基于匿名管道实现的进程池
1. 认识进程池
什么是进程池?进程池是一种资源预创建技术:
- 在系统启动时,预先创建一组子进程;
- 这些进程处于“待命”状态,不消耗 CPU,但随时可用;
- 任务到来时,直接分配给空闲进程,避免频繁创建/销毁的开销。
进程池是一种池化技术。池化技术的本质:对资源进行批量预创建,以换取更高的响应速度和更低的延迟。广泛应用于线程池、连接池、内存池等场景。
类比:消防水库 —— 水库中预先蓄水,火灾发生时无需寻找水源,直接灭火;进程池中预先创建进程,任务到达时无需 fork,直接调度。
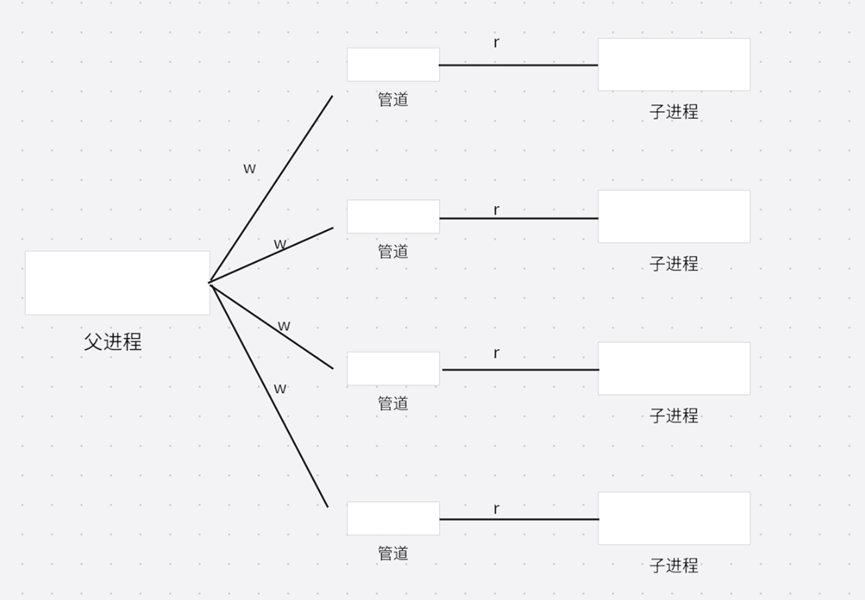
图中展示了一个典型的 Master-Slave 进程池 模型:
- 父进程(Master)创建多个子进程(Slave);
- 每个子进程拥有一个独立的管道,用于接收任务指令;
- 父进程通过向特定管道写入数据,通知对应子进程执行任务。
这种模式称为“主从式进程池”:
- 父进程是 Master,负责任务调度;
- 子进程是 Slave,负责执行任务;
- 通过管道实现轻量级通信与同步。
工作流程:
- 所有子进程启动后,立即进入循环,调用 read() 等待任务;
- 若管道为空,read() 阻塞,子进程暂停执行;
- 当父进程向某个子进程的管道写入数据时,内核唤醒该子进程,使从 read() 返回;
- 子进程读取数据,解析任务编号,执行对应函数;
- 执行完毕后,再次进入 read() 等待下一个任务。
为什么能实现“定向控制”?
- 每个子进程绑定一个专属管道;
- 父进程写哪个管道,就唤醒哪个子进程;
- 通过任务编号(如数组下标),可将不同任务分发给不同子进程。
2. 实现进程池
2.1 实现基本框架
Channel 类
父进程要通过一个个通道(管道)控制子进程,就需要管理这些通道,即这些通道的文件描述符是什么,通道所对应的子进程是哪一个,管道的名称。实现一个管道类:class Channel,先确定好通道类的成员属性,成员方法等到需要时再实现。
class Channel
{
public:
Channel(int wfd, pid_t pid) // 构造函数
: _wfd(wfd), _child_pid(pid)
{
// 自定义实现子进程的名字,to_string 函数将整型转化成字符串
_child_name = "child_name-" + std::to_string(_child_pid);
}
~Channel() {} // 析构函数
private:
// 成员属性
int _wfd; // 写文件描述符
pid_t _child_pid; // 对应的子进程的pid
std::string _child_name; // 管道的名称
};自定义退出码表
在代码实现过程中,会存在多种退出信息,因此自定义一个退出码表。使用枚举:
// 定义常量列表
enum
{
NO_PROBLEM = 0, // 没有问题
PIPE_CREATE_ERROR, // 管道创建失败
FORK_CREATE_ERROR // 子进程创建失败
};创建管道和子进程
子进程所要执行的任务不清楚,因此简单实现一个 Task 空函数。
void Task(int fd)
{
while (true)
{
sleep(1);
}
}我们要实现进程间的通信,子进程在父进程的控制下执行自己的任务。实现父进程写,子进程读,因此父进程关闭读端,子进程关闭写端。
// 1. 创建多个管道
int pipefd[2] = {0}; // 文件描述符数组
int n = pipe(pipefd); // 创建管道
if (n < 0) // 创建管道失败
{
std::cerr << "pipe create error" << std::endl; // 使用C++中打印错误的方式
exit(PIPE_CREATE_ERROR);
}
// 创建管道成功,创建子进程
pid_t id = fork();
if (id < 0) // 创建子进程失败
{
std::cerr << "chile process create error" << std::endl; // 使用C++中打印错误的方式
exit(FORK_CREATE_ERROR);
}
else if (id == 0) // 子进程
{
close(pipefd[1]); // 子进程读,关闭写端
exit(NO_PROBLEM);
}
else // 父进程
{
close(pipefd[0]); // 父进程写,关闭读端
}似乎还没有实现进程池呀?也没有创建多个管道和多个子进程?我们固定创建5个子进程,那么管道也是创建5个。我们之前所实现的代码都是创建一个子进程和一个管道,那么循环执行5次,就可以实现我们创建进程池的要求了。
for (int i = 0; i < processNum; i++)
{
// 1. 创建多个管道
int pipefd[2] = {0}; // 文件描述符数组
int n = pipe(pipefd); // 创建管道
if (n < 0) // 创建管道失败
{
std::cerr << "pipe create error" << std::endl; // 使用C++中打印错误的方式
exit(PIPE_CREATE_ERROR);
}
// 创建管道成功,创建子进程
pid_t id = fork();
if (id < 0) // 创建子进程失败
{
std::cerr << "chile process create error" << std::endl; // 使用C++中打印错误的方式
exit(FORK_CREATE_ERROR);
}
else if (id == 0) // 子进程
{
close(pipefd[1]); // 子进程读,关闭写端
Task(pipefd[0]); // 从管道中读取任务
exit(NO_PROBLEM);
}
else
{
// 父进程执行的任务
// 子进程不会执行后续的代码,在执行完自己的任务后就退出了,执行循环任务的只有父进程
close(pipefd[0]); // 父进程写,关闭读端
}
}processNum 定义成全局变量。
基本实现完毕后,考虑下一步的进行,实现子进程所要执行的任务函数:子进程要从管道处获取任务,因此要读取管道。但是管道数组 pipe 是一个临时变量,一旦当前的循环结束,只有管道的读文件描述符被对应的子进程所获取了,但是父进程没有办法获取到管道的写文件描述符。
