构建有记忆的硅基大脑:AI Agent 记忆方案的理论溯源与工程实践
当下的大模型赛道正陷入一场“上下文窗口”的军备竞赛。从 128K 到 1M Tokens 的激进扩张,似乎让人产生了一种错觉:只要窗口足够大,Agent 就自然拥有了长期记忆。但现实工程的毒打却接踵而至——暴力的文本堆砌不仅带来了高昂的 Token 消耗与难以忍受的推理延迟,更无法根除“中间遗忘”与事实混淆的致命痛点。
真正的记忆管理,绝非将历史日志无脑塞入 Prompt,而是一个涵盖多级存储、智能读写与动态遗忘的复杂系统工程。对于深耕 RAG 管道或基于 LangChain 构建业务的开发者而言,如何在连贯性、响应速度与算力成本之间寻找最优解,已成为打造生产级 Agent 的关键。
本文将为你提供一份拒绝空谈的硬核工程指南。我们将借用认知科学与冯·诺依曼架构的底层逻辑作为理论切入,全景式拆解从滑动摘要、Prompt Caching 到向量检索与知识图谱的记忆方案图鉴。通过剖析混合架构(Hybrid Memory)的工业级选型与多维评估体系,助你精准定位业务痛点,构建出低延迟、低成本且高准度的硅基大脑,并在此基础上前瞻下一代原生记忆模型的演进脉络。
1. 理论溯源:从认知科学到冯·诺依曼架构的 Agent 记忆模型
想象一个极具挫败感的开发场景:你耗费数月为用户打造了一个“全天候数字伴侣”,接入了最新的 GPT-5.3或 Claude 4.6 Sonnet,并慷慨地为其分配了 128K 的上下文窗口。用户第一天告诉它“我对花生严重过敏”,但到了第五天、经过了上百轮闲聊后,当用户问起“今晚吃什么”时,这个看似聪明的 Agent 却兴奋地推荐了花生酱三明治。
这不是智商问题,而是架构缺陷导致的必然结果。从“单次对话金鱼记忆”向“全天候数字伴侣”演进的最大技术鸿沟,在于大语言模型(LLM)底层推理的无状态(Stateless)本质与真实应用对有状态(Stateful)交互的强需求之间的根本矛盾。无论厂商如何鼓吹百万 Token 的物理上下文窗口,将所有历史文本一股脑塞给模型的“大力出奇迹”做法,不仅会带来高昂的 API 成本(Cost)和令人难以忍受的首字延迟(TTFB),还会不可避免地触发“中间迷失(Lost in the Middle)”效应。真正的记忆管理,从来不是盲目扩容,而是一门关于“如何优雅地记住,以及何时精准地遗忘”的系统工程。
要建立这套动态系统的心智模型,最高效的路径是向上溯源认知科学,向下对齐现代计算机的底层架构。
认知科学映射:AI 记忆的三层解构
人类大脑并非将所有经历事无巨细地存储在单一容器中,而是通过一套精密的分层机制来处理信息流。在设计 Agent 记忆模块时,我们可以直接套用这套成熟的认知科学框架,明确不同记忆单元的定义与边界:
- 工作记忆(Working Memory):这是大脑当前正在处理、极度活跃但容量极小的信息(如你正在心算的一道数学题)。对于 Agent 而言,这对应当前的 Prompt 上下文(含 System Prompt 与即时指令)。它的 Token 预算最为昂贵且稀缺,直接决定了模型当下的推理质量。
- 短期记忆(Short-term Memory):这是大脑对近期事件的短暂留存,随时间快速衰减。在 AI 系统中,它表现为近期会话窗口(Recent Chat History)。开发者通常通过滑动窗口(Sliding Window)或动态摘要机制,保持上下文连贯性的同时避免 Token 爆炸。
- 长期记忆(Long-term Memory):这是经过编码、固化并在需要时可被提取的外部历史库。对于 Agent,这就是外挂的 Vector DB(向量数据库)或 Graph DB(知识图谱)。它是无限扩展的,但模型无法直接在其上进行推理,必须经过“召回”动作。
冯·诺依曼架构隐喻:写给开发者的心智模型
如果你觉得心理学概念依然不够落地,我们不妨将其转化为工程师最熟悉的语言:冯·诺依曼架构(Von Neumann Architecture)。事实上,现代复杂 Agent 的演进,正越来越像是一套微型操作系统(OS)。
