【Agent论文精读】Memory in the Age of AI Agents
论文标题:Memory in the Age of AI Agents
arXiv链接:https://arxiv.org/pdf/2512.13564
Github链接:https://github.com/Shichun-Liu/Agent-Memory-Paper-List
1 Introduction
这篇论文的“1 Introduction”(引言)部分主要介绍了智能体记忆(Agent Memory)的研究背景、现有研究面临的挑战,以及本文旨在提出的全新分类框架。具体来说,引言讲了以下几个核心内容:
1. 记忆是大模型智能体的核心能力
- 过去两年中,大语言模型(LLMs)已经演变为强大的AI智能体,在深度研究、软件工程和科学发现等领域展现出巨大潜力 。
- 业界逐渐达成共识,一个真正的智能体除了LLM骨干外,还应具备推理、规划、感知、记忆和工具使用等能力 。
- 其中,“记忆”被视为智能体的基石,它将参数无法快速更新的静态LLM转化为能够通过与环境交互进行持续适应和演进的动态智能体 。
- 这种记忆能力对于个性化聊天机器人、推荐系统等实际应用,以及实现通用人工智能(AGI)的持续进化都至关重要 。
2. 为什么需要提出新的记忆分类法(研究动机)
- 现有分类法的局限性:早期的分类框架在快速的方法论进步面前已经过时,无法全面反映当前研究的广度和复杂性(例如2025年涌现的从以往经验中提取可重用工具等新方向并未被充分涵盖) 。
- 概念碎片化:随着相关研究的爆发式增长,“智能体记忆”在具体实现、目标和假设上差异巨大,各种术语(如陈述性、情景性、语义性、参数化记忆等)层出不穷,导致了概念上的模糊 。
- 因此,当前迫切需要一个连贯的分类法来调和现有定义并统一这些新兴概念 。
3. 本文的核心问题与“形式-功能-动态”框架
引言概述了这篇综述试图解答的关键问题,并提出了一个三维视角的统一框架:
- 概念界定:论文首先明确了智能体记忆的范围,并将其与LLM内部记忆、检索增强生成(RAG)和上下文工程等相关概念进行了详细区分 。
- 形式(Forms - 记忆的载体是什么?):探讨了记忆的架构形式,主要分为Token级别记忆(Token-level)、参数化记忆(Parametric)和潜在记忆(Latent memory)三种主流实现 。
- 功能(Functions - 为什么需要记忆?):超越了传统的“长/短期记忆”分类,提出了更细粒度的功能分类,包括记录互动知识的“事实记忆”、提升问题解决能力的“经验记忆”,以及管理单次任务工作区的“工作记忆” 。
- 动态(Dynamics - 记忆如何运作?):分析了在智能体与环境交互的生命周期中,记忆是如何形成、检索和演进的 。
4. 资源汇总与未来展望
- 为了支持经验研究和实际开发,论文汇总了一套全面的代表性基准测试(Benchmarks)和开源记忆框架资源 。
- 引言还前瞻性地指出了智能体记忆的未来前沿方向,包括面向自动化的记忆设计、强化学习(RL)与记忆系统的深度融合、多模态记忆、多智能体系统中的共享记忆,以及可信度问题 。
2 Preliminaries: Formalizing Agents and Memory
论文的第2部分“Preliminaries: Formalizing Agents and Memory”(预备知识:智能体与记忆的形式化)主要对基于大语言模型(LLM)的智能体及其记忆系统进行了数学和概念上的形式化定义,并对容易混淆的相关概念进行了严谨的界定与辨析。具体包括以下三个核心部分:
1. LLM智能体系统的形式化 (LLM-based Agent Systems)
- 环境与观察:定义了智能体所处的环境状态空间、状态转移模型,以及智能体在每一步接收到的观察(包含可见的历史交互记录)和具体的任务设定。
- 异构的动作空间:指出大模型智能体的动作不仅限于生成自然语言文本,还包括高度异构的动作:调用外部工具/API、输出规划和任务分解、直接控制和操作外部环境,以及与其他智能体进行通信。
- 交互轨迹:将智能体的完整执行过程形式化为环境观察、记忆检索、LLM计算和动作执行交织的连续轨迹。
2. 智能体记忆系统的形式化 (Agent Memory Systems)
- 将记忆系统定义为一个随着时间不断演进的记忆状态矩阵(可以是文本、键值对、图结构等任何形式)。
- 记忆的三大生命周期操作:
- 记忆形成 (Formation):从交互轨迹(如工具输出、反思、环境反馈)中提取有未来利用价值的信息转化为记忆候选。
- 记忆演进 (Evolution):将新提取的记忆整合到现有记忆库中,进行去重、解决冲突或剔除低价值信息。
- 记忆检索 (Retrieval):根据当前观察和任务上下文,构建查询并提取相关的记忆信号供大模型使用。
- 长短期记忆的本质:该部分特别指出,智能体的“短期记忆”和“长期记忆”并不一定需要架构上的物理分离。它们仅仅是由上述三大操作(形成、演进、检索)在任务内和跨任务间的不同调用频率和模式(Temporal Roles)所产生的效果。
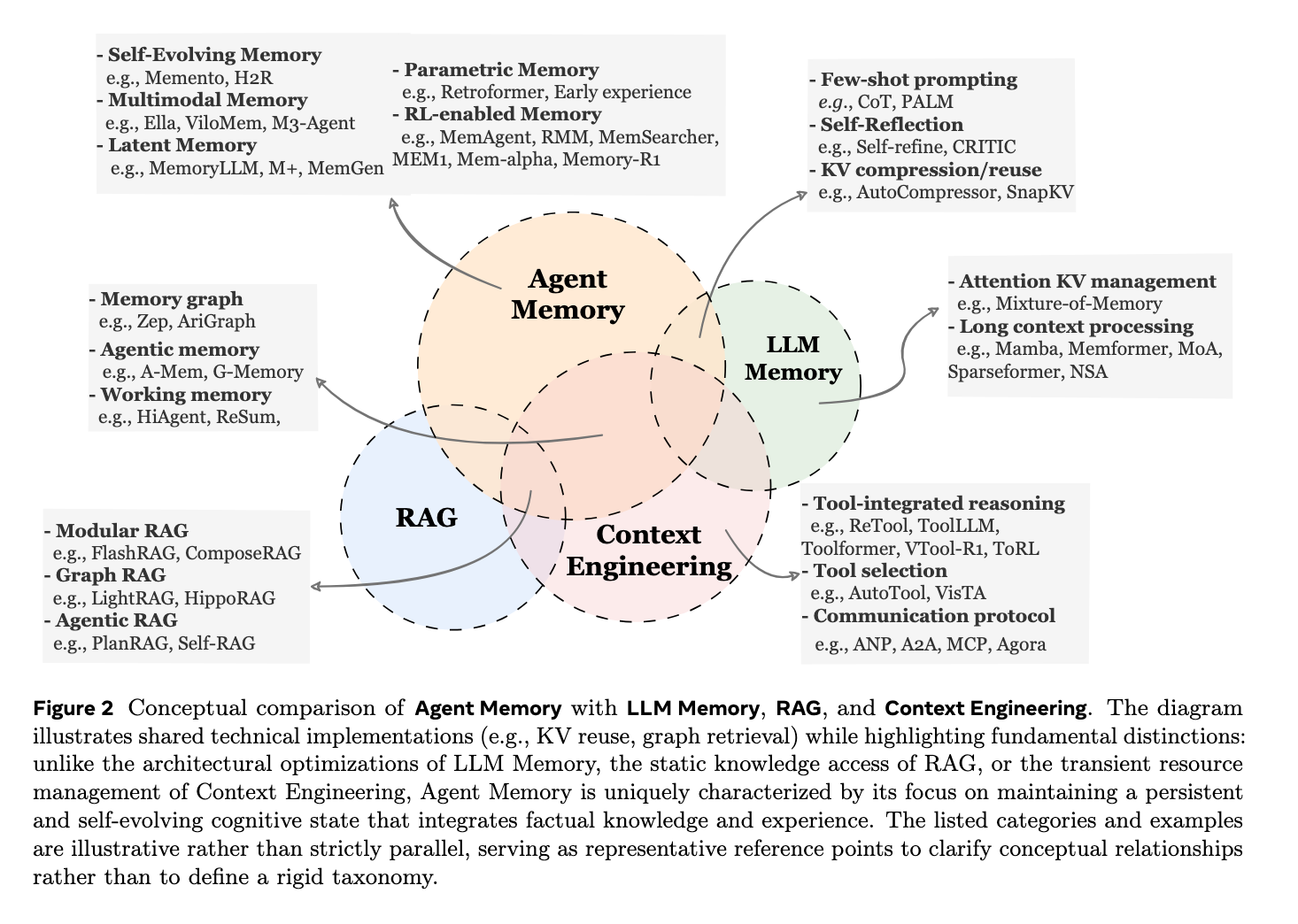
3. 智能体记忆与其他关键概念的辨析 (Comparing Agent Memory with Other Key Concepts)
这是该部分非常重要的一环,旨在消除学术界和工业界的概念碎片化:
- 智能体记忆 vs. LLM内部记忆 (LLM Memory):真正的“LLM记忆”研究应指代模型架构层面的修改(如KV Cache压缩、长上下文机制设计、模型权重更新)。而很多自称为“LLM记忆”的系统(如保存用户偏好、维护对话状态)实际上属于智能体记忆的范畴,因为它们提供的是用于决策演进的外部知识库。
- 智能体记忆 vs. 检索增强生成 (RAG):虽然底层技术(如向量检索、图检索)相似,但应用场景和目标不同。经典的RAG主要为单次推理任务从外部静态知识库中提取信息(外挂辅助);而智能体记忆是在多轮、跨任务的交互中,通过自身经验的积累,持续自我更新和演进的内部记忆库。
- 智能体记忆 vs. 上下文工程 (Context Engineering):上下文工程是一种“资源管理范式”,关注如何在有限的模型上下文窗口内高效打包、压缩和调度信息。而智能体记忆是一种更宏大的“认知范式”,关注的是决定智能体“知道什么”、“经历了什么”以及如何维持持久的身份和连贯性。
