终于有人讲清楚了!21张图解LLM与Agent理论基础(非常详细),从入门到精通,收藏这一篇就够了!
图解AI大模型通识
21张图强化LLM与Agent 理论基础
前言
**大模型技术日新月异,新概念层出不穷。**初学者就像走进了一个巨大的"技术超市":今天被 Transformer 的"注意力机制"吸引,明天又被 Prompt 的"魔法咒语"迷住,后天 LangChain 又来"拉链式"地串联一切。结果就是——购物车里装满了各种"商品",但回到家后一下子不知道怎么搭配使用。大模型学习过程容易出现知识碎片化、缺乏系统性,难以形成深度理解和持久记忆。
更要命的是,大模型发展的速度大于整理文章的速度!本文旨在通过可视化图解的形式整理相关概念,辅助构建从 AI 基础到 Agent 应用的知识体系,帮助读者系统掌握大模型技术的核心逻辑和演进脉络。
一、人工智能技术基础:从符号主义到深度学习
1.1 人工智能技术架构
在学习 AI 的过程中,如果能对整个技术版图有一个大致轮廓,知道每个知识点大概处于哪个层级和位置,对学习效果非常有帮助。
人工智能是一个庞大的知识领域,远不是几张图或少数术语所能完全概括。大多数人脑中其实已经「预训练」了不少 AI 知识,本文希望通过一个框架性的整理,对你的「大脑模型」进行一次小小的「微调」。

图 1:人工智能领域架构图
1.2 人工智能的分层领域
**核心关系:**人工智能(AI) → 机器学习(ML) → 深度学习(DL)。
发展历程:
-
符号主义时代(1950s-1980s)
:基于规则的专家系统,依赖人类显式编写规则。
-
机器学习时代(1990s-2000s)
:从数据中自动学习规律,开始弱化「手工规则」。
-
深度学习时代(2010s-2020s)
:大规模神经网络在语音、视觉、NLP 等领域全面开花。
-
大模型时代(2020s 至今)
:超大规模预训练模型、生成式模型爆发,迈向通用智能。
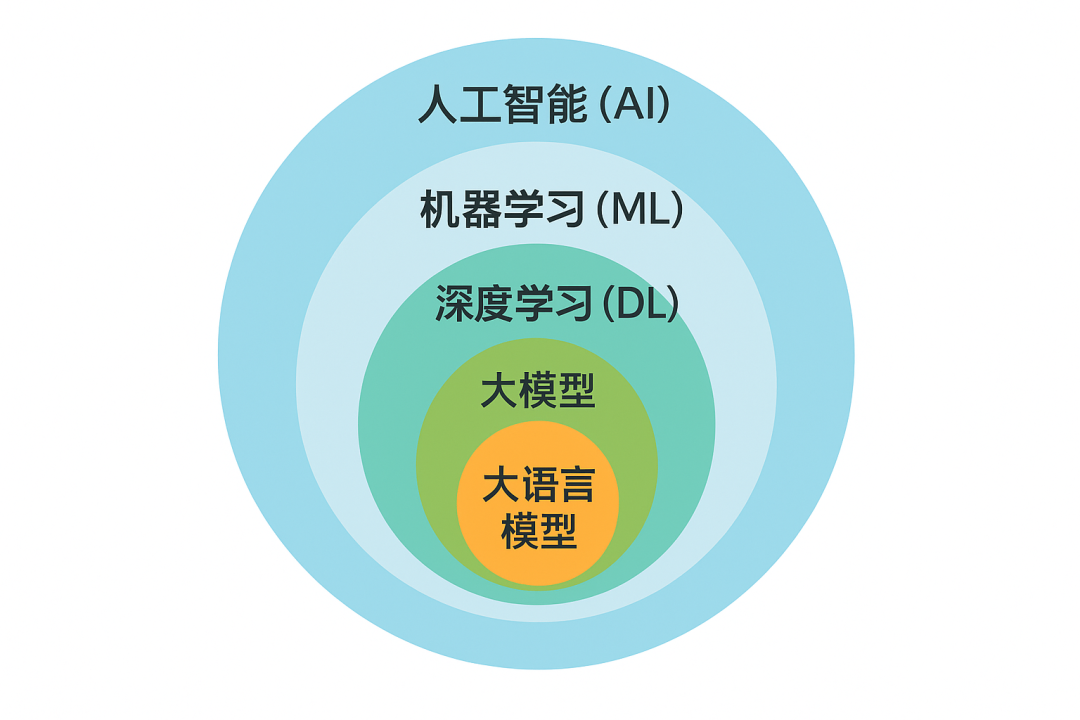
图 2:深度学习与大模型的关系
1.3 深度学习的核心:神经网络家族
**神经网络(Neural Network)**的基础是简单的感知机模型,由输入层、隐藏层、输出层组成,主要用于通用的模式识别任务。
在深度学习的发展中,出现了多种典型架构:
| 模型 | 特点 | 优势 | 应用 / 局限 |
|---|---|---|---|
| CNN(卷积神经网络) | 局部连接、参数共享 | 对局部空间特征敏感,参数量可控 | 广泛用于图像分类、目标检测等视觉任务 |
| RNN / LSTM(循环神经网络) | 序列建模、具备记忆机制 | 能够处理时间序列、文本序列 | 难以并行计算,长距离依赖问题明显 |
| Transformer | Self-Attention 机制、完全并行化 | 解决 RNN 并行性与长距离依赖问题,为大模型奠基 | 已成为 NLP、多模态等领域的大一统架构 |
Transformer 与 CNN、RNN 处于同一层级,都是神经网络的基础架构模式。Transformer 的革命性在于:
- 摆脱序列依赖,支持完全并行化训练;
- 更好地建模长距离依赖;
- 为大模型的扩展提供了可行的工程路径。
1.4 机器学习的范式:监督 / 无监督等学习方式
深度学习是机器学习的子领域,而「监督学习 / 无监督学习 / 强化学习」等,是从学习范式的角度对机器学习进行的分类。
| 学习方式 | 数据标注 | 主要特点 | 典型应用 |
|---|---|---|---|
| 监督学习 | 完全标注 | 学习输入到输出的映射关系 | 分类、回归(如垃圾邮件识别、房价预测) |
| 无监督学习 | 无标注 | 从数据中发现模式和结构 | 聚类、降维(如用户分群、特征压缩) |
| 强化学习 | 奖励 / 惩罚反馈 | 在环境中通过试错学习最优策略 | 游戏 AI、机器人控制等 |
| 半监督学习 | 部分标注 | 结合少量标注与大量未标注数据 | 文本分类、图像识别等标注成本高的任务 |
| 自监督学习 | 自构造标签 | 从数据本身构造预测任务来学习表示 | 预训练模型、BERT 等基础模型训练 |
核心区别:
- 监督 / 无监督的关键在于是否使用带标签的数据;
- 强化学习则通过试错 + 奖励信号来学习决策策略。
1.5 为什么需要大模型?
