提示词缓存完全指南:一文吃透这个大模型性能优化的秘密武器
其中包括系统指令、工具定义,以及它在三回合前已经处理过的项目上下文。所有这些内容在每一轮都会被重新读取、重新处理,并被重新计费。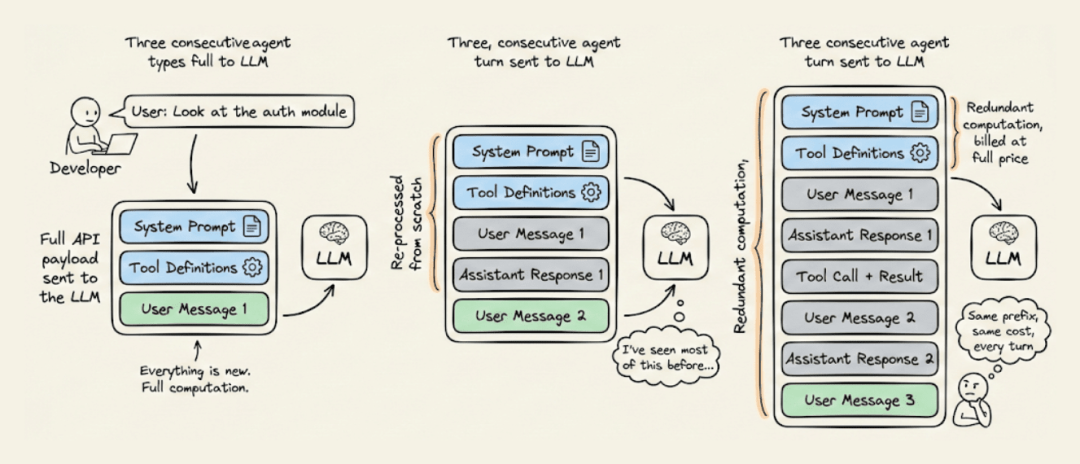
对于长时间运行的智能体工作流,这种冗余计算往往是你整个AI基础设施中最昂贵的支出。
一个包含20,000个Token的系统提示运行50轮,意味着100万个Token的冗余计算以全价计费,却产生不了任何新价值。而且这个成本会在每个用户和每个会话中累积。
解决方案就是提示词缓存。但要很好地使用它,你需要理解底层实际发生了什么。
静态上下文 vs 动态上下文
在优化提示之前,你需要了解什么会变化,什么不会变化。
每个智能体请求都有两个本质不同的部分:
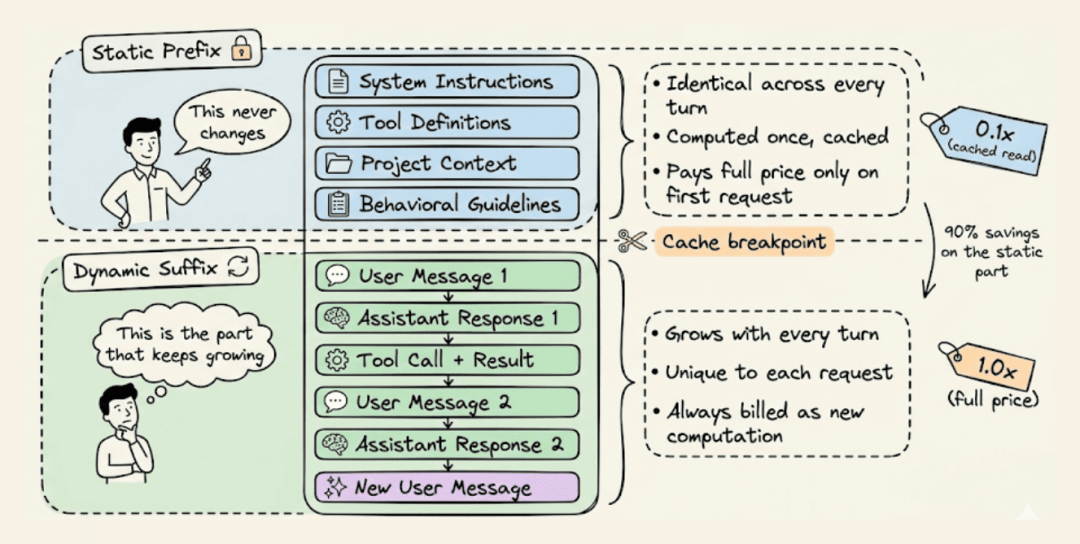
- • 静态前缀:跨轮保持相同的部分:系统指令、工具定义、项目上下文和行为准则。
- • 动态后缀:随着每一轮增长的部分:用户消息、助手响应、工具输出和终端观察。
这种分离使得提示词缓存成为可能。基础设施会存储静态前缀的数学状态,以便后续共享该精确前缀的请求可以完全跳过计算,直接从内存中读取。
一旦你理解了这一点,本文中的每个架构决策都变得显而易见了。
KV缓存是如何工作的?