站在父进程的角度,需要管理一个个的管道,每个管道都以 Channel 类的方式实现,需要管理这些管道的写文件描述符,因此需要“先描述,再组织”。我们已经实现“先描述”这一步了,接下来需要完成“再组织”这一步,使用 vector 容器组织 Channel 类。
std::vector<Channel> channels;在循环体中父进程没有办法获取到管道的写文件描述符,那么就定义一个 channel 对象,将管道的写文件描述符和子进程的 pid 初始化 channel 对象。
else
{
// 父进程执行的任务
// 子进程不会执行后续的代码,在执行完自己的任务后就退出了,执行循环任务的只有父进程
close(pipefd[0]); // 父进程写,关闭读端
// 保存管道的写端,将管道写文件描述符和子进程的 pid 传给 channel 类对象
Channel ch(pipefd[1], id);
// 保存到组织 Channel 类的容器中
channels.push_back(ch);
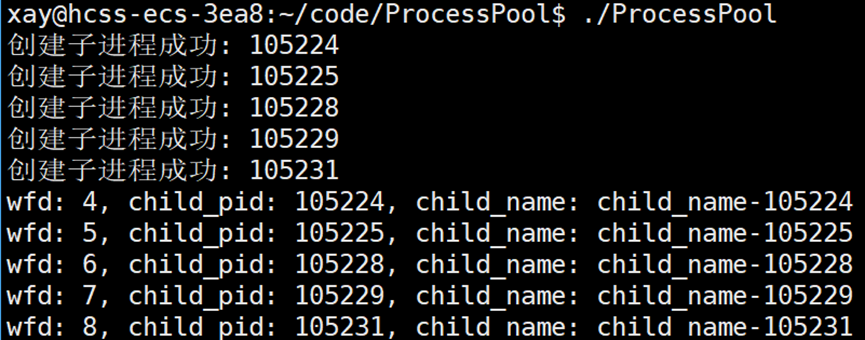
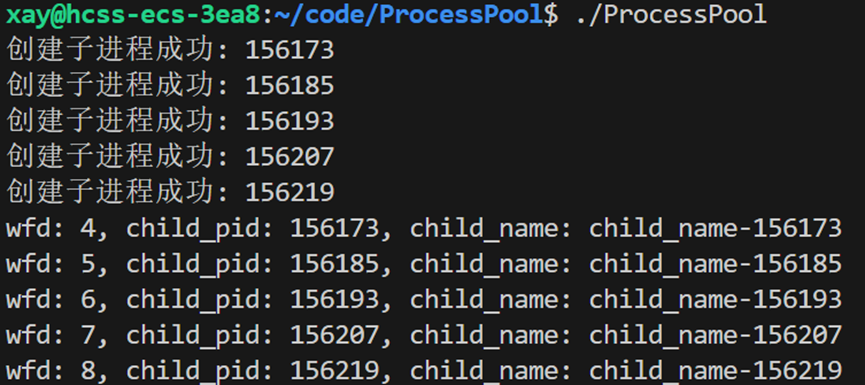
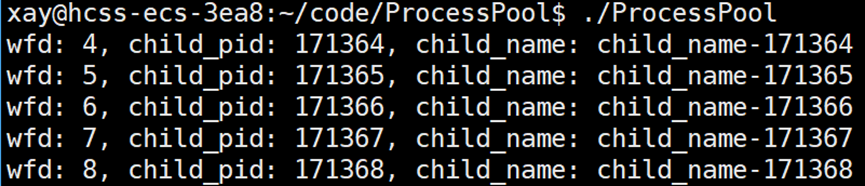
}测试当前实现的程序,要看到的结果:父进程创建5个子进程。

为了方便显示 channel 对象的信息,在 Channel 类中实现一个 PrintInfo 函数:
void PrintInfo()
{
printf("wfd: %d, child_pid: %d, child_name: %s\n", _wfd, _child_pid, _child_name.c_str());
}调用 PrintInfo 函数,观察结果:
2.2 优化框架
优化点1
使用 emplace_back 函数替换 push_back 函数:
// 保存管道的写端,将管道写文件描述符和子进程的 pid 传给 channel 类对象
// Channel ch(pipefd[1], id);
// // 保存到组织 Channel 类的容器中
// channels.push_back(ch);
channels.emplace_back(pipefd[1], id);优化点2
将创建子进程和管道功能的代码封装成函数 —— CreatProcessAndChannel:
void CreatProcessAndChannel(cb_t cb)
{
for (int i = 0; i < processNum; i++)
{
// 1. 创建多个管道
int pipefd[2] = {0}; // 文件描述符数组
int n = pipe(pipefd); // 创建管道
if (n < 0) // 创建管道失败
{
std::cerr << "pipe create error" << std::endl; // 使用C++中打印错误的方式
exit(PIPE_CREATE_ERROR);
}
// 创建管道成功,创建子进程
pid_t id = fork();
if (id < 0) // 创建子进程失败
{
std::cerr << "chile process create error" << std::endl; // 使用C++中打印错误的方式
exit(FORK_CREATE_ERROR);
}
else if (id == 0) // 子进程
{
close(pipefd[1]); // 子进程读,关闭写端
Task(pipefd[0]); // 从管道中读取任务
exit(NO_PROBLEM);
}
else
{
// 父进程执行的任务
// 子进程不会执行后续的代码,在执行完自己的任务后就退出了,执行循环任务的只有父进程
close(pipefd[0]); // 父进程写,关闭读端
// // 保存管道的写端,将管道写文件描述符和子进程的 pid 传给 channel 类对象
// Channel ch(pipefd[1], id);
// // 保存到组织 Channel 类的容器中
// channels.push_back(ch);
channels.emplace_back(pipefd[1], id);
// 测试
std::cout << "创建子进程成功: " << id << std::endl;
sleep(2);
}
}
}但是在 CreateProcessAndChannel 函数中获取不到 channels 了呀?CreateProcessAndChannel 函数内部还需要 channels 函数调用 emplace_back 函数呀?
优化点3
可以实现实现进程池,定义一个 ProcessPool 类,将 CreateProcessAndChannel 函数定义成成员函数,成员变量为保存 channel 管道的对象:
// 创建进程池类
class ProcessPool
{
public:
ProcessPool() {} // 构造函数
~ProcessPool() {} // 析构函数
private:
// 1. 创建多个进程和管道
void CreatProcessAndChannel(cb_t cb)
{
for (int i = 0; i < processNum; i++)
{
// 1. 创建多个管道
int pipefd[2] = {0}; // 文件描述符数组
int n = pipe(pipefd); // 创建管道
if (n < 0) // 创建管道失败
{
std::cerr << "pipe create error" << std::endl; // 使用C++中打印错误的方式
exit(PIPE_CREATE_ERROR);
}
// 创建管道成功,创建子进程
pid_t id = fork();
if (id < 0) // 创建子进程失败
{
std::cerr << "chile process create error" << std::endl; // 使用C++中打印错误的方式
exit(FORK_CREATE_ERROR);
}
else if (id == 0) // 子进程
{
close(pipefd[1]); // 子进程读,关闭写端
Task(pipefd[0]); // 从管道中读取任务
exit(NO_PROBLEM);
}
else
{
// 父进程执行的任务
// 子进程不会执行后续的代码,在执行完自己的任务后就退出了,执行循环任务的只有父进程
close(pipefd[0]); // 父进程写,关闭读端
// // 保存管道的写端,将管道写文件描述符和子进程的 pid 传给 channel 类对象
