spec coding 实践(spec-kit)
一:AI Coding 的范式演化
时间线是最诚实的叙事结构。
- 2023 年:GitHub Copilot,这是 AI Coding 真正进入工程师日常工作流的起点。彼时的用法极其简单:你在 IDE 里敲代码,AI 在光标后面补全。工程师把它当一个「聪明的自动补全」,没有人认真思考它会改变编程范式。
- 2024 年:模型能力的跳跃让情况发生了质变。Claude 3.5 Sonnet、GPT-4o 的发布,使得 AI 可以处理完整功能模块的生成,而不仅仅是片段补全。Cursor、Windsurf 等 AI-native IDE 的出现,让「对话式编程」成为可能。工程师开始尝试用自然语言描述需求,让 AI 生成整个文件甚至整个模块。这个阶段的特征是:工程师仍然是主控方,AI 是一个响应式的执行工具。
- 2025 年:边界被进一步打破。Anthropic 发布 Claude 3.7 Sonnet,其扩展思考(Extended Thinking)能力显著提升了复杂任务的推理深度。与此同时,一个新的概念开始在工程师社区广泛传播——Vibe Coding。
Andrej Karpathy,2025年2月6日**:“There’s a new kind of coding I call ‘vibe coding’, where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. I ask for the diffs, I accept all of them, I don’t read them.”
Karpathy 用「Vibe」这个词精准描述了一种状态:工程师不再逐行审查代码,而是凭直觉和感受驱动 AI 完成任务。你描述你「想要什么感觉」,AI 给出代码,你运行,看效果,不满意就继续对话调整。
这个概念之所以迅速引发共鸣,是因为它说出了很多工程师已经在做但没有命名的事情。
二:我们在用Vibe Coding 写代码时遇到了什么问题?
-
问题一:上下文衰减
即便 Claude 3.7 、GLM支持 200K tokens,当项目代码库超过一定规模,AI 对早期决策的记忆会出现漂移。
典型案例:一个需要 迭代 1 周的项目,我在第 1 天定义的数据库 Schema 命名规范,但是到第 4天AI 开始生成的字段名字居然错了。 -
问题二:意图模糊的级联放大
自然语言本质上有歧义。说「做一个用户登录功能」,AI 需要推断:JWT 还是 Session?要不要验证码?多设备策略?
单次推断可能恰好对了。但经过 10 次对话迭代,每次细微偏差累积,最终结果会偏离原始意图。 -
问题三:可验证性缺失
Vibe Coding 里,质量判断的标准是「感觉对不对」。但软件工程的质量需要是可验证的——单测覆盖率、接口契约、边界条件处理。
当你接受 AI 生成的代码但没有读过它,你就无法有效地为它写测试。这是 Vibe Coding 的结构性缺陷。
这三个问题都指向同一个本质:Vibe Coding 缺少一个约束层。 这个约束层需要在 AI 和最终代码之间,持久化地表达工程意图、设计决策和质量标准。
三:spec 概念应运而生
2025年,Sean Grove 在多篇工程博客和社区讨论中持续倡导 Spec Coding(规格驱动编码)的概念框架,这一思路随后在 AI Coding 实践者圈子里快速扩散。其核心主张是: 在让 AI 写代码之前,先让 AI 帮你写 Spec(规格说明书)。
这个主张听起来像是在绕远路。但本质上,它是在解决「上下文持久化」和「意图结构化」这两个问题。我们可以用一个类比来理解 Spec Coding 和 Vibe Coding 的区别:
3.1 Vibe Coding(感觉驱动)
依赖开发者的即时灵感和直觉推进,快速出码,快速迭代。
就像口述给一个实习生:「帮我做一个登录页,你知道的那种风格」。实习生理解你的意思,做出来,但你们之间的「理解」是隐性的、一次性的,换一个实习生就要重新解释。
优点:启动快、无需前期文档、灵活、适合探索性开发、对有经验的开发者效率高
缺点:知识在人脑里难以传递、文档滞后或根本没有、规模越大失控风险越高
3.2 Spec Coding(规范驱动)
严格遵循事先定义的技术规格说明书(Spec)来开发。Spec 是唯一的「真理之源」。
就像先写一份需求文档——哪怕这份文档是 AI 帮你生成的。这份文档成为所有后续对话的锚点,不管你和哪个 AI、在哪个会话里继续工作,约束条件都在那里。
核心流程:Think → Spec → Code → Test(先想清楚 → 写清楚 → 再执行)
优点:需求清晰边界提前暴露、文档和代码天然同步、便于协作和新人上手、可验证性强
缺点:前期投入较高、对灵活性要求高的项目不适合
3.3 如何判断用哪种模式?
判断依据:代码的生命周期 × 代码错误的代价。
- 周期越长、代价越高 → 越需要 Spec 约束
- 原型验证、个人工具、技术探索 → Vibe Coding 仍然有效
四:Spec 是什么?
Spec 不是传统软件工程里那种 200 页的 PRD。一个有效的 Spec 应该包含:
- 目标陈述:这段代码要解决什么问题,成功标准是什么
- 边界定义:明确做什么,明确不做什么(Not-scope 往往比 Scope 更重要)
- 设计决策:关键的技术选型和原因,约束条件
- 接口契约:对外暴露什么接口,输入输出的格式和约束
- 测试场景:正常路径、异常路径、边界条件
这五个维度,可以用一个 Markdown 文件表达,500 字以内,但它的作用是让 AI 在后续所有对话中有一个持久的「参考系」。
五:spec-kit 简介
Spec Kit 是 GitHub 开源的 AI 辅助规范驱动开发工具包(截止到目前79k 星),核心是让「规范先于代码」
更快地构建高质量软件:一个开源工具包,让您可以专注于产品场景和可预测的结果,而不是从头开始vibe coding每个部分 。
先把项目规则、需求细节、实现计划说清楚,再让 AI 生成代码,避免边写边改的返工。
5.1 什么是规范驱动开发?
规范驱动开发颠覆了传统的软件开发模式。
几十年来,代码至上——规范仅仅是搭建的框架,一旦开始“真正的”编码工作,规范就会被弃之不用。
规范驱动开发改变了这一切:规范变得可执行,能够直接生成可运行的实现,而不仅仅是指导实现。
5.2 规范驱动编程是AI编程的趋势
Cursor / GitHub Copilot 等AI 原生 IDE,相继支持Plan模式,深度适配 SDD 流程。相比Plan模式聚焦于「代码执行层」,Spec Kit更进一步关注在「需求定义层」不止在生成代码前写出详细计划、提出澄清问题,做到「先规范,再编码」
更把规范与代码一起,作为了项目的一部分。
5.3 与传统开发方式的对比
| 项目 | 传统 Vibe Coding | Spec Kit 规范围动开发 |
|---|---|---|
| 流程 | 需求 -> 编码 -> 发现问题 -> 重构 -> 再发现问题 | 需求 -> 竞法 -> 规范 -> 计划 -> 任务 -> 实现 |
| 投入时间 | 无前期规划,边写边改 | 前期投入长,AI 生成规范和人工 Review 规范时间各占一半 |
| 输出物 | 代码为主,文档缺失 | 每阶段都有明确文档输出(.md 文件) |
| 可维护性 | 差(知识留在取巧记录中) | 强(文档与代码同步更新) |
| 返工率 | 高(因需求模糊导致) | 低(需求先澄清,减少理解偏差) |
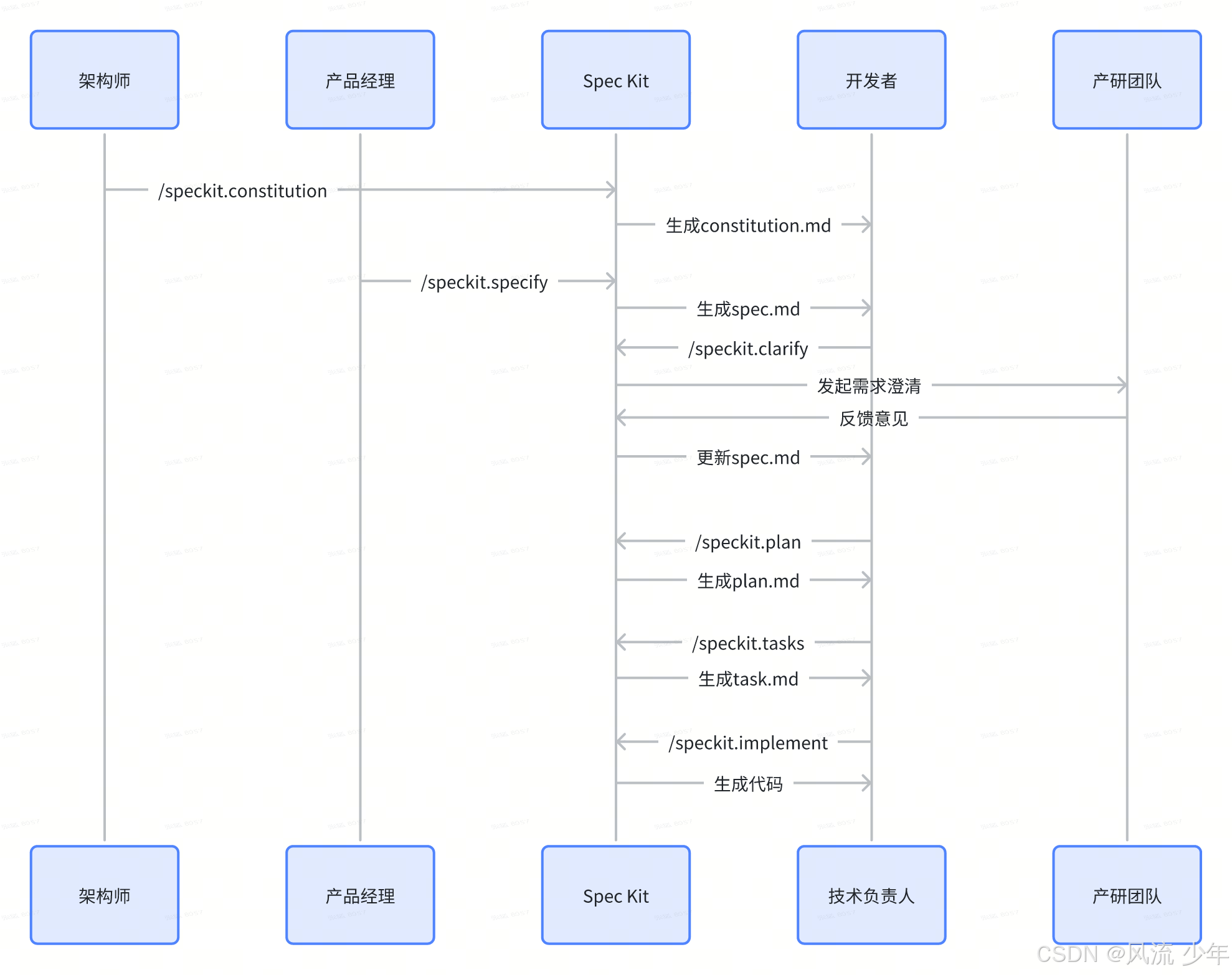
5.4 核心流程
| 阶段 | 作用 | 命令 | 文件名 | 产出物 | 本次时间投入 |
|---|---|---|---|---|---|
| 1. 宪法 (Constitution) | 定义项目“基本法”:如技术栈、命名规则、编码规范 | /speckit.constitution |
constitution.md |
项目管理原则、技术规范、开发标准 | 5分钟 |
| 2. 规范 (Specification) | 明确“做什么”和“为什么做” | /speckit.specify/speckit.clarify |
spec.md |
功能需求描述、场景说明、边界条件 | 10分钟 |
| 3. 计划 (Plan) | 决定“怎么实现” | /speckit.plan |
plan.md |
技术架构、API 规约、数据模型、实现路径 | 15分钟 |
| 4. 任务 (Tasks) | 拆解为具体可执行的小任务 | /speckit.tasks |
tasks.md |
可执行的任务清单 | 10分钟 |
| 5. 实现 (Implementation) | 生成代码 | /speckit.implement |
代码 | - |
六:优/劣势和适用场景
1.优势
- 更规范:每个阶段有明确输出,可追溯,如在constitution.md中规范项目整体的管理原则和开发指导方针,并影响后续所有需求
- 技术栈和架构约束
- 编码规范和命名规则
- 依赖策略
- 设计原则
-
少返工:通过上述四个阶段的文档产出和Review,尤其是Specification阶段的需求澄清,确保AI按实际需求推进
- 10:00 - 向 AI 描述需求:”做个 Todo API,支持创建、列表、更新、删除”
- 10:05 - AI 开始快速生成代码,一切看起来很顺利
- 10:30 - 突然意识到:数据库设计有问题、API 返回格式没统一、边界情况没考虑
- 10:35 - 重新调整需求,之前 30 分钟的工作大部分需要返工
-
早入场:传统AI在开发阶段才上场,现在PRD输出后就可以使用Spec Kit
-
有沉淀:项目文档和项目代码同步更新,每一次纠正AI的沟通不会只留存在chat里,解决vibe coding可维护性问题
specs/
└── 001-business-achievement/ # 需求分支文件夹:经营达成模块
├── spec.md # 功能规格说明
├── plan.md # 技术实现计划
├── tasks.md # 任务列表
├── data-model.md # 数据模型定义
├── research.md # 技术调研文档
├── quickstart.md # 快速开始指南
├── contracts/ # API契约文档目录
│ └── api-contracts.md # API接口契约
└── checklists/ # 检查清单目录
└── requirements.md # 需求检查清单
2. 劣势
- 费Token:更多的上下文意味着更多的Token消耗。
- 启动慢,前期投入时间长,走完Spec Kit完整流程(Constitution -> Specification -> Plan -> Tasks -> Implement 的)的耗时较长。
- 适用场景
- 适合 Spec-Kit 的场景
✅ 项目复杂度 ≥ 3 个文件/模块
✅ 学习新技术栈(流程帮助你建立系统性认知)
✅ 需要文档的项目(自动生成高质量文档)
✅ 团队协作项目(规范统一认知) - 不适合 Spec-Kit 的场景
❌ 简单的 CRUD
❌ 紧急 hotfix
❌ 需求尚不明确
七:安装与环境准备
通过uv安装Specify CLI,并初始化项目。
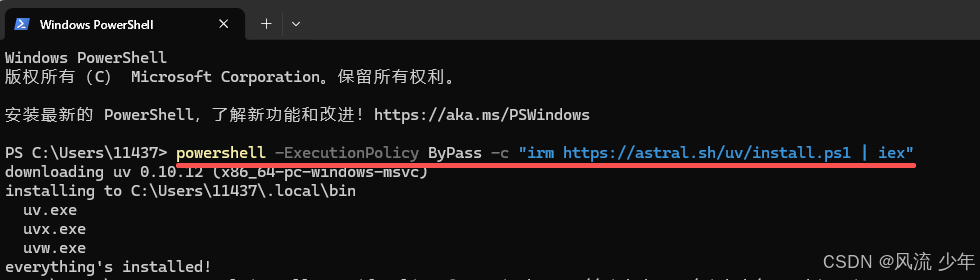
- 安装uv (Python包管理工具)