要理解缓存为何如此有效,你需要了解Transformer在处理提示时实际做了什么。
每个大语言模型推理请求都有两个阶段:
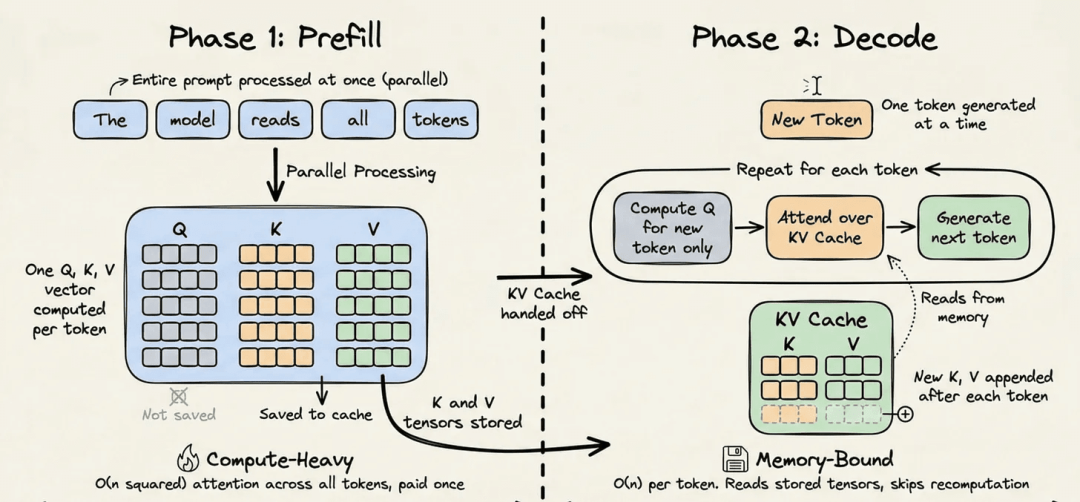
- • 预填充阶段:处理整个输入提示。它在上下文中的所有Token上运行密集矩阵乘法,以构建模型的内部表示。这是计算密集型且昂贵的。
- • 解码阶段:一次生成一个Token。每个新Token被添加到序列中,模型预测下一个Token。这个阶段是内存密集型的,因为它主要读取历史状态而不是进行重计算。
在预填充阶段,Transformer为每个Token计算三个向量:Query(查询)、Key(键)和Value(值)。注意力机制利用这些来确定每个Token与其他Token的关系。任何给定Token的Key和Value向量只取决于它前面的Token,一旦计算完成,它们就永远不会改变。
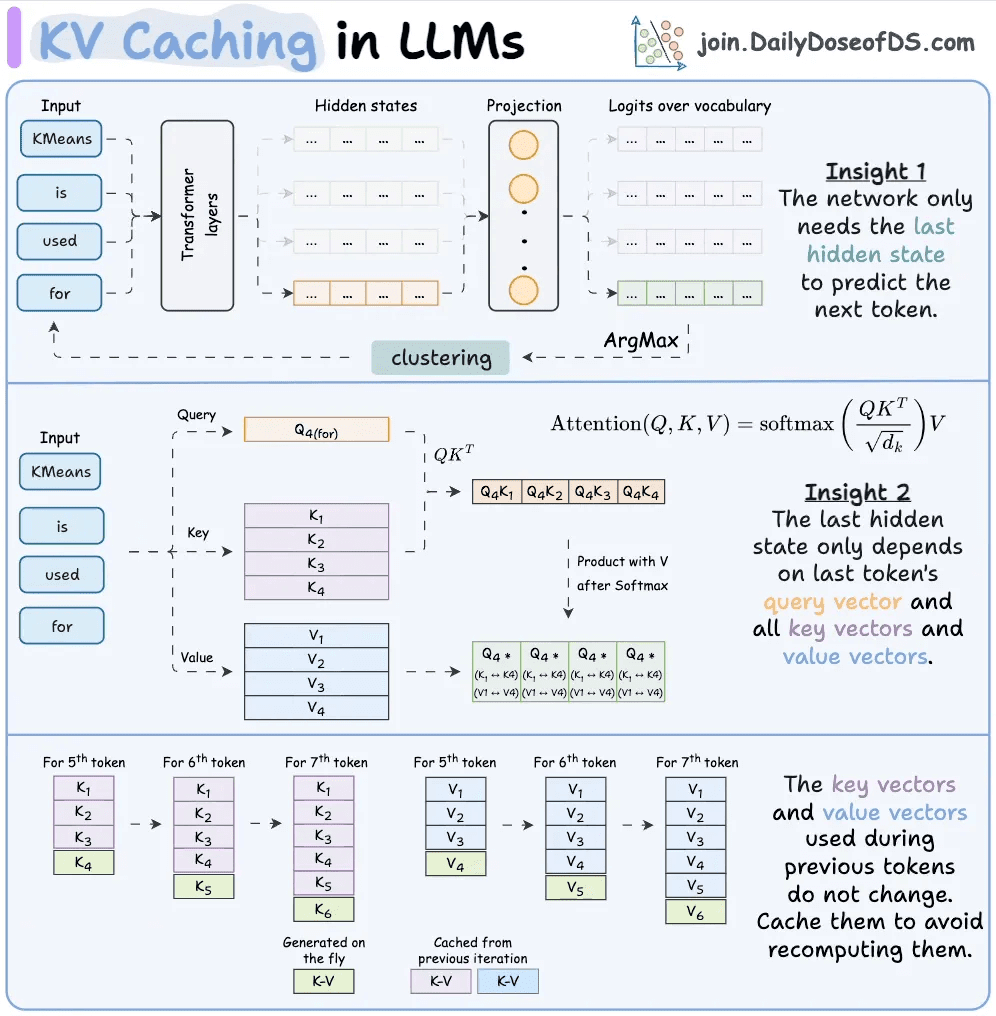
没有缓存的情况下,这些Key和Value张量在每个请求后都会被丢弃,下一个请求会从头重新计算它们。对于20,000个Token的前缀,这意味着20,000个Token的注意力计算本不必再次发生。
KV缓存通过在推理服务器上持久化这些张量来解决这个问题,使用Token序列的加密哈希作为索引。当新请求带有相同前缀到来时,哈希匹配,张量从内存中加载,这些Token的预填充计算被完全跳过。
