拒绝幻觉与“车轱辘话”:一文看透大语言模型采样原理与调参真相
在调用大模型API时,你是否遇到过这样的困境:明明提示词已经打磨到了极致,模型却依然一本正经地产生幻觉,或是像复读机一样陷入死循环输出“车轱辘话”?面对面板上的Temperature、Top-p等采样参数,许多开发者与提示词工程师往往只能依赖“0.2写代码,0.8写文章”的经验法则进行盲目试错。
事实上,大语言模型的文本生成绝非黑盒魔法,其本质是一场对概率空间的动态裁剪。那些失控的输出,往往源于我们对解码阶段概率分布干预机制的认知缺失。如果不理解这些参数背后的底层逻辑,就无法真正驾驭模型的能力边界。
本文将带你彻底跳出“玄学调参”的泥沼。我们将从模型预测“下一个词”的起点切入,系统拆解Temperature控制随机性的数学直觉,以及Top-K、Top-p与Min-p过滤低概率词汇的截断策略。我们将摒弃生僻晦涩的学术术语,用直白的工程语境与真实的业务场景,为你揭示多参数联合运用的真相。读完这篇实战指南,你将建立起一套科学的控制体系,在任务的准确性与多样性之间找到最优解,实现对模型输出的精准掌控。
1. 文本生成的起点:模型如何输出下一个词?
想象你正在调用 OpenAI 或开源模型的 API,面对控制台里那一排滑块——Temperature、Top-p、Top-k。稍微拉动它们,模型给出的回答就会从严谨的学术报告变成天马行空的狂想曲。对于许多开发者而言,这些参数的作用仅停留在一两句经验总结上(比如“发散思维调高点,写代码调低点”)。但它们究竟是如何施展魔法的?
要真正掌控这些“旋钮”,在各类业务场景中实现稳定、高质量的输出,我们必须先撕开大语言模型(LLM)黑盒的最后一层伪装,回到文本生成的第一性原理:预测下一个词(Predict the next token)。
破译黑盒的最后一步:从原始得分到概率分布
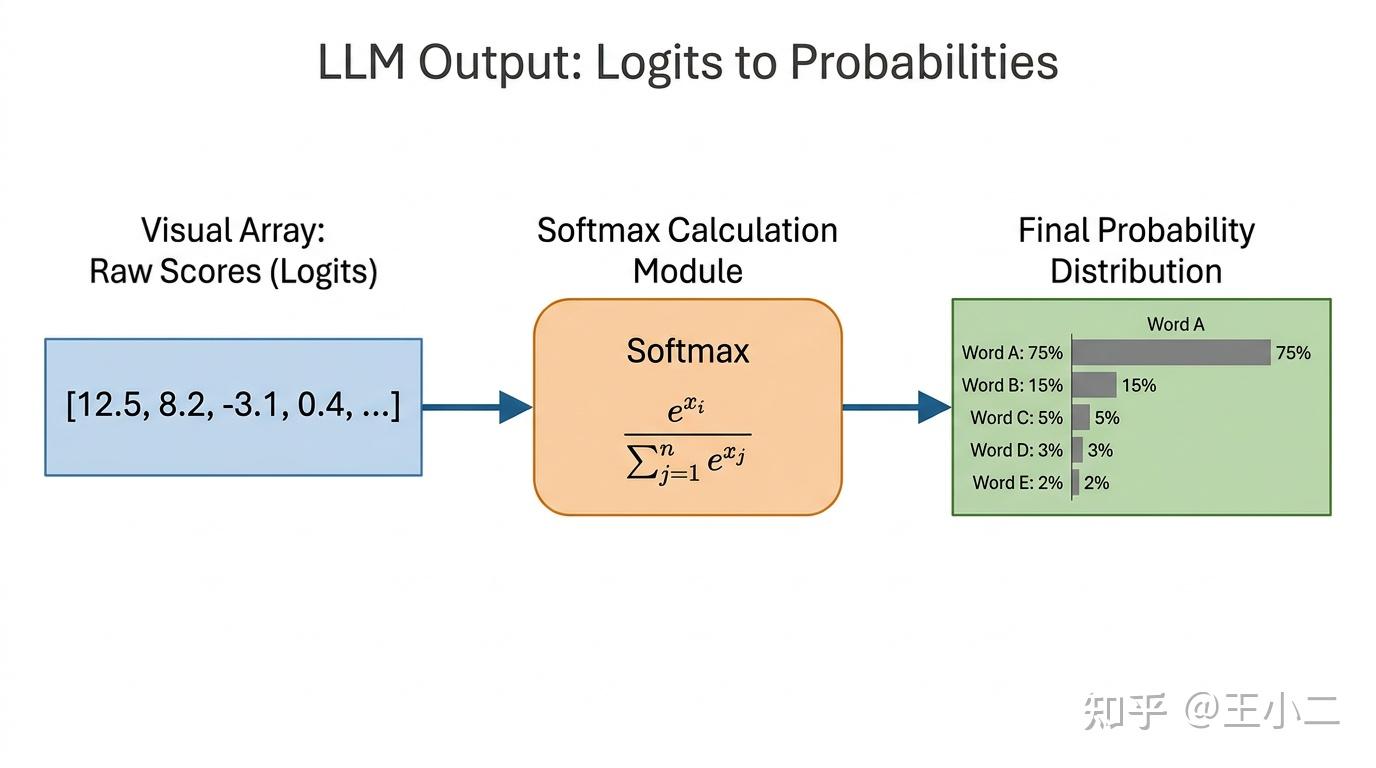
