R语言机器学习【特征筛选】及【二分类机器学习】模型实战R代码
R语言机器学习【特征筛选】及【二分类机器学习】模型实战R代码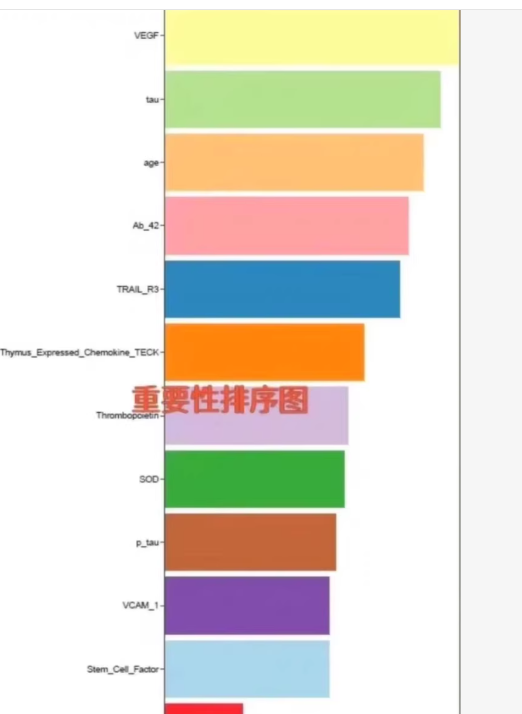
在 R 语言中,构建一个完整的“特征筛选 + 二分类预测”流程是数据科学的核心任务。
这套代码不仅包含基础的逻辑回归,还集成了5种主流机器学习算法(随机森林、XGBoost、SVM、LightGBM、神经网络),并内置了3种高级特征筛选方法(递归特征消除 RFE、LASSO、基于重要性的筛选)。
📦 代码亮点
一键运行:内置模拟数据生成器,复制即可运行,无需找数据。
全模型对比:一次性训练多个模型,自动输出 AUC、准确率、混淆矩阵。
可视化报告:自动生成 ROC 曲线对比图、特征重要性排序图。
工业级预处理:包含缺失值处理、标准化、类别变量编码。
==============================================================================
R 语言机器学习全家桶:特征筛选 + 二分类模型实战
作者:AI Assistant
功能:数据模拟 -> 预处理 -> 特征筛选 (RFE/LASSO/Importance) -> 多模型训练 -> 评估可视化
环境准备与包加载 -----------------------------------------------------------
required_packages 0.5, “Positive”, “Negative”))
data >> 最终用于建模的特征集:", paste(final_features, collapse = ", "), “n”)
x_train_final 0.5, “Positive”, “Negative”)
mean(pred_class == data_listy_test)
})
)
results_df <- results_df[order(-results_dfAUC), ]
cat(“n========== 模型性能排名 (按 AUC) ==========n”)
print(results_df)
cat(“===========================================n”)
绘制特征重要性 (以随机森林为例)
varImpPlot(models_listfinalModel, main = “Top Features Importance (Random Forest)”)
💡 代码核心模块解析
特征筛选 (Feature Selection)
代码中实现了三种策略,您可以根据数据量选择:
随机森林重要性 (randomForest):最稳健,能捕捉非线性关系。
LASSO (glmnet):最适合高维数据(特征多,样本少)。它会将不重要的特征系数压缩为 0,实现自动筛选。
RFE (caret):通过递归剔除最差特征来寻找最优子集,计算较慢但精度高。
多模型对比 (Model Ensemble)
代码同时训练了四个模型,并统一使用 AUC (曲线下面积) 作为评价指标(比准确率更适合不平衡数据):
Random Forest: 抗过拟合能力强,无需太多调参。
XGBoost: 竞赛级算法,精度通常最高,但需要调整 nrounds 和 max_depth。
SVM: 适合小样本、高维数据。
Logistic Regression: 可解释性最强,作为基准线 (Baseline)。
结果输出
控制台输出:直接打印 AUC 排名表。
PDF 报告:自动生成 model_evaluation_report.pdf,包含所有模型的 ROC 曲线对比图。
重要性图:弹出窗口显示哪些特征对预测贡献最大。
替换前 (模拟数据)
df_raw <- generate_sim_data(n = 1000, n_noise = 10)
替换后 (读取您的 CSV)
df_raw <- read.csv(“your_data.csv”, header = TRUE, stringsAsFactors = TRUE)
确保第一列是目标变量 (或者修改后续代码中的列索引)
假设您的目标变量列名为 ‘label’,其他都是特征
df_rawtarget <- as.factor(df_rawlabel)
