让 AI 读懂了我的私有文档——这是怎么做到的
有个同事,每次问 AI 技术问题都要先贴一大段背景,然后 AI Agent给他一个看起来很有道理但完全不符合我们系统的回答,然后他气得把 AI Agent关掉,去翻文档。
这个场景大概每天在全球发生几百万次。
问题不是 Claude 不够聪明。问题是它根本不知道你的项目是什么、你的文档写了什么、你们团队上周刚改了哪个架构决策。它活在自己的训练数据里,那里没有你。
解法叫做 RAG,中文全称"检索增强生成",听起来像某种健身方法,但实际上很简单:与其把整本手册塞给 AI,不如先找到最相关的几段,只把这几段送进去。精准喂食,而不是大胃王挑战赛。
我们花了几天时间,把这套东西搭起来了。
为什么不直接把文档复制粘贴给 Claude
可以。代价是:
钱。 Claude 按 token 计费。把一份 200 页 PDF 的完整内容每次都塞进 prompt,等于每次对话都在烧钱。一个月下来,你会发现自己给 Anthropic 贡献了相当数量的 API 费用,换来的是它用你自己的文档回答你的问题。
质量。 模型对超长上下文里中间段落的注意力会下降。你把 50,000 字塞进去,它可能"没看见"第 23 页那个关键段落。这不是 Claude 偷懒,是注意力机制的物理限制。
隐私。 公司内部架构图、客户合同、还没发布的产品文档——这些东西有些不适合每次都往外发。本地知识库,数据不出你的机器。
RAG 的思路是:先在本地用向量检索找到最相关的 5 段,只把这 5 段给 Claude,让它基于这 5 段回答。Claude 看到的是精华,你花的是精华的钱。
我们搭的这套系统
说几个关键数字:
-
月成本:$2–5(Embedding 在本地跑,完全免费;只有最后 Claude 生成回答那一步花钱)
-
知识库按领域隔离,流媒体、AI、通用……各放各的,互不干扰
-
支持 PDF、Word、Markdown、代码文件、网页 URL,什么格式都吃
-
定时自动抓取,你配置一个 URL,系统每 6 小时自动更新,你的知识库不会停在你导入它那天
跟用 OpenAI Embeddings + Pinecone + GPT-4 的方案比,同等使用量大概省 90%。主要省在 Embedding 这一步——我们用的是本地模型 all-MiniLM-L6-v2,跑在你自己机器上,零成本。
文档进库的流程:
你的文档(PDF / Word / Markdown / 代码 / 网页) ↓ 解析内容,按语义切块(Python 代码额外按函数和类切分) ↓ SHA-256 hash 去重(同一份文档传两次不会重复处理) ↓ 本地 Embedding,存入 ChromaDB ↓ 以后随时可查,永久有效
怎么用它和 AI 配合
最简单:直接问
系统跑起来之后,一行 curl 就能查:
curl -X POST http://localhost:8000/api/query/sync \
-H "Content-Type: application/json" \
-d '{"question": "播放器字幕实现的核心架构是什么?", "collection": "streaming"}'
返回的答案里,每条都标注了来源文件和页码。AI 说了什么、从哪来的,一目了然,不用担心它在瞎编。
进阶:让 Claude 自己决定什么时候查知识库
用 Claude 的工具调用(Tool Use),把知识库注册成一个工具,Claude 在对话过程中自己判断何时需要查内部文档:
import anthropic
import httpx
client = anthropic.Anthropic()
tools = [{
"name": "query_knowledge_base",
"description": "查询内部知识库,获取私有文档、技术规范、架构设计等信息",
"input_schema": {
"type": "object",
"properties": {
"question": {"type": "string"},
"collection": {
"type": "string",
"enum": ["streaming", "ai-knowledge", "default"]
}
},
"required": ["question", "collection"]
}
}]
def query_knowledge_base(question: str, collection: str) -> str:
resp = httpx.post(
"http://localhost:8000/api/query/sync",
json={"question": question, "collection": collection},
timeout=30
)
