正则化详解
目录
一、认识
正则化是指在机器学习和统计建模中的一种技术,用于控制模型的复杂度,防止模型在训练数据上过度拟合(overfitting)。当模型过度拟合时,会学习到训练数据中的噪声和细微变化,导致在新数据上的性能下降
正则化通过在模型的损失函数中引入额外的惩罚项,来对模型的参数进行约束,从而降低模型的复杂度。这个额外的惩罚通常与模型参数的大小或者数量相关,旨在鼓励模型学习简单的规律,而不是过度拟合训练数据
在深度学习中,正则化通常涉及到对网络的权重进行约束,以防止其变得过大或过复杂。常见的正则化技术有 L1 和 L2 正则化,分别通过对权重的 L1 范数和 L2 范数进行惩罚来实现。这些技术有助于降低模型的复杂度,并提高模型在未见过的数据上的泛化能力
二、L1正则化
L1 正则化,也称为 Lasso 正则化,是一种常用的正则化技术,用于控制模型的复杂度和防止过拟合。其原理是通过在模型的损失函数中增加权重的 L1 范数(权重向量的绝对值之和)作为惩罚项,从而鼓励模型产生稀疏权重,即让一部分权重趋近于零,实现特征选择的效果
是模型的数据损失,通常是模型的预测值与真实标签之间的误差,如均方误差(MSE)或交叉熵损失(Cross-entropy loss)
是正则化参数,用于控制正则化项的强度
表示模型的权重的绝对值
import torch
import torch.nn as nn
# 构建模型和损失函数(L1)
model = nn.Linear(10, 1)
criterion = nn.L1Loss()
# 输入与目标数据
torch.manual_seed(100)
input = torch.randn([32, 10])
target = torch.randn([32, 1])
print(input)
print(target)
# 推理
output = model(input)
print(output)
# 计算损失
loss = criterion(output, target)
print(loss)三、L2正则化
L2 正则化,也称为 Ridge 正则化。通过向模型的损失函数添加一个权重参数的 L2 范数的惩罚项来实现。L2 正则化中,惩罚项通常被定义为权重参数的 L2 范数的平方
是模型的数据损失,通常是模型的预测值与真实标签之间的误差
是正则化参数,用于控制正则化的强度
是权重向量w的 L2 范数的平方,表示为权重向量中各个参数的平方和
使用 L2 正则化的损失函数时,优化算法在优化过程中会同时考虑数据损失和正则化项,从而在保持对训练数据的拟合能力的同时,尽可能减小模型参数的大小,降低模型的复杂度
import torch
import torch.nn as nn
# 定义模型
model = nn.Linear(10, 1)
# 定义损失函数,包括L2正则化项
criterion = nn.MSELoss()
# 计算损失
input = torch.randn(1, 10)
target = torch.randn(1, 1)
output = model(input)
loss = criterion(output, target)
# 打印损失
print(loss)权重衰减
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=0.01)权重衰减是一种 L2 正则化,通过在优化器中添加权重衰减项来限制权重的大小
四、Elastic Net 正则化
Elastic Net(弹性网络)正则化是一种结合L1和L2正则化的技术,以实现特征选择和权值收缩之间的平衡
Elastic Net 正则化结合了 L1 和 L2 正则化的优点。L1 正则化项鼓励稀疏性和特征选择,将一些系数驱动到恰好为零。这有助于选择最相关的特征并降低模型的复杂性。另一方面,L2 正则化项鼓励使用较小但非零的系数,防止任何一个特征主导模型的预测并提高模型的稳定性
和
控制 L1 和 L2 正则化之间的平衡。较高的值
强调稀疏性,促进特征选择,而较高的值则
强调权重收缩和整体复杂性控制
import torch
import torch.nn as nn
import torch.optim as optim
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layer = nn.Sequential(
nn.Linear(768, 254),
nn.ReLU(),
nn.Linear(254, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, data):