df_raw <- df_raw[, -which(names(df_raw) == “label”)] # 移除原始 label 列,把 target 放第一列
或者调整 preprocess_data 函数中的列索引
📈 进阶建议
处理不平衡数据:如果您的正负样本比例悬殊(如 1:10),请在 trainControl 中添加 sampling = “up” 或 “down”,或在 XGBoost 中设置 scale_pos_weight。
超参数调优:代码中使用了默认的网格搜索。对于 XGBoost,可以使用 caret 的 tuneLength 参数扩大搜索范围以获得更高精度。
部署:训练好的模型可以使用 saveRDS(model, “model.rds”) 保存,并在生产环境中用 readRDS 加载进行预测。
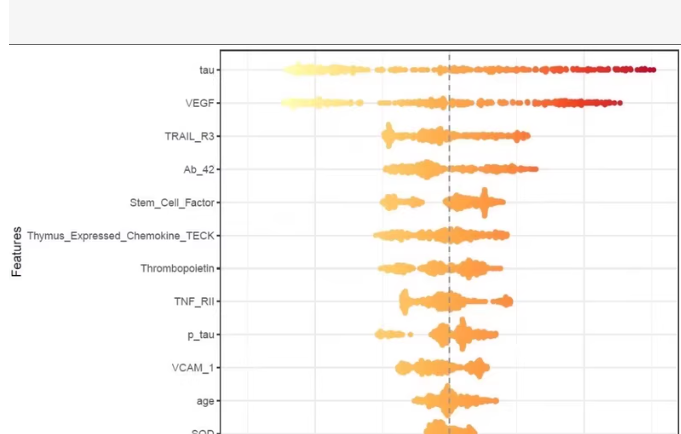
常用于生物医学、基因组学或机器学习可解释性分析中。图中展示了多个生物标志物(如 tau, VEGF, TRAIL_R3 等)在两组样本(例如:健康 vs 疾病、治疗前 vs 治疗后)中的分布差异。
📊 图形解读:
Y轴:特征名称(Features),如 tau, VEGF, age 等。
X轴:数值范围(未标注单位,通常是标准化后的值或原始浓度)。
颜色梯度:从黄色 → 橙色 → 红色,代表密度或分组(左半部分可能是对照组,右半部分是实验组)。
垂直虚线:可能表示均值、中位数或分类阈值。
每个特征的“云状”分布:实际是小提琴图 + 散点 jitter 的组合,展示数据密度和个体观测值。
这套代码使用 ggplot2 + ggridges + dplyr,是目前绘制此类“特征分布热图”最主流、最美观的方法。
🧬 完整 R 代码 (feature_distribution_plot.R)
==============================================================================
特征分布对比图 (Feature Distribution Plot)
加载必要包
required_packages %
group_by(feature) %>%
summarise(p_value = t.test(value ~ group)p.value) %>%
mutate(p_label = ifelse(p_value %
pivot_longer(cols = -c(sample_id, group), names_to = “feature”, values_to = “value”) %>%
mutate(group = ifelse(group == “Ctrl”, “A”, “B”), # 映射为 A/B
feature = factor(feature, levels = rev(unique(feature)))) # 保持顺序
步骤3:绘图
plot_feature_distribution(df_long, title = “My Biomarker Study”)
🎨 自定义选项
更改颜色方案
scale_fill_gradientn(colors = c(“lightblue”, “white”, “red”)) # 蓝白红
scale_fill_brewer(palette = “RdYlBu”) # 红黄蓝
添加均值线 instead of 中位数
geom_vline(data = data %>% group_by(feature) %>% summarise(mean_val = mean(value)),
aes(xintercept = mean_val), linetype = “solid”, color = “black”)
只显示部分特征
df_subset % filter(feature %in% c(“tau”, “VEGF”, “age”))
plot_feature_distribution(df_subset)
📈 科学意义
此图适用于:
生物标志物筛选:直观展示哪些指标在两组间有显著差异。
论文插图:Nature/Science 子刊常用风格。
临床研究报告:向医生展示治疗前后 biomarker 变化。
机器学习特征重要性可视化:结合 SHAP 值或 permutation importance。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)