多模态大模型学习笔记(二十二)——大模型微调全解:从全量调参到LoRA的参数高效训练实战
大模型微调全解:从全量调参到LoRA的参数高效训练实战
随着大语言模型的快速发展,预训练大模型已具备强大的通用语言理解与生成能力,但要让模型真正适配人类指令交互、垂直领域任务,微调(Fine-Tuning)是不可或缺的核心环节。本文将系统拆解大模型微调的完整体系,从有监督微调(SFT)的定位,到全量调参与参数高效微调(PEFT)的核心差异,再到以LoRA为代表的主流PEFT方法的原理、工程化落地与进阶策略,全方位讲透大模型微调的核心方法论。
1 大模型微调在完整训练生态中的定位
1.1 大模型的完整训练链路
大模型从0到可用的对话模型,完整训练生态分为四个核心阶段,如下图所示:
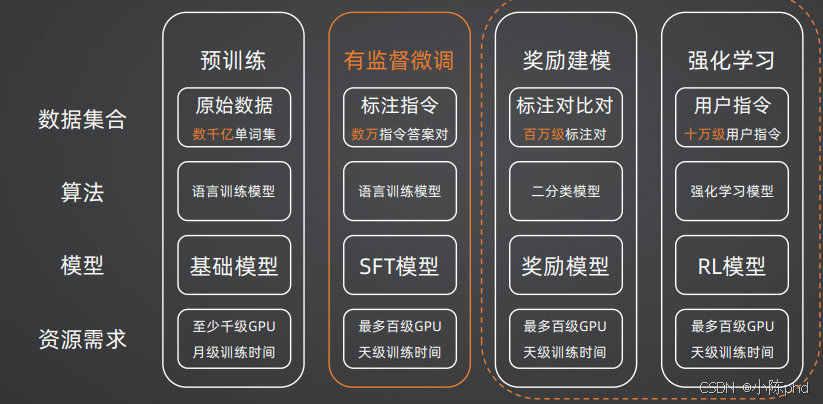
在整个链路中,四个阶段的核心定位与资源需求如下:
- 预训练阶段:大模型能力的根基,基于数千亿单词的原始文本语料训练语言模型,得到具备通用语言能力的基础模型。该阶段资源需求极高,需要至少千级GPU、月级训练时间,是大模型研发中成本最高的环节。
- 有监督微调(SFT,Supervised Fine-Tuning):让基础模型学会遵循人类指令的核心步骤,基于数万条人工标注的指令-答案对微调模型,得到SFT模型。相比预训练,SFT资源需求大幅降低,最多百级GPU、天级训练时间即可完成。
- 奖励建模(RM):基于百万级人工标注对比对,训练二分类奖励模型,用于判断模型输出的优劣,为后续强化学习提供奖励信号。
- 基于人类反馈的强化学习(RLHF):基于十万级用户指令,以奖励模型的输出为奖励信号,用强化学习算法进一步优化模型,让模型输出更贴合人类偏好。
SFT是整个链路中承上启下的关键环节——它将预训练模型的通用语言能力,转化为可交互、可执行人类指令的任务能力,也是绝大多数开发者落地大模型定制化的核心切入点。
2 SFT微调的两大核心范式:全量调参 vs 参数高效微调
SFT的核心是基于标注的指令数据,调整模型参数以适配指令遵循任务。根据参数调整的范围,分为全量调参(Full Fine-Tuning)和参数高效微调(PEFT,Parameter-Efficient Fine-Tuning)两大范式,两者的核心差异如下表所示:
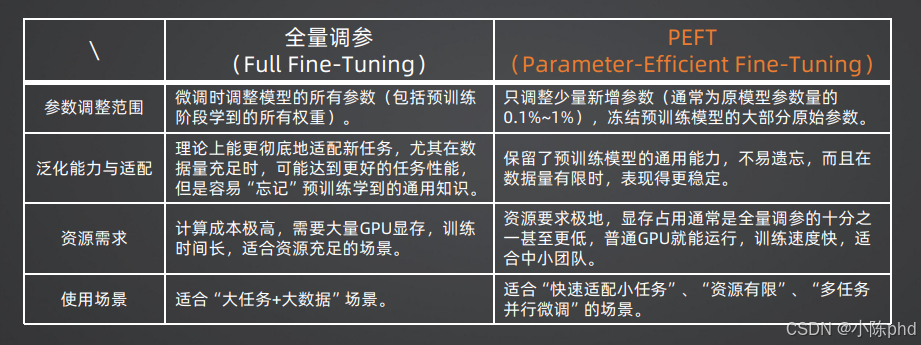
2.1 全量调参(Full Fine-Tuning)
全量调参是最传统的微调范式,核心逻辑是:微调过程中,调整预训练模型的全部参数,包括预训练阶段学到的所有权重。
- 核心优势:理论上能更彻底地适配新任务,当标注数据量充足时,可达到更优的下游任务性能。
- 核心痛点:
- 资源成本极高:需要大量GPU显存支撑,训练时间长,仅适合资源充足的机构与场景;
- 灾难性遗忘:模型容易“忘记”预训练阶段学到的通用知识,泛化能力下降;
- 部署成本高:每一个微调任务都需要保存一份完整的模型权重,多任务场景下存储成本极高。
- 适用场景:仅适合“大任务+大数据”的场景,比如通用大模型的基座SFT训练。
2.2 参数高效微调(PEFT)
PEFT是为解决全量调参的痛点而生的微调范式,核心逻辑是:冻结预训练模型的绝大部分原始参数,仅调整少量新增的、与任务相关的参数(通常仅为原模型参数量的0.1%~1%)。
- 核心优势:
- 资源需求极低:显存占用通常仅为全量调参的十分之一甚至更低,普通消费级GPU即可运行,训练速度快,适合中小团队与个人开发者;
