为什么 Prompt Engineering 正在过时,而 Context Engineering 正在接管一切:不同角色的人应如何应对
最近在看一些关于 AI 工程的讨论时,我注意到一个变化:越来越多的人不再谈 Prompt Engineering,转而开始谈一个新词——Context Engineering。
这件事最早引起我注意,是 2025 年 6 月 Andrej Karpathy 发的一条推文。他说:
Context engineering is the delicate art and science of filling the context window with just the right information for the next step.
翻译过来就是:Context Engineering 是一门精细的艺术和科学,核心是在上下文窗口里填入恰到好处的信息,以支持模型的下一步。
紧接着 Shopify 的 CEO Tobi Lütke 跟进回应,说这个词「更准确地描述了核心技能」。再往前翻,IEEE Spectrum 更早就刊文宣告 AI Prompt Engineering Is Dead。
一个词的更替,背后通常代表着某种更深层的认知转变。我开始认真去研究这件事,越看越觉得它不是换了个术语那么简单。
一、这些人到底在说什么
先仔细看看 Karpathy 的原话。
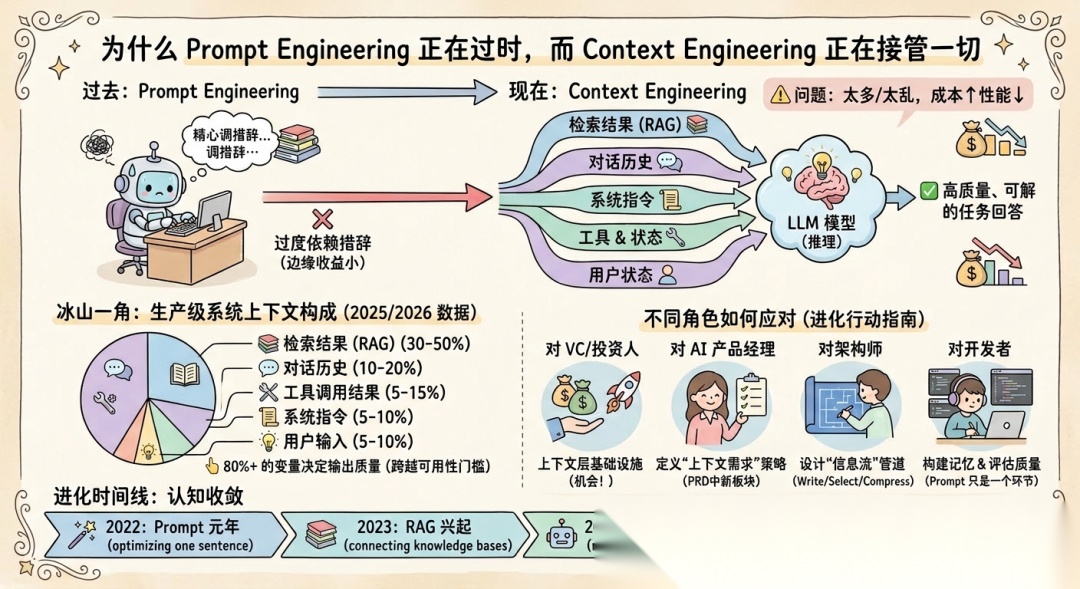
他解释了为什么「prompt」这个词不再够用:人们一提到 prompt,就联想到「写一句话给 AI」,但在真实的生产系统里,工作远比这复杂得多。你要决定塞进上下文窗口的全部内容——检索到的文档、对话历史、工具调用结果、用户状态、记忆、系统指令。这些加起来,才是模型「看到」的世界。
然后他说了一句我觉得很关键的话:
- 太少或形式不对,模型没有足够的上下文来做出好回答
- 太多或太不相关,成本上升,性能反而下降。
做好这件事,远不是写一句漂亮的 prompt 那么简单。
Shopify CEO Tobi Lütke 的回应也值得细看。他用了一个很精确的措辞:「为任务提供所有必要的上下文,让LLM有可能解决它」。
注意他的用词:有可能解决。不是「让 LLM 回答得更漂亮」,而是「让任务在逻辑上变得可解」。这个区别很关键,Context Engineering 的目标不是润色输出,而是确保模型有足够的信息基础来完成任务。
IEEE 的那篇文章走得更远。核心论点是:模型本身已经能比人类更好地优化 prompt 措辞。 当模型自己都能改写 prompt 了,你手动调措辞的边际收益就非常小了。真正的杠杆点已经从「怎么问」转向了「看什么」。