这将每生成一个Token的计算复杂度从O(n²)降低到O(n)。对于跨50轮重复的20,000个Token前缀,这是一个巨大的减少。
经济性
定价结构使得这个架构决策变得如此重要。
缓存读取只需基础输入价格的0.1倍,即每个缓存的Token享受90%的折扣。缓存写入需要1.25倍,即25%的溢价来存储KV张量。延长到一小时的缓存需要2.0倍。
以下是跨Anthropic的Claude模型的情况:
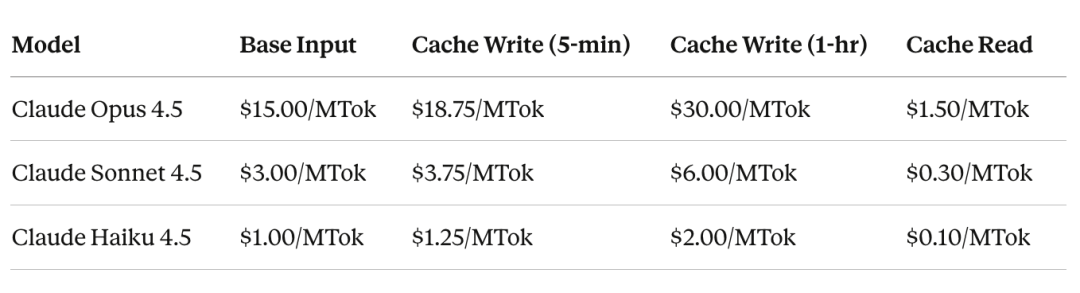
这个计算只有在缓存命中率保持高位时才有效。Claude Code是生产环境中最好的例子。
使用Claude Code的30分钟编码会话
Claude Code完全围绕一个目标构建:保持缓存热状态。
以下是从计费角度来看一个真实的30分钟编码会话是什么样的。
第0分钟:Claude Code加载其系统提示、工具定义和项目的CLAUDE.md文件。这个有效载荷超过20,000个Token,由于每个Token都是新的,这是整个会话中最昂贵的时刻。但你只需支付这一次成本。
第1-5分钟:你开始给出指令,Claude Code派出探索子智能体导航代码库、打开文件并运行grep命令。所有这些都被追加到动态后缀中。但这20,000个Token的静态前缀现在以0.30美元/百万Token的价格从缓存读取,而不是3.00美元/百万Token。
