从Transformer到基础模型:时空预测技术全景解读
本文基于ACM Computing Surveys 2025年发表的综述论文《A Survey on Spatio-Temporal Prediction: From Transformers to Foundation Models》,系统梳理时空预测领域的最新进展。
什么是时空预测?为什么它如此重要?
想象一下:
- • 早高峰时,导航软件精准预测15分钟后的路况
- • 气象台提前一周预警台风路径
- • 自动驾驶汽车预判行人的下一步动作
这些场景背后,都离不开时空预测(Spatio-Temporal Prediction) 技术。
时空数据是同时包含时间维度和空间维度信息的数据。随着物联网传感器的普及和智能设备的爆发式增长,我们正处于一个时空大数据时代。从交通流量、天气变化到人体运动,时空预测在众多领域扮演着关键角色。
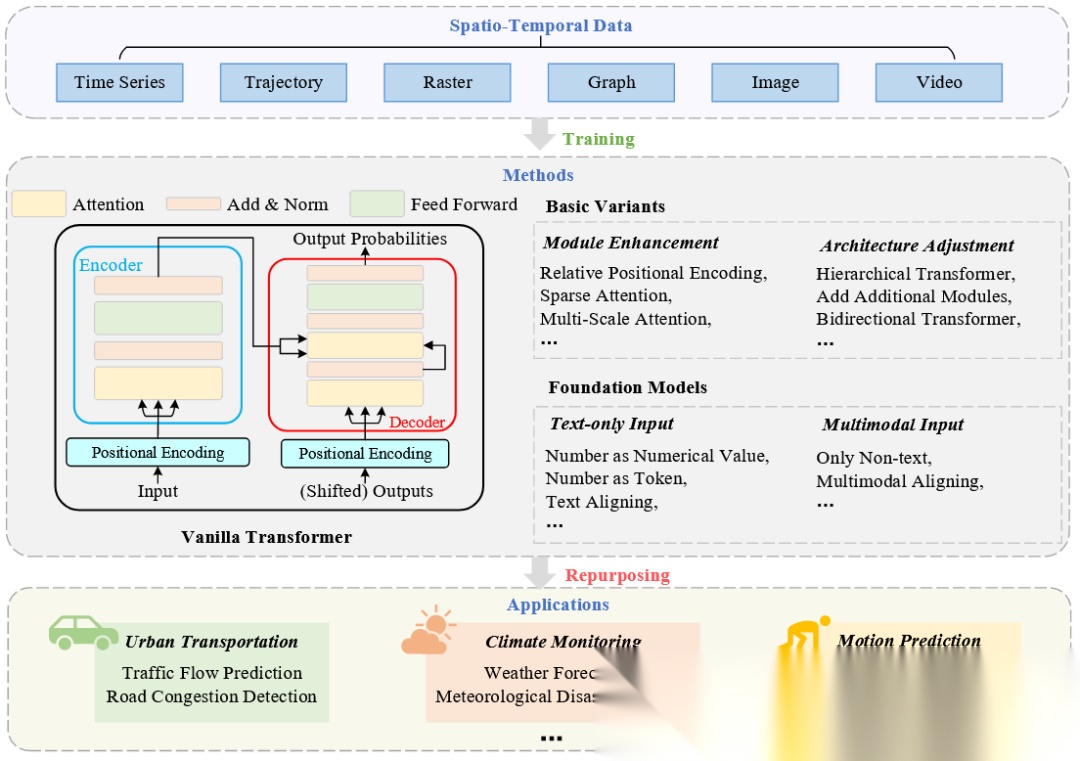
ST data classification, prediction methods, and application domains
时空数据的核心挑战
时空数据的复杂性体现在三个方面:
- 动态时间序列:数据随时间不断变化
- 空间相关性:不同位置的数据相互影响
- 复杂非线性关系:传统线性模型难以捕捉
传统统计方法(如ARIMA)和早期机器学习算法往往假设数据独立,难以有效捕捉时空关联。这正是深度学习,尤其是Transformer架构大显身手的地方。
为什么Transformer成为时空预测的"王者"?