当我们输入一段 Prompt 后,模型的千亿个参数便开始了一场浩大的矩阵乘法运算。然而,这座庞大的计算网络在最后一层吐出的,并不是一段现成的人类文字,而是一个极其庞大的浮点数数组。这个数组的长度等于模型词表的大小(例如 GPT-4 的词表超过 10 万个 token),我们称这些原始数值为 Logits(原始得分)。
Logits 存在一个致命的工程问题:它们的数值跨度极大,且有正有负(例如 [15.2, 8.4, -3.1, 0.5...]),人类和计算机都无法直接将其理解为“哪个词出现的几率更高”。
为了将这些桀骜不驯的原始得分转化为直观的概率,模型引入了数学上的破壁人——Softmax 函数。它执行了两个关键操作:
- 利用指数运算()将所有负数转化为正数,并成倍拉开高分与低分之间的差距。
- 将所有数值进行归一化处理,确保它们加起来等于 1(即 100%)。
从Logits到概率分布流程图
经过 Softmax 洗礼后,我们终于得到了一份结构清晰的“候选词概率分布字典”。例如,面对输入“今天天气很”,模型可能会输出这样的分布:
好:75%晴:15%差:5%热:4.9%苹果:0.0001%(极低概率词)
这正是所有生成策略赖以运转的基石。拿到这份榜单后,模型接下来的抉择,将直接决定文本的命运。
贪心搜索的局限性:为什么“永远选最优”是个糟糕的主意?
既然有了清晰的概率榜单,一个最符合直觉的策略呼之欲出:每次都无脑选择概率最高的那个词。在计算机科学中,这种策略被称为贪心搜索(Greedy Search)。
在执行严密的数学计算或事实问答时,贪心搜索似乎是完美的。但当它被用于长文本生成时,却会导致灾难性的后果。让我们看一个真实的由于贪心策略导致的退化(Degeneration)示例:
Prompt: 人工智能的未来将会 贪心搜索输出: 人工智能的未来将会是非常重要的,因为人工智能的未来将会是非常重要的,因为人工智能的未来将会是非常重要的…
为什么看似最求稳的策略,反而产出了“车轱辘话”的死循环?
