【NotebookLM 使用教程】NotebookLM 入门:知识工作者的外挂常超详细教程 教你入门NotebookLM(总览+案例+进阶)
前言
-
适合谁:第一次接触 NotebookLM,想快速建立“它能做什么/怎么用”的全局地图。
-
你会获得什么:从入门到案例再到进阶玩法的一套完整脉络,以及常见限制/配额/使用方式的解释。
-
建议阅读顺序:本篇先看完再进入后续输出专题(Slides / 播客 / 思维导图等)。
正文
NotebookLM 这个工具我关注很久了,但之前一直没真正用起来。
直到上周我在做一个很小但很真实的需求:管理后台新增「用户资料导出(CSV)」功能。相关信息散落在 PRD、会议纪要、Issue/PR 描述里,按传统方式要来回翻文档、手动整理,还特别容易漏掉边界条件和风险点。
所以我干脆把这 3 份材料一起丢进 NotebookLM,让它基于来源帮我:
-
输出开发任务清单(接口 / 权限与审计 / 频控 / CSV 转义与脱敏 / 测试用例)
-
列出风险点和待确认问题(并附引用定位)
-
生成验收 checklist
我当时的第一反应就是:这东西怎么不早点用?
这篇文章就是我这一周深度折腾 NotebookLM 的完整记录,也整理了不少我从各个社群里扒来的进阶玩法。
如果你是职场打工人,或者也像我一样想在有限时间里更高效地学习和产出,希望这篇笔记能帮你省掉一些摸索时间。
一、NotebookLM到底是个啥?
NotebookLM 是 Google 开发的一款 AI 驱动的研究与写作工具。它的核心理念是“你上传资料,它成为这些资料的专家”——你可以上传 PDF、Google Docs/Slides、网页链接、YouTube视频、音频文件等(最多50个来源),NotebookLM 会基于这些资料回答问题、生成摘要,并提供引用出处。
是另一个聊天机器人吗?
不是。完全不是。
ChatGPT、Claude这些通用大模型,就像一个博学但有点爱"编"的朋友。你问它问题,它从自己的记忆库里调答案,但这个记忆库是用全互联网的数据训练出来的,难免会"一本正经地胡说八道"——业内管这叫"幻觉"(Hallucination)。
NotebookLM走了完全不同的路子:它只根据你喂给它的资料来回答问题。
你上传了什么,它就只在这个范围内思考。
这种设计叫"基于来源的推理"(Source-Grounded Reasoning),这货不瞎编。
它是一个"圈地"思考工具
我觉得最好的比喻是这样的—— 普通AI聊天机器人 = 一个什么都懂但经常不靠谱的万事通
NotebookLM = 一个专门帮你读书、做笔记、找重点的私人助理
当你创建一个"笔记本"(Notebook)的时候,你实际上是在画一个圈:在这个圈里,AI只能用这些资料来思考。
这意味着什么?
意味着你可以把公司内部的文件扔进去分析,不用担心它混入别的信息。意味着你可以把一个完整的课程资料打包进去,让它帮你梳理知识体系。意味着你做研究的时候,它给你的每一个结论都能追溯到原文出处。
对我来说,这简直是内容创作者的福音。
以前整理资料最头疼的就是"这个观点是在哪看到的来着?"——NotebookLM直接给你标注原文位置,点一下就跳转。
主要功能包括
-
智能问答:针对上传资料提问,AI 回答并标注引用来源
-
