开源大模型:免费、可控、超强大,揭秘AI的“开源密码”!你还在用ChatGPT?快来看这个颠覆性的选择!
一句话定义
开源大模型 = 代码和权重完全公开的AI模型,可以免费下载、修改和部署,不受平台限制。
打个比方
就像软件的开源和闭源之别…
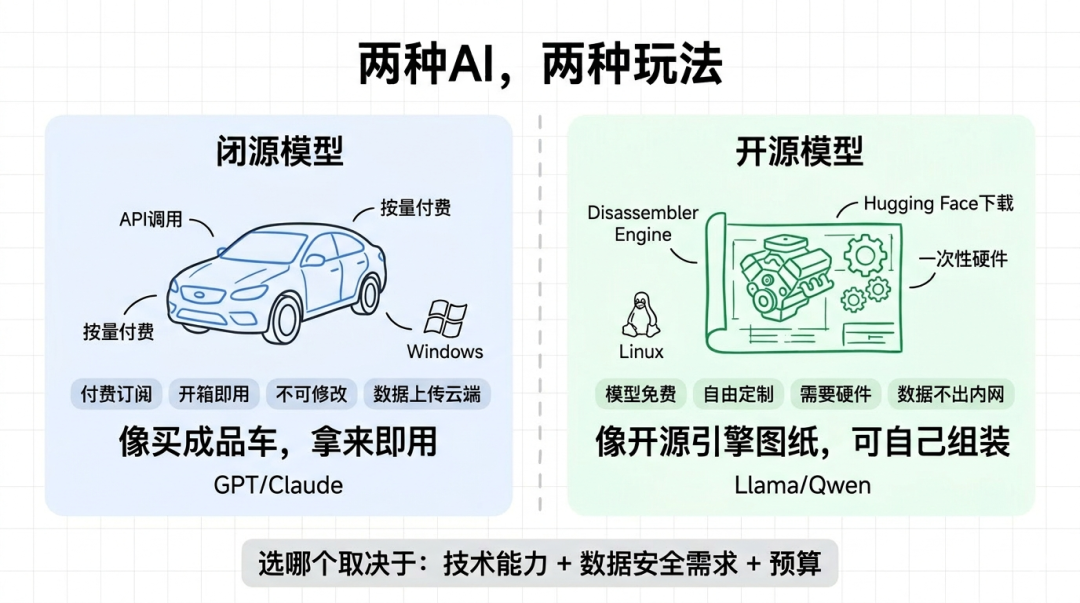
闭源模型(GPT/Claude):
- 像买成品车:拿来即用,但不能拆开改装
- 按月付费或按量付费
- 必须用厂家的服务
开源模型(Llama/Qwen):
- 像开源引擎图纸:可以自己组装/改装
- 模型免费,但需要自己准备硬件
- 完全掌控,想怎么改就怎么改
类比软件界:
- 闭源模型 = Windows/macOS(付费,开箱即用)
- 开源模型 = Linux(免费,自由定制,但需技术)
举个例子,企业要用AI:
- 闭源:调用ChatGPT API,每月付费,数据上传云端
- 开源:下载Llama部署到自己服务器,数据不出公司,一次性硬件投入
核心要点(3个)
1. "开源"意味着什么?
开源大模型公开了AI的"全部秘密",任何人都能获取和使用。
公开内容:
- ✅ 模型权重(训练好的参数)
- ✅ 模型架构(Transformer结构代码)
- ✅ 训练细节(可选,部分模型公开)
你可以做什么:
- 免费下载到本地运行
- 修改模型代码和参数
- 商业使用(大部分开源协议允许)
- 二次开发和微调
不能做什么:
- 不代表"零成本"(需要GPU服务器)
- 不代表"易使用"(需要技术能力)
- 不能直接拿来当ChatGPT用(需要部署和优化)
2. 主流开源大模型有哪些?