在这个隐喻下,LLM 自身只是纯粹的 CPU(中央处理器),只负责计算与逻辑推理,断电(Session 结束)即清空所有状态。那么记忆模块是如何运作的?
- 内存(RAM)= Context Window(上下文窗口):正如 CPU 只能直接寻址并处理内存中的数据,LLM 也只能“看”到位于当前 Context Window 内的 Token。工作记忆与短期记忆必须被加载到 RAM 中才能生效。
- 硬盘(Disk)= Vector / Graph DB(外部数据库):长期记忆持久化存储在硬盘中,容量近乎无限,存储成本低,但访问延迟高。LLM 无法直接对其运算。
- 缺页中断(Page Fault)与 I/O 读写 = RAG 与 Function Calling:当用户提问触发了模型知识盲区(对应 CPU 发现所需数据不在 RAM 中,触发缺页中断)时,系统通过 RAG 机制(操作系统的换页调度)去硬盘(向量库)中检索相关 Chunk,并将其换入 RAM(组装进 Prompt)供模型推理。而在更高级的架构中,Agent 可以通过 Function Calling 主动发起对硬盘的写操作(如调用
save_to_memoryAPI)。
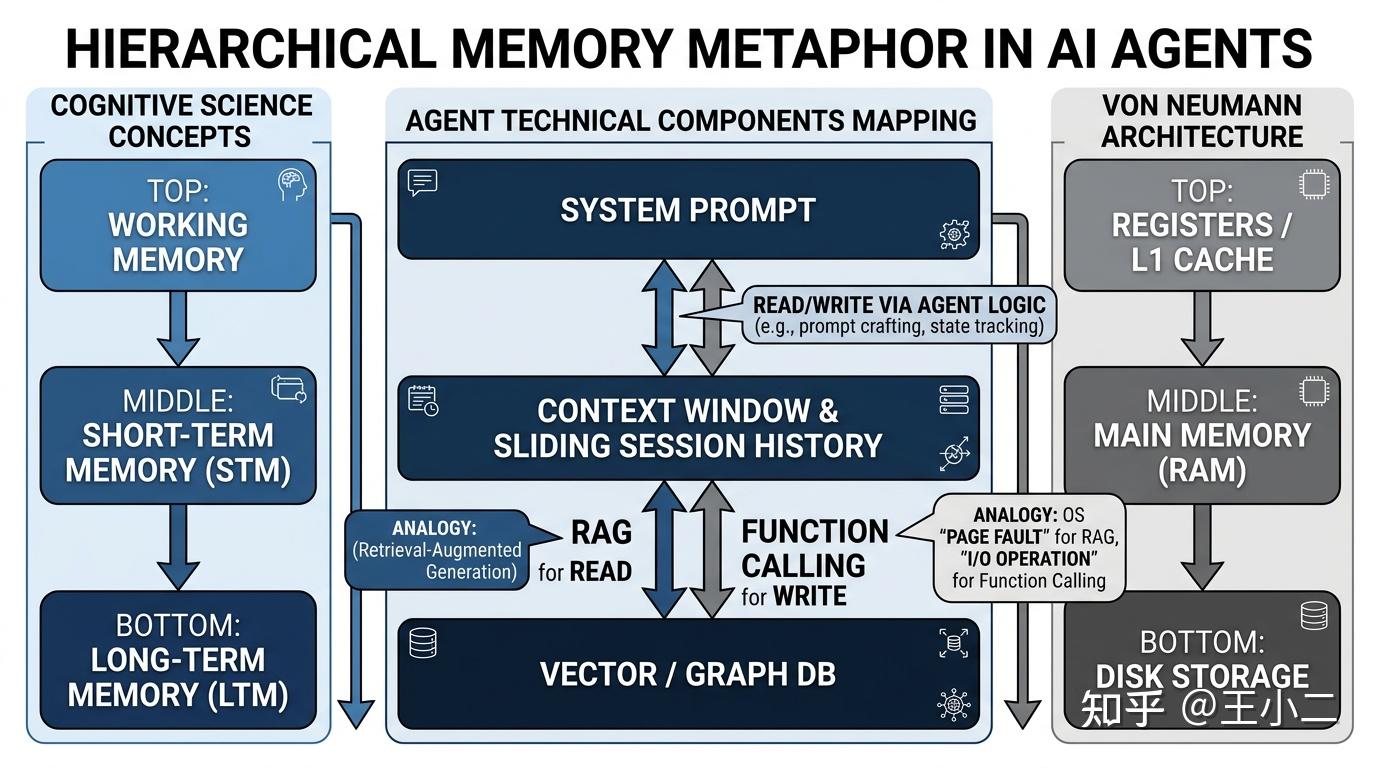
Agent分层记忆系统:认知科学与计算机架构映射图
演进路线:从金鱼到自治生命体
理解了上述分层架构后,我们就可以清晰地诊断当前市面上各种 AI 系统的代际差异。系统如何调度其 RAM 与 Disk 之间的资源,直接决定了它的智能上限。
不同形态 AI 系统的记忆能力对比矩阵
| 记忆系统形态 | 核心组件特征 | 冯·诺依曼隐喻级别 | 典型应用场景 | 核心痛点与局限 |
|---|---|---|---|---|
| 无记忆模型 (Stateless LLM) | 仅依赖单词会话的零样本/少样本输入。 | 单片机时代:只有少量寄存器,无外存,靠硬编码运行。 | 单次文本翻译、简单代码生成。 | 无法维持多轮对话上下文,严重依赖人类不断重复输入背景信息。 |
| 增强检索模型 (Retrieval-Augmented) | 滑动窗口 + 外部 Vector RAG 混合驱动。 | 早期分时系统:有硬盘与内存,由外部脚本被动触发缺页换入操作。 | 企业内部知识库问答、标准化客户服务机器人。 | “被动回忆”:依靠相似度检索,缺乏随时间推移的因果逻辑链条,信息易碎片化。 |
| 自治生命体 (Autonomous Agent) | L1 Cache (系统提示) + 读写隔离的长期记忆库。 | 现代操作系统:具备完整的文件系统,进程主动申请系统调用进行 I/O 读写。 | AI 数字伴侣、长时间跨度的自动化研究员(如 MemGPT)。 | 状态机复杂度极高,极度依赖模型的 Function Calling 准确率,容易陷入存储空间泄漏。 |
当我们将 Agent 的记忆视作一个包含“读、写、改、删”的动态 OS 级组件时,单纯追求物理长窗口的执念便会自然消解。接下来的章节,我们将从这个分层模型出发,深度图鉴当前主流的短期缓存与长期存储方案,看看工业界到底是如何“精打细算”地压榨模型内存的。
2. 主流方案图鉴(上):长上下文、Prompt Caching 与动态摘要
正如上一节所述,如果将大模型视作冯·诺依曼架构的 CPU,那么上下文窗口(Context Window)就是直接与计算单元交互的系统内存(RAM)。在构建复杂 Agent 时,内存条的容量与读写效率往往直接决定了系统的“智商”下限。目前,业界针对工作记忆与短期上下文的管理,演化出了两种截然不同的工程流派:一种崇尚硬件暴力的“大力出奇迹”,另一种则在工程侧“精打细算”。
“大力出奇迹”派:原生长上下文与 Prompt Caching
