程序员小白必看:轻松入门大模型,开启AI 2.0学习之旅
本文介绍了RAG(检索增强生成)系统如何通过外部知识增强大模型的理解和回答能力。概述了大模型的发展历程、关键进展及分类,深入解析了Transformer模型原理及其在大语言模型中的应用。针对RAG场景,文章详细探讨了如何选择合适的大模型,包括考虑开源与闭源、模型参数规模、国内与国外部署等因素,并结合SuperCLUE测评基准提供选型参考。最后,文章对比分析了闭源与开源大模型的优缺点,推荐了Qwen、Baichuan和ChatGLM等开源系列模型。
一、前提
- RAG 的本质是通过为大模型提供外部知识来增强其理解和回答领域问题的能力,类似于为大语言模型配备插件,使其能够结合外部知识作出更为精准和符合上下文的回答。大模型在 RAG 系统中起到大脑中枢的作用,尤其在面对复杂且多样化的 RAG 任务时,大模型的性能直接决定了整个系统的效果和响应质量,可以说大模型是整个系统的大脑。
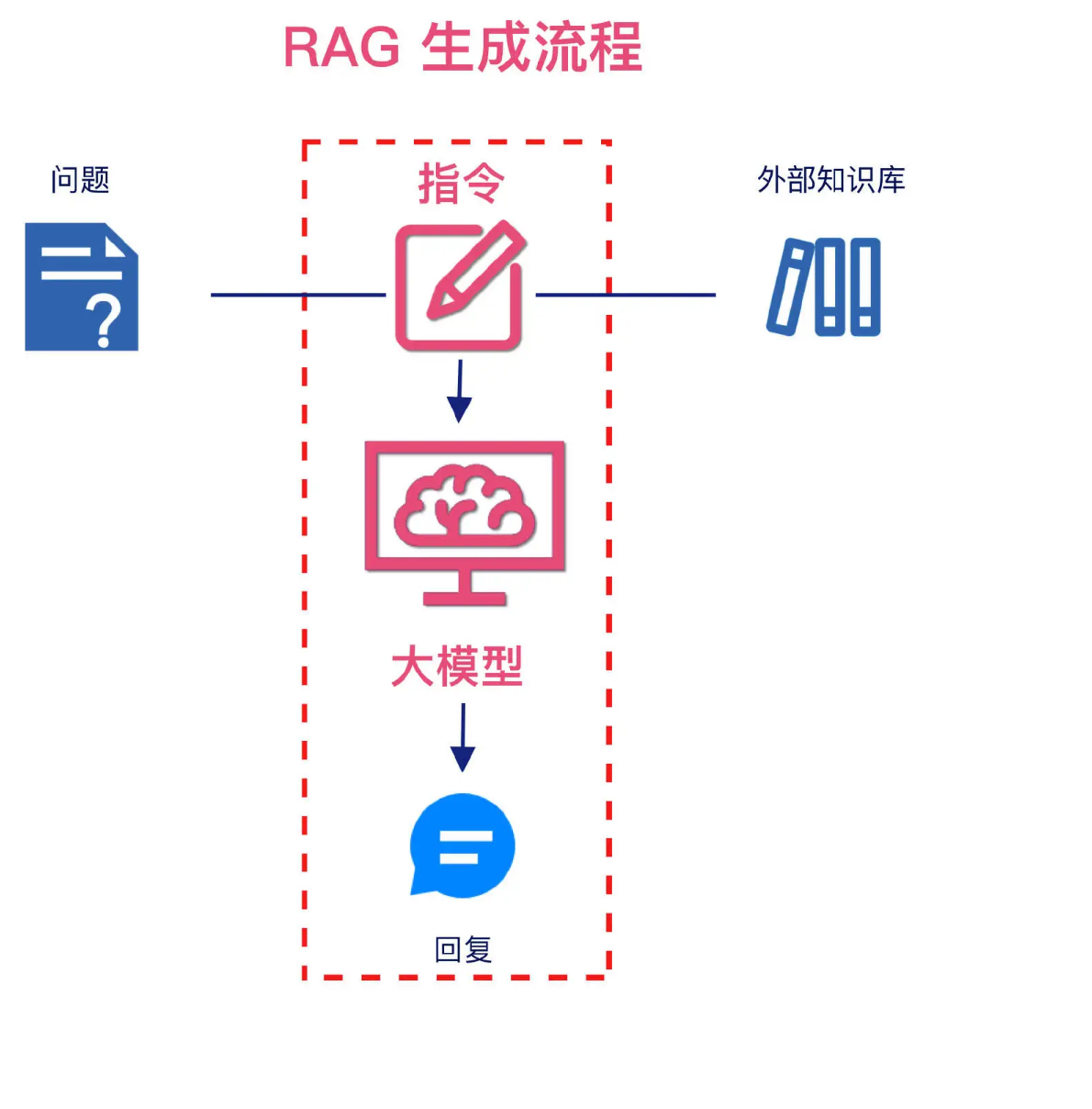
- 如下图所示,经过 RAG 索引流程外部知识的解析及向量化,RAG 检索流程语义相似性的匹配及混合检索,系统进入 RAG 生成流程。生成流程中,首先需要组合指令,指令将携带查询问题及检索到的相关信息输入到大模型中,由大模型理解并生成最终的回复,从而完成整个应用过程。
二·、大模型发展
- 自 2022 年 OpenAI 公司发布 ChatGPT 以来,AI 2.0 时代 “Scaling Law” 大模型技术范式在全球范围内引发了人工智能学术与产业热潮。
- 根据中文大模型综合性测评基准 SuperCLUE 组织发布的 2024 年 8 月报告阐述,AI 大模型 2023-2024 年关键进展大致可以分为四个阶段。
准备期:ChatGPT 发布后国内产学研迅速形成大模型共识
成长期:国内大模型数量和质量开始逐渐增长
爆发期:各行各业开源闭源大模型层出不穷,形成百模大战的竞争态势
繁荣期:更多模态能力的延伸和应用

- 在 OpenAI 公司领衔的 GPT 系列及 Sora 的推动下,全球 AI 大模型技术进入了快速发展的新阶段。国内各大模型同步迅速跟进,市场从活跃到爆发,企业纷纷加大研发投入,推动了大模型技术从学术研究走向实际应用。在不到两年的时间里,新技术和新产品的迅速涌现,带来了行业的深度变革,标志着 AI 2.0 时代的加速到来。
