深度学习驱动的海洋生物检测与细粒度识别:基于“检测-检索”级联架构的模型开发策略与前沿算法分析
深度学习驱动的海洋生物检测与细粒度识别:基于“检测-检索”级联架构的模型开发策略与前沿算法分析
1. 架构范式与战略基调:从人脸识别到海洋生态监测的知识迁移
在高度动态、视觉退化严重且物种呈现显著长尾分布的海洋环境中,实现对海量海洋生物类别的高精度检测与识别,是当前计算机视觉与海洋生态信息学交叉领域的一项核心挑战。针对这一需求,采用类似于人脸识别中“先检测后识别(Detect-then-Recognize)”的级联架构,不仅在工程学上具有高度的合理性,而且在生物多样性监测的理论框架中也得到了广泛验证与推崇 。
这种将目标定位(Localization)与细粒度分类(Classification/Re-identification)解耦的策略,本质上是一种分而治之的开发哲学。人脸识别系统通常首先利用高召回率的检测器在复杂背景中框出人脸,随后通过独立的特征提取网络将其映射到高维空间进行身份比对。将其平移至海洋生物检测领域,在第一阶段,通过训练一个类别不可知(Class-agnostic)或仅包含少数宏观类别(如“动物”、“底栖生物”)的通用检测器,模型能够最大程度地规避长尾分布带来的样本不均衡问题,专注于学习前景目标与复杂水下背景(如礁石、悬浮物、水体散射)的本质区别 。这一策略受到了陆地红外相机陷阱“MegaDetector”框架的启发,被证明在应对开阔水域中出现的未见物种时具有极强的泛化能力与鲁棒性 。
在第二阶段,面对数十上百甚至成千上万的具体物种类别,如果依赖传统的Softmax多分类器,网络结构会面临严重的参数膨胀问题,且极易导致类间距模糊,无法区分形态极其相似的同属物种。此时,引入度量学习(Metric Learning)或目标重识别(ReID)技术,将高维视觉特征映射至一个紧致的度量空间,通过特征向量的距离计算(如余弦相似度、欧氏距离)来确定具体类别,能够有效实现对新类别的大规模扩展与检索 。本报告将立足于上述级联架构,深入剖析数据处理引擎的构建,全面调研闭集与开放世界目标检测(OWOD)的前沿算法,并对纯视觉ReID方案与多模态视觉大语言模型(如CLIP)的优劣势进行详尽分析,最终为您输出一套完整的、具备工业级部署潜力的模型开发方案。
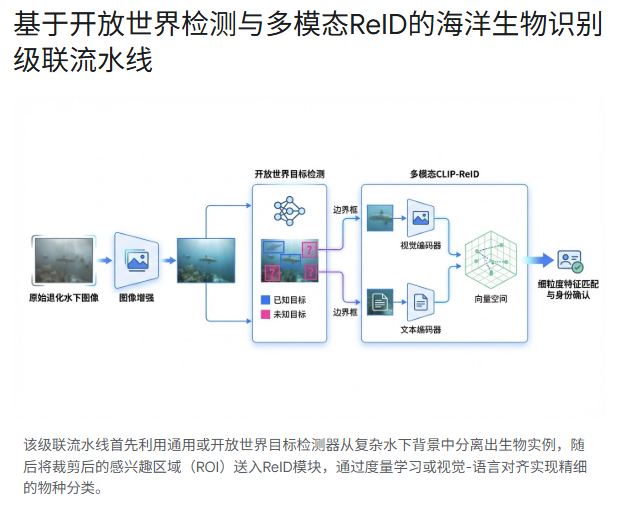
2. 数据处理引擎:应对物理退化与长尾分布的系统性策略
任何深度学习模型的能力上限都由其所摄取的数据质量和分布决定。在水下视觉领域,数据往往带有显著的物理退化噪声与极端的类别不平衡性,这两大痛点直接制约了检测与识别系统的性能底线。因此,在训练模型之前,构建一个强大的数据处理引擎是整个开发策略中不可或缺的首要任务。
2.1 水下图像的物理退化机制与图像增强技术演进
水下成像环境极具挑战性。由于水体介质对不同波长光线的吸收率不同(红光最先被吸收,蓝绿光穿透最深),以及水中悬浮微粒造成的强烈光散射作用,原始水下图像通常会表现出严重的颜色失真(Color Distortion)、细节模糊(Detail Blurring)和对比度骤降(Contrast Degradation)等退化特征 。根据2024至2025年的最新系统性文献综述,当前水下图像增强方法已演化出三大主要阵营:物理模型方法、非物理模型方法以及基于深度学习的数据驱动方法 。
物理模型方法致力于通过模拟光线衰减和散射的物理过程来逆转图像退化效应,虽然在理论上最为严谨,但其对水体光学参数的依赖性极高,且计算复杂度往往无法满足实时处理的需求 。非物理模型则侧重于直接在像素层面进行数学变换,而不深究底层的退化物理过程 。在实际的模型开发策略中,推荐采用一种轻量级且渐进式的色彩校正策略。具体而言,该策略包含自适应颜色量化驱动的全局颜色校正,随后紧跟基于引导滤波(Guided Filter)的局部色彩微调,这一过程能够在恢复准确色彩的同时极大增强视觉感知质量 。在更为复杂的视觉启发式增强框架中,可以将色彩调整后的图像分解为基础层(Base Layer)和细节层(Detail Layer),分别对应低频和高频视觉信息 。系统在细节路径上施加细节增强与噪声抑制,在结构路径上执行全局亮度校正,最后将双路径特征融合以输出高质量的增强图像 。
