台湾高雄市空气质量时空演变分析与可解释性研究-1
目录
1.研究背景
空气污染是当今全球最严重的公共卫生威胁之一。细颗粒物(PM2.5)因其可深入肺泡并进入血液循环,已被确认为心血管疾病、呼吸系统疾病、肺癌及中风等的主要环境风险因子。
本研究聚焦于台湾省高雄市。高雄市作为重要的工业和港口枢纽,其PM2.5年均浓度长期位居全台最高,重污染事件频繁,直接触发了如学校停课、限制老人儿童户外活动、工地与港口限排等严苛的应急措施。
尽管研究对象是高雄市,但本研究得出的关于不同算法在非平稳周期中的真实表现排序、对关键预测因子的物理意义解释,以及对模型失效模式的归因分析,具有高度的普适性。
2.数据描述
本文数据为台湾空气质量指数数据,数据源自Kaagle数据集。原始数据集收集了台湾省2016年1月1日至2024年8月31日的小时数据,其中包括台湾省的个县市,数据量为588万2208条。考虑到数据过于庞大,故从中选取一个有代表性的城市高雄市 (Kaohsiung City)进行研究。高雄市是台湾空气质量研究中最复杂、最典型、变量最丰富的样本,选择2020-2024年这5年的时间跨度,得到的数据总量为56万2158条。高雄市有19个监测站点用于监测污染物指标。具体如下表所示:
|
监测站点名称(sitename) |
数量 |
|
Qiaotou |
44843 |
|
Meinong |
44838 |
|
Renwu |
44838 |
|
Xiaogang |
44834 |
|
Fuxing |
44830 |
|
Daliao |
44826 |
|
Linyuan |
44824 |
|
Qianzhen |
44823 |
|
Zuoying |
44815 |
|
Qianjin |
44660 |
|
Nanzi |
43765 |
|
Fengshan |
40189 |
|
Kaohsiung (Hunei) |
25680 |
|
Kaohsiung (Nanzi) |
2013 |
|
Kaohsiung (Zuoying) |
1330 |
|
Kaohsiung (Alian) |
670 |
