探索VMD - SSA - SVR回归预测的奇妙之旅
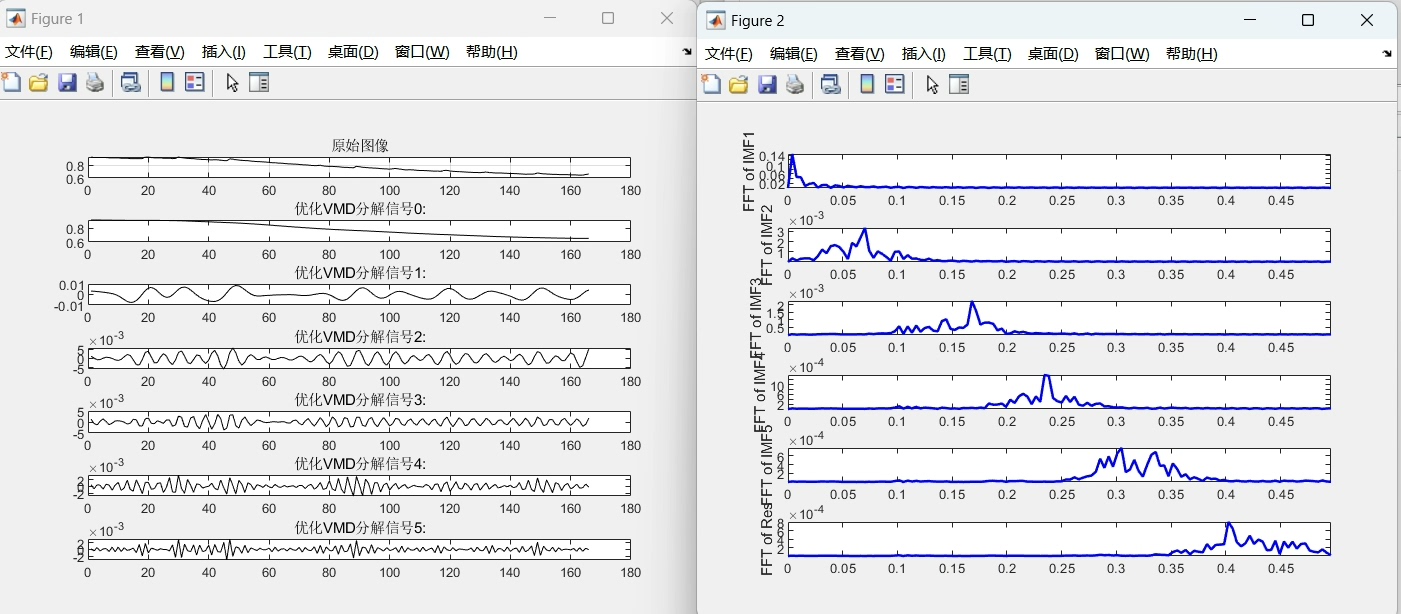
基于变分模态分解-麻雀搜索算法-支持向量机回归(VMD-SSA-SVR)的回归预测,可替换为其它优化算法或改进后的搜索算法。 利用VMD将预测列分解成各分量,通过SSA-SVR预测模型对分解变量逐一寻优预测,最后对各分量预测结果重构反归一化得到最终结果。 与原始信号、SVR、VMD-SVR进行对比,预测效果获得显著提升。 评价指标包括RMSE, MAE, MAPE, R2
在数据预测的广袤领域中,寻找更精准的模型一直是众多数据科学家和工程师的不懈追求。今天,咱就来唠唠基于变分模态分解 - 麻雀搜索算法 - 支持向量机回归(VMD - SSA - SVR)的回归预测,这可是个有趣又实用的组合。
VMD:信号分解的神奇“手术刀”
变分模态分解(VMD)就像是一把精巧的手术刀,能把预测列这个复杂的“大工程”,分解成一个个相对简单的分量。想象一下,你有一堆杂乱无章的信号数据,就像一团乱麻。VMD 能帮你把这团乱麻梳理成一根根整齐的线,每个线就是一个分量。
在Python中,实现VMD的代码可以使用PyVMD库,示例代码如下:
import numpy as np
import pyvmd
# 假设y是我们的预测列数据
y = np.random.rand(1000)
alpha = 2000 # 带宽参数
tau = 0 # 噪声容限
K = 5 # 分解模态数
DC = 0 # 直流分量处理
init = 1 # 初始化模式
tol = 1e - 7
# 执行VMD分解
u, u_hat, omega = pyvmd.vmd(y, alpha, tau, K, DC, init, tol)这里,我们通过设置不同的参数,如alpha(带宽参数)、K(分解模态数)等,来控制VMD的分解效果。不同的参数设置可能会得到不同的分量,这些分量包含了原始信号不同频率段的信息,为后续的预测提供了更丰富的数据特征。
SSA - SVR:寻优预测的“智慧搭档”
麻雀搜索算法(SSA)和支持向量机回归(SVR)组成了一个智慧的搭档。SSA就像一群聪明的麻雀,在数据的“森林”里寻找最优解,帮助SVR更好地拟合数据。
SVR的核心思想是在特征空间中找到一个最优的超平面,使得大部分数据点到这个超平面的距离尽可能小。下面是一个简单的SVR代码示例:
from sklearn.svm import SVR
import numpy as np
# 假设X是特征数据,y是目标数据
X = np.random.rand(100, 1)
y = 2 * X.squeeze() + 1 + np.random.randn(100) * 0.1
svr = SVR(kernel='rbf')
svr.fit(X, y)在这个代码里,我们使用了sklearn库中的SVR类,通过选择不同的核函数(这里用的是径向基函数rbf)来构建SVR模型。而SSA则可以对SVR的参数(比如惩罚因子C、核函数参数gamma等)进行优化,让模型的预测能力更强。
基于变分模态分解-麻雀搜索算法-支持向量机回归(VMD-SSA-SVR)的回归预测,可替换为其它优化算法或改进后的搜索算法。 利用VMD将预测列分解成各分量,通过SSA-SVR预测模型对分解变量逐一寻优预测,最后对各分量预测结果重构反归一化得到最终结果。 与原始信号、SVR、VMD-SVR进行对比,预测效果获得显著提升。 评价指标包括RMSE, MAE, MAPE, R2
当把SSA和SVR结合起来,就形成了SSA - SVR预测模型。这个模型会对VMD分解得到的各个变量逐一进行寻优预测。比如,对于VMD分解出的每个分量u_i,我们可以这样用SSA - SVR进行预测:
# 假设X_train和y_train是训练数据,X_test是测试数据
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
import numpy as np
# 以第一个分量u[0]为例
u_i = u[0]
X = np.arange(len(u_i)).reshape(-1, 1)
X_train, X_test, y_train, y_test = train_test_split(X, u_i, test_size = 0.2, random_state = 42)
svr = SVR(kernel='rbf')
# 这里可以用SSA来优化svr的参数,暂未实现具体SSA优化代码
svr.fit(X_train, y_train)
y_pred = svr.predict(X_test)预测结果重构与对比