# On macOS and Linux.
curl -LsSf https://astral.sh/uv/install.sh | sh
# On Windows.
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
- 安装Specify CLI
# Persistent Installation (Recommended)
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
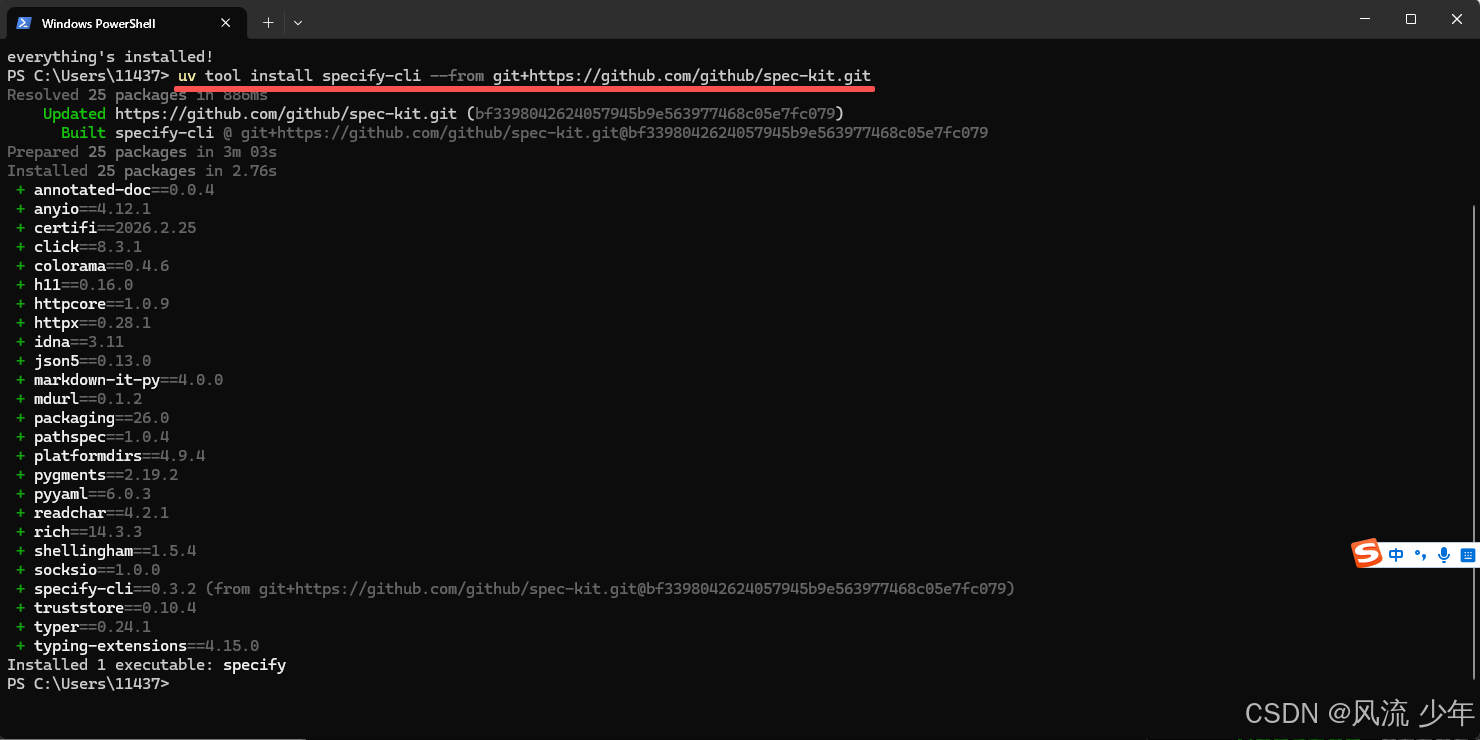
- 初始化Spec Kit项目
#新项目
specify init <PROJECT_NAME>
#老项目
specify init .
输入y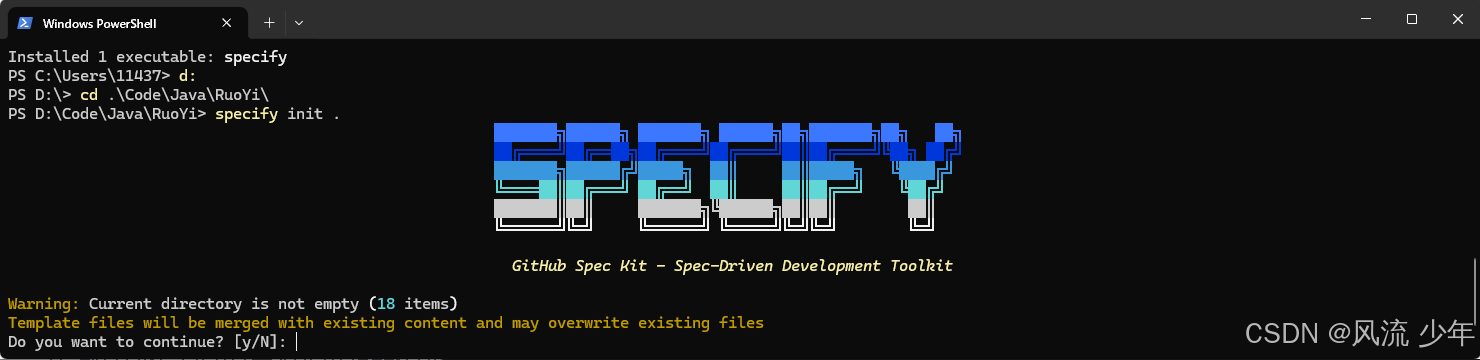
选择AI助手,看自己手上有哪些可用的模型,选择自己购买的模型即可。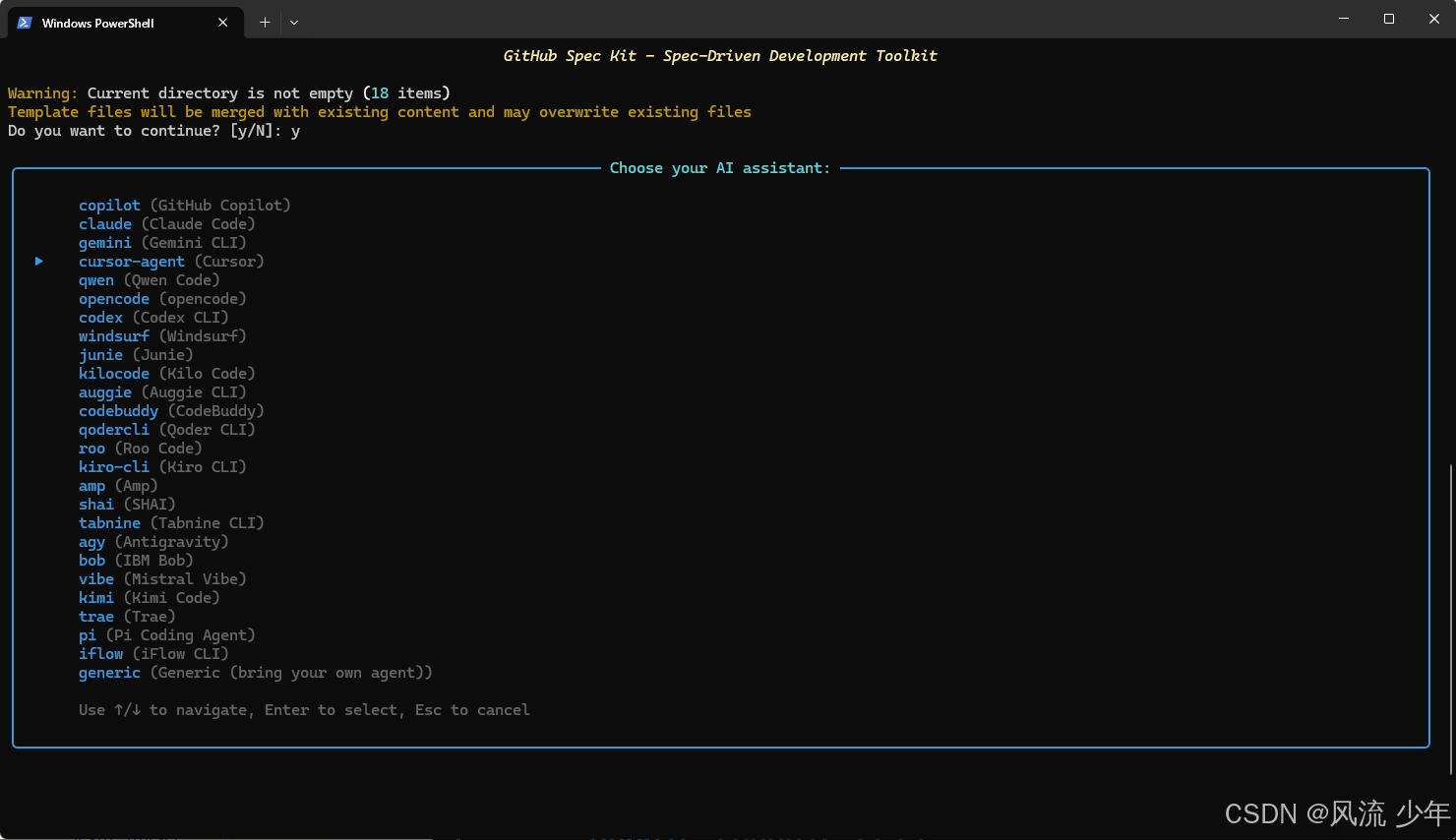
选择脚本类型

初始化完毕。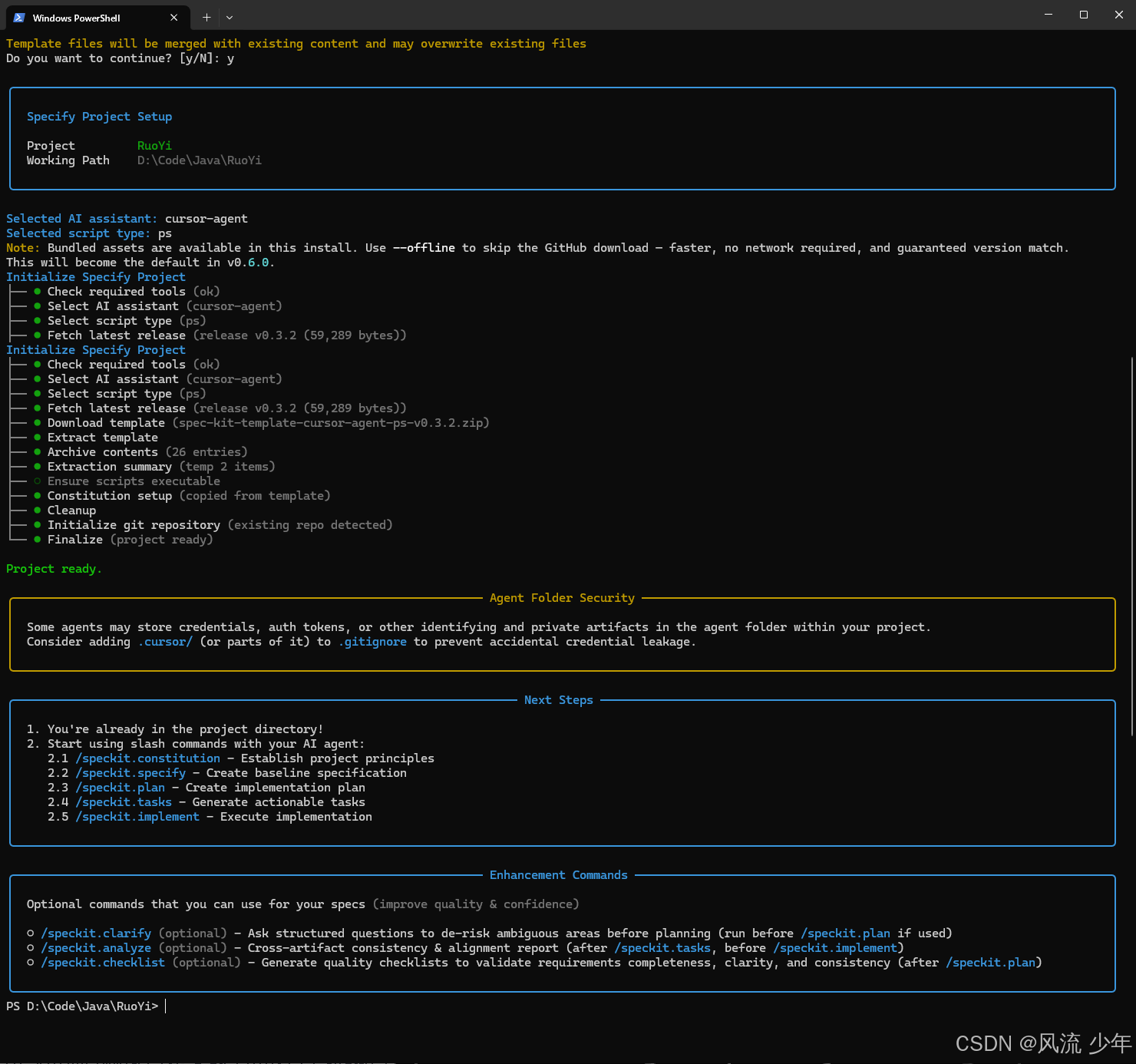
初始化完毕后,项目下创建了新文件夹.specify。
八:实战
1. 建立宪法 (/speckit.constitution)
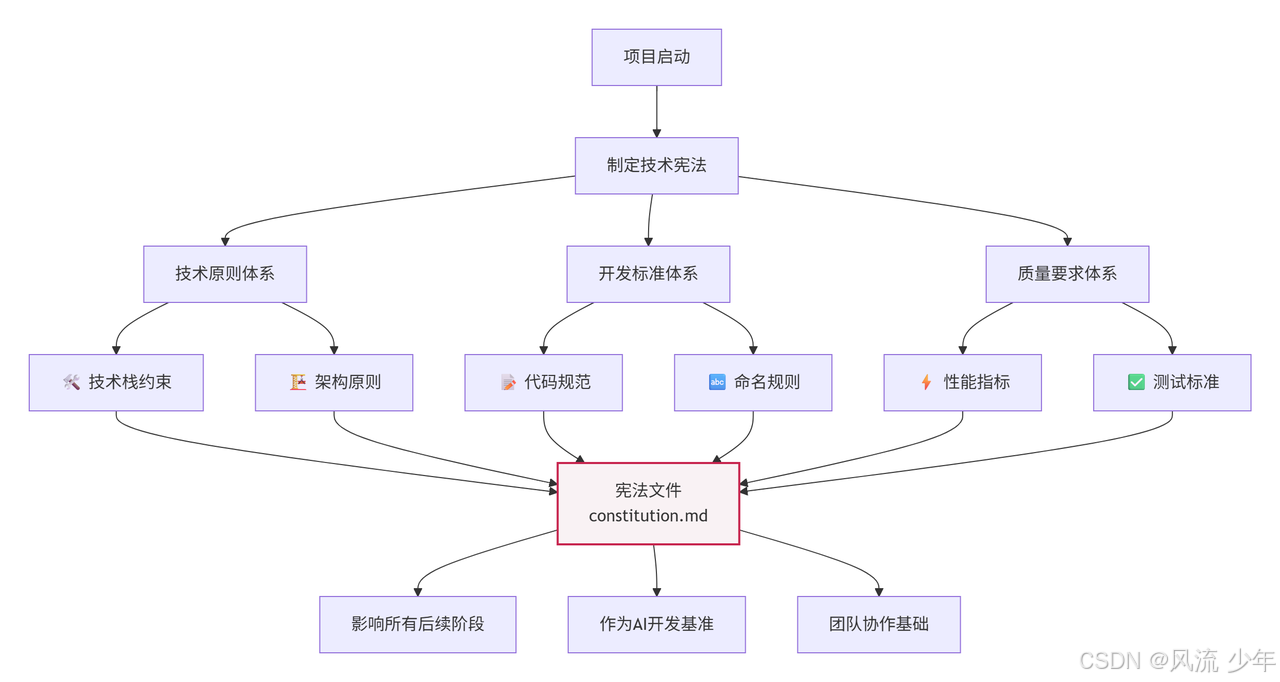
命令和响应
建立项目的核心治理原则和开发标准,填充宪法模板
建立宪法阶段可以使用关键字
| 关键词 | 核心定义 | 违反后果 | 真正适用场景 |