2025-2026年,顶级开源大模型已经媲美甚至超越闭源模型的能力。
国际主流:
- Llama 4(Meta):2025年4月发布,包含Scout(17B激活/109B总参数)、Maverick(17B激活/400B总参数)、Behemoth(288B激活/~2T总参数,有限预览中)
- DeepSeek-V3.2(DeepSeek):2025年12月1日发布,671B总参数/37B激活(MoE架构),MIT协议,IMO/IOI金牌级表现
- Mistral Large 3(法国,2025年12月):675B总参数/41B激活(MoE架构),256K上下文,Apache 2.0
国内主流:
- Qwen 3(阿里):2026年最新系列,Qwen3-Max-Thinking在推理任务上达到顶级闭源模型水平
- Qwen3.5(阿里):2026年2月发布,从397B-A17B旗舰到0.8B~9B小模型完整产品线,覆盖边缘设备到云端
- GLM-4.7(智谱AI):2026年1月开源,30B总参数/3B激活,性能接近GPT-4
- Kimi-K2.5(月之暗面):2026年1月发布,32B激活/1T总参数,业界最大开源模型
- MiniMax/Yi(零一万物):开源SOTA竞争者
能力对比(2026年3月水平):
- Llama 4 Maverick ≈ GPT-4o(在部分benchmark超越)
- Qwen3-Max-Thinking 在推理任务上达到顶级闭源模型水平
- GLM-4.7 ≈ GPT-4(编程榜单与Claude并列第一)
- Kimi-K2.5 = 原生多模态Agent模型(1T参数规模)

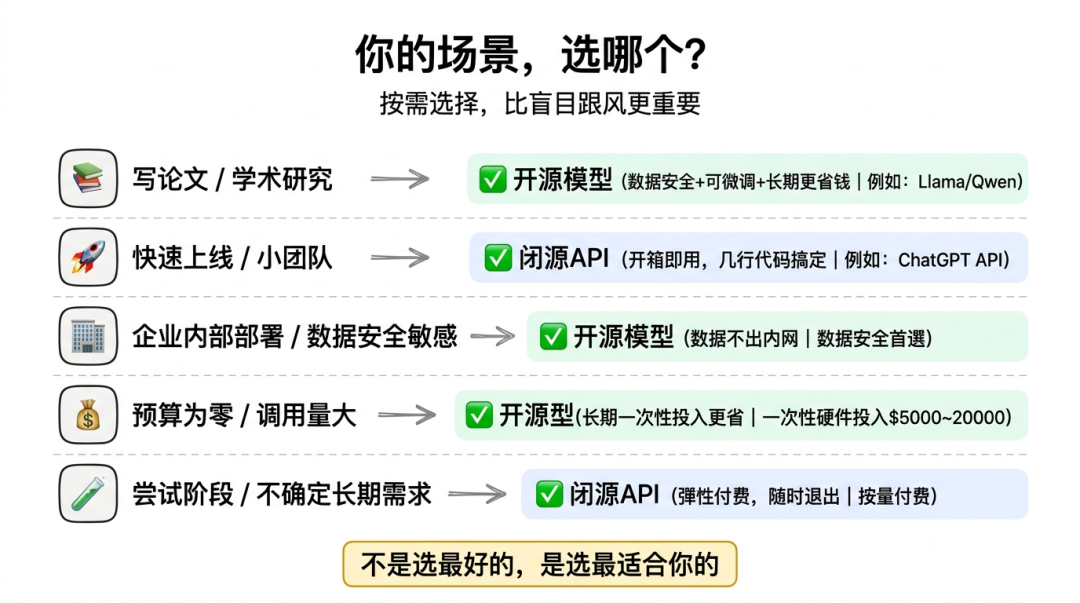
3. 开源 vs 闭源:如何选择?
