Linux线程基本概念
一、Linux下的进程与线程
进程统管运行起来的程序,也就是PCB+代码数据的结构,在OS视角来看,进程是承担系统资源分配的实体。
一个进程中可能存在多个main入口,这多个main入口都能调动资源形成各自相对独立的“小进程”,在Linux中,这种“小进程”被称为轻量级进程,也就是线程。线程是OS调度的基本单位。
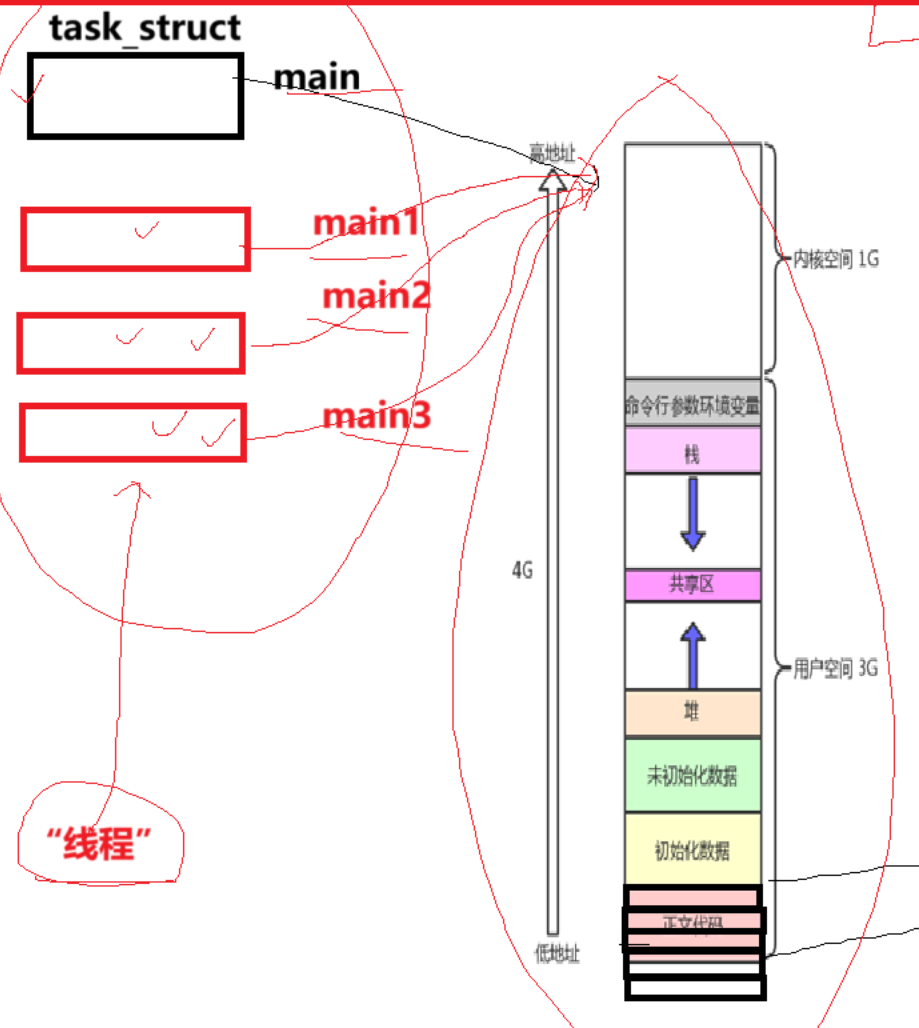
Linux在设计的时候,工程师发现进程与线程之间很相似,就认为没有必要为线程单独创建一个数据结构,转而是复用进程PCB达到轻量化目的,这也导致Linux下的线程严格点来讲应该叫做轻量级进程而不是线程的缘故。
进程=多个线程+地址空间+页表+代码数据=一个或多个轻量级进程+其它资源,我们之前学习的进程大多数内部只有一个执行分支,是进程中较为特殊的一种。但站在CPU角度来看,其根本不需要区分进程与线程,两者经过CPU的时候都是以执行流的方式经过。
Linux系统中,执行流就是轻量级进程。线程是进程内核数据结构模拟出来的。
二、页表与存储管理
在文件操作部分我们讲过,磁盘与内存之间的数据交流是以块为基本单位,一个块一般是4kb,4096字节。内存为了跟磁盘对齐,其最小基本单位页框也是4kb来划分存储空间。
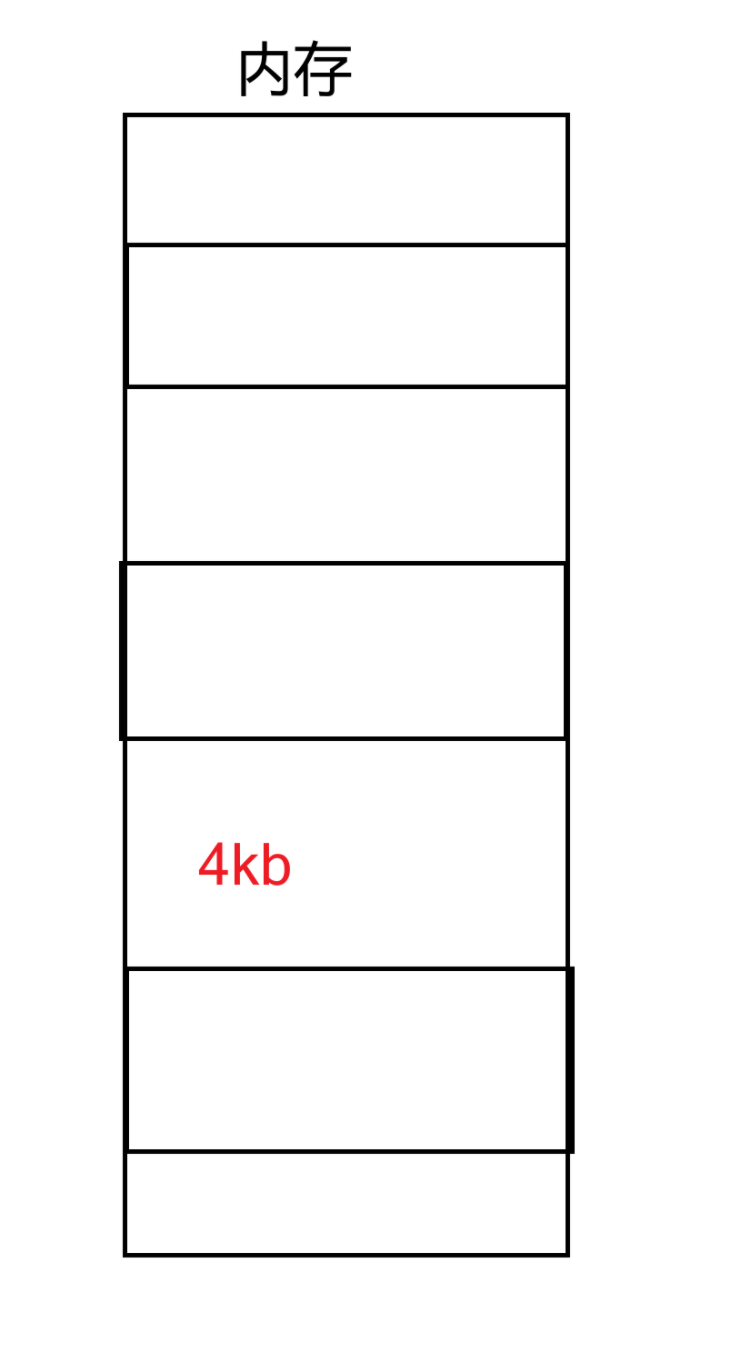
