的人工标注,文本描述的多样性、准确性有限,导致模型在OOD场景下的泛化性不足;同时,数据集仅覆盖了天空、海面、地面3种常规场景,没有极端天气、强电磁干扰、超远距离成像等极端场景的样本。
- 对比实验的局限性:论文仅和单模态的IRSTD方法做了对比,没有和其他多模态小目标检测方法做对比(因为领域内没有相关工作),无法充分证明多模态方法的普适性;同时,仅在单帧IRSTD任务上做了验证,没有在序列IRSTD任务上测试,而实际工业场景中,序列红外检测是主流应用。
- 性能评估的局限性:论文仅评估了模型的检测性能,没有评估模型的鲁棒性,比如对噪声、模糊、亮度变化的抗干扰能力;同时,没有评估模型在边缘设备上的部署性能,比如模型量化、蒸馏后的精度损失,以及实时推理能力。
5. 局限性与未来研究方向
(1)论文方法的核心局限性
- 多模态依赖的固有缺陷:模型的性能高度依赖与图像匹配的文本描述,无法直接处理无文本标注的红外图像,零样本场景下的泛化性极差,无法直接应用于未知场景的红外检测任务。
- 计算开销过大:模型的总参数量达389.57M,推理时延0.081s/帧(约12FPS),远高于轻量化单模态CNN模型(可达100FPS以上),无法在FPGA、ARM等边缘红外设备上部署,限制了其工业落地能力。
- 物理模型的精度瓶颈:模型中的场景深度估计,是用ResNet做的像素级分类,而非精准的单目深度估计,导致透射系数的计算存在误差,影响目标反解的精度,对超小目标(<3×3像素)的检测效果有限。
- 域泛化能力不足:模型仅在同分布的3个常规数据集上做了训练和测试,没有验证跨传感器、跨场景、跨天气的域泛化能力,而实际工业场景中,红外传感器的型号、成像环境千差万别,域泛化能力是核心需求。
(2)未来研究方向
- 零样本/少样本多模态IRSTD:研究无需文本标注的自监督图文对齐方法,比如用红外图像的场景特征自动生成文本prompt,摆脱对文本标注的依赖,实现零样本场景下的泛化;同时,研究小样本微调方法,让模型在少量新场景样本下即可快速适配。
- 轻量化多模态IRSTD模型:针对边缘部署需求,对CLIP和SAM做模型蒸馏、量化、剪枝,设计轻量化的跨模态融合模块,同时结合知识蒸馏,将大模型的语义能力迁移到轻量化CNN模型中,实现边缘设备上的实时推理。
- 序列红外图像的多模态检测:将单帧的SAIST模型扩展到序列红外图像,结合时序信息和运动特征,进一步区分目标和静态背景杂波,降低虚警率;同时,研究时序-文本的多模态融合,利用场景的时序变化特征,提升模型的鲁棒性。
- 物理模型与深度学习的深度融合:构建更精准的红外辐射传输模型,结合大气衰减模型、传感器噪声模型,提升深度估计和目标反解的精度;同时,将物理模型作为可学习的网络层,嵌入到模型的端到端训练中,实现物理模型与深度学习的完全融合。
- 多模态IRSTD基准的完善:构建大规模、多场景、多传感器、人工标注的多模态IRSTD数据集,覆盖天空、海面、地面、极端天气等多种场景,完善数据集的评价基准,推动领域的多模态研究发展。
6. 隐藏难点与研究挑战
(1)论文中未明确提及的隐藏难点
- 红外图像的域适配预处理:论文中仅提到将红外图像resize到1024×1024,复制为三通道,但没有说明是否做了域适配预处理。原生CLIP对输入图像的分布极其敏感,直接复制的三通道红外图像,与自然RGB图像的均值、标准差、分布差异极大,会导致CLIP的特征提取完全失效,这是复现中的核心坑。工程实现中,必须用风格迁移模型(如CycleGAN)将红外图像转换为类RGB图像,或者用红外数据集的统计量重新做标准化,才能保证CLIP的特征提取有效。
