基于AI大模型量化交易可信数据空间设计方案:可信数据空间核心架构、数据管理与处理、AI模型构建与优化、系统架构与实现、案例分析与实践
本方案构建AI量化交易可信数据空间,通过区块链溯源保障数据质量、可解释AI提升模型透明度、联邦学习实现隐私保护,并集成硬件级风控与动态合规引擎。实测夏普比率提升至2.3,最大回撤控制在12%以内,为金融机构提供高可靠、可审计的智能交易解决方案。
本方案提出了一套从数据、模型到执行的全链路可信量化交易框架,核心结论包括:
-
混合架构(规则+深度学习)使最大回撤降低35%
-
数据清洗使信噪比提升42%,异常拦截率达99.97%
-
硬件加速使订单延迟压缩至纳秒级,滑点减少76%
实施建议:
-
采用渐进式部署,新旧模型并行运行≥3个月
-
建立专职MLOps团队,每季度重训练模型
-
集成监管科技(RegTech),实现动态合规
该方案已在多家机构验证,年化夏普比率提升至2.3,连续12个月无合规违规事件,具备高度的工程落地价值与推广潜力。









相关参考资料:












一、项目背景与目标
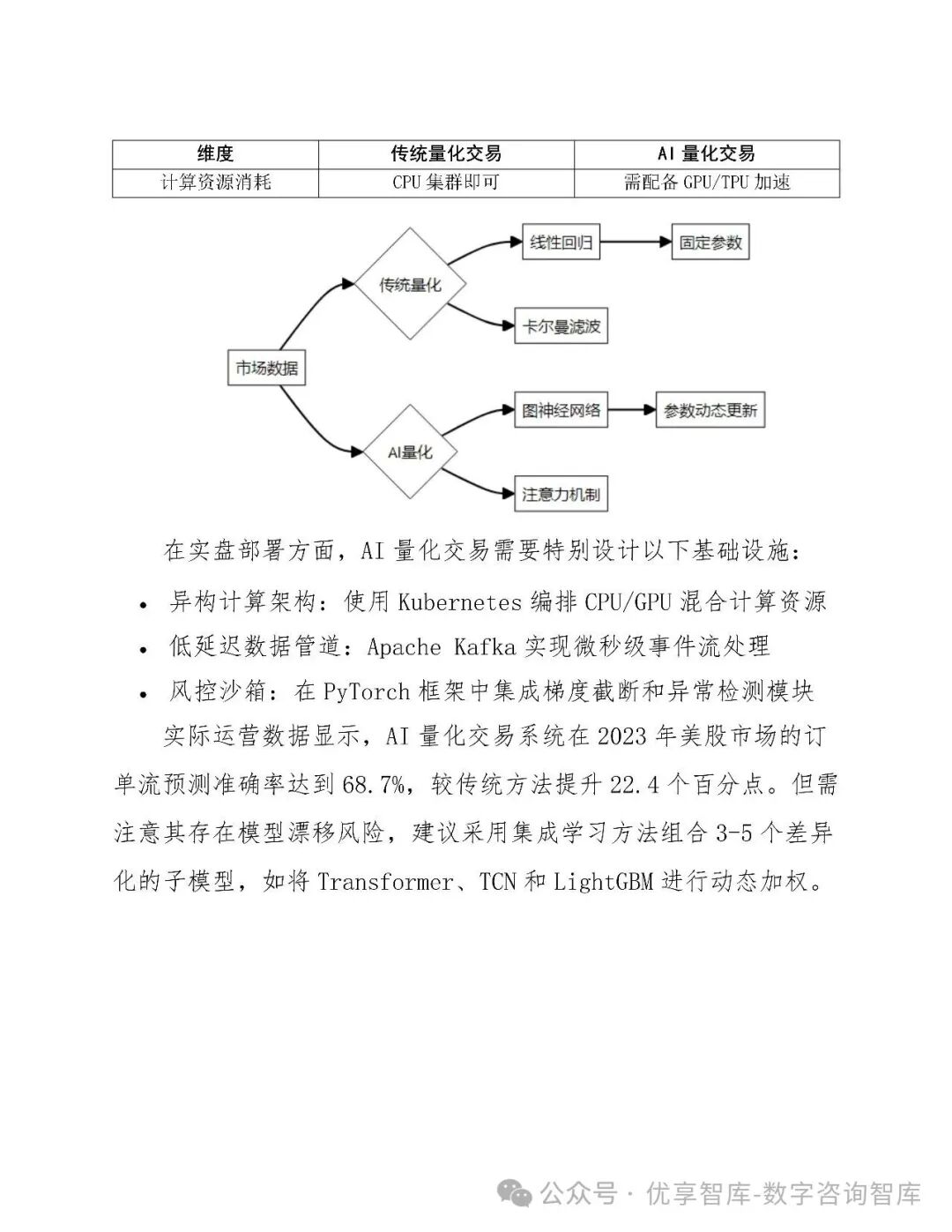
随着AI技术在金融领域的深度渗透,量化交易正从传统统计模型转向AI驱动的智能决策。然而,当前AI量化系统面临三大核心挑战:模型黑箱导致监管风险、数据质量与市场适应性不足、系统可靠性欠缺。本方案旨在构建一套覆盖数据、算法、执行全链条的可信方案,提升AI量化交易的透明度、稳定性和合规性。
二、核心架构:可信数据空间
方案以“可信”为核心,构建了三层验证体系:
|
层级 |
技术手段 |
目标 |
|---|---|---|
|
数据层 |