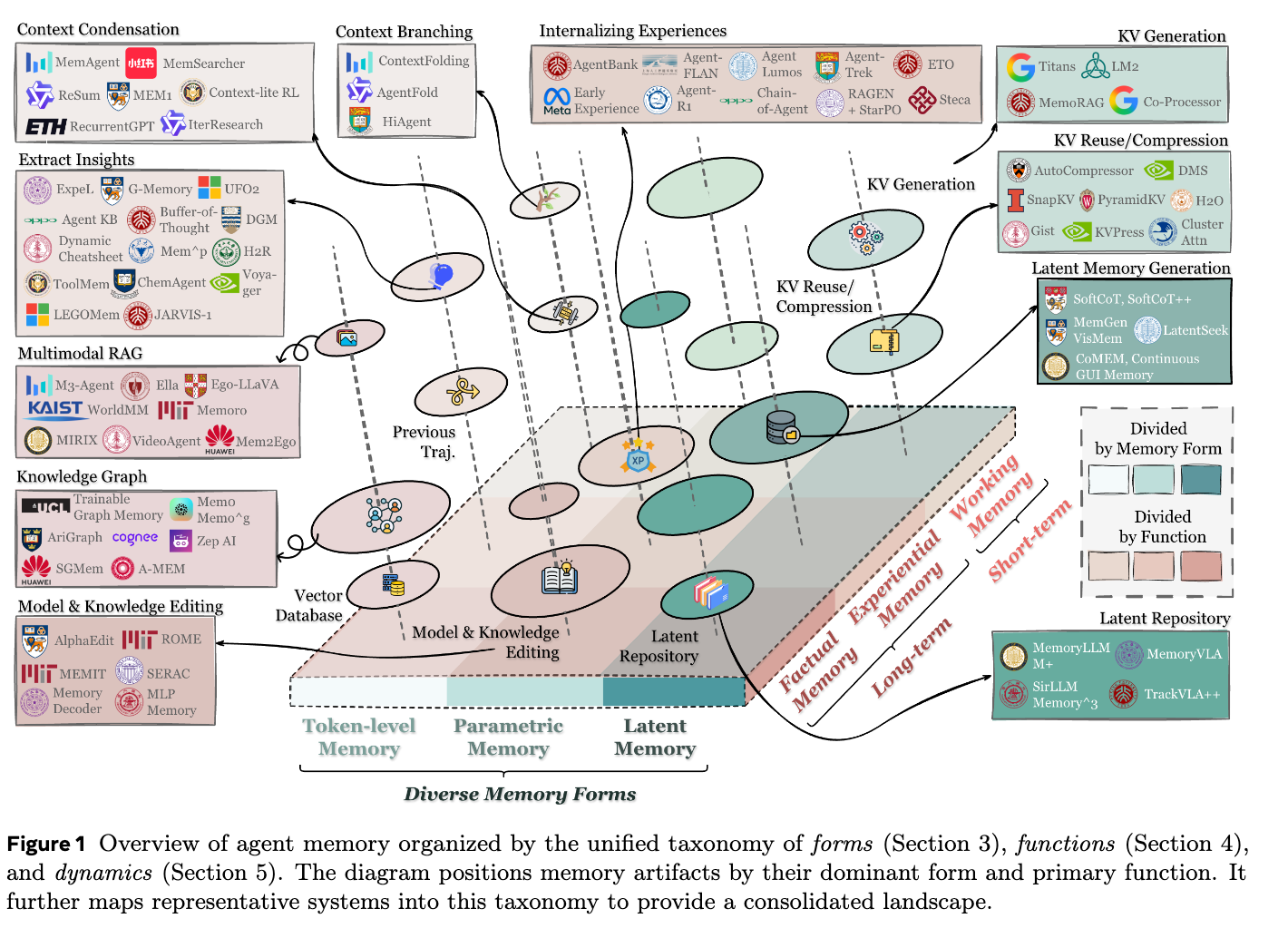
3 Form: What Carries Memory?
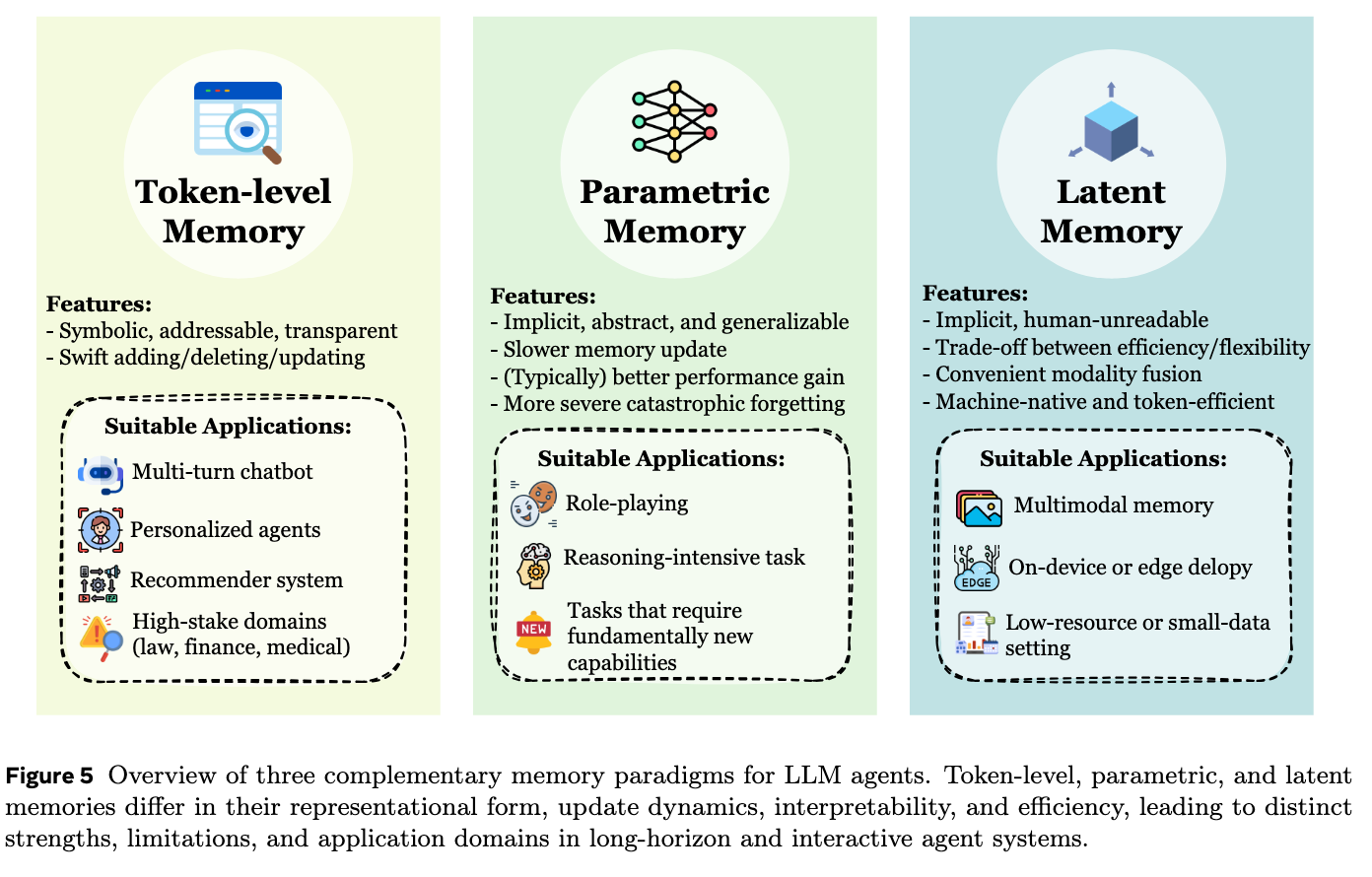
论文的第3部分“Form: What Carries Memory?”(形式:记忆的载体是什么?)主要探讨了智能体记忆在架构和表示上的具体存在形式。根据记忆存储的位置及其信息形态,作者将智能体记忆划分为三大主要类别,并在最后讨论了它们的适用场景:
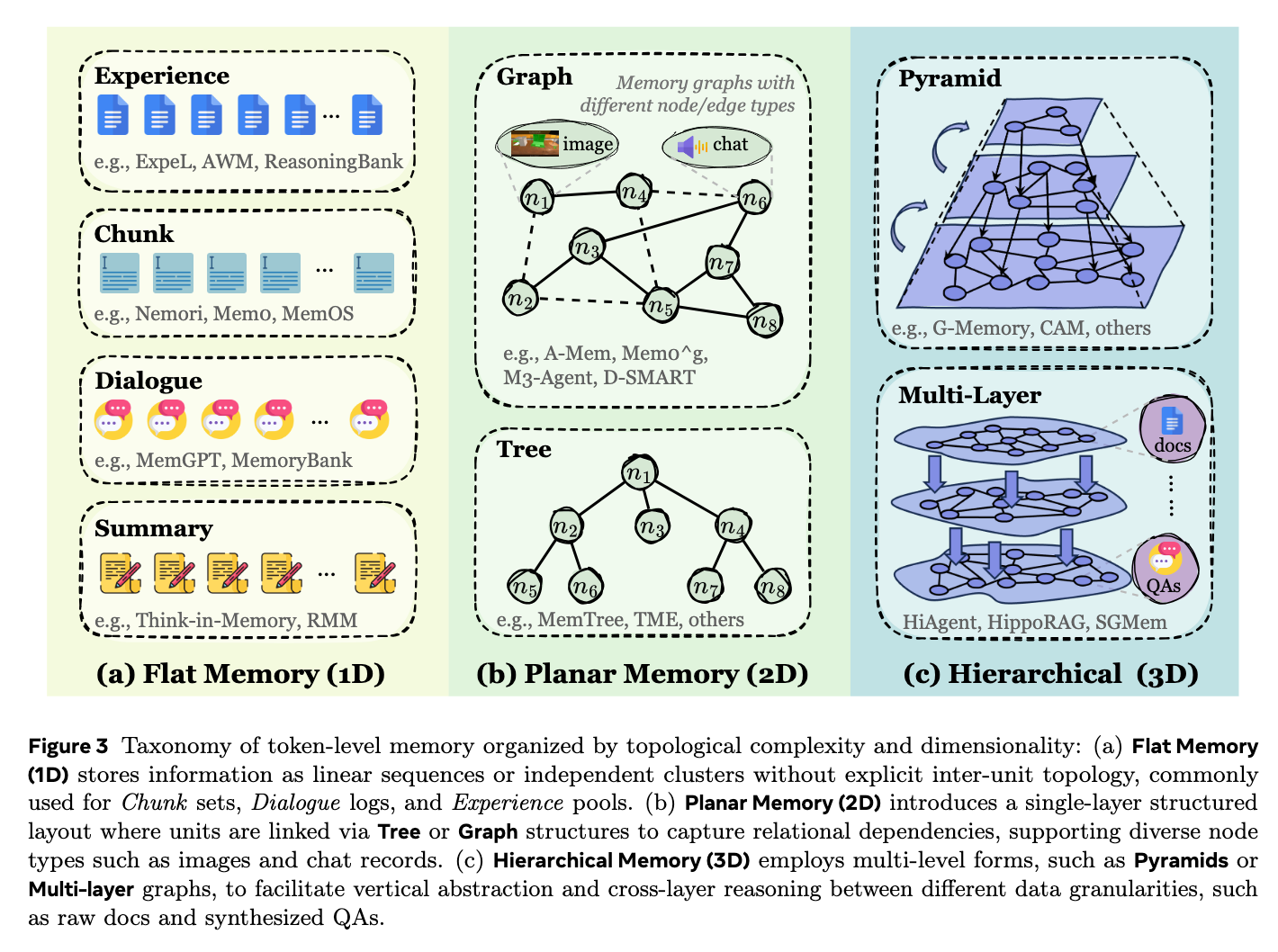
1. Token级别记忆 (Token-level Memory) 这是最常见的一类记忆,信息被存储为外部可见、离散且可独立访问、修改和重建的单元 。这些单元不仅限于文本Token,还可以是视觉或音频等可以被显式操作的离散元素 。根据记忆单元之间拓扑结构的复杂度,它被进一步细分为三种:
- 扁平记忆 (Flat Memory, 1D):单元之间没有显式的拓扑或语义依赖关系,信息以列表、序列或数据块的形式进行线性积累 。优点是简单易扩展,但缺乏结构化关联。
- 平面记忆 (Planar Memory, 2D):在单一层级内引入了显式的组织结构(如树状、图状或表格),通过节点建立关联 。这使得记忆从单纯的“存储”升级为“组织”,支持更复杂的逻辑和图遍历检索。