|
Hunei |
220 |
|
Nanzi Export Processing Zone |
159 |
|
Kaohsiung (Linyuan) |
1 |
由上表可知非常有必要删除数量少的数据,这些通常是移动监测车、临时站点,或者是数据上传时的命名错误。最后挑选出5个地理位置和污染类型不同的站点,即Xiaogang (小港)、Linyuan (林园)、Qianjin (前金)、Zuoying (左营)和Meinong (美浓)。最终得到的数据总量为22万3971条。如下表展示了数据中个指标的含义:
|
指标 |
中文释义 |
|
date |
日期 |
|
sitename |
监测站点名称 |
|
AQI |
空气质量指数 |
|
pollutant |
首要污染物 |
|
status |
空气质量状态(等级) |
|
SO2 |
二氧化硫浓度(μg/m³) |
|
CO |
一氧化碳浓度(mg/m³) |
|
O3 |
臭氧(1小时平均)浓度(μg/m³) |
|
O3_8hr |
臭氧(8小时滑动平均)浓度(μg/m³) |
|
PM10 |
可吸入颗粒物(≤10μm)浓度(μg/m³) |
|
PM2.5 |
细颗粒物(≤2.5μm)浓度(μg/m³) |
|
NO2 |
二氧化氮浓度(μg/m³) |
|
NOx |
氮氧化物(NO+NO₂)浓度(μg/m³) |
|
NO |
一氧化氮浓度(μg/m³) |
|
windspeed |
风速(m/s) |
|
winddirec |
风向(°) |
|
CO_8hr |
一氧化碳(8小时滑动平均)浓度(mg/m³) |
|
PM2.5_avg |
细颗粒物平均浓度(μg/m³) |
|
PM10_avg |
可吸入颗粒物平均浓度(μg/m³) |
|
SO2_avg |
二氧化硫平均浓度(μg/m³) |
|
longitude |
经度(°) |
|
latitude |
纬度(°) |
|
siteid |
监测站点编号 |
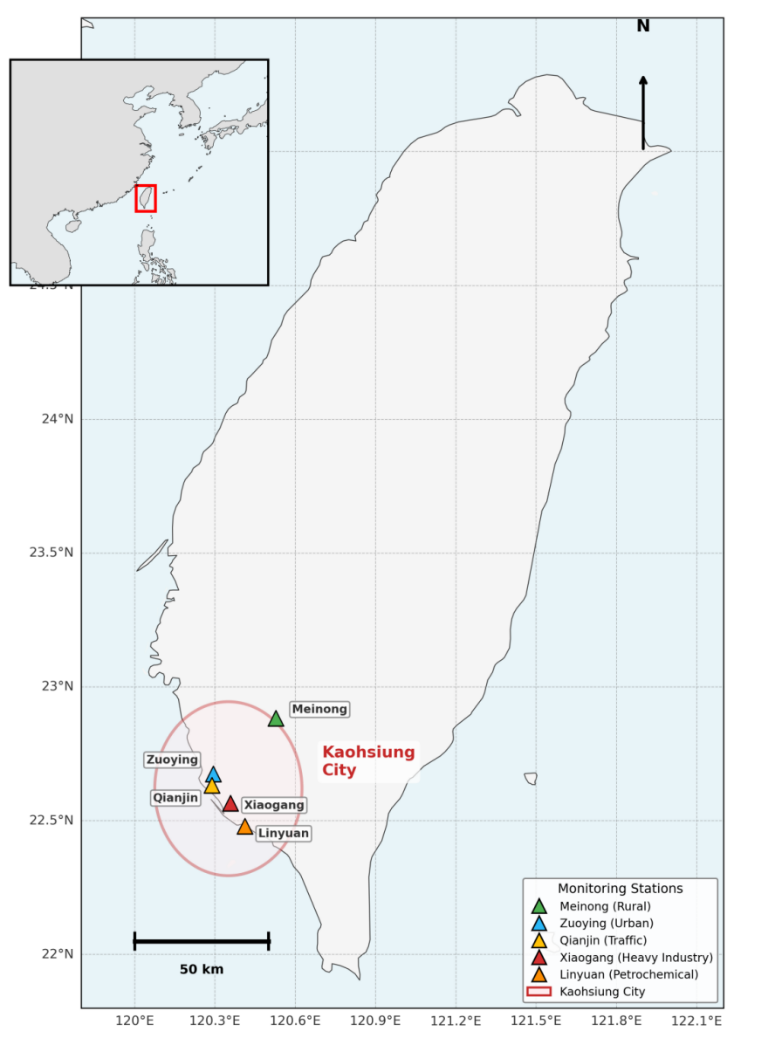