- 保留通用能力:冻结了预训练主干权重,最大程度保留了模型的通用知识,不易出现灾难性遗忘,在数据量有限时表现更稳定;
- 部署灵活:每个微调任务仅需保存新增的少量参数(通常仅几十MB),多任务场景下可快速切换适配,存储与部署成本极低。
- 适用场景:快速适配垂直领域小任务、资源有限的开发场景、多任务并行微调的场景,是目前大模型定制化落地的主流方案。
3 SFT微调的工程化落地核心环节
无论是全量调参还是PEFT,SFT的效果上限由数据质量决定。工程化落地中,SFT微调的核心环节包括样本设计、模板化处理、数据清洗与校验三大步骤。
3.1 微调样本的三元组设计
SFT的训练样本标准格式为指令三元组,即instruction(指令)、input(输入)、output(输出)三个核心字段,覆盖四大类核心场景,如下图所示:

3.1.1 基础问答场景
指令本身就是完整的问题,无额外补充输入,input字段为空。
示例:
{
"instruction": "什么是猫科动物",
"input": "",
"output": "猫科动物是哺乳纲食肉目猫科动物的统称,大多为食肉动物,具备敏锐的听觉、视觉与捕猎能力,常见的家猫、老虎、狮子等均属于猫科动物。"
}
3.1.2 信息查询场景
指令包含明确的信息查询需求,无额外补充输入,input字段为空。
示例:
{
"instruction": "故宫开放的时间是几点?需要提前预约吗",
"input": "",
"output": "北京故宫每年4月1日至10月31日采用旺季开放时间,开放时间为8:30-17:00,16:00停止入院;11月1日至次年3月31日为淡季,开放时间为8:30-16:30,15:30停止入院。故宫实行全网实名预约制,所有观众均需提前在官方渠道预约购票,不支持现场购票。"
}
3.1.3 多轮对话承接场景
input字段为上一轮的对话上下文,指令为当前用户的新问题,用于让模型学习多轮对话的上下文承接能力。
示例:
{
"instruction": "如果我带一个6岁孩子去,有没有适合的参观路线",
"input": "[{\"human\": \"故宫开放的时间是几点?需要提前预约吗\", \"assistant\": \"北京故宫每年4月1日至10月31日采用旺季开放时间...\"}]",
"output": "带着6岁孩子参观故宫,推荐以轻松路线为主,避免长时间步行:从午门进入,先参观太和殿、中和殿、保和殿三大殿,随后向东前往珍宝馆与钟表馆,这两个展馆有大量精美展品,能吸引孩子的注意力;之后沿御花园参观,最终从神武门离开,全程可控制在3小时左右,中途可在御花园休息。"
}
3.1.4 文本处理任务场景
input字段为待处理的具体文本内容,指令为对文本的处理要求,比如总结、翻译、润色、提取信息等,是垂直领域任务最常用的格式。
示例:
{
"instruction": "请把这段文字总结成3句话,重点突出核心结论",
"input": "2024年全国新能源汽车销量达949.5万辆,同比增长34.5%,市场渗透率提升至46.2%。其中比亚迪以342.8万辆的销量稳居第一,市场占比达36.1%,其核心优势在于全产业链自研带来的成本控制与技术迭代能力。专家预测,2025年新能源汽车市场渗透率将突破50%,行业竞争将从价格战转向技术与智能化体验的竞争。",