- 层次记忆 (Hierarchical Memory, 3D):跨越多个层级的结构化记忆(如金字塔或多层图),层与层之间相互链接 。它支持从原始观察到底层事件,再到高层抽象概念的多维度、跨层推理 。
2. 参数化记忆 (Parametric Memory) 与外部可见的Token级别记忆不同,这种记忆将信息直接隐式地编码在模型参数的统计模式中,并在前向计算时发挥作用 。根据记忆是否修改基础模型,它分为两类:
- 内部参数记忆 (Internal Parametric Memory):将知识或经验直接编码并更新到模型原始的权重和偏置中 。
- 外部参数记忆 (External Parametric Memory):将记忆存储在附加的参数集(如Adapter、LoRA模块或代理模型)中,这种方式可以在不改变原始模型权重的情况下引入新参数来承载记忆 。
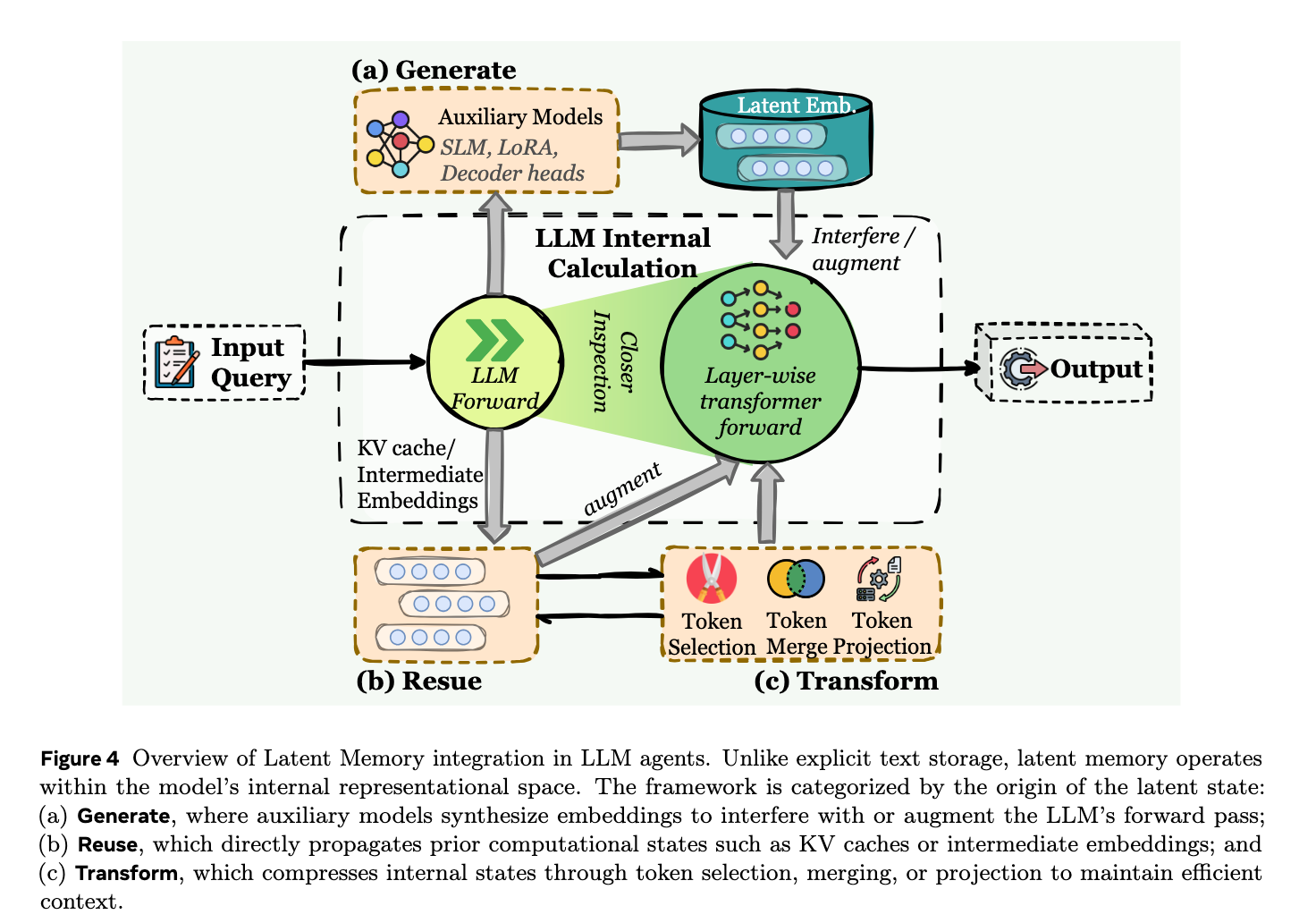
3. 潜在记忆 (Latent Memory) 这种记忆存在于模型内部的隐藏状态、连续表示(如KV Cache、连续向量空间)中 。它对人类来说是不可读的,但具有极高的计算效率和机器原生性 。根据潜在状态的处理方式,它被分为三种核心操作:
- 生成 (Generate):由独立的模型或模块生成新的潜在表示(如Summary Vectors或特殊的Memory Tokens),作为可重用的记忆注入给智能体 。