下图展示了本研究的高雄市空气质量监测站点分布。五个具有代表性的监测站点分别位于不同的地理区域和污染类型代表地。这些站点包括:位于高雄市重工业区的Xiaogang站(小港,钢铁/造船业),代表了高雄市的污染核心;Linyuan站(林园),位于石化工业区,位于高雄市最南端,特征鲜明;Qianjin站(前金),位于市中心,是交通污染的典型代表;Zuoying站(左营),为新兴的居住商业区,反映了混合型污染源的情况;以及Meinong站(美浓),位于农村/山区,用于评估地形及传输效应对空气质量的影响。
3.数据预处理
在空气质量研究中,特别是涉及机器学习和深度学习模型的应用中,数据预处理是衔接原始数据和高精度模型的关键桥梁。原始环境监测数据往往具有重复值、缺失值、异常值以及时间序列特性复杂等固有缺陷。这些问题若不加以处理,将直接导致模型训练过程不稳定、收敛速度慢,甚至产生有偏的、不可信的预测结果,从而严重影响研究的可靠性和决策的有效性。
首先,进行重复值的处理,去重的原则是同一站点的同一时间应该只有一条记录,经筛选发现重复记录数达到21346条,对多余出的数据进行去除,最后得到20万2625条数据。
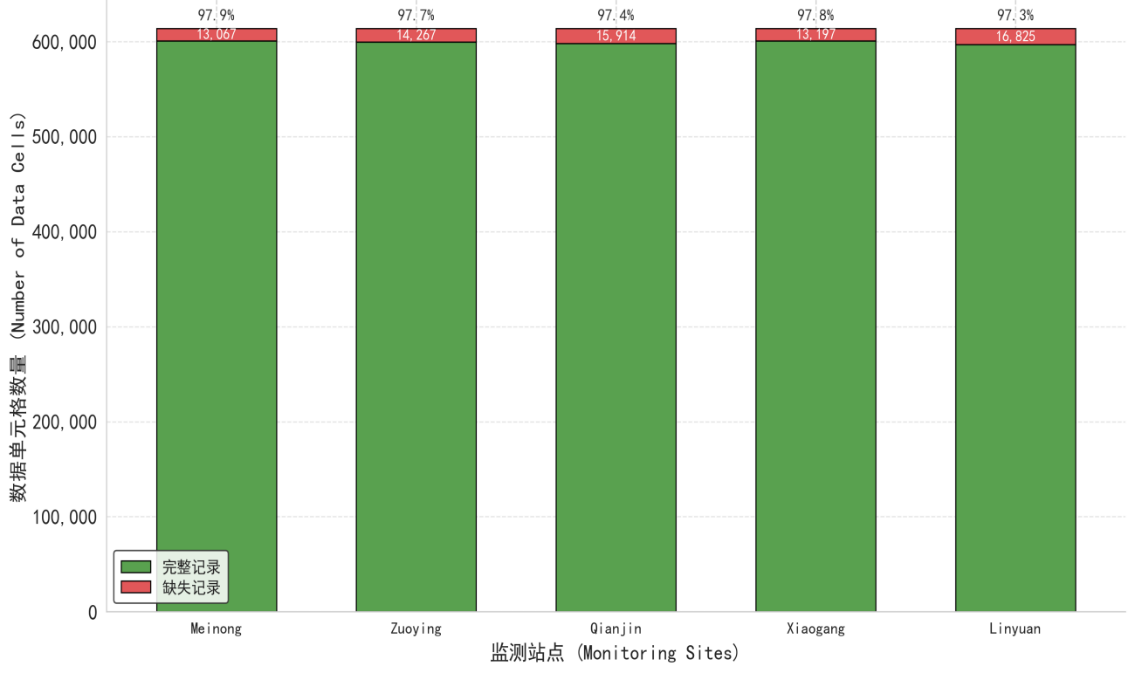
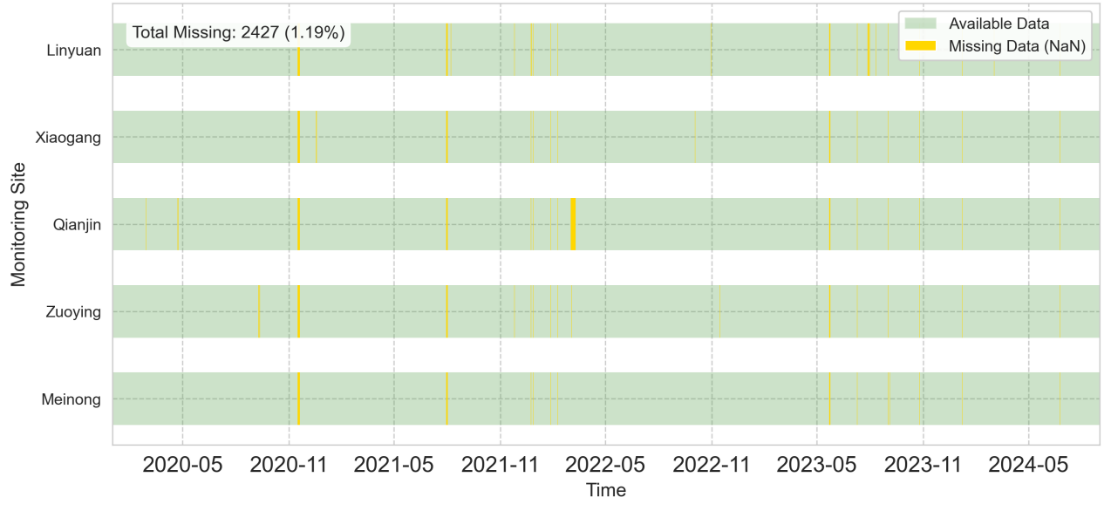
其次,是对缺失值的处理,数据选取的时间尺度是从2020年1月1日至2025年8月31日的小时数据,则一个监测站点就应该拥有40920条数据,5个监测站点合计20万4601条数据。故需将表格中每个监测站点空缺的时间点进行补充,再综合计算每个站点每个指标的缺失值数量。如下图所示,缺失最多的三个站点为Linyuan、Qianjin和Zuoying。
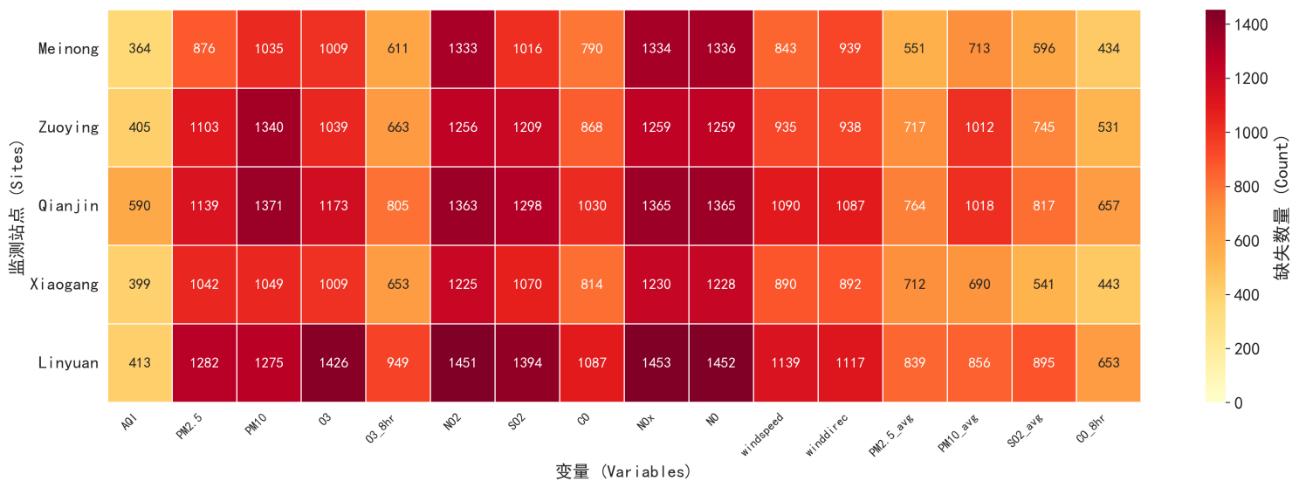
具体地,如下图显示了各站点各变量的数值型数据缺失情况,可以观察到SO2、PM10、NO2、NO和NOx的缺失情况较为严重,仍再可处理范围内,缺失量占总数的2%~3%之间。
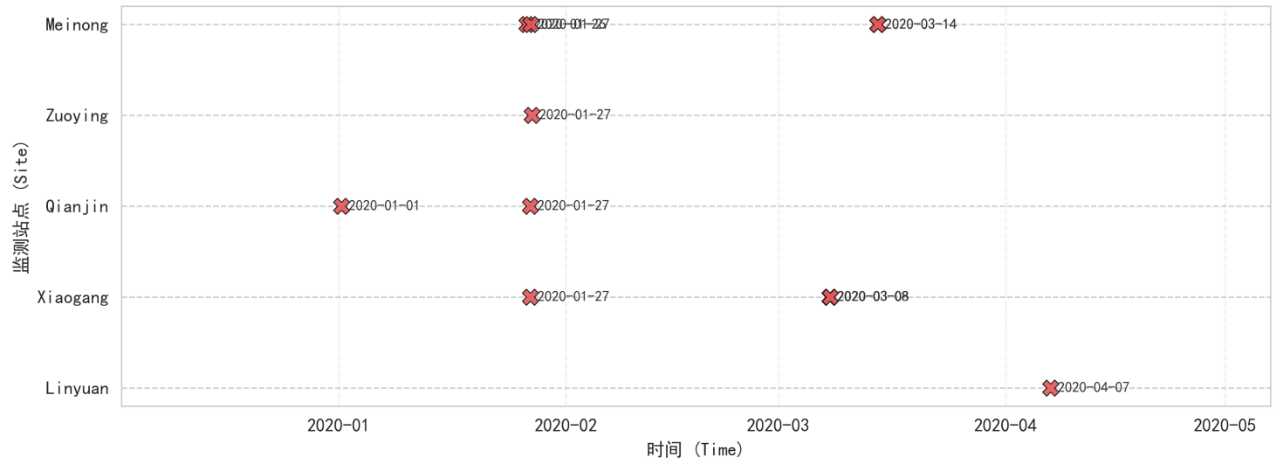
