ElastixAI 携 FPGA 方案打造新一代人工智能超级计算技术,打破神秘面纱
近年来,大模型训练几乎完全依赖 GPU,但随着生成式 AI 应用的爆发,一个新的问题逐渐显现:
-
大模型推理(Inference)与 GPU 架构并不完全匹配。
美国 AI 硬件初创公司 ElastixAI 提出了一种不同思路:
利用 FPGA 构建专门面向 LLM 推理的数据中心基础设施。
该方案通过 软件、机器学习和硬件协同设计(software-ML-hardware co-design),将标准 FPGA 服务器转化为高效率 AI 推理引擎。

几周前,总部位于西雅图的人工智能硬件初创公司ElastixAI正式亮相。该公司由前苹果和 Meta 机器学习工程师创立,推出了一款基于 FPGA 的推理平台。该公司声称,与基于 Nvidia GPU 的部署相比,该平台在大型语言模型推理方面可降低高达 50 倍的总拥有成本和 80% 的功耗。
该公司于 2025 年 5 月完成了由 Fuse VC 领投的 1800 万美元种子轮融资,其 Elastix Rack 产品定位为 GPU 服务器基础设施的即插即用替代品,计划于 2026 年年中首次出货。
在发布会之前,All About Circuits采访了联合创始人Mohammad Rastegari(首席执行官)、Saman Naderiparizi(首席技术官)和Mahyar Najibi(首席战略官),向其阐述了 FPGA 比 GPU 更适合 LLM 推理的技术原因,以及他们为什么认为时机成熟。
人工智能训练与人工智能推理
他们的核心论点是,GPU 的设计初衷是处理计算密集型工作负载,例如 LLM 训练。但当处理内存密集型工作负载(例如 LLM 推理)时,GPU 的效率会降低,计算利用率也会大幅下降。“训练严重依赖计算,而推理严重依赖内存,”Rastegari 说。这种不匹配导致推理过程中 GPU 的计算利用率很低。
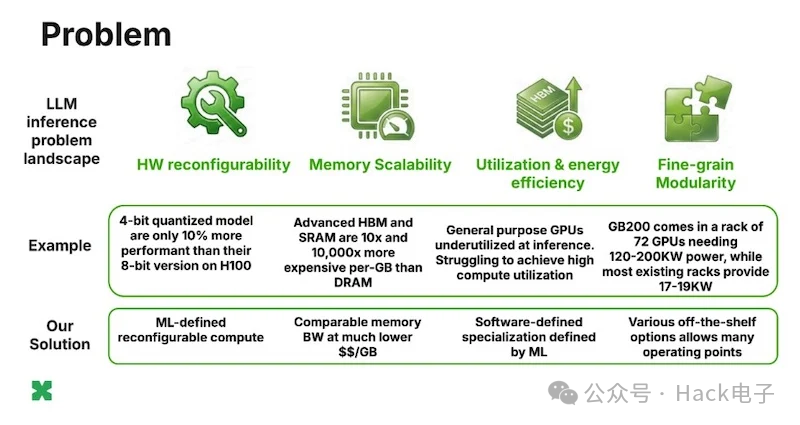
硬件的不灵活性加剧了这个问题:4 位量化理论上可以使吞吐量翻倍,但 Rastegari 指出,在像 H100 这样缺乏原生支持的硬件上,运营商“不得不围绕它构建一个软件内核,而这个内核只能利用其 10% 的潜力”。