从传统模型到大模型,本质是从「专家系统」走向「通用智能」的过程:
-
传统模型
:类似「专门训练的专家」,针对单一任务精调,泛化能力有限。
-
大模型
:类似「知识渊博的通才」,在统一模型中承载多任务、多领域能力。
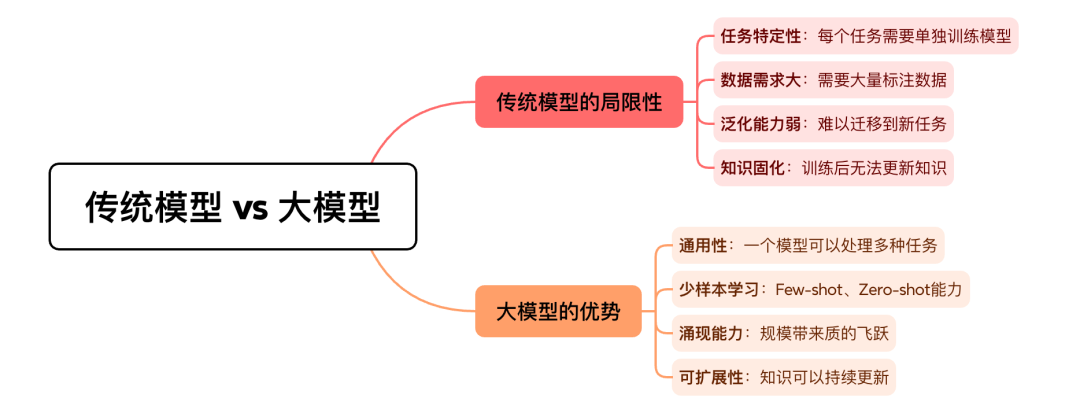
图 3:传统模型 vs 大模型对比图
二、大模型技术:从 Transformer 到模型应用
2.1 大模型领域知识框架
大模型领域概念众多,包括架构、训练范式、推理方式、应用形态等。可以从以下几个层次进行理解:
-
底层基础:
算力、数据、模型架构(如 Transformer)。
-
训练与对齐:
预训练、微调、指令微调、对齐(RLHF 等)。
-
能力扩展:
工具调用、RAG、长上下文、代码能力、多模态。
-
应用形态:
聊天助手、代码助手、搜索增强、Agent、Multi-Agent 等。
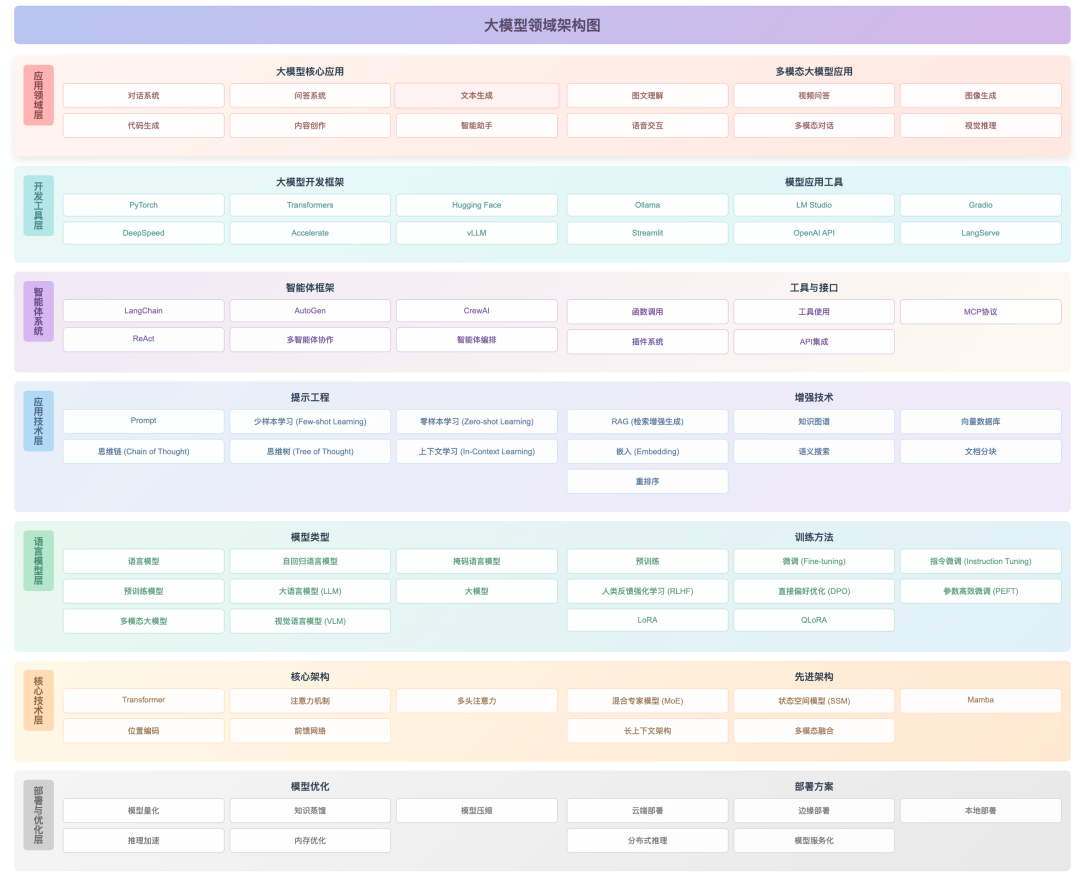
图 4:大模型领域架构图
2.2 大模型发展历程
大模型的发展可以简单概括为从「预训练语言模型」逐步演进到「通用多模态 Agent 平台」:
- 早期:基于统计与 n-gram 的语言模型。
- 中期:基于 RNN / LSTM 的语言建模。
- 转折点:Transformer 架构提出后,开始大规模预训练。
- 大模型阶段:GPT 系列、BERT 系列、各国与各厂商自研模型蓬勃发展。
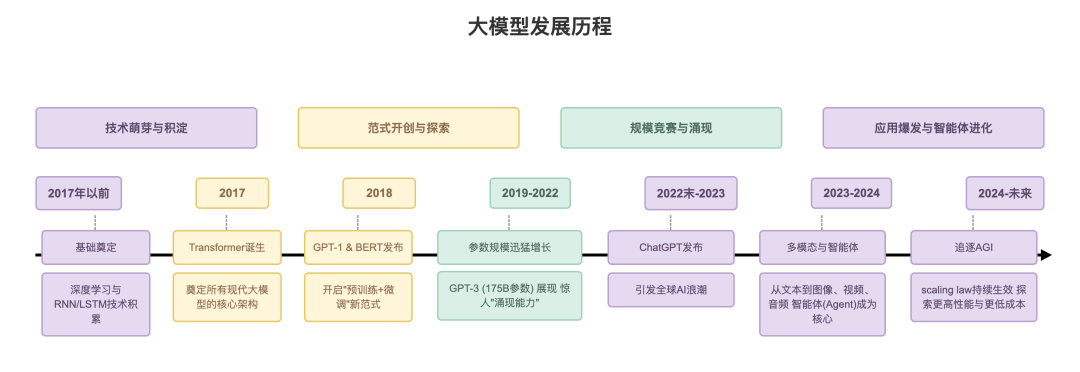
图 5:大模型发展时间轴图

图 6:2025 年主流大模型
2.3 Transformer 架构:并行化的革命
前面提到 RNN / LSTM 的主要问题:
- 难以并行:序列依赖严格,无法充分利用现代硬件并行能力。
- 长距离依赖弱:对很久之前的信息容易「遗忘」。
Transformer 的核心解决方案:Self-Attention 机制。