|---|---|---|---|
| NON-NEGOTIABLE | 「无协商空间」,规则是绝对不可变更的底线,任何场景下均不允许例外 | 应坚决驳回变更、全程禁止,产品/服务无法上线(无危险遮盖) | 合规性要求(如 GDPR 数据隐私);安全红线(如密码加密算法);法律强制条款 |
| MANDATORY | 「强制要求」,规则必须遵守,但极端情况下可通过正式流程申请豁免/变更;未满足则流程中断(如测试不通过),但经豁免后可放行 | 流程被阻断(如 API 字段校验);流程规范(如发布审核步骤);协作作业要求 | 技术接口标准(如 API 字段格式);流程规范(如发布审核步骤);协作作业要求 |
| CRITICAL | 「关键级」,规则失效会导致核心功能/系统崩溃,优先级最高且必须对齐的要求 | 系统核心功能失效、重大故障风险、紧急恢复,但可临时绕线(短期) | 系统依赖关系、重大故障风险、紧急恢复,但上线前须恢复 |
#英文
/speckit.constitution Create principles focused on code quality, testing standards, user experience consistency, and performance requirements
#中文
/speckit.constitution 创建专注于代码质量、测试标准、用户体验一致性和性能要求的原则
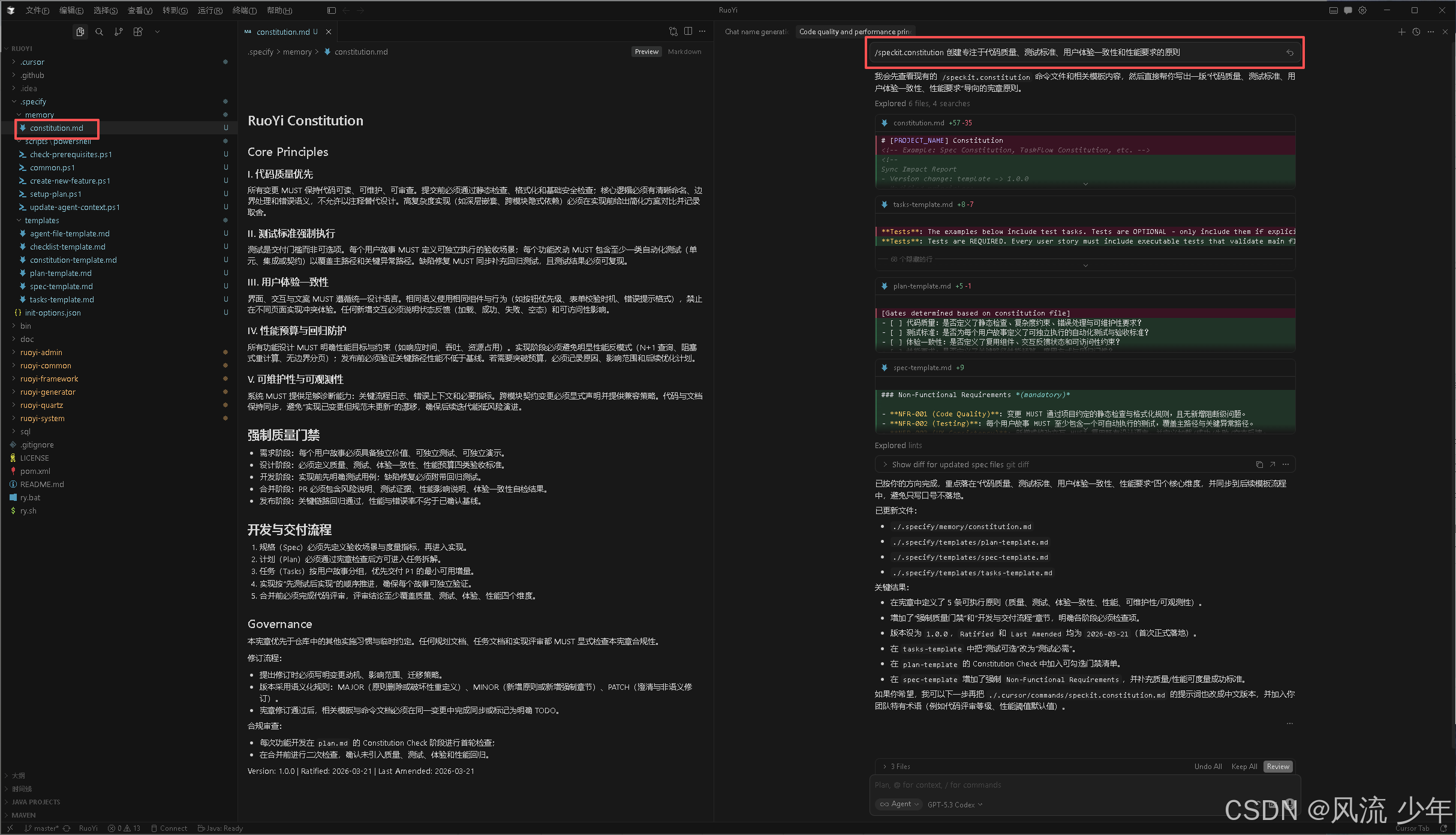
工作机制
- 加载 constitution 模板:读取 .specify/memory/constitution.md 中的模板;