第6-15分钟:计划子智能体收到的是一个摘要简报而不是原始结果,因为传递原始输出会不必要地膨胀动态后缀。它产生一个实施计划,你批准后,Claude Code开始进行更改。每一轮都从缓存读取静态前缀,命中率攀升至90%以上,每次访问都会重置TTL以保持缓存温热。
第16-25分钟:你请求更改,这意味着更多的工具调用、更多的终端输出,以及更多的上下文累积在动态后缀中。到目前为止,会话已经处理了数十万个Token,但每一轮都是从缓存中读取这20,000个Token的基础。
第28分钟:你在终端运行/cost。如果没有缓存,200万个Token以Sonnet 4.5的价格计算将花费6.00美元。由于缓存以92%的效率运行,184万个Token是缓存读取,总成本降至1.15美元。这是一个任务上81%的成本降低。
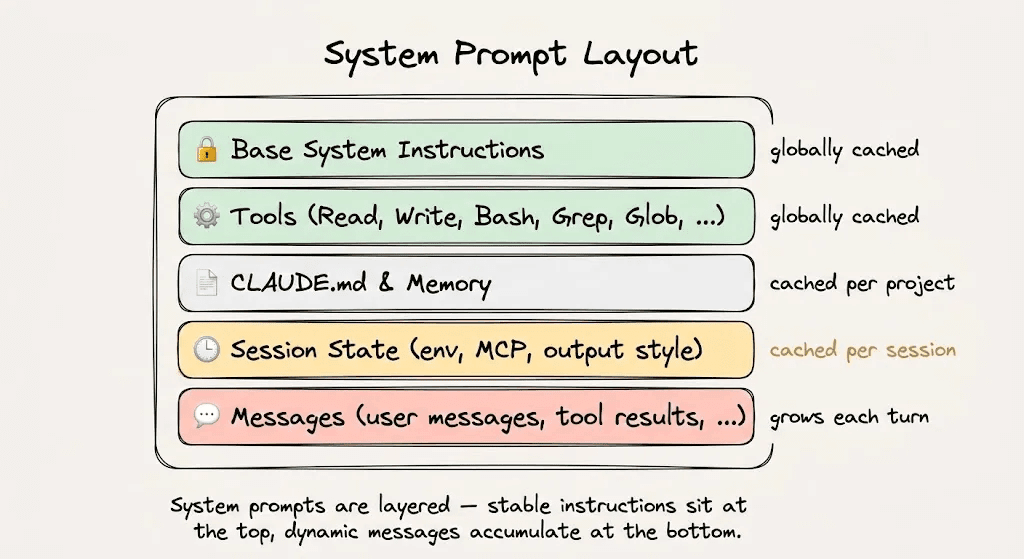
这就是热缓存的样子。你只需为静态基础支付一次费用,然后就可以免费读取它。动态尾部是唯一被收费的部分。
基于哈希缓存的脆弱性
关于提示词缓存,最反直觉的事情是:
"1 + 2 = 3"有效,但"2 + 1"会导致缓存未命中。
基础设施从头开始对整个Token序列进行哈希。如果序列中的任何内容发生变化,即使只是两个元素的顺序,哈希也会发生变化,整个前缀都会以全价重新计算。
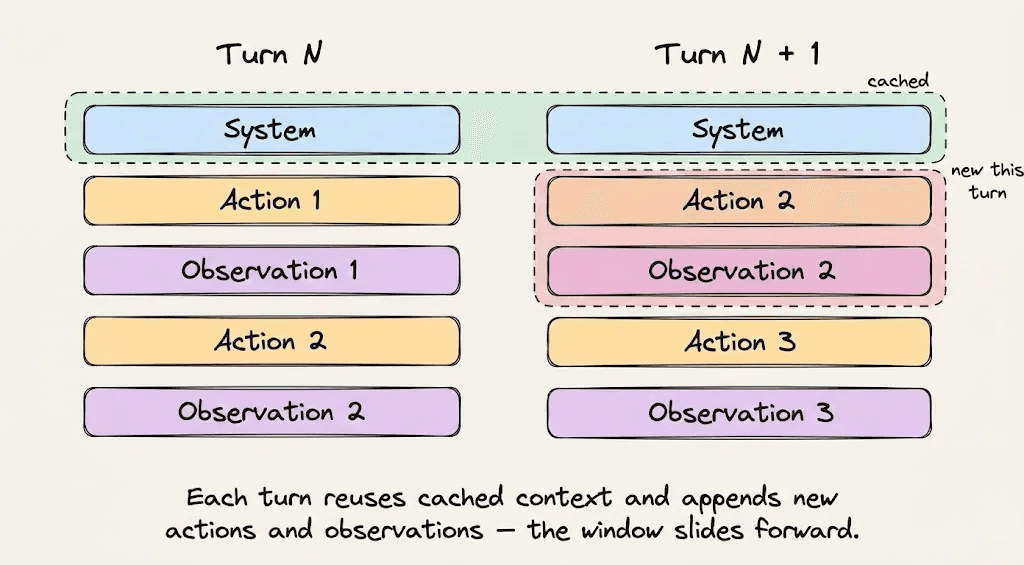
这不是一个小的实现细节。这是Claude Code中每个工程决策都围绕的核心约束。
以下是生产中导致缓存失效的真实例子:
- • 注入系统提示的时间戳在每个请求上创建了唯一的哈希。