// Channel ch(pipefd[1], id);
// // 保存到组织 Channel 类的容器中
// channels.push_back(ch);
channels.emplace_back(pipefd[1], id);
// 测试
std::cout << "创建子进程成功: " << id << std::endl;
sleep(2);
}
}
}
private:
// 组织所有的 Channel
std::vector<Channel> channels; // 成员变量
};为了方便后续的测试,在 ProcessPool 类中实现 PrintProcess 函数,打印子进程的信息:
// 打印子进程的信息
void PrintProcess()
{
for (auto &ch : channels)
{
ch.PrintInfo();
}
}在 main 函数中定义 ProcessPool 对象,创建进程池,打印进程池中进程的信息:
int main()
{
ProcessPool pp; // 创建进程池对象
pp.CreateProcessAndChannel();
pp.PrintProcess();
return 0;
}测试结果:
为了避免用户随意创建进程池,将 CreateProcessAndChannel 函数定义成私有。为了方便外部使用,定义 Init 函数,内部调用 CreateProcessAndChannel 函数。
// 初始化进程池
void InitProcessPool()
{
CreatProcessAndChannel();
}此外,还可以将 Channel 类定义成 ProcessPool 类的内部类。同样可以正常运行出结果:
初始化进程池本质上是要创建多个子进程,每个子进程需要完成什么任务,以现在实现的代码来看都是固定的,如果想让子进程自定义任务,可以使用函数指针,任务函数的返回值是void,参数为整数。
// 类型的重命名 —— 将 function<void (int)> 类型重命名为 cb_t
// typedef std::function<void (int)> cb_t;
using cb_t = std::function<void(int)>;重命名完成之后,就可以在初始化进程池中,传参数,给子进程分配任务。
// 初始化进程池
void InitProcessPool(cb_t cb)
{
CreatProcessAndChannel(cb);
}运行测试程序:
2.3 第二步:父进程控制子进程
第一步:创建多个子进程和管道完成之后,接下来做手完成第二步:父进程控制子进程。
管道是面向字节流的,如果父进程不写,子进程就会阻塞等待;但是如果子进程正在处理任务,父进程又向管道写入多个数据,而子进程在读取时可能一次性将这些数据全部读取。在进行数据解析时,可能就会出现问题。
因此,我们约定:向管道写入数据,统一4字节写入,读取数据也统一4字节读取。父进程向子进程写了10次4字节的数据,那么子进程也要按4字节读10次。如此父子进程可以通过这个约定协调读写的次数。
父进程选择一个子进程传输数据,怎么选择?为了避免只有一个少数进程在执行任务,多数进程空闲的情况,需要父进程均衡的向每个子进程派发任务。父进程均匀的将任务派发给子进程叫做负载均衡。如何实现负载均衡?轮询,随机,权重。在通道中定义一个计数器,记录历史上父进程向该管道写入几次数据,来表示每个管道的权重。这三种方法使用其中一个就可以实现负载均衡。
为了让子进程完成不同的任务,可以实现一个任务表,想让哪个子进程完成哪个任务,就传递任务码,这个任务码表示的就是数组的下标。任务码从哪里来?我们将约定好父进程向子进程每次写入4字节的数据为任务码。子进程收到任务码之后,就可以根据任务码执行指定的任务。
初步的框架已经搭建完成,总结我们需要实现的功能:子进程的选择,任务的选择,任务的派发。
在 ProcessPool 函数内部实现一个 RunProcessPool 的函数,内部用来承载将要实现的功能。
子进程的选择
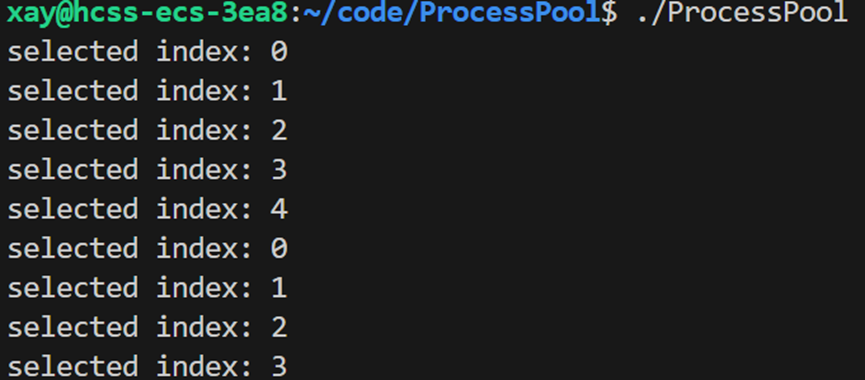
如何选择一个进程?选择子进程的本质是选择一个管道,选择一个管道也就是选择一个通道,而所有的通道都被 channel 对象管理起来了,所以选择一个进程本质上就是在 channel 中选择一个对应的进程。使用轮询的方法来选择子进程。
// 进程池运行
void RunProcessPool()
{
while(1)
{
std::cout << "-----------------------------" << std::endl;
// 1. 选择一个 channel(管道+子进程),本质上是在 vector 中选择一个下标数字
int whoindex = SelectChannel();
// 测试是否是轮询式的选择子进程
std::cout << "selected index: " << whoindex << std::endl;
sleep(1);
}
}
int SelectChannel() // 选择一个进程
{
// 使用轮询的方法选择子进程
static int index = 0; // 默认初始时选择下标为0的子进程
int select = index;
index++; // 轮询选择
index %= channels.size(); // 避免下标越界
return select;
}检测是否是轮询式的选择子进程:
任务的选择
选择任务的前提是有任务,所以需要先实现子进程要完成的任务:
void function1()
{
std::cout << "function1" << std::endl;
sleep(1);
}
void function2()
{
std::cout << "function2" << std::endl;
sleep(1);
}
void function3()
{
std::cout << "function3" << std::endl;
sleep(1);
}
void function4()
{
std::cout << "function4" << std::endl;
sleep(1);
}
void function5()
{
std::cout << "function5" << std::endl;
sleep(1);
}
typedef void (*task_t)(); // 使用函数指针
// 将上述的5个任务保存在任务数组中(全局变量)