两者各有优劣,取决于你的需求和技术能力。
开源模型适合:
- 🏢 企业内部部署(数据安全第一)
- 🔧 需要深度定制(特定领域微调)
- 💰 大量调用(长期看更省钱)
- 🎓 学术研究(研究模型原理)
闭源模型适合:
- 🚀 快速上线(开箱即用)
- 💼 小团队(没有AI工程师)
- 🧪 尝试阶段(不确定是否长期使用)
- 🎯 追求最强能力(最新闭源旗舰模型)或特定场景优化
成本对比(假设100万次调用):
- 闭源API:约$20-100(按量付费)
- 开源本地:一次性硬件$5000-20000 + 电费(长期更省)
为什么重要
开源大模型打破了AI垄断,让更多人能参与AI开发,尤其对中国AI生态至关重要。
实际应用场景:
- 🏢 企业内部部署:银行/医院等数据敏感行业
- 🔐 数据安全:数据不离开公司内网
- 🎨 创意应用:游戏NPC对话/虚拟角色定制
- 📚 教育科研:学校/实验室研究AI原理
- 🛠️ 开发者工具:本地代码助手(不上传代码)
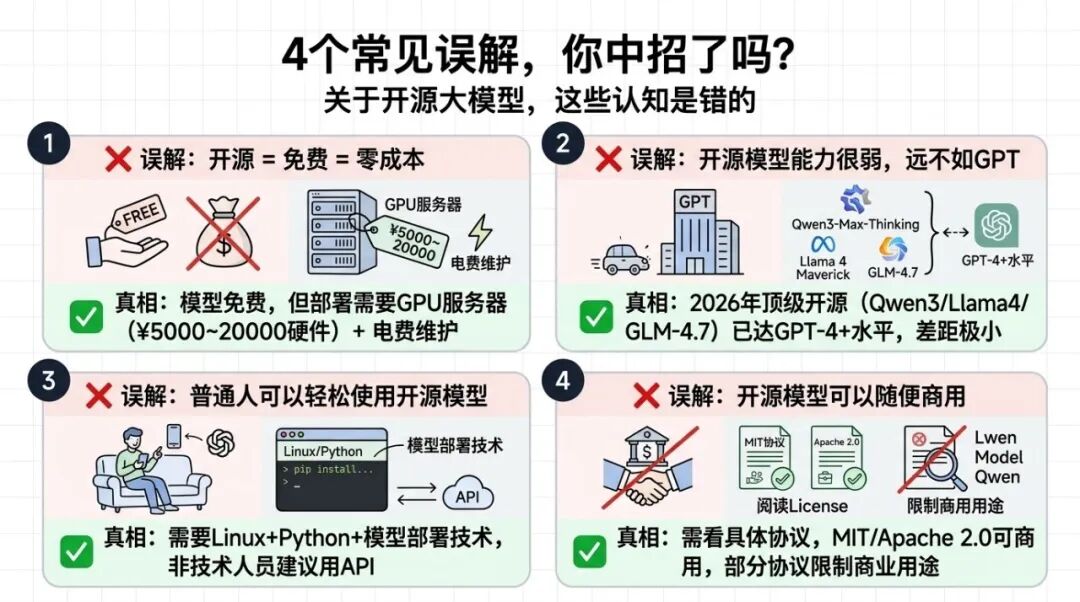
常见误解
误解1: 开源 = 免费 = 零成本
真相: 模型免费,但部署需要GPU服务器(几千到几万元硬件成本),还需要电费和维护成本。小规模使用反而比API贵。
误解2: 开源模型能力很弱,远不如GPT
真相: 2026年的顶级开源模型(如Qwen3-Max-Thinking、Llama 4 Maverick、GLM-4.7、DeepSeek-V3.2)已经达到GPT-4级别,部分任务甚至达到顶级闭源模型水平。开源与闭源的差距已经极小。
误解3: 普通人可以轻松使用开源模型
真相: 需要懂Linux、Python、模型部署等技术。对非技术人员,API仍是更好选择。
误解4: 开源模型可以随便商用
真相: 需要看具体开源协议。MIT/Apache 2.0可商用,部分协议限制商业用途,使用前务必阅读License。
开源 vs 闭源对比
| 维度 | 开源模型 | 闭源模型(GPT/Claude) |
|---|---|---|
| 获取方式 | Hugging Face下载 | API调用 |
| 成本模式 | 一次性硬件投入 | 按量付费/订阅 |
| 定制性 | 可修改代码/微调 | 只能Prompt调整 |
| 部署位置 | 本地/私有云 | 厂商云端 |
| 数据安全 | 数据不出内网 | 数据上传云端 |
| 技术门槛 | 高(需AI工程师) | 低(几行代码) |
| 能力上限 | 极高(顶级模型达GPT-4+) | 最强(最新闭源旗舰模型) |
| 更新速度 | 社区驱动,快速迭代 | 厂商定期更新 |
| 类比 | Linux自己装 | Windows买来用 |
3秒总结
记住这3点就够了:
- ✅ 完全公开:代码权重全开源,可自由下载修改
- ✅ 数据安全:本地部署,数据不出公司
- ✅ 需要技术:不如API简单,但自由度高
技术补充(开发者可选阅读)
主流开源模型详解
| 模型 | 开发方 | 参数规模 | 特点 | 开源协议 | 下载地址 |
|---|---|---|---|---|---|
| Llama 4 | Meta | Scout(17B激活/109B总)/Maverick(17B激活/400B总) | 原生多模态,超越GPT-4o | Llama License | huggingface.co/meta-llama |
| Qwen 3 | 阿里 | Max-Thinking/VL-Flash等多系列 | 推理能力达顶级闭源模型水平 | Apache 2.0 | huggingface.co/Qwen |