- 重用 (Reuse):不进行额外生成,直接继承和复用模型先前的计算状态(最典型的就是原始KV Cache的复用) 。
- 转换 (Transform):将现有的潜在状态通过token选择、合并或投影等方式进行压缩和转换,以保留核心信息并减少上下文占用 。
4. 适配与应用场景 (Adaptation)
在第3.4节中,论文进一步探讨了上述三种记忆形式在实际应用中的匹配度:
- Token级别记忆:具有符号化、可寻址和高度透明的特性,适合需要明确推理、高频更新以及要求可解释性的高风险领域(如医疗、法律),也常用于多轮对话机器人、个性化智能体和推荐系统 。
- 参数化记忆:隐式、抽象且泛化能力强,更适合需要将知识内化为模型本能的场景,如角色扮演任务以及对推理要求极高的复杂任务 。
- 潜在记忆:在灵活性和高效率间取得了平衡,便于跨模态融合,特别适合机器原生处理、多模态记忆管理,以及计算资源受限的端侧或边缘部署场景 。
4 Functions: Why Agents Need Memory?
论文的第4部分“Functions: Why Agents Need Memory?”(功能:为什么智能体需要记忆?)从功能性的角度,探讨了记忆在智能体系统中的核心作用。作者指出,记忆不是一个单一的组件,而是一组不同的功能系统,它们共同回答了“为什么需要记忆”的问题。
该部分跳出了传统的“长/短期记忆”的粗略划分,将智能体记忆的功能细分为三大支柱:
1. 事实记忆(Factual Memory):智能体知道什么?