std::vector<task_t> tasks = {function1, function2, function3, function4, function5};随机选择任务:
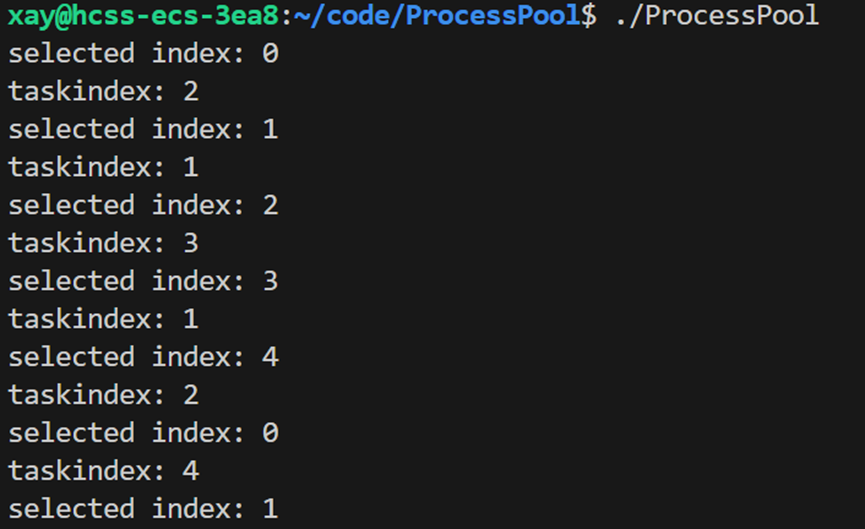
// 进程池运行
void RunProcessPool()
{
while(1)
{
std::cout << "-----------------------------" << std::endl;
// 1. 选择一个 channel(管道+子进程),本质上是在 vector 中选择一个下标数字
int whoindex = SelectChannel();
// 测试是否是轮询式的选择子进程
std::cout << "selected index: " << whoindex << std::endl;
sleep(1);
// 2. 随机选择一个任务
int task = SelectTask();
// 测试是否选择到了一个任务
std::cout << "taskindex: " << task << std::endl;
sleep(1);
}
}
int SelectTask() // 选择一个任务
{
srand((unsigned int)time(NULL)); // 定义随机数种子
int taskindex = rand() % tasks.size(); // 在任务列表中随机选择任务下标
return taskindex;
}检测功能是否是正常运行:
任务的派发
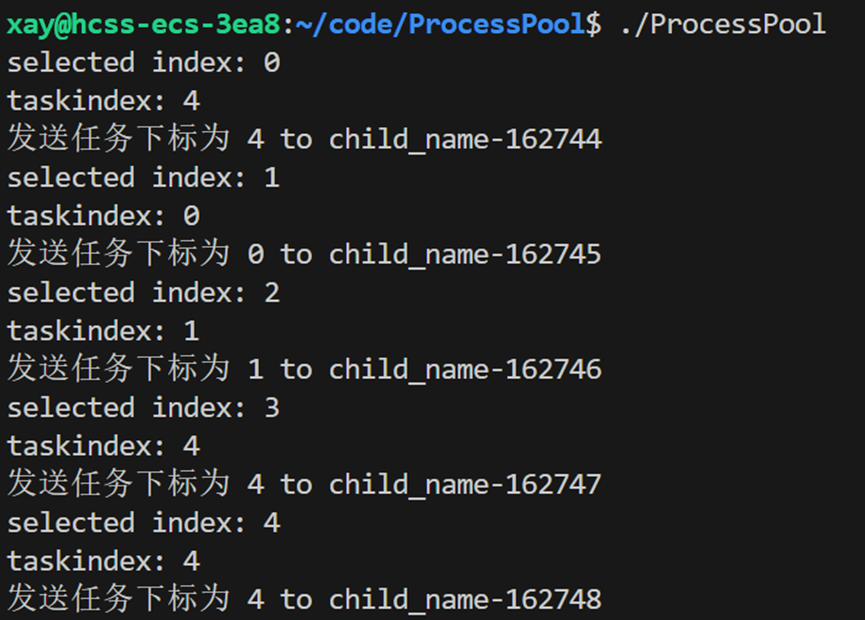
如何将任务发送给进程?管道都是由 channels 管理的,将对应的任务码 task 写给给指定的进程(whoindex)即可。
// 进程池运行
void RunProcessPool()
{
while(1)
{
std::cout << "-----------------------------" << std::endl;
// 1. 选择一个 channel(管道+子进程),本质上是在 vector 中选择一个下标数字
int whoindex = SelectChannel();
// 测试是否是轮询式的选择子进程
std::cout << "selected index: " << whoindex << std::endl;
// sleep(1);
// 2. 随机选择一个任务
int task = SelectTask();
// 测试是否选择到了一个任务
std::cout << "taskindex: " << task << std::endl;
// sleep(1);
// 3. 发送一个任务给指定的 channel(管道+子进程)
SendTasktoSalver(task, whoindex);
// 测试
printf("发送任务下标为 %d to %s\n", task, channels[whoindex].GetName().c_str());
sleep(1);
}
}
void SendTasktoSalver(int task, int whoindex)
{
// 如何将任务发送给进程?
// 管道都是由channels管理的,将对应的任务码task写给给指定的进程(whoindex)即可
// WriteTask 函数实现在 Channel 类内部
channels[whoindex].WriteTask(task);
}
void WriteTask(int task)
{
ssize_t n = write(_wfd, &task, sizeof(task)); // 这就是约定的4字节发送
(void)n;
}测试是否将选择到的任务发送给指定的进程(不写数据):
2.4 Task 函数的实现
RunProcessPool 函数内,父进程的视角:创建多个管道和子进程,将管道的写端全部保存在channels 对象中,父进程选择一个管道和对应的子进程,选择一个任务派发给指定的进程;子进程的视角:管道的读端传给回调函数,回调函数就是传递给 RunProcessPool 函数的 Task 函数,每个子进程都会调用 Task 函数,Task 函数是子进程的入口函数,子进程从管道中读取数据,并且统一规定一次读取4字节。
完善 Task 函数:
// 子进程的入口函数
void Task(int fd)
{
while (true)
{
int task_code = 0; // 获取到的任务码
// 从指定的管道读端读取数据
ssize_t n = read(fd, &task_code, sizeof(task_code));
}
}问题来了:读取管道中的数据后,子进程需要休眠吗?父进程每隔1秒向管道写入一个任务,对应的子进程再从管道中读一个任务。这不就是写端写得慢的情况吗?因此子进程不需要休眠,因为管道具有同步功能。
继续完善 Task 函数:
// 子进程的入口函数
void Task(int fd)
{
while (true)
{
int task_code = 0; // 获取到的任务码
// 从指定的管道读端读取数据
ssize_t n = read(fd, &task_code, sizeof(task_code));
// 返回值的大小等于任务码的大小,即读取到的数据的长度等于任务码的长度就可以说明获取到了任务码
if (n == sizeof(task_code))
{
if (task_code >= 0 && task_code <= tasks.size()) // 检测任务码是否安全
{
// 根据任务码选择对应的任务,并执行任务表中的任务
tasks[task_code]();
}
}
// 子进程读到0,即读到了管道的结尾,即父进程关闭了管道的写端,子进程需要退出了
else if (n == 0)
{
std::cout << getpid() << " quit ..." << std::endl; // 显示哪个子进程退出了
break;
}
else
{
perror("read"); // 读取错误
break;
}
}
}Task 回调函数调用完毕之后,会返回当时的调用处。
测试:
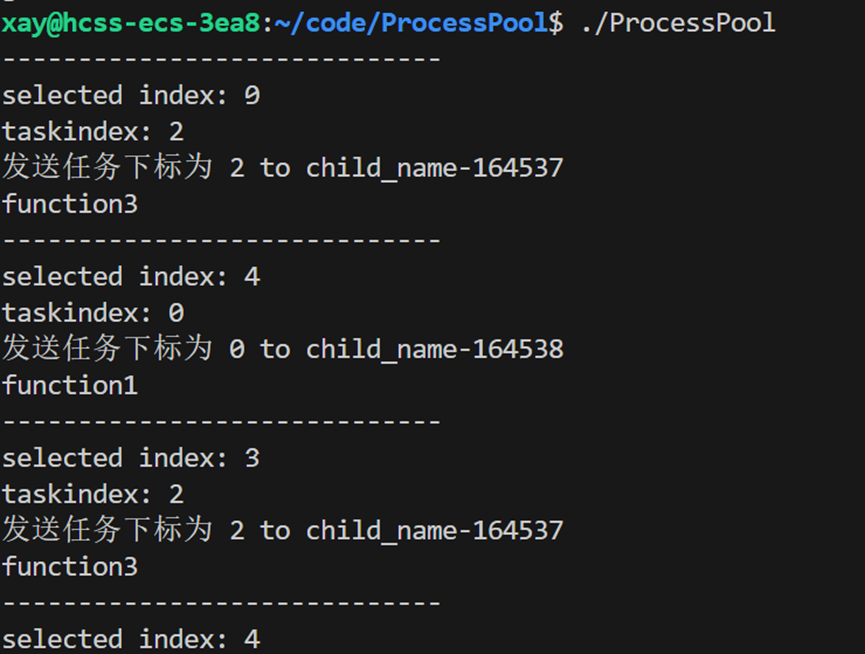
2.5 第三步:释放和回收所有资源
实现 QuitPeocessPool 函数,只需要父进程关闭管道的写端,子进程读取管道的结尾时,会自动退出,退出后子进程会进入僵尸状态,需要父进程回收子进程。那么具体就分成了两步:1. 退出所有子进程;2. 回收子进程。
释放和回收所有资源将会提供 3 个版本.