Audio Overviews(音频概览):一键生成两位 AI 主持人讨论你资料内容的「播客式」音频,还支持互动模式让你加入对话
-
自动生成内容:包括摘要、时间线、FAQ、简报文档、学习指南、闪卡、测验等
-
Video Overviews(视频概览):将资料转化为带图文解说的视频
-
思维导图:可视化展示资料结构
-
笔记功能:保存引用、整理想法
二、上手第一步
2.1 准备Google账号
NotebookLM 是 Google 出品的工具,需要使用 Google 账号登录。如果你在中国大陆使用,需要先解决网络访问问题。
关于价格:
NotebookLM 基础功能完全免费,但在高算力功能上(如生成幻灯片 Slide Deck、长音频 Deep Dive)有严格的每日配额。
免费版通常每天仅支持约 3 次音频生成;高峰期生成速度较慢,容易排队。
如果你是重度使用者,建议升级到 Gemini Advanced 订阅(包含在 Google One AI Premium 计划中),官方订阅价格为 $20/月。
该权益与 NotebookLM 账号互通,升级后将自动解锁 NotebookLM Plus 会员状态,拥有 5-10 倍的生成额度(如每天 20 次音频生成、500 次对话),且生成速度更快,无需长时间等待。
进入方式:
-
手机下载 App

2.2 创建笔记本
两种新建方式:
2.3 上传资料
支持的格式比我想象的多
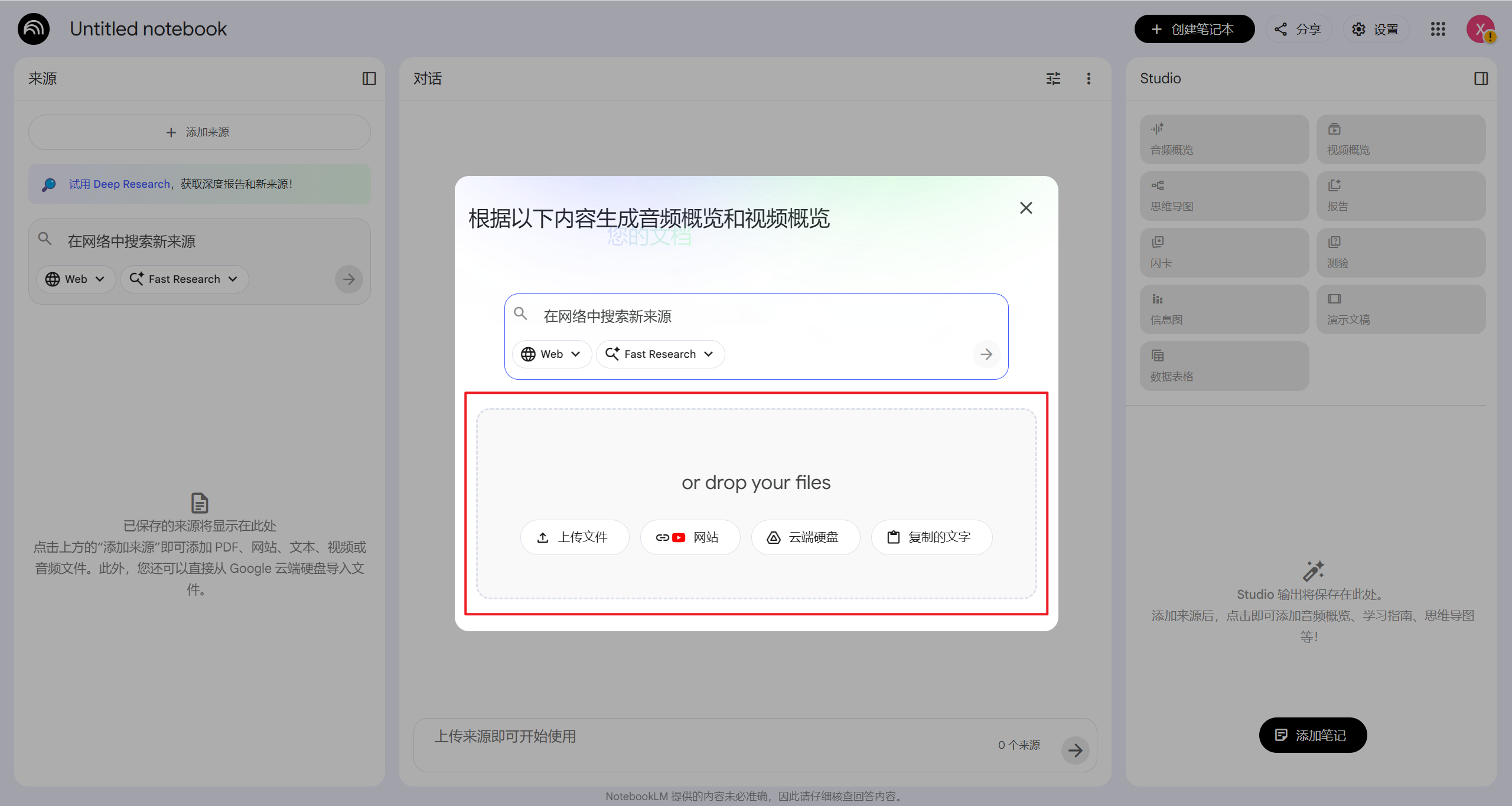
NotebookLM的"饭量"很大,能吃很多种格式:
文档类:
-
Google Docs(直接连接,可以同步更新)
-
PDF文件
-
TXT纯文本
网页和视频:
-
网页URL(它会自动抓取正文)
-
YouTube视频链接(自动读取字幕)
办公软件:
-
Google Slides
每个笔记本最多能放50个来源,每个来源最高50万字。算一下,一个笔记本理论上能容纳2500万字——相当于几十本厚书的量级。
2.4 中文设置
NotebookLM 右上角的设置只包含输出语言的设置:
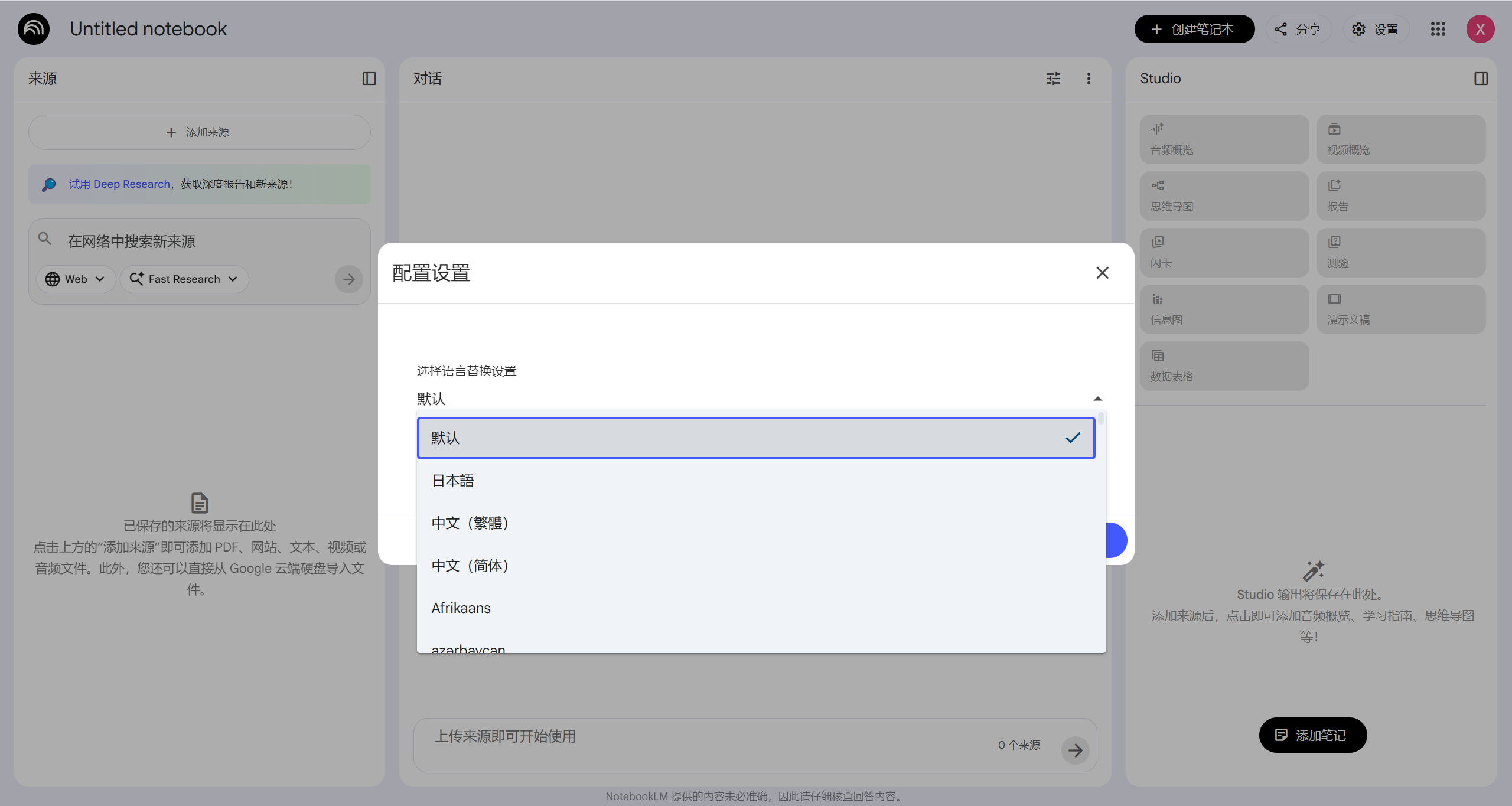
如果要设置界面语言,需要在 Google 账号 里调整。
NotebookLM 的界面语言会跟随 Google 账号的语言设置。
✅ 正确设置路径:
-
打开 Google 账号管理页面 (myaccount.google.com)。
-
点击左侧 “个人信息 (Personal Info)”。
-
下滑找到 “语言 (Language)”。
-
将首选语言修改为 “简体中文”。
-
关键一步: 改完后,回到 NotebookLM 页面,按
F5刷新或退出账号重新登录,中文界面才会生效!🔄
2.5 实操案例
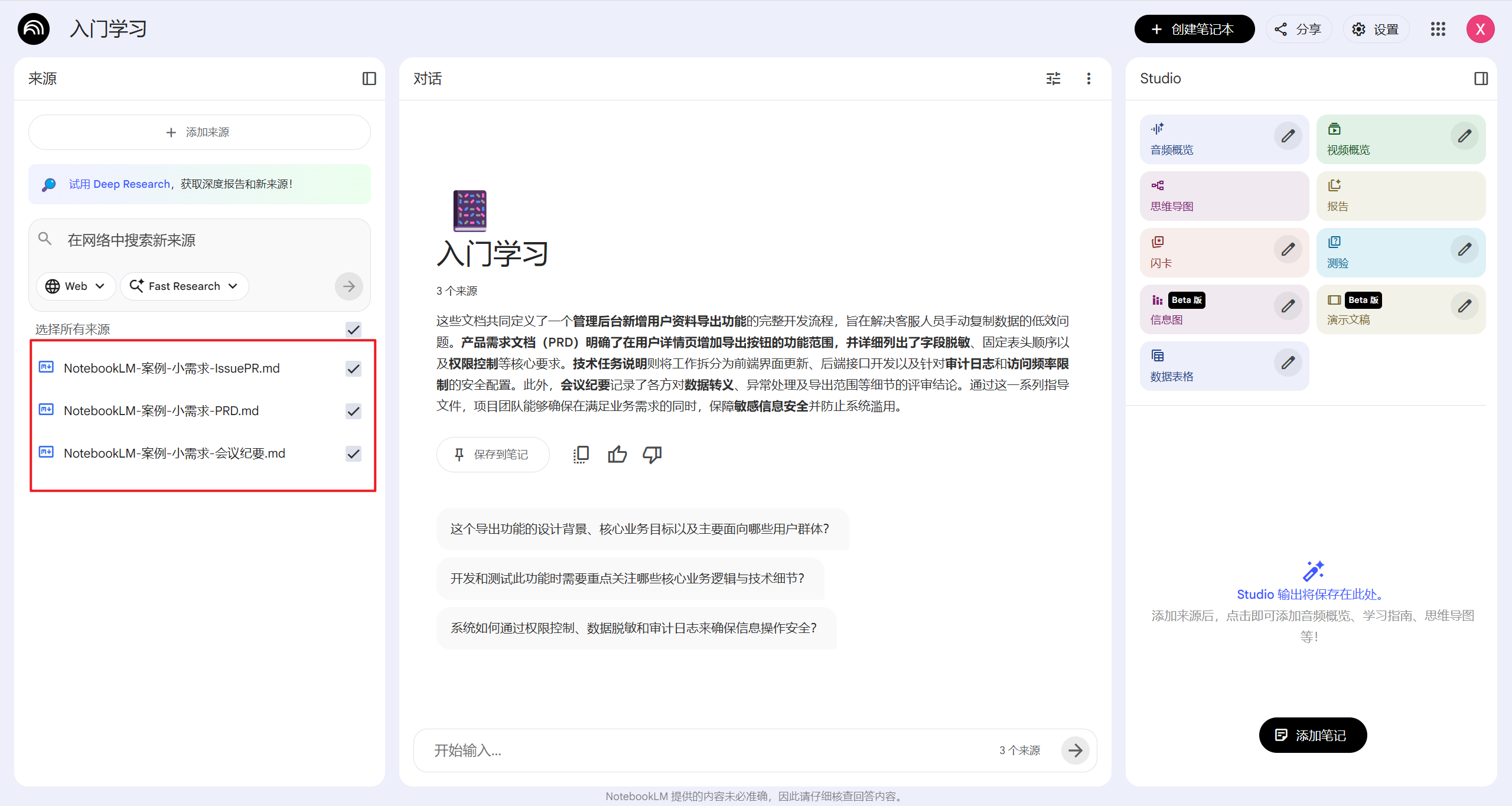
我用近期一个项目的资料来分享实操流程:
-
收集资料:选一个你正在做的“小迭代/小需求”,准备 3 份最常见的材料(越少越容易上手):
-
需求说明:PRD/需求卡片(飞书/语雀/Jira 任意一种,导出 PDF 或直接复制成 TXT)
-
会议纪要:评审/同步会的纪要(哪怕只有 1 页也行)
-
开发线索:相关 Issue/PR 的描述(GitHub/GitLab/Jira 截图或导出)