内存中的页框也需要管理,Linux 内核为每个物理页框分配一个 struct Page 结构体,用于描述页的状态(是否被占用、是否脏页、是否被缓存等)。
所有 struct Page 组成一个全局数组 struct page mem[1048576],数组下标与物理页框一一对应:页框物理地址 = 数组下标 × 4KB;任意物理地址 & ~0xFFF 即可得到页框基地址,进而通过地址换算找到对应的 struct Page,快速查询页属性。
Linux内核针对mem数组体积可能过大的问题,采取了多层优化:
1、按内存区域/NUMA节点拆分全局数组,避免单一大数组占用连续内存;
2、核心通过稀疏内存模型将连续数组改为按内存段按需分配的稀疏数组,仅为实际存在的内存段创建`struct page`;
3、同时仅为可用页框(排除预留/坏块内存)创建结构体,将mem布局在低地址内存区,并压缩`struct page`结构体体积,既保证物理内存管理效率,又适配从几百MB到TB级的内存场景,彻底解决数组体积过大问题。
伙伴系统
伙伴系统就是把整个物理内存按 2 的幂次大小(1 页、2 页、4 页、8 页……)分成若干内存块,并把相同大小的空闲块用链表管理起来;当进程需要连续物理页时,就从对应大小的链表中找一块,若没有则拆分更大的块;当内存被释放时,系统会检查相邻是否有大小相同、地址连续、来自同一块拆分的伙伴块,如果有就立即合并成更大的块,从而避免长期存在大量零散小碎片,保证后续能顺利分配到大块连续物理内存。