深度学习方法演进史
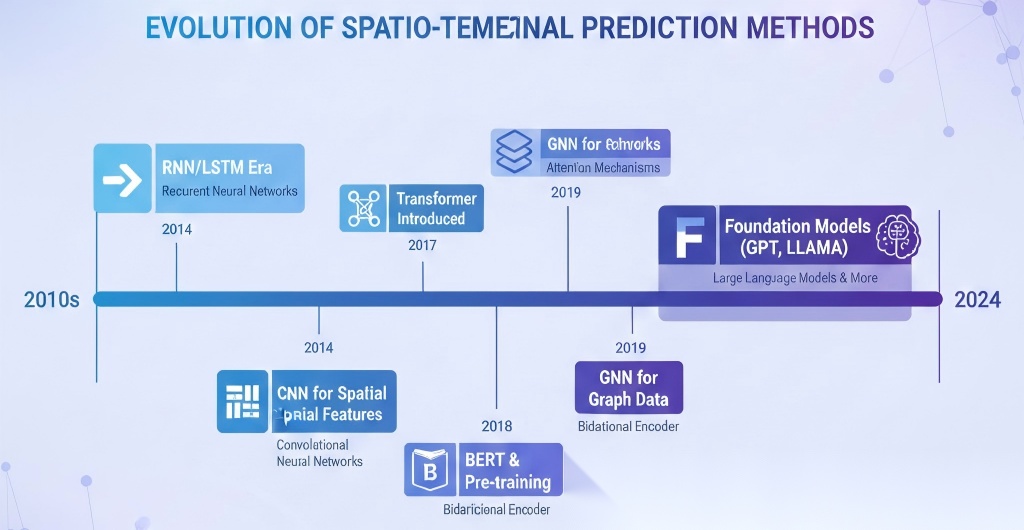
FIGURE TO DRAW: 时空预测方法演进时间线
时空预测方法经历了几个关键阶段:
| 时期 | 主流方法 | 特点 | 局限性 |
|---|---|---|---|
| 早期 | ARIMA、统计方法 | 简单、可解释 | 假设线性,无法处理复杂依赖 |
| 2010s | RNN/LSTM | 能处理时序数据 | 长序列梯度消失,难以并行 |
| 2014+ | CNN | 提取空间特征 | 局部感受野,远距离依赖差 |
| 2017+ | Transformer | 全局注意力,并行计算 | 计算复杂度高 |
| 2022+ | 基础模型 | 通用表示,迁移能力强 | 资源消耗大 |
Transformer的三大优势
- 全局依赖建模:自注意力机制可以直接连接序列中任意两个位置,不受距离限制
- 并行计算能力:不像RNN需要逐步处理,Transformer可以同时处理整个序列
- 灵活的架构设计:编码器-解码器结构可以根据任务需求灵活调整
实践提示:注意力机制的计算代价
标准自注意力的时间复杂度为 O(N²d),其中N是序列长度,d是隐藏层维度。当处理长时间序列或高分辨率空间数据时,显存消耗会急剧增加。实践中常用的解决方案包括:
- • 稀疏注意力(Sparse Attention)
- • 线性注意力(Linear Attention)