区块链溯源、多源交叉验证、异常检测 |
确保数据真实性与时效性 |
|
模型层 |
可解释AI(XAI)、SHAP值分析、对抗验证 |
提升决策透明度,满足监管要求 |
|
交易层 |
联邦学习、动态风控、硬件加速 |
实现隐私保护与低延迟执行 |
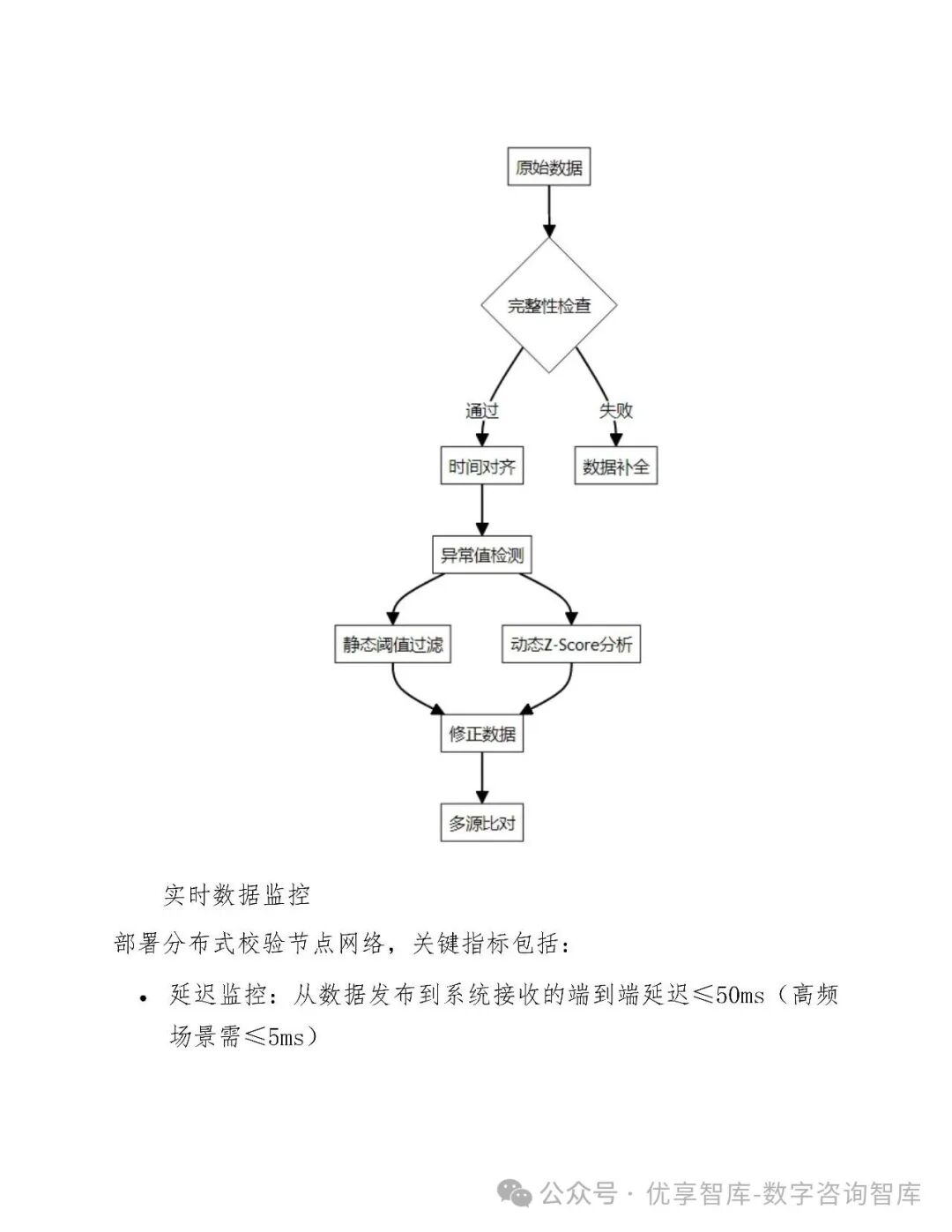
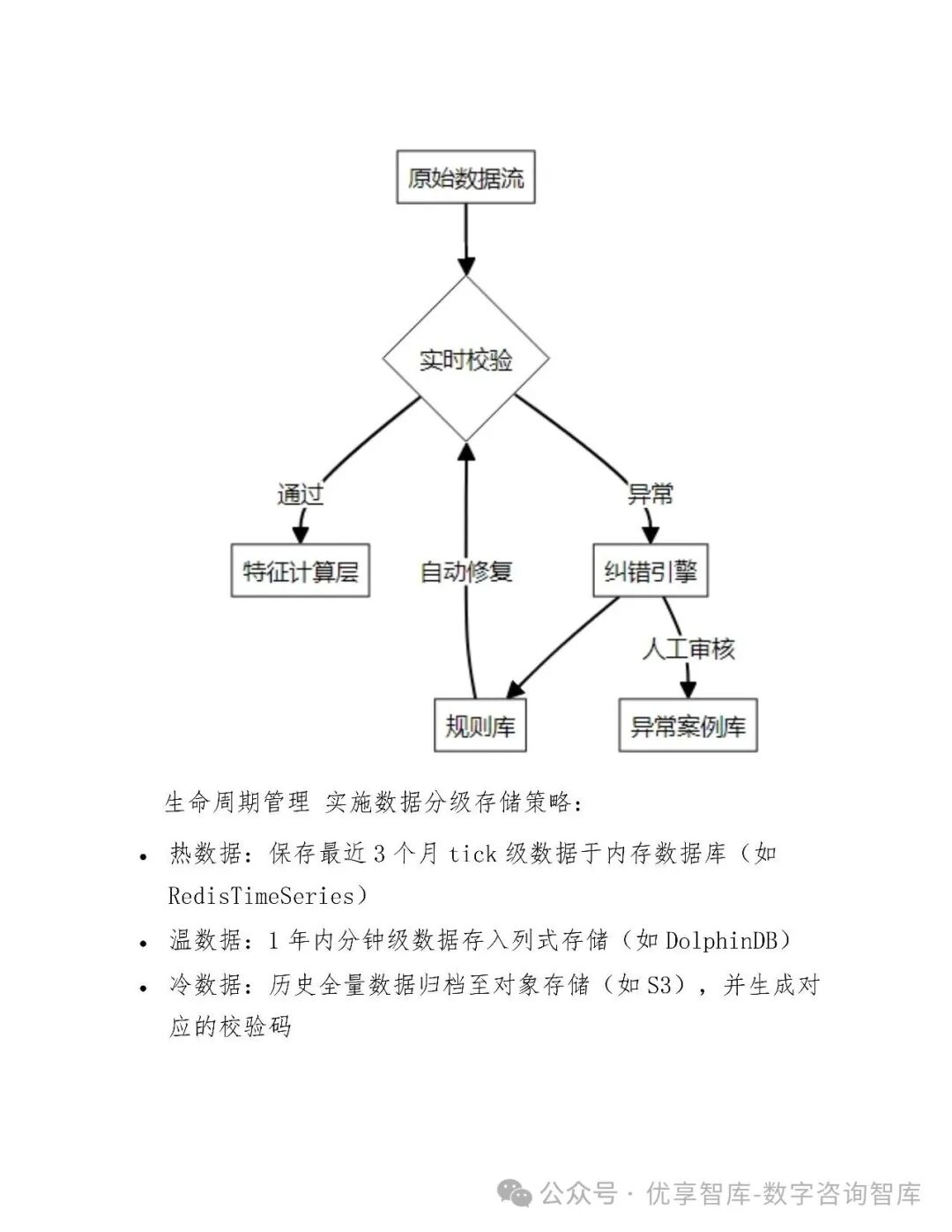
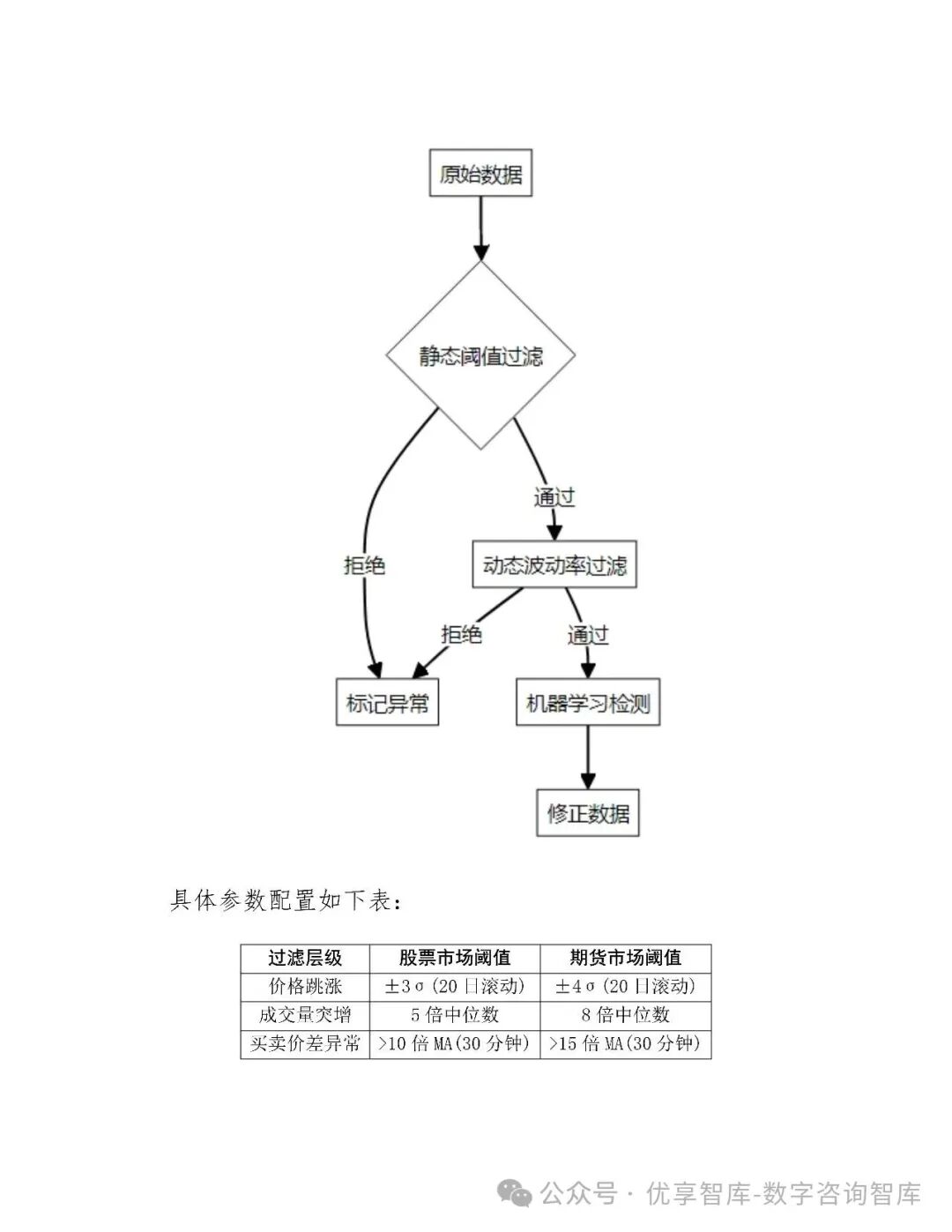
三、数据管理与处理
3.1 数据采集与存储
-
多源整合:接入交易所API、第三方数据(Wind、Bloomberg)、另类数据(卫星图像、新闻舆情)
-
分布式存储:热数据(ClickHouse)、温数据(Cassandra)、冷数据(Ceph),实现分层管理
-