version1
先退出所有的子进程,再回收。
// 进程池退出
void QuitProcessPool()
{
// version1:
// 1. 退出所有的子进程
for (auto &channel : channels) // 关闭所有的管道
{
channel.ClosePipe();
}
// 2. 回收子进程
for (auto &channel : channels) // 等待子进程
{
channel.WaitProcess();
}
}关闭管道和等待子进程定义在 Channel 类中。
// 关闭管道
void ClosePipe()
{
std::cout << "关闭文件描述符:" << _wfd << std::endl;
close(_wfd);
}
// 等待子进程
void WaitProcess()
{
pid_t rid = waitpid(_child_pid, nullptr, 0);
(void)rid;
}将 RunProcessPool 函数的处的循环条件改成非死循环,测试父进程退出后,是否正常是否和回收所有资源:
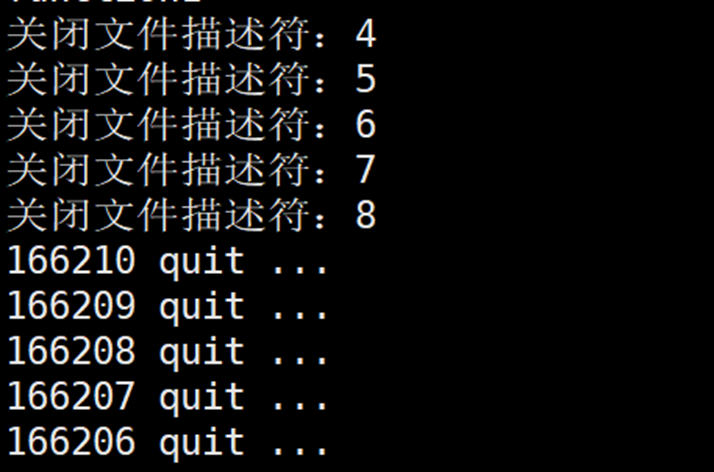
有人可能会有疑问:如果父进程要求子进程退出,管道中仍然存在任务还未处理,该怎么办?没有任何影响,如果管道写端被关闭,子进程读取到管道的结尾才会退出,即子进程必须将对应管道中的任务全部执行完毕才能退出。
version2
思考:为什么父进程是先全部退出所有子进程,再逐个进行回收的呢?为什么不能退出一个子进程就回收一个?
// bug演示:
for (auto &channel : channels)
{
channel.ClosePipe(); // 1. 退出所有的子进程
channel.WaitProcess(); // 2. 回收子进程
}如果这样实现释放和回收资源功能,会出现什么问题?运行结果:
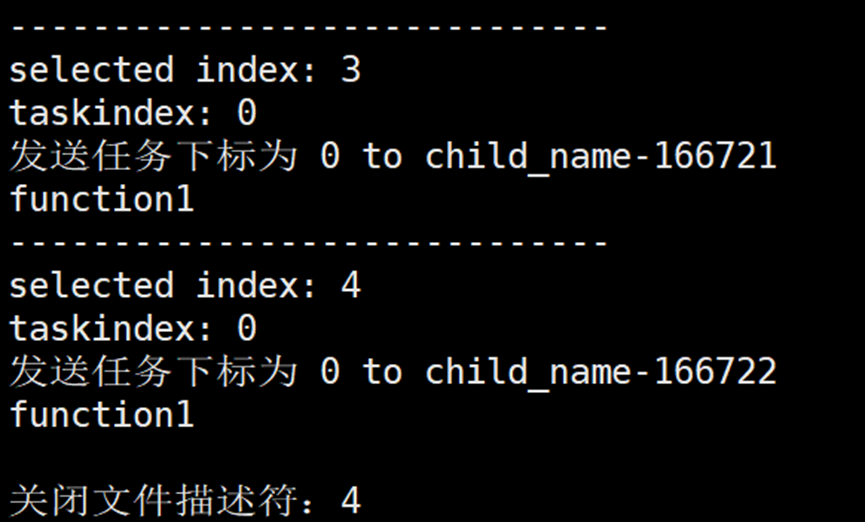
运行之后我们可以看到,父进程被卡住了,子进程没有退出。
为什么退出进程池的功能代码不能实现成上述那样?应该怎么修改?要想知道怎么修改,需要知道问题发生的根本。
分析:
父进程打开一个管道,fork 创建子进程,子进程拷贝父进程的文件描述符表,父进程要写,子进程要读,所以父进程关闭了读文件描述符,即3;子进程关闭了写文件描述符,即4。
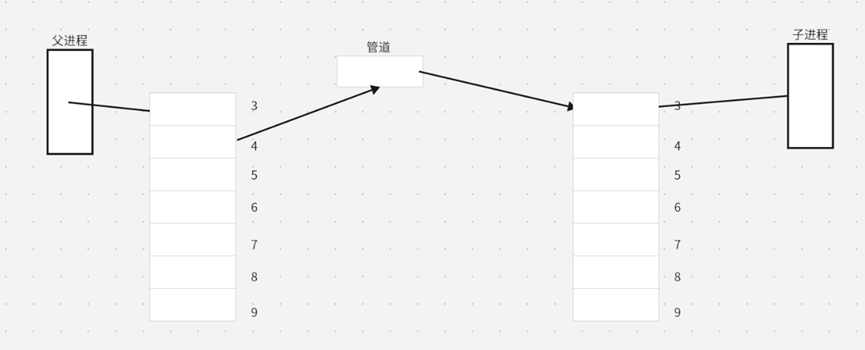
但是我们不仅仅创建了一个进程,父进程还会继续打开管道,那么会为其分配最小的未被使用的文件描述符,也就是3号和5号;紧接着继续 fork 创建子进程,子进程拷贝父进程的文件描述符表。接着为了实现单向通信的信道,各自关闭了读写端:
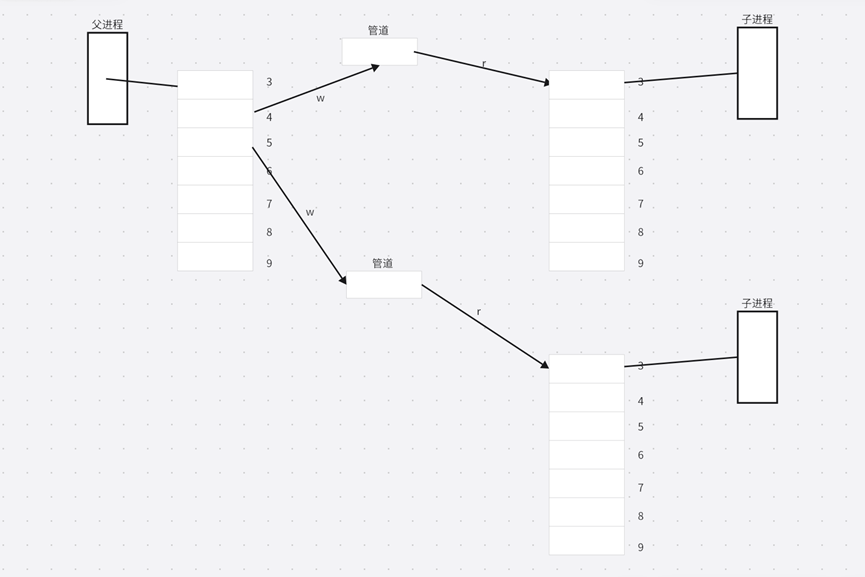
然而子进程拷贝父进程的文件描述符表,不仅会拷贝父进程的读写段文件描述符3和5,还会拷贝父进程之前4号文件描述符内的内容。
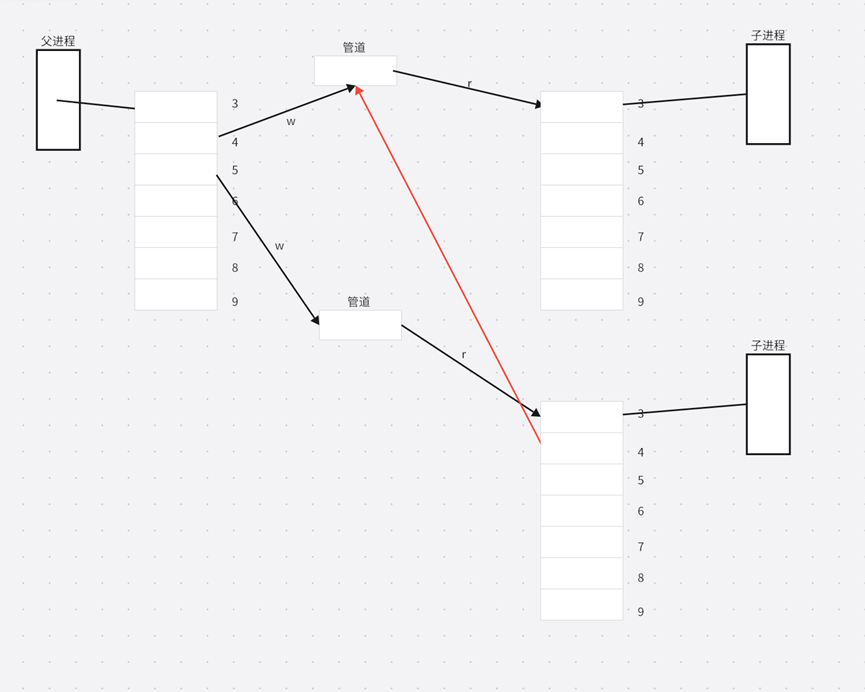
因此第二次创建的子进程的文件描述符表中的4号文件描述符还会指向第一次创建的管道的写端。
接着再创建一个管道,fork 创建子进程。
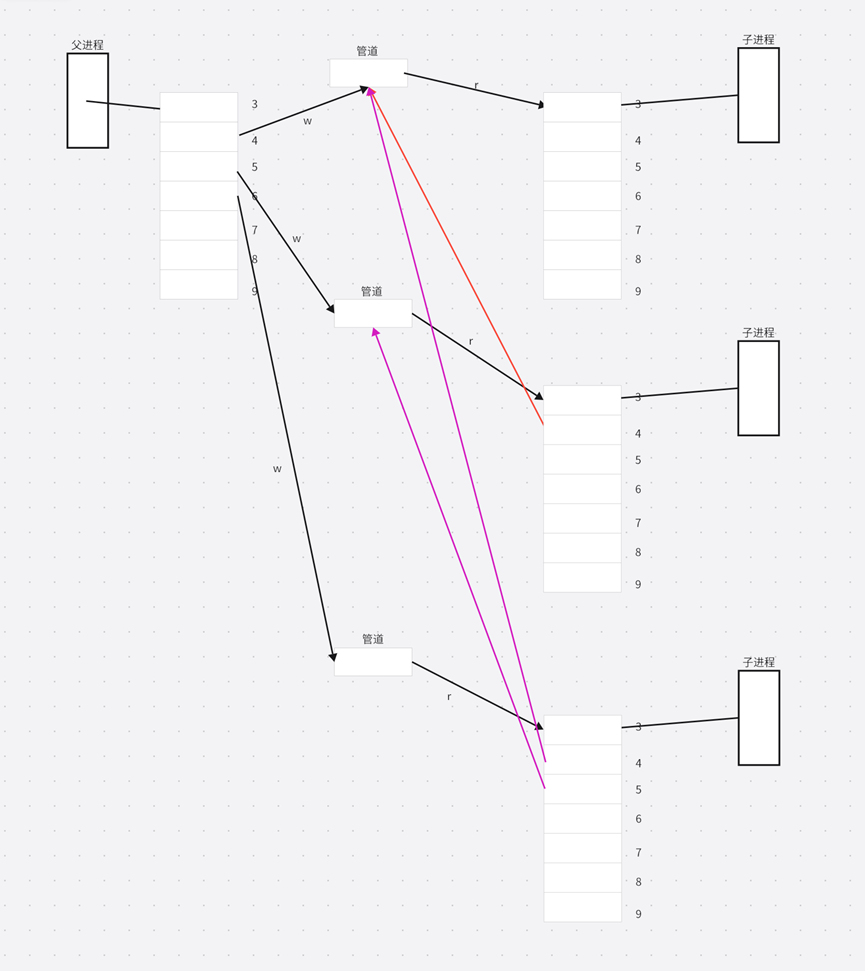
随着创建的子进程越来越多,后续进程的文件描述符会指向之前打开的管道。
回到问题本身,先关闭一个管道,接着就回收。从头开始关闭,只有父进程将自己的写端关闭了,接着就开始回收子进程,但是其它的兄弟进程仍然指向管道的写端,并不会出现写端关闭这种情况,因为管道的写端并没有关完全。问题出现的原因分析出来了:写端文件描述符没有关闭完全。
父进程创建了5个子进程,那么从开始到结束,每个子进程的文件描述符情况分别是:{3},{3,4},{3,4,5},{3,4,5,6},{3,4,5,6,7};父进程的文件描述符为:{4,5,6,7,8}。
下面来看父进程的文件描述符是否和我们分析的那样:
子进程的文件描述符是否和我们分析的那样。可以使用指令:ls /proc/进程的pid/fd 查看进程的文件描述符。
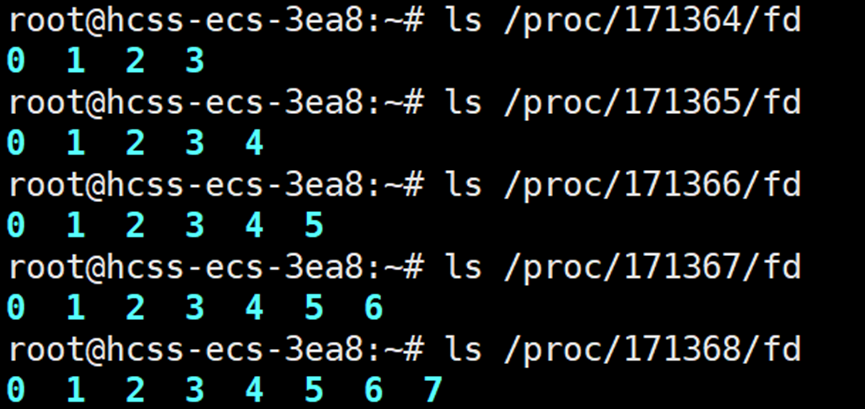
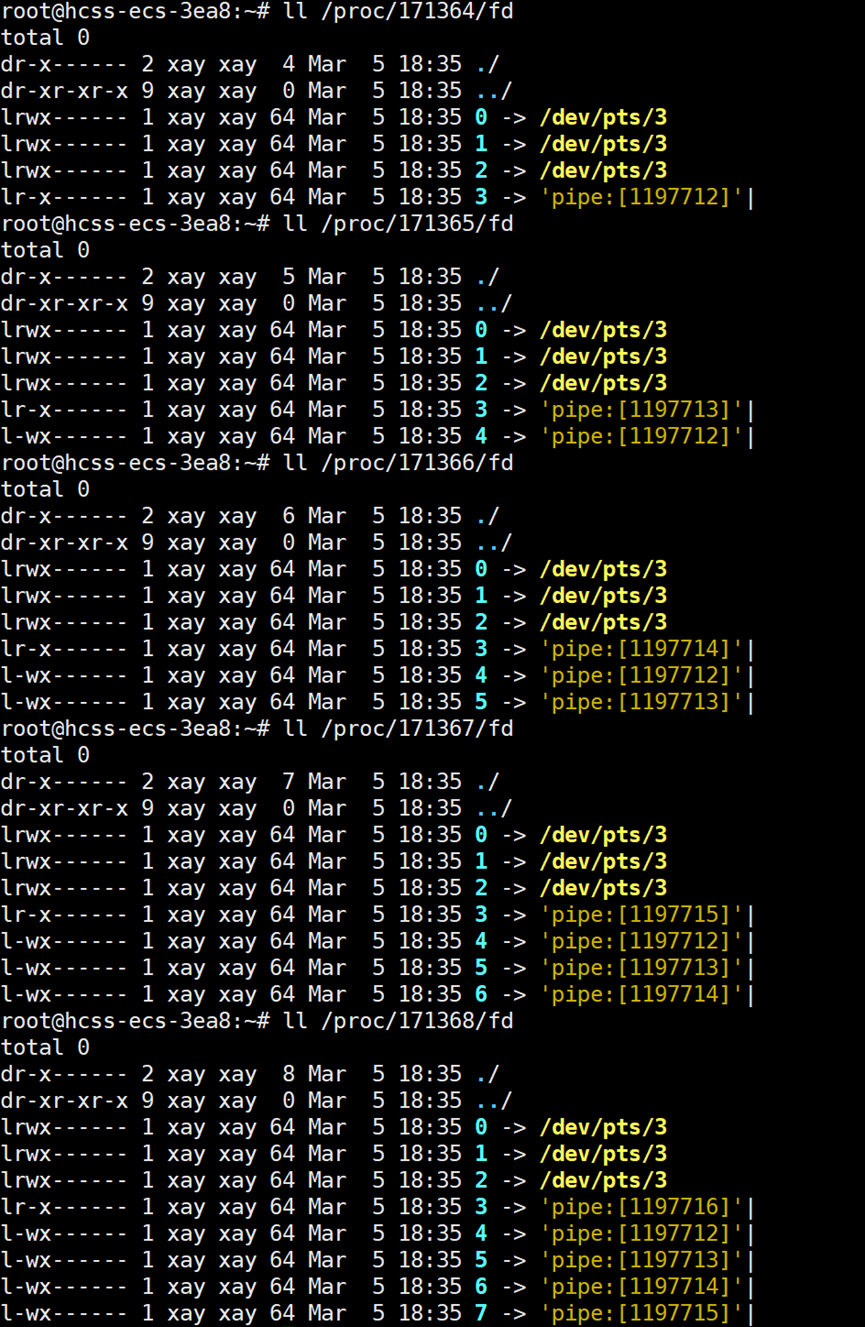
知道问题产生的原因后,解决方案为:逆向回收。
// version2: 逆向回收
int end = channels.size() - 1;
while (end >= 0)
{
channels[end].ClosePipe();
channels[end].WaitProcess();
end--;
}结果演示:
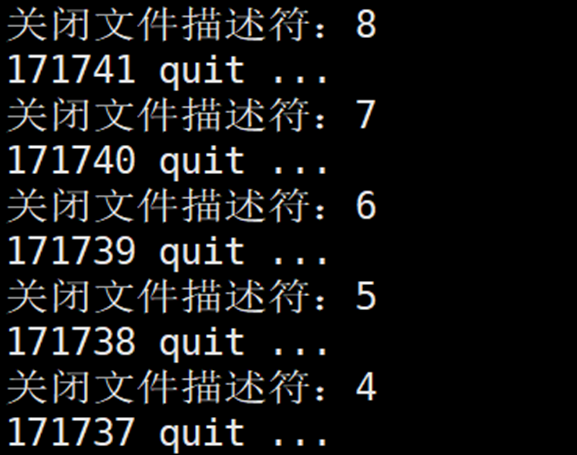
version3
如果就要正着回收,实现真正的1:1的读写端,应该怎么办?
我们需要知道第一次 for 循环时,历史上打开的文件描述符在哪?第一次创建子进程时,子进程没有写端;在创建第二子进程后,只需要关闭父进程历史上打开的写端,那么子进程拷贝父进程的文件描述符表就不会产生上述问题了。历史上打开的文件描述符在哪?—— 在 channels 对象中。
else if (id == 0) // 子进程
{
// version3:
// 关闭父进程的历史上的写文件描述符
if (!channels.empty()) // channels不为空,需要操作