答案在于自然语言的非线性和“惯性”。当我们强迫模型每次都走最高概率的路径时,它很容易在局部语境中找到一个极其常见的词组搭配。一旦模型输出了第一句“是非常重要的”,这句话就成为了新的上下文(Context)。在下一次预测时,“因为”这个词的概率被抬高;紧接着,“人工智能”又成了接在“因为”后面概率最高的词。循环往复,模型被困在了自己挖掘的概率深谷中,再也爬不出来。
不仅如此,即便没有陷入死循环,贪心搜索生成的文本也往往干瘪、机械。因为人类在日常交流和写作时,从不会每次都使用最烂俗、最可预测的词汇。语言的魅力,往往潜藏在那些“次优选择”的惊喜中。
采样的本质:给次优解一个机会
既然绝对的最优解走不通,我们就需要引入一种全新的机制来打破僵局——采样(Sampling)。
采样的本质,是放弃确定性,拥抱概率论。它不再死板地选取榜单第一名,而是将概率分布字典变成一个“加权轮盘赌”。概率越高的词,在轮盘上占据的面积越大,被指针扫中的机会就越高;但关键在于,那些排名第二、第三甚至更靠后的词,也拥有了属于自己的一席之地。
在“今天天气很”的例子中,如果使用采样机制,模型有 75% 的概率输出“好”,但也保留了 15% 的概率去输出“晴”,甚至有微小的可能去选择“热”。
通过引入这种适度的不确定性,采样机制完美地解决了贪心搜索的顽疾:
- 打破死循环:即使偶尔选到了极高频的句式,由于随机性的存在,模型也能在某一步跳出当前的局部最优,转向新的表达。
- 提升多样性:赋予了文本更接近人类的起伏感与创造力。
然而,这又引出了一个全新的致命挑战:如果我们放任轮盘盲目转动,万一指针转到了概率只有 0.0001% 的“苹果”(今天天气很苹果),文本的逻辑就会瞬间崩塌,产生荒谬的幻觉(Hallucination)。
这正是为什么我们在调用 API 时,绝不能任由模型“裸奔”采样。我们必须利用一组精密的控制阀门,来对这个轮盘的面积进行动态干预与裁剪。而在这些阀门中,最基础、最核心也是最能重塑模型概率分布的参数,正是我们下一章要探讨的绝对主角——Temperature(温度)。
2. Temperature(温度):控制输出的随机性与创造力
在上一节中,我们拆解了模型输出下一个词的第一性原理,并揭示了绝对求优的“贪心搜索”为何会不可避免地陷入长文本循环。既然我们需要通过“采样(Sampling)”来引入适度的不确定性,打破机械的重复,那么接下来的核心问题便是:如何精确控制这种不确定性的程度?