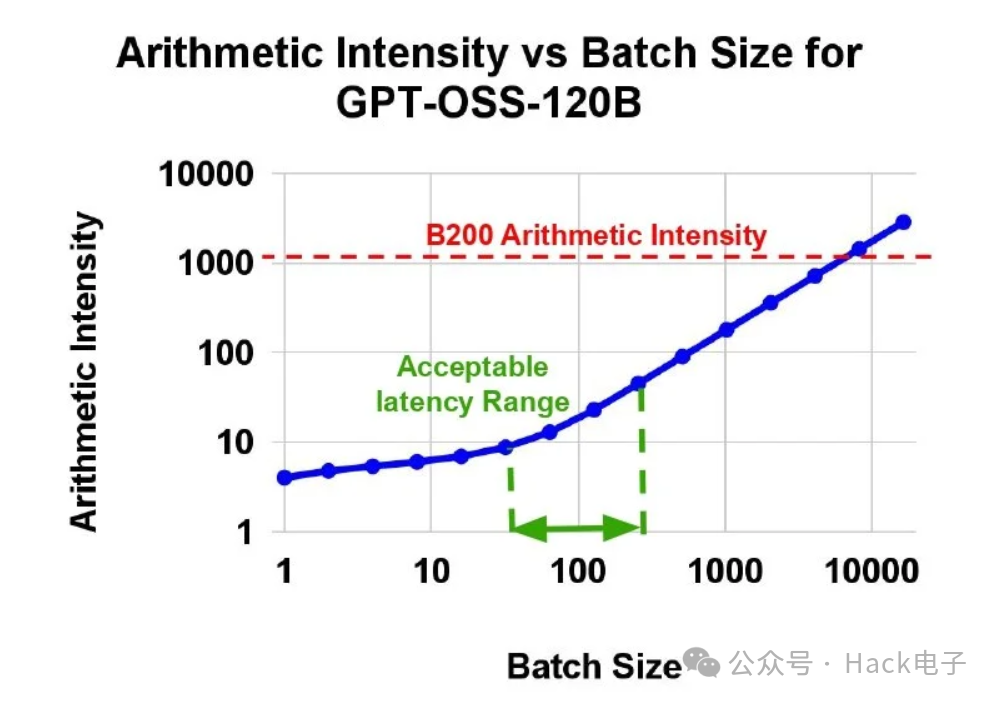 MoE 模型推理的典型批次大小需要 <100 的算术强度,导致 B200 上的计算利用率极低。
MoE 模型推理的典型批次大小需要 <100 的算术强度,导致 B200 上的计算利用率极低。
顶级加速器依赖于速度快、价格昂贵的内存,而 ElastixAI 则专注于真正影响总体拥有成本 (TCO) 的指标:每带宽成本和每容量成本。通过利用机器学习定义的软件专用化,ElastixAI 能够从运行在商用现成 FPGA 服务器上的低成本硬件(例如,先进的 DDR 和 HBM)中榨取最大性能。据该团队称,这种方法能够以远低于业界顶级内存的每 GB 成本,提供高性能推理所需的内存带宽。
ElastixAI 不将硬件视为固定约束,而是采用以 AI 优化为先的整体方法,将硬件视为软件的可重构扩展。自动化流程包括:
-
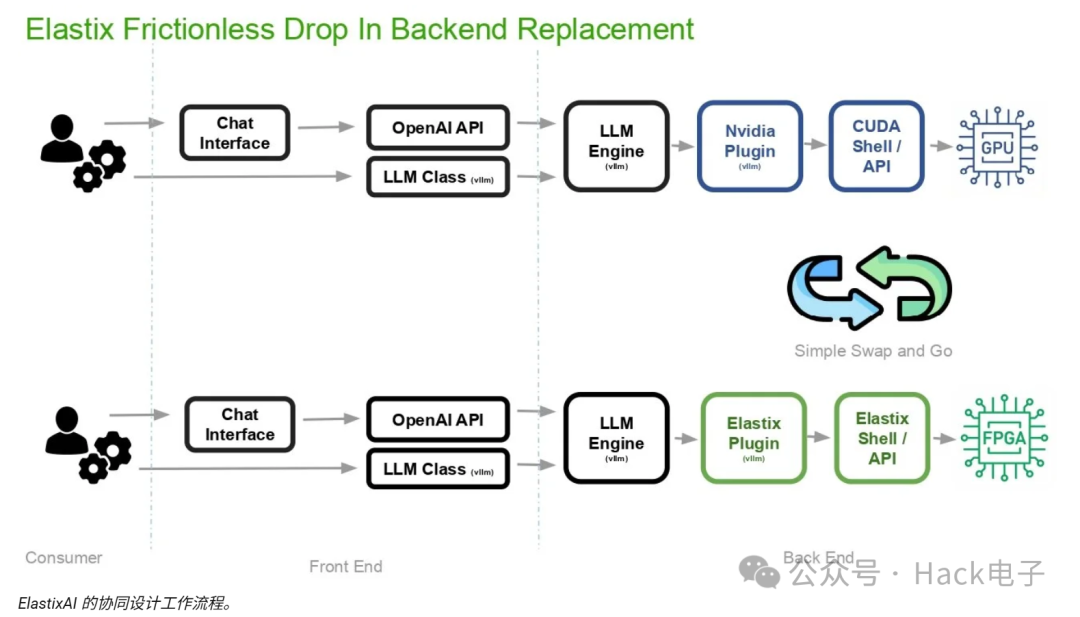
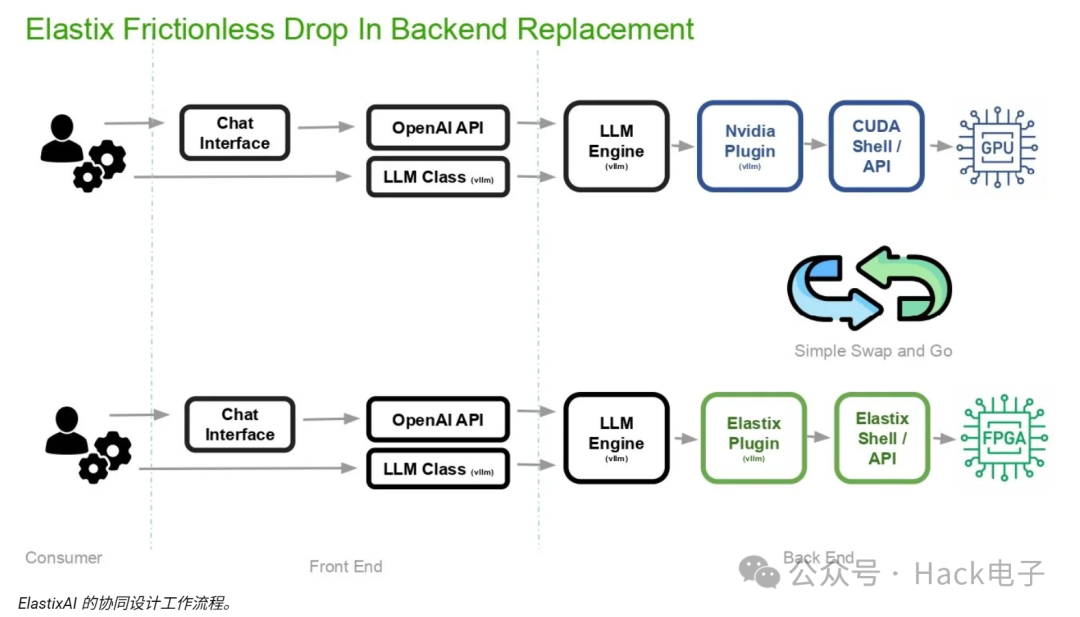
前端透明化:开发者可以使用现有的标准途径(例如 OpenAI API、vLLM LLM 类以及 PyTorch 等常用框架)与ElastixAI 的系统进行交互。这意味着无需更改现有应用程序逻辑或代码即可访问专用硬件。
-
即插即用的后端逻辑:该基础设施可直接替换现有的 GPU 后端,用ElastixAI 的 Elastix 插件和 Elastix Shell/API 取代传统的 NVIDIA 插件和 CUDA Shell/API。自动化系统能够透明地将神经网络计算路由到 FPGA 而非 GPU,同时保持基础设施团队的工作流程不变。
通过将最先进的FPGA与专有的机器学习优化技术相结合,与基于标准GPU的解决方案相比,每个GB的总拥有成本 (TCO) 可降低5-50倍。这一优势源于更低的资本支出(FPGA比高端B200或H100卡便宜得多)和更低的运营支出(由于更高的计算利用率和更低80%的功耗)。
为什么选择FPGA而不是定制芯片