-
-
分类上传:把这 3 份材料分别作为 3 个来源上传,命名清楚(例如“PRD-xx功能”“纪要-xx日期”“Issue-xx编号”)。
-
勾选控制:不同阶段只勾选不同来源,让 NotebookLM 输出更准:
-
做任务拆解:只勾选 PRD + 纪要,问“请生成开发任务清单(含前后端/接口/埋点/测试用例)并按优先级排序”。
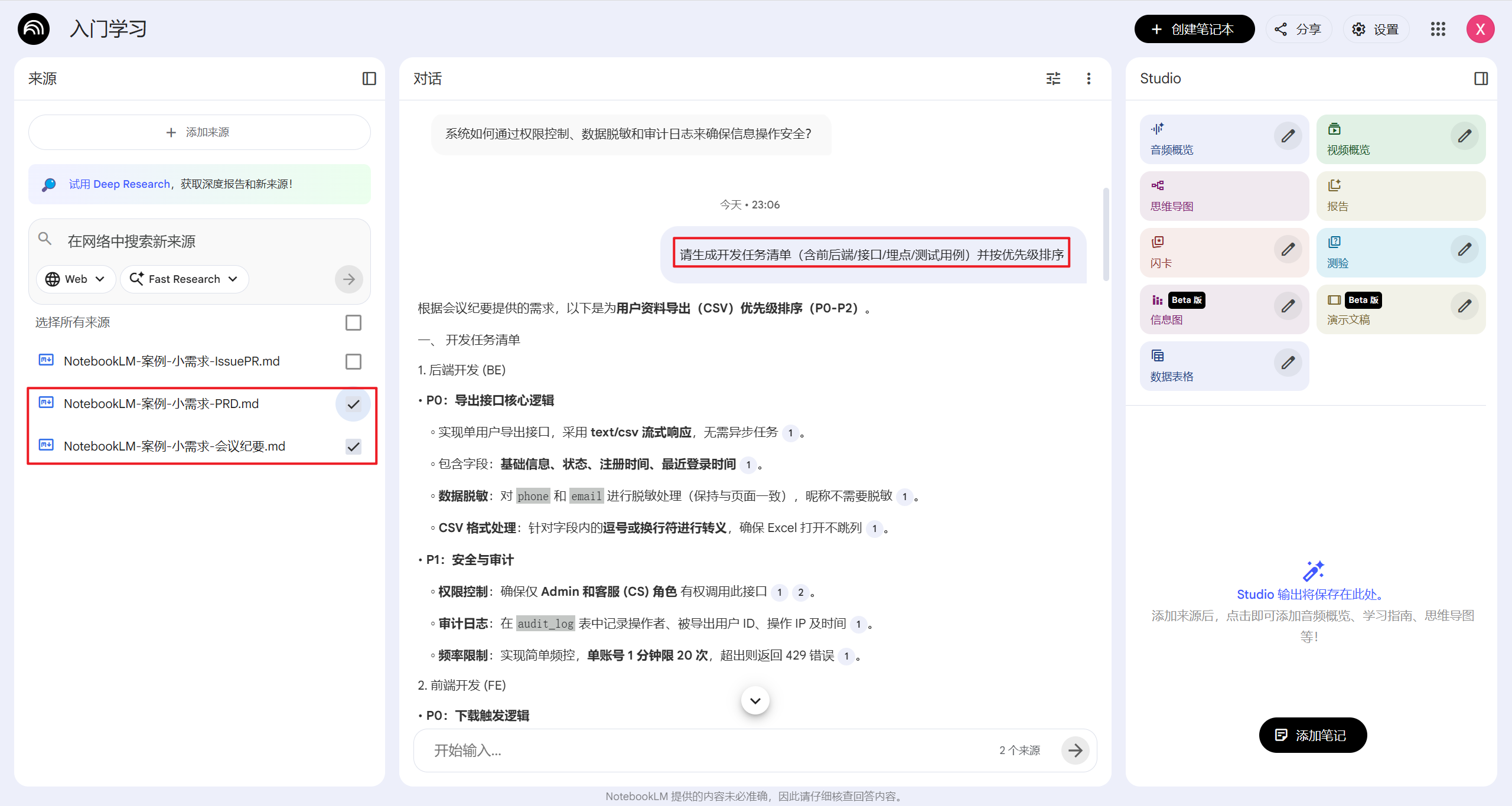
-
做风险排查:只勾选 纪要 + Issue/PR,问“请列出实现风险、依赖项、以及必须向产品/后端确认的问题(按影响程度排序)”。
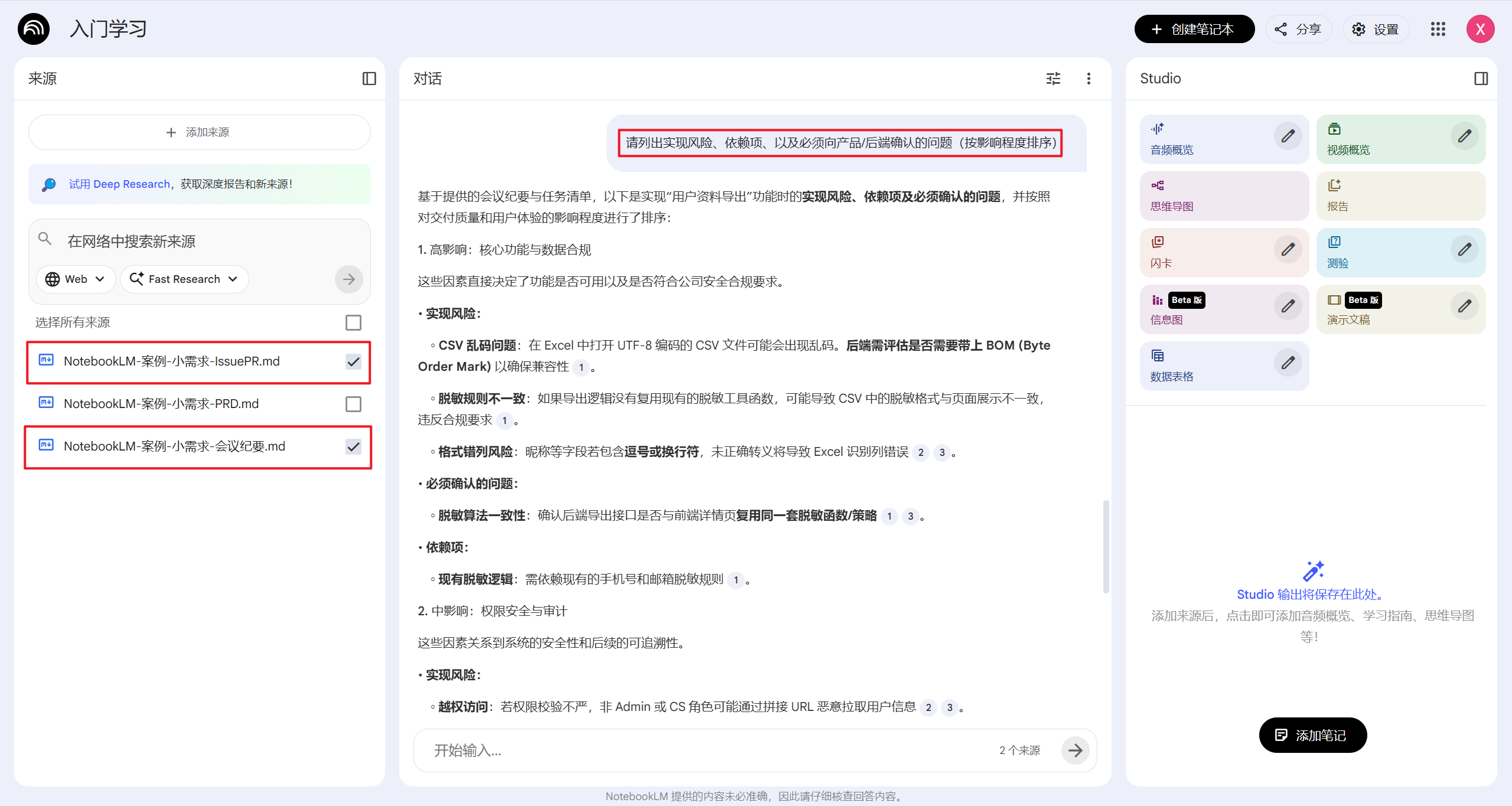
-
做验收准备:只勾选 PRD,问“请生成验收 checklist(含边界条件)并给出 10 条最容易遗漏的用例”。
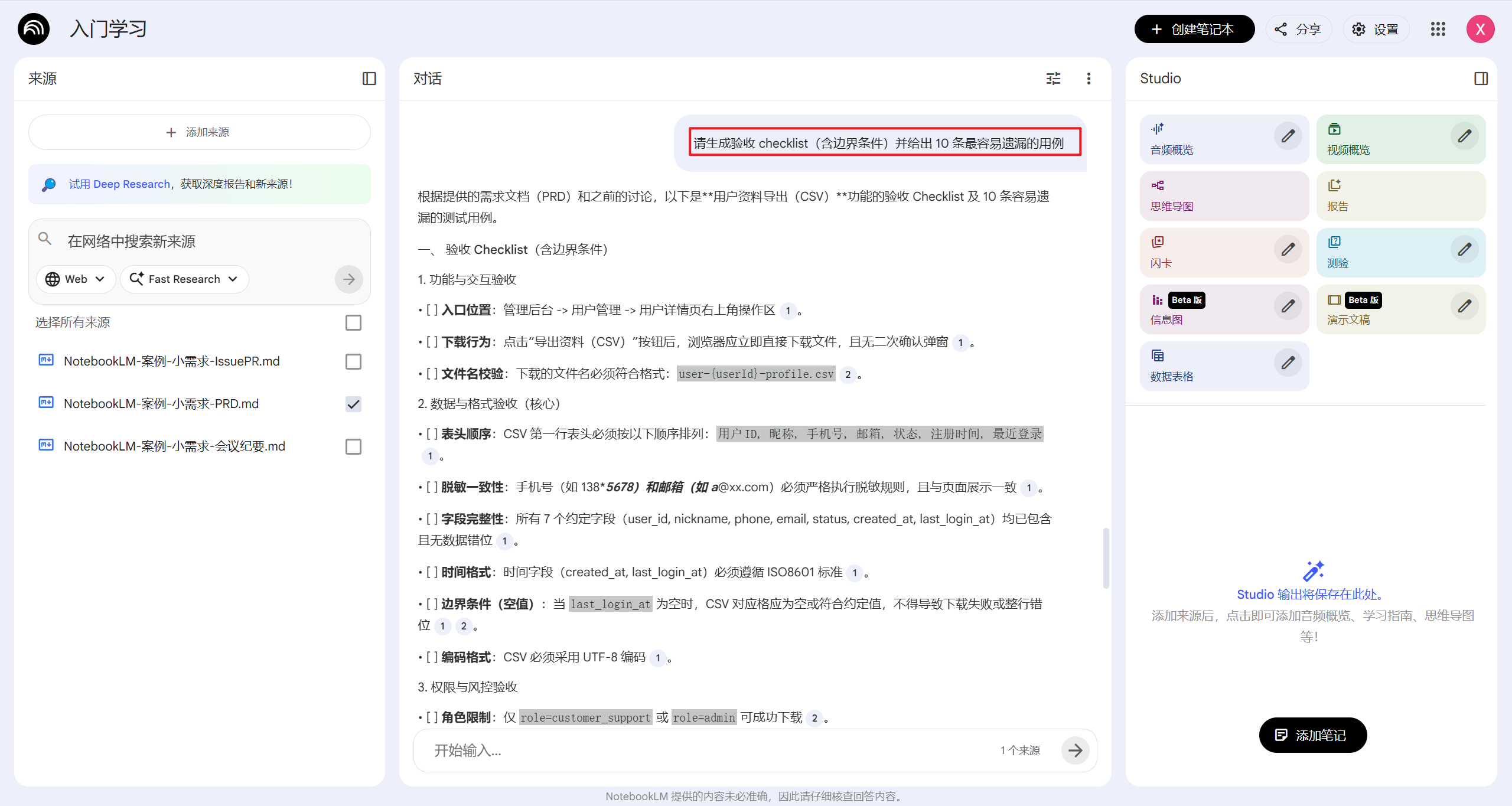
-
一个隐藏技巧:合并文件绕过50个限制
这是我从Reddit扒来的骚操作——如果你有很多小文件(比如100个笔记、一整年的周报),别傻傻地一个个上传。50个名额很快就用完了。
正确做法:在上传前把同类文件合并。
-
多个PDF → 用PDF合并工具整成一个大文件
-
大量Markdown笔记 → 用脚本合并成一个TXT
NotebookLM处理一个10万字的文件,比处理100个1000字的文件效率高得多,而且只占1个名额。
我现在的习惯是:先在本地整理好,能合并的先合并,再上传。
三、核心界面拆解:三块区域各有分工
点击新建,创建笔记
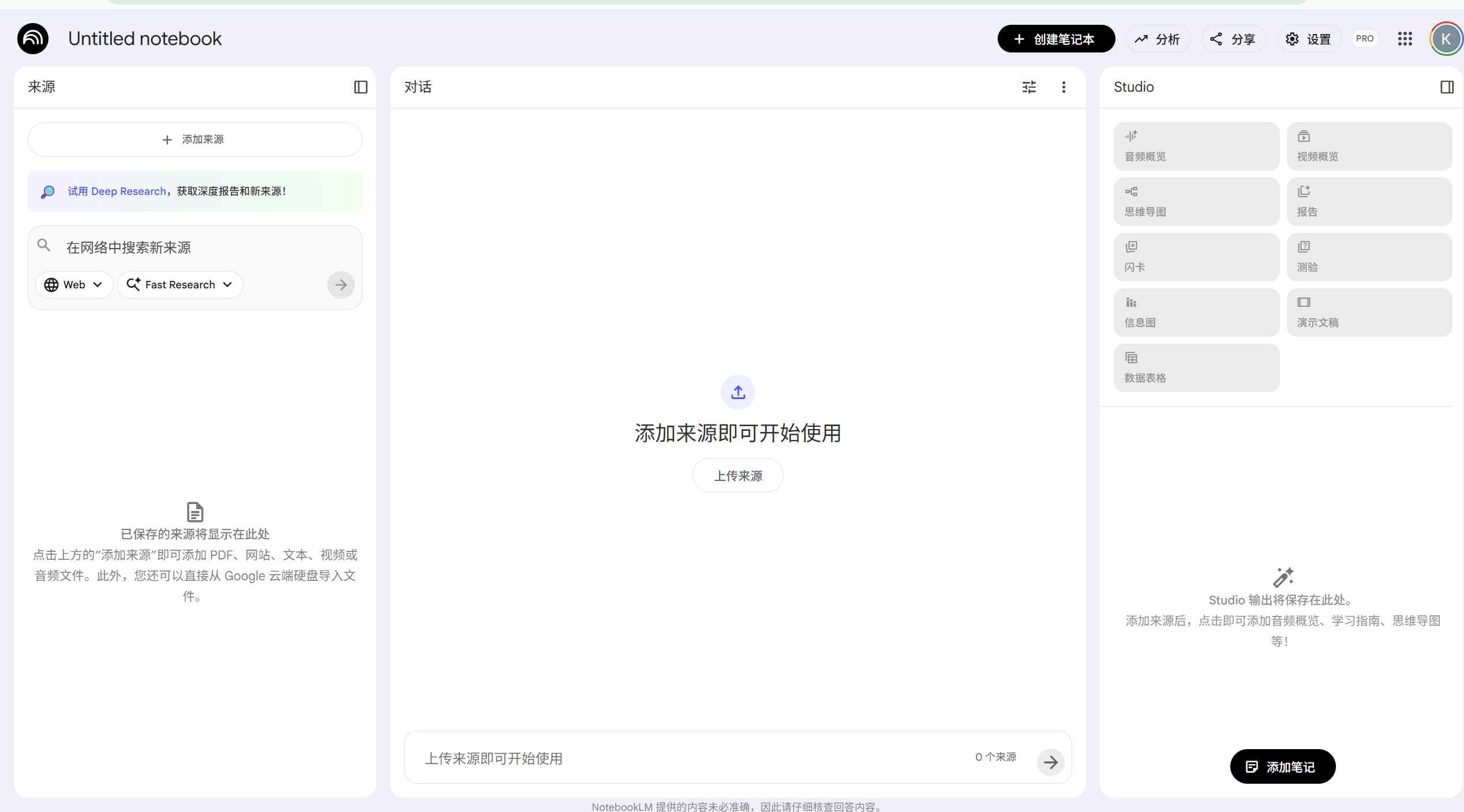
3.1 左边:资源面板(Source Panel)
这是你的"记忆库"。所有上传的资料都在这里列着。
关键功能:
-
复选框控制注意力:勾选哪些文件,AI就只看哪些文件
3.2 中间:对话区(Chat Interface)
这是你和AI聊天的地方。
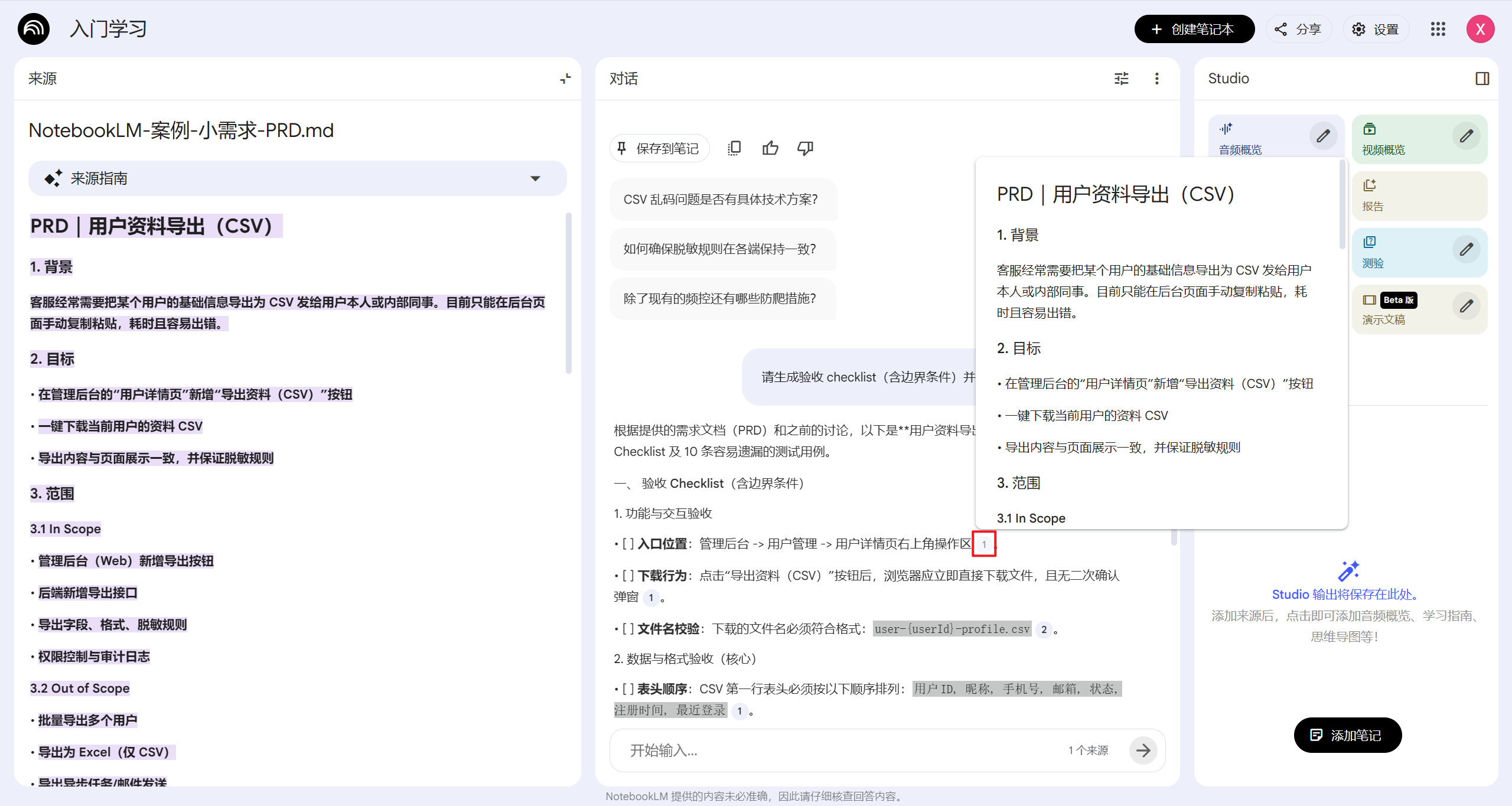
最有用的功能是内联引用。AI给你的每个回答,重要观点后面都会带一个数字脚注,比如1。点击这个数字,左边会自动高亮原文段落。
这个设计太重要了。意味着你可以随时验证AI说的是不是真的,有没有断章取义。
另外它还会根据你的资料自动生成一些"建议问题",对于刚上传资料不知道问啥的新手很友好。
3.3 右边:Studio工作台功能详解
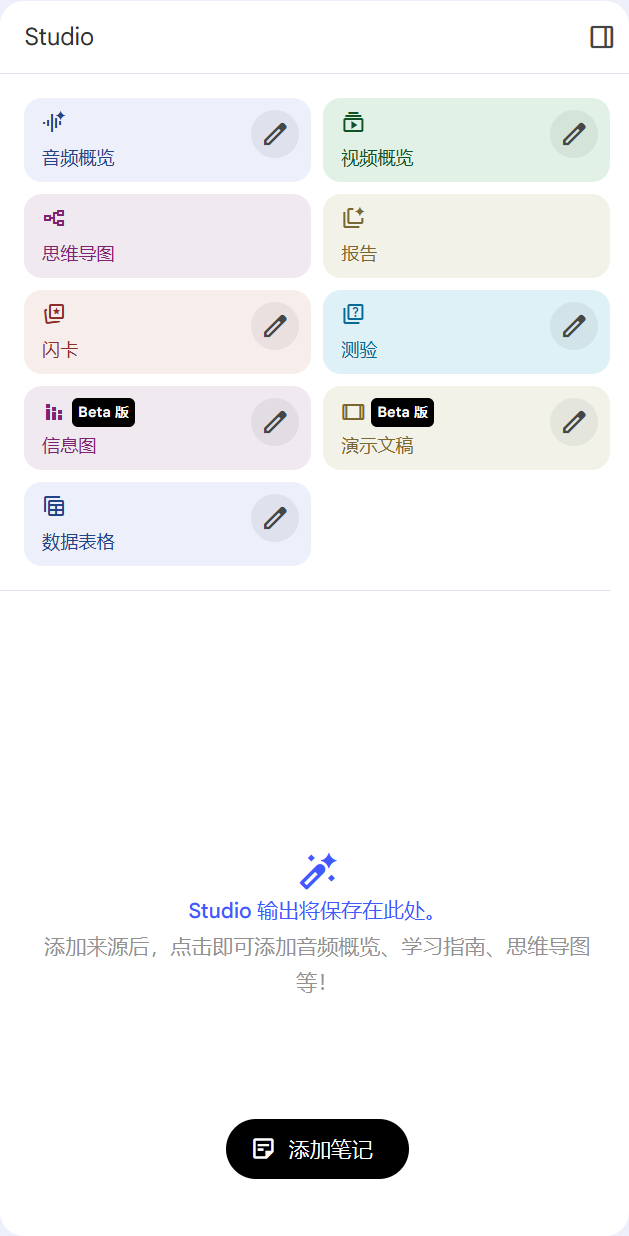
Studio面板位于界面右侧,包含9个主要功能模块,每个都支持自定义:
3.3.1 音频概览 (Audio Overview)
生成两位AI主持人讨论你资料的"播客式"音频
自定义选项:
-
格式:Deep Dive深度讨论 / Brief简报 / Critique评论 / Debate辩论
-
时长:简短(2-3分钟) / 标准(5-6分钟) / 加长(8-10分钟)
-
语言:支持80+语言
-
引导提示:指定聚焦主题、目标受众、专业程度等
-
互动模式:可实时加入对话向主持人提问(目前仅支持英语)
3.3.2 视频概览 (Video Overview)
生成带旁白的幻灯片式视频,包含图表、引用、数据可视化
自定义选项:
-
