常见Loss函数和大模型Loss计算过程
1.交叉熵损失函数
适用于多分类模型(transformer也很好)。进行一个累加,只有累加到真实类别时,Ti才是1,其余都是0,我们就可以观察对这一真实类别预测的概率,如果概率接近于1,那么损失也就接近于0,如果概率接近0,损失就接近无穷大了

2.二元交叉熵
这个就比较适用于而分类模型,如果真实值为1,就取左边的-log,真实值为0,就取右边的-log

3.均方误差损失
这个就适用于那种单输出的神经网络了,例如预测未来的天气等
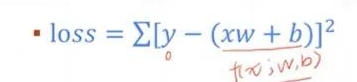
4.Transformer中怎么进行更新
1.对于预训练模型
预训练一般就是在网上爬数据,爬大量的文本,我们先要对文本进行预处理:
1. 采集与格式统一
- 从网页、书籍、论文、代码库、论坛等拉取内容
- HTML/PDF/Office 等先转成纯文本或结构化正文(去标签、抽取段落)
2. 清洗(Cleaning)
- 去乱码、乱码字符修复
- 统一编码(UTF-8)
- 去广告、导航、页脚、重复导航栏(网页尤其重要)
- 规范化空白与换行(多余空格、不可见字符)
3. 质量与合规过滤(Filtering)
- 语言检测:只要目标语言或按比例混合多语
- 可读性/困惑度:去掉明显垃圾、随机键盘输入
- 毒性、成人、极端内容:按政策做过滤或降权
- PII:脱敏或删除邮箱、电话、身份证等(程度因项目而异)
- 低信息密度:过短、全是符号、模板页等丢弃或降采样
4. 去重(Deduplication)——非常核心
- 精确去重:相同段落/文档直接删
- 近似去重(MinHash/SimHash 等):防止「改几个字」的重复
- 跨数据集去重:避免训练集和测试集泄漏
目的:减轻记忆、提高泛化,也影响评测公平性
5. 文档级与段落级处理
- 按文档切分或保留文档边界(有时用特殊分隔符)
- 过长文档后面再按窗口切块;过短可能拼接(packing)
然后我们就可以对文档内的数据进行训练样本构造:
1. 先有:token 长序列
假设分词后得到一整条语料流(简化):
文档A: [a1, a2, ..., a500]
文档B: [b1, b2, ..., b300]
训练目标仍是:每个位置预测下一个 token。
2. 两种把数据变成「长度 L」的主流方式
方式 A:滑动窗口(同一条长文档)
对文档 A(500 个 token),窗口 L=4、步长 stride=2 举例:
| 样本 | 内容(token) |
|---|---|
| 1 | a1 a2 a3 a4 |
| 2 | a3 a4 a5 a6 |
| 3 | a5 a6 a7 a8 |
| … | … |
- stride = L:不重叠,块与块紧挨
- stride < L:重叠,边界上下文更连续,样本更多、算力更贵
每条样本长度都是 L,天然适合简单 batch。
方式 B:拼接打包(很多短文档)
把多篇短文拼成一条「超长流」,中间用 文档结束符 隔开,例如:
[ a1 a2 <eos> b1 b2 b3 <eos> c1 ... ]
再按固定 L 一刀切:
样本1: a1 a2 <eos> b1 (假设 L=4)
样本2: b2 b3 <eos> c1 ...
<eos>/ 文档分隔符的作用:让模型学到「这里是一篇结束」,减轻把 A 的尾巴和 B 的开头当成同一语义连续段的问题。- 实际常用的是 tokenizer 自带的 EOS 或特殊 token(如
<|endoftext|>),各家不同。
3. 从「一条样本」到「一个 batch」:padding + mask
假设 L=4,本 batch 有 3 条样本,但每条真实长度不同(例如有的为了节省只取有效长度,或动态 batch)——更常见是:已经都切成 L 了,则长度相同。
若必须对齐到 batch 内最大长度(例如变长 batch):
样本1: [t1, t2, t3, PAD]
样本2: [t1, t2, PAD, PAD]
样本3: [t1, t2, t3, t4]
- input_ids:
(batch_size, max_len)整数矩阵 - attention_mask:同样形状,真实 token 位置 = 1,PAD = 0
- 计算 attention 时:PAD 位置不参与互相 attend(实现上常把 pad 的 logits 置为 -inf 或直接用 mask)
**labels(预测目标)**通常与 input 对齐:
- 位置 i 的 label 是「位置 i+1 的 token」
- PAD 位置的 label 常设为 -100(ignore_index),loss 不算它们
这样一次 forward 就是标准 矩阵乘 + mask,实现简单。
总的来说,如果文档中的文本太长,我们可以通过滑动窗口的方式去进行切分,如果文档中的文本太短,我们可以将其拼接打包成一个长文档再进行固定长度切分。
然后这每一个样本就可以丢进Transformer中进行训练了,这里需要产出的token数一般是你输入样本的token数-1。
我们在这里还就是前向传播,反向传播,更新梯度就行了
大概就是
1.输入一个样本
2.让其计算后续的token
3.计算完毕
4.将计算完的结果和真实的数据进行对其对照
5.用交叉熵损失函数计算每个token的loss,取loss平均值
6.反向传播更新Wq,Wk,Wv
2.对于SFT来说
这里我们丢进去的数据一般就是instruction,input,output格式的数据。
那么这里我们需要预测的长度一般就是output的token长度
一般可以采用Lora这种有监督微调
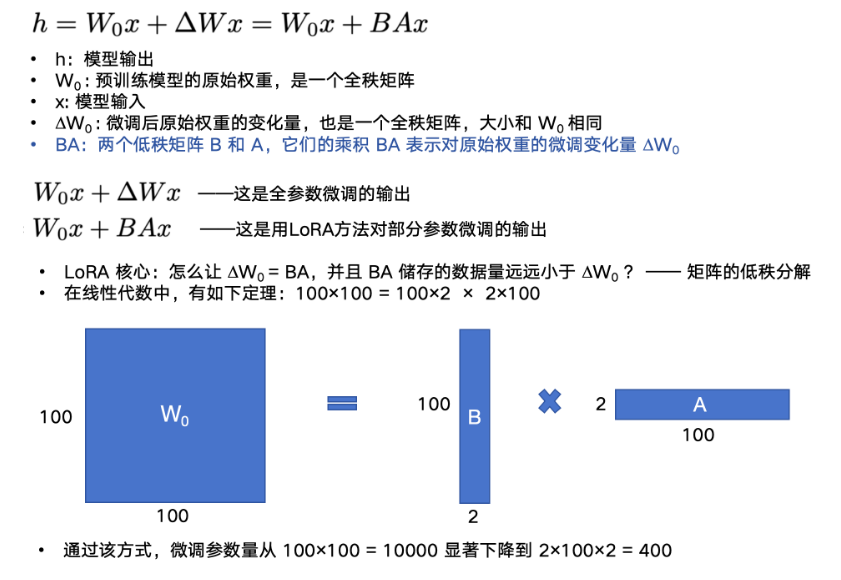
其使用低秩矩阵来减少参数量的存储,和反向传播时梯度的计算量
我们可以把W0看成初始值(在这里是冻结的),更新只靠AB两个矩阵:

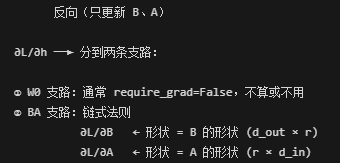
这样我们修改AB的值就可以了

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)