- • JSON序列化器在请求之间以不同方式排序工具模式键,使前缀失效。
- • 会话中更新参数的AgentTool清除了整个20,000个Token的缓存。
由此产生三条规则:
-
- 会话期间不要修改工具。工具定义是缓存前缀的一部分,因此添加或移除工具会使下游所有内容失效。
-
- 会话期间永远不要切换模型。缓存是模型特定的,这意味着会话中途切换到更便宜的模型需要从头重建整个缓存。
-
- 永远不要修改前缀来更新状态。Claude Code不会编辑系统提示,而是在下一条用户消息中追加一个提醒标签,这样前缀就保持不变。
将此应用到你自己的智能体
无论你使用Claude Code还是从头构建自己的智能体,相同的规则都适用。
按以下顺序组织你的提示:
-
- 顶部的系统指令和行为规则。会话期间不要更改它们。
-
- 预先加载所有工具定义。不要添加或移除它们。
-
- 然后是检索的上下文和参考文档。在整个会话期间保持它们稳定。
-
- 底部的对话历史和工具输出。这是你的动态后缀。
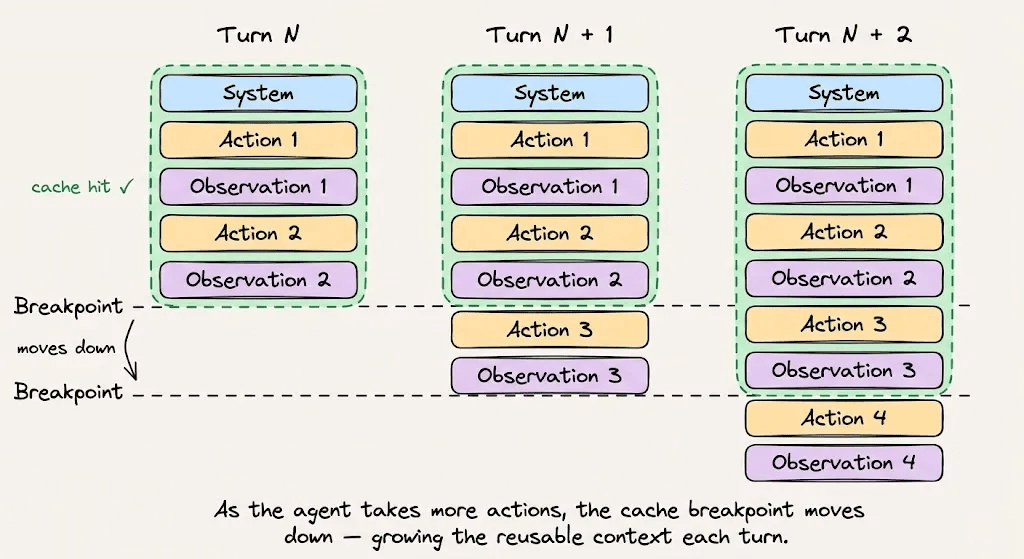
在Anthropic API上启用自动缓存后,缓存断点会随着对话增长自动推进。没有它,你需要手动跟踪Token边界,而错误的边界意味着完全错过缓存。
当接近上下文限制时进行上下文压缩,请使用缓存安全的分叉。保持相同的系统提示、工具和对话历史,然后将压缩指令作为新消息追加。缓存的前缀被重用,唯一被计费的新Token是压缩指令本身。