随着 RoPE(旋转位置编码)的优化与 Ring Attention 等分布式计算技术的成熟,百万级别 Token 的上下文窗口已从实验室走向工业界(如 Claude 3、Gemini 1.5)。这一流派的核心理念非常直接:只要内存足够大,就不需要复杂的内外存调度方案。
然而,原生大窗口带来了一个致命的工程痛点——算力账单与延迟噩梦。在标准 Transformer 架构下,注意力机制的计算复杂度为 。这意味着当你向模型扔进一份 50 万字的代码库时,首字延迟(TTFB, Time To First Token)可能会长达数十秒,且每次多轮对话的输入都要全量重复计费。
为了破局,Prompt Caching(提示词缓存) 技术应运而生。它的底层逻辑是典型的“空间换时间”:在推理引擎(如 vLLM 框架)中,将经常重复输入的文本前缀(如庞大的 System Prompt、长篇财报或底层代码仓库)在首轮计算后生成的 KV Cache 矩阵直接固化在 GPU 显存或主存中。当后续请求命中该前缀树时,模型无需重新计算 Attention,直接加载 Cache 进行自回归生成。
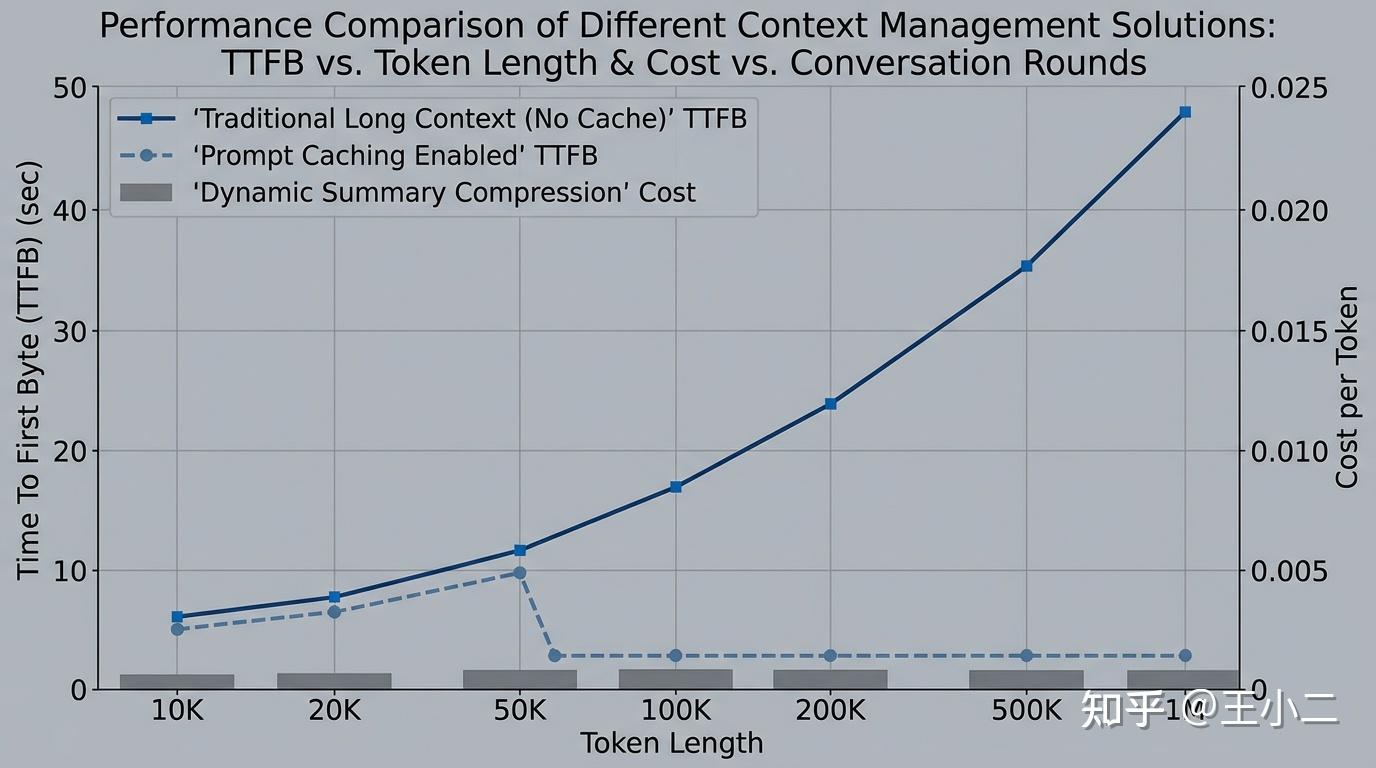
不同上下文管理方案的成本与首字延迟动态对比曲线
从图中的对比曲线可以清晰看出,在百万级 Token 规模下,无缓存方案的 TTFB 会随长度呈非线性飙升;而在启用 Prompt Caching 后,只要前缀命中,延迟和成本均呈现断崖式下降。这种方案是代码库分析、长文档沉浸式阅读、法务合同审查等“高频重用静态大文本”场景下的终极解法。 开发者无需再费心力去做文本切块(Chunking),直接交由模型原生处理,极大保留了信息流的完整性。
“精打细算”派:Token 预算管理与双层摘要算法
然而,“大力出奇迹”并不能包治百病。在真正的长期陪伴型 Agent 或高并发的闲聊机器人场景中,用户的对话具有极强的动态性。随时变化的对话记录无法有效复用 KV Cache,若无休止地累加历史消息,不但会迅速击穿 Token 账单,还会因为大量“你好”“废话”等无信息量文本导致模型推理效率断崖式下跌。
面对动态上下文,“精打细算”派提出了严格的 Token 预算管理(Budget Management) 理念,其核心落地方案是结合滑动窗口(Sliding Window)的双层动态摘要压缩算法。
这并非简单地调用一次 summarize() 函数,而是一个多层级的渐进式压缩流水线:底层保留最近的 轮原始对话以维持短期工作记忆的精确度;当超出预算时,中层触发段落级局部摘要,提取具体事件与核心实体;最顶层则不断将局部摘要向全局“宏观上下文”融合。
以下是一段展现双层压缩逻辑的核心伪代码:
class DualLayerMemoryManager:
def __init__(self, raw_limit=2000, total_budget=6000):
self.raw_history = [] # 工作记忆(原始对话)
self.local_summaries = [] # 中层记忆(局部事件摘要)
self.macro_context = "" # 顶层记忆(宏观系统状态)
self.total_budget = total_budget
self.raw_limit = raw_limit
def add_interaction(self, user_msg, ai_reply):
self.raw_history.append((user_msg, ai_reply))
# 步骤 1:检查近期记忆是否超出阈值
if count_tokens(self.raw_history) > self.raw_limit:
# 剥离最早的 N 轮对话
evicted_dialogues = self.raw_history[:5]
self.raw_history = self.raw_history[5:]
# 步骤 2:生成局部段落级摘要(保留关键实体与意图)
local_sum = LLM.generate(