格式:多种预设风格 + Custom自定义视觉风格
-
语言:80+语言
-
引导提示:指定聚焦内容、学习目标、目标受众
3.3.3 思维导图 (Mind Map)
可视化展示资料的主题结构和概念关系
自定义选项:
-
点击节点可深入提问
-
展开/折叠分支查看不同层级
-
可下载为图片分享
3.3.4 报告 (Reports)
生成结构化文档,如你截图中的"用户资料导出(CSV)实现检查清单"
自定义选项:
-
预设格式:Briefing Doc简报 / Study Guide学习指南 / Blog Post博客 / FAQ / Timeline时间线 等
-
自定义格式:完全自定义结构、风格、语调
-
语言:130+语言
-
动态建议:根据资料内容自动推荐适合的报告类型
3.3.5 闪卡 (Flashcards)
生成问答式记忆卡片
自定义选项:
-
主题:指定聚焦哪些内容
-
难度:基础 / 进阶
-
数量:设置卡片数量
-
每张卡片点击"Explain"可获得详细解释+引用
3.3.6 测验 (Quiz)
生成选择题测试
自定义选项:
-
主题:指定测试范围
-
难度:基础 / 进阶
-
题目数量:可设置
-
答错后可查看解释和出处
3.3.7 信息图 (Infographic)
将资料转化为可视化信息图
自定义选项:
-
语言:中文(简体)等多语言
-
屏幕方向:横向 / 纵向 / 方形
-
详细程度:简短 / 标准 / 详细(Beta)
-
描述提示:指定风格、颜色、侧重内容,如"使用蓝色主题,强调3个关键数据"
3.3.8 演示文稿 (Slides)
自定义选项:
-
格式:详细演示文稿(适合邮件发送/独立阅读)/ 演示用幻灯片(简洁直观)
-
语言:中文(简体)等多语言
-
时长:短 / 默认
-
描述提示:如"为新手用户创建一套演示文稿,采用大胆活泼的风格,注重分步说明"
核心要点:每个功能都可以通过点击✏️编辑图标进入自定义界面,输入引导提示(steering prompt)来精确控制输出内容。
3.3.9 数据表格 (Data Tables)
将散乱信息整理成结构化表格,可导出到Google Sheets
自定义选项:
-
语言:中文(简体)等多语言
-
描述提示:用自然语言指定行、列内容,如"创建对比表格,列:产品名称、价格、优缺点"
-
导出:可导出到 Google Sheets 继续编辑
使用场景示例:
-
会议记录 → 行动项表格(按负责人、优先级分类)
-
竞品分析 → 对比表格(价格、功能、策略)
-
研究论文 → 文献综述表格(研究年份、样本量、结论)
-
备考复习 → 知识点表格(按时间、人物、事件整理)
-
旅行规划 → 目的地对比表格(最佳时间、预算、景点)
注意:目前优先开放给 Google AI Pro/Ultra 订阅用户,普通用户会在几周内陆续开放。
四、让我惊艳的功能:AI播客生成
这是NotebookLM最出圈的功能,也是我觉得最神奇的地方。
它不是念稿子,是真的在"聊"
点击生成Audio Overview之后,系统会把你上传的资料转化成一段两个AI主持人(一男一女)的对话。
第一次听的时候我真的惊了——这俩人不是在念课文,是在聊天。他们会互相打断,会感叹,会用比喻解释复杂概念,偶尔还会开玩笑。
这种表达方式,比直接读原文友好太多了。我现在用它来"被动学习"——做饭的时候放着听,通勤的时候听,遛娃的时候听。