这三个声音来自不同方向——学术界、商业领袖、技术媒体,但指向了同一个结论:AI 工程的核心战场正在从 prompt 转移到 「context」****。
二、先搞清楚上下文窗口里到底装了什么
这里有一个很容易被忽略的事实,值得展开讲。
当大多数人想到 prompt 的时候,脑海里浮现的画面是 ChatGPT 的输入框:你打一句话进去,模型回一段话出来。但在真实的生产级 AI 系统中,用户输入的那句话只是冰山一角。
一个典型的生产系统,当模型开始推理的时候,它"看到"的完整上下文大致是这样的:
| 组成部分 | 占上下文窗口比例 | 说明 |
| 系统指令SystemPrompt | 5-10% | 角色定义、行为准则、输出格式要求 |
| 工具描述 ToolDefinitions | 5-15% | 可调用的 API、函数签名、参数说明 |
| 检索结果 RAG | 30-50% | 从知识库检索到的相关文档片段 |
| 对话历史 | 10-20% | 之前的对话轮次 |
| 记忆与状态 | 5-10% | 用户偏好、会话状态、长期记忆 |
| 用户输入 | 5-10% | 用户实际打的那句话 |
用户输入通常只占上下文窗口的 5-10%。 你精心打磨的那句 prompt,在模型看到的整个信息空间里只是一小片。剩下 80%-90% 的空间——检索结果、对话历史、工具定义、系统指令——才是真正决定输出质量的变量。
这就是为什么同一句 prompt,在不同系统里效果天差地别。你觉得是 prompt 的问题,其实是 context 的问题。
三、Context Engineering的定义
Context Engineering(上下文工程):系统性地设计和管理 LLM 在每次推理时「看到」的全部信息——包括系统指令、对话历史、检索到的文档、工具描述与输出、记忆、用户状态等——而不仅仅是用户输入的那句话。
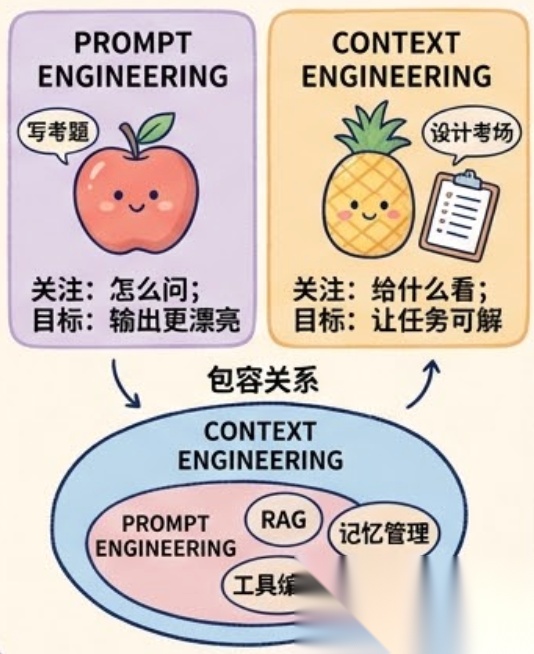
如果用考试来类比:
- Prompt Engineering 是「写考题」——怎么把题目出得更清楚、更精确
- Context Engineering 是「设计整个考场」——灯光亮不亮、桌上有没有参考资料、参考资料是不是对的、考生拿到的是不是自己的卷子、答题时间够不够、监考规则是什么
考题写得再精妙,如果考场没灯、参考资料是错的、考生拿到的是别人的卷子,结果不会好。反过来,考场设计得当,即使考题再难,考生也能发挥正常水平。
四、它和 RAG、Prompt Engineering 是什么关系
看到这里你可能会想:这不就是 RAG 吗?或者更复杂一点的 RAG?