此外,对比度受限自适应直方图均衡化(CLAHE)等传统增强策略作为数据预处理步骤,已被证明能够显著提升水下微小生物的边缘清晰度与检测召回率 。近年来,联合训练(Joint Training)范式也展现出巨大的工程潜力,例如设计一个轻量级的水下增强模块(Underwater Enhancement Module, UEM),并使其与下游的目标检测器进行端到端的联合优化 。这种模式的优势在于,增强网络不再盲目追求符合人类视觉美学的输出,而是自适应地学习最有利于下游检测器提取边界框的特征表征 。
| 图像增强方法类别 | 核心机制与代表技术 | 优势 | 局限性与挑战 |
|---|---|---|---|
| 物理模型方法 | 模拟光线衰减与散射物理过程;逆向求解退化方程 | 理论基础严谨,在已知水体参数下恢复效果最真实 | 计算复杂度极高,难以满足实时部署需求;参数依赖性强 |
| 非物理模型方法 | 像素级数学操作;渐进式色彩校正、引导滤波、CLAHE | 计算速度快,对低对比度和颜色投射有立竿见影的改善 | 容易引入伪影,无法从根本上恢复丢失的深层次结构信息 |
| 深度学习联合增强 | 数据驱动的端到端学习;UEM模块联合目标检测器优化 | 增强网络输出的特征直接服务于检测精度的提升,表现出极高自适应性 | 需要大规模成对或非成对训练数据;存在跨域泛化性(Domain Generalization)问题 |
2.2 应对数据长尾分布:标注清洗与合成数据策略
在现实的海洋生态系统中,物种的出现频率绝非均匀分布。海洋生物数据集普遍呈现出典型的“长尾分布(Long-tailed Distribution)”特性,即少数常见物种(头部类别,Head classes)占据了绝大多数的图像样本,而大量罕见物种(尾部类别,Tail classes)仅有极少、甚至个位数的观测样本 。例如,在动物识别任务中,收集常规鱼类的图像轻而易举,但获取特定深海罕见底栖生物的图像则极其困难 。
如果在此类分布失衡的数据集上直接驱动深度神经网络进行监督学习,模型极易陷入局部最优:它会对头部类别产生严重的过拟合倾向,而在面对尾部类别时则表现出极低的置信度,甚至将其直接归类为多数类或背景 。为了解决这一顽疾,学术界曾提出了一系列尾部到尾部的迁移学习策略。其中最直接的方法是过采样(Oversampling),例如合成少数类过采样技术(SMOTE)。该方法通过在特征空间中连接现有尾部样本的线段上生成额外的合成样本,以扩充尾部数据量 。随后,诸如ADASYN等变体通过利用尾部类实例的加权分布来指导合成样本的生成方向 。然而,由于尾部类别本身的表征信息极为匮乏,这些传统的过采样插值方法往往会导致严重的过拟合现象 。
针对海洋生物特殊的形态学特征,在有监督的数据增强层面,建议采用一种极度保守但高效的几何变换策略。在处理浮游生物或小型底栖生物图像时,仅应用保持标签语义不变的几何变换,如水平翻转、垂直翻转、180度旋转以及适度的光照强度缩放(例如 −10%、−5%、+5% 或 +10%)。规定每张原始图像仅应用单一变换,这种策略能够将极度稀缺的类别样本扩充至满足最低训练阈值,同时温和地强化罕见分类元的监督信号 。必须严格限制使用强烈的弹性形变或过度激进的随机裁剪,因为这些操作会永久性地破坏对于物种分类鉴定至关重要的形态学线索和细微纹理,导致网络学到错误的特征映射 。
2.3 挖掘无标签数据的潜力:半监督与自监督预训练
既然有监督的数据增强和重采样存在局限性,开发策略的重心应转向如何利用海量未标注的水下视频数据。海洋科学考察积累了极其庞大的视觉素材,但由于缺乏分类学家的专业标注,绝大部分数据处于休眠状态 。将这些无标签数据纳入预训练阶段,是打破长尾分布困境、提升模型泛化能力的颠覆性策略。
在识别网络(第二阶段)的训练中,全面对比四种预训练范式(监督学习、迭代监督学习、自监督学习、半监督学习)后发现,引入基于对比学习的半监督与自监督机制能够带来质的飞跃 。自监督学习(如SimCLR算法)通过构建对比损失,强迫网络识别同一张无标签图像的不同数据增强版本为“相似”,并将其与批次内的其他图像区分开来,从而在缺乏任何人工标签的情况下学习到极具区分度的深层视觉表征 。