自定义指令:做自己的导演

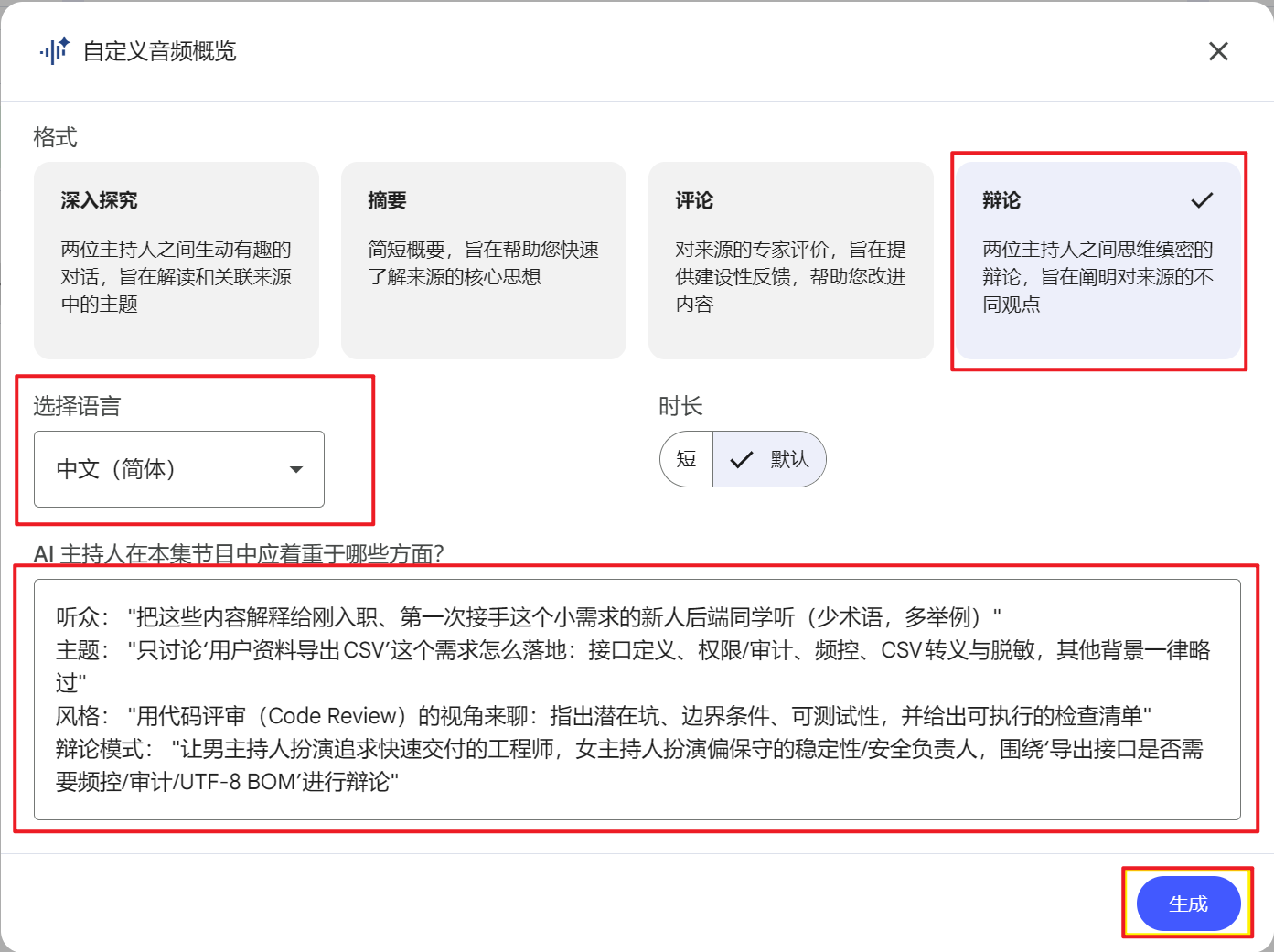
最新版本加了一个Customize功能,这才是真正好玩的地方。
你可以给AI主持人下指令,控制他们怎么聊:
设定听众: "把这些内容解释给刚入职、第一次接手这个小需求的新人后端同学听(少术语,多举例)"
聚焦主题: "只讨论‘用户资料导出CSV’这个需求怎么落地:接口定义、权限与审计、频控、CSV转义与脱敏,其他背景一律略过"
改变风格: "用代码评审(Code Review)的视角来聊:指出潜在坑、边界条件、可测试性,并给出可执行的检查清单"
辩论模式: "让男主持人扮演追求快速交付的工程师,女主持人扮演偏保守的稳定性/安全负责人,围绕‘导出接口是否需要频控/审计/UTF-8 BOM’进行辩论"
听众: "把这些内容解释给刚入职、第一次接手这个小需求的新人后端同学听(少术语,多举例)" 主题: "只讨论‘用户资料导出CSV’这个需求怎么落地:接口定义、权限与审计、频控、CSV转义与脱敏,其他背景一律略过" 风格: "用代码评审(Code Review)的视角来聊:指出潜在坑、边界条件、可测试性,并给出可执行的检查清单" 辩论模式: "让男主持人扮演追求快速交付的工程师,女主持人扮演偏保守的稳定性/安全负责人,围绕‘导出接口是否需要频控/审计/UTF-8 BOM’进行辩论"
我试过一个很骚操作的指令:"假设这是2016年,你们是两个刚接手这个老系统的工程师,用当时团队的技术栈和流程来讨论这个‘导出CSV’需求应该怎么做。"效果意外的有趣——AI会用“老系统视角”去提醒你哪些地方最容易踩坑。
五、这是我用上述项目的测试结果
5.1 音频概览
5.1.1 默认设置
目前不能显示
5.2 视频概览
5.2.1 默认设置
目前不能显示
5.2.2 添加自定义

案例1:
| 视觉风格 | 水彩 或 可爱 |
|---|---|
| AI主持人侧重 | 用轻松有趣的方式讲解这个小需求“用户资料导出(CSV)”怎么做:从 PRD 提炼目标与验收标准、从会议纪要提炼待确认项,最后把实现拆成「接口/权限与审计/频控/CSV 转义与脱敏/测试」五块。多用生活类比(比如“导出像打印清单”“脱敏像打码”),语气活泼。 |
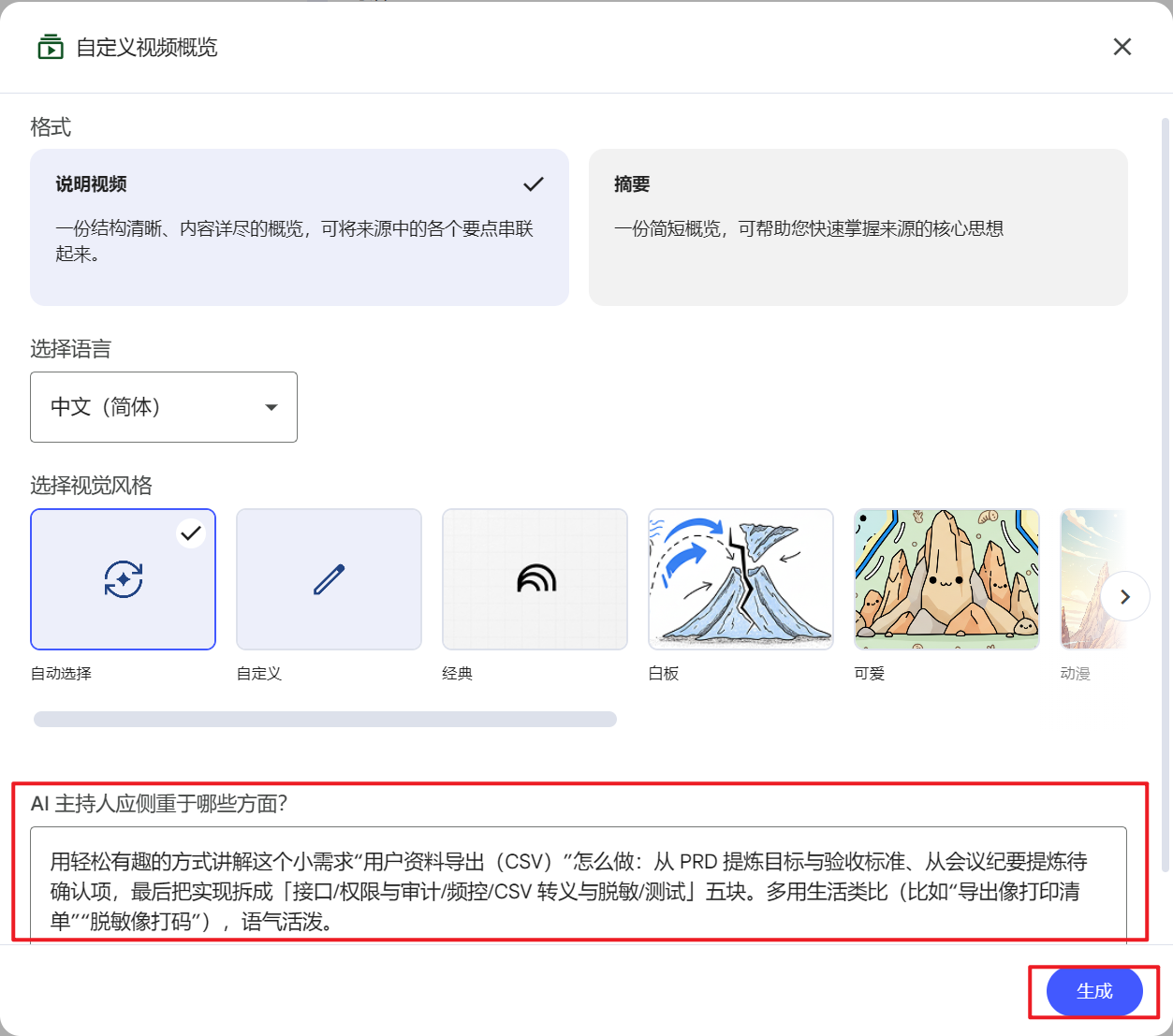
案例2:
| 视觉风格 | 动漫 |
|---|---|
| AI主持人侧重 | 我是刚入门的开发/测试同学,对后端接口不熟。请用最简单的语言解释这个导出功能要注意什么:为什么要权限控制、为什么要审计日志、为什么要做频控、CSV 为什么要转义(逗号/换行)、手机号/邮箱怎么脱敏。多用生活中的例子,尽量避免专业术语。 |
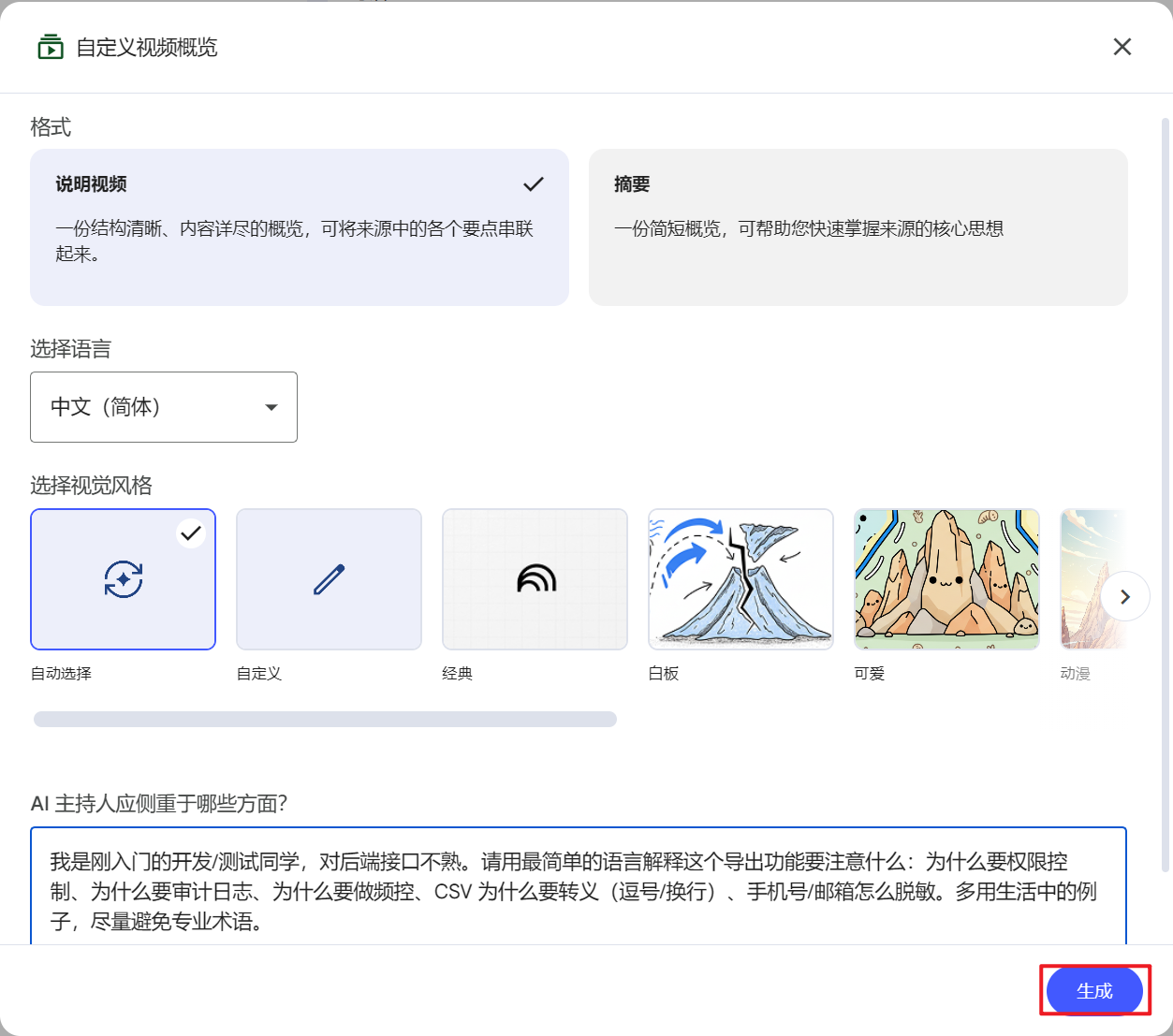
5.3 思维导图
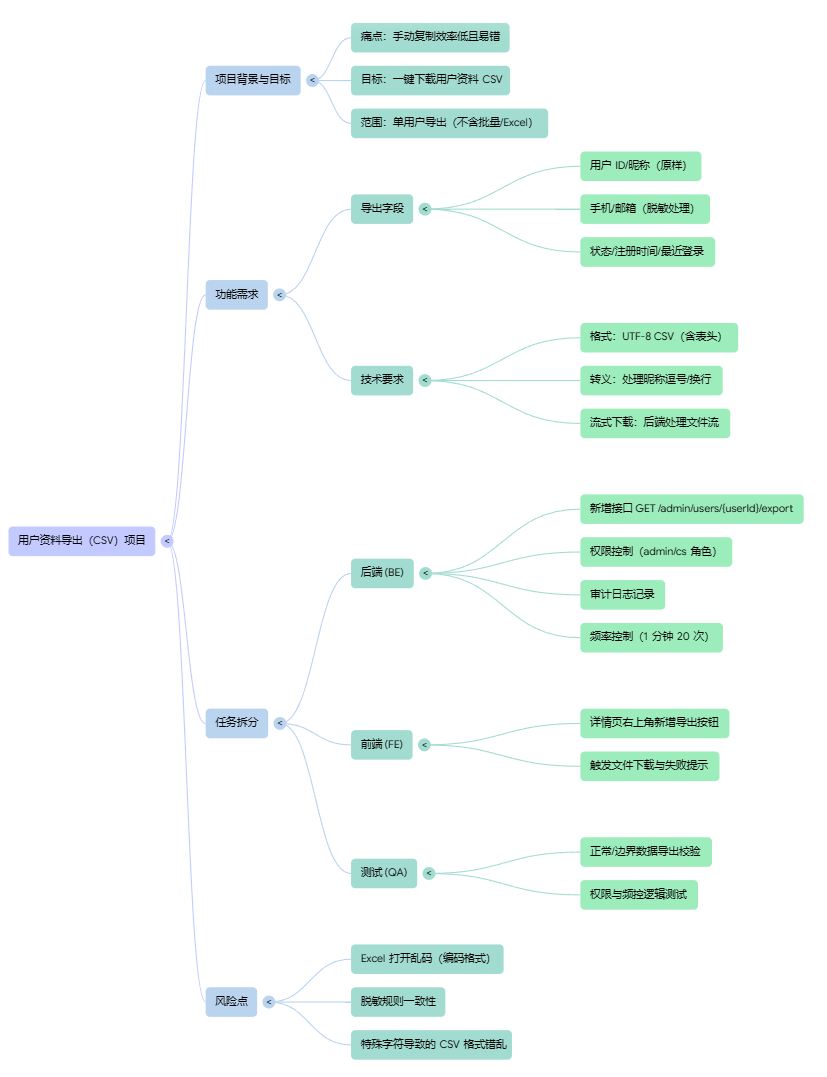
5.4 报告

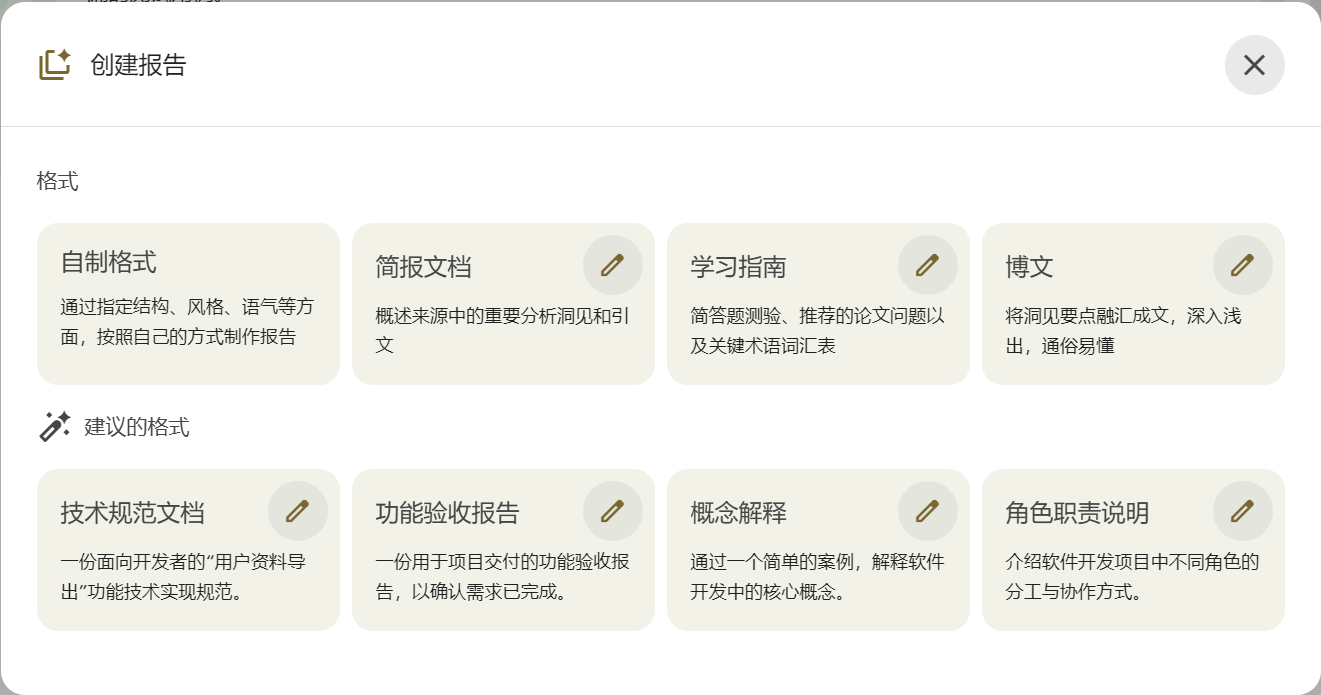
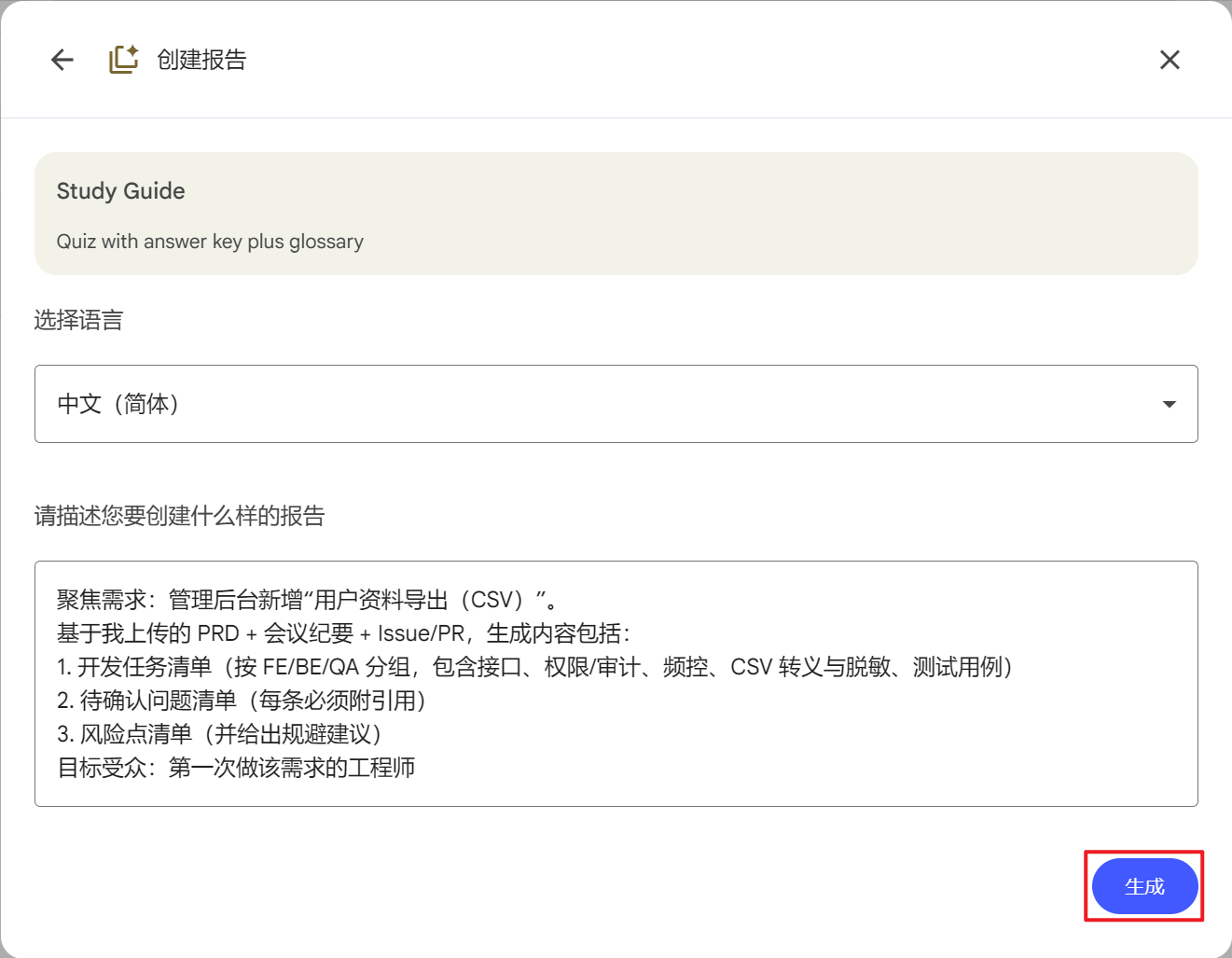
案例1:开发任务拆解(学习指南)
选择格式:学习指南 ✏️
点击编辑后输入:
聚焦需求:管理后台新增“用户资料导出(CSV)”。 基于我上传的 PRD + 会议纪要 + Issue/PR,生成内容包括: 1. 开发任务清单(按 FE/BE/QA 分组,包含接口、权限/审计、频控、CSV 转义与脱敏、测试用例) 2. 待确认问题清单(每条必须附引用) 3. 风险点清单(并给出规避建议) 目标受众:第一次做该需求的工程师
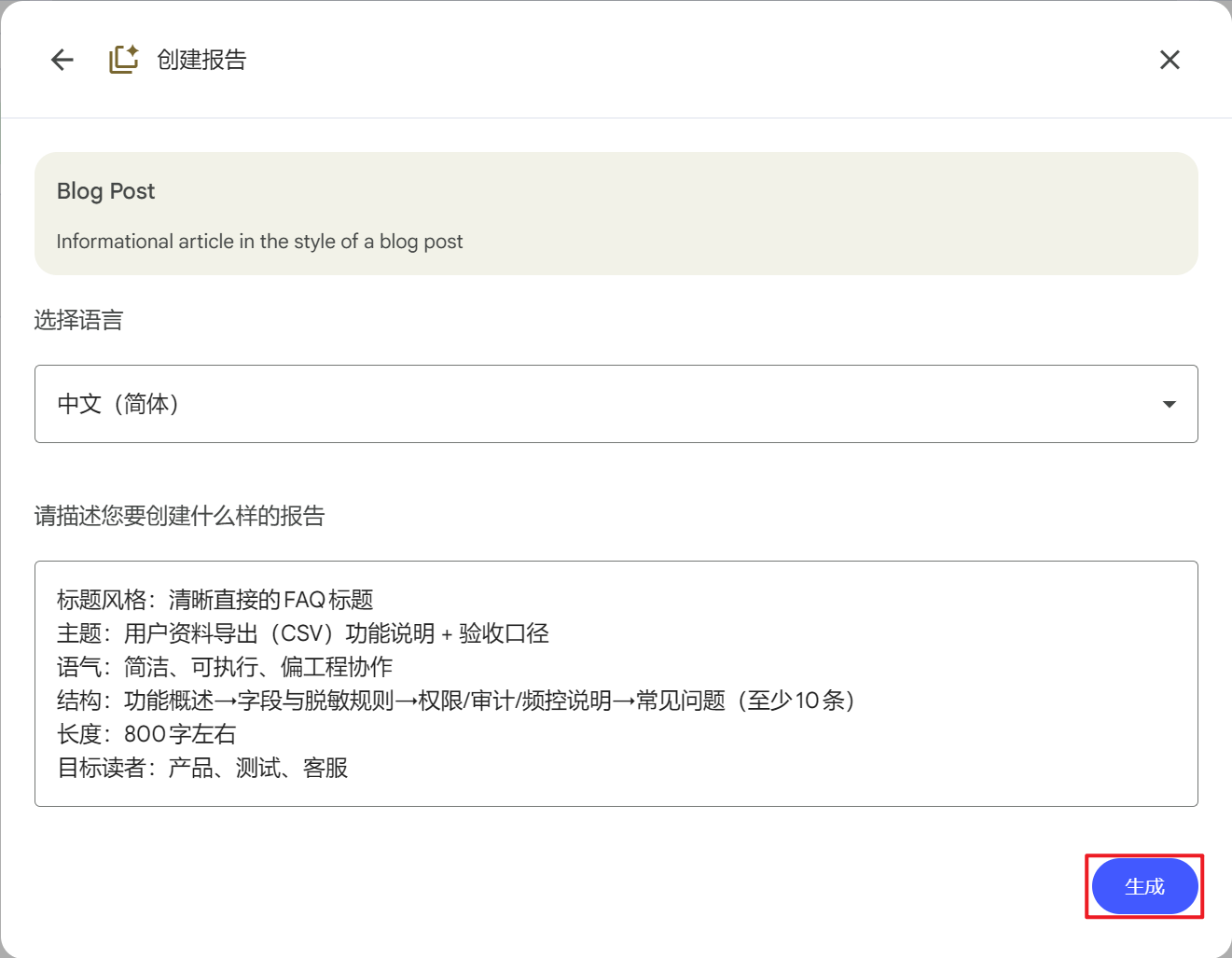
案例2:给产品/测试的FAQ(博文)
选择格式:博文 ✏️
点击编辑后输入:
标题风格:清晰直接的FAQ标题 主题:用户资料导出(CSV)功能说明 + 验收口径 语气:简洁、可执行、偏工程协作 结构:功能概述→字段与脱敏规则→权限/审计/频控说明→常见问题(至少10条) 长度:800字左右 目标读者:产品、测试、客服
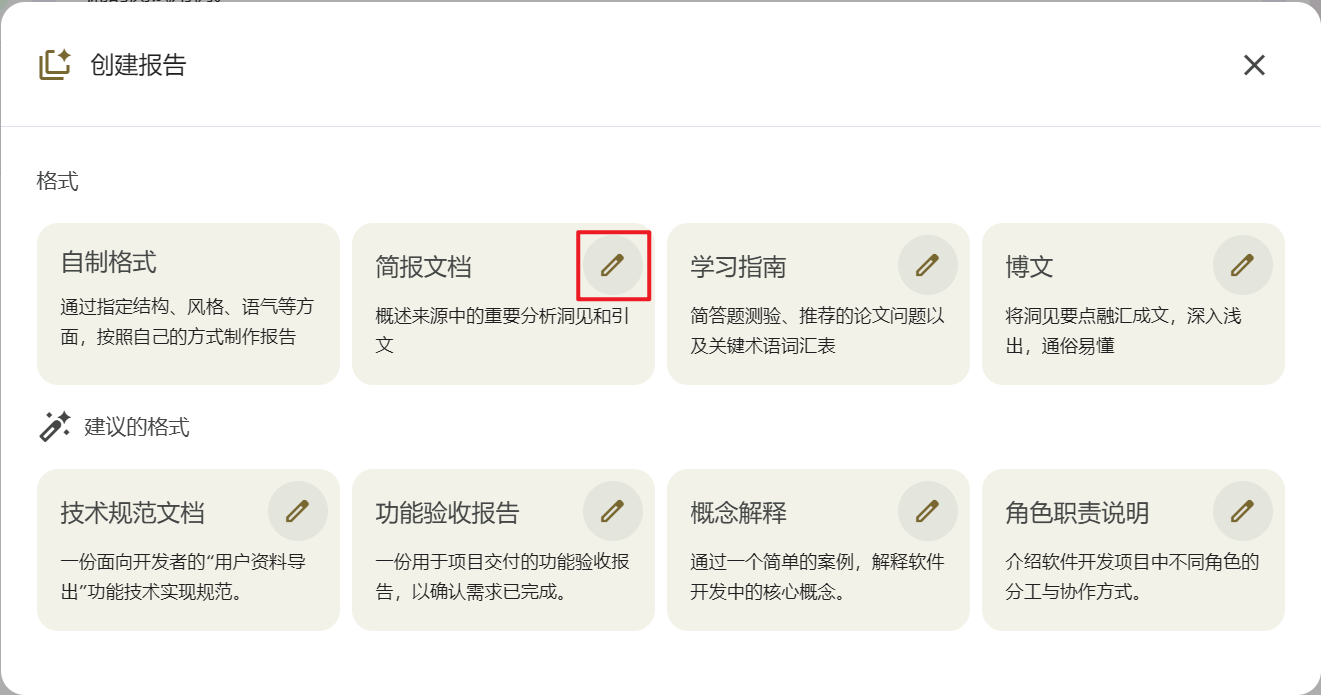
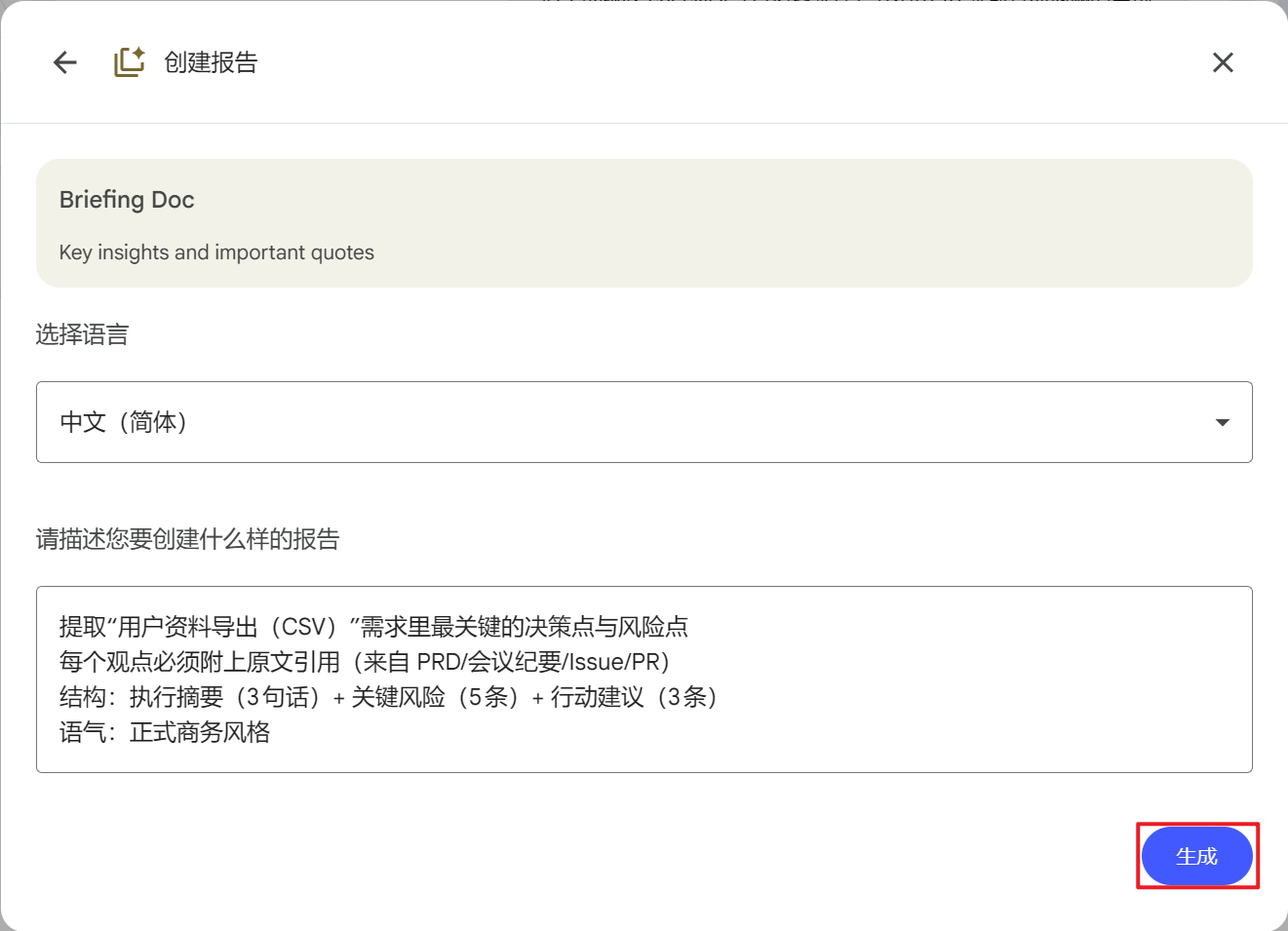
案例3:给老板的简报文档
选择格式:简报文档 ✏️
点击编辑后输入:
提取“用户资料导出(CSV)”需求里最关键的决策点与风险点 每个观点必须附上原文引用(来自 PRD/会议纪要/Issue/PR) 结构:执行摘要(3句话)+ 关键风险(5条)+ 行动建议(3条) 语气:正式商务风格
案例4:上线前检查清单(自制格式)
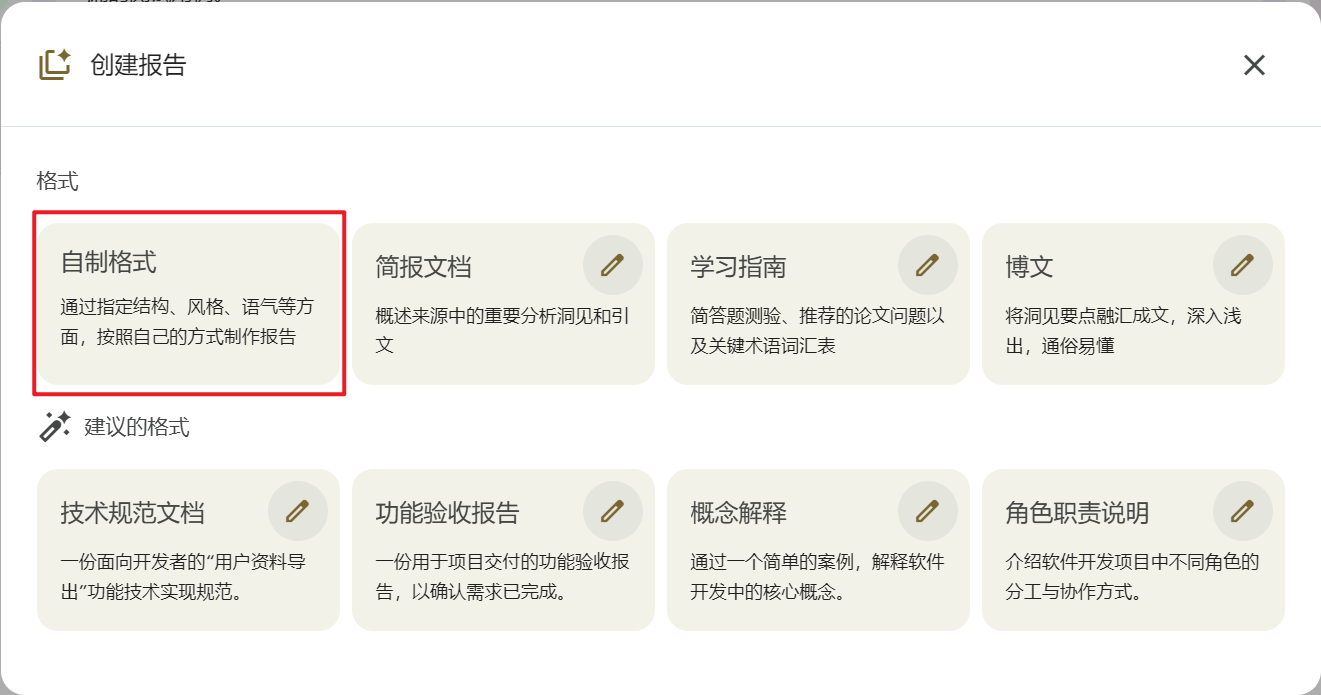
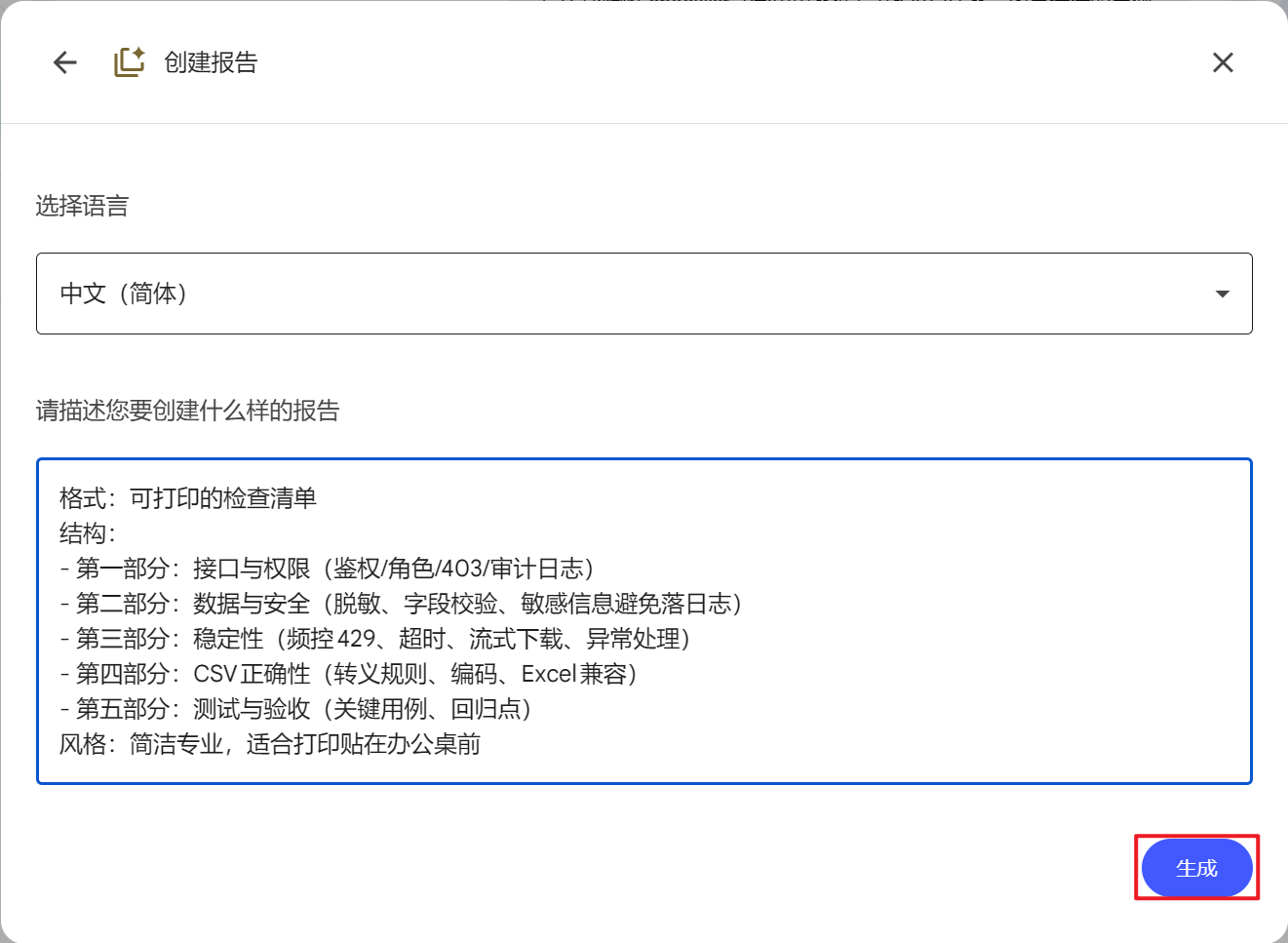
选择格式:自制格式
输入描述:
格式:可打印的检查清单 结构: - 第一部分:接口与权限(鉴权/角色/403/审计日志) - 第二部分:数据与安全(脱敏、字段校验、敏感信息避免落日志) - 第三部分:稳定性(频控429、超时、流式下载、异常处理) - 第四部分:CSV正确性(转义规则、编码、Excel兼容) - 第五部分:测试与验收(关键用例、回归点) 风格:简洁专业,适合打印贴在办公桌前
5. 闪卡
我个人感觉闪卡特别适用于把“需求口径/边界条件/异常码”这种容易漏的点做成随时复习的卡片,这里用“用户资料导出(CSV)”这个小需求做演示。

生成后可以在线使用闪卡:
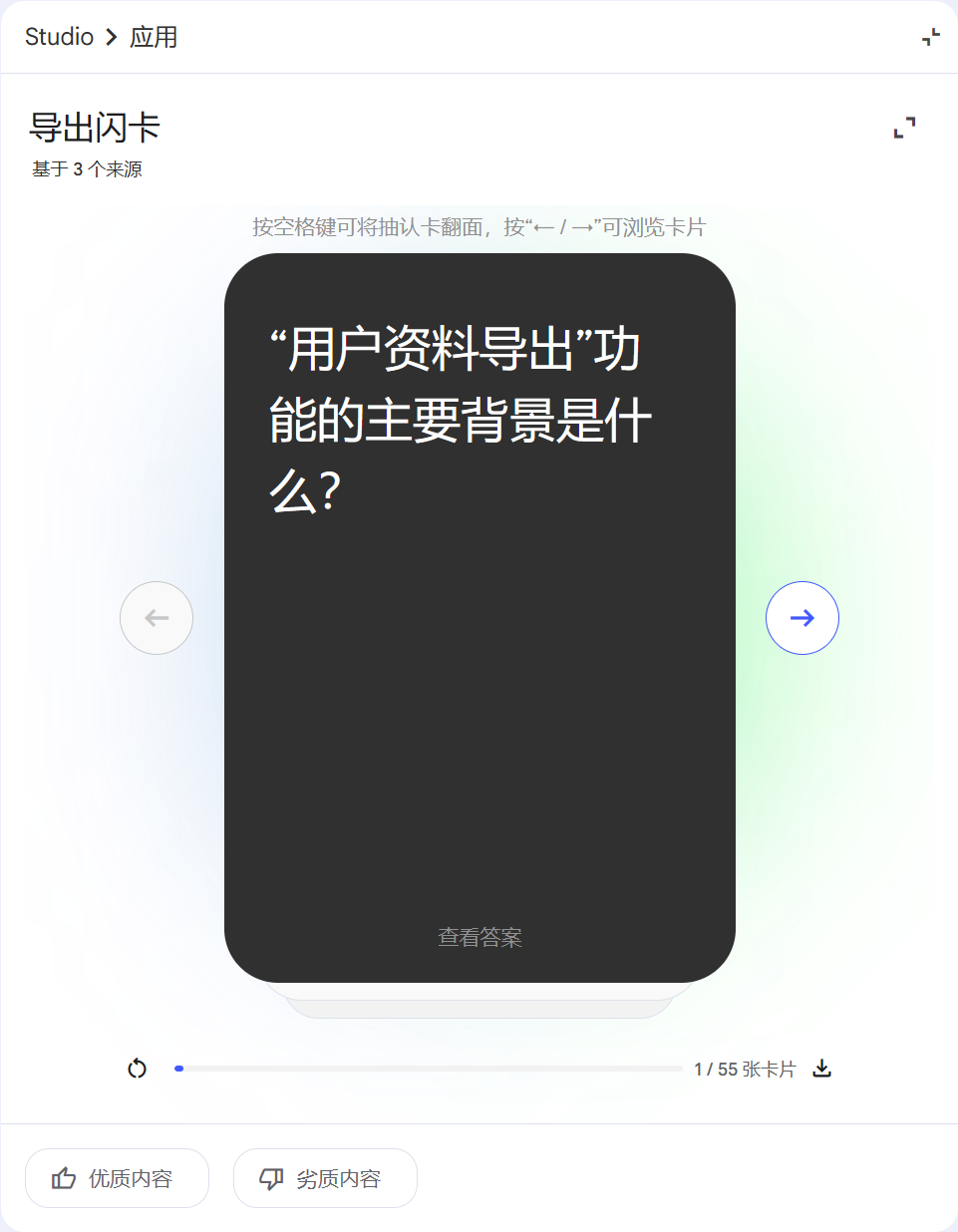
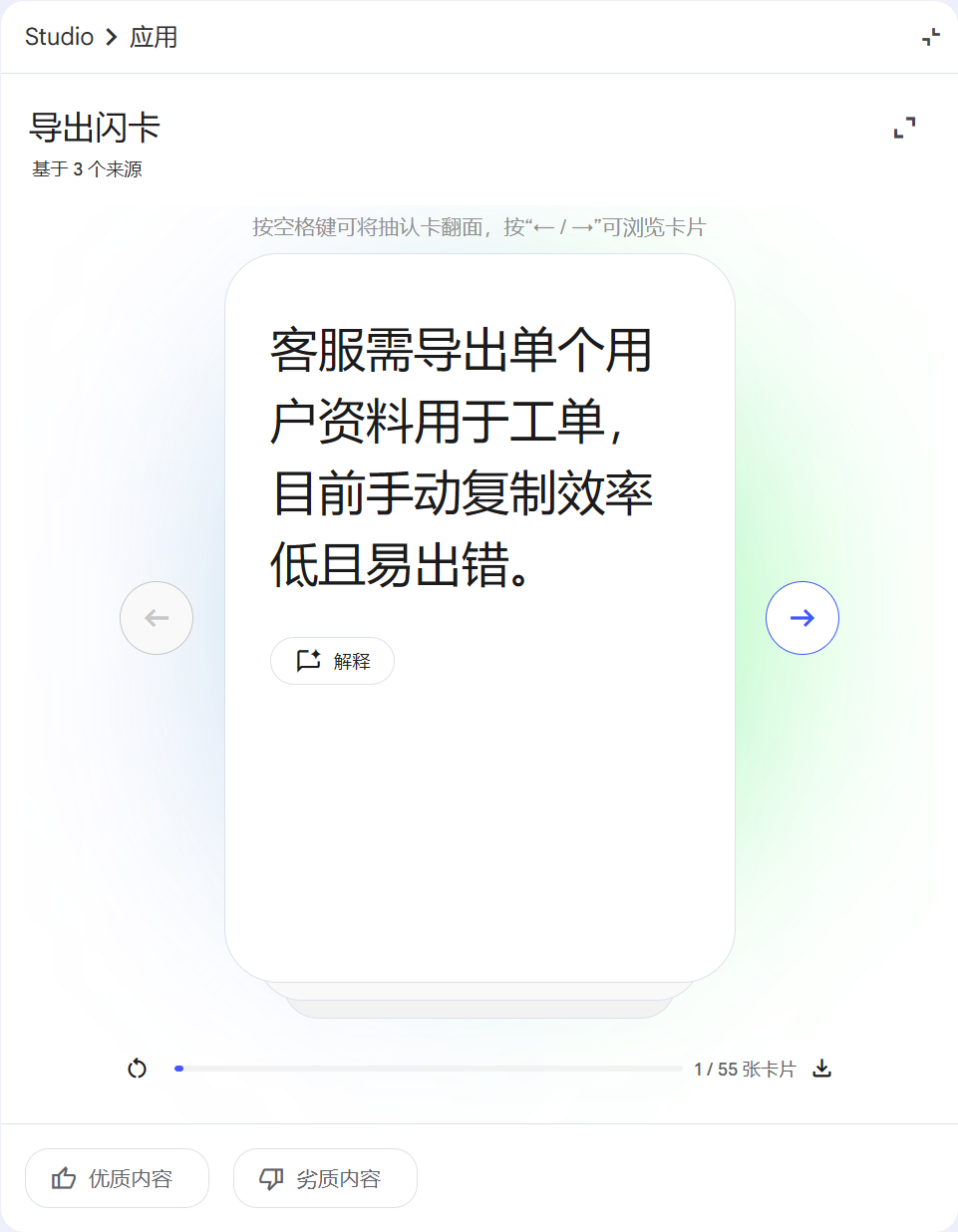
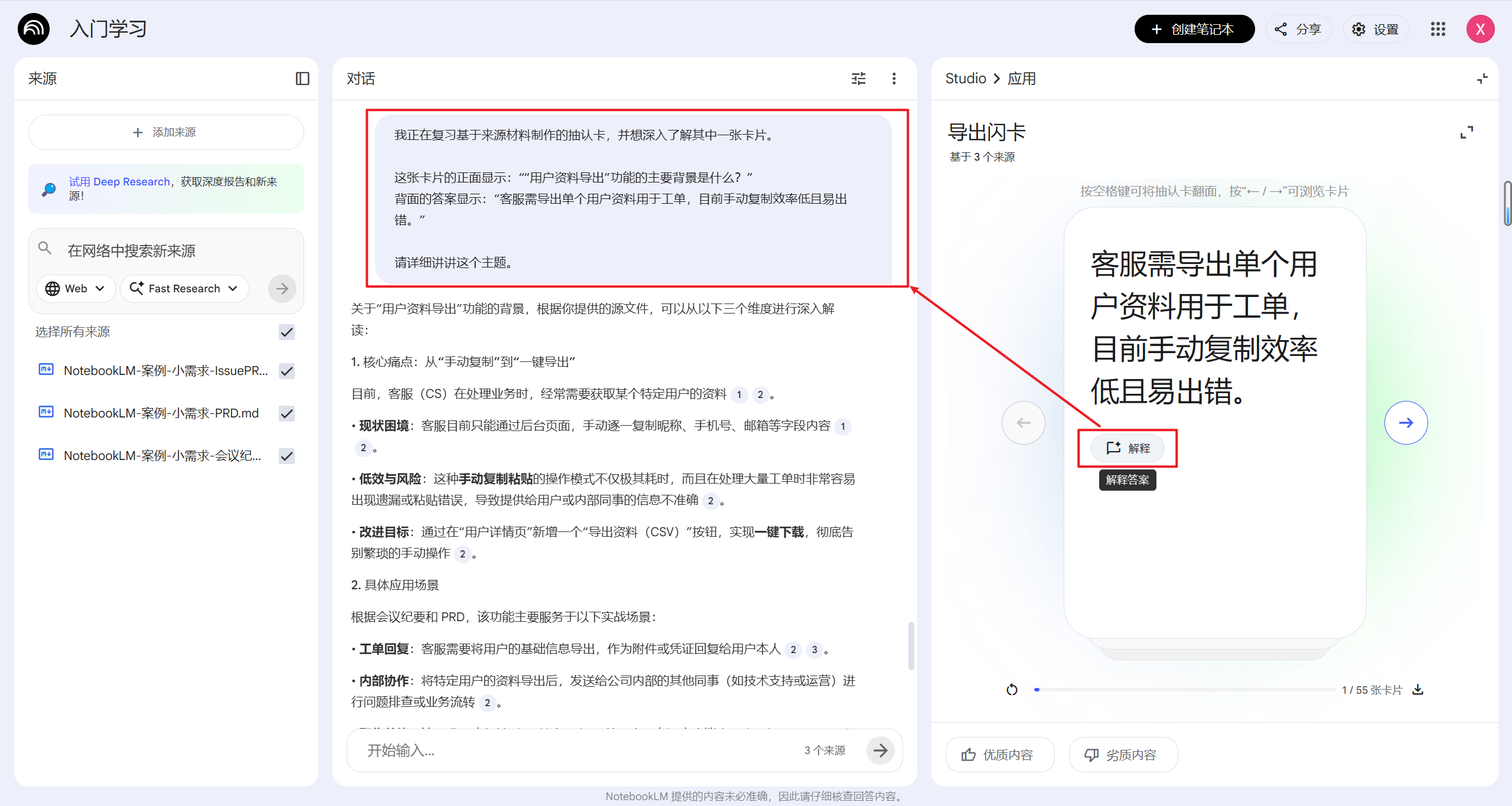
点击解释,可以在左侧对话框生成 AI 对话 为你解释这段信息:
如果想要下载到本地,通常会导出为 CSV 文件。
接下来可以用下面的工具导入并复习。
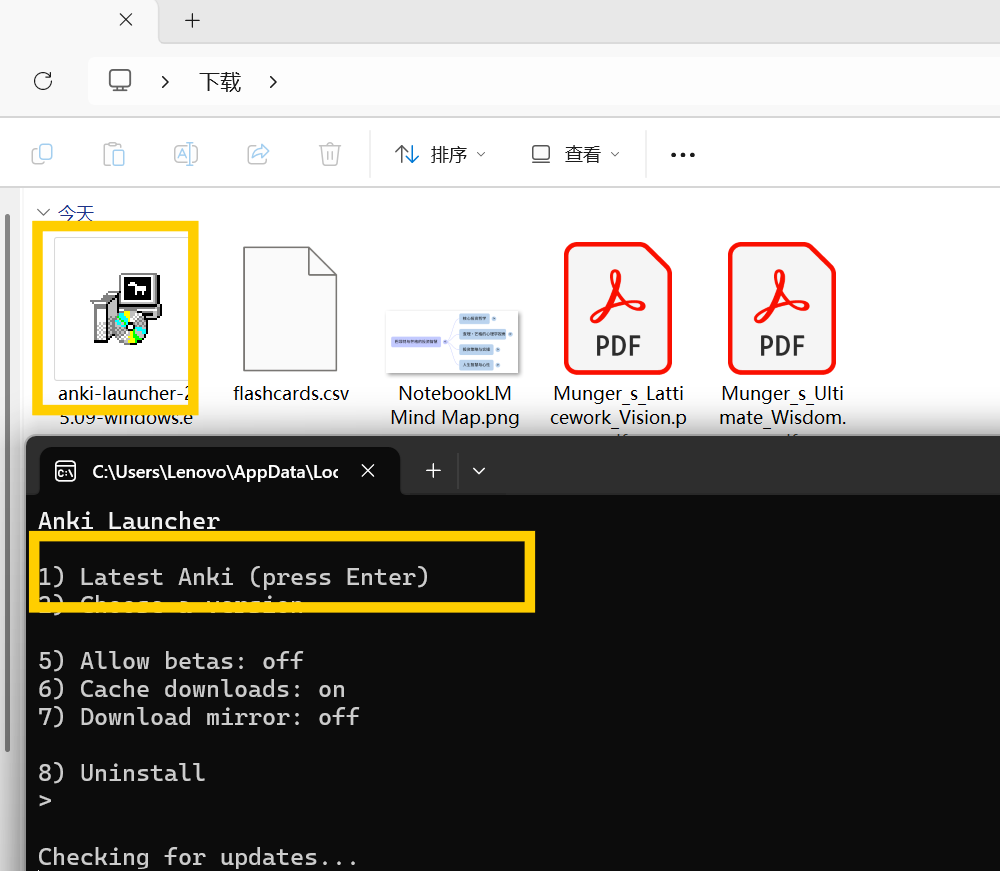
方法:导入Anki(推荐⭐)
Anki是最强大的间隔重复记忆软件,免费
步骤:
-
下载 Anki
-
安装
-
按 Enter → 开始下载安装最新版Anki
-
等待下载完成(可能需要几分钟)
-
安装完成后会自动打开Anki
-
- 打开Anki → 文件 → 导入
-
选择你的CSV文件
-
设置字段分隔符为「逗号」
-
第一列映射为「正面」,第二列映射为「背面」
这样就能用科学的间隔重复算法来复习了!