如果把模型每一次预测下一个词的概率空间比作一座起伏的山脉,那么 Temperature(温度)就是重塑这座山脉地形的“造物主”。它并不直接剔除字典中的任何词汇,而是通过数学上的全局变形,平滑或锐化整个概率分布曲线。
数学直觉的降维解释:分母的魔法
大模型在输出最终的词汇概率前,必然会经历一个关键的数学变换——Softmax函数。它的核心作用是将模型黑盒最后输出的未归一化原始得分(Logits)转化为总和为1的概率分布。而 Temperature(通常用 表示)正是这个公式中指数部分的分母:
无需精通复杂的微积分,我们仅从小学级别的除法逻辑,就能看透这只看不见的手是如何操控语言生成的:
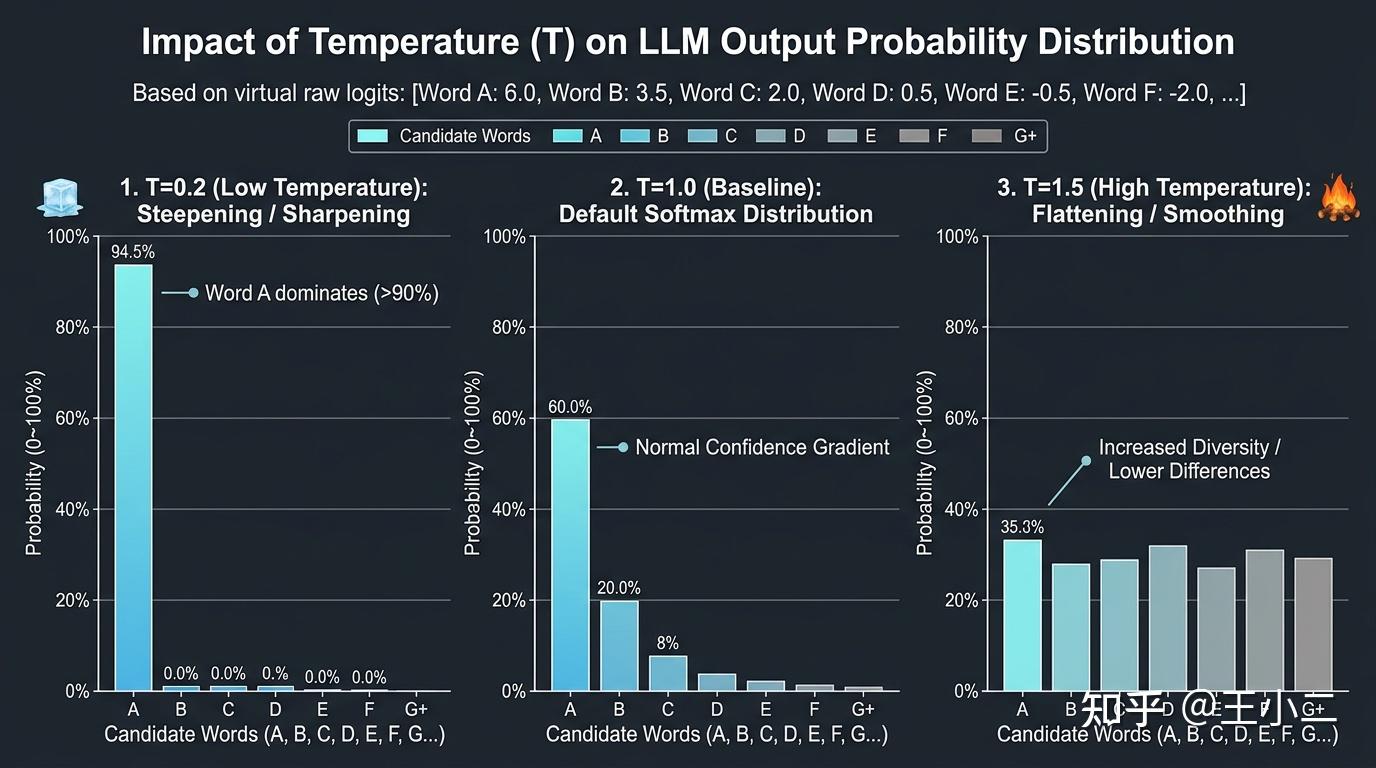
- 当 (低温)时,分母是个小数,这会将原本的得分(Logits)在数值上整体放大。 当这些被放大的数值进入指数运算()后,原本微小的得分差距就会被极其夸张地拉开,导致高分词的概率迅速逼近绝对垄断;而低分词的概率会被无情压缩到接近于零。这在工程上表现为一种“锐化(Sharpening)”效应。
- 当 (高温)时,分母大于1,这会将原本的得分(Logits)在数值上整体缩小。 当这些被缩小的数值进入指数运算()后,各个词原始得分的差异被强行抹平。原本遥遥领先的高频词优势遭到削弱,而原本垫底的冷门词被“提拔”上来,大家平起平坐。这表现为一种“平滑(Smoothing)”效应。
不同Temperature下的全局概率分布曲线对比
如上图所示,面对同一组原始的Logits得分,仅仅因为 值的不同,其最终呈现的概率分布形态发生了天翻地覆的变化。
极端值的体感对比:从绝对理性到随机乱码
理解了数学底层的“缩放”机制,我们就能轻易推导出 Temperature 在不同极端取值下的工程表现:
- :退化为贪心搜索。 当 无限趋近于0时,得分最高的词与次高分词之间的差距会被指数级放大至趋于无穷,导致经过 Softmax 映射后,最高分词分配到的概率将无限逼近 100%。此时,基于概率的采样机制名存实亡,模型变成了绝对理性的“答题机器”,每一次都死板地锁定局部最优解。这就是为什么在需要严格按指令执行、零容错的场景(如代码生成、JSON格式化、实体数据抽取)中,我们必须将 Temperature 设为0(或极小值)。
- :保留原始置信度。 这是模型出厂的“素颜”状态,完全忠实于海量训练数据赋予各个词的原始分布比例。不多一分发散,不少一分严谨。