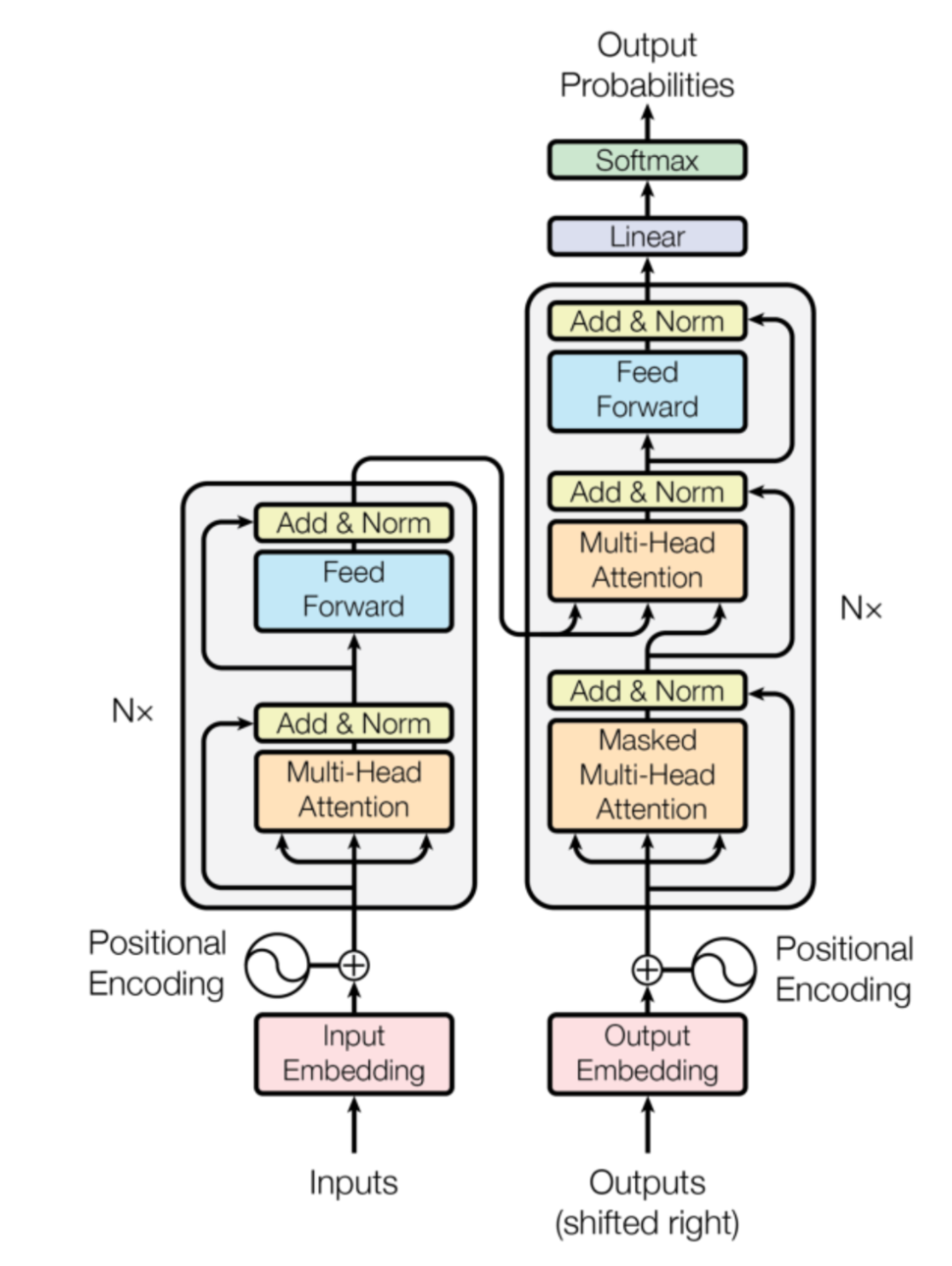
图 7:Transformer 核心架构图
1)Self-Attention(自注意力)
-
概述:
让序列中的每个元素都能与其他所有元素「对话」,通过计算相似度分配注意力权重,从而捕捉序列内部的依赖与语义关系。
-
比喻:
就像你在读一段话时,会自动把每个词与整段话中其他词联系起来,理解它在上下文中的真正含义。
2)多头注意力(Multi-Head Attention)
-
概述:
将输入向量拆分成多个「头」,每个头独立学习一套注意力权重,从不同「视角」关注信息。
-
比喻:
好比让多个专家从不同角度分析同一段文字,再综合他们的结论。
3)位置编码(Positional Encoding)
-
问题:
Self-Attention 本身对「顺序」不敏感。
-
解决:
通过显式加入位置编码,让模型知道每个 token 所在的位置。
4)编码器-解码器架构(Encoder-Decoder)
-
概述:
编码器负责理解和压缩输入信息,解码器在此基础上逐步生成输出序列。
-
比喻:
编码器像「理解者」,解码器像「表达者」,常用于机器翻译、文本摘要等任务。
Transformer 的革命性意义:
- 彻底解决 RNN 在并行化上的瓶颈;
- 为大规模预训练提供高效架构;
- 成为现代大模型的事实标准。
2.4 大模型的训练三阶段:预训练、微调、对齐
| 分类 | 预训练(Pre-training) | 微调(Fine-tuning) | 对齐(Alignment) |
|---|---|---|---|
| 目标 | 学习语言的基础表示和知识 | 适应特定任务或领域 | 让模型行为符合人类价值观与期望 |
| 数据 | 大规模无标注文本数据 | 有标注的任务相关数据 | 人类反馈数据、偏好数据等 |