data = resp.json()
sources = "\n".join(
f"- {s['filename']} 第{s['page']}页(相关度 {s['score']:.0%})"
for s in data.get("sources", [])
)
return f"{data['answer']}\n\n来源:\n{sources}"
def run_agent(user_question: str):
messages = [{"role": "user", "content": user_question}]
while True:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
tools=tools,
messages=messages,
)
if response.stop_reason == "end_turn":
return next(b.text for b in response.content if hasattr(b, "text"))
# 处理工具调用
tool_results = []
for block in response.content:
if block.type == "tool_use" and block.name == "query_knowledge_base":
result = query_knowledge_base(**block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result
})
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
# Claude 会自己去查知识库,然后基于内部文档回答
print(run_agent("我们的字幕方案用的是哪种 ASR 引擎?有什么优缺点?"))这个模式下,Claude 不是每次都查,而是在判断"这个问题我需要内部文档才能准确回答"时才调用。它自己做这个决定,你不用手动管。
再进阶:配合 Claude Code 做代码审查
如果你在用 Claude Code 写代码,可以在 CLAUDE.md 里配置:
## 知识库工具
当你需要了解项目技术细节时,调用:
POST http://localhost:8000/api/query/sync
{"question": "你的问题", "collection": "streaming"}
例如:
- 了解播放器架构前先查 streaming 库
- 了解 AI 相关技术前先查 ai-knowledge 库
这样 Claude Code 在帮你写代码、做 review 的时候,会自动参照你团队的内部文档,而不是用它自己对"行业惯例"的理解来猜你的意图。
定时追踪竞品和技术动态
把你关注的文档站点加进监控列表:
# 配置监控,每 24 小时自动抓取更新
curl -X POST http://localhost:8000/api/scheduler/urls \
-H "Content-Type: application/json" \
-d '{
"url": "https://ffmpeg.org/ffmpeg-filters.html",
"collection": "streaming",
"interval_hours": 24
}'
系统会自动 hash 去重,只处理有变化的内容。你的知识库会跟着更新,而不是永远停在你导入它那天。
想自己跑起来?
项目完全开源,本地部署,五步搞定:
# 1. 克隆项目 git clone <repo-url> cd rag-knowledge-base # 2. 安装依赖 python -m venv .venv && .venv\Scripts\activate # Windows # source .venv/bin/activate # Mac/Linux pip install -r requirements.txt playwright install chromium # 3. 配置 API Key(只需要一个 Anthropic Key) cp .env.example .env # 编辑 .env,填入 ANTHROPIC_API_KEY=sk-ant-xxx # 4. 启动 start.bat # Windows # bash start.sh # Mac/Linux # 5. 打开浏览器 # 前端:http://localhost:8501 # API 文档:http://localhost:8000/docs
上传第一份文档、问第一个问题,大概需要 3 分钟。
几个真实体验
上传了四份流媒体相关的 Markdown 文档后,问了一个问题:
"播放器字幕实现的核心架构是什么?"