- • 滑动窗口注意力
在8GB显存的GPU上,标准注意力通常只能处理约2000-4000长度的序列。
综述的核心分类体系
这篇综述提出了一个清晰的三层分类框架,将基于Transformer的时空预测模型分为三大类:
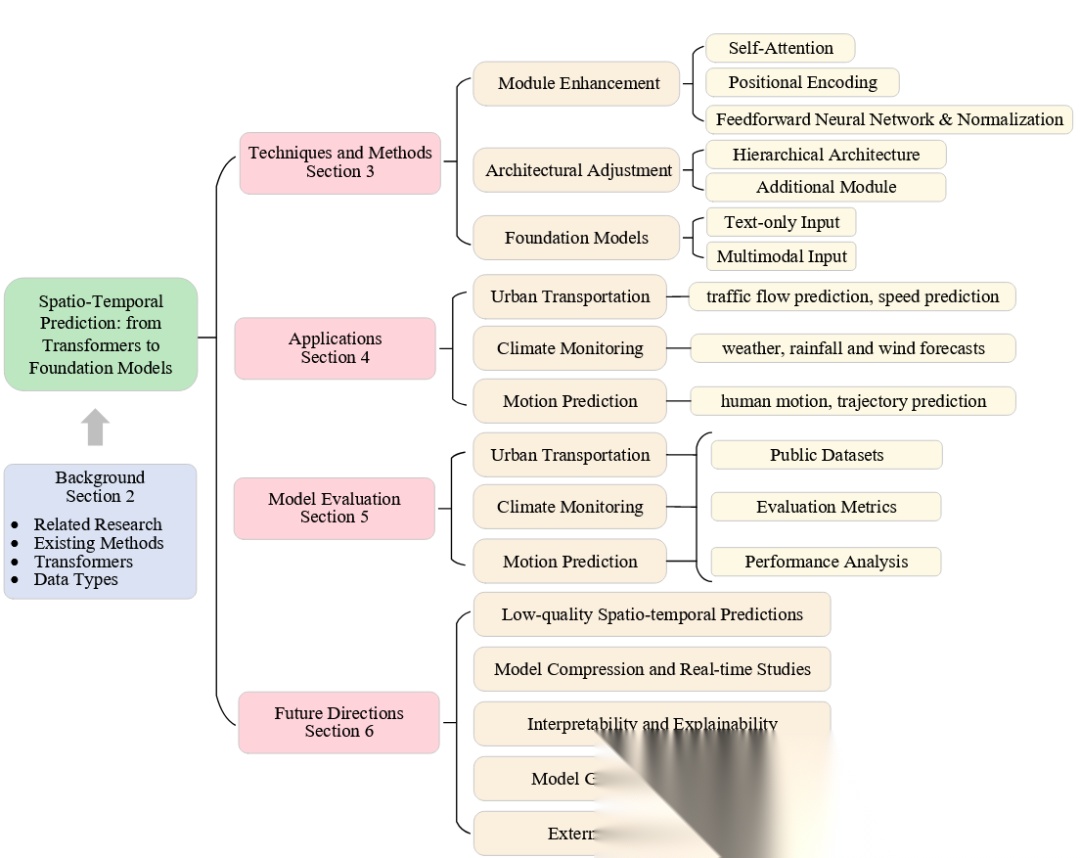
A comprehensive taxonomy of Transformers for ST prediction in background, techniques and methods, application domains, model evaluation, and future directions
第一类:模块增强(Module Enhancement)
在保持Transformer基本架构不变的前提下,对核心模块进行改进。
1. 自注意力机制改进
| 改进类型 | 核心思想 | 代表方法 |
|---|---|---|
| 稀疏注意力 | 限制注意力范围,减少计算量 | 滑动窗口、随机采样 |
| 线性注意力 | 重排计算顺序,实现线性复杂度 | 自适应注意力 |
| 多头注意力 | 多个注意力头学习不同模式 | 标准配置,可调整头数 |
2. 位置编码增强
原始Transformer使用固定的正弦位置编码,但对于时空数据,我们需要更灵活的方案:
- • 动态位置编码:可学习的位置参数,随训练更新
- • 相对位置编码:编码元素间的相对距离而非绝对位置