prompt=f"提取核心实体与事件,丢弃寒暄:{evicted_dialogues}"
)
self.local_summaries.append(local_sum)
# 步骤 3:全局预算检查与宏观摘要融合
if count_tokens(self.local_summaries) + count_tokens(self.macro_context) > self.total_budget - self.raw_limit:
# 将积累的局部摘要融入全局画像,抛弃时间久远的细节
self.macro_context = LLM.generate(
prompt=f"基于现有长期背景:{self.macro_context},融入新事件:{self.local_summaries},生成更新后的宏观背景。"
)
self.local_summaries.clear() # 清空已融合的局部摘要通过这种机制,Agent 的上下文始终由“凝练的宏观背景 + 近期事件摘要 + 原汁原味的当前对话”组成。系统可以在过滤冗余废话的同时,把上下文长度永远锁死在一个极低的成本阈值内。
方案局限:前端“内存”的物理瓶颈
无论是依赖 Cache 还是精巧的动态摘要,当我们试图在模型的输入端(前端内存)解决长期记忆问题时,都会触碰难以逾越的物理上限:
- 长上下文的“注意力稀释”问题:尽管各大模型都在秀“大海捞针”实验的满分成绩,但真实业务中的数据噪音远比实验环境大。当上下文超过特定阈值(如 200K)时,模型依然会面临典型的“Lost in the Middle”现象,导致针对长尾细节的细粒度召回率显著下降,甚至出现幻觉。
- 动态摘要的“不可逆信息流失”:压缩必然有损。双层摘要算法虽然聪明,但大模型在进行局部摘要时,其实并不知道未来的用户会问什么。今天被算法当作“无用寒暄”丢弃的细节(比如用户随口提了一句“我今天吃了海鲜”),明天可能就是判断其过敏史的关键线索。
前端内存的设计终归只能解决“眼前的问题”。当 Agent 需要记住一个项目三个月的演进历程,或者需要陪伴用户成长三年时,单靠扩大 RAM 或进行数据压缩已经捉襟见肘。此时,记忆管理必须向冯·诺依曼架构的更深处迈进——引入外部持久化存储系统(Disk),这便是下一章我们将深入探讨的向量检索与知识图谱的用武之地。
3. 主流方案图鉴(下):向量检索、知识图谱与操作系统级自治
正如上一节所剖析的,无论是简单粗暴地拉长上下文窗口,还是在前端进行精打细算的摘要压缩,本质上都是在“内存(RAM)”层面的螺蛳壳里做道场。当 Agent 面临长达数月甚至数年的运行周期时,内存的容量瓶颈与注意力稀释问题必然爆发。因此,为模型挂载持久化的“硬盘(Disk)”并建立高效的读写机制,就成了突破高阶 Agent 记忆上限的必经之路。
目前,工业界在外部记忆存储与管理上,已经分化出三条标志性的工程演进路线。
“外挂大脑”派:Vector RAG 的工程局限与边界
将历史对话或外部文档进行向量化(Embedding)并存入向量数据库,是目前最为普及的记忆方案。从冯·诺依曼架构看,这就是给 LLM 挂载了一块只能做大块读取或追加写入的外部磁盘。
不可否认,Vector RAG 架构简单、开箱即用,但在处理高动态性、长周期的 Agent 记忆时,其底层的两个工程硬伤暴露无遗:
- 强时序性失效:Embedding 本质上是在高维空间中度量语义的欧氏距离或余弦相似度,而非时间序列的先后关系。当用户询问“我上个月说把那个项目延期,后来结果怎样了?”时,向量检索往往会基于语义相关性,把过去半年内所有提及“项目延期”的文本片段一并捞出。由于向量底层缺乏对时间轴的原生感知机制,模型面对一堆乱序的相似切片时,极易发生记忆错乱。
- Chunking 导致的记忆碎片化:为了匹配 Embedding 模型本身的 Token 输入上限,开发者必须在入库前对长文档与历史记录进行分块(Chunking)。这种“切碎”操作在物理层面割裂了长程语境。检索回来的记忆往往如同破碎的拼图,即便模型拥有强大的生成能力,也难以还原出完整的上下文背景。