- 极端高温(如 或极高值):逼近均匀分布。 当 非常大时,所有词的 都在逼近 。这意味着字典里的几万个 Token,无论上下文是什么,被抽中的概率都趋于一致。此时模型彻底丧失了基于上下文的推理逻辑,输出的将是毫无连贯性的生僻字堆砌或随机乱码。
文本真实体感:温度如何重塑表达
为了更直观地感受“全局变形”对人类阅读体感的影响,我们来看一组真实的 Prompt 生成对照验证:
Prompt: 请以“夜空中划过一颗流星”为开头,续写一句话。
【低温 的生成结果】
夜空中划过一颗流星, 照亮了漆黑的天际,随后消失在远方的山脉后。 (解析:用词极其安全、符合常理。这是人类在描述流星时最常用的语境组合,准确但缺乏惊喜。)
【高温 的生成结果】
夜空中划过一颗流星, 仿佛宇宙不小心掉落了一枚银色的鳞片,在深蓝色的呼吸里短暂地烫下了一个吻。 (解析:长尾冷门词汇(如“鳞片”、“呼吸”、“烫下”)的概率被 T 值强行拉高并被幸运地抽中,生硬的逻辑被打破,文本充满了文学张力与惊人的创造力。)
高温的双刃剑效应:创造力与幻觉的伴生
上述的高温例子看起来非常惊艳,但这背后隐藏着大模型最致命的陷阱之一:幻觉(Hallucination)风险与逻辑链断裂。
许多 Prompt 工程师在处理“创意营销”、“头脑风暴”任务时,会盲目将 Temperature 调高,结果发现模型虽然词汇丰富了,但开始胡言乱语或捏造事实。其根本原因在于:Temperature 的平滑效应是无差别的。
它在拉高“冷门但优美”词汇概率的同时,也同等比例地拉高了那些“逻辑荒谬”、“事实错误”甚至“语法崩坏”词汇的概率。由于大模型的生成是自回归(Auto-regressive)的过程——每一步的输出都会成为下一步的输入。在高温下,一旦模型在某一步“不小心”选中了一个被人工膨胀起来的荒谬错词,这个错词就会污染后续的上下文。随着错误前提的累积,整个推理逻辑链条便呈指数级崩溃。这正是高温与幻觉如影随形、不可分割的数学宿命。
结语与悬念:仅仅改变全局形状就够了吗?
Temperature 是一个极其优雅且不可或缺的参数,它让我们能够在保守与激进的刻度尺上自由滑动。然而,这种全局变形存在一个天然缺陷:哪怕在 的极低温度下,那些排在字典几万名开外、极其荒谬的劣质词汇,其概率也只是“无限接近于零”,而在数学上永远不等于零。在动辄生成几千字的长文本任务中,只要采样基数足够大,这些小概率的灾难事件总有几率成为现实。