对数据的缺失情况进行探究发现,数据中存在长时间的缺失情况。每个监测站点均存在长时间或短时间的数据缺失情况,下表为展示了其中两个监测站点的部分长时间缺失情况:
|
站点 |
特征 |
缺失时间段 |
连续缺失数据长度 |
|
Meinong |
AQI |
2020-11-17 02:00:00 ~ 2020-11-19 13:00:00 |
60小时 |
|
2023-05-22 19:00:00 ~ 2023-05-24 17:00:00 |
47小时 |
||
|
PM2.5 |
2020-08-11 13:00:00 ~ 2020-08-14 14:00:00 |
74小时 |
|
|
PM10 |
2020-09-21 15:00:00 ~ 2020-09-25 11:00:00 |
93小时 |
|
|
winddirec |
2023-12-06 00:00:00 ~ 2023-12-20 22:00:00 |
359小时 |
|
|
Zuoying |
PM2.5 |
2020-08-03 15:00:00 ~ 2020-08-07 18:00:00 |
100小时 |
|
PM10 |
2023-07-24 14:00:00 ~ 2023-07-29 11:00:00 |
118小时 |
|
|
PM2.5_avg |
2021-06-04 14:00:00 ~ 2021-06-08 21:00:00 |
104小时 |
本文使用一种基于时间序列特征的严格分级缺失值填充策略。对于短期随机缺失和长期连续缺失问题,短期缺失(≤6小时)使用使用线性插值,短时间缺失空气污染物具有很强的自相关性,短时间内不会突变。线性插值最简单且误差最小。长期缺失(> 6小时)则放弃线性插值,使用历史同期均值填充,因为长期缺失可能跨越关键的时间事件,空气质量具有显著的季节性和日周期性,而历史周期性均值更能反映该时间点的典型数值。通过这种分级填充确保了短期缺失能够保持时序连续性,而长期缺失则能够更好地反映污染物浓度在季节和日周期上的典型周期模式,从而提高了填充数据的代表性和模型的可靠性。