二级页表
如果只用一级页表管理虚拟地址:页表项数量 = 4GB / 4KB = 1,048,576 项,每项 4 字节总大小 = 4MB,每个进程都要一份完整 4MB 页表,哪怕它只用到几 MB 内存,也得占 4MB,100 个进程就会吃掉 400MB 纯页表开销,开销巨大。
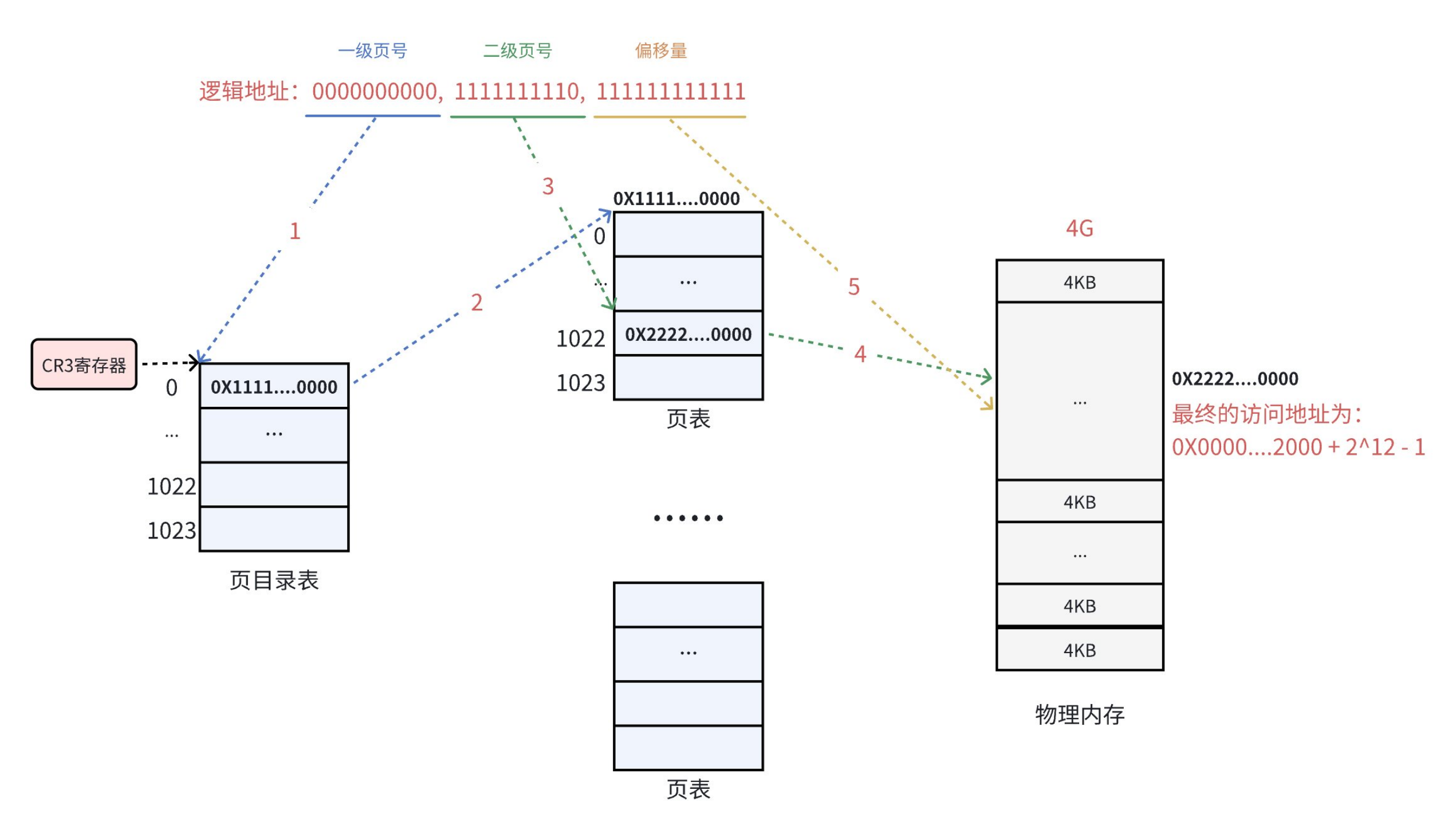
在这种问题之下,Linux设计了二级页表结构,页目录+页表:
在32位平台下,虚拟地址是32字节,二级页表把地址拆成 10 位页目录 + 10 位页表 + 12 位偏移:每个进程只需要1 个页目录(4KB),只有用到的虚拟地址区域,才去创建对应的页表(4KB)(懒加载!),比如进程只用到代码段 + 栈,总共几十 MB,那只需要几个页表,总页表体积远小于 4MB。
二级页表加上懒加载能很好解决页表体积过大的问题。
32字节虚拟地址:10+10+12
一个虚拟地址是32字节,我们按照10+10+12的方式分成三段:
第一段:高 10 位 → 页目录索引
位置:第 31 位~第 22 位作用:在页目录里找 “第几个页表”
- 10 位能表示多少个?2¹⁰ = 1024 个
- 所以页目录里有 1024 个项