事实记忆是智能体的陈述性知识库,用于存储关于过去事件、用户特定信息以及外部环境状态的明确事实。它的主要目的是确保智能体在长期交互中的一致性、连贯性和适应性。进一步细分为:
- 用户事实记忆(User factual memory):保存关于特定用户的可验证事实,包括身份、偏好、日常习惯和历史承诺等。这有助于保持对话的连贯性,避免重复提问或自相矛盾,并在多轮对话中保持目标的一致性,防止意图偏移。
- 环境事实记忆(Environment factual memory):存储独立于用户的外部世界实体和状态,如长文档、代码库和工具等。这能确保领域知识的持久性,并在多智能体协作中作为共享记忆访问点,减少冗余并保持状态一致。
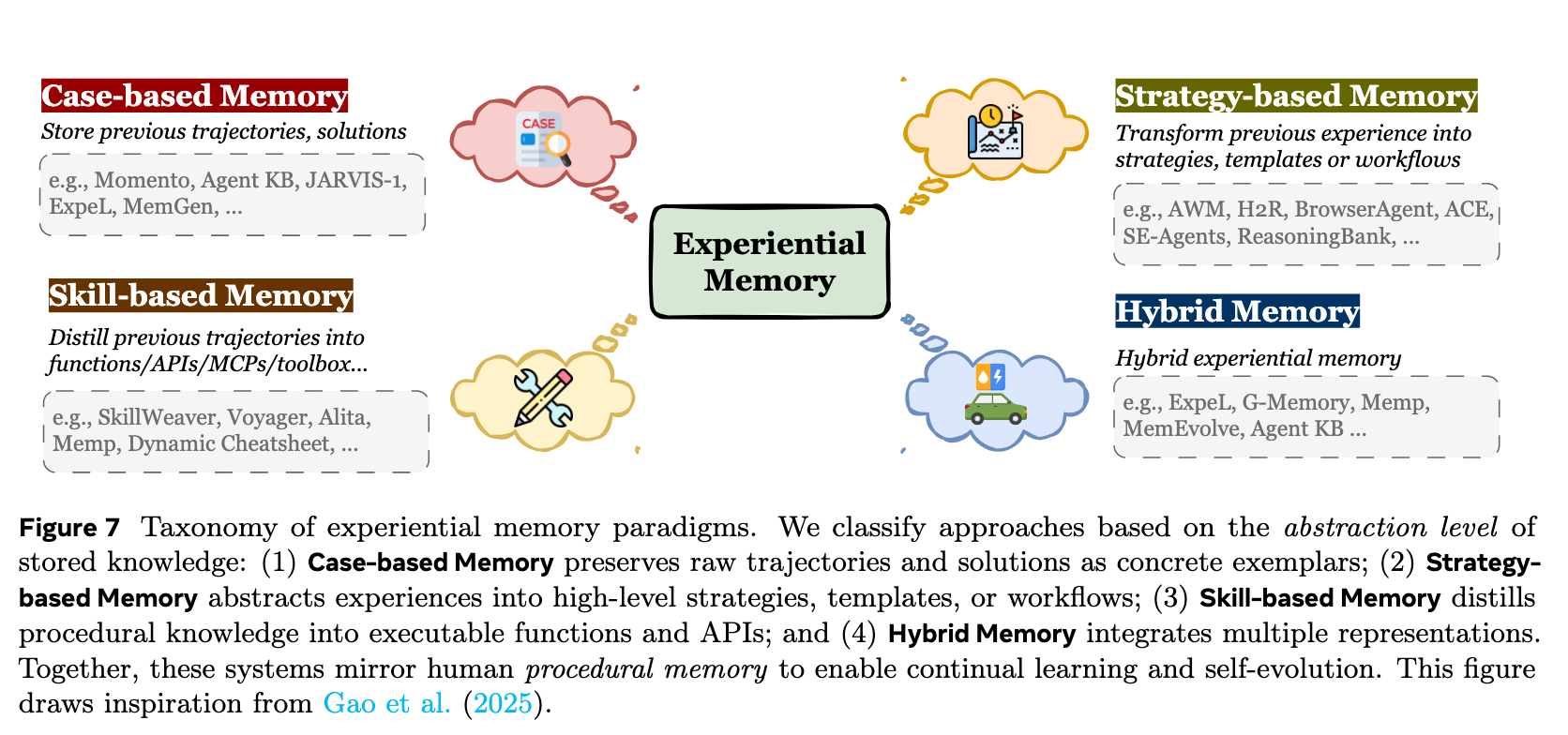
2. 经验记忆(Experiential Memory):智能体如何进化?
经验记忆封装了智能体的程序性和策略性知识。它让智能体能够从过去的执行轨迹、失败和成功中进行抽象,从而实现持续学习和自我进化。根据抽象程度的不同,细分为:
- 基于案例的记忆(Case-based Memory):存储未经深度处理的原始历史执行事件记录,保留了具体的情境-结果映射,以便直接重放或作为上下文示例进行模仿。
- 基于策略的记忆(Strategy-based Memory):从过去的经验中提炼出可迁移的推理模式、工作流(Workflows)和高层洞察。它脱离了具体情境,帮助智能体在面对多样化任务时提供高层次的规划指导。
- 基于技能的记忆(Skill-based Memory):将抽象的策略转化为可执行的操作能力,包括代码片段、函数脚本以及标准化的 API / MCP 调用。这是智能体实际与环境交互的执行基础。
- 混合记忆(Hybrid memory):结合上述多种形式,在具体案例的精确证据与策略规则的泛化逻辑之间取得平衡。
3. 工作记忆(Working Memory):智能体现在在思考什么?
工作记忆是一个容量有限、动态控制的“暂存区”,用于在单次任务或会话中主动管理当前的上下文信息,解决模型上下文窗口有限的问题。根据交互动态分为:
- 单轮工作记忆(Single-turn Working Memory):主要应对单次前向传播中的海量输入,如长文档或高维多模态流。核心机制包括“输入压缩”(剔除冗余内容)和“观察抽象”(将原始数据转化为结构化语义)。
- 多轮工作记忆(Multi-turn Working Memory):应对长期交互中的历史状态累积问题。核心机制包括状态合并(不断压缩流数据更新到一个固定大小的状态中)、层次化折叠(将完成的子任务折叠为摘要)以及认知规划(维护和更新一个前瞻性的计划或世界模型)。
总结来说,这三种功能构成了一个完整的认知循环:智能体通过事实记忆和经验记忆的持久化存储来进行编码和提取,并在工作记忆的动态空间中完成当下的推理与决策。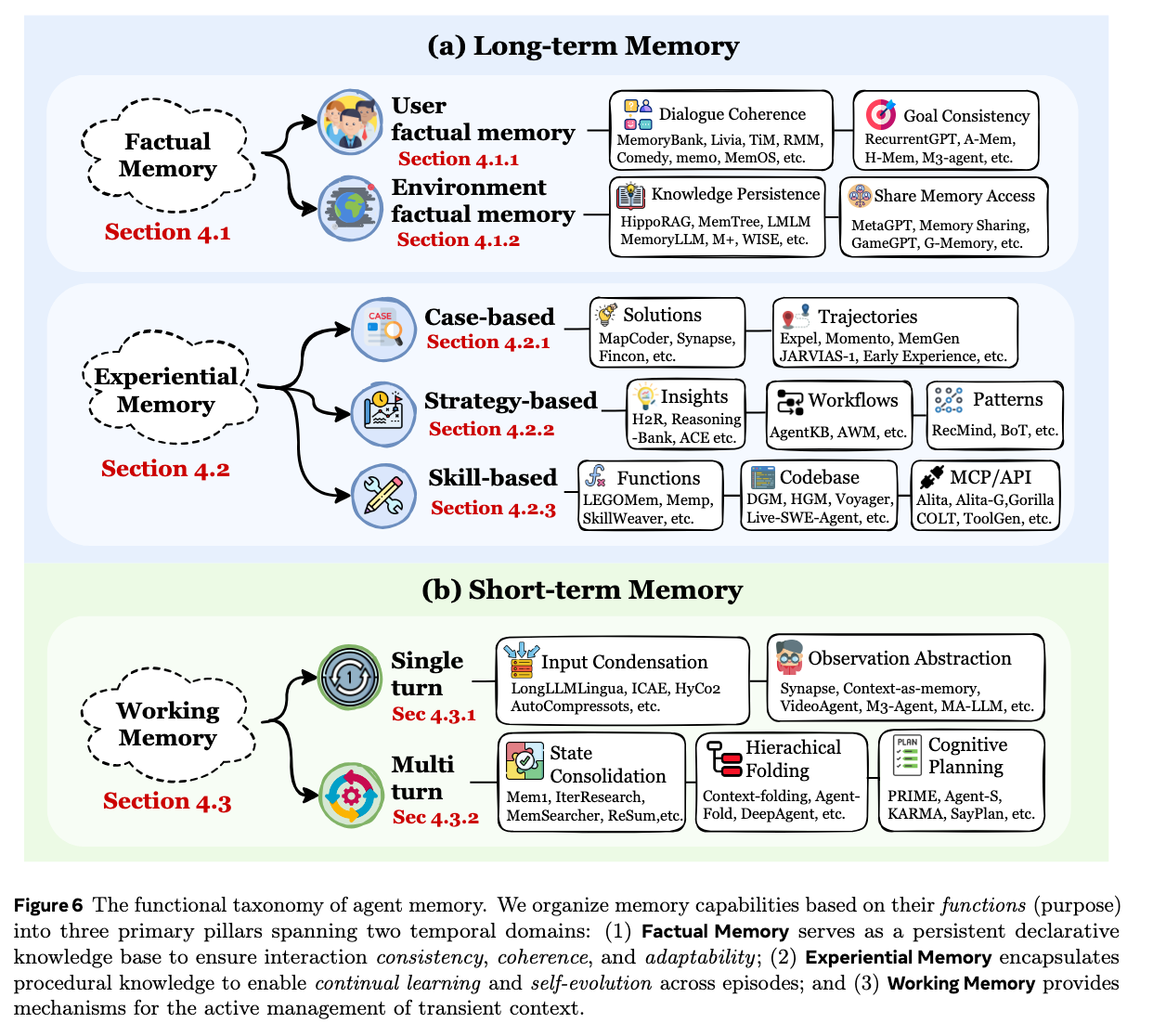