FPGA 相较于定制芯片的优势在于机器学习的发展速度远超芯片开发周期。Rastegari 是 Xnor.ai 的联合创始人,该公司于 2020 年被苹果以约 2 亿美元收购。Rastegari 后来领导了 Meta 的 Llama 405B 模型的推理优化工作。他指出,混合专家模型( Mixture-of-Experts)就是一个此前存在风险的例证。
“当时许多公司都在筹集资金,准备基于现有技术开发芯片,但随后混合专家算法出现了。”他说道,“突然之间,这些公司不得不重新设计芯片以支持混合专家算法,而这种算法在他们最初的设计过程中并不存在。”问题显而易见。定制芯片从设计到生产需要三年多的时间;而机器学习领域的快速发展可能在短短几个月内就彻底改变这一进程。
推理吞吐量需求也印证了这一点。Rastegari 加入 Meta 时,每秒 20 个词元足以满足语音交互的需求。“但对于推理而言,你需要更快地在后台生成词元;现在需要每秒 200 个词元。” 随着这些需求的变化,FPGA 可以进行重新配置。
“通用性和效率之间存在着根本性的权衡。一旦你想要更通用,就会降低效率,因为你必须增加额外的硅片来覆盖许多不同的工作负载。”
Rastegari认为,Transformer架构目前在结构上足够稳定,可以进行FPGA实现,而底层优化层仍在快速发展,因此锁定固定的芯片设计仍然存在风险。关于最终是否会流片定制芯片的问题,他谨慎地表示:“决定我们何时以及是否流片芯片的,实际上取决于机器学习改进的速度。”
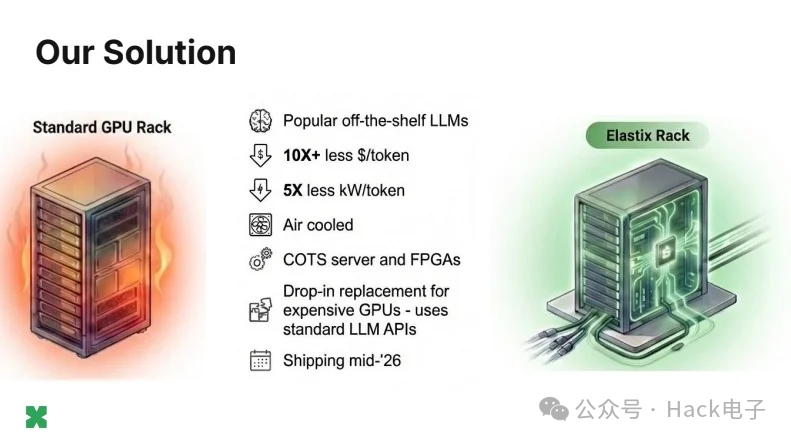 与标准的 GPU 机架式 AI 计算实现方案相比,ElastixAI 的方法具有几个关键优势。
与标准的 GPU 机架式 AI 计算实现方案相比,ElastixAI 的方法具有几个关键优势。
功率、成本和机架兼容性
Naderiparizi 谨慎地对主要性能数据进行了限定。他表示:“根据我们采用的令牌速率,与英伟达 B200 相比,我们可以在成本方面实现 10 倍甚至 50 倍的性能提升。”他指出,这一范围反映了目标用户不同的“每用户延迟”(或者说每秒每用户令牌数)。
这些数据涵盖了整个数据中心部署的资本支出和运营支出,并通过与FPGA制造商和数据中心运营商的合作验证。在功耗方面,Naderiparizi表示,在相同吞吐量下,每个令牌的功耗降低了五倍。
