LangGraph常见的工作流模式
目录
协调者-工作者模式(Orchestrator-Workers)
工作流模式是预先定义好的执行路径,就像工厂的流水线一样,每个步骤都有明确的输入输出和顺序。根据不同的需求场景,从而定制出工作流常见的用法选项。
提示链模式(Prompt Chaining)
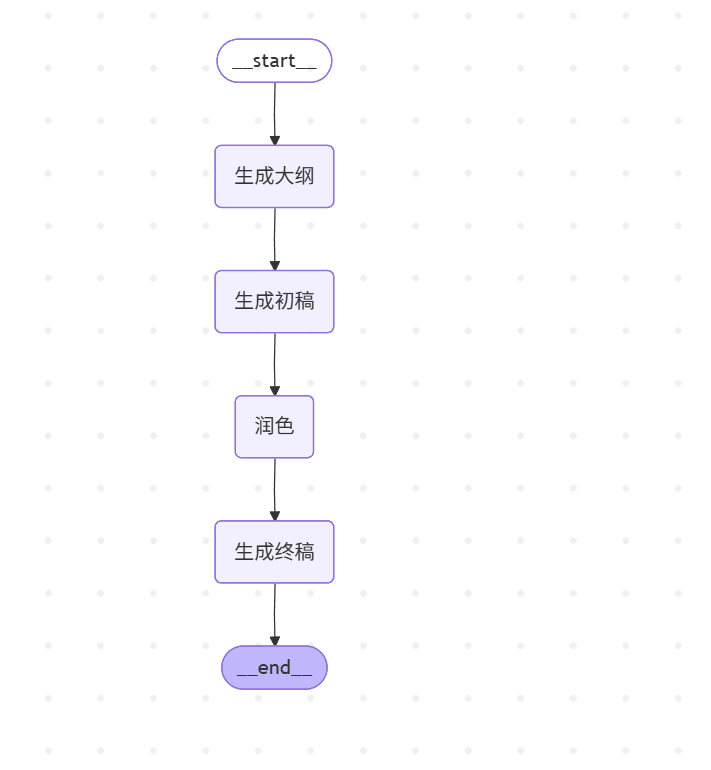
提示链就像流水线一样,前一个步骤的输出作为下一个步骤的输入。这就跟进⾏内容创作时,需要 大纲 → 初稿 → 润色 → 最终稿 ,且每个步骤的输出需要传输给下一个步骤,才能确保内容质量逐步提升。
我们可以创建一个内容创作场景的工作流,包含 大纲 → 初稿 → 润色 → 最终稿 。节点即可设计为:
- generate_outline 节点: 只负责大纲生成
- generate_draft 节点: 只负责初稿写作
- polish_content 节点: 只负责内容润色
- finalize_content 节点: 只负责最终整合
# 工作流模式:提示连模式
# 前一个节点的输出是后一个节点的输入
from typing import TypedDict
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage
from langgraph.constants import START, END
from langgraph.graph import StateGraph
model = init_chat_model(model="deepseek-chat")
class InputState(TypedDict):
topic:str #文章主题
class OutputState(TypedDict):
article:str #输出的文章
# 中间状态(节点之间传递的私有状态)
class State(InputState,OutputState):
outline: str # 第一步:生成的大纲
draft: str # 第二步:生成初稿
polished_draft:str #第三步:润色后的稿件
# 节点一:生成大纲
PROMPT_1 = (
"根据主题⽣成⽂章⼤纲。\n"
"主题:{topic}\n"
"要求:"
"1.只需两个最核⼼标题"
"2.不⽤进⾏说明,只返回最终⼤纲"
)
def node_1(state:InputState):
"""根据主题生成大纲"""
print("*"*50)
print("\n大纲生成中...\n")
prompt = PROMPT_1.format(topic=state["topic"])
result = model.invoke([HumanMessage(content=prompt)])
print(result.content)
print("\n大纲生成完毕\n")
return {
"outline":result.content
}
PROMPT_2=(
"根据以下内容生成文章完整初稿。\n"
"主题:{topic}\n"
"大纲: "
"{outline}\n"
"要求:"
"1.每个标题下,最多使用三句话的内容即可"
"2.不用进行说明,只返回最终结果"
)
# 节点二:生成初稿
def node_2(state:State):
"""根据大纲生成初稿"""
print("*"*50)
print("\n初稿生成中...\n")
prompt = PROMPT_2.format(topic=state["topic"],outline=state["outline"])
result = model.invoke([HumanMessage(content=prompt)])