- 每项 4 字节 → 页目录总大小 = 4KB
第二段:中 10 位 → 页表索引
位置:第 21 位~第 12 位作用:在页表里找 “第几个物理页框”
- 同样 10 位 → 1024 个项
- 每个页表大小 = 1024 × 4B = 4KB
第三段:低 12 位 → 页内偏移
位置:第 11 位~第 0 位作用:在 4KB 的物理页里,定位具体是第几个字节
- 12 位能表示:0 ~ 4095
- 刚好覆盖一页大小:4KB
一般来说,只要是 4KB 对齐的地址(物理页框、页目录、页表的起始地址),因为都是 2¹² 的整数倍,所以低 12 位固定为 0;而虚拟地址里的低 12 位是页内偏移,不是起始地址,因此可以不为 0。
根据这个特性,我们可以使用位运算得到我们想要的部分:
| 用途 | 位运算表达式 | |
|---|---|---|
| 取页目录号 | (32 位虚拟地址>> 22) & 0x3FF(F=1111) | |
| 取页表号 | (32 位虚拟地址>> 12) & 0x3FF | |
| 取页内偏移 | 32 位虚拟地址 & 0xFFF | |
| 构造物理页框起始地址 | 物理页号 << 12 | |
| 合成最终物理地址 | (物理页号 << 12) | (32 位虚拟地址 & 0xFFF) |
这样一来,我们就能过实现物理地址和虚拟地址的相互转化。
那页目录地址又怎么获取呢?