5 Dynamics: How Memory Operates and Evolves?
论文的第5部分“Dynamics: How Memory Operates and Evolves?”(动态:记忆如何运作与演进?)聚焦于智能体记忆的生命周期管理。作者强调,智能体的记忆不仅是静态的数据存储库,更是一个随着时间推移不断适应、重组和优化的动态系统。
该部分将记忆的运作机制拆解为三个相互关联的核心过程:
1. 记忆形成 (Memory Formation):从原始交互中提取知识
这一阶段解决的是“如何将源源不断的感知流、对话历史和执行轨迹转化为高质量记忆单元”的问题。
- 智能体需要从冗杂的原始上下文中,识别并提取出具有未来复用价值的关键信息。
- 核心方法包括:直接记录(原样保存关键事件)、总结与压缩(将冗长的交互转化为精炼的摘要)、以及自我反思(Self-reflection/Self-evaluation)。在反思过程中,智能体会像人类一样,分析过去行为的成功或失败原因,并从中提炼出高层次的经验、策略或规则。
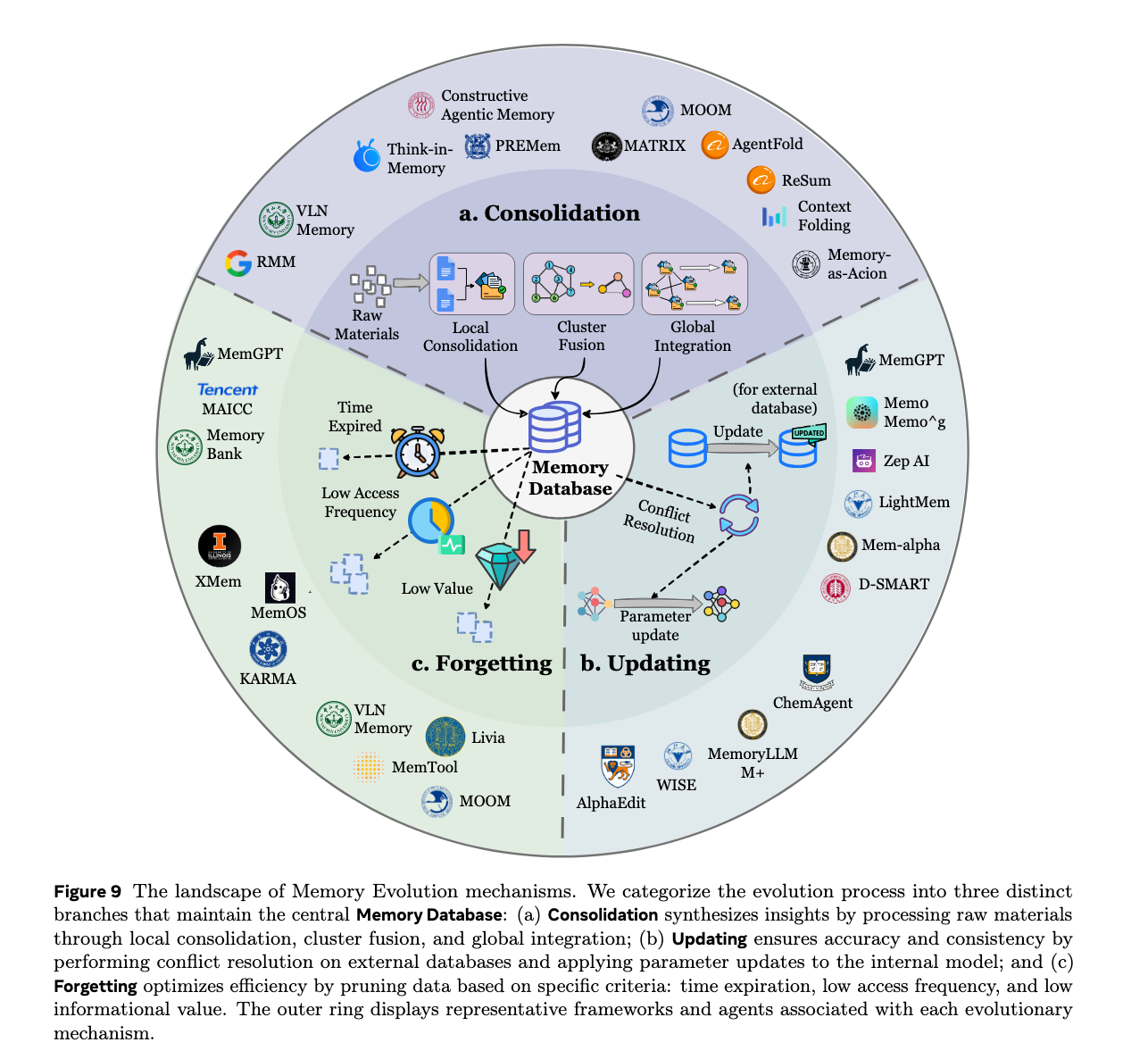
2. 记忆演进 (Memory Evolution):维护记忆系统的连贯与高效
随着智能体不断与环境交互,其记忆库会迅速膨胀,并不可避免地产生冗余、冲突或过时的信息。记忆演进旨在动态地管理和维护整个记忆库的质量。
- 整合与合并 (Consolidation & Merging):将碎片化或结构相似的短期记忆整合起来,泛化为更高级别的事实或全局策略。
- 更新与冲突解决 (Updating & Conflict Resolution):当感知到外部状态改变或用户偏好发生变化(例如用户搬到了新城市)时,智能体需要解决新旧记忆之间的矛盾,覆写过时信息,确保知识库在事实上的绝对一致。
- 遗忘机制 (Forgetting/Pruning):受人类认知机制启发,系统会主动淘汰那些低价值、长时间未使用或与核心目标无关的记忆。这不仅能防止“记忆过载”,还能显著降低后续的检索成本并减少大模型的上下文干扰。
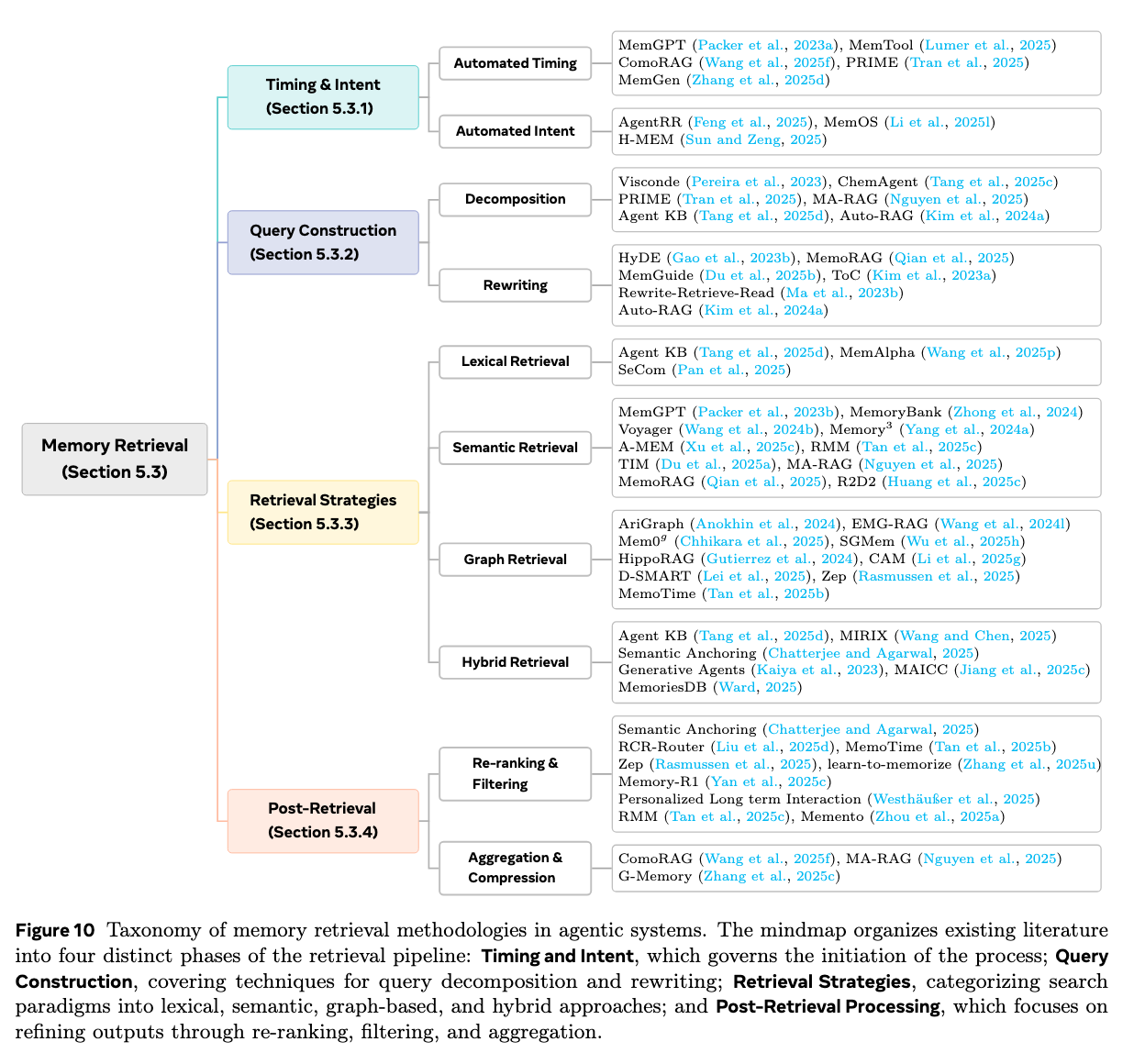
3. 记忆检索 (Memory Retrieval):在正确的时间提取正确的信息
这一阶段探讨了智能体如何在特定的任务上下文中,从庞大的记忆库中激活并提取最相关的经验或事实。
- 检索触发机制:系统需要决定“何时检索”。这可以是高频的主动检索(例如每次对话生成前),也可以是按需触发的被动检索(例如当智能体面对陌生任务、感到置信度低或遇到特定触发条件时才去调用记忆)。
- 检索策略:详细梳理了各种检索范式,包括基于关键词的词法检索、主流的基于向量语义相似度的密集检索(Dense Retrieval),以及能够捕捉实体间复杂拓扑关系的基于图的检索(Graph-based Retrieval)。先进的智能体系统甚至会采用混合检索策略,或直接让大语言模型充当“检索路由器”,根据当前任务的复杂度动态调整查询方式。