| 方法 | 自监督学习(掩码语言模型、下一词预测等) | 监督学习或指令微调(Instruction Tuning) | RLHF、人类偏好建模、Constitutional AI、DPO 等 |
| 结果 | 获得基础语言理解与生成能力 | 在特定任务上性能大幅提升 | 模型更安全、有用、诚实 |
| 比喻 | 给模型「灌输知识」 | 在专业方向上「精进」 | 培养「情商」与「沟通能力」 |
2.5 大模型的分类与应用
大模型可以从多个维度进行分类,例如:
- 按模态:文本模型、图像模型、语音模型、多模态模型等。
- 按用途:通用对话模型、编程模型、搜索增强模型、Agent 型模型等。
- 按部署形态:云端大模型、本地轻量模型、端侧模型等。
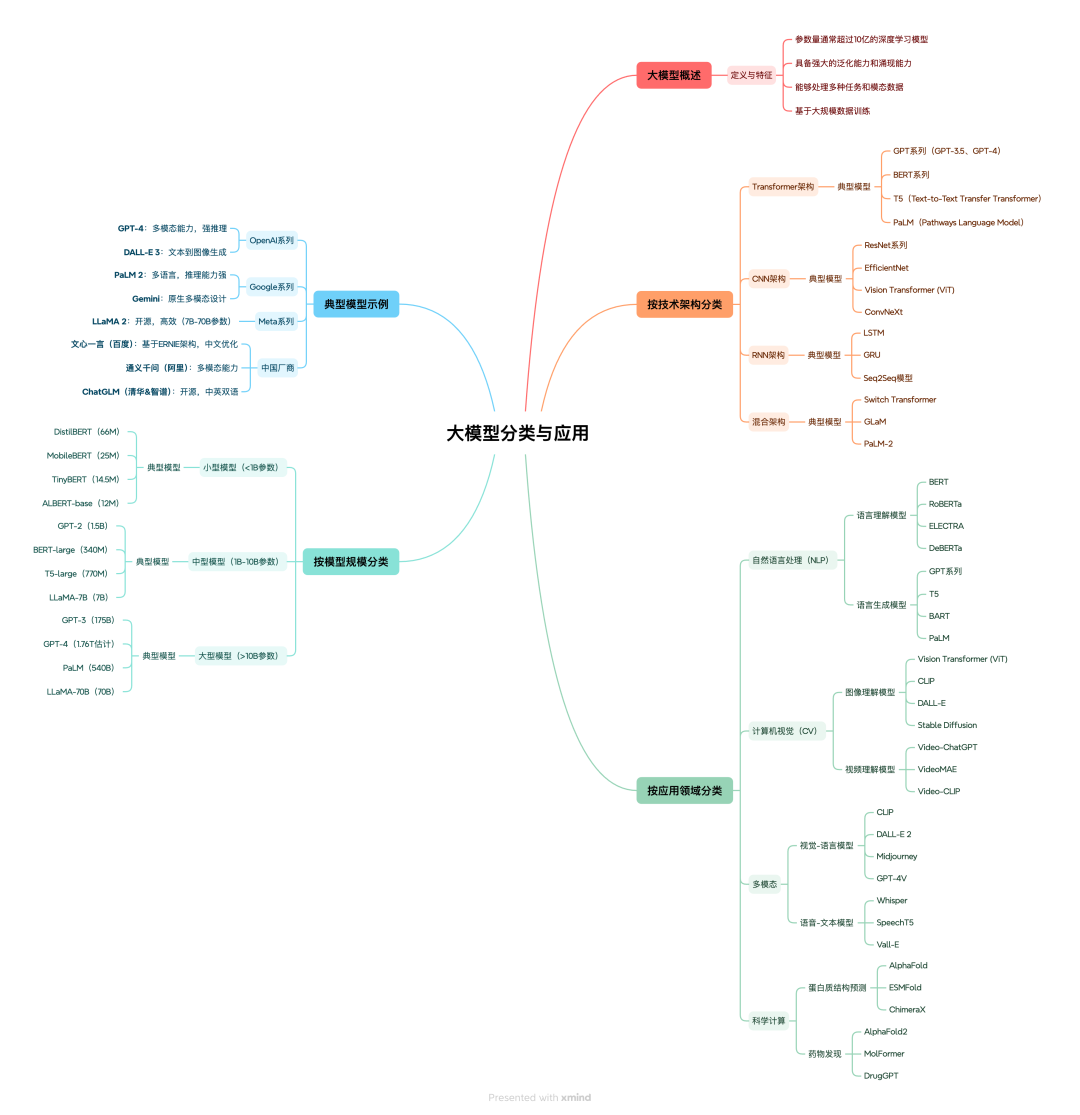
图 8:大模型分类与应用
2.6 Prompt Engineering:与 AI 对话的艺术
Prompt 是人与 LLM 之间的桥梁,清晰的 Prompt 是指令模型的灵魂。
- 好的 Prompt:目标清晰、约束明确、步骤拆解合理、提供适当上下文。
- 差的 Prompt:指令模糊、缺乏边界条件、缺少示例、缺少角色设定。
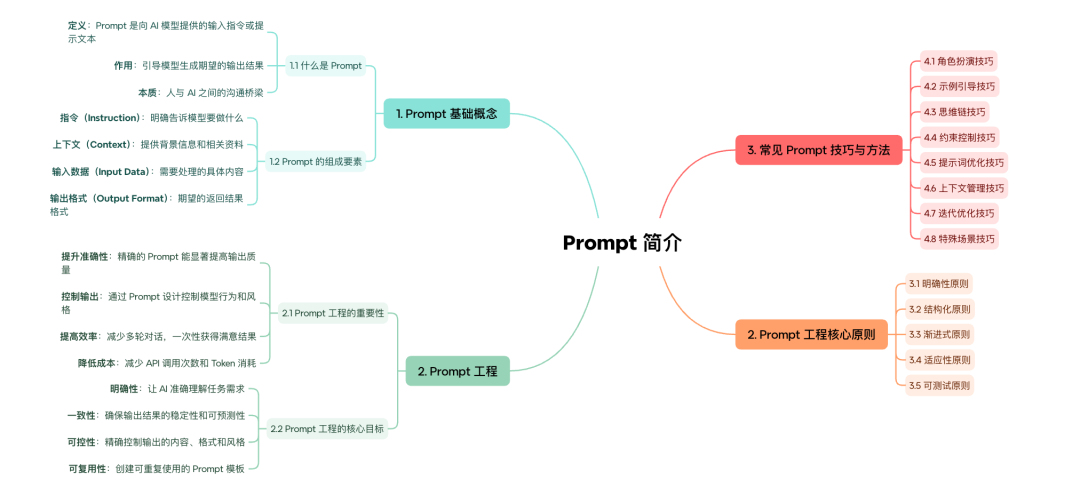
图 9:Prompt 介绍图
2.7 RAG:检索增强生成
RAG(Retrieval-Augmented Generation)是一种将外部知识检索与大模型生成结合的技术路线:
- 在调用大模型前,从向量数据库或搜索引擎中检索相关文档;
- 将检索到的内容与用户问题一起输入模型;
- 模型在「读完资料」的基础上进行回答,提升准确性与时效性。
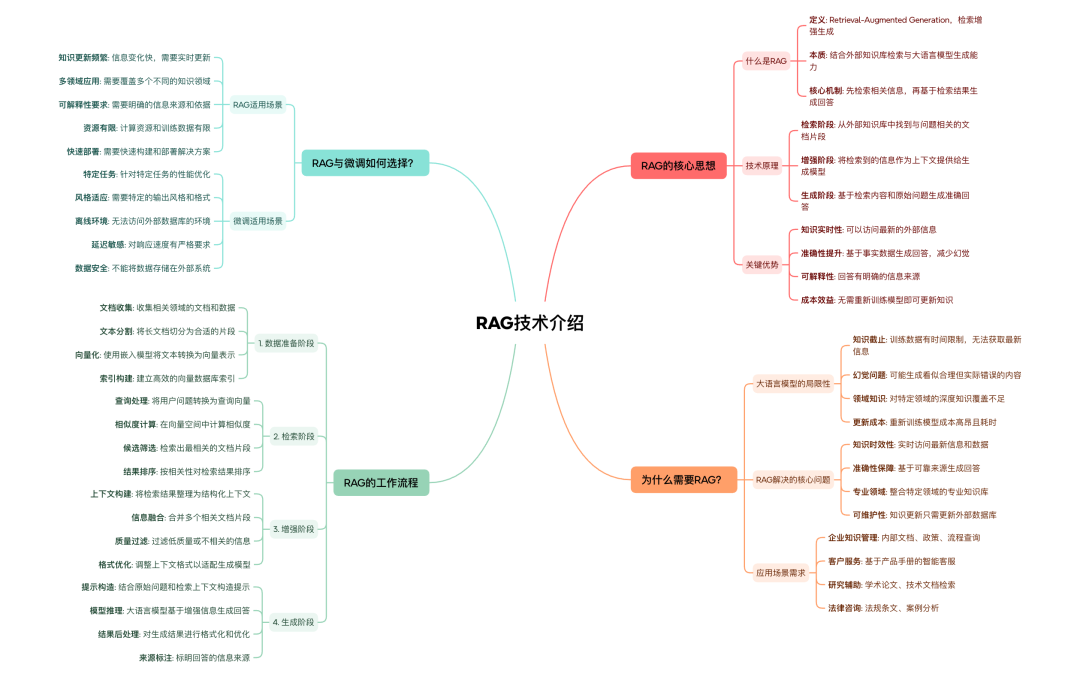
图 10:RAG 介绍图
三、智能体(Agent)技术:让 AI 具备行动能力
3.1 智能体(Agent)的定义
许多人对 AI Agent 的概念比较模糊,一个重要原因是:Agent 在不同语境下有多种定义。可以从三个视角理解:
(1)学术视角
AI Agent = 具备以下能力的智能实体:
- 感知能力(Perception)
- 决策能力(Decision Making)
- 行动能力(Action)
- 目标驱动(Goal Oriented)
它不是一个简单的模型,而是一个能够在环境中自主运行的智能体。
(2)现代大模型时代的视角
在大模型时代,AI Agent 通常包含:
-
大模型(LLM / 多模态模型)
:核心的推理、理解与生成能力。
-
记忆(Memory)
:存储长期知识、上下文与交互历史。
-
工具使用(Tool Use / Function Calling)
:调用 API、数据库、搜索引擎、代码执行器等外部能力。
-
规划(Planning)
:将复杂任务拆解为可执行步骤,进行反思与迭代。
-
行动(Action)
:根据计划调用工具、操作系统或应用,直至完成目标。
(3)产品 / 工程视角
从产品和工程实践看,AI Agent 是一个可以持续运行、可重复执行任务、能自主完成工作的软件智能体,例如:
- 自动写代码、运行代码、修复错误的 AI Dev Agent;
- 自动处理客户咨询、工单流转的 AI 客服 Agent;
- 自动分析业务数据并生成结论的 AI 分析 Agent 等。
总结定义:
-
广义:
AI Agent 是一种能够在环境中自主感知、思考、规划并执行行动,以达成特定目标的智能系统。
-
与大模型关系:
Agent 不一定必须包含大模型,但当前主流 Agent 基本都以 LLM 或多模态模型为核心,外接工具调用、记忆与规划机制,形成类似人类执行任务的闭环能力。
**更易落地的当下定义:**AI Agent 是基于大模型的自主智能系统,具备感知环境、保持记忆、进行规划、调用工具并执行行动以实现明确目标的能力。
3.2 智能体和大模型:从「大脑」到「完整的身体」
-
大语言模型(LLM)