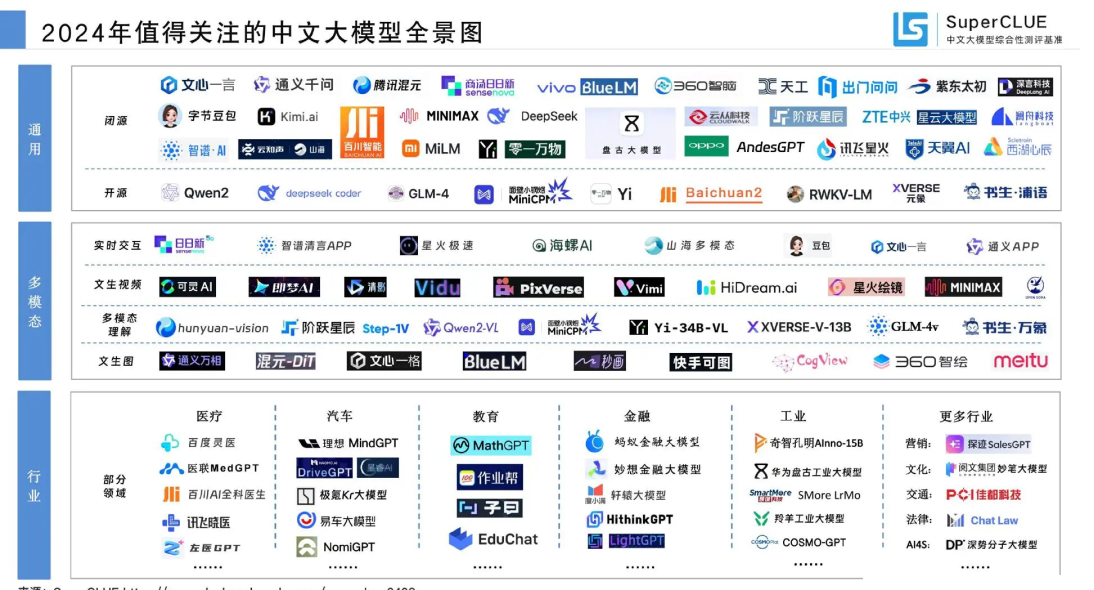
- 同时 SuperCLUE 组织也发布了中文大模型全景图,展示了 2024 年值得关注的中文大模型,从通用、多模态、行业三个层面进行了详细分类,各领域的大模型应用层出不穷。RAG 中目前更关注通用大模型,比如闭源的文心一言、通义千问、腾讯混元、字节豆包、Kimi Chat 等都是可选择的大模型组件,如果需要私有化部署,Qwen 系列、GLM 系列、Baichuan 系列都在可考虑范围。
三、大模型原理
- 一切始于 Google 在 2017 年发表的论文 《Attention Is All You Need》,论文访问地址为https://arxiv.org/pdf/1706.03762 ,引入了 Transformer 模型,它是深度学习领域的一个突破性架构,大型语言模型的成功得益于对 Transformer 模型的应用。
- 与传统的循环神经网络(RNN)相比,Transformer 模型不依赖于序列顺序,而是通过自注意力(Self-Attention)机制来捕捉序列中各元素之间的关系。Transformer 由多个堆叠的编码层(Encoder)和解码层(Decoder)组成,每一层包括自注意力层、前馈层和归一化层。这些层协同工作,逐步捕捉输入数据信息特征,从而预测输出,实现强大的语言理解和生成能力。
- Transformer 模型的核心创新在于位置编码和自注意力机制。位置编码帮助模型理解输入数据的顺序信息,而自注意力机制则允许模型根据输入的全局上下文,为每个词元分配不同的注意力权重,从而更准确地理解词与词之间的关联性。这种机制使得 Transformer 特别适用于语言模型,因为语言模型需要精确捕捉上下文中的细微差别,生成符合语义逻辑的文本。
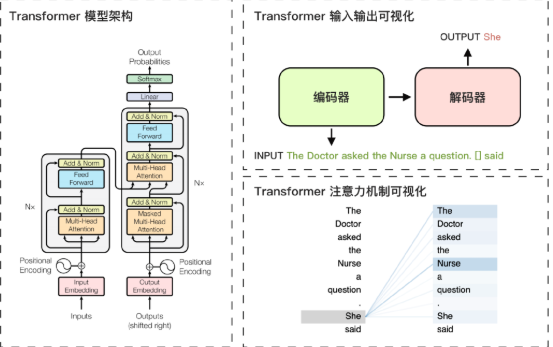
- 上图展示了 Transformer 模型的架构及其核心机制的可视化示例。左图中,Transformer 模型由编码器和解码器两部分组成。编码器负责理解输入信息的顺序和语义,解码器则输出概率最高的词元。
- 右上图中的示例显示了输入句子中的填空任务,解码器依据输入句子的特征和已生成的部分句子,生成了“She”作为模型的预测结果。生成“She”的核心原因在于右下图所示的注意力机制,其中需要填空的部分对输入句子中的词元“The Doctor”和“Nurse”分配了较高的注意力权重,从而提高了“She”作为输出词元的生成概率。