return self.layer(data)
def compute_l1_loss(self, w):
return torch.abs(w).sum()
def compute_l2_loss(self, w):
return torch.pow(w, 2.).sum()
torch.manual_seed(100)
x = torch.randn([5, 768])
y = torch.randn([5, 10])
model = MLP()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
outputs = model(x)
loss = criterion(outputs, y)
# Elastic Net正则化
l1_weight = 0.3
l2_weight = 0.7
parameters = []
for parameter in model.parameters():
parameters.append(parameter.view(-1))
l1 = l1_weight * model.compute_l1_loss(torch.cat(parameters))
l2 = l2_weight * model.compute_l2_loss(torch.cat(parameters))
loss += l1 + l2
loss.backward()
optimizer.step()
五、L1 和 L2 正则化的区别
L1和L2正则化的主要区别在于训练期间添加到损失函数中的惩罚项
L1正则化(Lasso)
L1正则化将模型系数(权重)的绝对值之和添加到损失函数中。表示为
L1 正则化倾向于通过将某些系数驱动为零来生成稀疏模型
其执行自动特征选择,因为模型实际上忽略了系数为零的特征。当处理高维数据集或需要特征选择和可解释性时,这可能是有利的
通过忽略不相关或不太重要的特征来帮助控制模型复杂性。导致模型具有更少的非零系数和更简单的表示。通过减少模型的复杂度,L1 正则化可以提高模型的泛化能力,减少过拟合的风险
但 L1 正则化项在零处不可微,这给优化带来了挑战。次梯度方法可以通过 L1 正则化有效地优化损失函数
L2 正则化(Ridge)
L2 正则化将模型系数的平方值之和添加到损失函数中。可以表示为
L2 惩罚鼓励较小但非零的系数,防止任何一个特征主导模型的预测并促进整体权重收缩
通过缩小所有系数的大小来控制模型复杂性。其在特征之间提供更均匀分布的权重收缩,防止任何一个特征主导模型的预测,有效减少了过拟合,提高了模型的稳定性
如何选择 L1 正则化和 L2 正则化
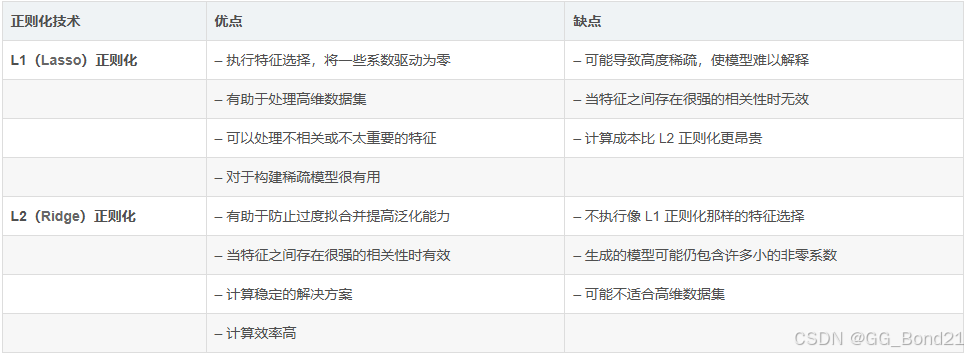
使用 L1 正则化(Lasso)
- 特征选择:当拥有包含许多特征的高维数据集,并且希望通过将某些系数精确为零来执行特征选择时,L1 正则化是合适的选择。其鼓励稀疏性,有效地选择最相关的特征并忽略不相关或不太重要的特征
- 可解释的模型:若可解释性很重要,L1 正则化会很有帮助,因为其生成的稀疏模型仅包含具有非零系数的特征子集。这可以帮助了解模型预测中最有影响力的组成部分
使用 L2 正则化(Ridge)
- 强特征相关性:当数据集包含高度相关的特征时,L2正则化比L1正则化更有效。L2 正则化在系数之间更均匀地分配相关特征的影响,防止任何一个特征主导模型的预测
- 泛化性能:众所周知,L2 正则化可以通过减少过度拟合来提高模型的泛化性能。当没有特定的特征选择需要并且您想要控制模型的整体复杂性时,它通常是一个不错的选择
也可以使用Elastic Net 正则化来平衡两种方法
六、Dropout
在训深层练神经网络时,由于模型参数较多,在数据量不足的情况下,很容易过拟合。Dropout 就是在神经网络中一种缓解过拟合的方法
缓解过拟合的方式就是降低模型的复杂度,而 Dropout 就是通过减少神经元之间的连接,把稠密的神经网络神经元连接,变成稀疏的神经元连接,从而达到降低网络复杂度的目的
import torch
import torch.nn as nn
def test01():
inputs = torch.randint(0, 10, size=[5, 8], dtype=float)
print(inputs)
print('-' * 50)
dropout = nn.Dropout(p=0.8)
outputs = dropout(inputs)
print(outputs)
if __name__ == "__main__":
test01()