:相当于一个「强大的大脑」,具备丰富知识和推理能力,但本身没有「手脚」,无法直接感知世界或执行操作。
-
智能体(Agent)
:在拥有「大脑」(LLM)的基础上,再加上「手脚」(Tool)和「记忆」(Memory),可以主动感知、规划、行动和反思。
3.3 智能体的四大核心组件
最常见的一张图,会把智能体拆解成四大核心组件:
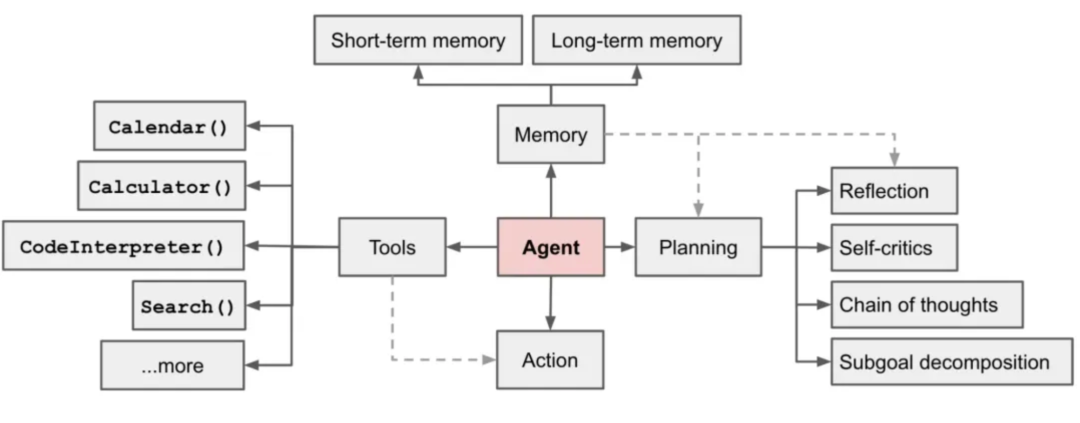
图 11:智能体核心组件原图
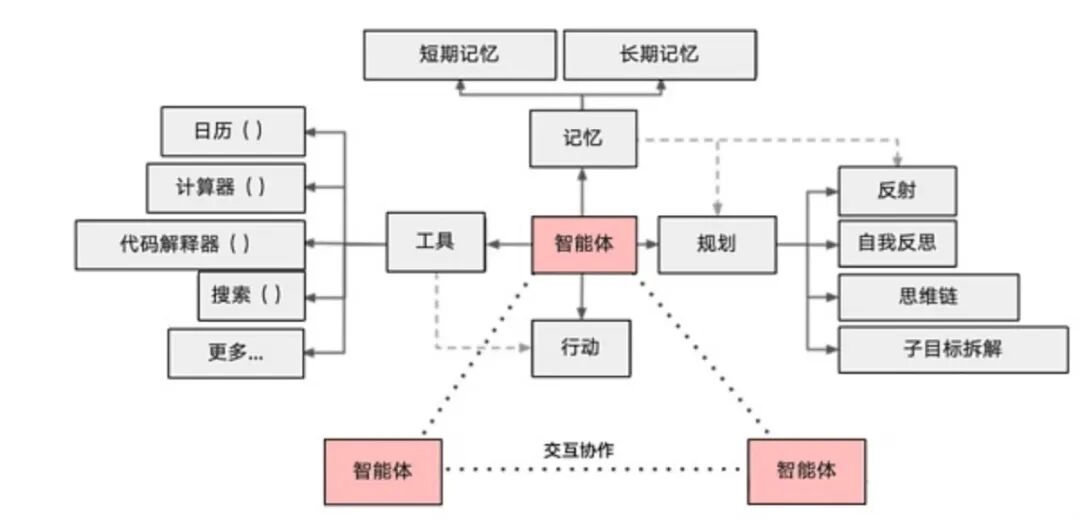
图 12:智能体核心组件翻译图
| 模块 | 功能 | 能力 | 比喻 |
|---|---|---|---|
| 大脑模块(Brain / LLM) | 推理、规划、决策 | 逻辑推理、因果分析、任务分解 | Agent 的「大脑」 |
| 工具模块(Tool Module) | 执行具体操作 | Function Calling、API 调用、代码执行等 | Agent 的「手脚」 |
| 记忆模块(Memory Module) | 存储短期与长期信息 | 短期记忆(对话历史、上下文窗口)与长期记忆(向量数据库、知识图谱) | Agent 的「记忆」 |
| 规划模块(Planning Module) | 任务分解、执行路径规划 | 制定、调整与优化任务执行计划 | Agent 的「计划能力」 |
3.4 智能体的工作流程:感知 - 决策 - 行动 - 反思
本文侧重的是基于大模型的智能体(LLM Agent),其典型流程包括:
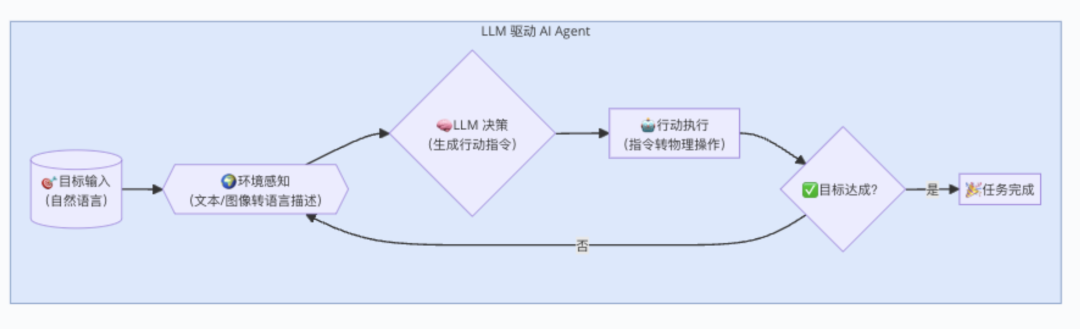
图 13:智能体执行流程图
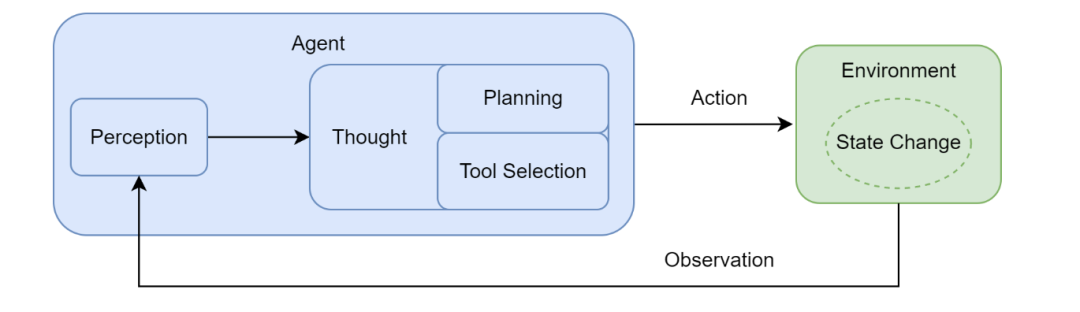
图 14:智能体循环(Agent Loop)
智能体循环的核心步骤:
-
感知(Perception)