Elastix 机架符合标准的 17-19 kW 机架功率范围,并采用空气冷却,而 Nvidia 的 GB200 NVL72 需要 120 kW 至 200 kW 的功率以及大多数现有数据中心无法支持的专用液冷基础设施。
原生支持新型优化
业界才刚刚开始探索机器学习优化的潜力,但许多最有前景的技术仍然无法得到传统硬件的支持。ASIC 和 GPU 通过施加严格的限制,有效地冻结了硬件设计,阻碍了机器学习的发展。正因如此,业界领先的研究人员一再呼吁采用新的硬件方法来支持新兴的突破性技术:
苹果公司的研究人员指出,传统 GPU 对运行低比特率的压缩模型支持不佳。
鉴于 BitNet 带来的全新计算范式,微软研究院已发出行动号召,要求设计专门针对 1 位 LLM 优化的新硬件和系统。
谷歌研究表明,在缺乏硬件灵活性的情况下,研究人员被迫将硬件视为需要克服的“沉没成本”,而不是可以根据模型需要进行调整的灵活事物。
将一项优化原生集成到硬件中所带来的影响,在英伟达从 Hopper (H200) 架构到 Blackwell (B200) 架构的飞跃中体现得淋漓尽致。Blackwell 架构成本效益(每Tokens总拥有成本)提升的主要驱动力不仅在于芯片规模的扩大,更在于其原生硬件对 4 位量化的支持。
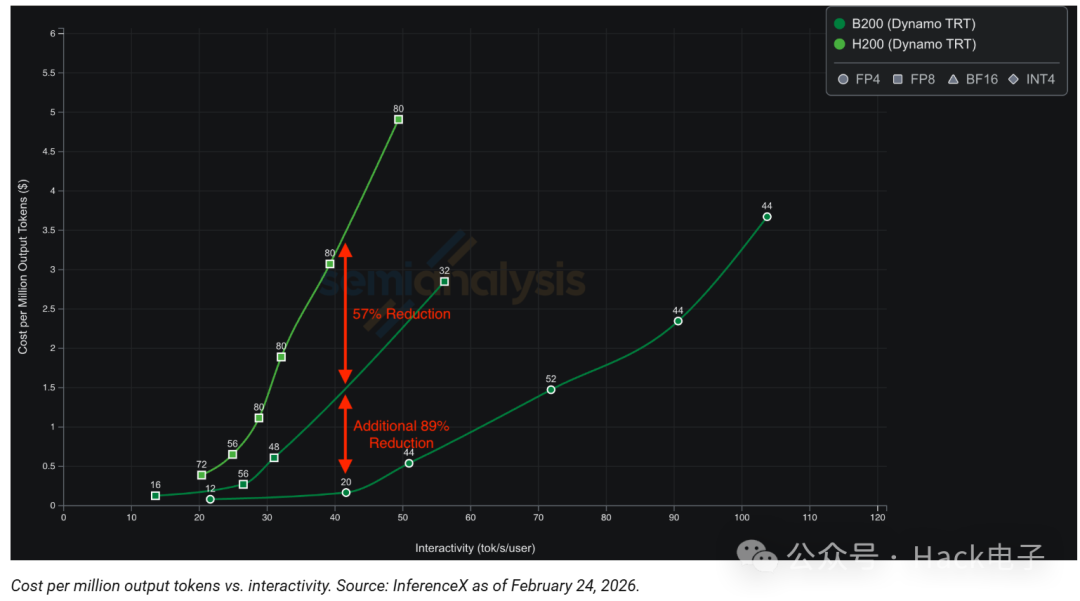
截至 2026 年 2 月 24 日, SemiAnalysis 的 InferenceX 数据显示,对于像 DeepSeek-R1 这样的模型,交互速度为 41.6 个Tokens/秒/用户,过渡到原生 4 位支持从根本上改变了经济方程式。

通过将一项已有数年历史的机器学习优化技术原生集成到硬件中,实现了成本效益的显著提升。采用基于 FPGA 的方法,无需等待下一代芯片即可获得这些优势。相反,只需简单的软件更新,即可在几天内实现这些甚至更高级的优化。
直接替换
集成是通过 vLLM 插件实现的,该插件替换了 Nvidia CUDA 后端,同时保持前端 OpenAI 兼容 API 不变,因此从 GPU 基础架构迁移的运营商无需修改其应用程序堆栈。