{
for (auto &channel : channels)
{
channel.ClosePipe();
}
}
close(pipefd[1]); // 子进程读,关闭写端
// Task(pipefd[0]); // 从管道中读取任务
cb(pipefd[0]); // 从管道中读取任务
exit(NO_PROBLEM);
}有人可能会担心:子进程关闭父进程打开的写文件描述符会不会影响父进程?完全不会,这里只是子进程关闭,子进程影响的是自己的文件描述符表。
结果演示:
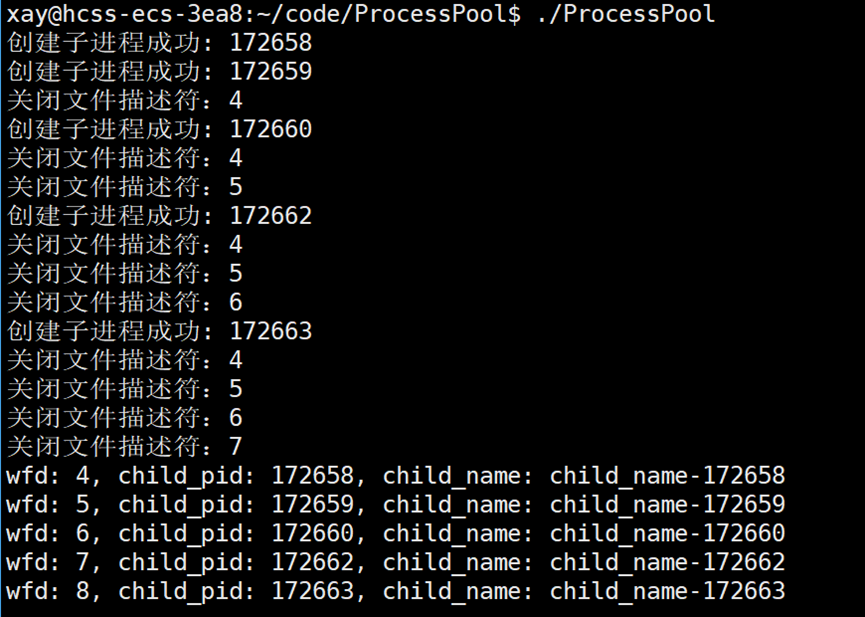
全代码展示
简单的进程池就实现完毕了,下面是完整的代码:
#include <iostream>
#include <string>
#include <unistd.h>
#include <vector>
#include <cstdio>
#include <functional>
#include <sys/wait.h>
//////////////////////////////// 子进程要完成的任务 ///////////////////////////////////////////
void function1()
{
std::cout << "function1" << std::endl;
sleep(1);
}
void function2()
{
std::cout << "function2" << std::endl;
sleep(1);
}
void function3()
{
std::cout << "function3" << std::endl;
sleep(1);
}
void function4()
{
std::cout << "function4" << std::endl;
sleep(1);
}
void function5()
{
std::cout << "function5" << std::endl;
sleep(1);
}
typedef void (*task_t)(); // 使用函数指针
// 将上述的5个任务保存在任务数组中(全局变量)
std::vector<task_t> tasks = {function1, function2, function3, function4, function5};
////////////////////////////////////// 进程池 ////////////////////////////////////////////////
// 定义常量列表
enum
{
NO_PROBLEM = 0, // 没有问题
PIPE_CREATE_ERROR, // 管道创建失败
FORK_CREATE_ERROR // 子进程创建失败
};
const int processNum = 5; // 定义创建子进程的数量
// 类型的重命名 —— 将 function<void (int)> 类型重命名为 task_t
// typedef std::function<void (int)> task_t;
// using task_t = std::function<void(int)>;
using cb_t = std::function<void(int)>;
// 子进程的入口函数
void Task(int fd)
{
while (true)
{
int task_code = 0; // 获取到的任务码
// 从指定的管道读端读取数据
ssize_t n = read(fd, &task_code, sizeof(task_code));
// 返回值的大小等于任务码的大小,即读取到的数据的长度等于任务码的长度就可以说明获取到了任务码
if (n == sizeof(task_code))
{
if (task_code >= 0 && task_code <= tasks.size()) // 检测任务码是否安全
{
// 根据任务码选择对应的任务,并执行任务表中的任务
tasks[task_code]();
}
}
// 子进程读到0,即读到了管道的结尾,即父进程关闭了管道的写端,子进程需要退出了
else if (n == 0)
{
std::cout << getpid() << " quit ..." << std::endl; // 显示哪个子进程退出了
break;
}
else
{
perror("read"); // 读取错误
break;
}
}
}
// 创建进程池类
class ProcessPool
{
private:
// 定义管道类
class Channel
{
public:
Channel(int wfd, pid_t pid) // 构造函数
: _wfd(wfd), _child_pid(pid)
{
// 自定义实现子进程的名字,to_string 函数将整型转化成字符串
_child_name = "child_name-" + std::to_string(_child_pid);
}
~Channel() {} // 析构函数
void PrintInfo()
{
printf("wfd: %d, child_pid: %d, child_name: %s\n", _wfd, _child_pid, _child_name.c_str());
}