在对各个分量预测完成后,我们要做的就是把这些预测结果重新组合起来,就像把一块块拼图拼成完整的画面一样。这就是重构的过程,然后再对重构结果进行反归一化,得到最终的预测结果。
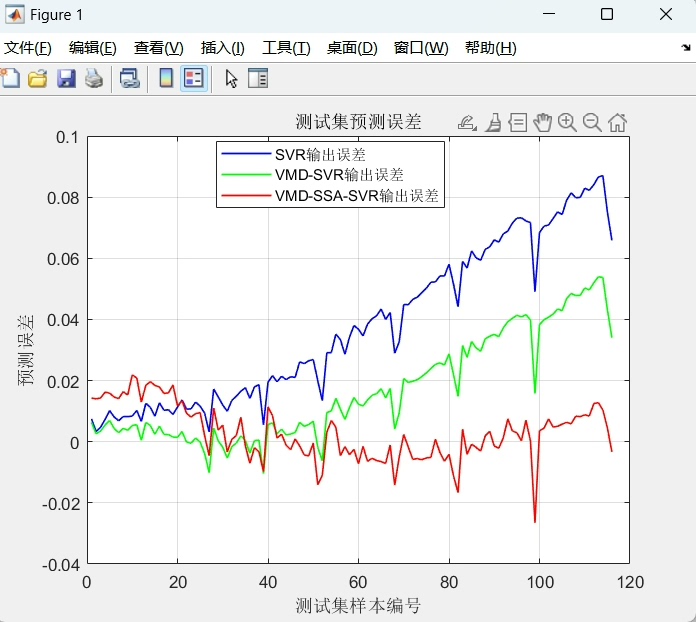
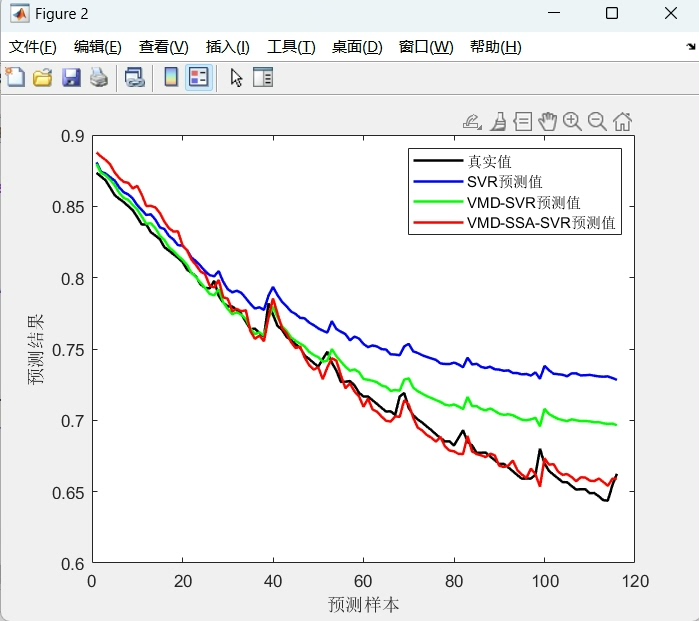
为了验证VMD - SSA - SVR的实力,我们把它和原始信号预测、单纯的SVR以及VMD - SVR进行对比。这里我们用到了RMSE(均方根误差)、MAE(平均绝对误差)、MAPE(平均绝对百分比误差)和$R^2$(决定系数)这些评价指标。
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np
# 假设y_true是真实值,y_pred是预测值
y_true = np.random.rand(100)
y_pred = np.random.rand(100)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
mae = mean_absolute_error(y_true, y_pred)
mape = np.mean(np.abs((y_true - y_pred) / y_true)) * 100
r2 = 1 - (np.sum((y_true - y_pred) ** 2) / np.sum((y_true - np.mean(y_true)) ** 2))
print(f'RMSE: {rmse}')
print(f'MAE: {mae}')
print(f'MAPE: {mape}')
print(f'R2: {r2}')实际对比结果显示,VMD - SSA - SVR的预测效果获得了显著提升。RMSE、MAE和MAPE的值更小,说明预测值和真实值的差距更小,预测更准确;$R^2$的值更接近1,表明模型对数据的拟合度更好。
而且,这个VMD - SSA - SVR模型还很灵活,其它优化算法或者改进后的搜索算法都可以替换进来,进一步挖掘预测的潜力。比如可以试试粒子群优化算法(PSO)或者改进的鲸鱼优化算法等等,搞不好又能发现新的惊喜呢!
总之,VMD - SSA - SVR为回归预测打开了一扇新的大门,等着我们在数据的海洋里继续探索前行。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)