总体而言,这三个动态过程(形成吸纳新知、演进维持秩序、检索反哺决策)共同构成了智能体持续学习和进化的认知闭环。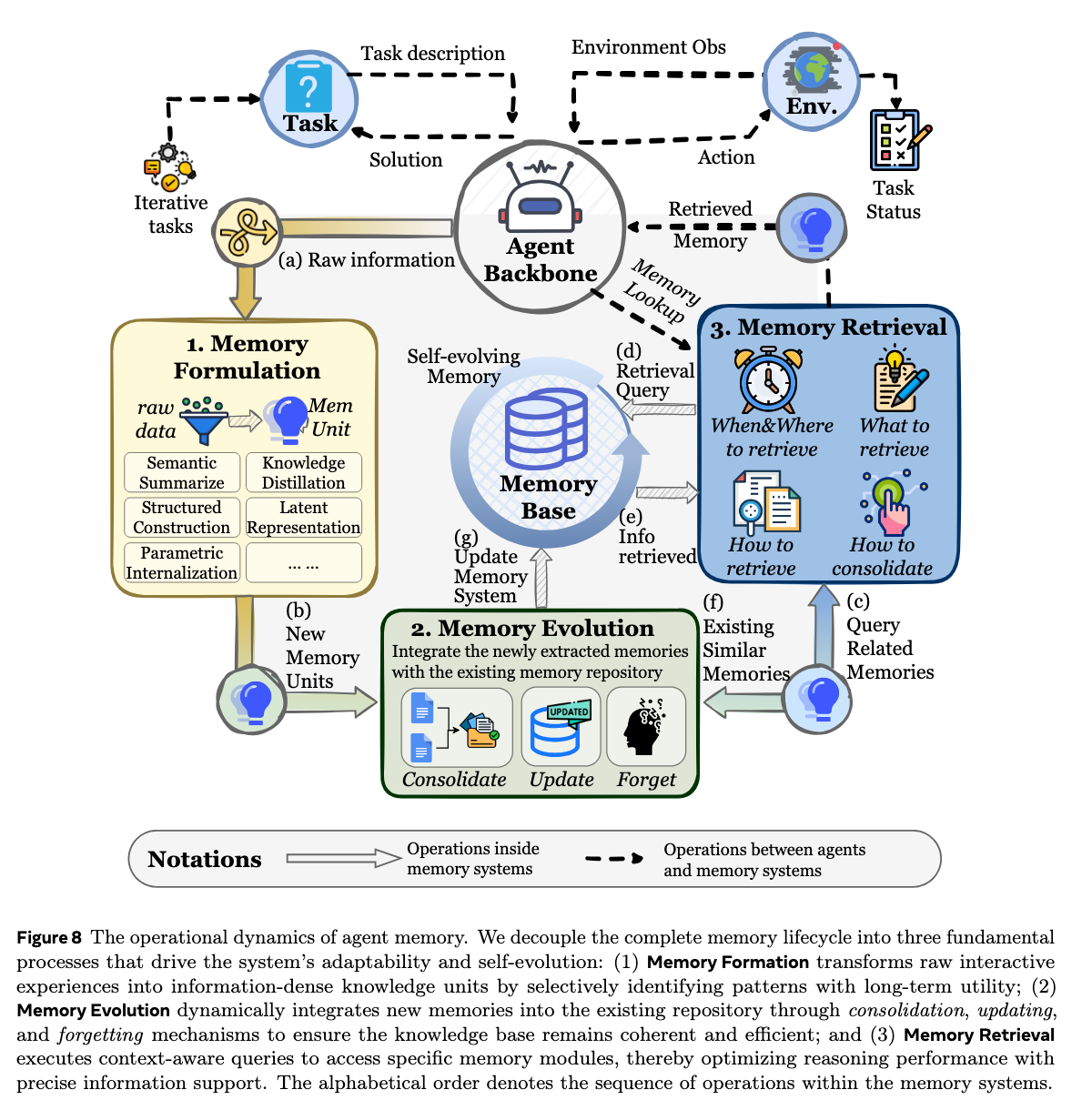
6 Resources and Frameworks
Insight:
- Memory / Lifelong / Self-Evolving Agents不分家
- 提供了一些开源的Benchmark和Framework
7 Positions and Frontiers
"7 Positions and Frontiers"(立场与前沿)这一章主要探讨了基于大语言模型(LLM)的智能体记忆系统在设计上的关键转变和未来的前沿研究方向。这一章不仅是对现有方法的总结,更是指出了重塑未来智能体记忆架构的几个范式转变和核心挑战。
具体来说,该章节涵盖了以下8个重要方向:
-
记忆检索 vs. 记忆生成 (Memory Retrieval vs. Memory Generation)
- 过去的记忆系统主要依赖于“检索”范式,即从数据库中提取相关记忆。
- 未来将越来越多地转向“生成式记忆”(Generative Memory)。智能体不再仅仅是提取原始记忆,而是根据当前上下文和异构信号,直接生成或重构出更精炼、更具适应性的记忆表征。
-
自动化记忆管理 (Automated Memory Management)
- 目前的系统大多依赖人类设定的规则或启发式方法来决定何时存储、更新或检索记忆。
- 未来的发展方向是让智能体能够自主管理记忆生命周期。例如,通过工具调用让智能体自行决定记忆的增删改查,或是发展出能够自我组织和优化的层次化自适应记忆架构。
-
强化学习与智能体记忆的结合 (Reinforcement Learning Meets Agent Memory)
- 强化学习(RL)已经被初步应用于记忆的某些环节,如检索排序或工作记忆的压缩。
- 未来的记忆系统可能走向“完全由RL驱动”。这意味着记忆的架构、格式和更新规则将减少对人类先验知识的依赖,而是通过端到端的强化学习在复杂环境中自然涌现和自我优化。
-
多模态记忆 (Multimodal Memory)
- 大多数现有的多模态记忆方法仍然局限于单一模态(特别是视觉或视频),或者只是跨模态的松散结合。
- 随着智能体在具身和交互式环境中运行,未来的记忆系统需要支持多种异构信号的统一存储、融合和检索,并在保留语义对齐的同时实现真正的“全模态”支持。
-
多智能体系统中的共享记忆 (Shared Memory in Multi-Agent Systems)
- 早期多智能体系统依赖孤立的局部记忆和显式的消息传递,这导致了高昂的通信成本和上下文碎片化。
- 共享记忆正在成为多智能体协作的“共享认知基底”,未来的系统需要进一步利用共享记忆来促进一致性、规划交接并建立共识。
-
世界模型的记忆 (Memory for World Model)
- 以前的记忆架构更多是作为“被动的数据缓存”。