更为有效的是半监督预训练策略。例如,采用 PAWS(Predicting View Assignments with Support Samples)算法或结合 SuNCEt 损失的 SimCLR 方法,在对比预训练阶段引入极小比例的高质量监督标注(例如仅占用总数据集10%的标注数据)作为支撑集 。实验数据显示,在真实世界长尾分布的水下数据集上,采用 PAWS 进行半监督预训练并辅以有监督微调,能够在所有物种类别上产生显著提升的“平衡准确率(Balanced Accuracy)” 。具体而言,在处理极度稀有物种(分布的尾部)时,该方法将平衡准确率得分提升了近一倍 。尽管这种为了平衡长尾分布而在特征空间进行的强制对齐有时会以牺牲极其微小的整体准确率(因为模型可能会对某些极度常见的头部类别稍微降低置信度)为代价,但这对于以生物多样性监测和新物种发现为核心诉求的海洋业务系统而言,是一笔极其划算的交易 。
3. 第一阶段开发策略:通用目标检测与开放世界感知网络
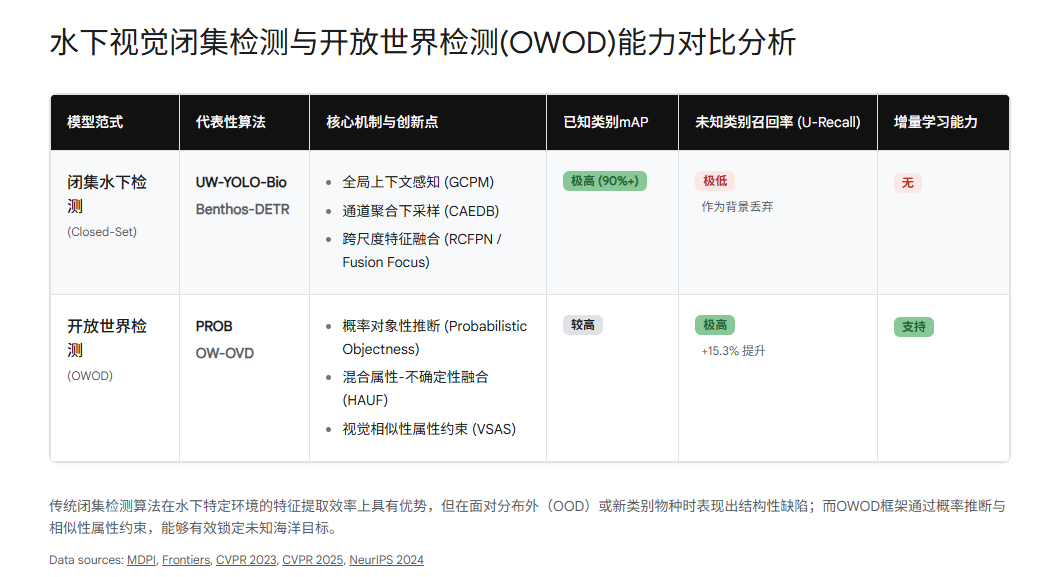
在“先检测、后度量”的级联方案中,第一阶段检测器的唯一且神圣的使命是:以尽可能高的召回率(Recall),将画面中所有潜在的生物个体(无论种类)准确地框选出来,并将它们从复杂的背景中裁剪分离。这一过程直接决定了后续识别系统能否看到目标。针对该阶段的开发,需要对传统闭集检测算法的特化改进以及新兴的开放世界目标检测(OWOD)算法进行严密的对比分析。
3.1 高效水下闭集目标检测算法的定制与特化
如果您的应用场景相对封闭,例如特定的近海养殖场或物种群落极其稳定的海域,采用经过水下环境定制改进的闭集目标检测(Closed-set Object Detection)算法足以胜任。当前工业界和学术界的主流基座依然是 YOLO(You Only Look Once)系列的单阶段检测器(如YOLOv8至YOLOv12)以及基于注意力机制的 DETR(Detection Transformer)系列 。针对海洋生物尺度变化剧烈、对比度低下的问题,近期的算法创新提供了丰富的参考范本。
基于 YOLO 架构的定制模型 UW-YOLO-Bio 提供了一个极具代表性的高性能范例。为了在不引入标准自注意力机制高昂二次方计算成本的前提下捕获全局特征,该模型在骨干网络中创新性地集成了全局上下文3D感知模块(Global Context 3D Perception Module, GCPM)。GCPM 通过协同 C2f 模块、全局上下文块(GCBlock)与通道级 SimAM 机制,能够有效地建立图像中的长距离依赖关系,这对于抵抗水下严重的遮挡和水体噪声干扰起到了决定性作用 。此外,为了防止水下低对比度目标在网络深层的降采样过程中丢失关键信息,UW-YOLO-Bio 部署了通道聚合高效下采样块(CAEDB)。最终,通过区域上下文特征金字塔网络(RCFPN),结合可分离核空间注意力(SKSA)与内容感知特征重组(CARAFE)技术,对多尺度信息进行情境感知融合,极大提升了对微小海洋生物的检测精度 。
在追求极致轻量化与小目标检测能力的维度上,YOLO-WDN(基于YOLOv11改进)提出了 DAPM 模块,将可变形卷积(Deformable Convolution)与通道注意力机制深度融合以增强特征提取 。更为巧妙的是,该模型在检测头设计上直接移除了针对大型目标的检测分支,将全部计算资源倾斜至小目标检测任务,从而在降低计算成本的同时提高了对细小游动生物的捕捉能力 。
另一方面,Transformer 架构在水下场景的潜力也在不断被挖掘。Benthos-DETR 针对底栖生物(如海参、海胆、扇贝)检测,在 RT-DETR 网络基座上引入了级联组注意力机制,强化了同一特征尺度内的信息交互 。其颈部网络使用融合焦点模块(Fusion Focus Module)替代了传统的级联拼接,实现了高效的跨尺度特征融合 。类似地,LSOD 算法将 Mamba 原理(状态空间模型)与 YOLO 结合,利用共享卷积与组归一化设计了极轻量级的检测头,专为算力匮乏的低成本海洋遥感设备打造 。尽管 YOLO 系列在小目标密集检测和绝对推理速度上仍占据微弱优势,但 DETR 系列凭借相对简洁的架构和优雅的端到端注意力机制,在规避 NMS(非极大值抑制)后处理计算瓶颈方面展示出了巨大的潜力 。