- 识别占位符:找到所有[ALL_CAPS_IDENTIFIER] 格式的占位符,如 [PROJECT_NAME]、[PRINCIPLE_1_NAME] 等;
- 收集具体值:从用户输入、已有仓库上下文、或推断中获取占位符的实际值;
- 版本控制:按语义版本规则自动更新 CONSTITUTION_VERSION(MAJOR、MINOR、PATCH);
- 一致性传播:检查并更新所有相关模板文件,确保新原则在整个工具链中生效;
- 生成同步报告:在文件顶部添加 HTML 注释,记录修改历史和影响的模板。
关键设计:
Constitution 不只是一个文档,它是整个工具链的“基本法则”,所有后续命令都必须严格遵守这里定义的原则。比如你在这里定义了“必须使用 TypeScript”,那么后续的 plan 和 tasks 都会自动遵循这个约束。
2.描述需求 (/speckit.specify)
描述要构建什么,专注于 what 和 why,而非技术实现。
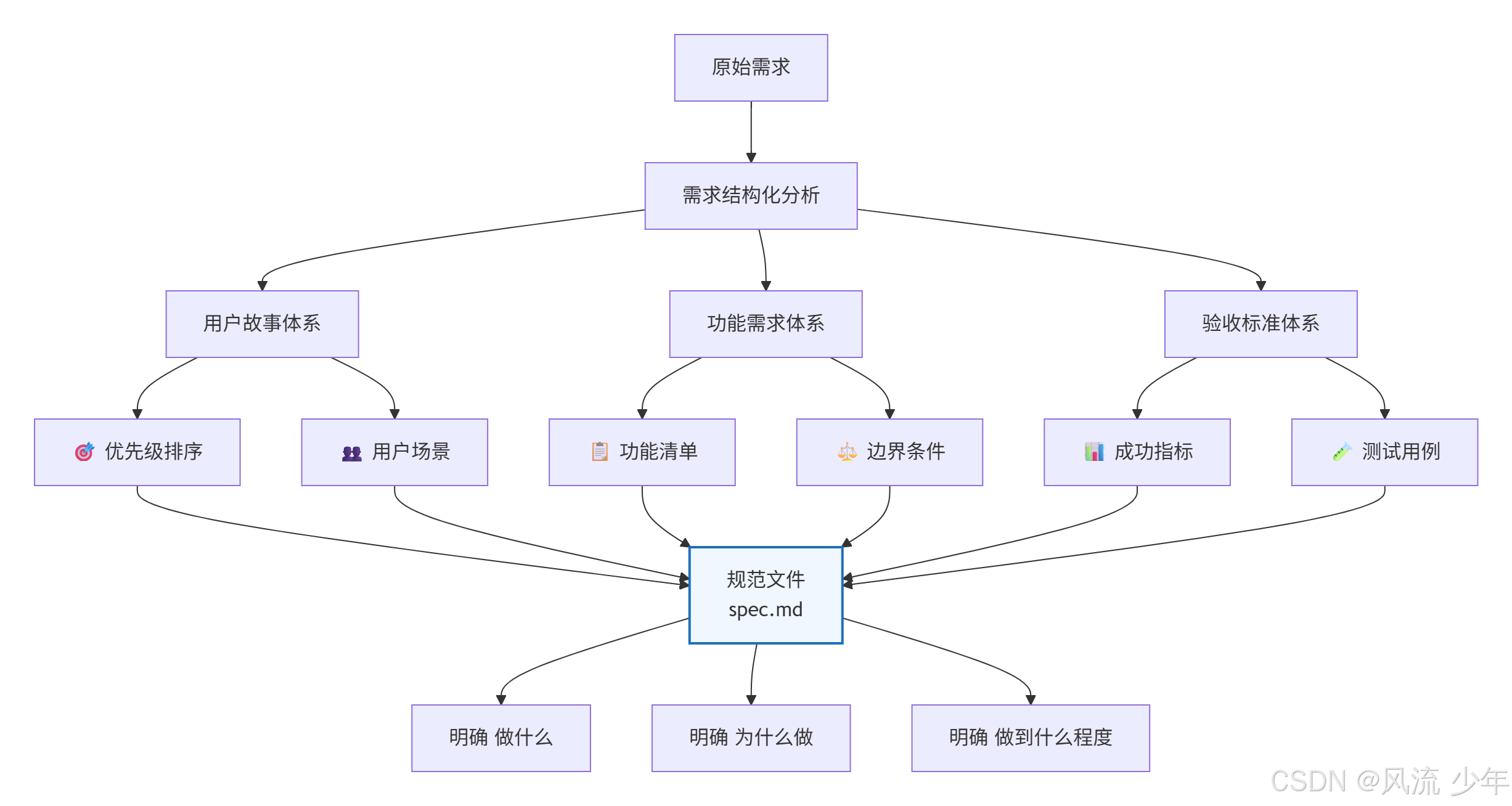
准备工作
随便生成一份需求文档。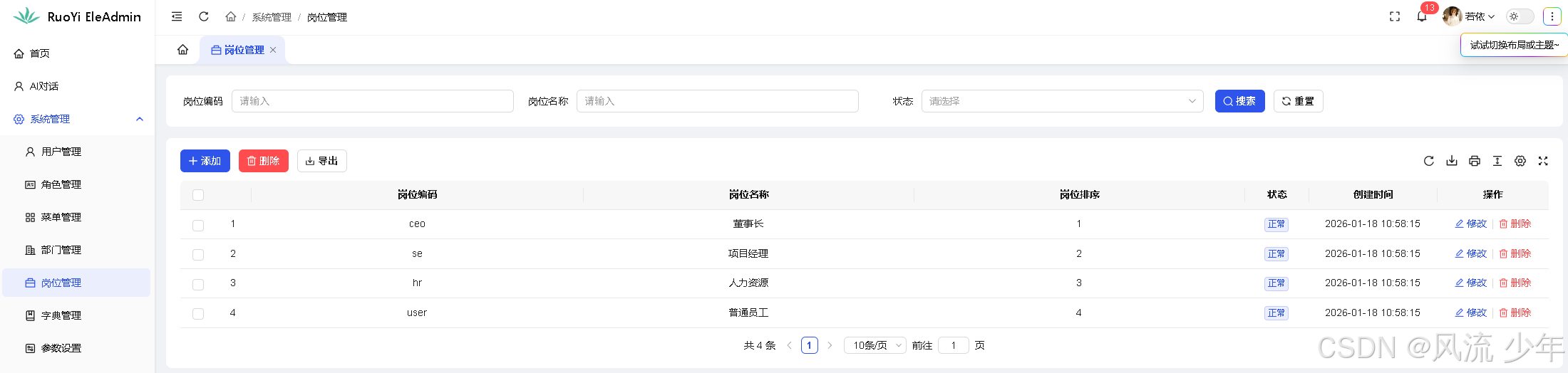
参考截图页面的功能,生成一个文章管理”的需求,将需求写到飞书文档中:https://mi.feishu.cn/wiki/XrYcwaeD6ijf
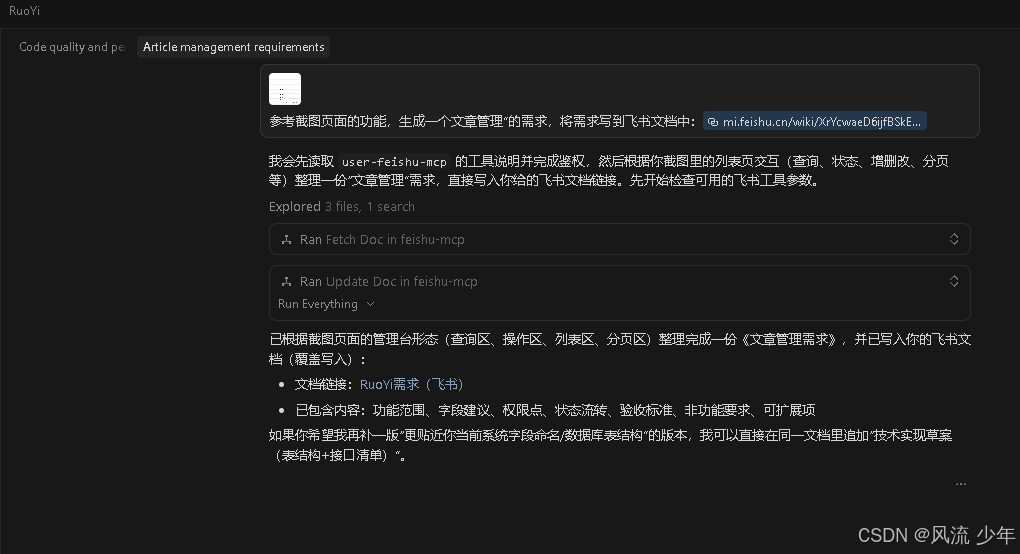
将文档https://mi.feishu.cn/wiki/XrYcwaeD6ijfBSkEYYUcgeyCnjf 转为markdown格式并保存到当前目录
