【C++入门指南(上篇)】内含命名空间、缺省参数、函数重载、内联函数等超详细讲解!
C++入门指南(上篇)
嗨,未来的程序员!欢迎来到C++的世界——一个充满力量与创造力的地方。如果你是编程新手,或者刚刚开始学习C++,这篇文章将带你揭开C++的“神秘面纱”。话不多说,我们发车啦!
文章目录
1. C++的第一个程序:Hello world!
下面是一个最简单的C++程序:
#include<iostream>
using namespace std;
int main()
{
cout << "Hello world!" << endl;
return 0;
}
你可能看不懂 namespace std,cout 等,不要担心,下面我们将会详细讲解!
2. 命名空间: 防止“撞名”的身份证
假如你所在的班级有两个“张三”。老师一喊“张三”,俩人同时答应,场面混乱。怎么办?加个限定,比如“高的张三”和“矮的张三”。在C++里,这种“限定”就叫命名空间。
2.1 为什么要有命名空间?
因为C++的库、你写的代码、同事写的代码里,可能会有相同名字的函数或变量(比如大家都想用print做函数名)。命名空间就像“姓氏”,把不同来源的代码隔开,避免冲突。
注意看下面这段代码:
#include<stdio.h>
#include<stdlib.h>
int rand = 10;
int main()
{
printf("%d\n", rand);
return 0;
}
猜猜看这段代码运行会不会报错
答案是:会!!因为rand以前的定义是函数,这里打印就犯了重定义的错误!
那么我们要如何解决这个问题呢?这就要请出namespace了
2.2 namespace 的定义
- 定义命名空间使用关键字 namespace,后跟命名空间的名字,然后是一对大括号 { }(注意大括号外没有分号!),里面可以包含变量、函数、类、结构体、甚至另一个命名空间。
namespace本质是定义出一个域,这个域跟全局域各自独立,不同的域可以定义同名变量。- 命名空间只能在全局作用域或其他命名空间内定义,不能在函数内定义。
- 项目工程中多文件中定义的同名namespace会认为是一个
namespace,不会冲突.- C++标准库都放在一个叫std(standard) 的命名空间中。
现在就可以重新写一下上面的代码了:
#include<stdio.h>
#include<stdlib.h>
namespace hj
{
int rand = 10;
}
int main()
{
printf("%p\n", rand);//这里打印出来的是地址,默认访问的
//是全局的rand函数指针
printf("%d\n", hj::rand);//这里是 hj命名空间中的rand
return 0;
}
输出: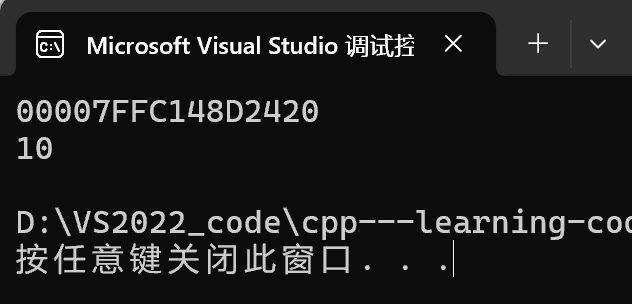
敲黑板: 这里使用的 :: 是域作用限定符,符号左边可以写域的名字,如果什么都不写默认去全局域查找,右边写需要查找的内容
命名空间还可以嵌套:
namespace hj
{
namespace zr
{
int rand = 20;
int Add(int left, int right)
{
return left + right;
}
}
namespace zj
{
int rand = 30;
int Sub(int left, int right)
{
return left - right;