print(result.content)
print("\n初稿生成完毕\n")
return {
"draft":result.content
}
PROMPT_3 = (
"根据文章初稿进行润色。\n"
"主题:{topic}\n"
"初稿: "
"{draft}\n"
"要求:"
"1.润色后,文章不能太长"
)
#节点三: 对初稿进行润色
def node_3(state:State):
"""润色初稿"""
print("*"*50)
print("\n润色初稿中...\n")
prompt = PROMPT_3.format(topic=state["topic"],draft=state["draft"])
result = model.invoke([HumanMessage(content=prompt)])
print(result.content)
print("\n润色完毕\n")
return {
"polished_draft":result.content
}
PROMPT_4 = (
"根据润色版文章,生成文章终稿。\n"
"主题:{topic}\n"
"大纲: "
"{outline}\n"
"润色版文章: "
"{polished_draft}\n"
)
# 节点四:生成最终稿
def node_4(state:State):
"""生成最终稿"""
print("*"*50)
print("\n生成最终稿中...\n")
prompt = PROMPT_4.format(topic=state["topic"],outline=state["outline"]
,polished_draft=state["polished_draft"])
result = model.invoke([HumanMessage(content=prompt)])
print(result.content)
print("\n生成最终稿完毕\n")
return {
"article":result.content
}
builder =StateGraph(State,input_schema=InputState,output_schema=OutputState)
builder.add_node(node_1)
builder.add_node(node_2)
builder.add_node(node_3)
builder.add_node(node_4)
builder.add_edge(START,"node_1")
builder.add_edge("node_1","node_2")
builder.add_edge("node_2","node_3")
builder.add_edge("node_3","node_4")
builder.add_edge("node_4",END)
graph = builder.compile()
result = graph.invoke({
"topic":"小猫和小狗"
})
print(result)
并行化模式(Parallelization)
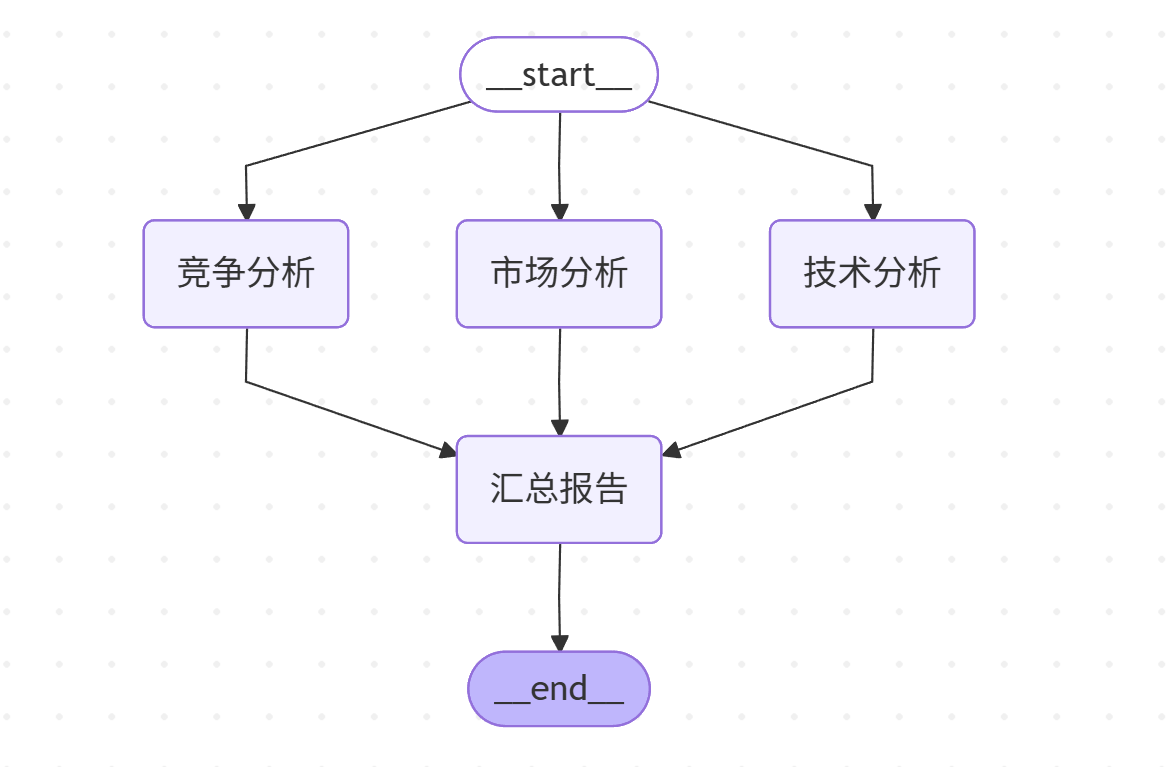
并行化是指多个任务同时进行,提⾼效率,最终汇总结果。在多⻆度处理同一问题时,常用该模式。例如,现在需要研发一款主打城市通勤的 智能电动自行车 ,具有导航、社交、防盗等功能。在开始研发前,需要进行多维度分析,如:
- 市场分析:用户关注续航⾥程、车身重量、防盗能力,并对“骑行社交”(组队、分享路线)有新兴兴趣。
- 竞品分析:传统品牌车型智能化不足;互联网品牌车型续航和线下售后服务是其短板。