- • 层次位置编码:不同层级使用不同的编码策略
- • 多模态位置编码:为不同类型的输入设计专门的编码
3. 前馈网络与归一化
- • 激活函数:从ReLU到GELU、GLU
- • 归一化策略:LayerNorm → GroupNorm → InstanceNorm
- • 残差连接:可学习的残差权重
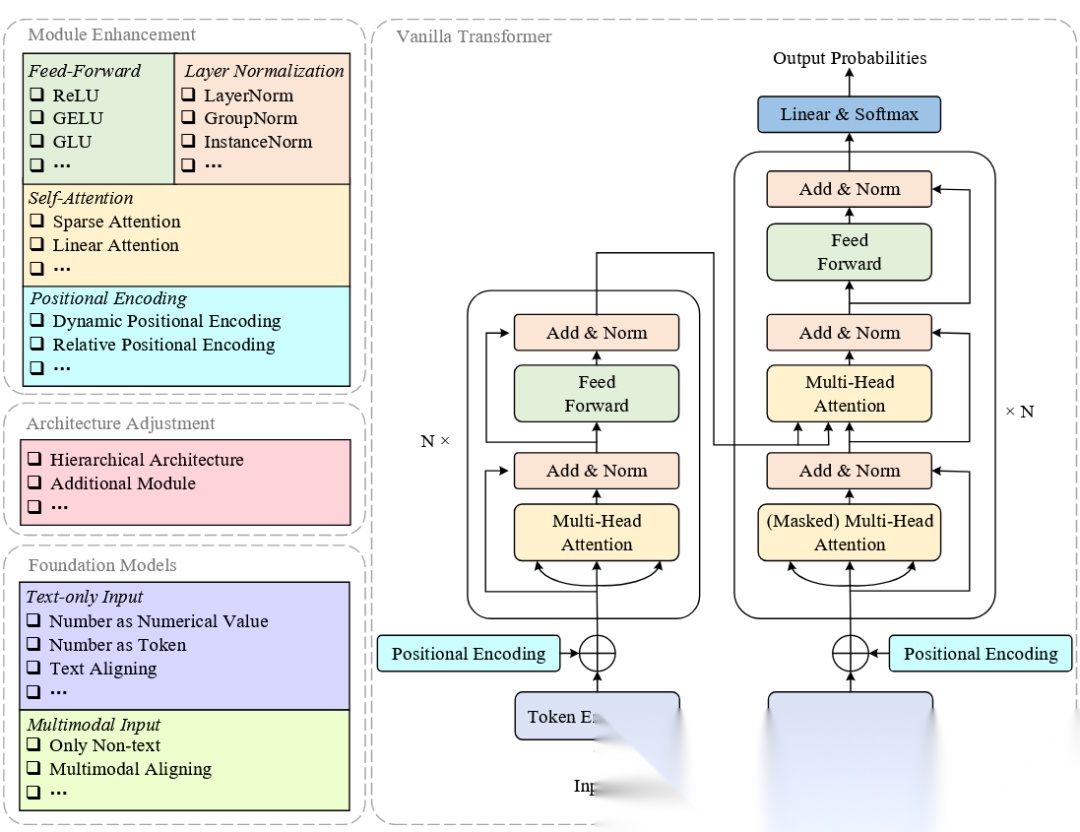
The architecture of Vanilla Transformer and its main variants
第二类:架构调整(Architecture Adjustment)
对Transformer的整体结构进行更大幅度的修改。
1. 层次化架构
将输入序列分层处理,从细粒度到粗粒度逐步聚合:
原始特征 → 初级Transformer → 聚合 → 高级Transformer → 最终输出
代表模型:
- • Informer:通过最大池化层降低时间维度
- • Deepnet:跨尺度注意力机制
2. 附加模块集成
最常见的是与图神经网络(GNN)的结合:
方案一:GNN作为独立模块
- • GNN负责空间依赖
- • Transformer负责时间依赖
- • 代表:GraphTrans
方案二:GNN与注意力深度融合
- • 在注意力计算中引入图结构信息
- • 代表:Graphformers、Crossformer
工程实践提示:如何选择架构?