- 大语言模型的突破始于 2022 年年底 OpenAI 发布的 ChatGPT。其核心优势体现在庞大的参数规模(数百亿甚至数千亿)、基于 PB 级别数据的训练所带来的卓越语言理解与生成能力,以及其显著的涌现能力。大语言模型不仅在传统的自然语言处理任务中展现了卓越表现,还具备了解决复杂问题和进行逻辑推理等高级认知能力。
- 基于 Transformer 模型通过预测下一个词元的原理,大语言模型在分析了海量的语料库后,能够在逻辑上精准补全不完整的句子,甚至生成新的句子。这一推理模式赋予了大语言模型生成连贯且上下文相关文本的能力,使其在文本生成、翻译、问答系统等多个领域得到广泛应用。
四·、RAG 中如何选择大模型
- 在如今大模型层出不穷的情况下,如何在 RAG 应用场景中选择合适的模型呢?我们面对的是开源与闭源的选择、大参数与小参数的对比,成本的考虑以及云端与私有化部署的抉择。针对这些问题,我们需要结合测评和具体的应用场景进行综合考量。
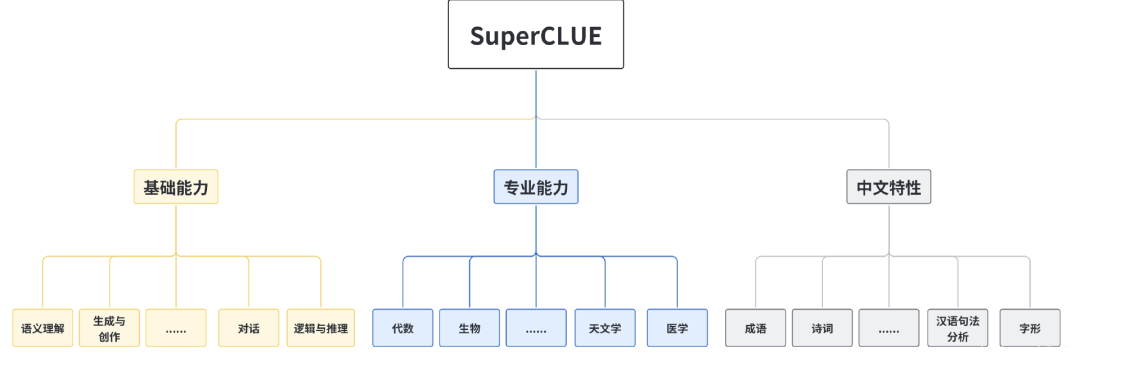
- 从测评角度来看,前面已经介绍了中文通用大模型的综合性测评基准 SuperCLUE,SuperCLUE的访问地址为https://www.cluebenchmarks.com/static/superclue.html,它对中文场景中的多个任务分支进行测试,涵盖基础能力、专业能力以及中文特性多个方面。每个任务分支又包含多个维度,例如语义理解、生成与创作、代数、生物、成语、诗词等。下图展示了这些维度的具体内容,SuperCLUE 每月都会更新测评结果,确保其反映大模型的最新表现。
- 尤其需要关注的是 SuperCLUE-RAG 检索增强生成测评 SuperCLUE中文大模型测评基准-AI评测榜单,在 RAG 场景中,大模型的检索能力表现是核心。SuperCLUE 针对 RAG 应用场景进行了独立测试,具体评估了大模型在检索和生成过程中的表现,测试数据如下图所示(2024 年 9 月 5 日数据)。
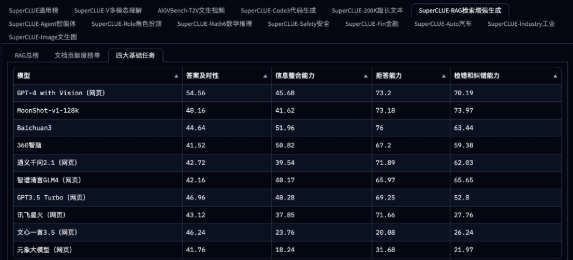
- 在 SuperCLUE 官网的 SuperCLUE-RAG 检索增强生成分支页面上,可以查看其总榜及四大基础任务的测评结果。选择模型时可以根据总分,以及模型在答案及时性、信息整合能力、拒答能力、检错和纠错能力等方面的表现,进行综合评估,作为场景选型参考。