CR3寄存器
每个进程创建时,内核会给它分配 一个 4KB 的物理页存放页目录。这个页的物理地址就是 页目录地址。进程切换时,CPU 把这个地址写入 CR3 寄存器,之后进行地址翻译时,硬件直接从 CR3 读取页目录地址。
注意CR3中存放的就是真实物理地址,不是虚拟地址。CR3寄存器的上下文就是进程上下文。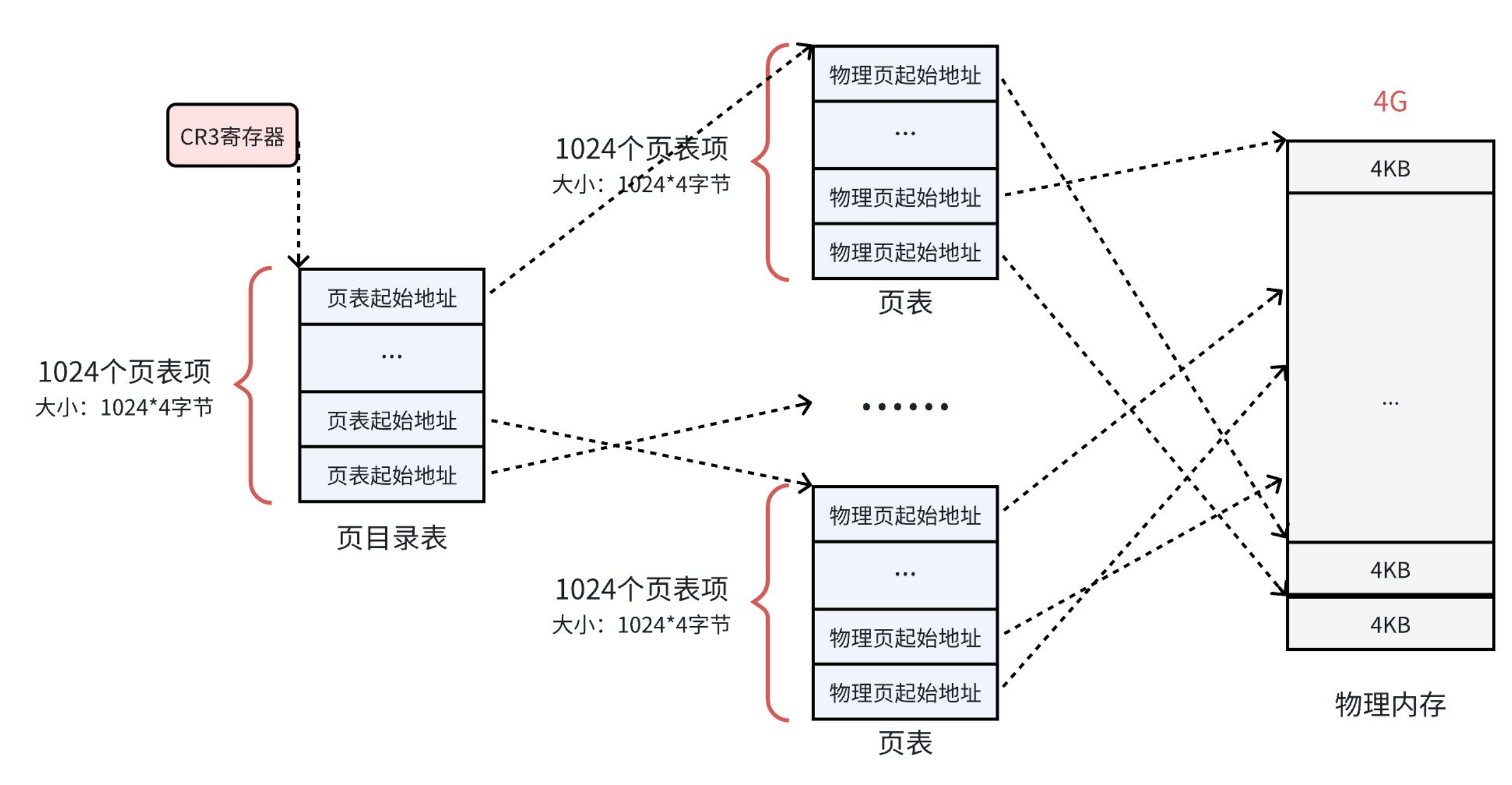
再看页表
页表是进程看到内存资源的窗口,它的核心作用可以从这几个角度理解:
-
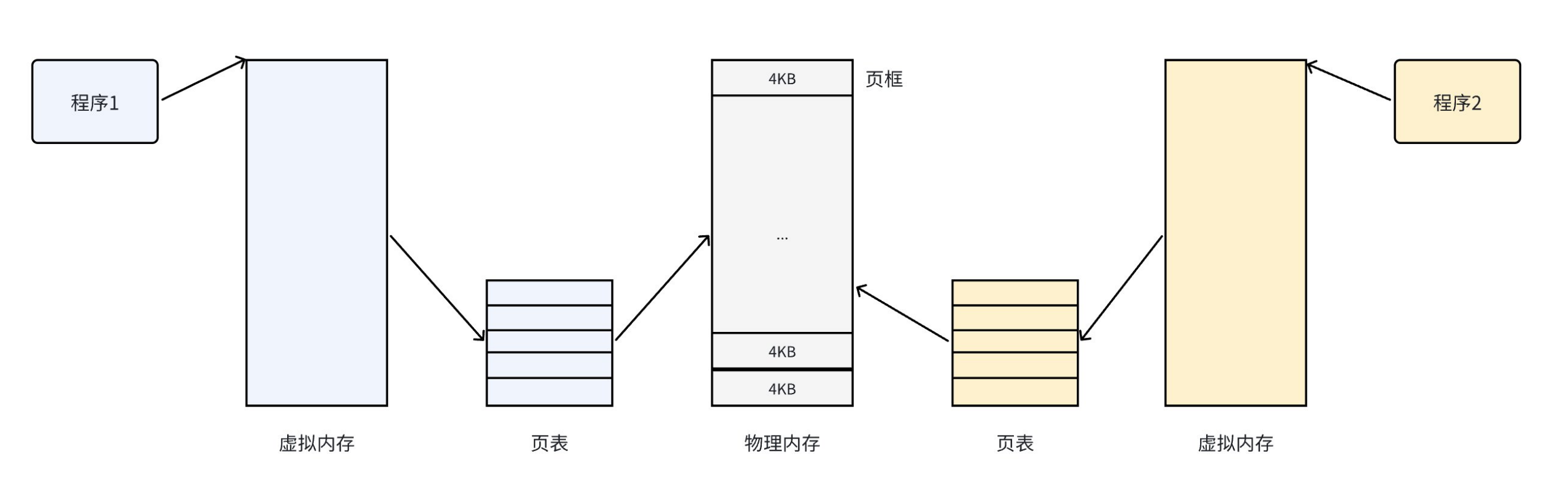
虚拟地址与物理内存的映射桥梁进程拥有的虚拟地址空间越大,理论上可映射的物理内存就越多;页表负责把进程的虚拟地址,逐一翻译成物理内存地址,让进程能安全、隔离地使用内存。
-
内存区域划分的载体页表会按代码段、数据段、栈、堆等不同功能,划分虚拟地址区域,让不同用途的内存访问互不干扰,保证进程运行的稳定性。
-
多执行流(线程 / 轻量级进程)共享与隔离的基础不同的 PCB(线程 / 轻量级进程)可以共享同一个进程的虚拟地址空间,同时又能通过页表执行进程代码的不同部分(比如不同函数),既实现了资源共享,又保证了执行流的独立。
-
进程隔离的保障每个进程都有自己独立的页表,这意味着不同进程的虚拟地址空间完全隔离,一个进程的内存操作不会影响到其他进程,这是操作系统稳定运行的核心保障。
Linux上的线程
正如上面所说,Linux上严格并不存在线程这一概念,他复用task_struct模拟实现线程的功能并做到轻量化便于维护。