- 技术分析:评估更轻量化的电池材料与车身设计以提升续航和便携性,并开发基于GPS和移动网络的智能防盗系统与社交功能App的集成。 最终汇总分析结果。而并行分析不仅省时,还能提升决策质量。
# 并行化模式
from typing import TypedDict
from langchain_core.messages import HumanMessage
from langgraph.constants import START, END
from langgraph.graph import StateGraph
class State(TypedDict):
concept:str #概念
market:str #市场分析
competitor:str #竞争分析
tech:str #技术总结
report:str # 汇总报告
# 三个并行分析任务
def market_task(state:State):
return {"market": "用户关注续航、重量、防盗,对骑行社交有兴趣..."}
def competitor_task(state:State):
return {"competitor": "传统品牌智能化不足,互联网品牌续航和售后差..."}
def tech_task(state:State):
return {"tech": "轻量化电池车身、GPS防盗、社交App集成..."}
# 汇总结果
def combine_results(state: State):
"""生成最终报告"""
report = f"产品分析报告\n\n"
report += f"市场分析:\n{state['market']}\n\n"
report += f"竞品分析:\n{state['competitor']}\n\n"
report += f"技术分析:\n{state['tech']}\n\n"
report += "建议:聚焦续航、防盗、社交功能的平衡发展"
return {"report": report}
# 构建工作流
builder = StateGraph(State)
builder.add_node(market_task)
builder.add_node(competitor_task)
builder.add_node(tech_task)
builder.add_node(combine_results)
builder.add_edge(START,"market_task")
builder.add_edge(START,"competitor_task")
builder.add_edge(START,"tech_task")
builder.add_edge("market_task","combine_results")
builder.add_edge("competitor_task","combine_results")
builder.add_edge("tech_task","combine_results")
builder.add_edge("combine_results",END)
graph = builder.compile()
# print(graph.get_graph(xray=True).draw_mermaid())
print(graph.invoke({"concept":"智能电动自行车"})["report"])
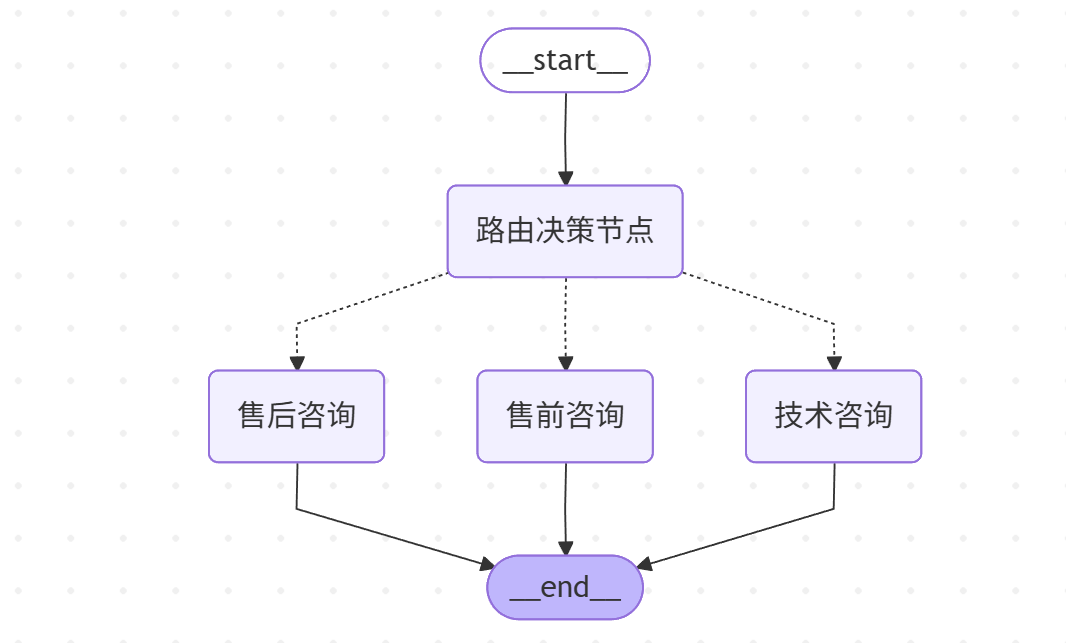
路由模式(Routing)
路由模式也被称为"智能分流",根据输入内容决定执行哪个分支。最典型案例就是智能客服系统,可 以用户问题自动分类处理,如下所示:
# 路由模式
# 实现一个智能客服系统,根据用户的问题,自动进行分类(售前咨询,售后咨询,技术咨询)
from typing import TypedDict
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from typing_extensions import Literal
from langchain.chat_models import init_chat_model
from pydantic import BaseModel, Field
class State(TypedDict):
input:str
descision:str # 路由决策
output:str
# 给大模型调用定义输出结构
class Route(BaseModel):
descision : Literal["pre_sale","after_sale","technical"]=Field(
description="根据用户的问题,决策是路由到售前处理,售后处理还是技术处理")
# 路由决策节点:根据用户输入的问题,决定路由的下一个节点
def model_call_node(state:State):
model=init_chat_model(model="deepseek-chat")
result = model.with_structured_output(Route).invoke(state["input"])
return {
"descision":result.descision
}
# 售前节点
def pre_sale(state:State):
return {"output":"处理售前咨询..."}
# 售后节点
def after_sale(state:State):
return {"output":"处理售后咨询..."}
# 技术节点
def technical(state:State):
return {"output":"处理技术咨询..."}
# 构建工作流
builder = StateGraph(State)
builder.add_node(model_call_node)
builder.add_node(pre_sale)
builder.add_node(after_sale)
builder.add_node(technical)
def route_descision(state:State):
if state["descision"]=="pre_sale":
return "pre_sale"
elif state["descision"]=="after_sale":
return "after_sale"
elif state["descision"]=="technical":
return "technical"
builder.add_edge(START,"model_call_node")
builder.add_conditional_edges(
"model_call_node",
route_descision,
["pre_sale","after_sale","technical"]
)
builder.add_edge("pre_sale",END)
builder.add_edge("after_sale",END)
builder.add_edge("technical",END)
graph = builder.compile()
# print(graph.get_graph(xray=True).draw_mermaid())
print(graph.invoke({"input": "Using extra keyword arguments on Field is deprecated and will be removed. "})["output"])协调者-工作者模式(Orchestrator-Workers)