基于上述局限,Vector RAG 的主战场应当严格限定在静态知识库问答与标准化 SOP 机器人。在这些场景中,知识本身是离散、扁平且相对固定的,无需模型频繁进行跨时间线上的因果溯源。
“逻辑推理”派:GraphRAG 破局长期因果与人物图谱
如果说 Vector RAG 是在海量的碎片中“大海捞针”,那么 GraphRAG 则是将信息的孤岛编织成一张“捕鱼网”。为了解决跨越漫长周期的深度逻辑关联问题,以图谱为核心的结构化记忆架构应运而生。
GraphRAG 的核心不再是单纯的文本切割匹配,而是引入 LLM 作为知识提取器,将每一轮交互提炼为“实体(Entity)-关系(Relationship)-属性/状态”的三元组,并将其注入图数据库(如 Neo4j)。当记忆以拓扑网络固化后,Agent 就不再是去比对字符串的相似度,而是顺着图谱的边(Edge)进行路径遍历。
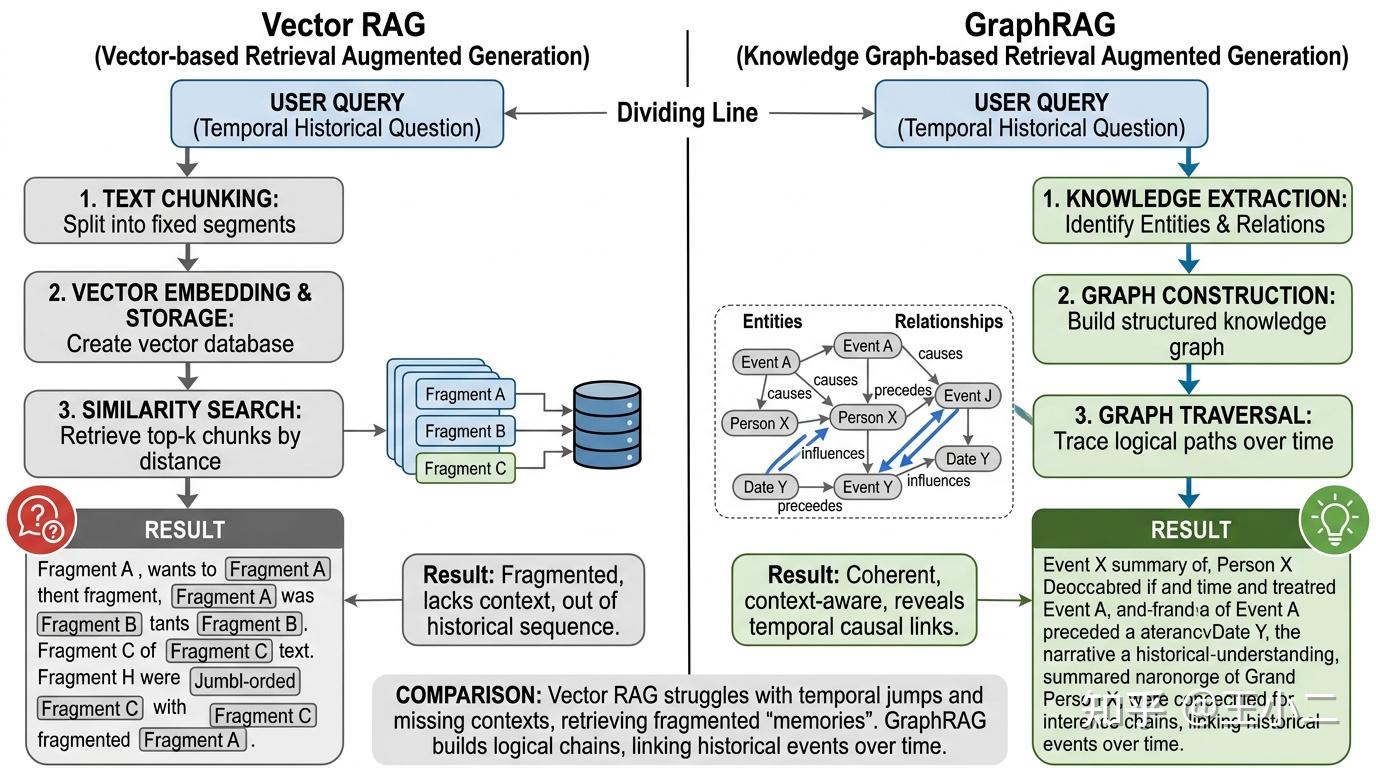
Vector RAG与GraphRAG路径与结果对比图
正如上图对比所示,当处理类似“张三上周因失眠换了什么药,目前复查情况如何?”这类复合追问时,Vector RAG 极易因为相似度召回“张三以前吃感冒药”的废料信息。而 GraphRAG 能够锁定核心实体“张三”,并沿着“症状->失眠(过去)”、“用药变更->A药换B药(上周)”、“当前状态->改善(今日)”的网状拓扑路径,严丝合缝地重构跨越时间跨度的因果链条。
这种演进极大地提升了系统对于历史演变状态的保真度,天然适用于复杂因果推理与深度人物关联分析场景,诸如长线虚拟陪伴Agent、复杂业务链条的法务/案件辅助系统等。然而,其代价是极高的前置算力成本——每一次记忆的入库与图谱关系的演进,都需要大模型进行繁重的逻辑提取。
“自主生命体”派:操作系统级自治(MemGPT/Letta 模式)
需要指出的是,不论是 Vector 还是 GraphRAG,传统架构在控制流上依然遵循着“被动触发”模式:外部(Python 脚本/LangChain 链)决定何时检索、检索什么,然后将其作为 Context 塞给大模型。这种“填鸭式”的交互剥夺了 Agent 自身对记忆的掌控力。
真正的长期记忆管理,其最终形态应当是将记忆的控制权彻底交还给模型本身。这一理念的集大成者是 MemGPT(及其背后的 Letta 架构),它将冯·诺依曼隐喻推向了操作系统级的纵深:直接把 LLM 视为系统的主 CPU,将当前上下文窗口(Context Window)划分为容量极小的“核心内存(Core Memory)”,将庞大的外部数据库定义为“归档外存(Archival Memory)”,并在此之上挂载了一个常驻的事件循环(Event Loop)。
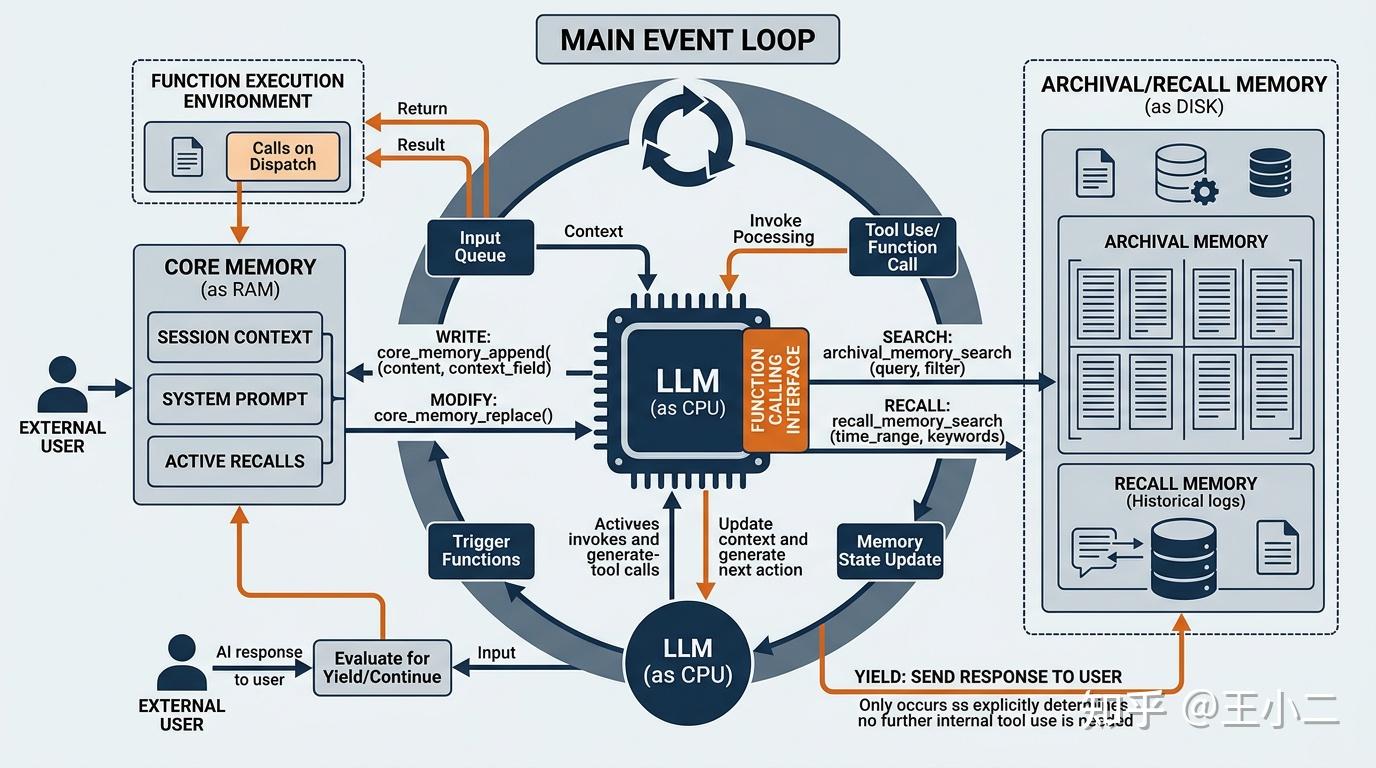
MemGPT分层记忆工具调用闭环时序流图
在这一自治架构下,模型获得了操作系统级别的底层 API(System Calls)权限。正如时序流图所示,大模型不再盲目等待外部投喂,而是通过 Function Calling 机制主动调度存储资源:
- 自主写入与纠错:一旦察觉到用户的关键状态发生转移(例如用户提到“我不做开发了,转行做产品”),模型会立即触发
core_memory_replace工具,主动覆写内存中陈旧的用户画像。 - 自主检索与挂起:当用户的提问超出了当前内存覆盖范围,模型并不会立刻产生幻觉乱答,而是将响应用户的任务暂时挂起(Interrupt),主动调用
archival_memory_search去外部向量或图谱外存中进行分页翻找,直到获得足够论据后再将结果组装(Yield)给用户。 - 自主遗忘与归档:随着对话的推进,模型还能持续评估内存槽位的健康度,通过
archival_memory_insert将活跃度降低的记忆主动降级至慢速硬盘,从而实现内存预算的动态平衡。