| 算法框架 | 核心创新模块与网络结构 | 主要应用场景与优化目标 | 性能表现特征 |
|---|---|---|---|
| UW-YOLO-Bio | 全局上下文3D感知(GCPM);通道聚合下采样(CAEDB);区域上下文特征金字塔(RCFPN) | 复杂海洋背景下抗遮挡、抗噪声,提升微小生物定位能力 | 减少8.3%参数,mAP提升最高2.0%,实时推理帧率达61.8 FPS |
| YOLO-WDN | 动态卷积与注意力融合(DAPM);ODC3K2特征提取;移除大目标检测分支 | 极端注重水下微小目标的召回率,降低冗余计算负荷 | 精度提升3.8%,参数量下降6.7%,FPS提升12.5% |
| Benthos-DETR | 级联组注意力模块;融合焦点特征聚合;基于RT-DETR基座 | 底栖生物(海参、海胆等)的高精度轻量化检测 | 在开源数据集实现超过91.6%的mAP50,有效规避传统CNN局限 |
| LSOD (Mamba-YOLO) | Mamba原理整合;组归一化与共享卷积检测头;跨阶段特征融合 | 专门部署于算力极其受限的水下低成本遥感设备与AUV | 在保持低计算复杂度的同时,对特定底栖生物的精度突破90% |
3.2 拥抱未知:开放世界目标检测(OWOD)的必然趋势
尽管上述闭集检测器在已知类别上表现优异,但在真实的开阔海域生态调查中,系统必然会遭遇大量未曾标注过的、甚至是科学界尚未发现的未知海洋生物(Unknown Marine Objects, UMOs)。传统的闭集检测器受限于训练时的分类标签空间,在面对这些未知生物时,不仅无法识别其类别,更严重的是,它们会将这些具有明显生物特征的前景目标直接错误分类为“背景(Background)”并予以丢弃 。这种结构性的漏检,彻底阻断了后续ReID模块进行识别或发现新物种的可能。
为了从根本上解决这一困境,将第一阶段的检测器升级为**开放世界目标检测(Open World Object Detection, OWOD)**框架,是当前模型开发策略中的前沿共识。OWOD 的核心理念在于打破静态知识库的边界:模型不仅能够精确识别训练集中预定义的类别(已知类,Known Marine Objects),同时具备强大的“新奇性检测(Novelty Detection)”能力,主动发现不属于任何已知类的目标并将其框选,标记为“未知(Unknown)”。更重要的是,当这些被标记为未知的生物图像经过人工标注赋予新身份后,OWOD模型能够通过增量学习(Incremental Learning)机制将其吸收为新的已知类别,且在这个过程中极力避免“灾难性遗忘(Catastrophic Forgetting)”,即不破坏已学到的旧知识 。
当前,OWOD 领域涌现出数个具有里程碑意义的算法架构,可直接作为您方案的第一阶段模型:
- PROB (Probabilistic Objectness) 概率对象性推断架构:针对传统检测器缺乏区分未知物体与背景的监督信号这一痛点,PROB 引入了一种新颖的概率对象性评估框架 。该算法在特征嵌入空间中交替执行两个关键步骤:已知目标概率分布的估计,以及对象性似然的最大化 。这一机制赋予了网络一种通用的“前景感知能力”,使其能够精准地测算不同候选框包含实质性物体的概率,而不是简单地将其非黑即白地划分为特定已知类或背景。在标准OWOD基准测试中,基于Transformer的PROB检测器将未知对象的召回率(Unknown Recall)提升了近2倍,同时也将已知物体的mAP提升了约10% 。在水下环境的实证研究(如连续水面/水下目标检测)中,PROB算法在未知目标识别和增量学习能力上显著超越了主流方法 。