不完全是。RAG 是 Context Engineering 的一个重要组成部分,它解决「从外部知识库检索信息并注入上下文」这一步。但 Context Engineering 的范围要广得多:
- RAG 关注的是「检索什么」,Context Engineering 关注的是「整个上下文窗口里放什么、不放什么、怎么组织、什么时候更新」
- Prompt Engineering 关注的是「怎么问」,Context Engineering 关注的是「给什么看」
- Context Engineering 把两者都包含进来,再加上记忆管理、状态追踪、工具编排、上下文压缩等,形成一个完整的信息管道设计

用一个包含关系来理解:
Prompt Engineering 和 RAG 都是 Context Engineering 的子集,不是反过来。
这个认知决定了你应该把精力花在哪里。如果你的系统效果不好,不应该只去调 prompt 或者只去优化 RAG,应该审视整个上下文:系统指令对不对?工具描述太多了?对话历史太长了?不同类型的信息混在一起了?
五、为什么现在火起来:从玩具到生产的必然
接下来讲为什么这件事在「**现在」**变得特别重要。
1. 40% 的失败不是模型的错
这里有一组值得认真消化的数据:
- 超过 40% 的 AI 项目失败源于上下文问题,而非模型能力不足(contextengineering.ai 数据)
- 42% 的企业 AI 项目在 2025 年被废弃,比 2024 年的 17% 暴涨了 25 个百分点(Gartner)
- 60% 的企业 AI 投资未产生实质性回报(Brent Johnson/Substack 综合数据)
- Gartner 预测到 2026 年,组织将废弃 60% 的 AI 项目,主要原因是缺乏组织上下文
仔细看这些数字,它们指向同一个结论:AI 项目大规模失败的根因不是模型不够强,而是没给模型足够好的上下文。
这很反直觉。大多数团队在 AI 项目遇到问题时的第一反应是「换更大的模型」「加更多参数」「用更贵的 API」。但现实是:一个拿到正确上下文的中等模型,往往比一个拿到垃圾上下文的顶级模型表现更好。
2. 80% 是一条生死线
另一组关键数据来自 Gartner 和 Atlan 的研究:
- 上下文准确率 < 80%:用户拒绝使用 AI 系统。不信任、体验差、宁可手动
- 上下文准确率 > 80%:采用率开始加速。用户觉得「靠谱了」,愿意依赖
80% 是一个 tipping point。 从 70% 到 80%,靠 prompt 调优能做到一部分。但从 80% 往 90% 走,几乎完全取决于上下文的系统设计——检索准不准、历史管不管得好、工具输出可不可靠、无关信息有没有被过滤掉。
这就是 Context Engineering 从「nice to have」变成「must have」的根本原因:它是跨越 80% 可用性门槛的关键。
3. Anthropic 的验证:结构化上下文减少 40%+ 幻觉
2025 年 9 月,Anthropic 发了一篇影响很大的博文 Effective Context Engineering for AI Agents。核心发现:通过结构化上下文设计(明确分区、合理排序、及时检索)幻觉率可以降低 40% 以上。
注意,这不是靠 prompt 措辞做到的。这是靠信息架构做到的。
2026 年 2 月,一项覆盖 9,649 次实验的同行评审研究进一步确认:上下文质量比 prompt 本身更重要。结构化上下文可以在前沿模型上再提升 2.7% 的准确率。2.7% 听起来不多,但在已经 90%+ 准确率的前沿模型上,这个提升非常显著——相当于把「偶尔出错」变成「几乎不出错」。
六、进化时间线:这不是一个新概念,是一次认知收敛