}
}
}
int main()
{
printf("%d\n", hj::zr::rand);
printf("%d\n", hj::zj::rand);
printf("%d\n", hj::zr::Add(2,1));
printf("%d\n", hj::zj::Sub(2,1));
return 0;
}
输出: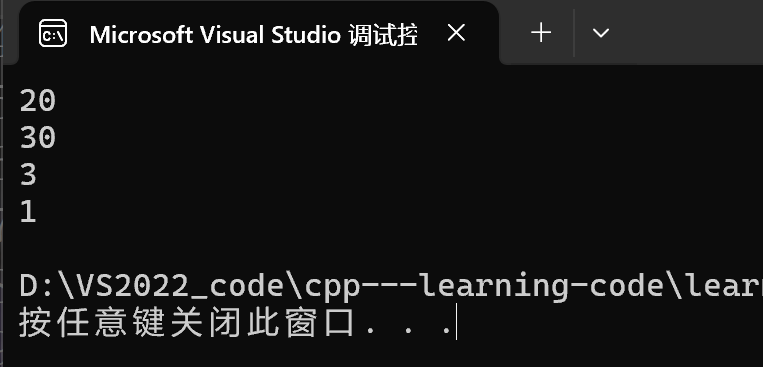
2.3 命名空间的使用
定义好命名空间后,如何访问里面的成员呢?有三种主要方式:
- 作用域限定符 ::
最直接的方式就是使用 ::(作用域解析运算符)来指定成员所属的命名空间。
- using 声明
using 声明 可以将命名空间中的某个特定成员引入当前作用域,之后就可以直接使用该成员的名字。
- using 指令
using 指令 会将整个命名空间中的所有成员都引入当前作用域,之后就可以直接使用该命名空间内的任何成员。
举个例子:
namespace hj
{
int a = 1;
int b = 2;
}
int main()
{
//指定命名空间访问
printf("%d\n", hj::a);
return 0;
}
//using 将命名空间中的某个成员引入当前作用域
using hj::b;
int main()
{
printf("%d\n", hj::a);
printf("%d\n", b);
}
//using 将整个命名空间中的所有成员都引入当前作用域
using namespace hj;
int main()
{
printf("%d\n", a);
printf("%d\n", b);
}
重要提示: 在实际开发中,尤其是在头文件中,绝对不要使用 using namespace std; 或其他 using 指令,因为头文件会被多个源文件包含,可能导致意想不到的命名冲突。通常只在 .cpp 文件的函数内部或实现文件中局部使用 using 指令。
3. C++输入&输出
3.1 C++ 的 I/O 库主要包含几个头文件:
<iostream>:标准输入输出(cin、cout、cerr、clog)<fstream>:文件输入输出(ifstream、ofstream、fstream)<sstream>:字符串流(istringstream、ostringstream、stringstream)<iomanip>:格式化 I/O 的操纵符(setw、setprecision 等)
3.2 标准输入输出
cout是C++ 最常用的输出对象,它把数据发送到标准输出设备(通常是屏幕)。配合左移运算符 <<,你可以输出各种类型的数据,<< 还可以连续使用。endl 与 \n
std::endl 不仅换行,还会刷新输出缓冲区(强制把数据立即输出)。如果只是换行而不需要立即刷新,可以使用转义字符 \n。cin是标准输入对象,通常从键盘读取数据。使用右移运算符 >> 提取数据,可以一次输入多个变量,用空格或回车分隔。cout/cin/endl等都属于C++标准库,C++标准库都放在一个叫std(standard)的命名空间中,所以要通过命名空间的使用方式去用他们。
敲黑板:
cin >>读取字符串时,遇到空白字符(空格、制表符、换行)就会停止。比如输入 “Hello World”,cin >> s 只会得到 “Hello”。- C++的输入输出可以自动识别变量类型,它会根据变量的类型自动选择输出格式(这样写起来会比C语言爽的多!)