- OW-OVD 统一开放感知框架:这是一种试图融合开放世界目标检测(OWOD)的主动未知探索能力,与开放词汇目标检测(Open Vocabulary Object Detection, OVD)零样本泛化能力的最新力作 。为了在标准检测器上实现这一壮举,该模型提出了**视觉相似性属性选择(VSAS)方法。在迭代训练中,VSAS通过计算已人工标注区域与未标注候选区域之间的相似度分布,并辅以相似性约束保证属性的多样性,精准甄选出最具备跨类别泛化能力的通用特征属性 。随后,模型利用混合属性-不确定性融合(HAUF)**机制,将这些泛化属性的相似度得分与模型对已知类分类预测的不确定性结合起来,联合推断出当前目标属于“未知海洋生物”的绝对似然度 。评估结果令人瞩目,OW-OVD 在两项核心指标上实现了大幅跨越:未知对象召回率(U-Recall)飙升了 +15.3,未知类别平均精度(U-mAP)也大幅提升了 +15.5 。
- 模型行为预测与深层归因网络(UMB):为了进一步打开OWOD预测未知类别的“黑盒”,最新研究开始对检测器的预测行为进行数学建模 。UMB架构不仅预测候选框是否为对象,还构建了经验概率分布、分布内(In-distribution)置信度以及分布外(Out-of-distribution, OOD)概率的多维联合决策边界 。这种深度的概率建模让开发者能够逆向推导出一个未知海洋生物在特征空间上与哪种已知鱼类最为相似,以及究竟是目标的哪一种属性特征促使模型做出了“未知”判定 。这种机制在真实世界测试中将未知类别的绝对mAP提高了5.3 。
综合考量,在包含海量且持续增长类别的海洋场景下,选择部署如 OW-OVD 或 PROB 这样的开放世界检测器,是确保系统具备长生命周期和新物种发现能力的最优策略。
4. 第二阶段:海量类别的细粒度重识别(ReID)与度量学习范式
当第一阶段的开放世界检测器成功将画面中各式各样的生物目标裁剪为一个个感兴趣区域(ROI)后,系统进入了挑战最为严峻的第二阶段:确定这些生物极其具体的物种类别。海洋生物学家面临的鉴定难题在于,不同生物可能共享着绝大多数宏观特征(如体型、鳍的分布),而区分物种的线索往往隐藏在极细微的局部斑纹或骨骼构造中;这本质上是一个细粒度视觉识别(Fine-Grained Visual Recognition, FGVR)任务 。在面对海量类别时,放弃传统的Softmax硬分类器,全面转向度量学习(Metric Learning)进行特征向量的聚类与检索匹配,是当前最合理的工程策略。在这个赛道上,纯视觉算法的极致深耕与多模态基础模型的降维打击展现出了不同的技术魅力。
4.1 纯视觉度量学习范式与损失函数工程
在纯视觉重识别(Pure Vision ReID)策略中,算法工程师不需要借助任何外部语言知识库,而是完全依赖卷积神经网络(CNN)或视觉Transformer在海量像素中发掘微观拓扑规律。由于摒弃了分类全连接层,纯视觉度量学习的核心全部浓缩在损失函数(Loss Function)的设计上,它负责指导网络将原始图像非线性地映射到一个高质量的特征嵌入空间(Embedding Space)。在这个空间内,算法要求具有相同身份(同一物种)的图像特征向量紧密聚拢(类内方差极小化),而不同类别特征向量之间被强行推开(类间方差极大化)。
现有的纯视觉度量学习损失函数主要沿着两条脉络演进: 基于配对的损失(Pair-based Losses):以对比损失(Contrastive Loss)和三元组损失(Triplet Loss)为代表 。三元组损失的核心思想是随机抽取一个“锚点(Anchor)”样本,同时抓取一个同类别的“正样本(Positive)”和一个不同类别的“负样本(Negative)”。优化目标是迫使锚点与负样本之间的距离,严格大于锚点与正样本的距离加上一个预设的硬性裕度(Margin)。这种策略的优势在于能够极度细致地利用数据点之间深层次的局部语义联系。然而,其代价是灾难性的训练复杂度。为了让模型持续学习,必须在每个批次中执行复杂的硬负样本挖掘(Hard Negative Mining)去寻找那些容易被模型混淆的样本对。这导致训练对数量呈几何级数(O(N2)O(N^2)O(N2) 或 O(N3)O(N^3)O(N3))爆炸式增长,使得模型收敛极度缓慢且难以训练稳定 。