:通过传感器(如 API 监听、用户输入接口)接收来自环境的输入信息,这些信息即为观察(Observation)。
-
思考(Thought)
:由大语言模型驱动的内部推理过程,可细分为:
-
规划(Planning)
:结合当前观察与记忆,更新对任务与环境的理解,制定或调整行动计划,将复杂目标拆解为子任务。
-
工具选择(Tool Selection)
:从可用工具库中选择最合适的工具,并确定调用参数。
-
行动(Action)
:通过执行器(Actuators)执行具体行动,通常表现为调用某个工具(如代码解释器、搜索 API 等),对环境施加影响。
-
观察与反思
:根据行动结果更新记忆与计划,进入下一轮循环。
从应用角度看,Agent Loop 通常对应「不断根据用户需求和环境反馈,迭代执行任务直至达成目标」。
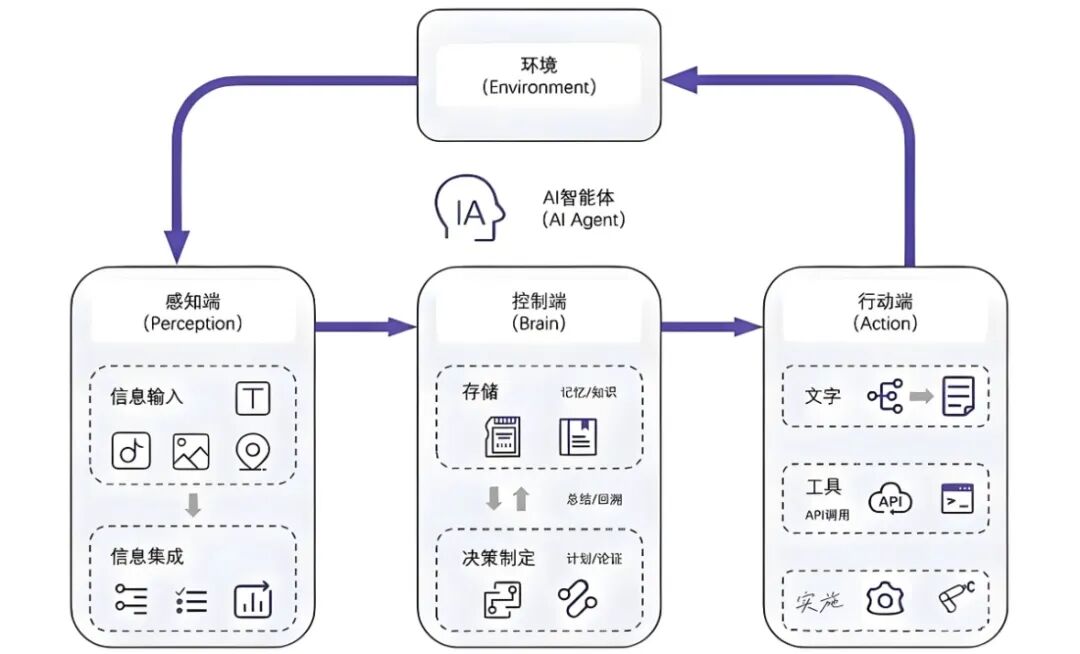
图 15:应用角度看智能体循环
3.5 MCP 协议
**MCP(Model Context Protocol)**是一种开放标准协议,用于连接 AI 应用与外部数据源和工具:
- 提供统一接口,让 AI 模型安全访问文件系统、数据库、API 等资源;
- 支持本地和远程服务器;
- 提供工具调用与资源访问能力;
- 简化 AI 应用与外部系统的集成开发。
MCP 由 Anthropic 等公司推动,旨在标准化 AI 应用的上下文管理和外部交互。
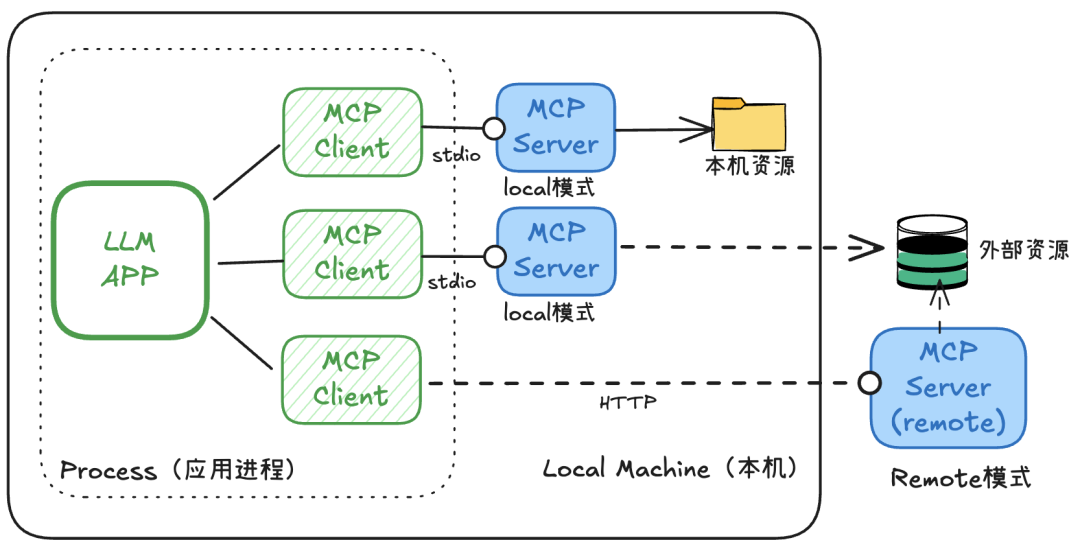
图 16:MCP 协议示意图
3.6 智能体设计的参考流程
设计一个 AI Agent 时,通常会经历以下步骤:
- 明确目标与场景;
- 设计 Agent 的能力边界、工具集合与记忆策略;
- 规划交互流程与 Agent Loop;
- 迭代调优与监控评估。

图 17:智能体设计参考流程
四、多智能体(Multi-Agent)技术:AI 协作的新范式
4.1 多智能体简介
为什么需要多智能体?