- • 如果数据有明确的图结构(如交通网络、社交网络)→ 优先考虑GNN+Transformer
- • 如果数据是规则网格(如气象栅格数据)→ CNN+Transformer或纯Transformer
- • 如果序列特别长 → 层次化架构 + 稀疏注意力
- • 资源受限场景 → 优先模块增强,避免复杂架构
第三类:基础模型(Foundation Models)
基础模型通过大规模预训练获取通用表示能力,然后微调适应下游任务。
纯文本输入方式
| 策略 | 描述 | 代表模型 |
|---|---|---|
| 数值作为数值 | 直接将时序数据作为数值输入 | TimeGPT、TimesFM |
| 数值作为Token | 将数值离散化为类别标签 | TDML(金融领域) |
| 文本对齐 | 通过对比学习将时序与文本对齐 | Time-LLM、TEST |
多模态输入方式
| 策略 | 描述 | 代表模型 |
|---|---|---|
| 纯视觉 | 将时空数据转为图像 | PanGu、FengWu |
| 多模态对齐 | 文本引导多模态数据理解 | ImageBind、PandaGPT |
实践提示:基础模型的选择
- • 零样本/少样本任务:优先考虑基础模型
- • 领域数据充足:传统Transformer可能更高效
- • 实时推理要求:基础模型通常太重,考虑蒸馏或模块增强方法
- • 计算资源:FengWu等大模型需要32张A100训练17天
三大核心应用领域详解
领域一:城市交通
交通预测是时空预测最成熟的应用场景,包括:
- • 交通流量预测
- • 车速预测
- • 拥堵检测
- • 行人流量预估
代表模型对比
| 模型 | 核心特点 | 优势 | 局限 |
|---|---|---|---|
| Traffic Transformer | 多种位置编码策略 | 捕捉全局-局部时间依赖 | 未考虑空间相关性 |
| Lastjormer | 时空联合注意力 | 线性注意力,计算高效 | 可解释性差 |
| ASTGCN | 层次化注意力 | 整合短期/日/周周期依赖 | 缺乏外部信息融合 |
| CorrSTN | 空间/时间相关信息 | 考虑变量相关性 | 模型结构复杂 |
常用数据集
| 数据集 | 规模 | 时间范围 | 采样间隔 |
|---|---|---|---|
| METR-LA | 207传感器 | 2012.3-6 | 5分钟 |
| PEMS-BAY | 325检测器 | 2017.1-5 | 5分钟 |
| PeMSD4 | 307检测器 | 59天 | 5分钟 |
| LargeST | 8600传感器 | 5年 | - |
实践提示:交通预测的数据泄露陷阱
时空数据的划分需要特别注意:
- 时间泄露:训练集不能包含测试时间段之后的数据
- 空间泄露:如果使用邻接矩阵,确保测试节点的邻居信息处理正确
- 周期性:按时间顺序划分,而非随机划分
推荐划分比例:7:1:2(训练:验证:测试),按时间顺序切分
领域二:气候监测
气象预测对各行业和公共健康至关重要:
- • 天气预报
- • 降水预测
- • 风速预测
- • 空气质量预测