- 一般日常练习中我们可以
using namespace std,实际项目开发中不建议使用using namespace std
上代码看看:
#include <iostream>
using namespace std;
int main()
{
int a = 1;
double b = 1.1;
char c = 'X';
//这两种输出写法效果相同
cout << a << " " << b << " " << c << endl;
std:: cout << a << " " << b << " " << c << endl;
cin >> a >> b >> c;//输入数据
cout << a << " " << b << " " << c << endl;
return 0;
}
效果: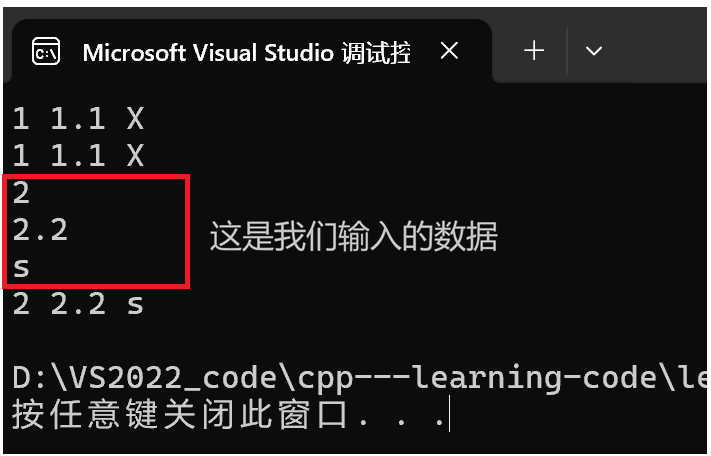
小知识:
在io需求比较高的地方,比如竞赛题中,加上以下3行代码,可以提高C++IO的效率
#include <iostream>
using namespace std;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
return 0;
}
4. 缺省参数
- 缺省参数就是在函数声明或定义时,为形参指定一个默认值。这样,在调用函数时,如果省略了该参数,编译器就会自动用默认值代替;如果提供了实参,则用实参覆盖默认值。
- 全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值。这条规则一定要牢记!一旦某个参数有了默认值,它右边的所有参数都必须有默认值。也就是说,默认参数只能放在参数列表的末尾。
- 带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参。
- 在 C++ 中,函数的声明和定义可以分开。缺省参数通常只放在声明中,不要在定义中重复
那么我们要如何定义缺省参数呢?上代码!
#include<iostream>
using namespace std;
//全缺省
void Func1(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
//半缺省
void Func2(int a, int b = 10, int c = 20)//这里必须从右往左依次连续缺省
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
Func1();//不传参数的话会使用默认值
Func1(1);//要从左到右依次给实参,这里的1给的是a,
//b和c还是使用的默认值
Func1(1, 2, 3);
//这里还要注意一下,给半缺省传参时至少要传一个值
Func2(4, 5, 6);
}
效果: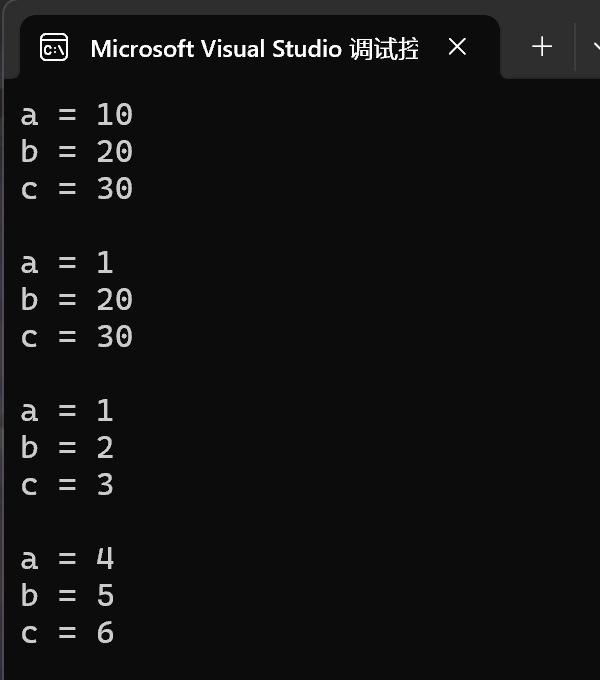
使用缺省参数有什么好处呢?