(1)单智能体的局限性:
- 能力单一:很难同时具备多种专业技能;
- 任务复杂:某些任务需要多步骤、多领域协同;
- 效率低下:串行执行,难以充分利用并行资源;
- 扩展困难:难以应对大规模分布式场景。
(2)多智能体的优势:
- 专业化分工:每个智能体专注自己的领域;
- 并行处理:多个智能体同时工作,加速整体任务;
- 复杂任务分解:将大任务拆解为多个子任务分别处理;
- 系统可扩展性:可以按需动态增加或替换智能体。
多智能体(Multi-Agent)模式,是智能体系统从「单打独斗」走向「团队协作」的核心演进方向:通过多个专业化智能体 + 通信机制 + 协调策略,实现从「全能型助手」到「专家团队」的转变。
4.2 多智能体的协作模式
常见的多智能体协作模式包括:
-
主从模式
:一个主 Agent 调度多个子 Agent;
-
平行协作
:多个 Agent 平级协作,通过协调机制统一结果;
-
黑板模式
:所有 Agent 通过共享黑板交换信息;
-
组织 / 角色模式
:以「部门 - 角色」的方式分配任务。
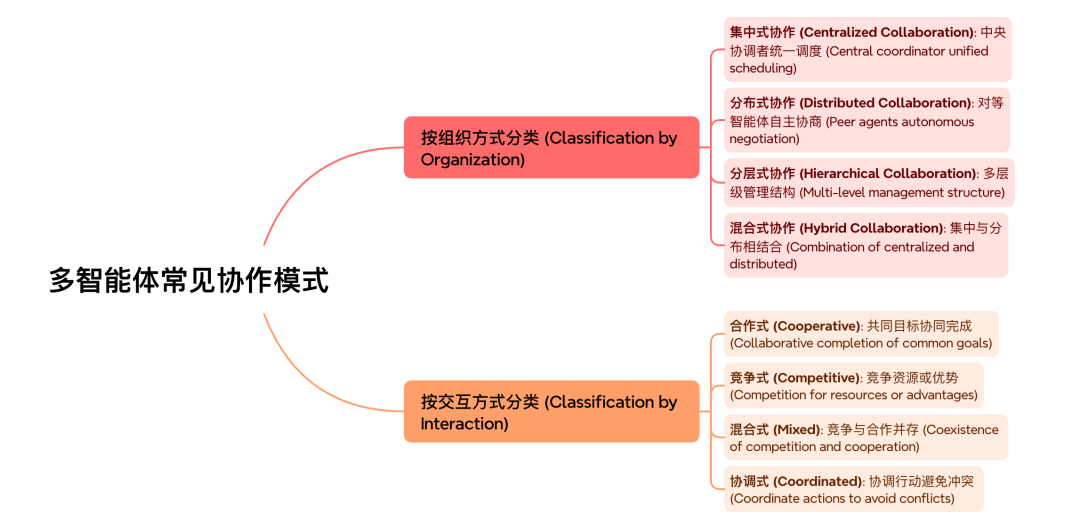
图 18:多智能体常见协作模式
4.3 A2A 协议
A2A(Application to Application)协议是一种企业级集成协议,用于实现不同应用系统之间的直接通信和数据交换。
在 AI 与多智能体场景下,A2A 协议可用于:
- 定义不同 AI 智能体之间的消息格式与交互规则;
- 支持任务分配机制和协作流程;
- 实现智能体之间的知识共享、能力互补与分布式问题求解。
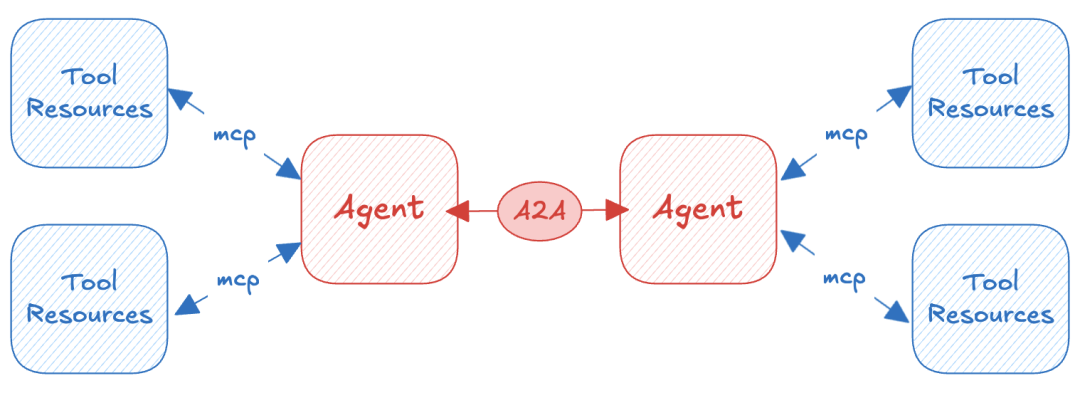
图 19:A2A 协议在多智能体领域的应用
4.4 多智能体的核心机制
多智能体系统的核心机制包括:
-
任务分解
:将复杂问题拆分为多个子任务,并根据各智能体的专业能力合理分配。
-
智能体协调
:通过任务调度、优先级管理和负载均衡等策略,避免资源冲突和重复劳动。
-
通信协议
:建立标准化的信息交换机制,支持同步与异步通信,保证数据与状态传递的准确性和及时性。
-
决策融合
:对多个智能体的决策结果进行整合,通过投票、加权平均或专家系统等方式形成最终决策。
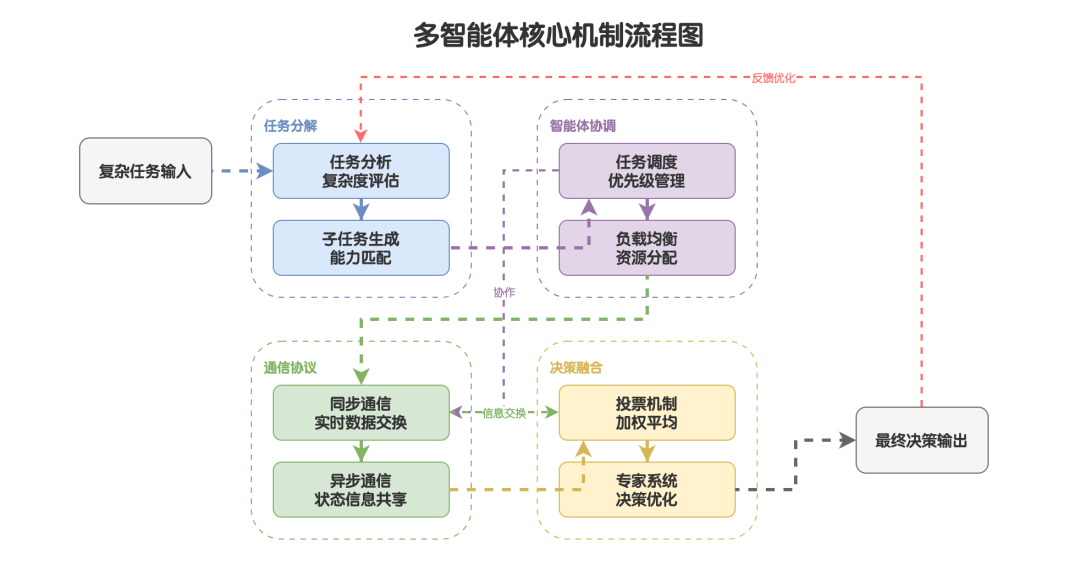
图 20:多智能体核心机制图
4.5 主流多智能体框架
多智能体框架是构建复杂 AI 系统的重要基础,常见框架包括(示例):
- 面向科研的多智能体仿真平台;
- 与大模型结合的多 Agent 协作框架;
- 支持工具编排与工作流的 Agent 平台等。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)