如果回头看这几年 AI 工程的进化,会发现 Context Engineering 不是凭空出现的,而是一步步走过来的。这条线值得完整看一遍,因为它揭示了杠杆****点是怎么逐步下移的。
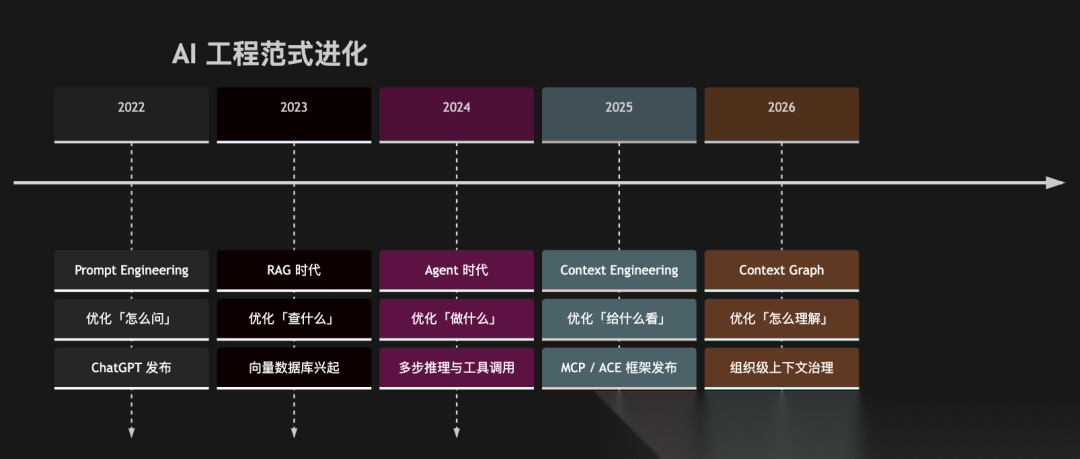
2022 年,Prompt Engineering 元年
ChatGPT 发布,prompt 工程师成为热词。大家发现同一个模型,问法不同,效果差异巨大。于是出现了大量 prompt 模板、技巧、课程。核心方法论是 Chain-of-Thought、Few-shot、角色扮演等,本质上是在优化「那一句话」。
这个阶段的范式是:一个用户,一次对话,一句精心设计的指令。
2023 年,RAG 兴起
团队开始把大模型接入企业知识库,RAG 成为落地标配。这一步的核心突破是:模型不再只靠参数记忆,而是可以「开卷考试」。
但 RAG 也带来了新问题:分块不好就检索不到、检索到了垃圾模型照样瞎编、多文档拼接格式混乱……人们开始意识到,问题不只是「问什么」,更是「给模型看什么」。
2024 年,Agent 起飞
AutoGPT、Devin、各种 Agent 框架涌现。AI 不再是单次问答,而是要多步推理、调用工具、长时间运行。这对上下文管理提出了全新挑战:
- 上下文越来越长,token 成本暴增
- 对话历史堆积,关键信息被淹没
- 工具调用的结果需要即时注入
- 多 Agent 协作时,谁该看到什么信息?
在这个阶段,「上下文管理」从一个技术细节变成了架构核心问题。
2025 年,Context Engineering 正名
Karpathy 的推文是一个标志性时刻,但它更像是一个「命名仪式」——行业已经在做的事情终于有了一个准确的名字。
这一年发生的关键事件:
- Anthropic 发布 MCP,统一 AI 连接外部工具和数据的标准
- Anthropic 发布 Context Engineering 博文,系统阐述上下文管理策略
- Microsoft 发布 ACE(Agentic Context Engineering)框架,被 ICLR 2026 收录
- 多家企业开始设立「Context Engineer」岗位
2026 年+,ContextGraph时代
Gartner 预测到 2028 年,超过 50% 的 AI Agent 系统将使用 Context****Graph(知识图谱的进化形态),不仅记录「什么是什么」,还记录「为什么这么决策」「怎么做出来的」。
同时,Gartner 也警告:到 2028 年,60% 仅依赖MCP而缺乏语义基础的 Agent 项目将失败。 光有连接还不够,还需要有组织化的上下文理解能力。
把这条线拉出来看,每一步的杠杆点都在下移——从优化提问措辞,到优化检索内容,到优化整个信息系统。
七、这对不同人意味着什么
Context Engineering 不是一个只有开发者需要关心的技术概念。它影响的是整个 AI 产品的决策链。
1. 对 VC 和投资人
上下文层(Context Layer)正在成为新一代 AI 基础设施。
过去几年 AI 投资集中在模型层(大模型、推理优化)和应用层(SaaS、copilot)。但中间有一层被低估了:把正确的信息在正确的时间送给正确的模型的那一层。
这一层包括:向量数据库(Pinecone、Weaviate、Qdrant)、记忆管理(Mem0、Zep)、检索优化(Cohere Rerank)、上下文编排(LangChain、LlamaIndex)、治理审计(Atlan、Galileo)。
**当 42% 的 AI 项目因为上下文问题失败时,解决上下文问题的公司就有了结构性机会。**这不是「锦上添花」的效率工具,而是「没有就做不出来」的基础设施。
2. 对 AI 产品经理
需求定义需要升级——不能只写「接个大模型」,还要定义上下文策略。
和开发团队沟通时,PM 需要能回答这些问题:
- 模型需要看到哪些信息才能完成这个任务?