这种将何时读取、何时写入、何时归档与遗忘的决策权完全内置于 LLM 的设计机制,标志着 Agent 从机械的外部数据库堆砌,正式跨入了一个能够自我维系内部状态的“数字生命”门槛。
当然,赋予系统如此高阶的自治能力,必然极大考验底层大模型处理 Function Calling 时序逻辑的稳健度。同时,在真实的业务现场,单一流派往往独木难支。如何将上述方案融为一炉,构建一套兼顾成本、低延迟且具备容错能力的混合架构,将是我们下一步需要攻克的工程难点。
4. 工业实践:混合架构(Hybrid Memory)选型与多维评估体系
前面我们分别探讨了基于“内存”的前端上下文管理策略与基于“外存”的持久化知识工程。然而,真实的业务挑战从来不是单选题:全量喂入长上下文,暴涨的推理账单和首字延迟(TTFB)会摧毁产品体验;仅依赖向量检索,割裂的语义切片又会使 Agent 丧失长期逻辑连贯性。因此,工业界的最佳实践不再纠结于寻找单一的“银弹”,而是转向类似于现代计算机分级存储体系的混合记忆架构(Hybrid Memory)。
L1 至 L3:分层路由的混合记忆架构
要在低延迟、低成本与高智商之间取得平衡,系统需要根据数据被访问的频率(Hot/Cold Data)和对当前推理的重要性,进行分级存储与路由调度。基于这一理念,我们可以构建出层级分明的 L1 至 L3 混合记忆系统。
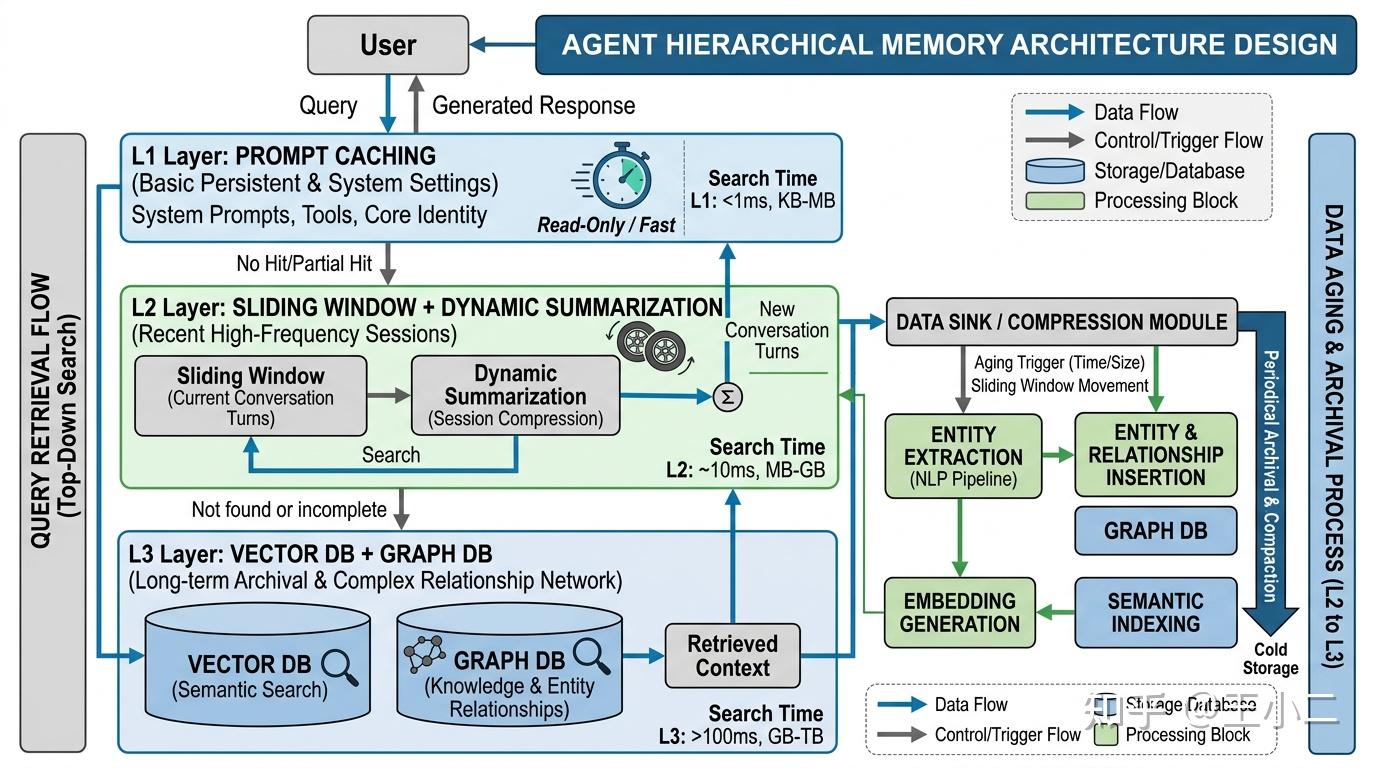
Agent 多级混合记忆 (Hybrid Memory) 数据流转架构图
- L1(基础常驻层):Prompt Caching。 这一层相当于 Agent 的 L1 Cache,主要存放高频命中、近乎静态的核心数据。例如 System Prompt、系统运作指令(Function Calling Schema)以及提炼出的极简“用户核心画像”。由于这类信息几乎每次对话都会被调用,利用前文提及的 KV Cache 复用技术,能以极低的 TTFB 和接近 10% 的 Token 成本让模型在毫秒级读取关键设定,确保 Agent 的基础“人格”不崩塌。
- L2(近期会话层):Sliding Window + 动态摘要。 这一层对应工作记忆,用来维系当前任务或短周期内的连贯性。工程上通常采用固定轮次(如最近 10 轮)的滑动窗口保留原始文本,确保细粒度的问答对不丢失;超出窗口边界的部分则触发异步的动态摘要压缩,将浓缩后的结论流转到更深层。这种机制确保了对即时多轮对话的高保真还原,同时严格控制了当前上下文的 Token 预算。
- L3(历史档案与画像层):Vector + Graph DB 组合。 当对话数据沉淀变冷,就需要作为长期记忆被归档(Archived)。这里采用双轨存储:一方面,将所有历史对话切片并存入向量数据库,以便随时通过语义相似度“打捞”过去的细节;另一方面,将抽取出的核心实体(如人物、地点、事件)及关系存入知识图谱(Graph DB)。当面临涉及时间跨度的复杂查询(如“过去三个月我提到最多的投资方向是什么”)时,L3 层的图谱能提供全局的拓扑视角,而向量提供上下文支撑,通过 Agentic RAG 技术拉回至前端。
动态更新与纠错:记忆的覆写、淘汰与衰减
拥有了多级架构,随之而来的痛点就是记忆冲突。随着时间推移,用户的偏好或状态是会改变的。如果用户在两个月前说“我非常喜欢吃辣”,而在昨天说“我最近得了胃溃疡,一点辣都不能碰”,单纯的向量检索极可能因为旧记忆文本更多、语义匹配度更高,而给出“推荐麻辣火锅”的致命错误回答。
在工业实践中,记忆的动态更新与纠错机制通常通过引入时间戳(Recency)与重要度权重(Importance)的综合打分系统来解决。当检索特定实体的记忆片段时,总打分公式可以抽象为:
其中, 是向量相似度, 是该记忆碎片在生成时由 LLM 赋予的初始重要程度打分(例如核心健康状态权重远大于日常闲聊),而 则代表了基于时间的记忆衰减惩罚(通常使用指数衰减函数)。