基于代理的损失(Proxy-based Losses):为了解决配对损失的效率瓶颈,学术界提出了如 Proxy-NCA 等基于代理的方法 。这类方法放弃了样本间的直接对比,转而在特征空间中为每个类别静态设置一个虚拟的“代理(Proxy)”中心点,所有的样本只与其对应的代理中心进行对比优化。这极大加速了收敛速度并增强了训练可靠性,但代价是彻底丢失了对细粒度识别至关重要的样本到样本(Data-to-data)的直接相对空间关系 。
为了在超大规模海洋生物类别上实现最优开发策略,本报告强烈推荐采用结合二者优势的前沿损失架构,如 Proxy-Anchor Loss(代理锚点损失) 或引入几何角度边距的 ArcFace 框架 。Proxy-Anchor Loss 巧妙地保留了代理机制以维持高效的训练速度和对异常噪声标签的强鲁棒性;但在反向传播更新时,它允许属于同一代理的各个实际数据特征向量通过梯度惩罚项产生相互作用。这意味着网络在加速收敛的同时,重新获得了挖掘复杂数据点之间内在结构关系的能力,在多个细粒度公共基准测试中达到了顶尖的收敛速度和检索精度 。此外,由于海洋动物在三维水体中呈现自由游动状态,其旋转角度千变万化(与陆地上始终保持直立行走的人类截然不同),因此在特征提取骨干网络中嵌入 RotTrans 等专门用于学习旋转不变(Rotation-invariant)表征的模块,能够在水下ReID场景中取得决定性的性能优势 。
4.2 多模态视觉-语言大模型(VLM/CLIP)的跨界打击
尽管纯视觉度量学习在闭门造车式地深挖特征像素,近年来以 CLIP(Contrastive Language-Image Pretraining)为代表的视觉-语言大模型彻底颠覆了视觉特征表达的传统认知边界。多模态方案通过利用自然语言这一拥有无限可能性的高维语义空间来指导视觉特征的学习,为海洋生物分类带来了降维打击般的零样本(Zero-shot)泛化能力。
在将CLIP应用于细粒度图像重识别(ReID)任务时,研究者首先面临一个严峻的阻碍:传统的ReID数据集标签仅仅是毫无语义的数字索引(Index),缺乏针对图像内容的具体文本描述,这使得CLIP强大的文本编码器似乎毫无用武之地 。然而,前沿算法 CLIP-ReID 提出了一种极具创造性的双阶段微调策略,完美跨越了这一鸿沟:
- 隐式语义构建阶段:为每一个数字物种ID分配一组随机初始化的可学习文本令牌(Learnable Text Tokens)。在第一阶段训练中,严格冻结CLIP庞大的图像编码器和文本编码器,唯一允许发生改变的是这些文本令牌 。网络在一个批次内通过跨模态的对比损失从头优化这些令牌,迫使它们在文本编码器内部“翻译”成能够精确描述对应ID视觉特征的高维向量。这些令牌最终形成了一种对于人类而言不可读,但对模型而言高度判别性的“模糊语义描述” 。
- 约束视觉微调阶段:在第二阶段,将第一阶段学习到的特定ID文本令牌及其对应的文本编码器彻底固定,将其作为空间锚点或静态约束。此时解冻并微调图像编码器。在下游任务设计的特殊损失函数引导下,图像编码器被强制将其提取的视觉数据向量化,并精准地镶嵌到由文本语义搭建好的特征度量空间中 。
除了通用 CLIP 架构,针对极度缺乏标准语料库的海洋科学领域,特化的领域级基础模型也已破茧而出。AquaticCLIP 就是其中的标志性成果。研究团队从极其庞杂的异构资源(涵盖1200余部海洋学与珊瑚礁专著、国家地理纪录片、YouTube水下素材等)中,提取并构建了包含高达200万对水下图像-文本描述配对的超级数据集 。在不依赖任何高成本人工边界框精确标注(Ground-truth)的前提下,AquaticCLIP 完成了针对水下光学退化特性的原生领域预训练 。该模型摒弃了简单的特征拼接,创新性地设计了提示词引导视觉编码器(Prompt-guided Vision Encoder, PGVE)机制。通过一系列可学习的视觉提示网络,模型能够根据深层语言逻辑逐步聚合和强调图像中的关键斑块(Patch)特征。这种视觉反馈语言、语言指导视觉的双向强化,使得 AquaticCLIP 在识别深海极端模糊环境下的长尾物种时,展现出了纯视觉模型难以企及的零样本鲁棒性 。实验表明,即使对于某些在生物分类学数据库(如WoRMS)中仅存有不到10张残缺图像的稀有十足目甲壳类动物,这种多模态预训练先验依然能够提供具有高度竞争力的分类精度 。