void WriteTask(int task)
{
ssize_t n = write(_wfd, &task, sizeof(task)); // 这就是约定的4字节发送
(void)n;
}
// 获取 Channel 名字
std::string GetName() { return _child_name; }
// 关闭管道
void ClosePipe()
{
std::cout << "关闭文件描述符:" << _wfd << std::endl;
close(_wfd);
}
// 等待子进程
void WaitProcess()
{
pid_t rid = waitpid(_child_pid, nullptr, 0);
(void)rid;
}
private:
// 成员属性
int _wfd; // 写文件描述符
pid_t _child_pid; // 对应的子进程的pid
std::string _child_name; // 管道的名称
};
public:
ProcessPool() {} // 构造函数
~ProcessPool() {} // 析构函数
// // 初始化进程池
// void InitProcessPool(task_t task)
// {
// CreatProcessAndChannel(task);
// }
// 初始化进程池
void InitProcessPool(cb_t cb)
{
CreatProcessAndChannel(cb);
}
// 打印子进程的信息
void PrintProcess()
{
for (auto &ch : channels)
{
ch.PrintInfo();
}
}
// 进程池运行
void RunProcessPool()
{
int cnt = 10;
while (cnt--)
// while(1)
{
std::cout << "-----------------------------" << std::endl;
// 1. 选择一个 channel(管道+子进程),本质上是在 vector 中选择一个下标数字
int whoindex = SelectChannel();
// 测试是否是轮询式的选择子进程
std::cout << "selected index: " << whoindex << std::endl;
// sleep(1);
// 2. 随机选择一个任务
int task = SelectTask();
// 测试是否选择到了一个任务
std::cout << "taskindex: " << task << std::endl;
// sleep(1);
// 3. 发送一个任务给指定的 channel(管道+子进程)
SendTasktoSalver(task, whoindex);
// 测试
printf("发送任务下标为 %d to %s\n", task, channels[whoindex].GetName().c_str());
sleep(1);
}
}
int SelectChannel() // 选择一个进程
{
// 使用轮询的方法选择子进程
static int index = 0; // 默认初始时选择下标为0的子进程
int select = index;
index++; // 轮询选择
index %= channels.size(); // 避免下标越界
return select;
}
int SelectTask() // 选择一个任务
{
srand((unsigned int)time(NULL)); // 定义随机数种子
int taskindex = rand() % tasks.size(); // 在任务列表中随机选择任务下标
return taskindex;
}
void SendTasktoSalver(int task, int whoindex)
{
// 如何将任务发送给进程?
// 管道都是由channels管理的,将对应的任务码task写给给指定的进程(whoindex)即可
// WriteTask 函数实现在 Channel 类内部
channels[whoindex].WriteTask(task);
}
// 进程池退出
void QuitProcessPool()
{
// 只需要父进程关闭管道的写端,子进程读取管道的结尾时,会自动退出
// 退出后子进程会进入僵尸状态,需要父进程回收子进程
// // version1:
// // 1. 退出所有的子进程
// for(auto& channel : channels) // 关闭所有的管道
// {
// channel.ClosePipe();
// }
// // 2. 回收子进程
// for(auto& channel : channels) // 等待子进程
// {
// channel.WaitProcess();
// }
// bug演示:
// for(auto& channel : channels)
// {
// channel.ClosePipe(); // 1. 退出所有的子进程
// channel.WaitProcess(); // 2. 回收子进程
// }
// version2: 逆向回收
// int end = channels.size() - 1;
// while(end >= 0)
// {