但由于市面上如Windos操作系统还是将线程这一概念单独拎出来并进行传播,这就导致Linux陷入一个比较尴尬的情况。
为了迎合市场符合用户习惯,Linux在用户态实现了一个thread库,以满足用户的使用习惯。这个库划分于POSIX 标准库,使用的时候需要进行链接(新编译器会默认处理)。
clone函数
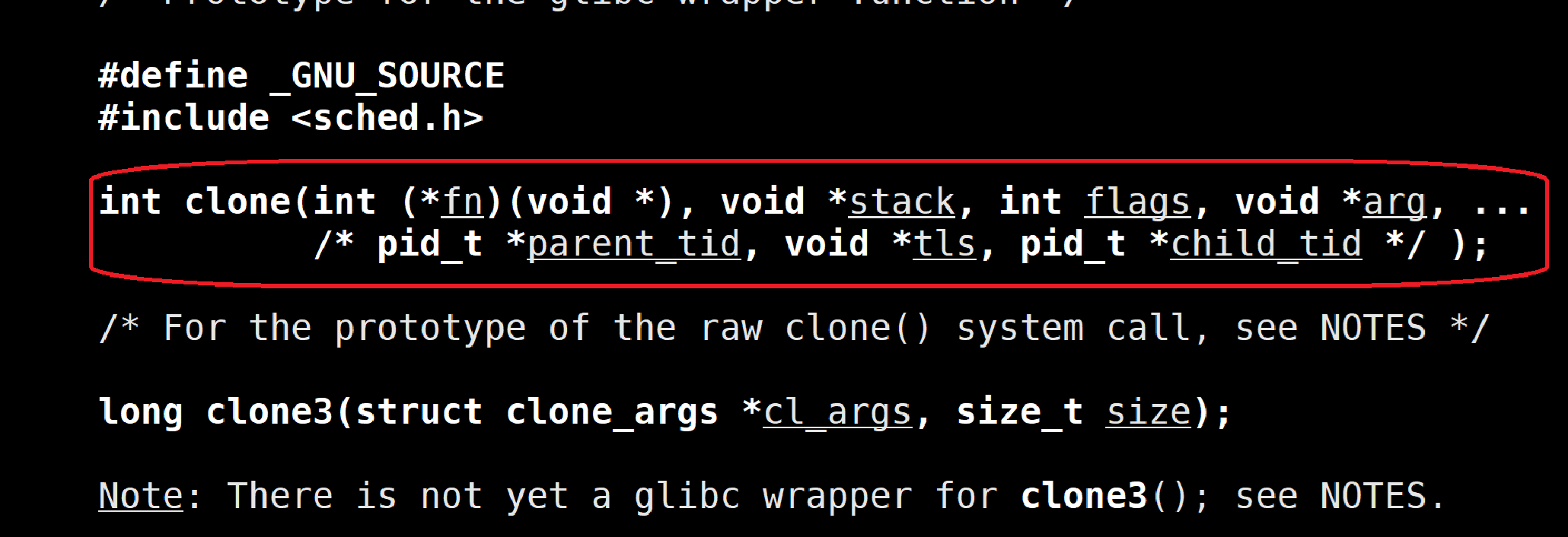
clone函数是 Linux 内核提供的创建轻量级进程 / 线程的底层系统调用,也是 pthread 库实现线程的核心依赖。
| 参数名 | 类型 | 核心作用 | 关键说明(线程 / 进程差异) |
|---|---|---|---|
fn |
int (*)(void *) |
新执行流(线程 / 轻量级进程)要执行的函数入口地址 | 线程必须指定,进程(fork 等价)无需指定 |
child_stack |
void * |
给新执行流分配的栈空间起始地址(栈顶) | 线程必须传独立栈(栈向低地址生长,需传栈顶);进程传 NULL(复用父栈) |
flags |
int |
资源共享 / 隔离的核心标志位(宏组合) | 决定是创建 “进程” 还是 “线程”,核心宏见下方子表 |
arg |
void * |
传给 fn 函数的参数 |
仅线程场景有效,进程场景无意义 |
pid(可选) |
pid_t * |
用于返回新执行流的 PID/LWP ID | 扩展参数,通常可省略 |