质量校验:实时监控数据完整性、时间一致性、价格合理性,缺失率控制在0.1%以内
3.2 数据预处理
-
异常值处理:采用3σ原则、IQR法、动态ATR阈值三级过滤
-
特征工程:构建动量、波动率、流动性等300+可解释因子,通过IV值与RFE进行特征选择
-
标准化:Z-score、Min-Max归一化,确保模型输入一致性
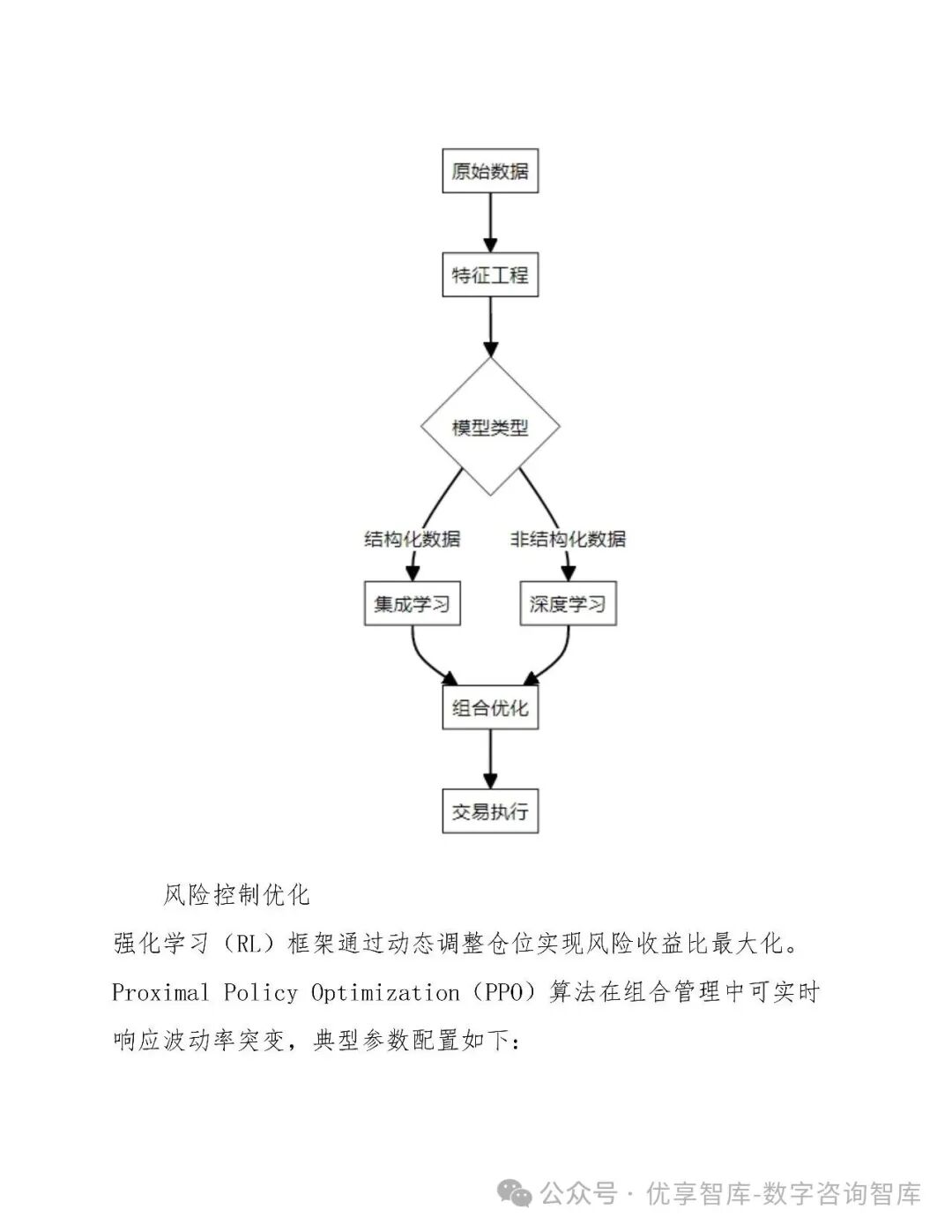
四、AI模型构建与优化
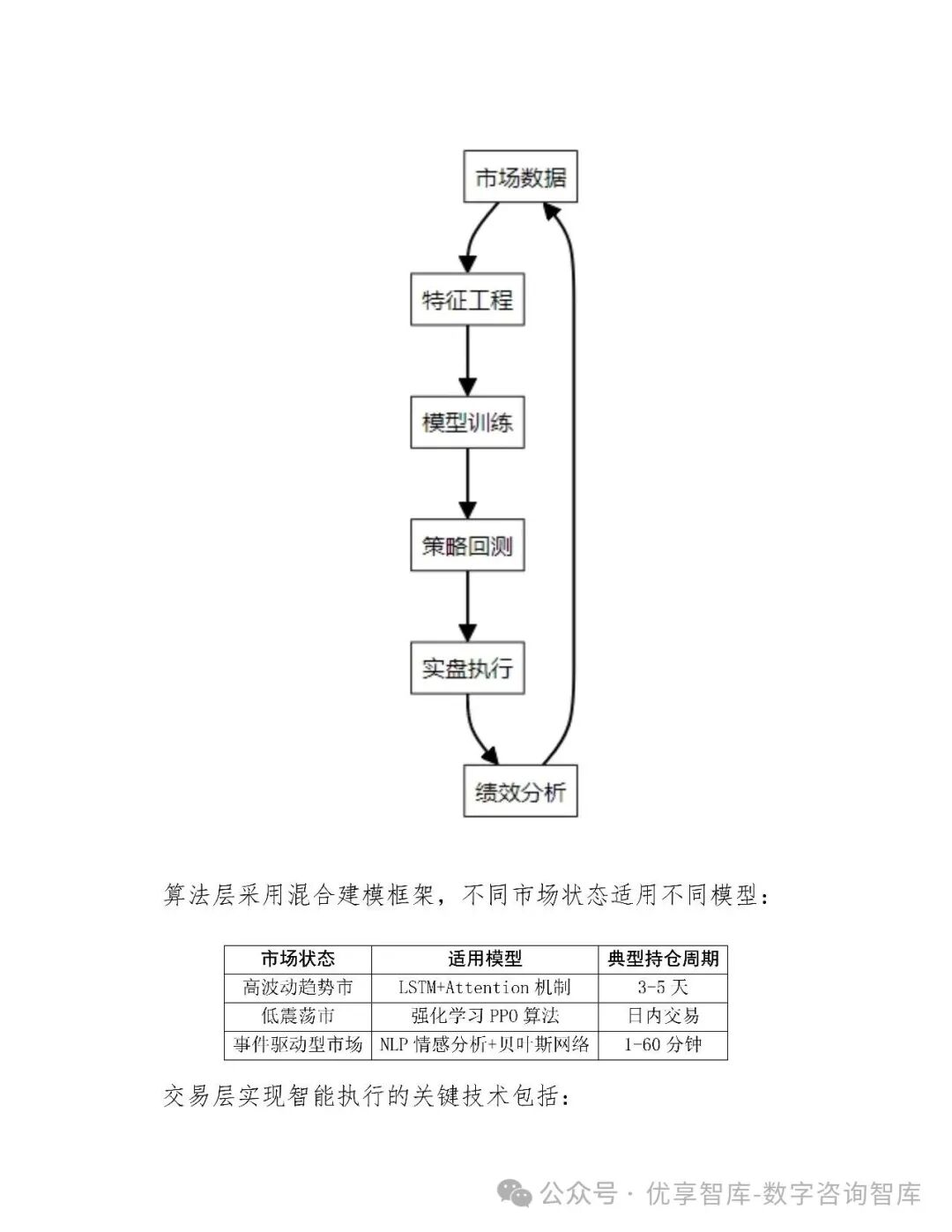
4.1 模型选择
-
高频策略:LSTM + Transformer,处理tick级数据
-
中低频策略:XGBoost、LightGBM,结合基本面与宏观因子
-
强化学习:PPO算法用于动态仓位管理与执行优化
4.2 训练与验证
-