验证你的缓存是否工作
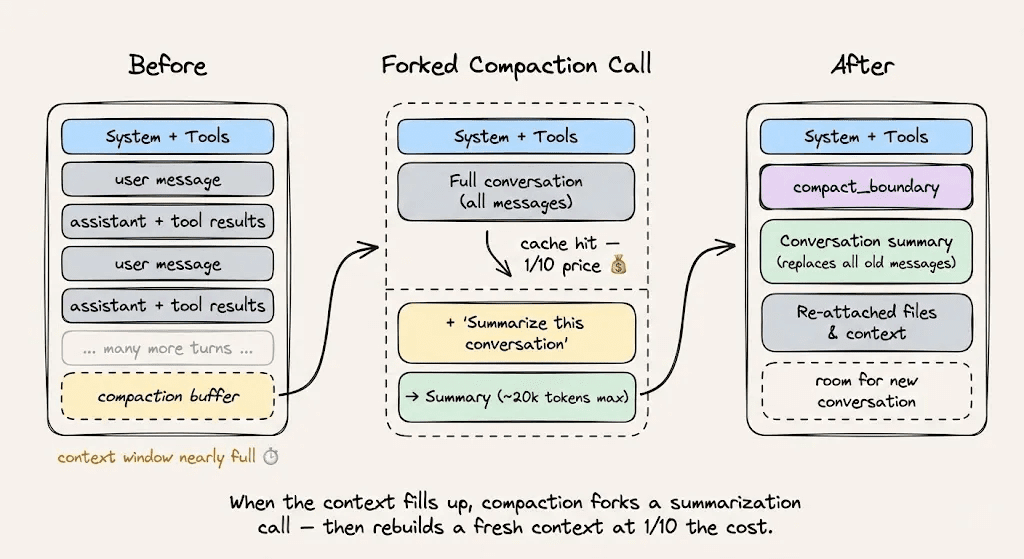
要验证你的缓存是否正常工作,请监控API响应中的这三个字段:
- •
cache_creation_input_tokens:写入缓存的Token。 - •
cache_read_input_tokens:从缓存服务的Token。 - •
input_tokens:未使用缓存处理的Token。
你的缓存效率 = cache_read_input_tokens / (cache_read_input_tokens + cache_creation_input_tokens)。像跟踪正常运行时间一样跟踪它。
关键要点
提示词缓存不是一个你可以切换的功能,它是你围绕设计的架构原则。
核心思想很简单:组织你的提示,使静态内容位于顶部,动态内容在底部增长。基础设施对前缀进行哈希,存储KV张量,并在每次后续读取时给你90%的折扣。
但原则体现在细节中。不要将时间戳注入系统提示,不要打乱工具定义,会话期间不要切换模型,不要修改缓存断点上游的任何内容。
Claude Code展示了大规模运行的样子,缓存命中率为92%,成本降低81%。如果你正在构建智能体而不是围绕提示词缓存进行设计,你将把大部分利润留在桌面上。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献156条内容
已为社区贡献156条内容

所有评论(0)