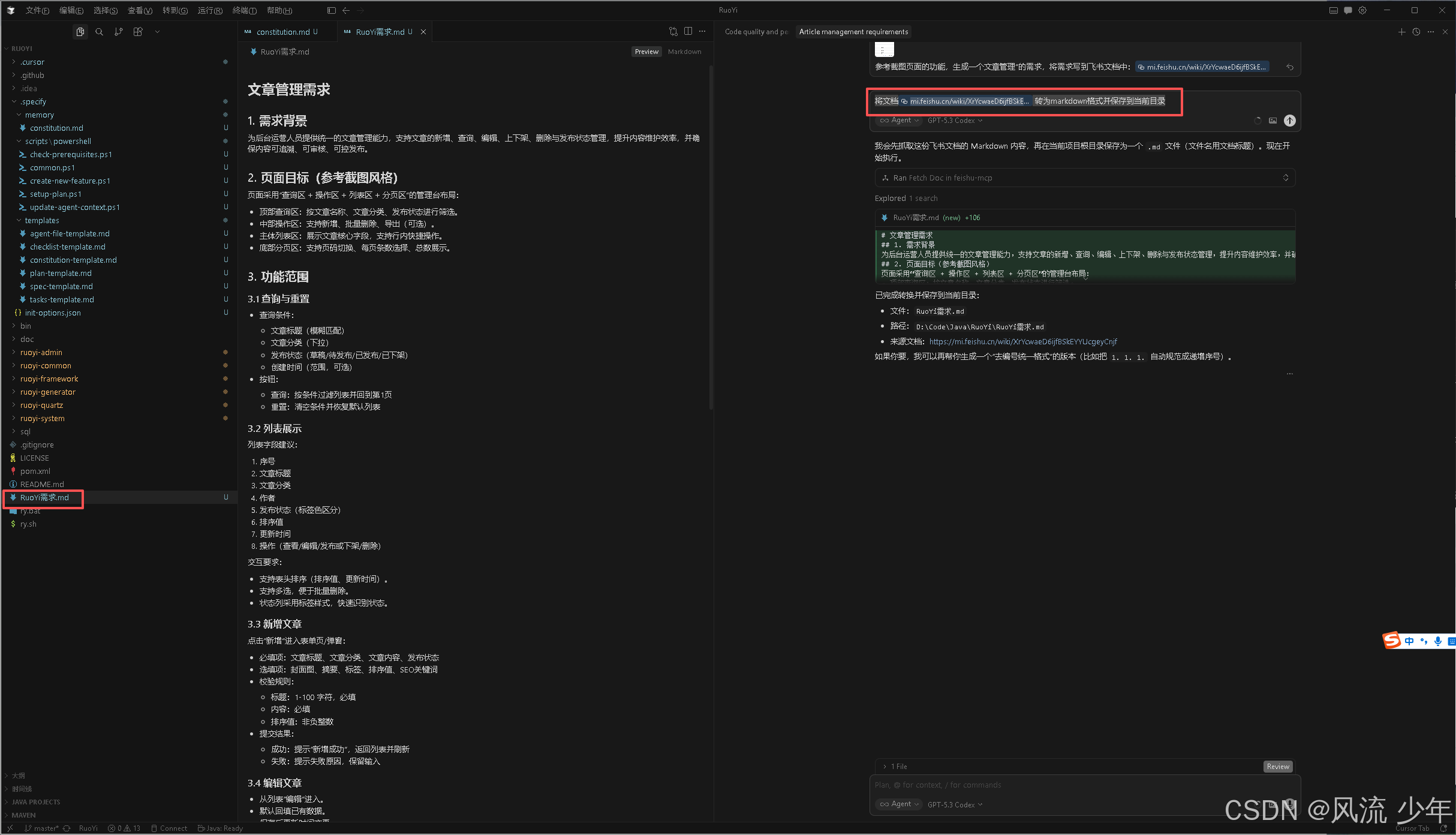
描述需求
/speckit.specify 需求文档地址为 https://mi.feishu.cn/wiki/XrYcwaeD6ijfBSkEYYUcgeyCnjf
产出物:新分支、需求目录、需求文档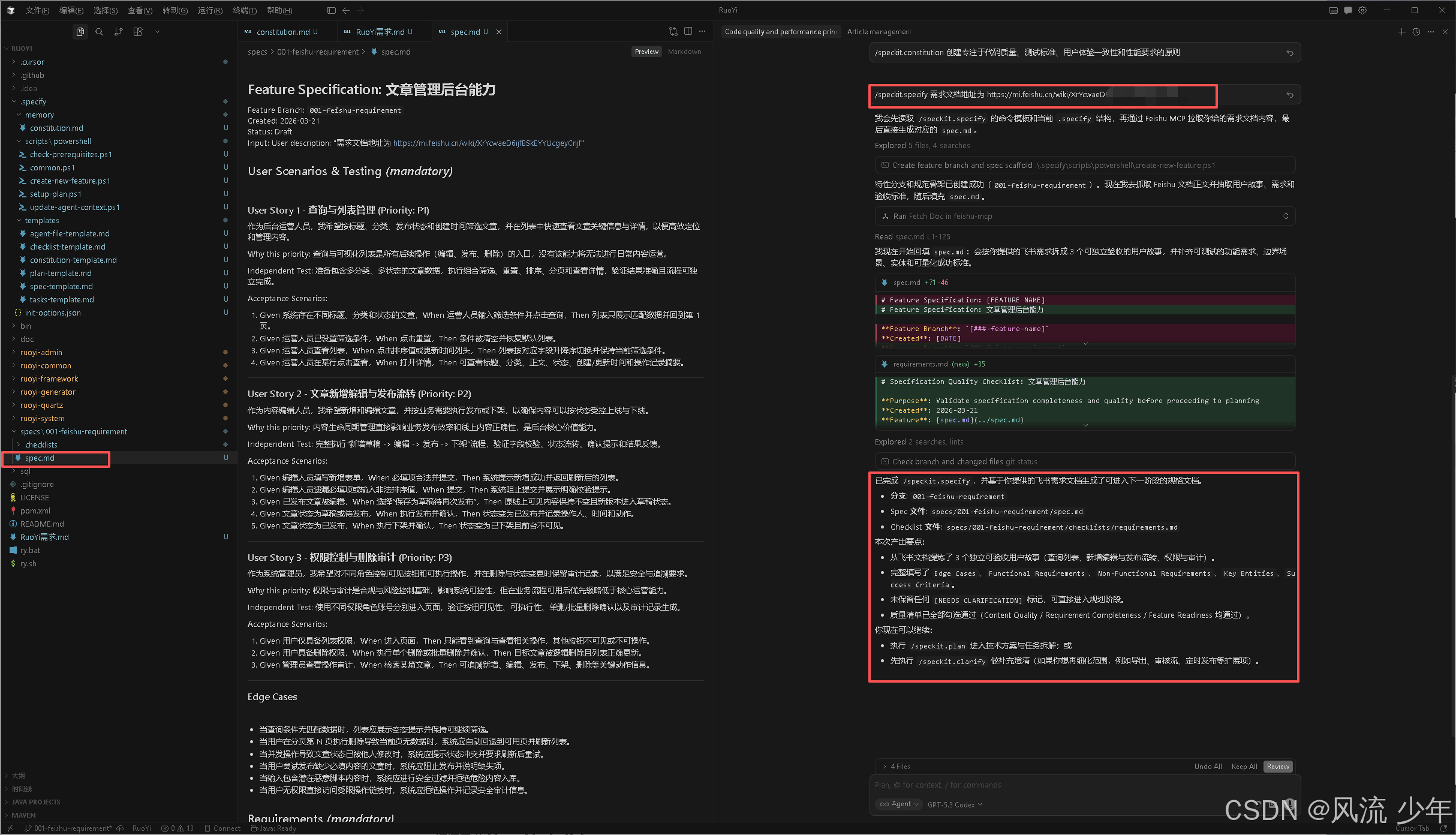
工作机制
- 运行分支创建脚本:
执行 .specify/scripts/bash/create-new-feature.sh --json “$ARGUMENTS”,
创建新的 feature 分支并返回 JSON 格式的分支名和规范文件路径; - 加载规范模板:读取 .specify/templates/spec-template.md 了解必需的章节结构;
- 智能内容生成:将你的自然语言描述转换为结构化规范,替换模板中的占位符但保持顺序和标题;
- 规范文件写入:在新分支的指定路径创建完整的 spec.md 文件。
关键设计:
整个过程只需要运行一次创建脚本。脚本会自动处理 Git 分支切换和文件初始化,然后 AI 在此基础上填充具体内容。
3. 澄清需求 (/speckit.clarify)
澄清规范中不够明确的地方
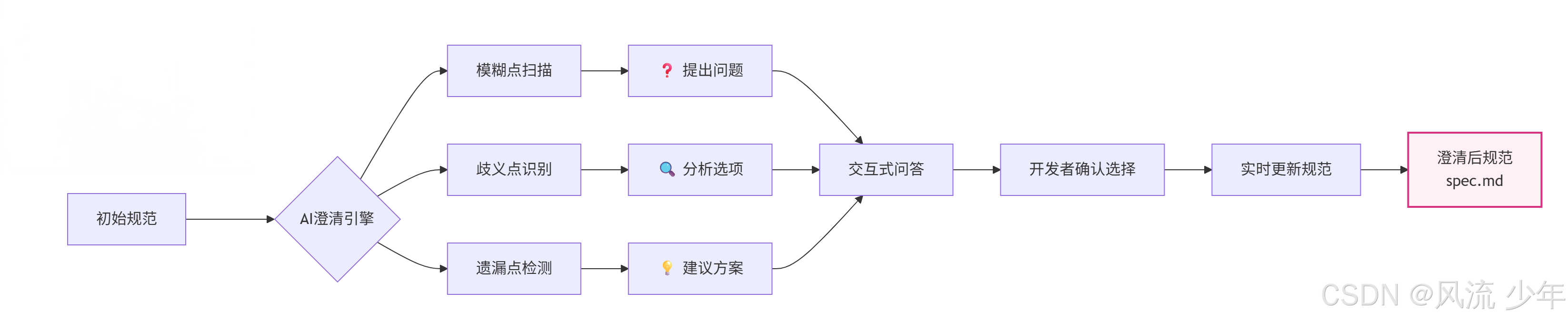
#主动澄清需求
/speckit.clarify 查询功能中的按标题查询支持模糊搜索
产出物:澄清后的需求文档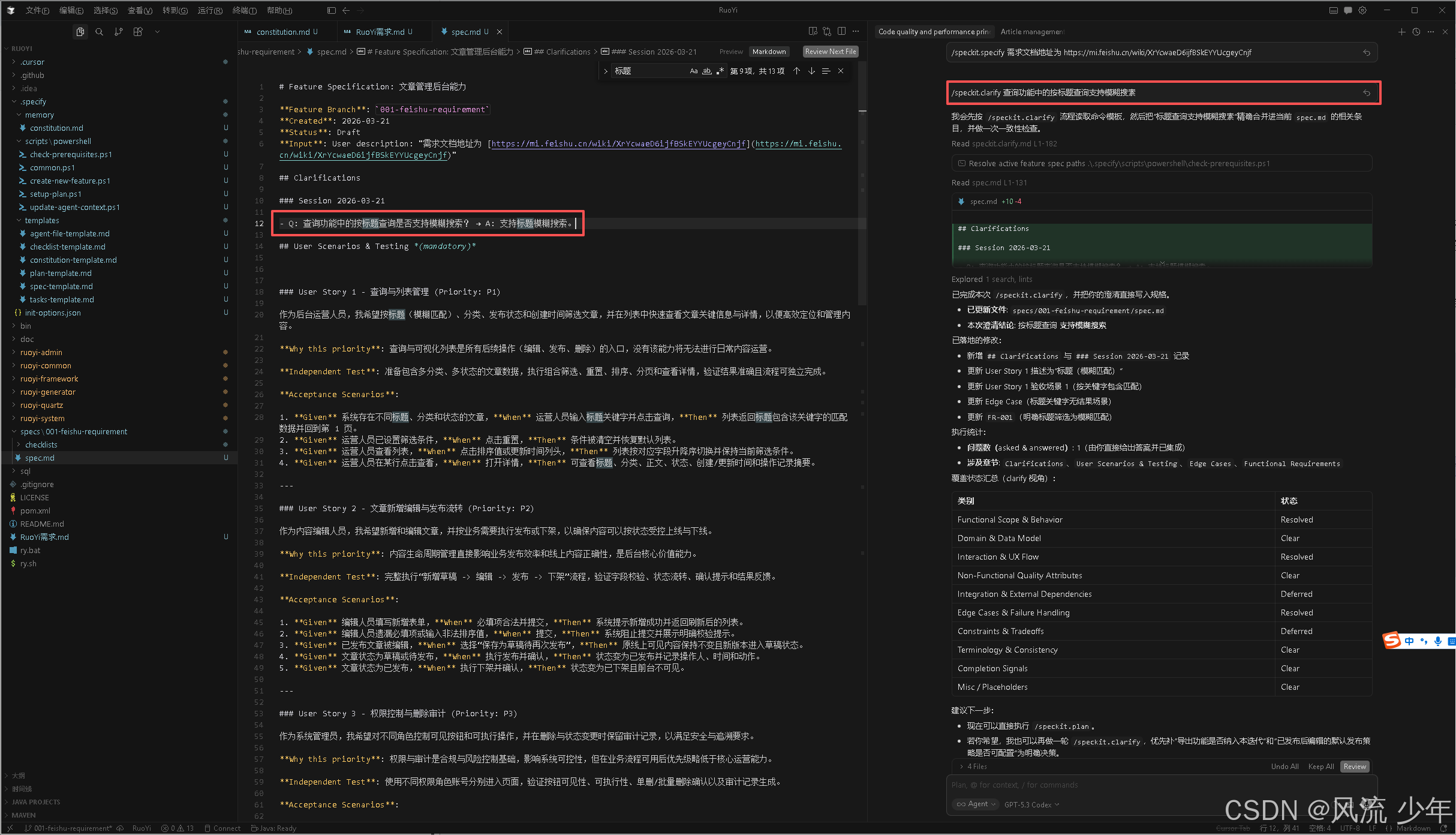
工作机制