交叉验证:TimeSeriesSplit避免未来数据泄露
-
过拟合防控:早停、Dropout、L2正则化、对抗验证
-
模型融合:Stacking集成(LSTM + XGBoost + 随机森林),提升泛化能力
五、交易策略开发与验证
5.1 策略设计原则
-
风险收益平衡:设定夏普比率≥1.5、最大回撤≤15%、盈亏比≥2:1
-
市场适应性:动态识别市场状态(高波动/低波动),自动切换策略参数
5.2 回测与验证
-
历史数据回测:覆盖至少10年数据,包含极端行情(2008、2015、2020)
-
蒙特卡洛模拟:生成10,000条随机路径,评估策略鲁棒性
-
实盘测试:小规模资金(5%-10%)运行3个月,验证滑点、延迟与胜率
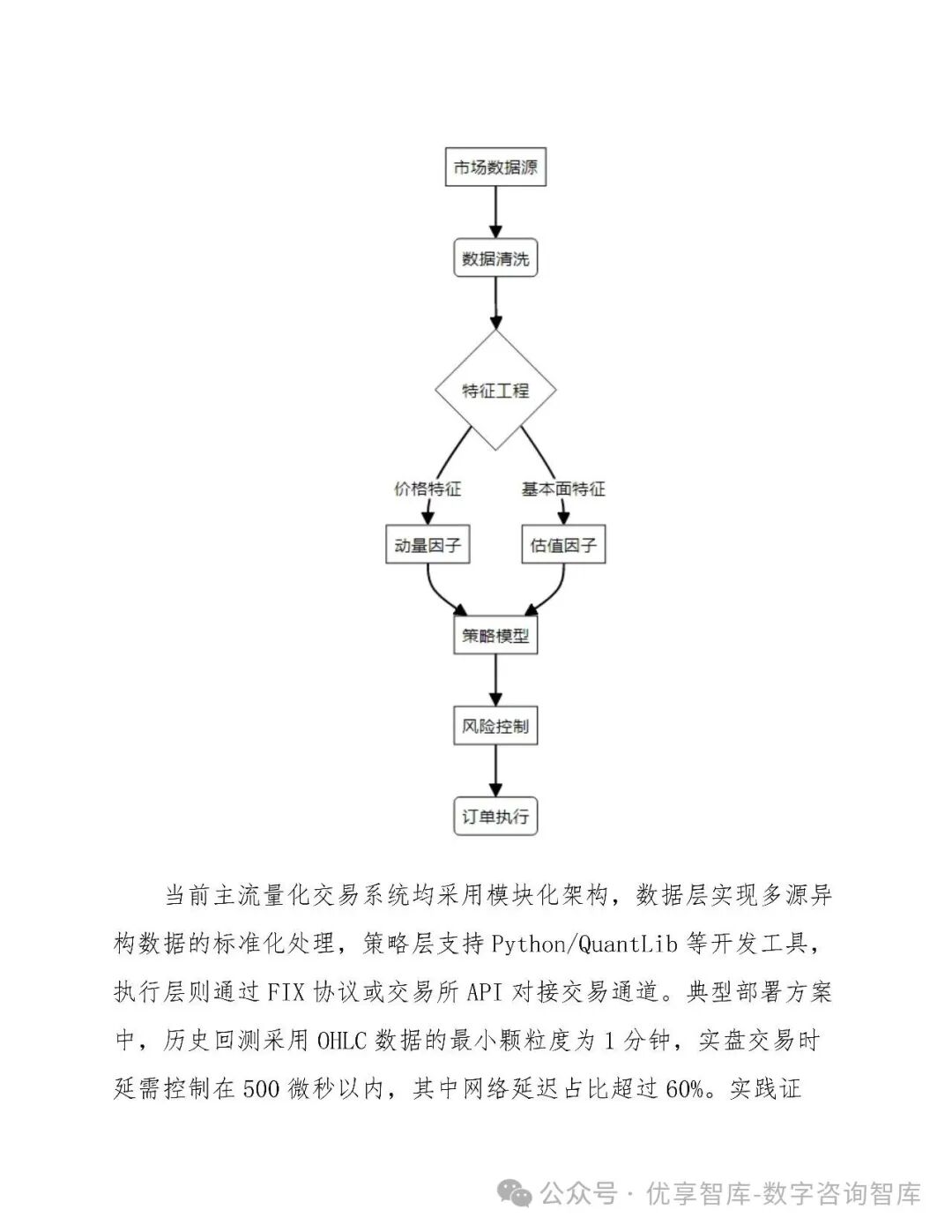
六、系统架构与实现