4.3 部署权衡:知识蒸馏(Knowledge Distillation)化解算力困境
面对纯视觉方案与多模态CLIP方案,您的模型开发策略必须在“数据泛化能力”与“硬件部署极限”之间做出残酷的权衡。 CLIP方案的优势无可比拟:它极大地降低了对成规模高质量标注数据的依赖,甚至可以依据专家的文本特征描述直接关联未见物种 。然而,其致命缺陷在于极其庞大的计算负担。一个标准的CLIP-ReID教师模型体积动辄接近半个GB(例如477 MB的庞大权重参数),如果将其强行部署在能源与算力双重受限的自主水下航行器(AUV)或低功耗遥感观测节点上,根本无法满足高帧率实时推理的工程底线,会导致系统严重卡顿甚至宕机 。相反,纯视觉CNN模型(如轻量级ResNet或MobileNet变体)在推理速度和内存占用上拥有天然优势,但泛化上限不足。
破解这一死局的最佳工程路径是实施**知识蒸馏(Knowledge Distillation, KD)**范式。在云端或高性能计算中心,您可以投入充足的算力训练一个完整、庞大的基于CLIP-ReID的多模态网络作为教师模型(Teacher)。随后,构建一个极其紧凑的纯视觉度量学习网络作为学生模型(Student)。在蒸馏训练过程中,学生模型不仅要学习匹配真实的物种标签,更要努力模仿教师模型在高维空间输出的软概率分布与深层特征拓扑图景。研究数据表明,通过这种跨模态的信息传递,可以将原本重达 477 MB 的复杂多模态逻辑,完美压缩并刻录进一个体积仅为 1.97 MB(参数量骤减约 242 倍)的超轻量级纯视觉网络中 。这个极度袖珍的学生模型不仅在边缘设备上运行如飞,其最终在各大ReID公开基准测试中的精度表现,与庞大的CLIP教师模型相比仅有极其微弱、甚至可以忽略不计的性能衰减 。

5. 全链路模型开发策略与实施路线图
在透彻理解了数据预处理、开放世界检测架构以及多模态重识别度量空间的底层逻辑后,针对您面临的海量海洋生物类别识别任务,本报告为您梳理出以下具备极高实战价值的系统性实施路线图。
5.1 注入领域先验:层次化分类网络架构(Hierarchical Classification)
在真实的海洋生态鉴定中,即使是最强大的度量学习模型也偶尔会在形态极端相似的近缘物种之间产生灾难性的特征混淆。生物分类学本身并非扁平的列表,而是一棵严谨的树形本体拓扑结构(界、门、纲、目、科、属、种)。在开发模型时强行剥离这种结构关系是极不明智的。将层次化分类机制(Hierarchical Classification)深度融合进ReID网络,是提升大尺度检索准确率的核心技巧 。
该策略主张放弃让网络“一步到位”直接预测最细粒度的物种索引标签。相反,应当通过多任务学习分支,要求特征网络首先输出一个较高置信度的广义生物集群或科级(Family level)分类预判,然后在这一宏观类别的概率条件约束下,再利用度量层细分到具体的种级(Species category)。这相当于在特征前向传播时,利用自顶向下的先验知识数据库强制规划出一个树状的决策分支 。此外,在进行大规模特征向量检索引擎构建时,可引入基于概率主成分分析(PPCA)的层次模型。该模型假设各图像类别服从高斯分布,先将目标测试样本分配至最有可能的超级类(Super-class),随后在子类簇内部使用马哈拉诺比斯距离(Mahalanobis distance, r(x;μ,Σ)=(x−μ)TΣ−1(x−μ)r(x; \mu, \Sigma) = (x - \mu)^T \Sigma^{-1} (x - \mu)r(x;μ,Σ)=(x−μ)TΣ−1(x−μ))进行精准检索。这种策略不仅能通过引入结构性约束消除错误候选池,还能在计算层面规避毫无意义的全局暴力特征对比,将系统检索速度呈指数级提升,且不损失任何细粒度精度 。
5.2 跨域动态适应:基于 CLIP 引导的模型自适应选举机制