"output": "1. 2024年全国新能源汽车销量达949.5万辆,同比增长34.5%,市场渗透率提升至46.2%;2. 比亚迪2024年新能源汽车销量稳居行业第一,市场占比超3成,核心优势来自全产业链自研能力;3. 专家预测2025年新能源汽车渗透率将突破50%,行业竞争核心转向技术与智能化体验。"
}
3.2 样本的模板化与占位符设计
为了保证模型训练的稳定性,提升模型的跨任务泛化能力,需要对样本进行模板化与标准化处理,核心设计如下图所示:

3.2.1 统一指令模板
所有单轮样本统一使用标准化的三元组模板,确保模型输入格式的一致性:
instruction : {instruction}, input : {input}, output : {output}
3.2.2 多轮对话场景模板
多轮对话样本采用固定的角色模板,明确区分用户(human)与助手(assistant)的对话轮次,让模型学习对话的角色边界与上下文承接逻辑:
human : {user_turn_1}, assistant : {assistant_turn_1},
human : {user_turn_2}, assistant : {assistant_turn_2}
...
3.2.3 跨任务能力模板
针对翻译、分类、提取等标准化任务,固定指令的表述方式,让模型快速学习同类任务的处理逻辑,提升跨任务的泛化能力,比如翻译任务的固定模板:
instruction : "把下边的文本翻译成英语", input : {中文文本}, output : {英文文本}
3.2.4 占位符设计
针对同类不同细节的任务,使用占位符来泛化样本,让模型学习任务的核心逻辑,而非特定的细节内容,比如代码生成任务的占位符模板:
instruction : 用C++实现{功能描述},
input : 要求{具体约束,比如时间复杂度O(n)},
output : {代码}
3.3 数据清洗与一次性校验
低质量的训练数据会直接导致微调效果变差,甚至让模型学到错误的知识,因此数据清洗与校验是SFT微调中不可或缺的环节,核心流程如下图所示:

3.3.1 低质量数据样本过滤
- 过滤无意义内容:去除乱码、重复字符、与任务无关的文本、无意义的灌水内容;
- 修复错误输出:校验输出内容的准确性,修正事实性错误,比如“巴西的首都是里约热内卢”这类错误内容;
- 去除冗余信息:过滤输入与输出无关的内容,确保输出严格响应指令,不包含无关信息;
- 平衡样本分布:避免某一类任务的样本占比过高,确保模型在多任务上均衡学习,不会出现能力偏科。
3.3.2 样本逻辑一致性校验
- 指令与输出的一致性:确认输出内容真正响应了指令的要求,没有答非所问;
- 输入与输出的关联性:如果输入中包含了具体的参考信息,确认输出严格基于输入内容生成,而非凭空捏造;
- 格式一致性:确保同类任务的输出格式统一,比如日期格式统一为“YY-MM-DD”、列表格式统一等,提升模型输出的稳定性;
- 价值观对齐:过滤带有偏见、歧视、有害内容的样本,确保模型学习到符合伦理规范的内容。
3.3.3 自动化与人工结合的校验方案
- 自动化工具:基于规则或小模型,对全量样本进行初步过滤,快速筛除低质量、有明显错误的样本;
- 人工校验:针对医疗、金融、政务等关键领域,进行人工二次校验,确保样本的准确性与合规性。
4 主流PEFT方法详解
经过多年的发展,业界已经推出了多种PEFT方法,不同方法的核心思路、适用场景各有差异,主流方法的对比如下图所示: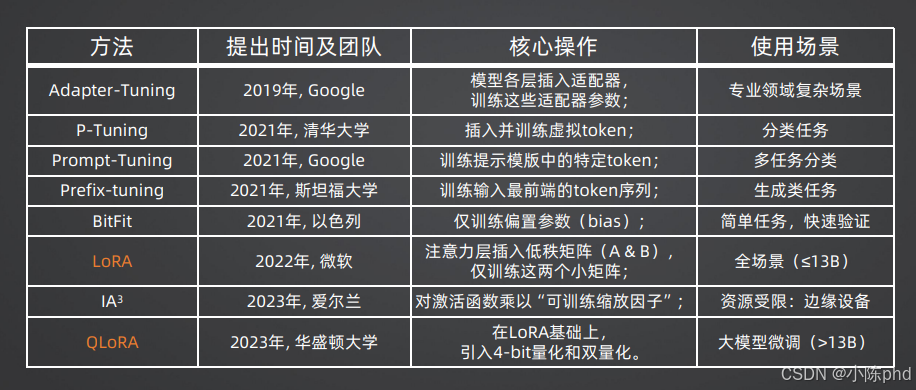