案例1:核心概念速记卡
| 设置 | 选择 |
|---|---|
| 卡片数量 | 更少 |
| 难度等级 | 简单 |
| 主题 | 聚焦这个需求最核心的5个工程概念:权限控制、审计日志、频控、CSV 转义、数据脱敏。卡片正面是概念名称,背面是一句话定义 + 该需求中的落地示例。 |
案例2:金句记忆卡
| 设置 | 选择 |
|---|---|
| 卡片数量 | 更少 |
| 难度等级 | 简单 |
| 主题 | 提取这个需求里最容易遗漏的10条“验收口径/边界条件”。卡片正面是关键词(1-3个字),背面是完整规则 + 出处引用 + 一句话解释。 |
案例3:中英对照术语卡
| 设置 | 选择 |
|---|---|
| 卡片数量 | 标准 |
| 难度等级 | 中等 |
| 主题 | 需求/接口常见术语中英对照。卡片正面是英文(如Audit Log / Rate Limit / CSV Escaping),背面是中文解释 + 在本需求中的使用场景 + 引用。 |
案例4:安全与隐私专项
| 设置 | 选择 |
|---|---|
| 卡片数量 | 更多 |
| 难度等级 | 中等 |
| 主题 | 仅限于“安全与隐私”专项。每张卡片正面是一个风险点(如“越权导出”“日志泄露手机号”“频控缺失”),背面包含:定义 + 触发场景 + 规避做法 + 引用。 |
5.6 测验


案例1:场景应用测量(进阶)
| 设置 | 选择 |
|---|---|
| 问题 数量 | 标准 |
| 入口等级 | 中等 |
| 主题 | 测试能否把 PRD/纪要里的口径应用到实现与验收。题目形式:给出一个场景(如无权限访问、昵称含逗号、超限429),判断应该返回什么/如何处理/如何验收。 |
案例2:安全/稳定性风险识别(抽样测验)
| 设置 | 选择 |
|---|---|
| 问题 数量 | 更多 |
| 入口等级 | 困难 |
| 主题 | 仅限于“安全/稳定性”相关内容。测试风险识别能力:给出一个实现做法或事故现象,判断属于哪类问题(越权、脱敏缺失、频控缺失、CSV格式错误、审计缺失等)。 |
5.7 信息图

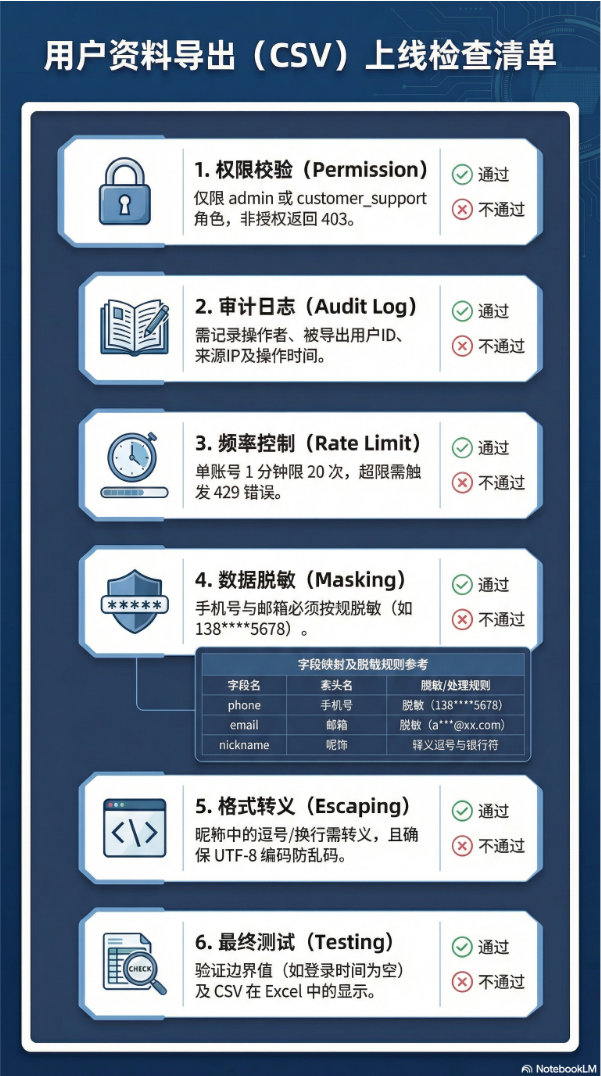
案例1:上线检查清单信息图(适合打印)
| 设置 | 选择 |
|---|---|
| 语言 | 中文(简体) |
| 屏幕方向 | 纵向 |
| 详细程度 | 标准 |
| 描述 | 用户资料导出(CSV)上线检查清单流程图。使用深蓝色商务风格,按实现顺序排列检查项(权限→审计→频控→脱敏→转义→测试),用图标表示"通过/不通过"。适合打印贴在办公桌前。 |
案例2:五大关键点一图总结
| 设置 | 选择 |
|---|---|
| 语言 | 中文(简体) |
| 屏幕方向 | 方形 |
| 详细程度 | 简短 |
| 描述 | 5个关键工程点的视觉总结:权限控制、审计日志、频控、数据脱敏、CSV转义。使用温暖的橙色和米色配色,每个点用一个简单图标+一句话解释。风格简洁可爱,适合团队分享。 |

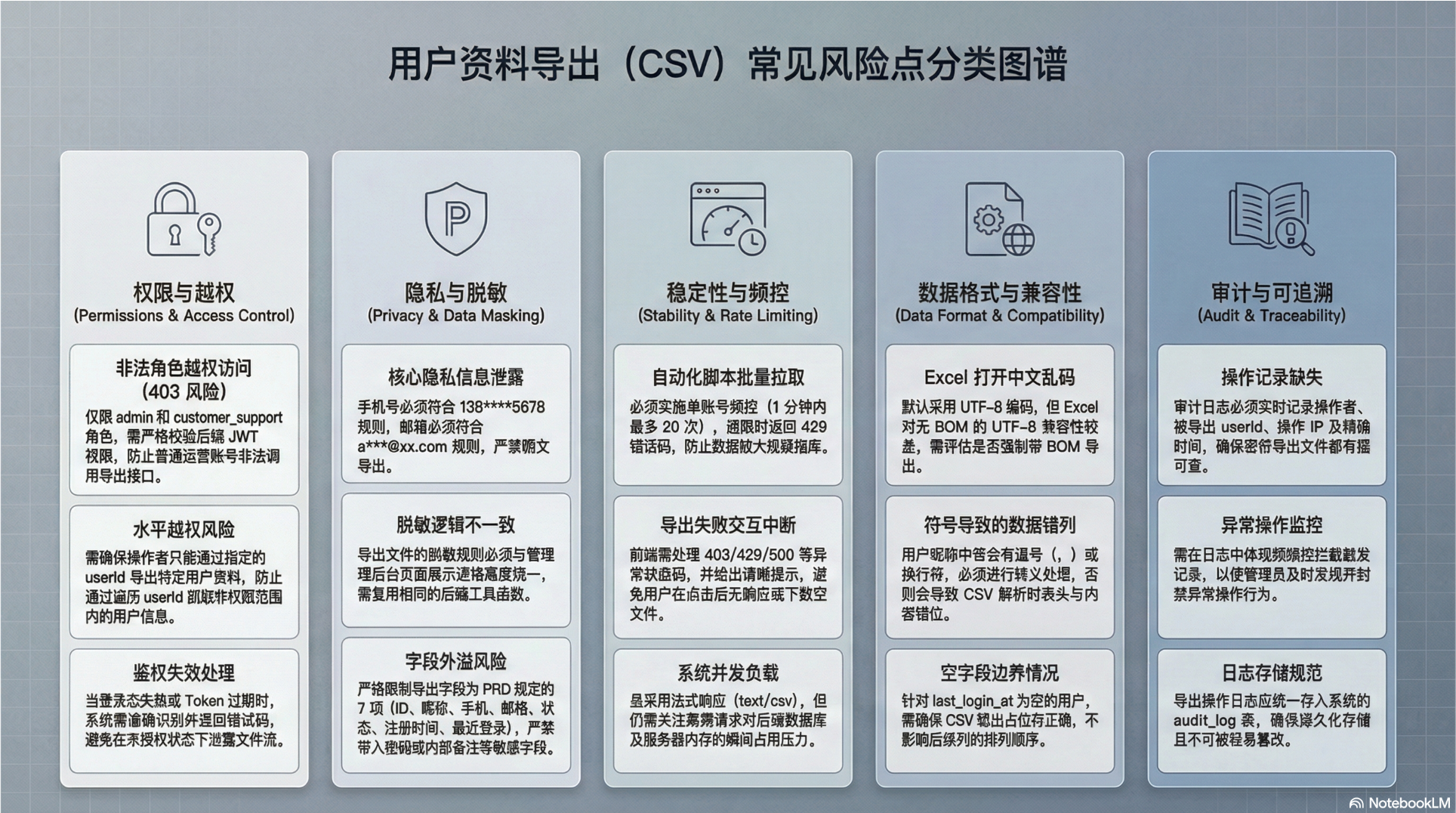
案例3:风险点全景图
备注:图片中如果字数内容太多,还是有乱码
方法:可以生成多张图片,内容分开,每一张上减少中文内容。
| 设置 | 选择 |
|---|---|
| 语言 | 中文(简体) |
| 屏幕方向 | 横向 |
| 详细程度 | 详细 |
| 描述 | 用户资料导出(CSV)常见风险点分类图谱。按类别分组(权限与越权、隐私与脱敏、稳定性与频控、数据格式与兼容性、审计与可追溯),每类给出3-5个风险点。使用学术风格的灰蓝配色。 |
案例4:实现模块地图
| 设置 | 选择 |
|---|---|
| 语言 | 中文(简体) |
| 屏幕方向 | 横向 |
| 详细程度 | 标准 |
| 描述 | 展示这个需求的实现模块地图(接口层、权限与审计、业务拼装、CSV生成与转义、脱敏工具函数、频控中间件、测试用例)。使用彩色圆圈表示不同模块,中心是“导出CSV”。 |
5.8 演示文稿

案例1:给新人开发的入门演示
| 设置 | 选择 |
|---|---|
| 格式 | 幻灯片 用幻灯片 |
| 语言 | 中文(简体) |
| 时长 | 短 |
| 描述 | 为第一次做该需求的新人介绍“用户资料导出(CSV)”的3个最核心点:权限与审计、脱敏与转义、频控与稳定性。每页只放一个要点+一个例子,语言通俗易懂,避免过多术语。风格轻松友好。 |
案例2:公司内部培训文档(详细版)
| 设置 | 选择 |
|---|---|
| 格式 | 详细演示文稿 |
| 语言 | 中文(简体) |
| 时长 | 默认 |
| 描述 | 为工程团队准备的“导出功能实现规范”培训材料。包含完整讲解文字,每个模块配有:定义→原理→本需求示例→常见坑→测试要点。适合通过邮件发送给团队成员自学。 |
案例3:跨团队对齐用的5页短演示
| 设置 | 选择 |
|---|---|
| 格式 | 幻灯片 用幻灯片 |
| 语言 | 中文(简体) |
| 时长 | 短 |
| 描述 | 5页短演示,主题“导出功能最容易翻车的5个坑”。每页一个要点,标题要有冲击力(如“一个未脱敏就可能是事故”),内容简短有力,用于跨团队对齐。目标受众:产品/测试/后端/安全。 |
案例4:复盘分享PPT
| 设置 | 选择 |
|---|---|
| 格式 | 幻灯片 用幻灯片 |
| 语言 | 中文(简体) |
| 时长 | 默认 |
| 描述 | 复盘分享用PPT,主题“用户资料导出(CSV)上线复盘”。结构:背景→需求口径→实现方案→踩坑与解决→验收与监控→可复用 checklist。风格稳重大气,每页要点尽量附来源或证据。 |
5.9 数据表格

案例1:上线检查清单表格
| 设置 | 输入 |
|---|---|
| 描述 | 创建“导出CSV上线检查清单”表格。列:检查项目、核心问题、判断标准、通过/不通过示例。行:按实现顺序排列(权限→审计→频控→脱敏→转义→测试→监控)。 |

案例2:风险点对照表
| 设置 | 输入 |
|---|---|
| 描述 | 整理“导出功能风险点对照表”。列:风险点、类别、触发条件、影响、检测方式、修复方案。按类别分组(权限、安全、稳定性、数据格式、可观测)。 |
案例3:多元思维模型学科汇总
| 设置 | 输入 |
|---|---|
| 描述 | 汇总“导出CSV需求涉及的模块/依赖”。列:模块名称、职责、关键函数/接口、依赖、测试点、常见坑。行:前端下载、后端接口、鉴权、审计、频控、脱敏工具、CSV生成。 |
案例4:验收口径分类表
| 设置 | 输入 |
|---|---|
| 语言 | 中文(简体) |
| 描述 | 整理“导出CSV”需求的验收口径与关键规则。列:规则原文、分类(权限/审计/频控/脱敏/转义/异常码)、一句话解释、适用场景。按分类排列。 |
六、不同人群怎么用?我整理了几个场景
场景1:自媒体内容创作者
痛点:每天要看大量资料,但能转化成内容的很少
用法:
-
把一个选题相关的所有资料扔进一个笔记本
-
让AI生成核心观点提炼
-
用对比功能找出不同资料的观点差异(这就是内容角度)
-
生成FAQ,每个问答就是一条潜在内容
实例: 我之前想把“导出CSV”这个小需求写成团队周报/分享,把 PRD+纪要+Issue 扔进去后,问AI:"这个需求最容易翻车的5个点是什么?每个点给出引用依据和规避建议"——直接得到一份可用的风险清单。
场景2:职场打工人
痛点:会议记录太多,文档太杂,找信息像大海捞针
用法:
-
把项目相关的所有文档(需求文档、会议记录、邮件往来)扔进一个笔记本
-
直接问:"关于XX功能,我们过去三个月做了哪些决策?"