- 前置检查:
运行 .specify/scripts/bash/check-prerequisites.sh --json --paths-only
获取 feature 目录和规范文件路径; - 多维度覆盖扫描:
对规范进行系统性的模糊性和覆盖度扫描,
涵盖功能范围、数据模型、交互、质量、集成依赖等共计 10 个分类。 - 智能问题生成:
生成最多 5 个高优先级澄清问题,每个问题都满足下面的条件:
- 可以通过多选题(2-5 个选项)或短答案(≤5 词)回答;
- 对架构、数据建模、任务分解等有实质影响;
- 能显著降低下游返工风险。
- 交互式问答循环:
一次只问一个问题,获得答案后立即更新规范文件; - 增量规范更新:
每个答案都会实时写入规范的相应章节,并在 ## Clarifications 部分记录。
关键设计:
最多问 5 个问题,确保澄清过程高效且聚焦。
如果你想跳过澄清步骤,需要明确说明,否则后续 plan 命令会检查并要求先运行 clarify。
4. 技术实现计划 (/speckit.plan)
指定实现技术栈、框架和架构设计
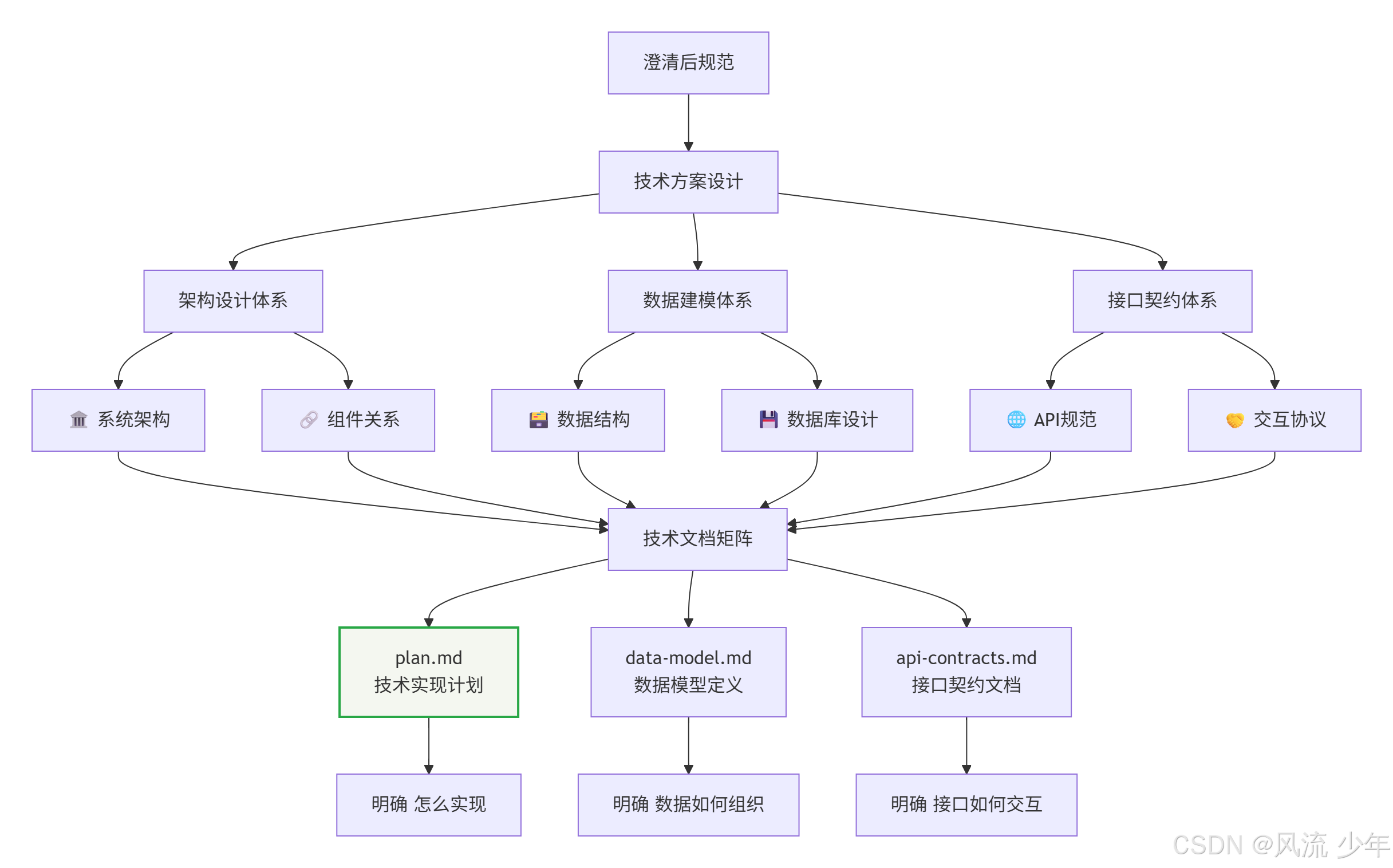
/speckit.plan 根据生成的文档 ,生成后端技术实现
产出物:技术实现计划、技术调研、数据模型、API 契约、快速开始指南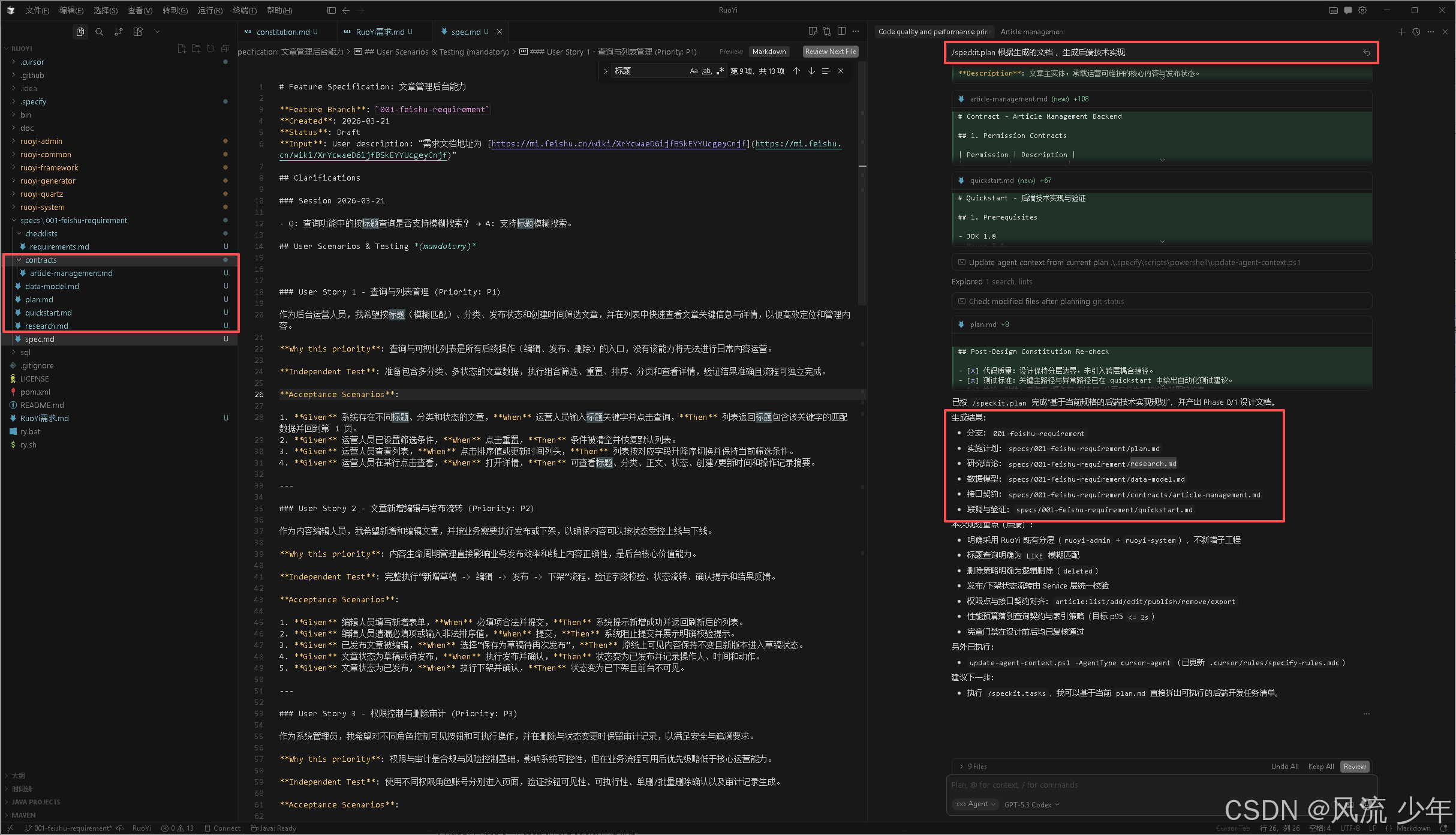
实施计划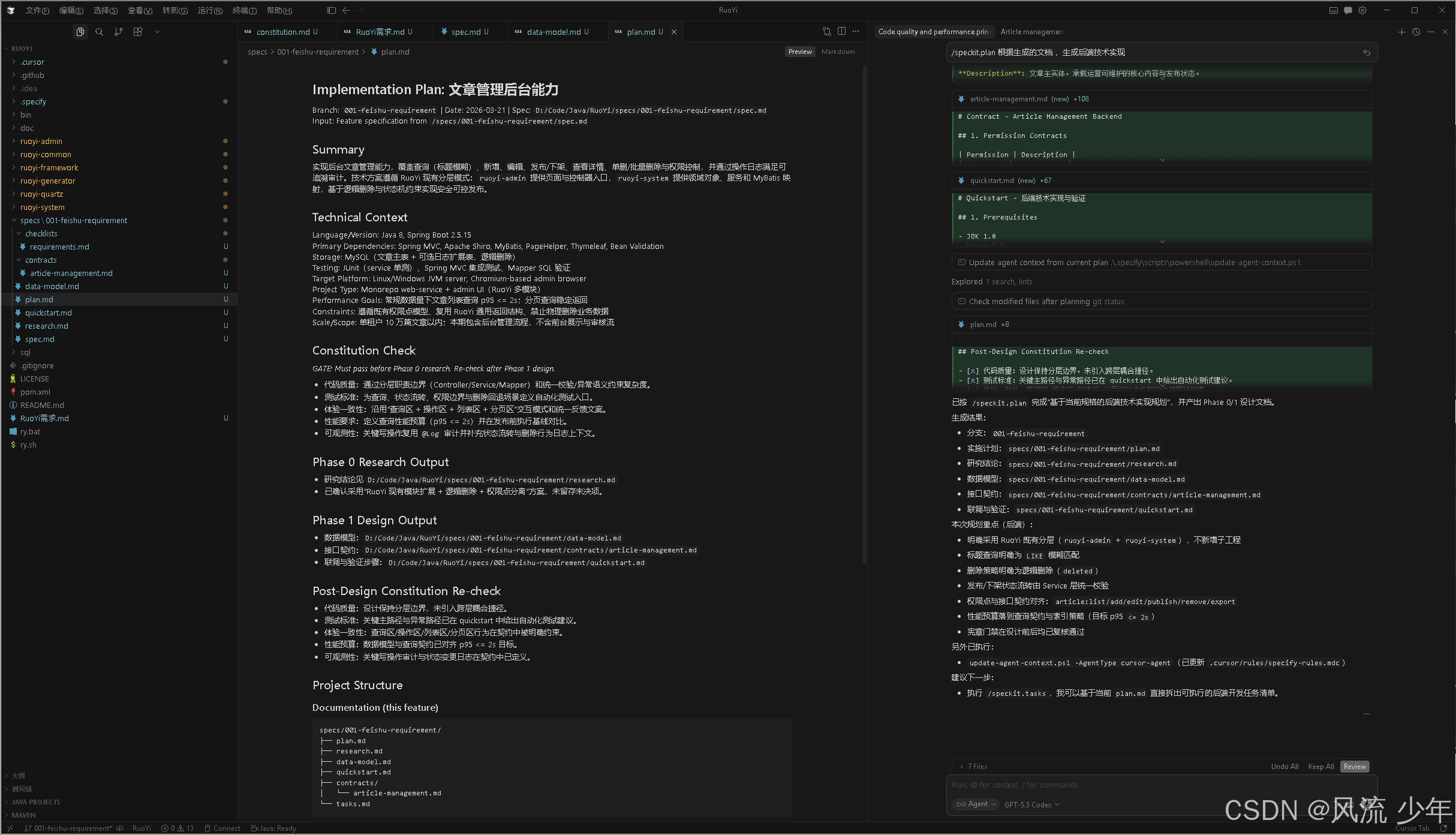
研究结论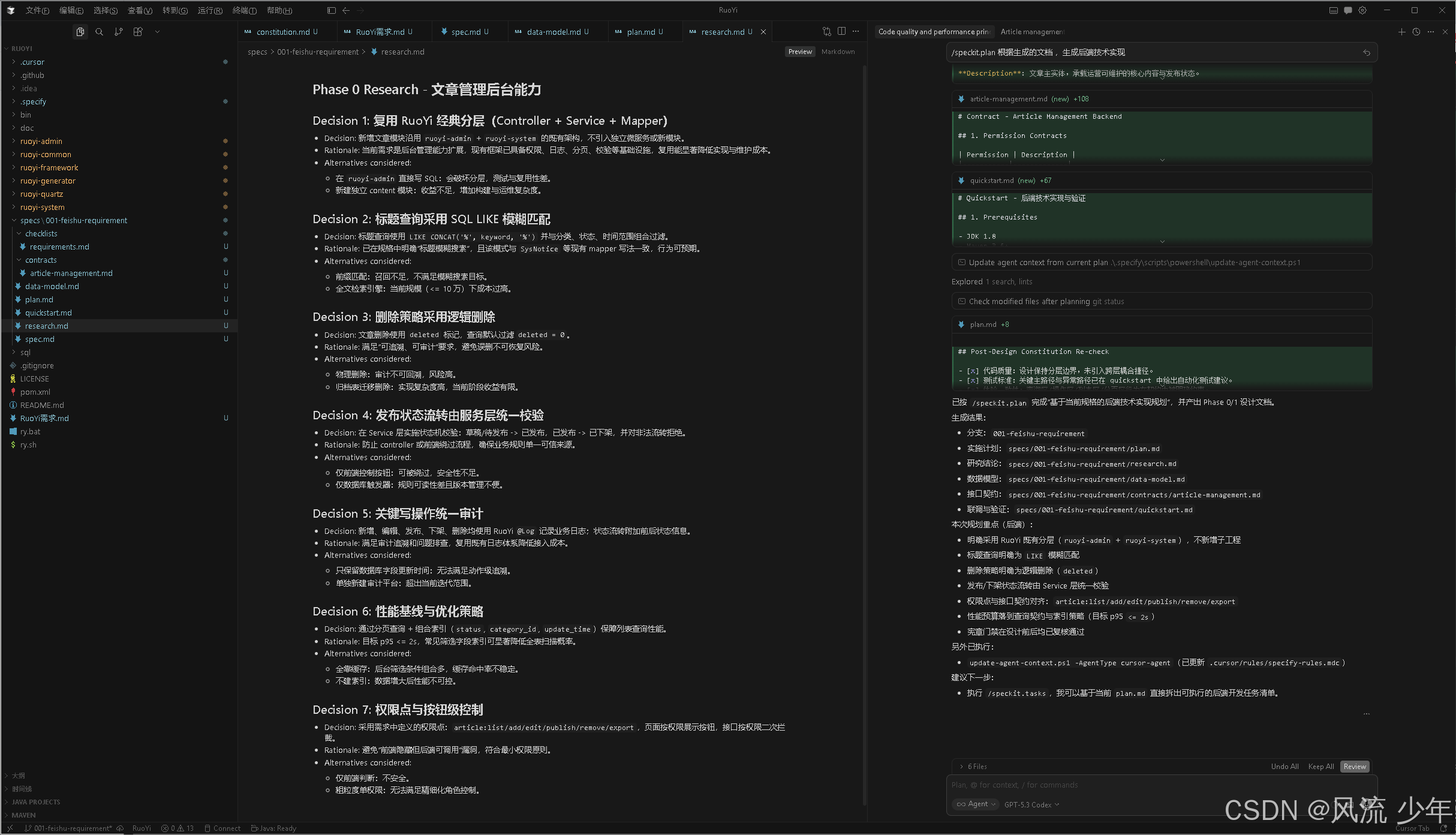