在填补缺失值时发现PM2.5指标列存在非数值情况,即“ND”,如下图所示ND通常意味着污染物浓度低于仪器的最低检测限,或者是仪器故障没读数。共11个非数值数据,直接将其转换为NaN,然后参与到“插值/历史同期填充”流程。
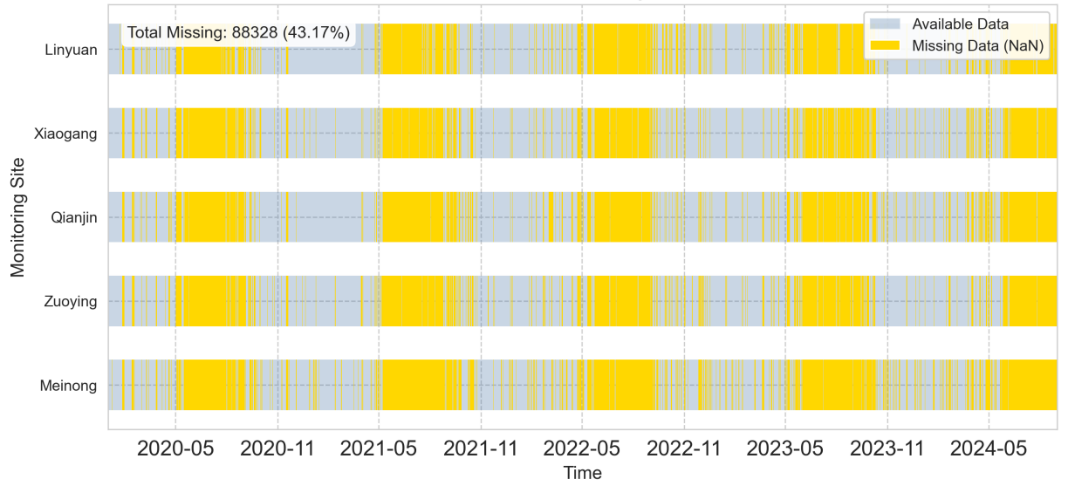
仍剩余pollutant与status特征还未处理其缺失情况,缺失情况如下图所示。虽然显示其缺失情况高达43.17%,但这并不都是缺失,因为该列是污染物情况,不是每天都被高污染物影响,status数据缺失处的填补要根据AQI列来决定。
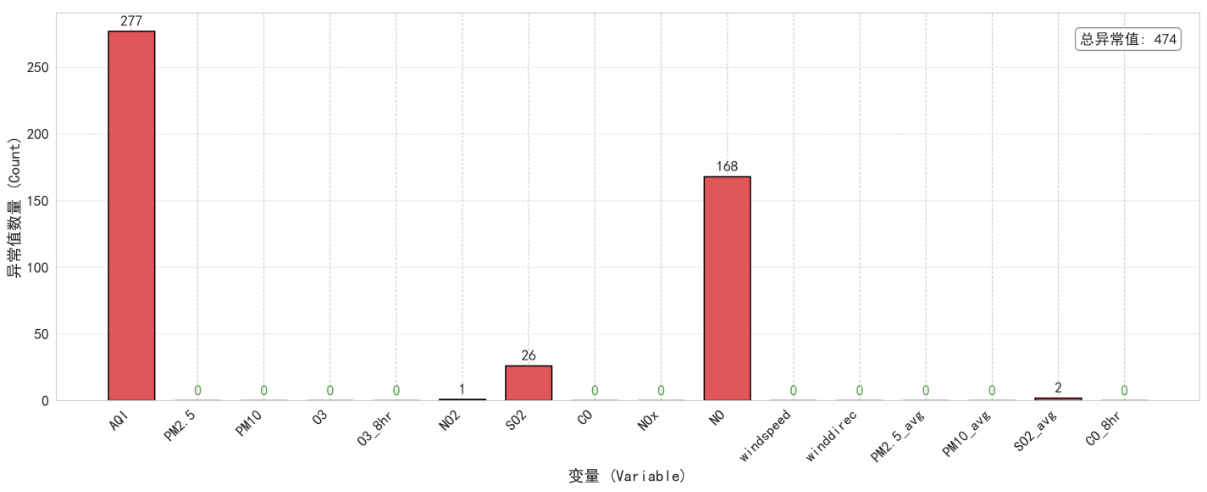
最后,由于数据中的异常值会影响对pollutant与status中类别情况的判断,故考虑先对数据进行异常值处理,数值型特征数据若按照IQR方法进行剔除数据,则会将许多有价值的数据删去。故本文采用物理范围法对异常值进行剔除,由于全部数值型特征均未超过上界,但存在部分特征的数值小于下界。如下图所示,共计474个异常值,其中AQI有277个异常值,NO2有1个异常值,SO2有26个异常值,NO有168个异常值,SO2_avg有2个异常值。将其全部转换未Nan值,使用分级缺失值填充策略进行填补。
最后,对pollutant与status特征进行处理。status特征缺失数量为2427,pollutant特征缺失数量为88328。因为status数据缺失处的填补要根据AQI来决定,如下表所示:
|
空气质量等级 |
AQI数值范围 |
|
Good |
AQI ≤ 50 |
|
Moderate |
51 ≤ AQI ≤ 100 |
|
Unhealthy for Sensitive Groups |
101 ≤ AQI ≤ 150 |
|
Unhealthy |
151 ≤ AQI ≤ 200 |
|
Very Unhealthy |
201 ≤ AQI |
据此,status特征的缺失值已填补完成,最后个类别数据数量如下表所示。status列中等级为“Good”所对应的pollutant列应为无污染,所以对pollutant列进行填充“Zero Pollution”,填补过后pollutant特征仅缺失1263条数据。