tls(可选) |
struct user_desc * |
线程本地存储(TLS)描述符 | 仅线程场景需要,进程无需 |
ctid(可选) |
pid_t * |
指向子线程的 CLONE_THREAD 标识 | 内核内部使用,用户态极少用到 |
flags核心标志位
| 标志位宏 | 含义 | 线程(轻量级进程) | 独立进程(fork 等价) |
|---|---|---|---|
CLONE_VM |
共享虚拟地址空间(页表) | ✅ 必选 | ❌ 禁用 |
CLONE_THREAD |
加入同一个线程组,共享线程组 ID | ✅ 必选 | ❌ 禁用 |
CLONE_FS |
共享文件系统信息(当前目录、umask) | ✅ 必选 | ❌ 禁用 |
CLONE_FILES |
共享文件描述符表 | ✅ 必选 | ❌ 禁用 |
CLONE_SIGHAND |
共享信号处理函数表 | ✅ 必选 | ❌ 禁用 |
CLONE_PARENT |
新执行流与父进程拥有相同的父进程 | ✅ 必选 | ❌ 禁用 |
CLONE_CHILD_CLEARTID |
子线程退出时清理线程 ID | ✅ 可选 | ❌ 禁用 |
CLONE_SYSVSEM |
共享 System V 信号量 | ✅ 可选 | ❌ 禁用 |
0(无标志) |
无资源共享,完全隔离 | ❌ 禁用 | ✅ 必选(等价 fork) |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)