接口契约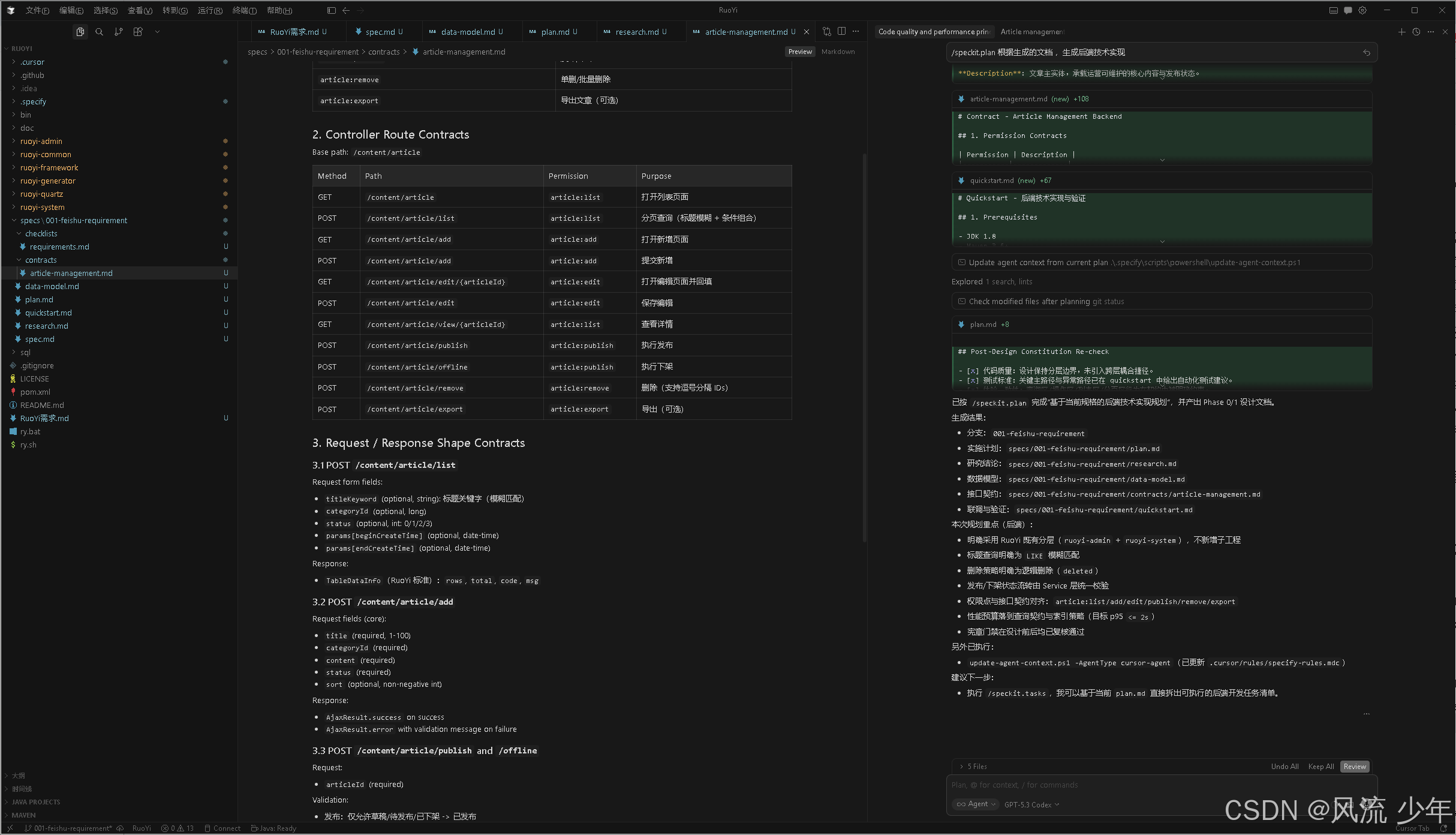
数据模型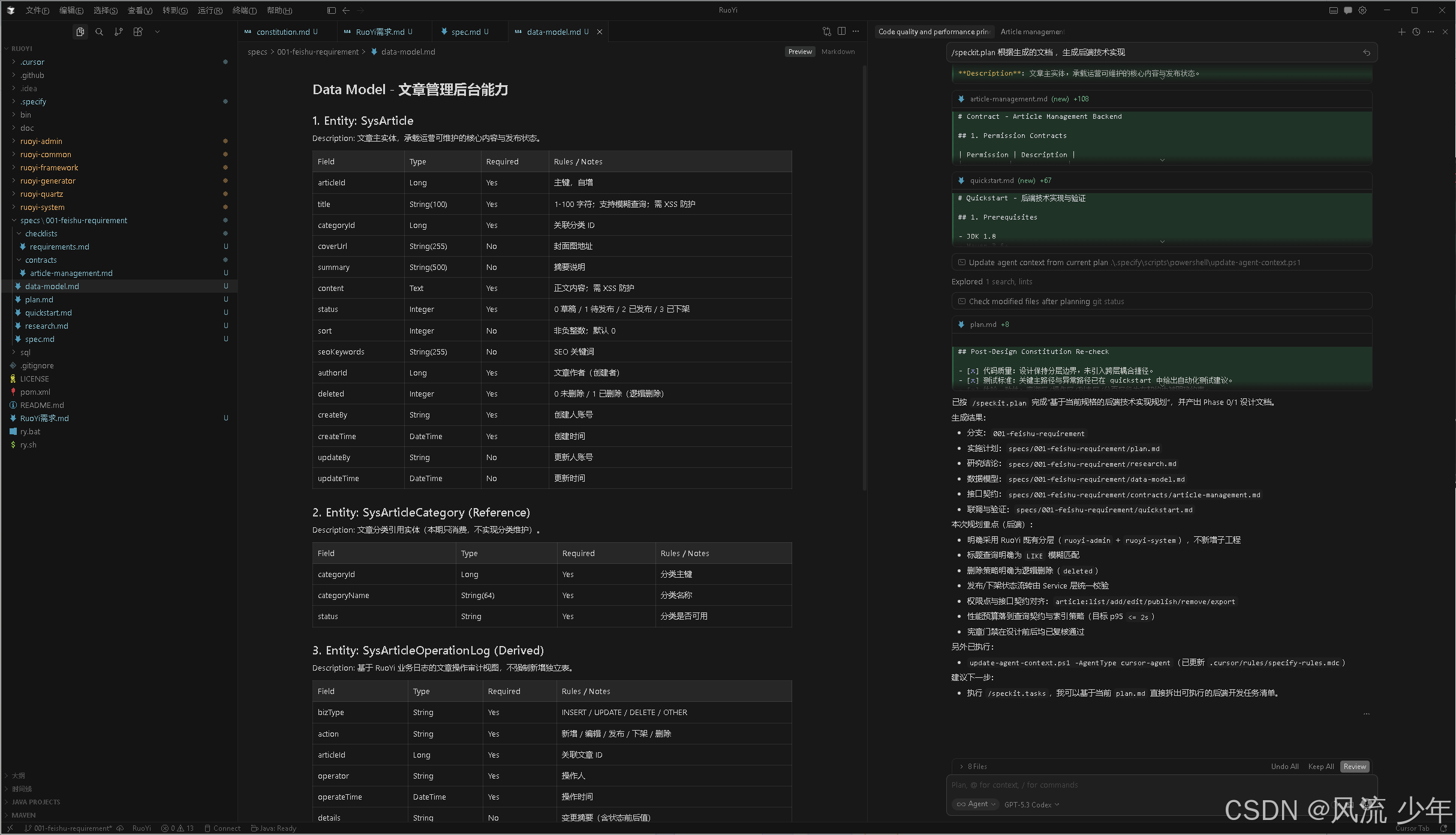
联调与验证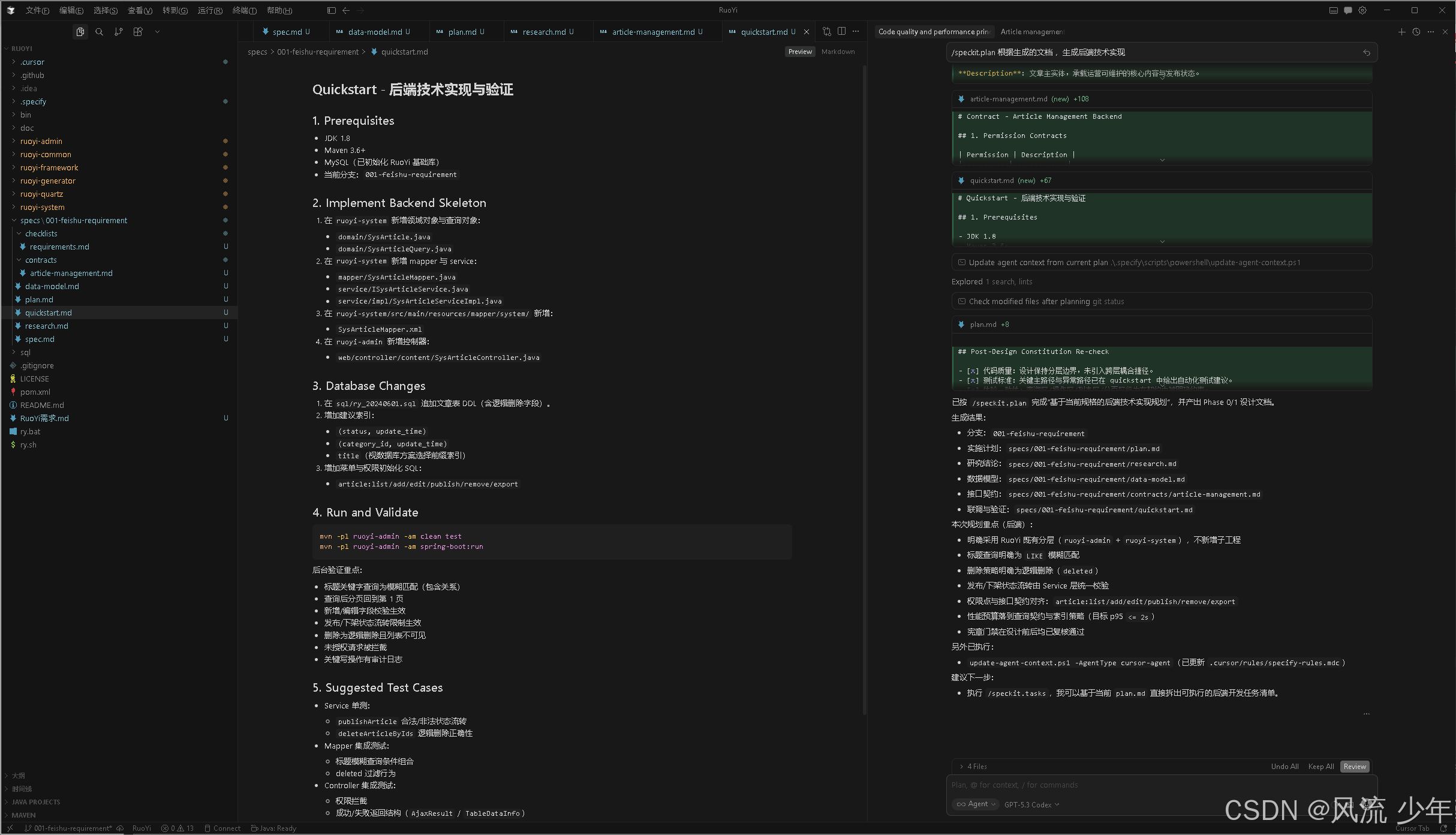
5.任务分解(/speckit.tasks)
将实现计划分解为详细的可执行任务
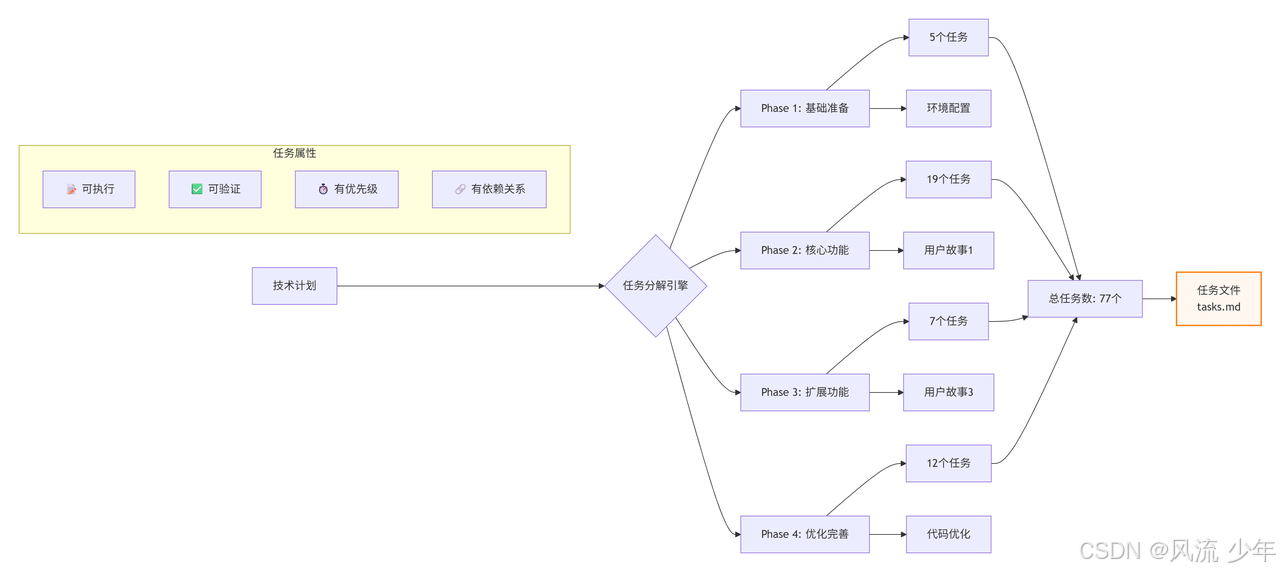
/speckit.tasks 输出内容为中文
产出物:任务分解文档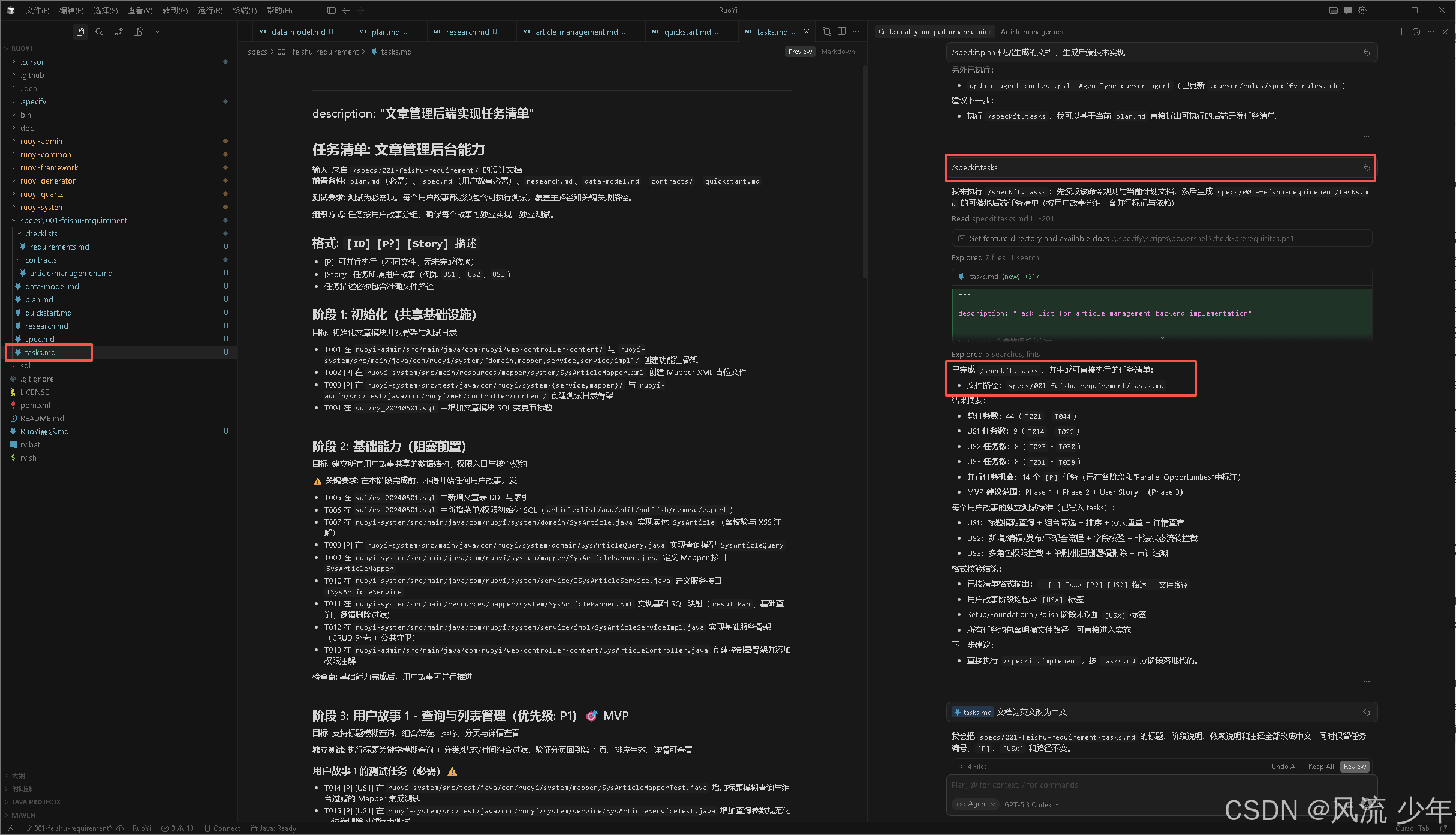
6. 代码实现(/speckit.implement)
根据任务列表执行具体的代码实现
建议:模型切换到 Claude 4.6 Sonnet或者Opus 4.6 以获得更好的代码生成能力
/speckit.implement 实现文章管理需求
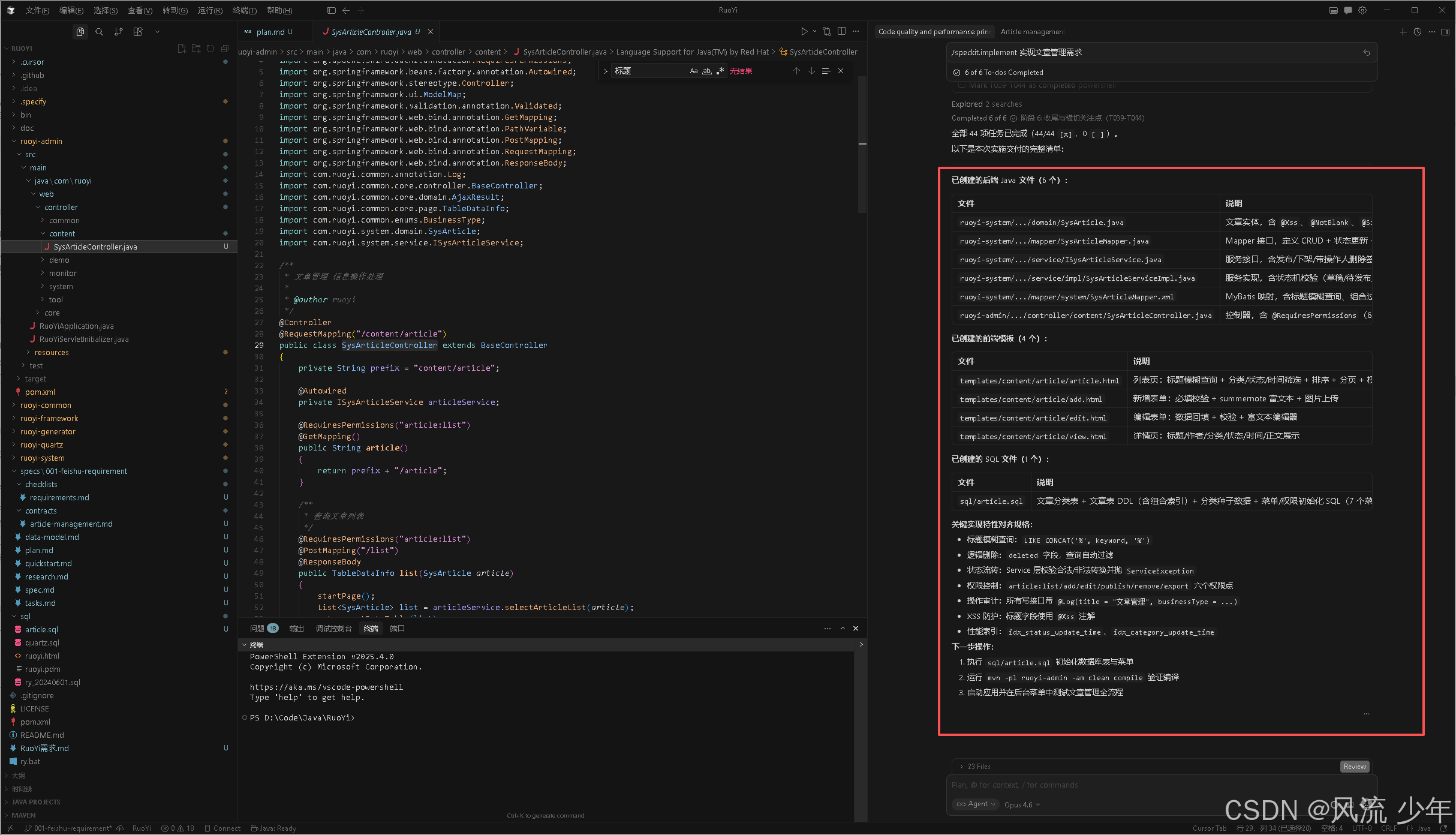
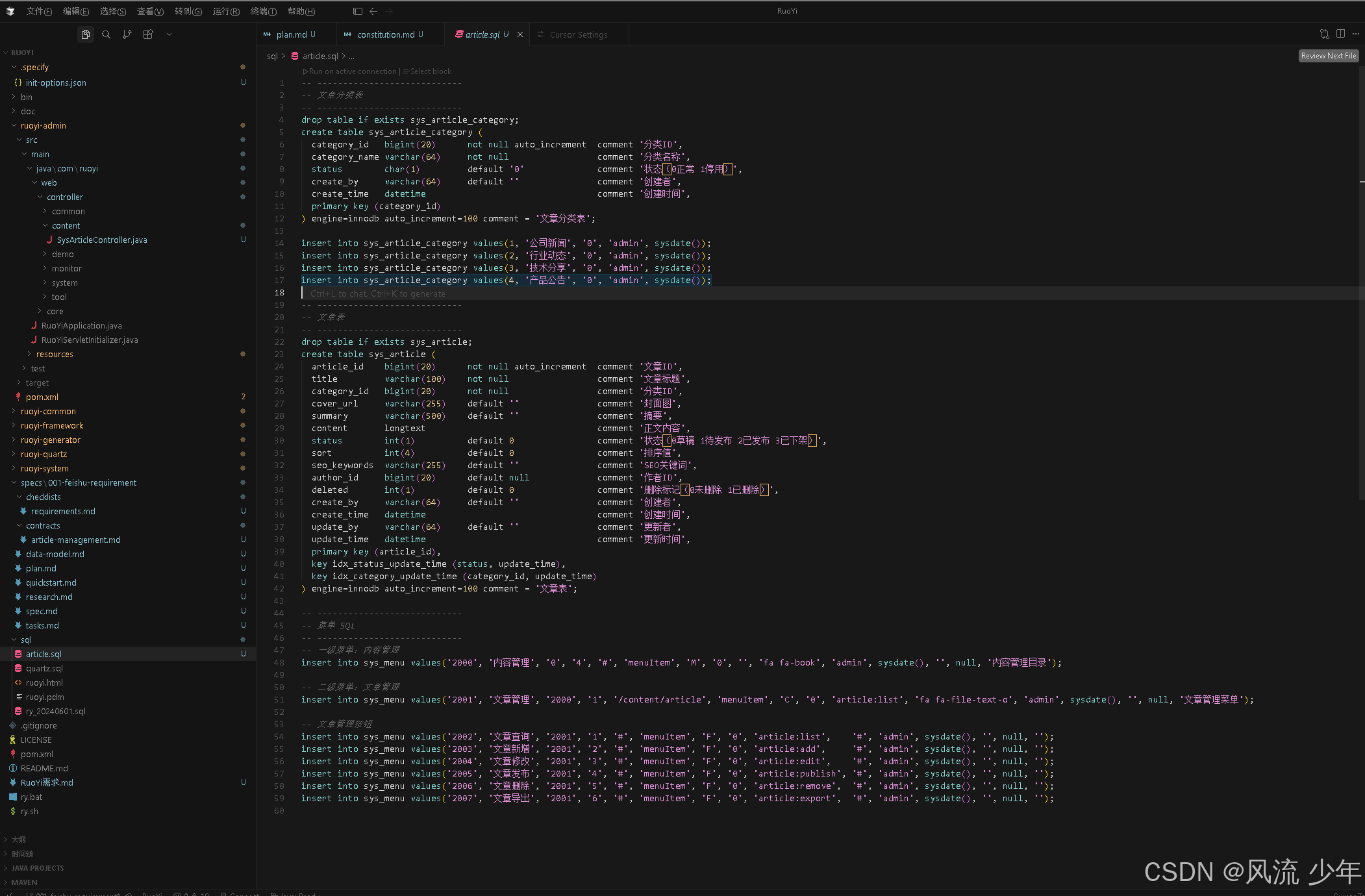
这里发现了2个问题:
- 一个是前端项目生成html文件了,应该把ruoyi-vue前端项目也纳入到此次需求中,这里并没有指定所以生成最原始的html,前端项目一般是通过Figma MCP来生成前端项目,在实战中最开始的对话截图是用Figma的截图,也可以根据需求文档作为Prompt扔给Figma让AI自动绘制出UI图。
- 第二个问题java文件中的{ 风格不对,这里可以更正过来并写入到宪法中,以后都要遵循。