- 这些信息从哪来?怎么检索?多久更新?
- 上下文窗口的 token 预算怎么分配?
- 如何评估上下文质量(而不只是最终答案质量)?
- 多轮对话时,历史怎么管理?什么时候压缩?
Context Engineering 正在PRD中催生一个新板块:上下文需求**,**和功能需求、性能需求并列。
3. 对架构师
信息管道设计成为架构核心。
以前架构师关注的是计算流(请求怎么走、服务怎么拆、数据怎么存)。现在还需要关注信息流:上下文怎么组装、怎么在组件之间传递、怎么在多 Agent 之间隔离或共享。
Anthropic 在博文中提出的四大策略——Write(写入外部存储)、Select(精准检索)、Compress(智能压缩)、Isolate(分区管理)——正在成为架构设计的新参考框架。
(后面会单独一篇文章讲解, 有兴趣的朋友可以关注我~)
4. 对开发者
Context Engineering 正在取代 Prompt Engineering 成为核心技能。
这不是说 prompt 不重要了,而是说它变成了更大系统中的一个环节。开发者需要掌握的新技能包括:
- 设计检索管道(不只是调 API,而是理解分块、嵌入、混合检索、重排序)
- 管理上下文窗口(token 预算分配、注意力偏好、压缩策略)
- 构建记忆系统(工作记忆、情景记忆、语义记忆的分层设计)
- 评估上下文质量(Context Precision、Context Recall,不只是答案指标)
一个趋势是:会写好 prompt 的人有很多,但能设计好整个上下文系统的人,目前非常稀缺。
八、几个常见的误解
最后澄清几个我在讨论中经常看到的误解。
❌「Context Engineering 不就是 Prompt Engineering 换了个名字吗?」
不是。Prompt Engineering 关注的是用户输入的那 5-10%,Context Engineering 管理的是整个 100%。一个是写一句话的技巧,一个是设计信息系统的工程。
类比:写 SQL 查询语句是一个技能,设计整个数据库架构是另一个技能。它们有交集,但不是一回事。
❌「大模型上下文窗口越来越长,不需要管理了吧?」
恰恰相反。上下文越长,管理越重要。研究表明,当上下文窗口利用率超过 85% 时,模型性能会下降约 23%。200K+ token 的超长上下文会产生「注意力盲区」,中间的信息被系统性忽略(即「Lost in the Middle」问题)。窗口大了不等于能用好,就像图书馆大了不等于能找到书。
❌「我用了 RAG 就算是做 Context Engineering 了。」
RAG 是 Context Engineering 的重要组成部分,但不是全部。RAG 解决的是「检索并注入外部知识」;Context Engineering 还包括记忆管理、对话历史压缩、工具输出整合、多 Agent 上下文隔离、上下文质量评估等。只做 RAG 就像只装了发动机但没装变速箱——能转,但跑不远。
最后
回到 Karpathy 那条推文。他说的其实很简单:模型在推理的那一刻,看到了什么信息,决定了它能给出什么回答。 这些信息太少、太多、太乱、太不相关,都会导致结果不好。而系统性地管理这些信息,远比写一句漂亮的 prompt 重要得多,也复杂得多。
这也是我接下来想深入写的方向。Context Engineering 到底怎么做?技术上有哪些策略?Agent 场景下有什么特殊挑战?商业上意味着什么?怎么落地?
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)