要彻底杜绝模型“从垃圾桶里挑词”的风险,单靠重塑概率分布的形状是不够的。我们还需要一把物理意义上的“剪刀”,直接把概率垫底的劣质候选池一刀切断。这,正是我们下一节要深度剖析的局部截断策略:Top-K、Top-p 与 Min-p。
3. Top-K、Top-p与Min-p:过滤低概率词汇的截断策略
在上一节中,我们探讨了 Temperature(温度)如何通过调整概率差距来实现对输出分布的“全局变形”。然而,无论是高温还是低温,Temperature 都只是在重新分配概率,它并不会真正剔除任何一个词汇。即使在极低的概率下,那些荒谬的长尾词(如乱码、完全不相干的字)依然存在被选中的微小可能。当生成长文本时,这些微小概率会不断累积,最终导致“幻觉”或逻辑崩盘。
为了给模型的创造力加上一道“物理安全锁”,我们需要引入截断策略(Truncation Strategies)。如果说 Temperature 是改变概率分布的化学反应,那么截断策略就是一把物理剪刀——它直接将概率低于特定标准的候选词强制清零,彻底将劣质词汇挡在抽卡池之外。
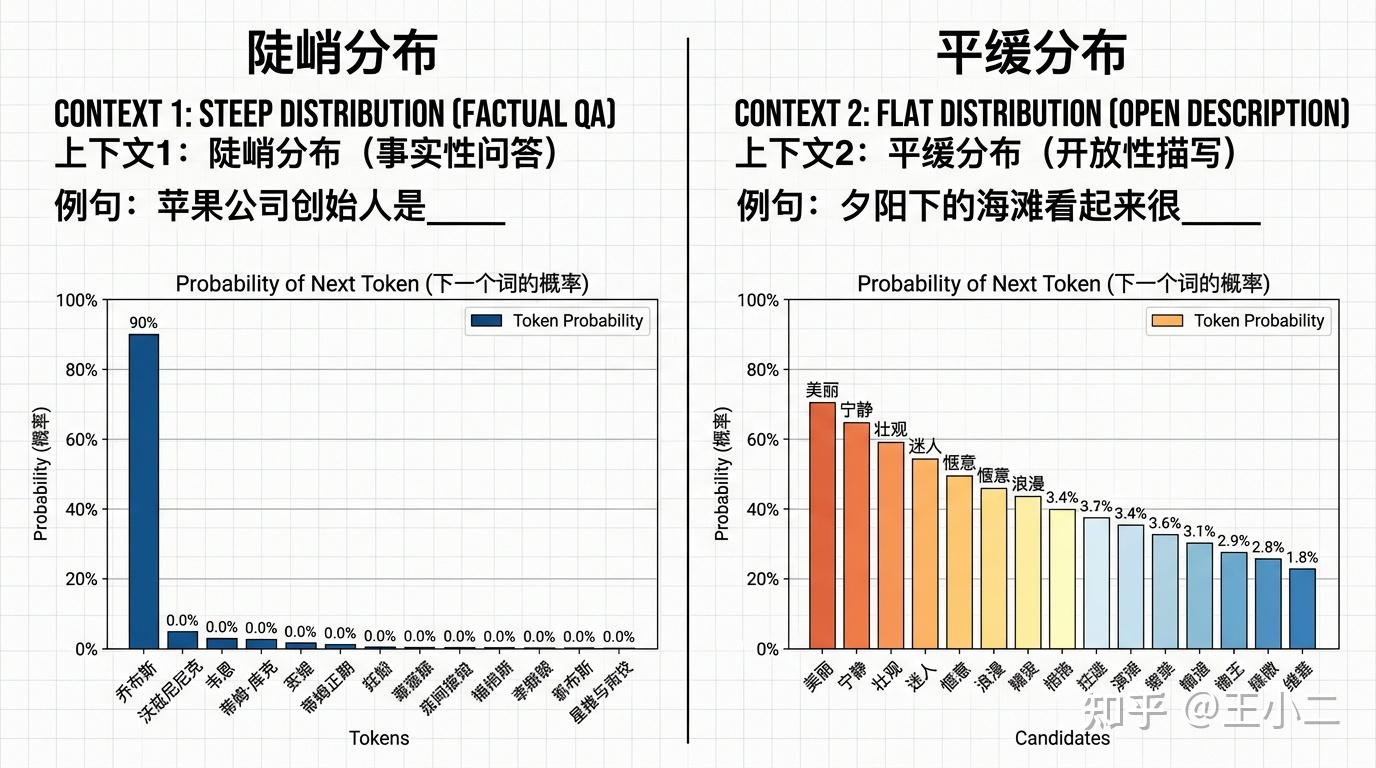
在深入讨论截断机制前,我们必须先理解自然语言的一个核心特征:语境会导致概率分布在“平缓”与“陡峭”之间动态交替。
自然语言预测中的陡峭与平缓分布对比
如上图所示,当面临事实性约束强的语境(如“苹果公司的创始人是”)时,模型对“史蒂夫·乔布斯”的预测概率可能高达 90%,形成一个陡峭分布(Steep Distribution);而在开放性描写语境(如“夕阳下的海滩看起来很”)中,“美丽”、“宁静”、“壮观”等多个词的概率可能都在 5% 到 15% 之间徘徊,形成一个平缓分布(Flat Distribution)。这种动态交替,正是导致早期截断策略出现局限性的根本原因。
Top-K:固定截断机制及其两难局限
Top-K 是一种最古老且直观的截断方案。它的底层逻辑极其简单粗暴:按照概率从高到低排序,只保留前 K 个候选词,其余全部丢弃(概率归零),随后将剩下的 K 个词的概率重新归一化。
在早期的开源模型中,API 默认往往会设置 top_k=50。这意味着无论模型当前的词汇表有十万个还是二十万个词,它永远只在排名前 50 的词中做选择。
然而,固定名额的 Top-K 很快在实践中暴露出一个致命的“两难困境”:
- 在平缓分布中容易“误杀”:当模型面临极具开放性的创作时,可能有 100 个词都相当合理(概率差距微小)。此时如果强行截断到
K=50,就会把第 51 到 100 个优秀的候选词无情剥夺,导致生成的文本词汇贫乏、缺乏惊喜。 - 在陡峭分布中放过“劣质词”:当模型极度确信下一个词只有一个正确答案(头名概率 99%)时,第 2 到第 50 名的词其实全是毫无逻辑的垃圾词汇。但因为 K 是固定值 50,这些垃圾词依然会被放入候选池。一旦在随后的抽卡中发生极小概率事件抽中了它们,文本就会立刻出现明显的语病或幻觉。
Top-p(核采样):基于累积概率的动态智慧
为了解决 Top-K 刻板的固定名额问题,学术界提出了 Top-p 采样(也称 Nucleus Sampling / 核采样)。它如今已成为各大 LLM API(如 OpenAI、Anthropic)中最主流的截断参数。
Top-p 不再固定保留多少个词,而是设定一个累积概率阈值(如 top_p=0.9)。模型同样会按概率从高到低排序候选词,然后逐个将它们的概率相加。一旦总和刚好达到或超过 0.9,截断立刻发生,排名在后面的词全被舍弃。
这种机制的精妙之处在于它的“动态适应性”:
- 遇到陡峭分布时:假设最高概率词占 88%,第二名占 3%,两者相加达到 0.91(超出了 0.9 的阈值)。此时,Top-p 会瞬间斩断后续所有词,等价于自动触发了
K=2,完美拦截了所有垃圾长尾词。 - 遇到平缓分布时:由于每个词的概率都很低(比如都在 1%~3% 之间),模型可能需要一路往下累加 50 甚至 80 个词,总和才能达到 0.9。此时它等价于自动放宽到
K=80,最大限度地保留了表达的多样性。
简而言之,Top-p 是用“累积面积”划定边界,完美契合了自然语言在不同语境下的动态变化需求。
Min-p:解决极度确信盲区的前沿探索
尽管 Top-p 表现卓越,但在极端边缘场景下依然存在缺陷。设想一种“极度不确信且极度平缓”的情况:模型对下一个词毫无头绪,最高概率的词仅仅只有 10%(甚至更低),剩下几百个词的概率都在 0.1% 到 1% 之间。如果此时 top_p=0.9,模型为了凑够 90% 的累积概率,被迫把成百上千个毫无意义的极低频词汇全部拉入候选池,这通常也是大模型产生“胡言乱语”的重灾区。
为了填补这一盲区,开源社区(如 llama.cpp 和 vLLM 等推断框架)近年来开始推广一种更先进的策略:Min-p(相对阈值截断)。