代表模型对比
| 模型 | 类型 | 核心创新 | 参数量 |
|---|---|---|---|
| AirFormer | 模块增强 | 引入潜在随机变量 | 246K |
| Earthformer | 架构调整 | 立方体注意力机制 | 3.61M |
| ClimaX | 基础模型 | Vision Transformer | 7.76M |
| FengWu | 基础模型 | 多模态多任务 | 4.53G |
FengWu是目前最强大的气象预测模型之一,但训练成本极高(32×A100,17天)。
常用数据集
- • ERA5:欧洲中期天气预报中心的全球大气再分析数据,覆盖1979年至今
- • CMIP6:全球气候模型对比项目数据,用于气候变化研究
领域三:运动预测
运动预测包括两个主要方向:
1. 轨迹预测
- • 行人轨迹预测
- • 车辆轨迹预测
- • 无人机路径规划
2. 人体动作预测
- • 3D人体姿态预测
- • 动作识别与预测
- • 骨骼运动预测
代表模型对比
| 模型 | 任务 | 核心特点 | 优势 |
|---|---|---|---|
| TrajFormer | 轨迹分类 | 语义位置编码 | 精确经纬度处理 |
| SGTN | 行人轨迹 | 多模态预测 | 融合多模态特征 |
| STCT | 人体运动 | 交叉Transformer | 时空特征连贯性 |
| BEVGPT | 自动驾驶 | 鸟瞰图输入 | 输入简洁直观 |
常用数据集
轨迹预测:
- • ETH/UCY:行人轨迹数据集,包含5个场景
- • Waymo:自动驾驶场景,含LiDAR和图像标注
人体运动:
- • Human3.6M:大规模3D人体姿态数据集
- • PoseTrack:视频中的人体姿态跟踪
模型评估:指标与性能分析
常用评估指标
| 指标 | 英文全称 | 适用场景 | 解释 |
|---|---|---|---|
| MAE | Mean Absolute Error | 通用 | 平均绝对误差,越小越好 |
| RMSE | Root Mean Squared Error | 通用 | 均方根误差,对大误差敏感 |
| MAPE | Mean Absolute Percentage Error | 通用 | 平均绝对百分比误差 |
| ADE | Average Displacement Error | 轨迹预测 | 所有时间步的平均欧氏距离 |
| FDE | Final Displacement Error | 轨迹预测 | 最终时间步的欧氏距离 |
| MPJPE | Mean Per Joint Position Error | 人体姿态 | 关节点平均位置误差 |
METR-LA数据集性能对比
| 模型 | 15分钟 | 30分钟 | 60分钟 |
|---|---|---|---|
| Vanilla Transformer | 2.98/6.04/8.88 | 3.65/7.03/9.64 | 4.25/7.96/12.41 |
| Traffic Transformer | 2.43/4.73/6.57 | 2.79/5.61/7.45 | 3.28/6.68/9.08 |