- 其次,也是最重要的,我们需要根据实际应用场景来考量并选择适合的大模型,以下几个维度是关键:
开源与闭源:开源模型适用于数据敏感性高或有严格合规要求的场景,通过自托管实现对数据的完全掌控,确保隐私与安全。而闭源模型则适合数据敏感度较低的应用场景,其维护与服务相对完善,能够降低运维复杂度。
模型参数规模:大参数模型在复杂任务中的推理与生成能力较强,但并非所有应用场景都需要高精度模型。小参数模型(如 7B)在满足简单逻辑任务时,具备更优的响应速度、成本控制和资源利用效率。因此,模型规模应依据应用复杂性及算力预算进行合理匹配。
国内与国外部署:模型选择还需考虑部署环境。如果应用主要在国内进行,虽然调用国外大模型的接口是可行的,但可能会遇到稳定性、网络延迟、注册认证、充值付费等方面的实际问题。此外,数据合规性是重要考量,尤其对于需要遵循国内隐私和数据安全法规的场景,选择国内大模型或本地化部署更为合适。 - 综上所述,模型的选择应结合 RAG 应用场景的需求和限制,更好地选择合适的大模型以最大化其效果。
- 最后对闭源和开源大模型做个分析和推荐。闭源与开源大模型在 RAG 应用中的选择需要结合参数规模、性能差异、成本及数据安全等多重因素加以考虑。
闭源大模型,如通义千问、文心一言、混元大模型、豆包大模型和 Kimi Chat 等,由于参数量较高,在 RAG 应用中的实际表现差异其实较小,此类大模型的选择更多地取决于成本需求。
开源大模型,基于其在国内的广泛使用和优异表现,推荐以下三个系列:Qwen 系列模型、Baichuan 系列模型、ChatGLM 系列模型
不管你是零经验的编程小白,还是想转型大模型的传统程序员,这份学习路线和资源都能精准匹配你的需求——基础薄弱?有入门专题帮你补;想练实战?有项目案例带你做;要找工作?有面试资源助你通关。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?
别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明:AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。


四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)