更进一步,针对显式的偏好冲突(如“我现在不吃辣了”),系统在将 L2 数据向 L3 归档时,需引入一个类似 MemGPT 中“记忆管理器”的路由判断机制。当模型识别到新对话与图谱(Graph DB)中已存在的实体节点发生对立时,系统会直接触发“覆写(Overwrite)”或“软删除(大幅降低旧节点置信度权重)”操作。通过这种带时间戳和冲突校验的读写机制,Agent 才能摆脱刻板印象,保持与用户状态的动态同步。
多维评估体系:给记忆系统做“全面体检”
设计了一套精密的混合记忆架构后,我们还需要一把标尺来衡量系统的健康度。在真实业务上线前,评估记忆模块不能仅凭“看起来准不准”的直觉,而必须建立以下四个维度的量化评估体系:
- 成本效率 (Cost/TTFB): 这是最底线的工程指标。不仅要监控每次请求平均消耗的 Input/Output Token 数量,更要关注首字返回时间(TTFB, Time To First Token)。通过对比引入 L1 缓存机制前后的 TTFB 数据,可以直观评估缓存穿透与复用机制是否真正降低了推理侧的物理延迟。
- 召回准确率 (Hit Rate & Precision@K): 在 L3 层触发 RAG 或图谱查询时,系统拉回的记忆片段是否真的是当前回答必需的?如果拉回了大量看似相关但无用的历史对话,不仅增加幻觉风险,还会引发注意力稀释。该指标直接反映了向量嵌入模型和查询重写策略的成熟度。
- 记忆保真度 (Memory Fidelity): 用于评估信息在经历 L2 层的滑动摘要、L3 层的提取归档后,核心实体特征是否发生了扭曲或遗失。测试方法通常是注入多条细节相近的伪造长跨度对话,观察经过数次内存淘汰流转后,Agent 还能否准确无误地复述出初始设定的罕见实体。
- 容错纠偏能力 (Correction Rate): 针对上述的偏好冲突场景,测试 Agent 在面对反转指令(如“忘记我刚才说的话,其实我的真正要求是……”)时,调整自身内部记忆图谱状态的成功率。高容错能力的系统不仅能响应最新指令,更能主动清理被废弃的冗余记忆节点。
混合架构的落地与多维量化指标的确立,构筑了现代复杂 Agent 健壮的软件外壳。我们在算法层面穷尽了调度、压缩与检索的技巧,但这依旧是在弥补基础大模型无状态特性的先天缺陷。面对 Transformer 架构处理无限长序列时 的算力鸿沟,外挂记忆系统终究会有性能极限。那么,如果将视线投向底层模型的基座结构本身,我们是否能找到更为原生的解法?这便是我们要探讨的下一个命题。
5. 前沿趋势:非 Transformer 架构的原生记忆模型与未来展望
前文的探讨,我们从认知分层一路走向操作系统级混合架构,试图通过极尽精巧的工程设计——无论是缓存复用、动态摘要还是图向量编织——来构建 Agent 的长期记忆。然而,如果我们回到计算范式的原点审视,便会发现这一系列复杂的“外部脚手架”之所以存在,其根本动机都源自于当前主流 Transformer 架构底层的物理局限。要洞悉未来,我们必须从模型的“基因”层面寻找突破口。
理论天花板:Transformer 架构的“记忆诅咒”
Transformer 的自注意力机制(Self-Attention)是其理解深层语义的王牌,却也是限制其长期记忆的致命枷锁。在其设计中,模型每一次生成新的 Token,都必须与上下文中过往的每一个 Token 进行点积运算。这是一种极其奢侈的“照相机记忆”模式——为了不遗漏任何细节,它将所有的历史文本同时平铺在冯·诺依曼架构的“内存”中。
这种设计的代价是灾难性的:其计算复杂度随序列长度 呈现 的二次型爆炸式增长。尽管工程界提出了 PagedAttention 或 Prompt Caching 等显存优化手段,但在处理真正意义上的无限长交互记录时,单纯依靠外部系统去弥补这一瓶颈,终将触碰到算力与能耗的物理天花板。只要自注意力机制依然是底层核心,大模型在“上下文内存”上的扩容成本就始终难以随着边际效用递减。
原生状态模型破局:让隐式长期记忆成为可能