4.1 早期PEFT方法
4.1.1 Adapter-Tuning
- 提出时间与团队:2019年,Google
- 核心操作:在Transformer模型的各层之间插入小的适配器(Adapter)网络,训练时冻结主干模型,仅训练适配器的参数。适配器通常由两个降维-升维的线性层组成,参数量极小。
- 使用场景:专业领域的复杂任务场景,适配性强,是早期最主流的PEFT方案。
4.1.2 P-Tuning
- 提出时间与团队:2021年,清华大学
- 核心操作:在输入序列中插入可训练的虚拟token,仅训练这些虚拟token的嵌入向量,冻结主干模型的全部参数。
- 使用场景:自然语言理解、分类任务,在中文大模型的分类任务中表现优异。
4.1.3 Prompt-Tuning
- 提出时间与团队:2021年,Google
- 核心操作:为每一个下游任务训练专属的提示模板token,仅更新提示模板中的特定token参数,冻结主干模型。
- 使用场景:多任务分类场景,适合大规模多任务并行适配。
4.1.4 Prefix-tuning
- 提出时间与团队:2021年,斯坦福大学
- 核心操作:在Transformer每一层的输入前缀添加可训练的token序列,仅训练这些前缀token,冻结主干模型。
- 使用场景:文本生成类任务,比如摘要、翻译、对话生成。
4.1.5 BitFit
- 提出时间与团队:2021年,以色列团队
- 核心操作:仅训练Transformer模型中的偏置参数(bias),其余所有参数全部冻结,是参数量最小的PEFT方案之一。
- 使用场景:简单任务、快速验证场景,适合快速验证数据与任务的可行性。
4.2 核心主流方法:LoRA(Low-Rank Adaptation,低秩适配)
LoRA是目前业界应用最广泛的PEFT方法,由微软团队于2022年提出,其核心思路是:用低秩矩阵分解来近似模型微调过程中的权重更新量,仅训练低秩矩阵的参数,冻结主干模型权重。
4.2.1 LoRA的核心原理与公式
Transformer模型的核心是自注意力机制,其中的线性层(全连接层)是参数的主要载体。对于一个预训练好的线性层,其前向传播公式为:
h=W0x h = W_0 x h=W0x
其中,W0∈Rd×kW_0 \in \mathbb{R}^{d \times k}W0∈Rd×k 是预训练好的权重矩阵,xxx 是输入向量,hhh 是输出向量。
在全量微调中,我们会更新整个 W0W_0W0,得到微调后的权重 W=W0+ΔWW = W_0 + \Delta WW=W0+ΔW,其中 ΔW\Delta WΔW 是权重的更新量。
而LoRA的核心创新是,将更新量 ΔW\Delta WΔW 做低秩分解,即:
ΔW=BA \Delta W = BA ΔW=BA
其中,B∈Rd×rB \in \mathbb{R}^{d \times r}B∈Rd×r,A∈Rr×dA \in \mathbb{R}^{r \times d}A∈Rr×d,rrr 是秩,且 r≪min(d,k)r \ll \min(d, k)r≪min(d,k)(通常r取8、16、32、64,远小于模型隐藏层维度d)。
此时,线性层的前向传播公式变为:
h=W0x+BAx h = W_0 x + BA x h=W0x+BAx
训练过程中,W0W_0W0 被完全冻结,不参与梯度更新,仅训练矩阵A和B的参数。