海洋的地理跨度注定了水下视觉场景的极度非均质性。从漆黑浑浊的深海热液喷口、光照充足且色彩斑斓的浅水珊瑚礁,到存在大量人造结构干扰的近海浑浊水域,光学参数的变化是极其剧烈的。期待单一网络权重在所有海域工况下均达到最优性能是不切实际的。近年来发布的 FishDet-M 大型统一基准测试(整合了13个公开水下数据集,囊括105,556张图像与海陆空多维生境)为跨域检测提供了一条创新路径 。
借鉴该框架,您的系统管线应在前端部署一个动态多域模型选择器。该机制摒弃了传统耗时费力的多模型集成计算(Ensemble),转而利用轻量化环境分类器或直接调用多模态 CLIP 模型的零样本理解能力,对当前采集到图像的水体底色、悬浮物浓度、光照散射等上下文语义特征进行秒级瞬时评估。随后,系统根据评估结果,以极低的延迟动态调用预设在缓存中的、最匹配当前水文视觉域的检测器与ReID权重组合进行推理 。这种上下文感知的机制赋予了检测管线卓越的跨域环境自适应弹性。
5.3 从实验室到海床:端到端四阶段训练路线部署
综合上述前沿探索,您的海洋生物检测与识别项目应严格遵循以下四阶梯度的工程开发范式进行落地:
- 第一阶段:特征基座的无监督锚定。 疯狂收集所有可见的水下图像与视频帧,不论其是否带有精确的人类专家分类标注,亦或是仅仅模糊记录了采集坐标与深度。投入计算资源,利用如 SimCLR 配合 PAWS 算法构建自监督与半监督的对比预训练管道,或者直接使用包含200万配对数据的 AquaticCLIP 多模态权重作为网络初始化基座。这一步决定了模型未来抵抗恶劣光学干扰与抗长尾分布的根本上限 。
- 第二阶段:概率性对象感知的 OWOD 检测器培育。 摒弃传统的闭集检测思维,转而在数据引擎处理过的增强图像上,采用 PROB 或 OW-OVD 架构训练开放世界检测模型 。重点引导网络通过混合属性-不确定性融合(HAUF)机制,精准分割出具备任意生物特征的独立前景斑块,即便它面对的是图库中从未收录的新奇深海物种 。
- 第三阶段:文本隐式对齐的多模态 ReID 空间映射。 将由检测器源源不断输送出来的目标切割框汇聚为检索库。引入 CLIP-ReID 的两阶段训练策略,利用带有对比约束的可学习文本令牌,凭空建立一张不可见的高维语义坐标网。同时运用带有结构互动惩罚的 Proxy-Anchor 损失函数,取代繁重的三元组硬负样本挖掘,指引视觉编码器将庞杂的生物类别高效且秩序井然地安插到这个度量空间之中 。
- 第四阶段:向受限硬件降维的知识蒸馏落幕。 一切云端的繁华终需落地于深海的铁盒。在算法指标稳定后,彻底冻结多模态教师大模型的权重。精心构筑极其精简的纯视觉目标检测头与特征检索网络作为学生模型,通过软标签与特征分布迁移实施知识蒸馏。将参数量极致压缩两百倍后,应用 TensorRT 框架进行半精度(FP16)乃至整型(INT8)算子级量化,最终搭载至 AUV 的边缘计算芯片之中,实现水下低延迟、高精度的生物多样性智能监控 。
6. 结论
将发源于陆地安全防御领域的人脸识别系统架构——“先检测、再特征度量检索”的设计哲学,通过底层算法的基因重组迁移至极具挑战的光学退化海洋场景,已经被证明是一条不仅极具理论高度,且工程落地性极强的康庄大道。本报告的深度技术侦察确认:在管线的前哨阵地,应用诸如 PROB 或 OW-OVD 这样具备强大概率对象性推理机制的**开放世界目标检测(OWOD)*框架,是突破罕见物种漏检魔咒、捕获未知生态多样性目标的唯一钥匙。而在管线的中枢地带,面对物种类别爆炸且呈极度长尾分布的检索深水区,利用蕴含海量人类语料认知的多模态基础大模型(如CLIP)进行零样本空间对齐,同时结合极简高效的纯视觉学生网络实施*跨模态知识蒸馏与基于代理(Proxy-Anchor)的细粒度度量学习,构建了最无坚不摧的识别引擎。这套由图像增强纠偏、层次化分类先验以及动态域适应机制层层包裹的现代级联神经架构,不仅在面对极其生僻甚至未命名物种时保持了敏锐的嗅觉,也毫不妥协地兼顾了深海边缘节点在严苛算力红线下的实时推理诉求,为次世代智能海洋生物生态普查平台的构建刻画了标准的终极蓝图。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)