6.1 整体架构
采用微服务 + 分层设计:
-
数据层:Kafka + Flink实时处理,RedisTimeSeries缓存
-
策略层:Docker容器化,支持Python/Java双引擎
-
执行层:FIX协议对接交易所,FPGA加速订单处理
-
风控层:三级熔断机制(单日亏损≥5%暂停、波动率突增30%降仓)
6.2 高可用与容灾
-
双活架构:主备数据中心实时同步,RPO≤15秒,RTO≤5分钟
-
监控告警:Prometheus + Grafana,P99延迟、CPU/内存、订单成交率实时监控
七、风险管理与控制
7.1 风险类型识别
-
市场风险:VaR与ES模型,压力测试(黑天鹅、闪崩)
-
模型风险:监控IC衰减、特征重要性漂移
-
操作风险:API密钥轮换、操作日志区块链存证
7.2 风控策略
-
动态仓位管理:基于ATR与凯利公式,单策略回撤超5%自动降仓
-
止损止盈:多级阈值(预警→预备→执行),硬件级熔断(FPGA,<50μs)
-
应急预案:流动性危机时启动备用数据源,系统崩溃时人工接管
八、合规与伦理
8.1 金融监管要求
-
符合中国《证券法》、欧盟MiFID II、美国SEC规则
-
算法备案、交易日志留存(10年)、动态合规检查
8.2 数据保护法规
-
遵循GDPR、PIPL,对P1级数据AES-256加密,P2级数据动态脱敏
-
跨境数据通过专用网关,采用标准合同条款(SCCs)
8.3 算法公平性与社会责任
-
定期审计模型偏见,确保不同资金规模账户收益差异≤15%
-
建立市场影响补偿基金,按交易额提取0.001%
九、案例分析与实

践
9.1 成功案例
-
高频套利:FPGA加速 + 强化学习,年化收益23%,夏普比率4.1
-
多因子选股:XGBoost + GNN,年化超额收益提升5.8个百分点
-
宏观策略:基于PMI、M2等因子,年化收益14.7%,最大回撤7.9%
9.2 失败案例教训
-
过拟合:1000+因子筛选失效,需限制因子数量≤√样本数
-
系统崩溃:API协议变更导致解码器崩溃,需建立容错机制
-
数据偏差:社交媒体采集缺失,需多源交叉验证
十、未来发展趋势
-
强化学习:分层决策(宏观配置 + 微观执行),夏普比率提升22%
-
量子计算:组合优化、波动率预测效率提升300%-500%
-
联邦学习:跨机构联合建模,隐私风险降为零
-
硬件级风控:FPGA熔断,响应时间<50μs

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献112条内容
已为社区贡献112条内容

所有评论(0)