回答:
采用生产者-消费者 Channel 队列:视频文件 → FFmpeg 音频提取 → PCM 重采样(16000Hz 单声道)→ ASR 识别服务 → SubtitlesManager 管理 → 显示字幕。支持 Whisper.cpp 和 Faster-Whisper 两种方案……
来源:播放器实时字幕实现.md 第1页(相关度 84%)
这份 Markdown,Claude 训练数据里肯定没有。它能回答,是因为文档在知识库里,检索到了,送进去了。
比直接问 Claude"字幕方案怎么做"得到的通用回答,质量差了不止一个数量级。
用了才知道的边界
知识库不是搜索引擎。 它靠语义相似度检索,不靠关键词精确匹配。问"字幕"能找到相关内容,但问一个文档里从没出现过的概念,它不会神奇地生成答案,会明确告诉你"知识库中未找到相关内容"。这比瞎编要好。
中文文档建议换模型。 默认的 all-MiniLM-L6-v2 是英文优先的。中文文档的话,在 .env 里换成 EMBED_MODEL=BAAI/bge-small-zh-v1.5,同样免费,对中文检索质量明显更好。
分块大小影响答案细节。 默认 512 字符/块。密集的技术规范可以调小(256),叙述性文档可以调大(800)。调整 .env 里的 CHUNK_SIZE 即可,不需要改代码。
让 AI 读懂你的私有文档,不是一件需要很多资源的事。这套系统证明了:本地部署、月花 $3、十分钟上手,已经够用了。