协调者-工作者模式可以理解为一个大脑(协调者)分配任务,多个工人(工作者)执行,最后合成最 终结果。例如,当我们要处理几百页的技术文档,可以让协调者拆分文档,接着安排多个工作者并行 处理不同章节,最终汇总结果。如下图所示:
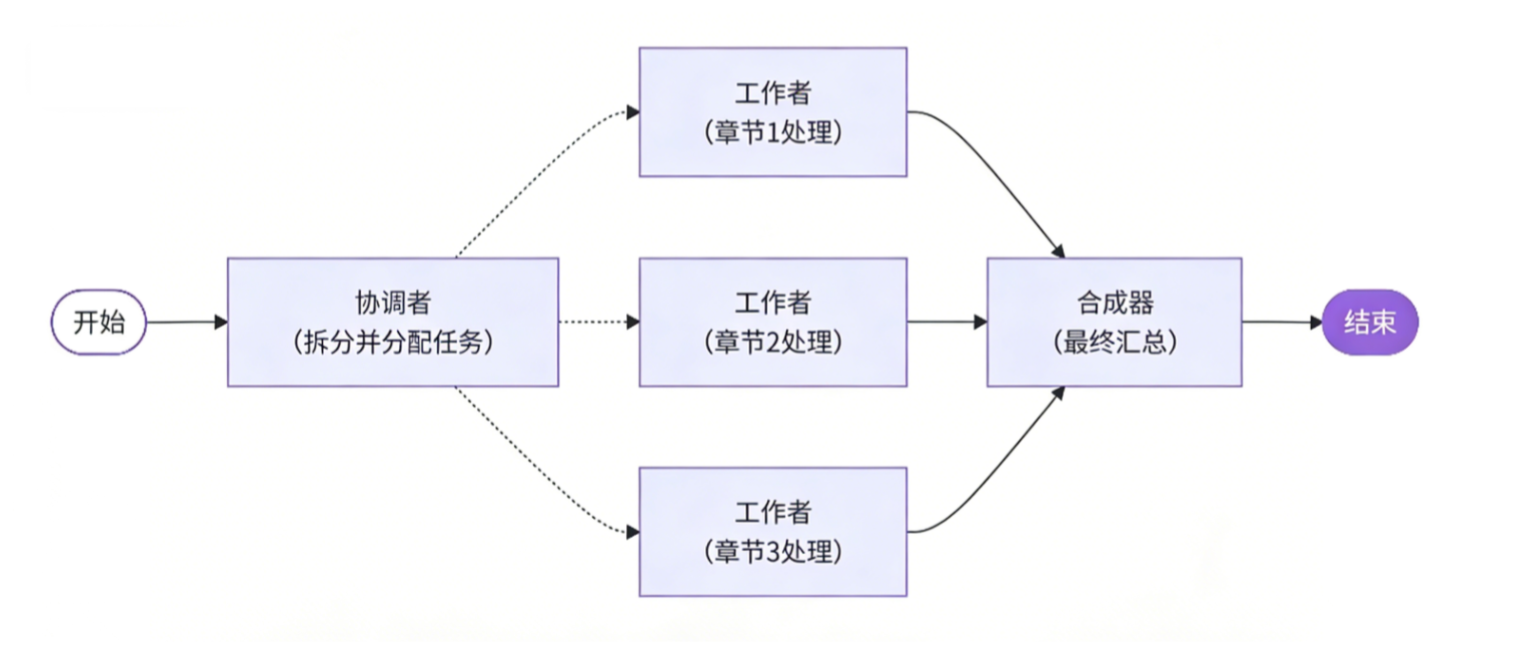
协调者-工作者模式和并行化模式都涉及同时执行多个任务,但它们的核心区别在于任务分配方式:
- 并行化 :任务在设计时就确定,所有任务同时开始。
- 协调者-工作者 :任务在运⾏时由协调者动态分配。
举个例⼦:
【案例:文档翻译】
并行化 :已知要翻译3个固定章节,同时翻译
协调者-工作者 :先分析文档结构,发现需要翻译5个章节,动态分配
【案例:数据分析】
并行化 :同时计算平均值、最⼤值、最小值(固定指标)
协调者-工作者 :先分析数据特征,决定需要计算哪些统计指标
示例:
-
协调者:负责根据{topic}⽣成报告大纲。并根据生成的大纲,将⽣成内容的子任务指派给工作者。
-
工作者:生成大纲对应的内容。
-
合成器:汇总所有工作者的成果。
注意:协调者生成3个标题,就需要3个工作者生成对应内容;⽣成10个标题,就需要10个工作者⽣成对应内容。
因此,关键在于任务指派,协调者在运⾏时需动态分配工作者,即边的数量在运行时才能确定。
为了支持这种设计模式,LangGraph 支持从条件边返回 Send 对象。 Send 有两个参数:第一个是节点的名称,第二个是要传递给该节点的状态。
def assign_task(state:State):
"""分配任务到工作者"""
worker_tasks=[]
# 拿到章节信息,然后发送给对应的工作者执行
for section in state["sections"]:
# 目前只有一个工作者节点,所以写死了
# 如果由多个工作者节点,加上判断语句即可
worker_tasks.append(Send("worker_1",{"section":section}))
return worker_tasks这样,任务分配函数会根据任务的数量,运行时动态生成n条数量的、指向工作节点的边。
完整代码如下:
# 协调者-工作者模式
# 协调者对任务进行拆分,拆分成多个子任务(制定计划)
# 再将这些子任务分配给工作者(节点),工作者可以是1个,也可以是多个,这一步通过条件边完成(conditional_edge)
# 工作者完成任务后,再将结果进行汇总(到达汇总节点),最后生成结果
# 这种模式的图结构是在运行时生成的
# 示例:根据主题生成文章
import operator
from typing import TypedDict, Annotated, List
from langchain.chat_models import init_chat_model
from langgraph.constants import START, END
from langgraph.graph import StateGraph
from langgraph.types import Send
from pydantic import BaseModel
class State(TypedDict):
topic:str #主题
sections:list #协调者生成的计划
completed_sections:Annotated[list,operator.add] #工作者完成的结果
final_report:str #最终的汇总报告