| Lastjormer | 2.64/5.11/6.74 | 2.99/6.01/8.13 | 3.36/7.03/9.67 |
格式:MAE/RMSE/MAPE(%)
关键发现:Traffic Transformer通过多种位置编码策略,在各时间尺度上都取得最佳性能。
实践提示:基线选择建议
- 必须包含的基线:
- • Vanilla Transformer(证明改进有效)
- • 领域内SOTA模型(如交通用ASTGCN)
- • 简单基线(如Historical Average)
- 公平对比原则:
- • 相同的数据划分
- • 相同的输入窗口和预测窗口
- • 相同的超参数搜索预算
- 避免的陷阱:
- • 只在单一数据集上报告结果
- • 选择性报告最好的预测步长
- • 忽略模型复杂度和推理速度
五大未来研究方向
方向一:低质量时空数据预测
问题:实际场景中数据常有缺失、噪声和错误,但大多数研究使用高质量公开数据集。
研究方向:
- • 缺失值感知的预测框架
- • 噪声鲁棒的注意力机制
- • 分布外(OOD)场景的泛化
方向二:模型压缩与实时性
问题:Transformer模型参数量大,难以部署到边缘设备,实时性不足。
研究方向:
- • 低秩近似 + 结构化剪枝
- • 知识蒸馏
- • 混合专家(MoE)架构(受DeepSeek启发)
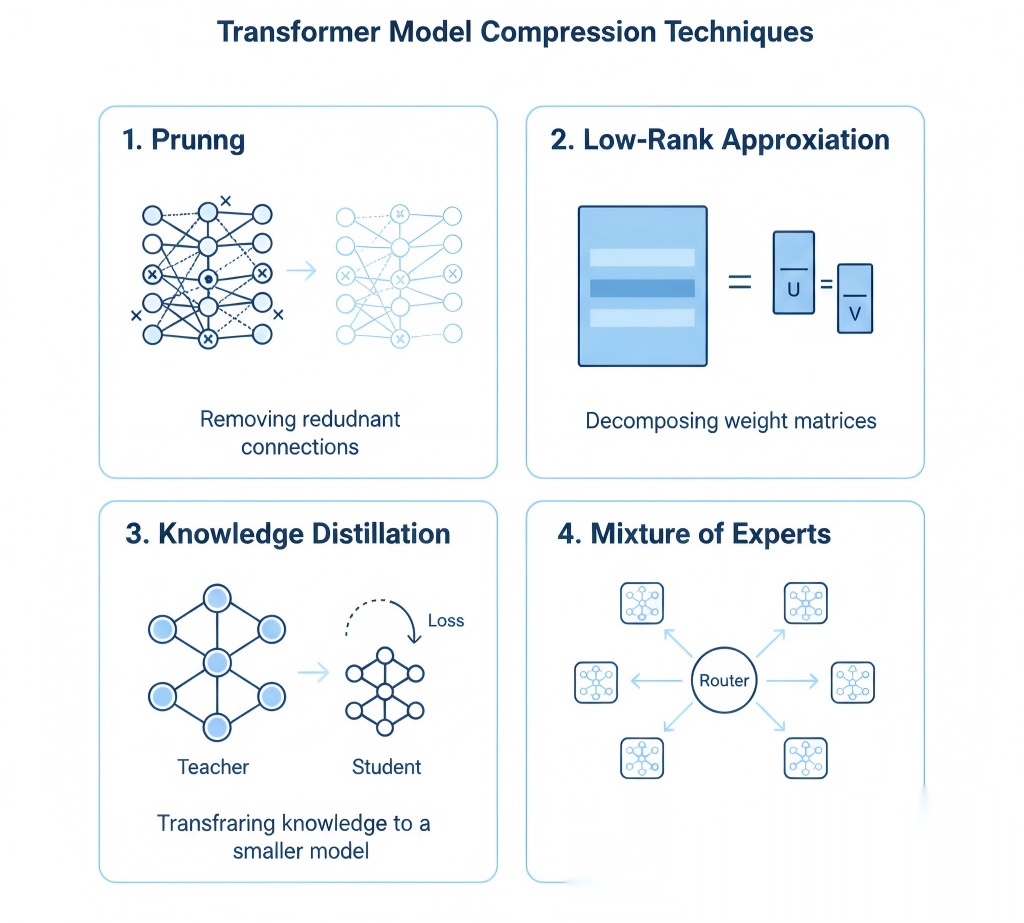
模型压缩技术对比图
方向三:可解释性与可信度
问题:深度学习模型被视为"黑箱",用户难以理解预测依据。
研究方向:
- • Relevance Rollout可视化
- • 注意力权重解释
- • 物理模型与数据驱动模型融合
方向四:模型泛化能力
问题:模型容易在特定数据集上过拟合,难以迁移到新场景。
研究方向:
- • 大规模预训练
- • 因果推理增强(如NuwaDynamics)
- • 数据增强策略
- • 多源多任务学习
方向五:外部信息融合
问题:仅靠历史时空数据难以捕捉所有影响因素。
可融合的外部信息:
- • 物理规律约束
- • 地理位置特征
- • 地形地貌数据
- • 气候特征
- • 卫星遥感数据
融合方式:
- • 多模态融合
- • 结构化注意力机制
- • 定制神经网络结构
应该记住的5件事
1. 时空预测的本质
时空预测需要同时建模时间依赖和空间关联,传统方法难以处理这种复杂的非线性关系。
2. Transformer的核心优势
自注意力机制能够捕捉全局依赖,并行计算带来效率提升,灵活架构支持多种变体。
3. 三类改进范式
- • 模块增强:改进注意力、位置编码等模块
- • 架构调整:层次化结构、GNN融合
- • 基础模型:大规模预训练 + 微调
4. 应用领域各有特点
- • 交通预测:图结构明显,GNN+Transformer常见
- • 气象预测:数据量大,基础模型潜力大
- • 运动预测:需要多模态信息融合
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献210条内容
已为社区贡献210条内容

所有评论(0)