- 前沿研究正转向“主动的状态模拟”。这包括探索双系统架构(快系统处理即时物理交互,慢系统处理复杂推理和世界一致性),以及将记忆设计为能够主动总结和丢弃信息的认知工作区。
-
可信记忆 (Trustworthy Memory)
- 随着记忆深度嵌入智能体,可信度问题(如基于检索的幻觉)变得至关重要。
- 未来的挑战在于需要开发类似操作系统的抽象管理机制,实现记忆的分段、版本控制、可审计性,并通过机制可解释性技术来诊断和控制幻觉,确保记忆安全可靠。
-
人类认知联系 (Human-Cognitive Connections)
- 当代智能体记忆系统的架构(如容量有限的上下文窗口与大型外部向量库的结合)已经与过去一个世纪建立的人类认知模型(如Atkinson-Shiffrin多存储模型)产生了高度的结构一致性。
- 未来,认知科学将继续为构建真正自适应和自主的智能体提供深刻的指导。
总而言之,这一章描绘了智能体记忆的发展蓝图:它将从一个被动、静态、人工设计的外挂模块,进化为一个主动、可学习、自我组织且深度融合的多模态内在认知系统。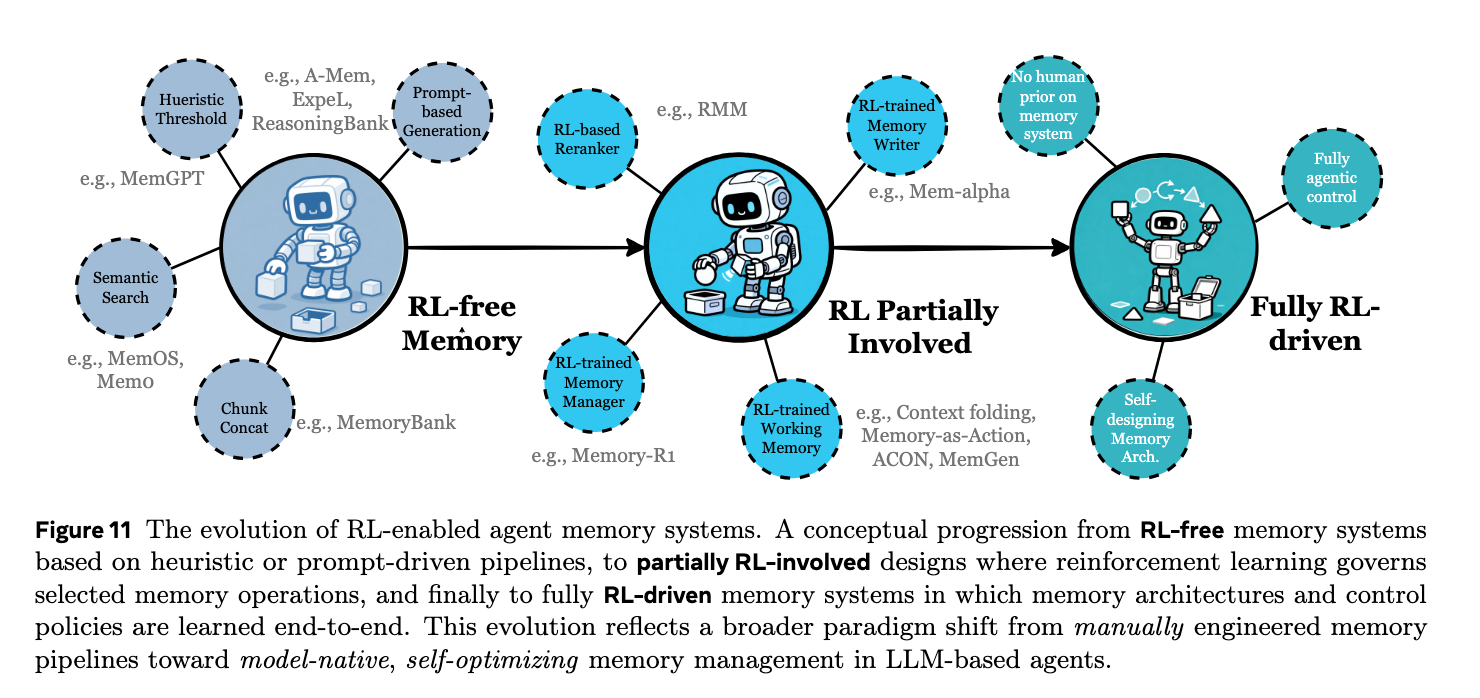
8 Conclusion
论文的第8部分“Conclusion”(结论)是对全文的总结与升华。它主要重申了智能体记忆的战略地位,并对该领域的未来发展方向做出了总结与呼吁。具体讲了以下几个核心内容:
1. 确立“记忆”为智能体的第一类原语(First-class Primitive)
结论强调,随着大模型智能体的发展,记忆已经彻底摆脱了早期“可选附加模块”或单纯数据缓存的地位,成为了基础模型智能体不可或缺的核心基础设施。真正的智能体必须具备这种持久化的认知能力,才能实现跨任务的长周期推理和与复杂环境的持续适应。
2. 总结统一框架的核心价值
回顾了论文试图解决的核心痛点:此前智能体记忆的研究高度碎片化,各类术语缺乏统一标准,且常常与传统RAG(检索增强生成)或大模型内部记忆混为一谈。结论重申了本文提出的形式(Forms)、功能(Functions)、动态(Dynamics)三维分类法,指出这一新框架成功打破了传统长/短期记忆二分法的局限,为理解当今复杂的记忆系统提供了一张清晰的认知地图。
3. 对未来智能体设计的期许
结论不仅是对现有工作的回顾,更为未来的研究指明了道路。它呼吁学术界和工业界在设计下一代智能体时,要推动记忆系统从目前的“基于人工规则和启发式策略(Heuristic)”向“自主学习与端到端自我优化”演进,从简单的“被动检索”走向真正的“主动生成与内化”,并在多模态融合、强化学习结合等方面持续突破。
4. 最终愿景
作者们在最后表达了期许:希望这篇综述不仅能作为当前研究者和工程开发者的全面参考手册,更能作为一块概念基石(Conceptual Foundation),启发大家重新思考记忆在人工智能中的定位,从而去构建能够随着时间推移、不断积累经验并自我进化的通用人工智能体。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)