-
用时间轴功能梳理项目进展
-
新人入职?直接让TA问笔记本,减少打扰老员工的频率
实例: 一个做产品的朋友跟我说,他把竞品分析报告全扔进去,然后问"竞品解决了哪些我们目前产品没解决的痛点"——省了他好几个小时的对比阅读时间。
场景3:时间碎片化人群
痛点:想学习但没整块时间,只能利用碎片时间
用法:
-
把想学的课程资料(PDF、视频字幕、讲义)扔进去
-
生成Audio Overview
-
做家务、通勤、遛娃的时候听
-
听到感兴趣的点,回来再用文字对话深挖
实例: 我会把 PRD/纪要/Issue 生成一份 Audio Overview,当“通勤播客”听。听到某个点(比如频控/审计/脱敏)有疑问,回到笔记本里点引用再深挖,实现上手更快。
场景4:工程师/新人接手
痛点:资料太多,需求口径散,容易漏边界、漏风险
用法:
-
把 PRD、会议纪要、Issue/PR 全扔进去
-
生成 Study Guide(学习指南)做任务拆解
-
让它出“验收/边界条件”小测验自测
-
问“最容易遗漏的3个实现细节是什么(带引用)”
实例: 我把三份材料扔进去后,问"哪些验收点在 PRD/纪要/Issue 中被重复强调?"——直接得到“必须做”的高优先级清单。
七、进阶玩法:从社群扒来的骚操作
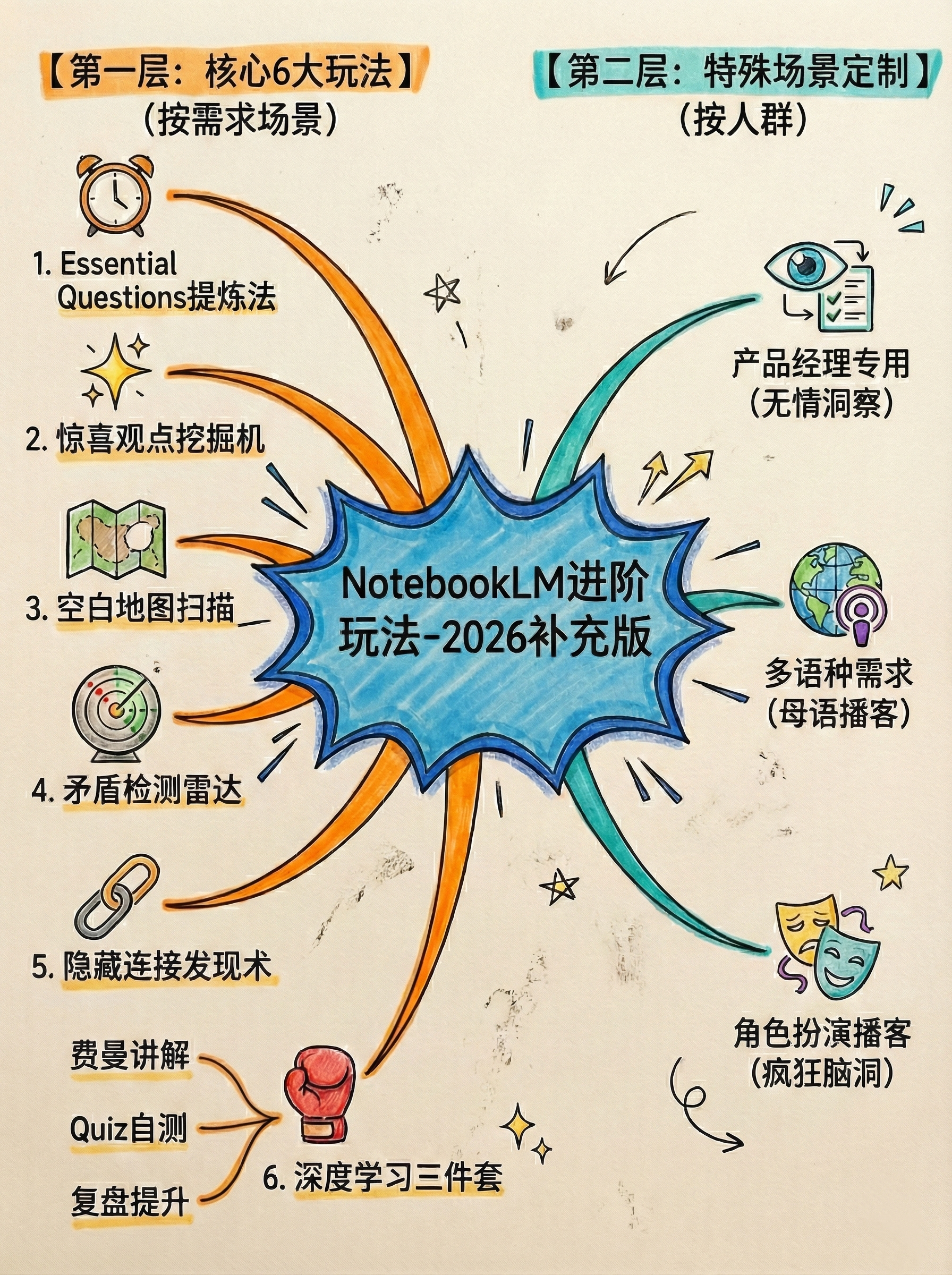
这些是我从Reddit、Twitter、各种AI社群里扒来的高级技巧,官方文档里不一定有。
我把它们分成两类:核心6大玩法(按需求场景分)和特殊场景定制(按人群分)。
【第一层:核心6大玩法】按需求场景选
玩法1:5分钟吃透难点——(核心问题/实质性问题)提炼法
适用场景: 面对一堆复杂资料,想快速抓住核心
社群来源: 这招来自一个医学生的分享,他用这个方法把500页教材浓缩成5个问题。
提示词模板:
分析我上传的所有资料,找出理解这个主题必须回答的5个核心问题。 这些问题应该: 1. 覆盖主要概念和定义 2. 抓住反复强调的关键点 3. 揭示概念之间的关系 4. 连接到实际应用场景 注意:不要总结内容,只给我5个问题。
实战案例(工程师版):
-
上传:PRD + 会议纪要 + Issue/PR
-
输出:5个核心问题,例如:
-
“导出接口的权限边界是什么?哪些角色允许导出?”
-
“CSV需要哪些转义/编码规则,Excel打开是否会错列/乱码?”
-
“为什么必须审计?审计日志包含哪些字段?”
-
“频控策略怎么定?超限时前端/后端怎么表现?”
-
“验收 checklist 的Top 10是什么?”
-
-
为什么有用: 记住5个问题比记住50行需求描述更容易,而且能迅速暴露理解盲区
玩法2:找爆款角度——惊喜观点挖掘机
适用场景: 内容创作者找选题、考证党找记忆点
社群来源: 一个YouTuber分享的"钩子挖掘法",专门找那些"原来如此!"的惊喜点。
提示词模板:
我在研究[主题X]。 从所有上传的资料中,找出最令人惊讶、意外、或特别有趣的观点/事实。 对每个观点: 1. 说明为什么它令人惊讶 2. 直接引用原文作为证据(带页码/出处) 重点关注[具体方向],避免强调[其他方面]。
实战案例:
-
工程师: "挖掘这个需求里10个最容易漏的边界条件(必须引用原文)"
-
测试: "找出最容易回归漏测的5条用例,并给出期望结果(403/429/文件名/字段顺序等)"
为什么有用: 惊喜点=记忆点=爆款钩子
玩法3:发现竞品盲区——空白地图扫描
适用场景: 做课程设计、写差异化内容、找研究方向
社群来源: 结合了你原有的"研究空白发现"+文章的"Source Gap"提示词
提示词模板:
审查所有上传的文档,告诉我"什么东西缺失了",而不是"已经有什么"。 基于2026年[行业X]的标准,我想知道: 1. 哪些关键数据/观点应该存在但没有出现 2. 哪些地方做了假设但缺乏证据支撑 3. 哪些观点之间存在矛盾(用原文引用对比) 4. 给我5个深度研究问题,用来填补这些空白 不要泛泛而谈,所有矛盾必须基于直接引用。
实战案例:
-
课程设计: "市面上的...课程都讲了什么?我的课程能填补什么空白?"
-
内容创作: "竞品账号都在讲什么角度?我能抢占什么未被占领的山头?"
玩法4:找到真相——矛盾检测雷达
适用场景: 面对多个来源的信息,想知道到底该信谁
社群来源: 原版+补充:矛盾(Contradictions)提示词强化版
提示词模板:
对比所有上传的关于[主题X]的文档,找出最大的矛盾或冲突观点。 对每个矛盾: 1. 引用双方的具体说法(带出处) 2. 分析为什么会有分歧(方法差异?样本不同?时间不同?) 3. 告诉我需要什么证据才能解决这个矛盾 不要总结,只关注会改变结论的重大冲突。
实战案例:
-
考证党: "教材说A,辅导书说B,历年真题考C——到底该信谁?"
-
内容创作者: 观点冲突就是选题宝藏:"XX领域的两大流派到底谁对?"
玩法5:跨界创新——隐藏连接发现术
适用场景: 想做原创内容、跨界组合、新角度分析
社群来源: 原版+补充:内在联系(Hidden Connections)提示词
提示词模板:
探索并综合[主题A]和[主题B]之间的联系(即使这个联系很抽象)。 对每个相关的资料: 1. 引用与任一主题相关的关键证据 2. 将它与其他资料中的信息建立联系 3. 指出任何冲突或矛盾的观点 4. 强调有趣或意外的组合 最后给我一个清晰的总结:这两个主题如何连接。 所有观点必须基于原文引用。如果资料不支持连接,请明确指出。
实战案例:
-
跨模块连接: "把 PRD 里的验收口径和 Issue 里的实现任务一一对应,看看哪里缺了/多了"
-
创新角度: "把‘导出CSV’当成一个安全/合规问题来分析:哪些点如果没做会直接变事故?"
玩法6:深度学习三件套——互动强化组合拳
适用场景: 想彻底学透一个知识点,而不是浅尝辄止
社群来源: 整合了原版的"费曼技巧+角色扮演播客"+补充:Quiz和Self-Improvement
【套装A:费曼小白化讲解】
把上传的内容解释给一个好奇的初中生听。 用简单语言、短句子,不预设任何背景知识。 每个回答按这个结构: - TL;DR:一句话总结(超级简单的词汇) - 类比:一个现实世界的例子或比喻 - 词汇表:3个难词,用大白话解释 如果某段太技术化,把它变成True/False小测验。
【套装B:Quiz(测验)自测题库生成】
基于上传的资料,创建一个互动讨论。 格式选择:Quiz模式 - 两个主持人 - 一个主持人出题,另一个回答 - 10道题(选择题+判断题混合) - 回答者会故意答错几道 - 纠错时必须引用原文解释 - 最后公布分数 所有题目和答案必须基于上传的资料,不要自己编。
【套装C:Self-Improvement(自我提升)复盘提升】
我尝试了某件事,但没成功。请对比我的做法和上传资料中的方法。 详情: - 项目:[我尝试的事] - 我的方法:[我的步骤] - 结果:[实际发生了什么] - 预期:[我以为会发生什么] 现在交叉对比资料,找出: 1. 我没遵循的方法或步骤(直接引用原文) 2. 我完全错过的重要概念 3. 我跳过的前提条件或基础 输出格式: "在[概念X]上的差距: 你漏掉了[步骤], 但[资料名称,第X页]指出: '[原文引用]'" 重点是学习,不是指责。所有差距必须有原文证据。
实战案例(工程师专用三步走):
-
第一步: 用费曼法把需求讲给“第一次做该需求的新人”听(尽量少术语)
-
第二步: 生成10道“边界条件/异常码/权限”题自测,看看哪里还没懂
-
第三步: 把做错的题丢给Self-Improvement,让它基于引用指出你漏掉的口径
【第二层:特殊场景定制】按人群需求选
玩法7:产品经理专用——无情洞察提取机
适用场景: 面对一堆竞品分析、用户访谈、市场报告,需要快速提炼"能做什么"而不是"说了什么"
社群来源: 灵感来自硅谷某产品总监在Twitter的分享。他说传统AI助手的问题是"太客气、太啰嗦、总想展示自己懂很多",而产品经理需要的是像手术刀一样精准的信息提取——直接告诉我哪里有机会、哪里有坑、哪里有盲区。
你现在是一位准备向CEO汇报的首席产品经理。 审查上传的所有文档,为决策准备一份备忘录。 忽略废话和评论,只关注影响实际决策的洞察。 用子弹点总结你的发现,分为以下几个部分: 【一、用户证据】 - 直接引用能揭示真实用户问题、需求或痛点的内容 - 不要总结"用户想要什么",给我原话 - 标注出处(文档名+具体位置) 【二、可行性检查】 - 技术限制:资料中提到的技术、操作或资源约束 - 成本限制:提到的预算、时间、人力约束 - 政策限制:法规、合规、流程约束 【三、盲点识别】 - 重要信息缺失:应该有但没有的数据 - 未考虑的因素:被忽略的关键问题 - 假设漏洞:哪些结论基于未验证的假设 【四、风险预警】(新增!) - 资料中暗示但未明说的风险 - 不同来源之间的矛盾点 - 可能的失败模式 如果我的问题或目标不清晰,先暂停,问我澄清问题, 不要自己假设或得出结论。
与其他提示词组合使用
组合1:盲点识别 +玩法3:发现竞品盲区——空白地图扫描
-
先用"产品经理提示词"找到缺失信息
-
再用"Source Gap提示词"深挖为什么会缺失
组合2:用户证据 + 玩法2:找爆款角度——惊喜观点挖掘机
-
先用"产品经理提示词"提取用户痛点
-
再用"惊喜观点挖掘"找出其中反常识的洞察
组合3:可行性检查 + 玩法4:找到真相——矛盾检测雷达
-
先提取限制条件
-
再看不同来源对限制条件的矛盾说法
完整版本:产品经理的提示词组合拳
玩法8:多语种需求——母语播客生成
适用场景: 想用方言/外语学习,或做区域化内容
社群来源: 补充多语言播客(Multilingual Podcast)提示词
提示词模板:
基于上传的资料,创建一个深度讨论,完全用[目标语言]进行。 全程只用[目标语言]。除非某个技术术语无法翻译,否则不要使用英语。 保持自然对话的语气,就像真实的播客或口头解释。
实战案例:
-
把英文AI论文变成中文播客
-
把 PRD/会议纪要变成粤语播客(通勤时听)
大家一起来听听看,这个粤语标准吗?可以在评论区留下观点哦。
目前的遗憾是:还无法做到全程粤语输出,后面再看看有没有优化的办法。
此内容暂时无法在飞书文档外展示。
玩法9:角色扮演播客——疯狂脑洞版
补充:Audio Overview的角色扮演玩法远不止官方展示的那些。
社群里有人试过:
-
"你们是两个1920年代的学者,刚发现了这份来自未来的文档"
-
"一个人是该理论的狂热粉丝,另一个是极度悲观的批评者"
-
"模拟安全同学/测试同学问开发的场景"
甚至有人试过让主持人"中途摔下楼梯带着痛苦继续主持"——纯属搞笑,但说明这个功能的可塑性很强。
严肃应用(工程师版):
-
"模拟上线评审:评审人刁难 vs 开发应对(必须引用资料)"
-
"两个人辩论:导出接口是否必须强制频控/审计/加BOM?"
八、必须说清楚的局限性
工具再好也有边界,用之前要清楚这些:
局限1:不联网
NotebookLM不会实时搜索网络。它只知道你喂给它的内容,加上它本身预训练的知识。
你问它今天的股价、昨天的新闻,它是不知道的——除非你把相关资料上传进去。
局限2:图片识别一般
虽然能处理PDF,但对图表、图片里的信息提取能力不算强。它本质上还是一个文字处理工具。
如果你的资料里有大量图表,别指望它能完美解读。
局限3:引用不是100%完美
虽然它很努力在"不瞎编",但当你上传的多个文件之间有矛盾时,它偶尔也会困惑。
最佳实践是:重要结论一定要点击引用,回到原文核实。
局限4:50个来源上限
一个笔记本最多50个来源。对于小项目够用,对于大型研究可能要想办法合并文件。
局限5:免费版有使用限制
目前个人用户免费,但企业/教育账户可能需要管理员开权限。另外18岁以下用户有访问限制。
九、关于隐私:能不能放敏感资料?
这是很多人关心的问题。
官方说法:
-
个人账户上传的数据不会用于训练模型(除非你主动点赞/点踩反馈)
-
企业版数据严格隔离,谷歌员工也看不到
我的建议:
-
公开资料、学习资料:放心用
-
公司内部文档:如果公司允许,可以用企业版
-
极其敏感的个人信息(身份证号、银行卡等):上传前脱敏处理
我自己的原则是:不传任何我不愿意被泄露的东西。虽然官方说不会泄露,但任何云端服务都有理论上的风险。
十、我的NotebookLM工作流总结
懿轩个人的一套使用习惯:
第一步:明确目的
在创建笔记本之前,先想清楚这个笔记本要解决什么问题。
是“快速把小需求落地并可验收”?还是“把零散资料整理成任务与风险清单”?还是“分析竞品策略”?
目的不同,资料选择和提问策略也不同。
第二步:资料预处理
-
能合并的文件先合并
-
无关的内容先删掉(比如书的前言、广告页)
-
格式统一(最好都是PDF或纯文本)
垃圾进,垃圾出。输入质量决定输出质量。
第三步:先全局后局部
上传完先生成一份Summary或Briefing Doc,确认方向对了。
然后再开始问具体问题。
第四步:善用勾选筛选
不要总是让AI看所有资料。当你想做局部分析时,只勾选相关的几个文件。
这样AI的回答会更聚焦,也更准确。
第五步:保存有价值的笔记
对话过程中产生的有价值洞察,随时保存为笔记。
这些笔记可以继续参与后续对话,形成知识的累积。
第六步:音频转化碎片学习
学完之后,生成一份Audio Overview。
这样你的"系统学习"就变成了"可随时复习的音频资料",碎片时间都能用上。
NotebookLM 给我最大的启发是:与其把时间花在“怎么写出更好的 Prompt 让 AI 帮我写文章”,不如回到根上想——“怎么整理更好的数据源,让 AI 帮我一起思考”。
说到底,输入决定输出;你给的数据质量,决定了它能给到你的洞察质量。 你喂给 AI 什么,它就会用同样的材料回馈你什么。
这篇笔记就是我这周折腾 NotebookLM 的完整记录:从怎么整理资料、怎么提问,到怎么把它落到日常工作流里。 希望能帮你少走点弯路、少踩点坑。
如果你也在用这个工具,欢迎留言交流你都怎么玩、有什么更高效的用法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)