| Qwen3.5 | 阿里 | 397B-A17B旗舰 / 0.8B~122B全系列 | 完整产品线覆盖边缘到云端 | Apache 2.0 | huggingface.co/Qwen |
| GLM-4.7 | 智谱 | 30B总/3B激活 | MoE架构,编程能力顶尖 | GLM License | huggingface.co/THUDM |
| Kimi-K2.5 | 月之暗面 | 32B激活/1T总 | 业界最大开源模型 | Apache 2.0 | modelscope.cn |
| DeepSeek-V3.2 | DeepSeek | 671B总/37B激活 | MoE架构,IMO/IOI金牌级数学表现 | MIT | huggingface.co/deepseek-ai |
| Mistral Large 3 | Mistral | 675B总/41B激活 | 256K上下文,高效MoE架构 | Apache 2.0 | huggingface.co/mistralai |
部署开源模型的方式
1. 本地部署(需要GPU):
- 硬件要求:8GB显存起(7B模型),24GB+(70B模型)
- 工具:Ollama、LM Studio、vLLM
- 适合:开发测试、小规模使用
2. 云端部署:
- GPU租用:阿里云/AWS/AutoDL等(¥2-20/小时)
- 托管服务:Hugging Face Inference API
- 适合:生产环境、大规模应用
3. 量化加速:
- 4-bit量化:模型体积减少75%,几乎不损失性能
- 工具:GPTQ、AWQ、llama.cpp
快速上手(Python示例)
# 使用transformers库加载开源模型from transformers import AutoTokenizer, AutoModelForCausalLM# 加载GLM-4.7-Flash模型(轻量高效)model_name = "THUDM/glm-4-9b-chat"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="auto")# 对话messages = [{"role": "user", "content": "你好,介绍一下你自己"}]inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)outputs = model.generate(inputs, max_length=200)print(tokenizer.decode(outputs[0], skip_special_tokens=True))
🌍 国内可用的开源模型资源
| 平台 | 内容 | 访问 |
|---|---|---|
| Hugging Face | 模型下载中心(需镜像) | huggingface.co |
| 魔搭社区 | 国内镜像,速度快 | modelscope.cn |
| 始智AI | 开源模型评测榜单 | flageval.baai.ac.cn |
推荐入门模型(由易到难):
- GLM-4.7-Flash(3B激活):轻量高效,手机/笔记本可跑
- Llama 4 Scout(17B激活):单张H100可跑,原生多模态
- Qwen3系列:中文场景首选,多系列可选
- Llama 4 Maverick(17B激活/400B总):媲美GPT-4o的顶级开源模型
- Kimi-K2.5(1T总参数):最大开源模型,需多卡部署
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)