推理阶段,我们可以将训练好的BA矩阵合并到原权重 W0W_0W0 中,得到 W=W0+BAW = W_0 + BAW=W0+BA,此时前向传播公式与原模型完全一致,不会增加任何推理延迟,这是LoRA相比其他PEFT方法的核心优势之一。
4.2.2 LoRA的核心优势
- 全场景适配:可适配所有Transformer架构的大模型,无论是分类、生成、对话等场景均有优异表现,适配模型规模可达13B;
- 无推理延迟:推理时可将低秩矩阵合并到原模型,不会增加任何推理耗时,不影响模型的推理性能;
- 显存占用极低:仅训练少量低秩矩阵参数,显存需求远低于全量调参,消费级GPU即可完成7B、13B模型的微调;
- 效果媲美全量调参:在绝大多数场景下,LoRA的微调效果可达到甚至超过全量调参,同时不会出现灾难性遗忘;
- 部署灵活:单个LoRA权重文件通常仅几十MB,可快速切换、合并多个LoRA权重,适配多任务场景。
4.2.3 LoRA 的核心超参数详解
理解 LoRA 的核心超参数,是调优 LoRA 微调效果、平衡训练成本与模型效果的关键。LoRA 的核心可配置参数分为秩 r、缩放因子 alpha、丢弃率 dropout 三大类,核心定义与工程化逻辑如下:

4.2.3.1 秩 r
秩 r 是 LoRA 最核心的超参数,决定了低秩矩阵 A 和 B 的维度,直接控制可学习参数的总规模。
参数量计算公式:LoRA可学习参数规模 ≈ r*(输入维度 + 输出维度)
核心影响逻辑:r 越小,可训练的参数量越少,训练速度越快、显存占用越低,但模型能捕捉的任务特征越有限,可能无法适配复杂任务;r 越大,可学习的特征维度越丰富,对下游任务的拟合能力越强,但参数量会随之上升,训练成本增加,同时在小数据集场景下有过拟合的风险。
工程化推荐值:通用对话、简单分类、轻量垂直场景,r 通常取 8、16、32;代码生成、专业领域长文本生成、复杂推理等任务,r 可提升至 64、128。
4.2.3.2 缩放因子 alpha
alpha 是 LoRA 的权重缩放因子,核心作用是平衡低秩矩阵的更新幅度,保证训练过程中的梯度稳定,避免梯度爆炸或梯度消失。
核心计算逻辑:在 LoRA 的前向传播中,低秩矩阵的输出会乘以 alpha / r 的缩放系数。当 alpha 设置为与 r 相等时,缩放系数为 1,此时低秩矩阵的更新幅度与原模型的梯度尺度完全对齐,是最稳妥的梯度稳定配置。
工程化推荐值:通用场景下默认设置为与 r 相等,是业界最通用的配置;如需放大 / 缩小低秩分支的权重,可按比例缩放 alpha 值。
4.2.3.3 丢弃率 dropout
dropout 即随机丢弃率,核心作用是防止模型过拟合,提升微调后模型的泛化能力。
核心逻辑:在训练过程中,随机丢弃一部分输入到低秩矩阵的特征,强制模型学习更鲁棒的通用任务特征,避免过度拟合训练集中的噪声与特例。
工程化推荐值:通用场景通常取 0.05-0.1;数据量较少、容易过拟合的场景,可提升至 0.2~0.3;数据量充足、任务简单的场景,可设置为 0,加快训练收敛速度。
4.2.4 LoRA 的工程化配置:目标层选择与冻结策略
除了超参数调优,LoRA 的微调效果还取决于目标层的选择与冻结策略,这是工程落地中最容易被忽略、却直接决定微调成败的关键环节。
4.2.4.1 目标层选择
LoRA 的低秩适配器可以插入到 Transformer 模型的任意线性层,不同层的核心能力不同,适配效果差异极大,主流可选目标层与适配逻辑如下:
注意力层的 Q/K/V 投影矩阵:Transformer 自注意力层的核心,负责输入文本的特征编码与注意力权重计算,是 LoRA 最优先选择的适配层。其中,Q/K 层(查询 / 键投影矩阵)是优先级最高的选择,绝大多数场景下,仅适配 Q/K 层即可达到优异的微调效果,同时控制参数量。
输出投影矩阵 O:自注意力层的输出投影层,负责注意力特征的维度变换、空间映射与特征提取,适合对生成效果有精细化要求的下游操作,可作为 Q/K 层的补充适配层。
MLP(多层感知机)层:Transformer 的前馈神经网络层,负责特征的非线性变换与深度语义编码。对于代码生成、专业领域推理、数学计算等需要强特征变换能力的任务,在 Q/K 层基础上增加 MLP 层的 LoRA 适配,往往能带来显著的效果提升。
4.2.4.2 冻结策略
LoRA 的冻结策略分为两类,核心原则是最大化保留预训练模型的通用能力,仅适配任务相关的特征,避免破坏模型的基础能力:
全部冻结:冻结预训练主干模型的所有权重,仅训练 LoRA 低秩适配器的参数,这是最通用、最推荐的冻结策略。该策略完全保留了预训练模型的基础能力,不会出现灾难性遗忘,同时训练成本最低,适配绝大多数场景。
部分冻结:仅冻结模型的底层主干权重,放开顶层部分 Transformer 层的参数,配合 LoRA 一起训练。该策略仅适合数据量极大、任务与预训练目标差异极大的场景,使用时需极其谨慎,否则极易破坏预训练模型的基础能力,出现灾难性遗忘。
4.3 LoRA的进阶方案:QLoRA
QLoRA由华盛顿大学团队于2023年提出,是在LoRA基础上的进阶优化方案,解决了超大模型(>13B)的微调难题。
- 核心操作:在LoRA的基础上,引入4-bit量化与双量化技术,将预训练模型量化为4-bit精度并冻结,仅训练低秩的LoRA适配器参数。
- 核心优势:在不损失模型性能的前提下,进一步大幅降低显存需求,可在单张消费级GPU上完成65B、70B超大模型的微调,同时效果与全量16-bit微调持平。
- 使用场景:超大模型(>13B)的微调场景,是目前落地超大模型定制化的首选方案。
4.4 不同预训练目标的 PEFT 适配策略
PEFT 的核心不是盲目 “调参数”,而是先看懂模型的预训练任务逻辑,再让 PEFT 的配置匹配这个逻辑。
不同预训练目标训练出来的模型,其核心能力、参数分布、语义编码逻辑天差地别,选错适配策略会直接导致微调效果差、甚至破坏模型的基础能力。主流的预训练目标分为三类,对应的 PEFT 适配策略如下表所示: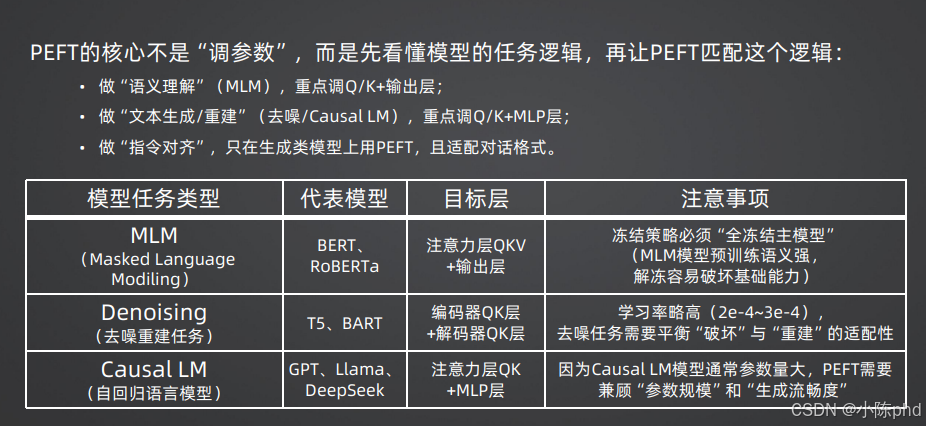
针对三类模型的核心适配逻辑详解:
- MLM 掩码语言模型:这类模型的核心能力是语义理解,预训练阶段通过 “掩码 token 预测” 任务,学习了极强的文本语义表征能力。因此 PEFT 适配时,重点调整 Q/K + 输出层即可,必须全冻结主模型,绝对不能解冻主干参数,否则会直接破坏模型预训练学到的核心语义理解能力,导致下游任务效果大幅下降。
- Denoising 去噪重建模型:这类模型采用编码器 - 解码器(Seq2Seq)架构,核心能力是文本的去噪、重建、翻译、摘要等序列到序列任务。PEFT 适配时,需要同时覆盖编码器和解码器的 QK 层,保证编码器的语义理解能力和解码器的生成能力同时适配下游任务;同时可适当提高学习率,加快模型对下游任务的适配速度。