当“大力出奇迹”遭遇瓶颈,学术界开始重新审视曾经的递归神经网络(RNN)精神,试图通过状态空间模型(State Space Model, SSM)为大模型赋予内生的记忆能力。以 Mamba 和 RWKV 为代表的原生状态模型,正试图从根本上打破 的算力魔咒。
在认知科学中,人类真实的记忆机制绝非像素级录制,而是对过往经验进行状态压缩。SSM 架构完美地映射了这一理念:它不再将全部明文历史强行塞入内存,而是将过去的序列信息抽象并编码为一个固定维度的隐状态向量(Hidden State)。当新信息输入时,模型只需基于当前的内部状态和新 Token 进行线性更新,随后便可丢弃新输入的明文细节。这种将外挂存储彻底内化的机制,赋予了模型近乎无限的长期记忆潜力。
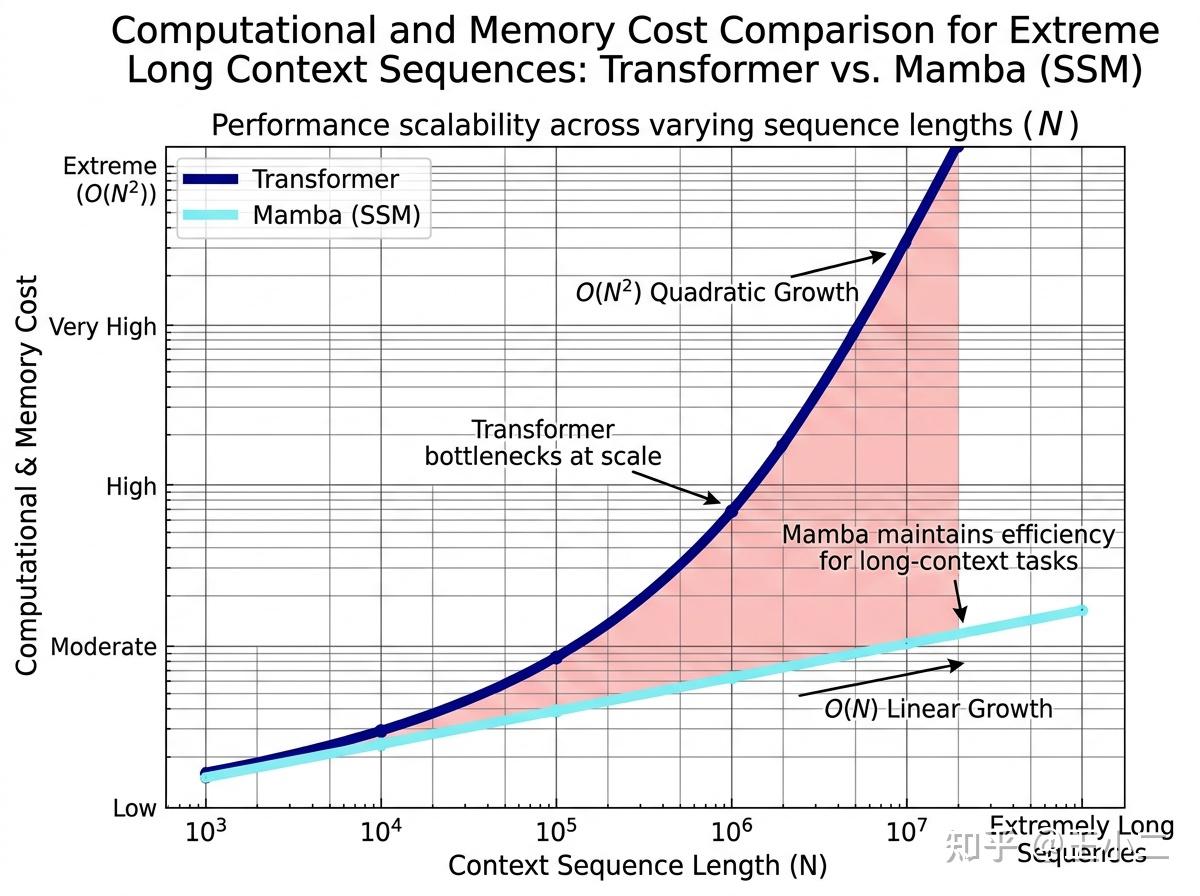
计算复杂度演进:Transformer vs SSM
通过以下简表,我们可以清晰地量化以 Mamba 为代表的状态模型在长序列注意力机制上带来的工程颠覆:
| 评估维度 | Transformer (自注意力机制) | 原生状态模型 (如 Mamba) |
|---|---|---|
| 注意力计算复杂度 | O(N^2) 二次型急剧增长 | O(N) 线性平缓增长 |
| 推理时显存消耗 | 随序列长度 N 线性增加 (KV Cache 不断膨胀) | 固定大小 (仅需维护常数级的隐状态空间) |
| 记忆表现形式 | 显式无损 (必须随时回溯每一个历史明文 Token) | 隐式有损压缩 (随时间迭代的连续状态向量) |
| 高并发长连接成本 | 极高 (易受算力与显存双重制约) | 极低 (吞吐量优势显著,非常适合全天候在线 Agent) |
需要审慎指出的是,目前原生状态架构在处理极端复杂的跨时间步逻辑推理时,其零样本泛化峰值相比顶尖的 Transformer(如 GPT-4)仍存在微小折损。因此,底层的替换并不会一蹴而就,而是在特定的长背景交互、个人伴侣等低延迟强上下文场景中率先突围。
未来展望:走向极简与内生的 Agent 架构
当未来某一刻,大模型本身真正演化出极低成本的内生无限记忆力时,现有的复杂 Agent 开发范式将迎来一次“奥卡姆剃刀式”的重塑,整体架构必将向“极简与内生”的方向演进。
首当其冲的,是前端记忆管理组件的消亡。我们在前文探讨的基于滑动窗口的摘要擦除、精打细算的 Token 预算控制等妥协性设计,将随着内生记忆的普及而被彻底废弃。Agent 只需要像人类一样保持与外界的持续交互,模型底层的状态流转机制会自动完成短时感知向长期心智的过渡。
其次,外部持久化存储将回归其本质使命。知识图谱(Graph DB)和向量库(Vector DB)不再被迫充当弥补模型短期对话遗忘的“高频缓存”,而是真正退回到冯·诺依曼架构中不可篡改的“硬盘”角色——专门负责沉淀脱离个人交互的绝对客观事实、超大规模的企业结构化库和宏观世界规律。记忆系统将实现前所未有的高内聚与低耦合。
总结而言,记忆管理的发展史,就是一部 AI 逐渐摆脱物理桎梏、走向自治的演进史。 从生硬的外部检索拼接,到包含动态遗忘机制的操作系统级引擎,再到未来原生状态模型的降维打击,技术的形态在不断更迭,但我们打造兼顾长期连贯性与独立人格记忆系统的核心愿景从未动摇。未来的开发者,将从缝补外部碎片的繁琐工程中解放出来,把真正的精力聚焦于如何塑造 AI 的认知对齐与心智成长。这才是赋予 Agent 真正“灵魂”的终极之路。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?
别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明:AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。


四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)