- prompt模板的超参数优化:论文中仅提到了prompt的模板格式,但没有说明模板的具体用词、长度、场景分类方式。CLIP的文本编码器对prompt的用词、长度极其敏感,不同的模板会导致最终的性能差异超过10%,这是论文中没有提及的关键超参数。工程实现中,需要对prompt模板做大量的消融实验,优化模板的用词、长度、场景分类,才能达到论文中的效果。
- LoRA微调的超参数选择:论文中仅提到用LoRA微调SAM的图像编码器,但没有说明LoRA的微调位置、秩r、α等关键超参数。不同的超参数设置,会导致微调效果和过拟合风险差异极大:如果微调的层过多,极易过拟合;如果秩r过大,可训练参数量过多,训练成本极高;如果秩r过小,无法适配红外域的特征。工程实现中,仅微调注意力的Q/K矩阵,秩r=8,α=16,是最优的折中方案。
- 小目标的样本不平衡问题:红外小目标通常仅占图像的0.01%以下的像素,样本极度不平衡,传统的Dice损失、IoU损失无法有效学习目标特征。论文中没有提及损失函数的加权策略,这是复现中效果不达标的核心原因。工程实现中,必须对前景像素做10-20倍的权重加权,同时加入Focal Loss缓解样本不平衡问题,才能有效学习小目标的特征。
(2)潜在的研究空白
- 多模态IRSTD的域泛化问题:现有研究仅在同分布的数据集上做了验证,没有研究跨场景、跨传感器的域泛化问题,而这是实际工业应用中的核心痛点。如何让多模态模型在未知的传感器、未知的场景下,依然保持稳定的检测性能,是领域内的核心研究空白。
- 端到端的多模态IRSTD模型:现有的SAIST模型是两阶段的(SR-CLIP预训练+CG-SAM微调),不是端到端训练,图文两个模块无法联合优化,限制了模型的性能上限。如何设计端到端的图文联合优化框架,实现跨模态特征的端到端学习,是未来的重要研究方向。
- 红外小目标的语言语义建模:现有方法仅对场景背景做了文本描述,没有对红外小目标本身的物理特性、语义特征做语言建模,比如「红外小目标是高亮度、点状、无纹理的热辐射源,其辐射强度符合大气传输规律」。如何将红外小目标的物理先验、语义特征融入到语言模型中,进一步提升模型的检测能力,是尚未被探索的研究空白。
- 多模态融合的轻量化方法:现有大模型的多模态方法计算量过大,无法在边缘红外设备上部署,而领域内的轻量化研究,均集中在单模态CNN模型,没有针对多模态融合的轻量化方法。如何设计轻量化的跨模态融合模块,将大模型的语义能力迁移到边缘设备,是实现工业落地的核心研究方向。
全景总结
小白一句话总结
这篇论文给红外图像里找微小目标的任务,加了一个「场景文字提示」的帮手,就像找东西时有人给你念环境说明,能帮你在复杂背景里更快更准地找到目标,还大大减少了认错的情况。
硕士一句话总结
该论文首次将CLIP与SAM结合的图文多模态技术引入红外小目标检测任务,通过SR-CLIP模块实现红外域的图文特征对齐与精准prompt生成,再通过融合红外成像物理模型的CG-SAM模块实现目标-背景的精准分离,在多个公开数据集上取得了SOTA性能,大幅降低了检测虚警率。
博士一句话总结
该论文突破了传统红外小目标检测单模态图像驱动的范式瓶颈,首次构建了图文多模态的IRSTD基准框架与数据集,通过场景语义建模的跨模态对齐方法解决了大模型在红外域的迁移难题,同时将物理成像模型与大模型解码过程深度融合,为IRSTD领域提供了可解释、高性能的多模态研究新范式,也为其他低信噪比小目标检测任务的多模态大模型应用提供了重要参考。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)