# 定义结构化输出
# 章节
class Section(BaseModel):
name:str
description:str
class Sections(BaseModel):
sections:List[Section]
model=init_chat_model(model="deepseek-chat")
planner = model.with_structured_output(Sections)
# 协调者节点:指定计划
def orchestrator(state:State):
"""协调者:生成计划,按照主题,生成大纲,包含3-5个章节"""
report_sections = planner.invoke(f"为主题{state['topic']}生成大纲,要求包含3个章节")
return {
"sections":report_sections.sections
}
# 工作者节点
def worker_1(state:State):
"""工作者节点:根据分配的任务生成内容"""
# 该节点的状态是通过协调者经过条件边获得的
# 拿到章节结构
section = state["section"]
result = model.invoke(
f"编写文章,章节名称:{section.name},内容要求:{section.description}"
)
return {
"completed_sections":[result.content]
}
# 汇总节点
def synthesizer(state:State):
"""汇总所有工作者的成果"""
completed_sections=state["completed_sections"]
final_report = "\n\n --- \n\n".join(completed_sections)
return {
"final_report":final_report
}
# 构建工作流
builder = StateGraph(State)
builder.add_node(orchestrator)
builder.add_node(worker_1)
builder.add_node(synthesizer)
builder.add_edge(START,"orchestrator")
def assign_task(state:State):
"""分配任务到工作者"""
worker_tasks=[]
# 拿到章节信息,然后发送给对应的工作者执行
for section in state["sections"]:
# 目前只有一个工作者节点,所以写死了
# 如果由多个工作者节点,加上判断语句即可
worker_tasks.append(Send("worker_1",{"section":section}))
return worker_tasks
builder.add_conditional_edges(
"orchestrator",
assign_task,
["worker_1"]
)
# 所有的工作者节点都指向汇总节点
builder.add_edge("worker_1","synthesizer")
builder.add_edge("synthesizer",END)
graph = builder.compile()
# print(graph.get_graph(xray=True).draw_mermaid())
print(graph.invoke({"topic": "AI应用开发"})["final_report"])

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)