|
空气质量等级 |
样本数量(条) |
|
Moderate |
96395 |
|
Good |
87065 |
|
Unhealthy for Sensitive Groups |
19597 |
|
Unhealthy |
1541 |
|
Very Unhealthy |
2 |
对于首要污染物(Pollutant)缺失值的填补,本研究采用空气质量分指数(IAQI)计算方法进行判定。根据美国环境保护署和台湾环保署发布的空气质量指标标准,各污染物的IAQI通过分段线性插值公式计算:
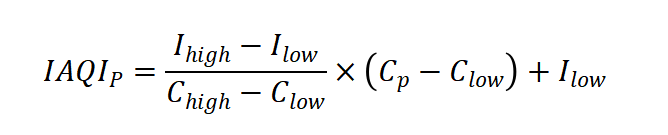
本研究计算了PM2.5、PM10、O3(小时值及8小时滑动平均)、NO2和SO2共六种污染物的IAQI值,并将IAQI最大值对应的污染物判定为该时刻的首要污染物。当AQI≤50且无明显首要污染物时,将其标记为“Zero Pollution”。该方法共填补了1263条缺失记录,确保了数据的完整性和分析的可靠性。如下表显示了这1263条缺失数据的去向,其中,主要还是流入PM2.5中。如下表展示了完全填补后的污染物分布情况。
|
首要污染物 |
样本数量(条) |
|
PM2.5 |
1145 |
|
Ozone (8hr) |
97 |
|
PM10 |
21 |
|
污染物 |
样本数量(条) |
|
PM2.5 |
101735 |
|
Zero Pollution(无污染) |
87065 |
|
Ozone (8hr) |
13633 |
|
PM10 |
1790 |
|
Nitrogen Dioxide (NO2) |
295 |
|
Sulfur Dioxide (SO2) |
78 |
空气质量数据的预处理阶段完成,暂告一段落再开启建模分析!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 26
26 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)