- Causal LM 自回归语言模型:这是目前主流大语言模型(GPT、Llama、DeepSeek 等)采用的预训练目标,核心能力是自回归文本续写与生成,也是对话大模型的主流基座。PEFT 适配时,核心调整注意力层的 QK 层,对于代码生成、专业推理等复杂任务,需增加 MLP 层的适配,同时兼顾参数量与生成流畅度,是目前 PEFT 落地最主流的模型类型。
除此之外,针对 “指令对齐” 类的微调任务,必须在生成类模型(Causal LM)上使用 PEFT,同时严格适配模型的官方对话格式模板,才能保证指令对齐的效果,避免微调后模型出现对话格式混乱、无法稳定遵循指令的问题。
4.5 其他轻量化PEFT方案:IA³
IA³由爱尔兰团队于2023年提出,是极致轻量化的PEFT方案。
- 核心操作:不对权重矩阵做修改,仅对模型激活函数的输出乘以可训练的缩放因子,仅训练这些缩放因子的参数,参数量比LoRA更小。
- 核心优势:显存需求极低,训练速度极快,适合资源严重受限的场景。
- 使用场景:边缘设备、端侧模型的微调,资源严重受限的场景。
5 PEFT的进阶优化策略
在基础PEFT方法之上,业界还推出了多种进阶优化策略,进一步提升微调效果、降低训练成本,主要分为舍去策略与组合策略两大类,如下图所示:
5.1 舍去策略
舍去策略的核心是,在训练过程中仅保留对任务最关键的参数,舍去冗余参数,进一步降低训练成本,提升模型泛化能力。
5.1.1 DARE(动态丢弃)
核心逻辑:按比例随机丢弃适配器的参数,对保留的参数进行缩放校准,在不损失效果的前提下,降低适配器的参数量,同时缓解过拟合问题,提升模型的泛化能力。
5.1.2 Child-tuning
核心逻辑:仅选择模型中“对任务敏感的核心参数”(主要是注意力头的相关参数)进行训练,冻结其余所有参数,进一步降低训练的参数量,同时保留模型的通用能力。
5.2 组合策略
组合策略的核心是,将多种PEFT方法结合,或与其他大模型优化技术结合,实现更优的微调效果与更强的任务适配能力。
5.2.1 LoRA+MoE
核心逻辑:部署多组“LoRA专家”,每个LoRA专家适配一类子任务,通过门控网络,根据输入的指令动态选择适配的LoRA专家,实现多任务场景下的效果最优,同时保留PEFT的轻量化优势。
5.2.2 UniPELT
核心逻辑:集成了LoRA、Adapter-Tuning、Prompt-tuning多种PEFT子模块,通过门控网络,为不同的任务、不同的模型层自动选择最优的子模块,实现自适应的参数高效微调,在复杂多任务场景下表现优异。
5.2.3 QLoRA+知识蒸馏
核心逻辑:先用QLoRA对超大模型进行微调,得到效果优异的大模型适配器,再通过知识蒸馏技术,将大模型的能力蒸馏到小模型中,最终部署小模型,兼顾了微调效果与部署的推理性能,是落地端侧、边缘场景的常用方案。
6 总结
大模型微调是预训练大模型落地到具体场景的核心环节,从全量调参到以LoRA为代表的参数高效微调,技术的发展大幅降低了大模型定制化的门槛。
- 对于资源充足的机构,全量调参可在大数据场景下实现最优的任务适配;
- 对于中小团队与个人开发者,以LoRA、QLoRA为核心的PEFT方案,是落地大模型定制化的首选,在极低的资源成本下,即可实现媲美全量调参的效果;
- 而SFT微调的效果上限,始终由数据质量决定,标准化的样本设计、严格的数据清洗与校验,是微调成功的核心前提。
未来,随着大模型技术的持续发展,参数高效微调技术也会持续迭代,进一步降低大模型的落地门槛,让大模型能更便捷地适配千行百业的具体场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)