ElastixAI计划最终向机器学习研究人员开放其模型转换工具——Naderiparizi明确地将这一策略与Nvidia构建CUDA生态系统的方式进行了比较。“起初,Nvidia免费向研究人员发布其软件。但问题在于,CUDA是为Nvidia服务的——人们为CUDA框架开发的任何东西都会对Nvidia有所帮助。” ElastixAI计划围绕其自身平台构建同样的开发者良性循环。
创始团队成员还包括纳吉比 (Najibi),他曾为苹果智能团队做出贡献,此前还担任过 Waymo 的首席科学家。公司董事会成员之一是乔恩·格尔西(Jon Gelsey ),他曾担任 Xnor.ai 的首席执行官,也是 Auth0 的创始首席执行官,Auth0 后来被 Okta 以 65 亿美元收购。格尔西目前担任 ElastixAI 的战略和市场营销主管。
ElastixAI 目前仅面向部分企业合作伙伴和数据中心运营商开放,硬件出货预计将于 2026 年年中开始。
参考链接
https://www.allaboutcircuits.com/news/elastixai-emerges-from-stealth-with-fpga-approach-to-gen-ai-supercomputing/
https://www.elastix.ai/blog/five-reasons-why-fpgas-hit-the-sweet-spot-for-llm-inference-jk2ds
https://www.elastix.ai/blog/five-reasons-why-fpgas-hit-the-sweet-spot-for-llm-inference
总结
FPGA 的优势在于:
-
可重构架构
-
高能效推理
-
硬件与模型协同设计
随着 LLM 推理需求快速增长,FPGA 可能成为 GPU 与 ASIC 之间的重要折中方案。
ElastixAI 提出的 FPGA 推理平台并不是简单的硬件替代,而是一种新的计算思路:
ML-defined computing
其核心思想包括:
-
软件-ML-硬件协同设计
-
FPGA 可重构推理架构
-
面向数据流的 LLM 加速
通过这种方式,可以构建更灵活、更高能效的大模型推理基础设施。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)