你的文档在那里,AI 的能力也在那里。差的只是一个连接。
项目地址:rag-knowledge-base/ 前端界面:http://localhost:8501 API 文档:http://localhost:8000/docs
我自己的本地知识库截图:
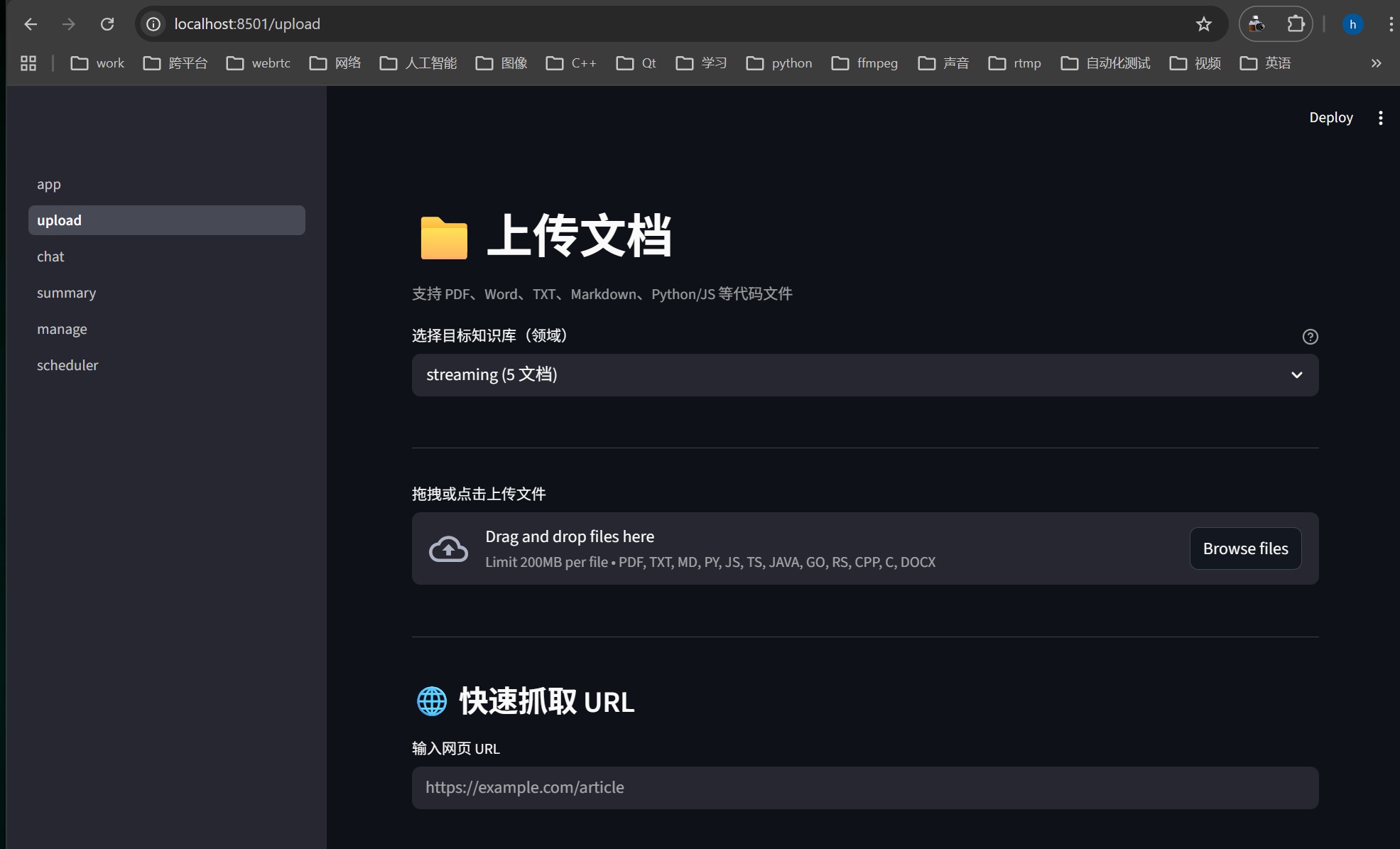
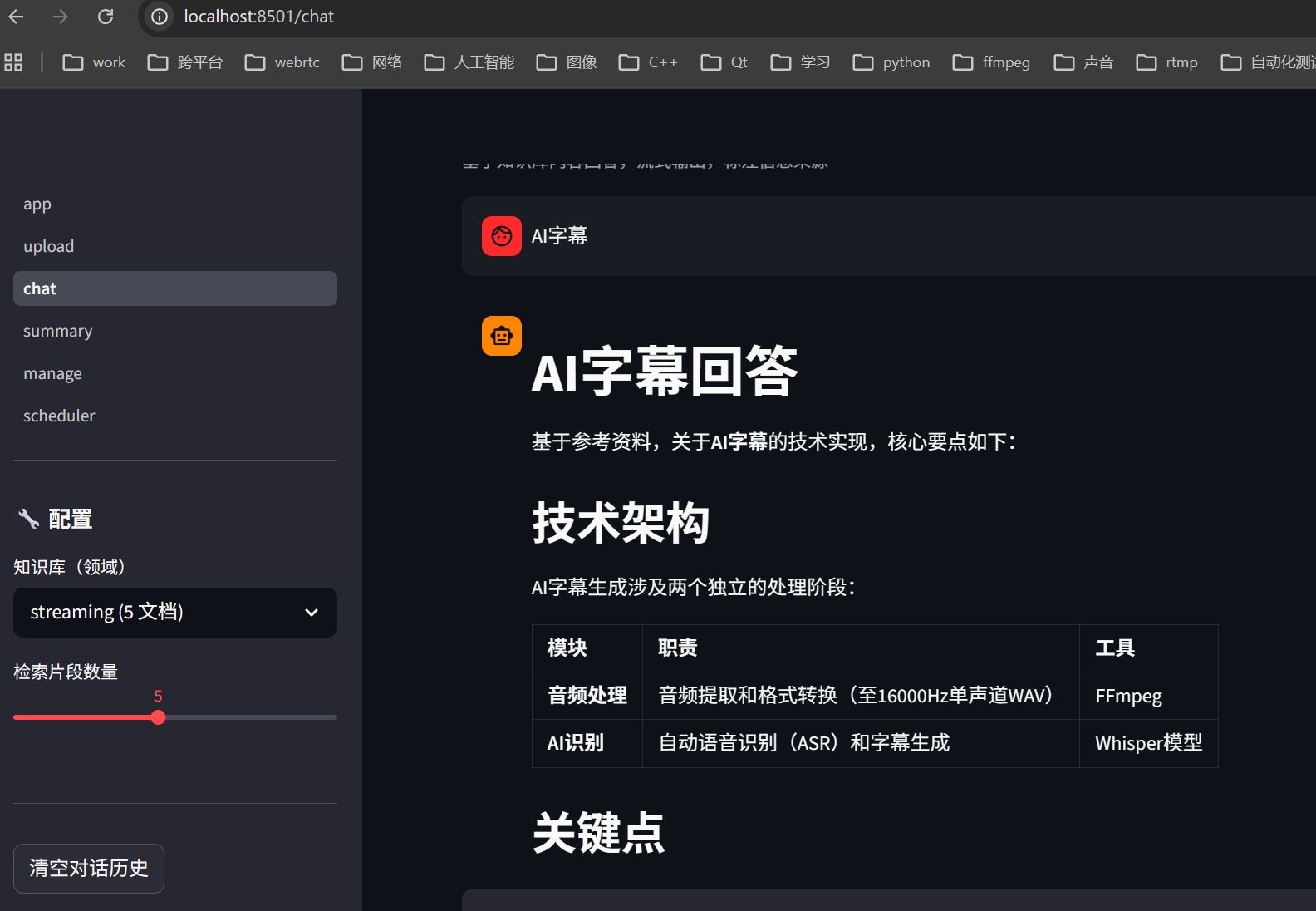
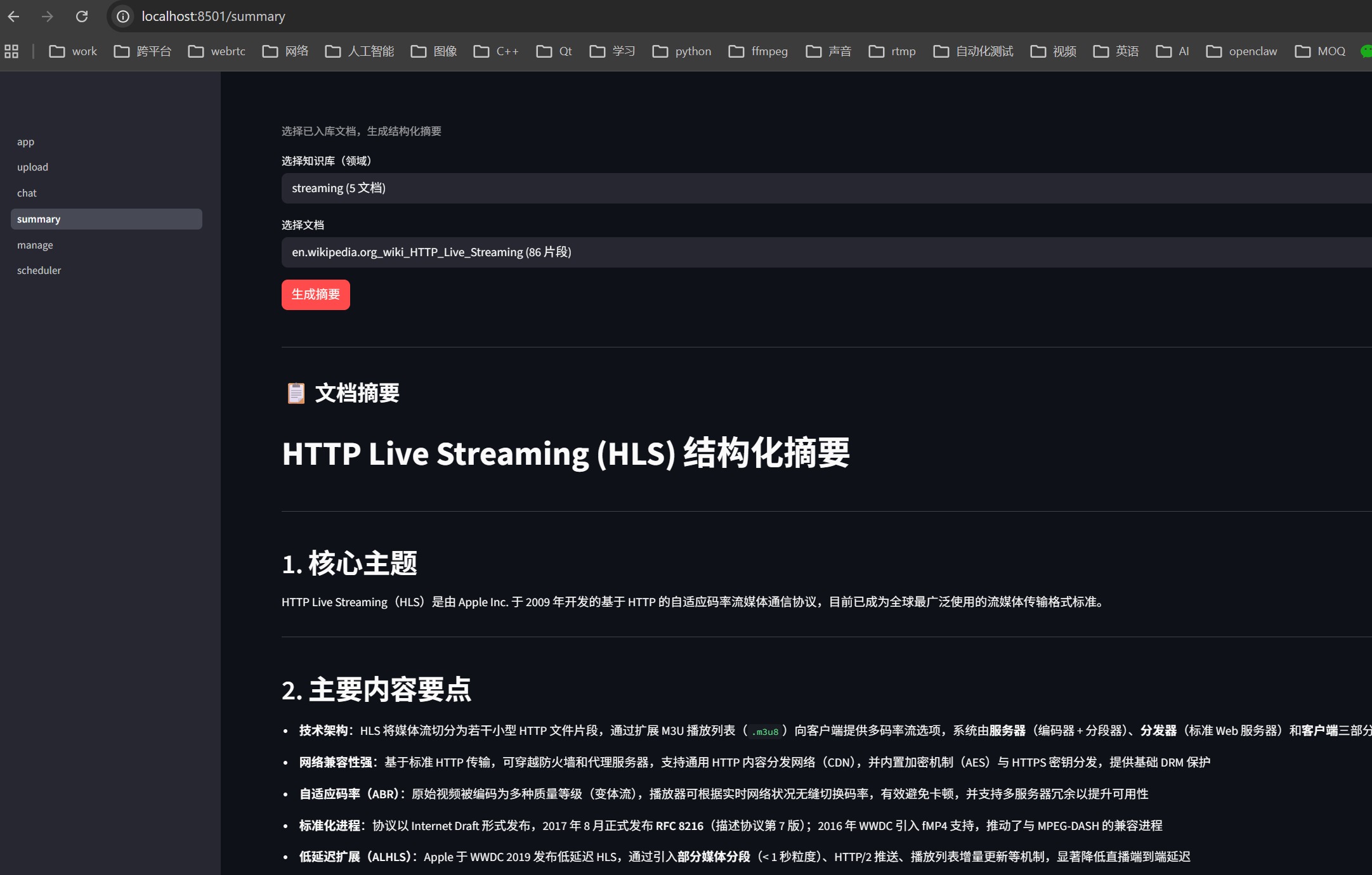

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)