生成的代码风格需要调整,java代码中大括号 { 禁止占用一行,应该放在上一行代码的末尾处,该规则需要同步到宪法中,以后都要遵循该规则
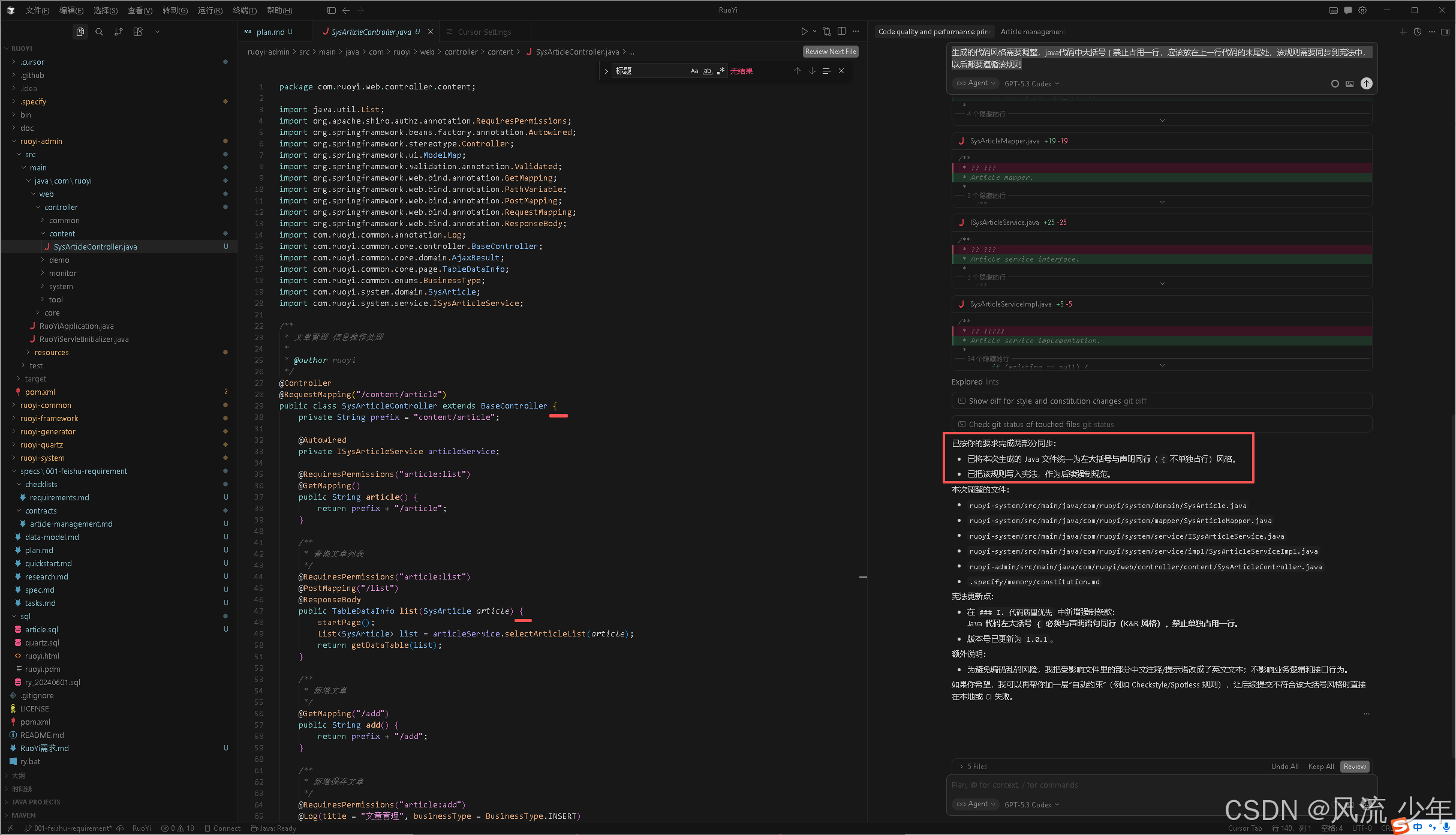
宪法中已经加入了该规则。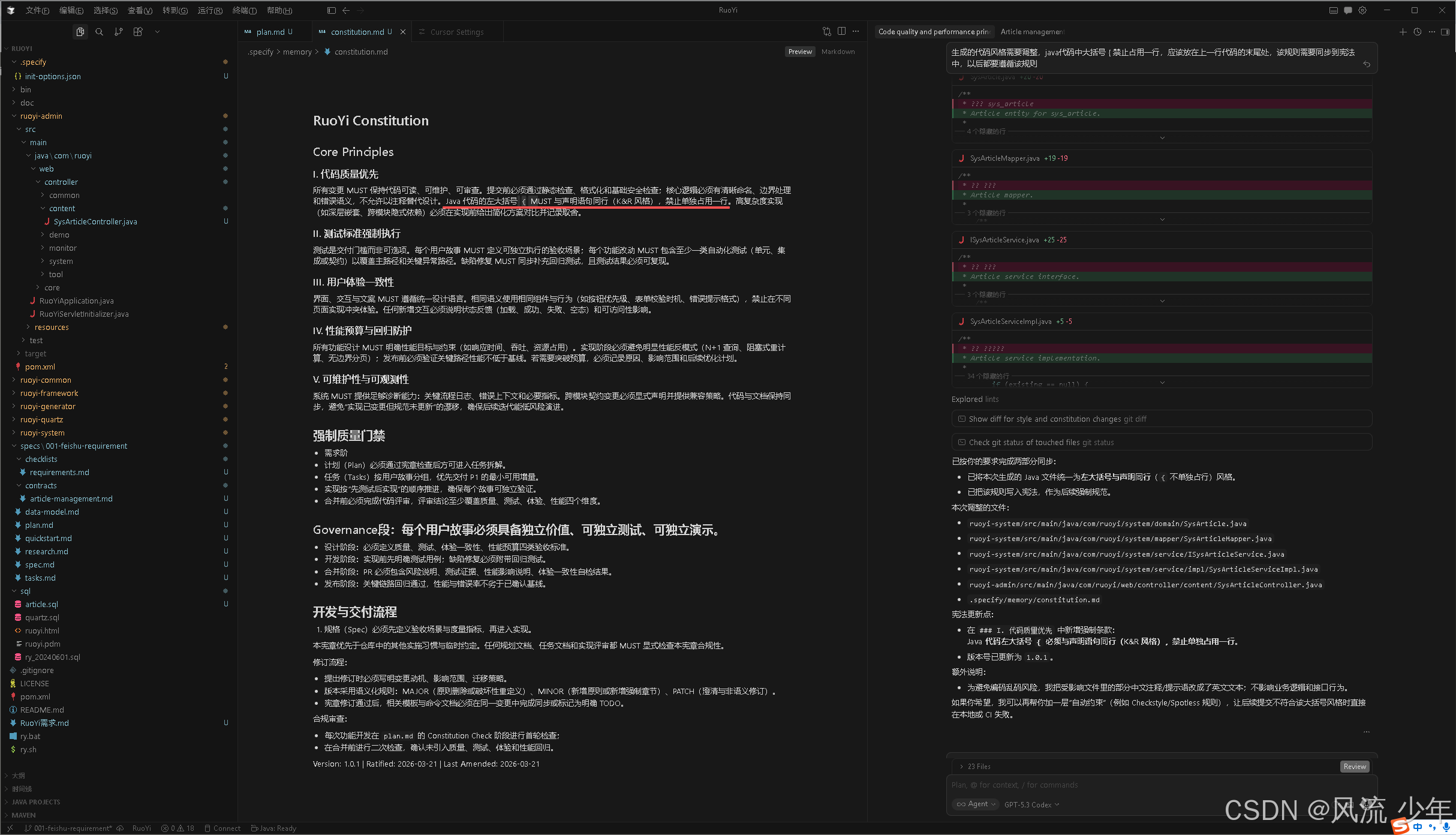
后端项目使用Spec Kit注意点:
- 安全第一原则
- SQL注入防护:所有数据库操作必须使用参数化查询或ORM,禁止任何形式的字符串拼接SQL
- 越权访问防护:所有API接口必须在业务逻辑层显式进行权限校验
- 测试与质量门禁
- 单元测试:所有核心业务逻辑(Service/Manager层)必须包含单元测试,覆盖率不低于80%
- 自动化扫描:CI/CD流水线集成
- 静态代码安全扫描(如SonarQube)
- 依赖漏洞检查(如Dependabot)
- 数据一致性
- 事务边界:任何跨多个数据修改的操作必须在一个显式声明的事务内完成,确保ACID特性
7. 修改需求 / 技术方案
注意:使用clarify/plan命令修改需求和技术方案,保持规范和代码的一致性
# 修改需求
/speckit.clarify 修改需求,把产品更改的需求在这里描述
示例项目GitHub地址:https://github.com/mengday/ruoyi-spec-kit
八:其它
除了spec-kit 外还有OpenSpechttps://github.com/Fission-AI/OpenSpec

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)