# tensor([[2., 5., 0., 0., 9., 9., 6., 7.],
# [1., 7., 4., 7., 0., 1., 9., 6.],
# [1., 5., 4., 8., 8., 5., 9., 1.],
# [1., 5., 8., 6., 7., 5., 3., 4.],
# [3., 6., 9., 8., 0., 5., 4., 9.]], dtype=torch.float64)
# --------------------------------------------------
# tensor([[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 35.0000],
# [ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 30.0000],
# [ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 45.0000, 5.0000],
# [ 5.0000, 0.0000, 0.0000, 30.0000, 0.0000, 0.0000, 0.0000, 0.0000],
# [ 0.0000, 0.0000, 0.0000, 40.0000, 0.0000, 0.0000, 0.0000, 0.0000]],
# dtype=torch.float64)将 Dropout 层的概率 p 设置为 0.8,此时经过 Dropout 层计算的张量中就出现了很多 0,概率 p 设置值越大,则张量中出现的 0 就越多。上面结果的计算过程如下:
- 先按照 p 设置的概率,随机将部分的张量元素设置为 0
- 为了校正张量元素被设置为 0 带来的影响,需要对非 0 的元素进行缩放,其缩放因子为: 1/(1-p),上面代码中 p 的值为 0.8, 根据公式缩放因子为:1/(1-0.8) = 5
- 如:第 8 个元素,原来是 5,乘以缩放因子之后变成 25
丢弃概率 p 的值越大,则缩放因子的值就越大,相对其他未被设置的元素就要更多的变大。丢弃概率 P 的值越小,则缩放因子的值就越小,相对应其他未被置为 0 的元素就要有较小的变大
dropout 对网络参数的影响
# 设置随机数种子
torch.manual_seed(0)
def caculate_gradient(x, w):
y = x @ w
y = y.sum()
y.backward()
print('Gradient:', w.grad.reshape(1, -1).squeeze().numpy())
def test02():
w = torch.randn(15, 1, requires_grad=True)
x = torch.randint(0, 10, size=[5, 15]).float()
caculate_gradient(x, w)
def test03():
w = torch.randn(15, 1, requires_grad=True)
x = torch.randint(0, 10, size=[5, 15]).float()
dropout = nn.Dropout(p=0.8)
x = dropout(x)
caculate_gradient(x, w)
if __name__ == '__main__':
test02()
print('-' * 70)
test03()
# Gradient: [19. 15. 16. 13. 34. 23. 20. 22. 23. 26. 21. 29. 28. 22. 29.]
# ----------------------------------------------------------------------
# Gradient: [ 0. 0. 25. 25. 45. 45. 45. 40. 0. 15. 30. 0. 20. 0. 70.]经过 Dropout 层之后一些梯度为 0,这使得参数无法得到更新,从而达到了降低网络复杂度的目的
七、早停
早停是一种简单而有效的正则化方法,在训练过程中监视模型在验证集上的性能,一旦验证集上的性能开始下降,就停止训练。这样可以避免模型在训练集上过拟合
八、数据增强
数据增强是通过对训练数据进行变换来增加数据的多样性,从而减少过拟合的风险
- 图像数据:旋转、翻转、裁剪、缩放等
- 文本数据:同义词替换、插入、删除、交换等

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)