// channels[end].ClosePipe();
// channels[end].WaitProcess();
// end--;
// }
// version3: 子进程关闭父进程的历史写文件描述符
for (auto &channel : channels)
{
channel.ClosePipe(); // 1. 退出所有的子进程
channel.WaitProcess(); // 2. 回收子进程
}
}
private:
// 1. 创建多个进程和管道
void CreatProcessAndChannel(cb_t cb)
{
for (int i = 0; i < processNum; i++)
{
// 1. 创建多个管道
int pipefd[2] = {0}; // 文件描述符数组
int n = pipe(pipefd); // 创建管道
if (n < 0) // 创建管道失败
{
std::cerr << "pipe create error" << std::endl; // 使用C++中打印错误的方式
exit(PIPE_CREATE_ERROR);
}
// 创建管道成功,创建子进程
pid_t id = fork();
if (id < 0) // 创建子进程失败
{
std::cerr << "chile process create error" << std::endl; // 使用C++中打印错误的方式
exit(FORK_CREATE_ERROR);
}
else if (id == 0) // 子进程
{
// version3:
// 关闭父进程的历史上的写文件描述符
if (!channels.empty()) // channels不为空,需要操作
{
for (auto &channel : channels)
{
channel.ClosePipe();
}
}
close(pipefd[1]); // 子进程读,关闭写端
// Task(pipefd[0]); // 从管道中读取任务
cb(pipefd[0]); // 从管道中读取任务
exit(NO_PROBLEM);
}
else
{
// 父进程执行的任务
// 子进程不会执行后续的代码,在执行完自己的任务后就退出了,执行循环任务的只有父进程
close(pipefd[0]); // 父进程写,关闭读端
// // 保存管道的写端,将管道写文件描述符和子进程的 pid 传给 channel 类对象
// Channel ch(pipefd[1], id);
// // 保存到组织 Channel 类的容器中
// channels.push_back(ch);
channels.emplace_back(pipefd[1], id);
// 测试
std::cout << "创建子进程成功: " << id << std::endl;
sleep(2);
}
}
}
private:
// 组织所有的 Channel
std::vector<Channel> channels; // 成员变量
};
int main()
{
// // 组织所有的 Channel
// std::vector<Channel> channels;
ProcessPool pp; // 创建进程池对象
// pp.InitProcessPool(); // 初始化进程池
pp.InitProcessPool(Task); // 初始化进程池
pp.PrintProcess();
// 2. 父进程控制子进程
// pp.PrintProcess();
pp.RunProcessPool(); // 运行进程池
std::cout << std::endl;
// 3. 释放和回收管道和子进程
pp.QuitProcessPool();
return 0;
}
// // 1. 创建多个管道
// int pipefd[2] = {0}; // 文件描述符数组
// int n = pipe(pipefd); // 创建管道
// if (n < 0) // 创建管道失败
// {
// std::cerr << "pipe create error" << std::endl; // 使用C++中打印错误的方式
// return PIPE_CREATE_ERROR;
// }
// // 创建管道成功,创建子进程
// pid_t id = fork();
// if (id < 0) // 创建子进程失败
// {
// std::cerr << "chile process create error" << std::endl; // 使用C++中打印错误的方式
// return FORK_CREATE_ERROR;
// }
// else if (id == 0) // 子进程
// {
// close(pipefd[1]); // 子进程读,关闭写端
// Task();
// return NO_PROBLEM;
// }
// else // 父进程
// {
// }
// // 父进程执行的任务
// close(pipefd[0]); // 父进程写,关闭读端gitbub 代码链接:Linux/ProcessPool at master · sincot/Linux

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)