- 1. 简化调用: 当某个参数在大多数情况下都是同一个值时,就不必每次重复写它。
- 2.扩展功能: 可以在不修改已有调用代码的情况下,给函数增加新的参数。只要新参数有默认值,所有旧代码依然能正常工作(因为它们省略了新参数,自动取默认值)。
5. 函数重载
日常生活中,同一个词往往有不同的含义,比如“打”字:可以“打篮球”、“打电话”、“打酱油”……虽然都是“打”,但具体动作完全不同。听的人会根据上下文(后面的词语)自动理解。C++ 中的函数重载就借鉴了这种思想——允许你定义多个同名函数,只要它们的参数列表不同,编译器就会根据调用时传入的参数类型和个数,自动选择合适的版本执行。
函数重载是指在同一个作用域内,可以定义多个同名函数,但它们的参数列表必须不同(参数的个数、类型或顺序不同)。这样,我们就可以用同一个名字表示功能相似但实现细节不同的操作,提高代码的可读性和可维护性。
举几个例子:
#include<iostream>
using namespace std;
//1.参数类型不同
int Add(int left, int right)//整型
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)//浮点型
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
int main()
{
Add(1, 2);
Add(1.1, 2.2);
return 0;
}
效果: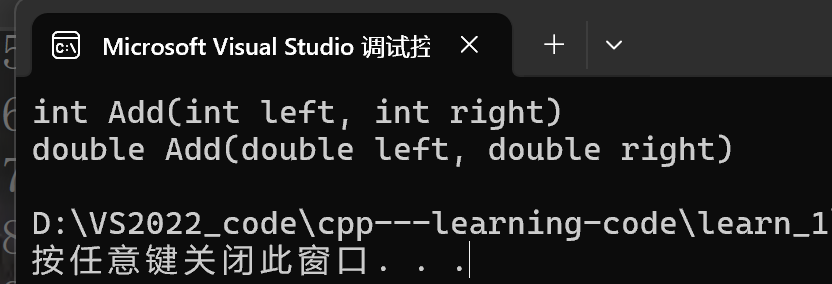
//2.参数个数不同
#include<iostream>
using namespace std;
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(a)" << endl;
}
int main()
{
f();
f(1);
}
效果: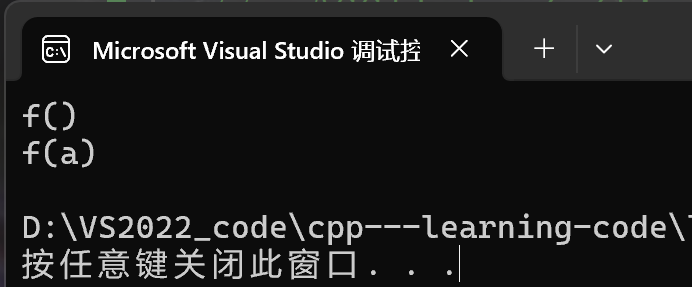
//3.参数类型顺序不同
#include<iostream>
using namespace std;
void f(int a, char b)
{
cout << "void f(int a, char b)" << endl;
}
void f(char b, int a)
{
cout << "void f(char b, int a)" << endl;
}
int main()
{
f(1, 'a');
f('a', 1);
}
效果: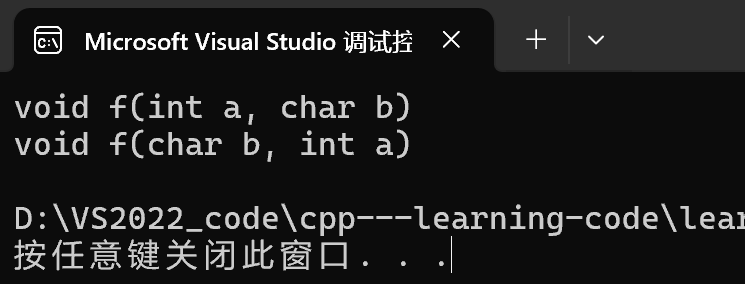
还要注意 返回值类型不同不能作为重载依据! 因为调用时无法区分!
#include<iostream>
using namespace std;
void f()
{
//...
}
int f()
{
//...
return 0;
}
如果两个同名函数一个参数部分有默认值,另一个没有,编译时也会报错!
#include<iostream>
using namespace std;
//存在歧义,编译器不知道调用谁
void f1()
{
cout << "f1()" << endl;
}
void f1(int a = 1)
{
cout << "f1(int a)" << endl;
}
结语
现在,你已经解锁了 命名空间、输入输出、缺省参数、函数重载、这些“核心技能”,从此写 C++ 不再是天书!
当然,前方还有 类、继承、模板、 STL 等“高级副本”等着你,但别慌——你已经掌握了最硬核的入门装备。
代码无bug,学习不迷路,我们下篇再见!(•̀ᴗ•́)و

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)