Min-p 不看排名,也不看累积概率,它完全以当前“最高概率词”作为基准线,按照设定比例划定一条及格线。假设你设置 min_p=0.1(即最高概率的 10% 作为阈值):
- 如果最高概率词是 80%,那么及格线就是 8%(80% × 0.1)。所有概率低于 8% 的词直接剔除。这保证了在模型有把握时,过滤极其严格。
- 如果最高概率词只有 20%,那么及格线自动降为 2%(20% × 0.1)。这保证了在模型迷茫时,能适度包容更多可能性,但绝不会放过那些概率仅有 0.5% 的绝对垃圾词。
Top-K、Top-p与Min-p的截断机制几何切分对比图
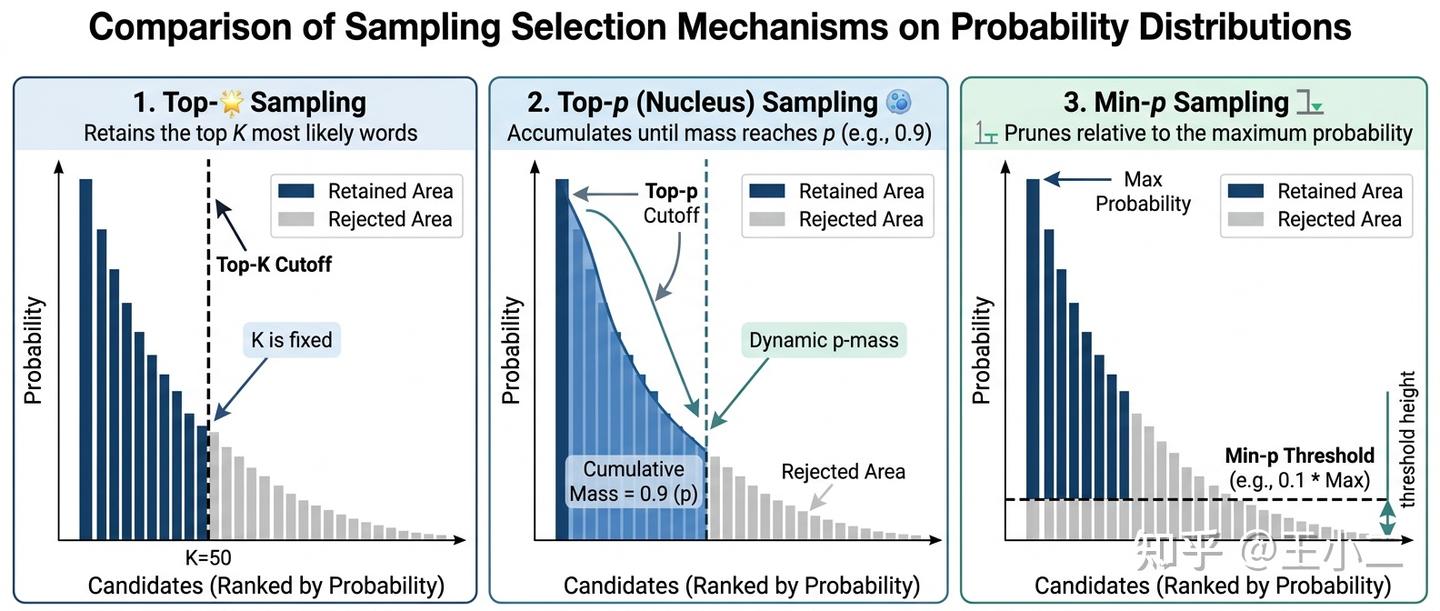
如上图的几何切分对比所示:Top-K 是一把垂直劈下的死板大斧(固定 X 轴截断);Top-p 是覆盖曲线下方面积的动态幕布;而 Min-p 则是基于最高山峰画出的一条自适应水平刻度线(相对 Y 轴截断)。
理解了这三种截断策略的演进逻辑,我们便能看清局部控制机制的核心诉求:在不破坏语境多样性的前提下,尽可能精准地剔除“必定导致错误的噪音”。然而,在真实的 API 调试中,我们往往不是单独使用某一个参数,而是将 Temperature 与 Top-p 等参数组合运用。当这些参数叠加在一起时,底层系统究竟是如何执行的?我们又该如何在逻辑推理、内容总结或创意写作等不同场景中找到最佳组合配方?这将是我们在下一章展开的实战重点。
4. 场景实战:不同任务下的最佳参数配置建议
当我们理解了 Temperature 的“全局滤镜”效应,以及 Top-K / Top-p / Min-p 的“物理剪刀”机制后,如何将这些理论应用到实际的生产工作流中?在真实的 API 调用场景里,不同参数绝非孤立运作,而是一个精密的协作系统。掌握它们在底层的执行顺序以及相互作用的化学反应,是彻底告别“玄学调参”的最后一步。
解密 API 底层的执行顺序:采样计算流水线
大多数开发者在调用大模型 API 时,会将一堆参数同时丢给接口。但实际上,在各大主流推理框架(如 HuggingFace transformers 或开源的高性能推理引擎 vLLM)的底层源码中,这些参数严格遵循着先后生效的流水线逻辑。
以 HuggingFace 的 LogitsProcessor 机制为例,模型对概率空间的动态裁剪遵循着以下标准顺序:
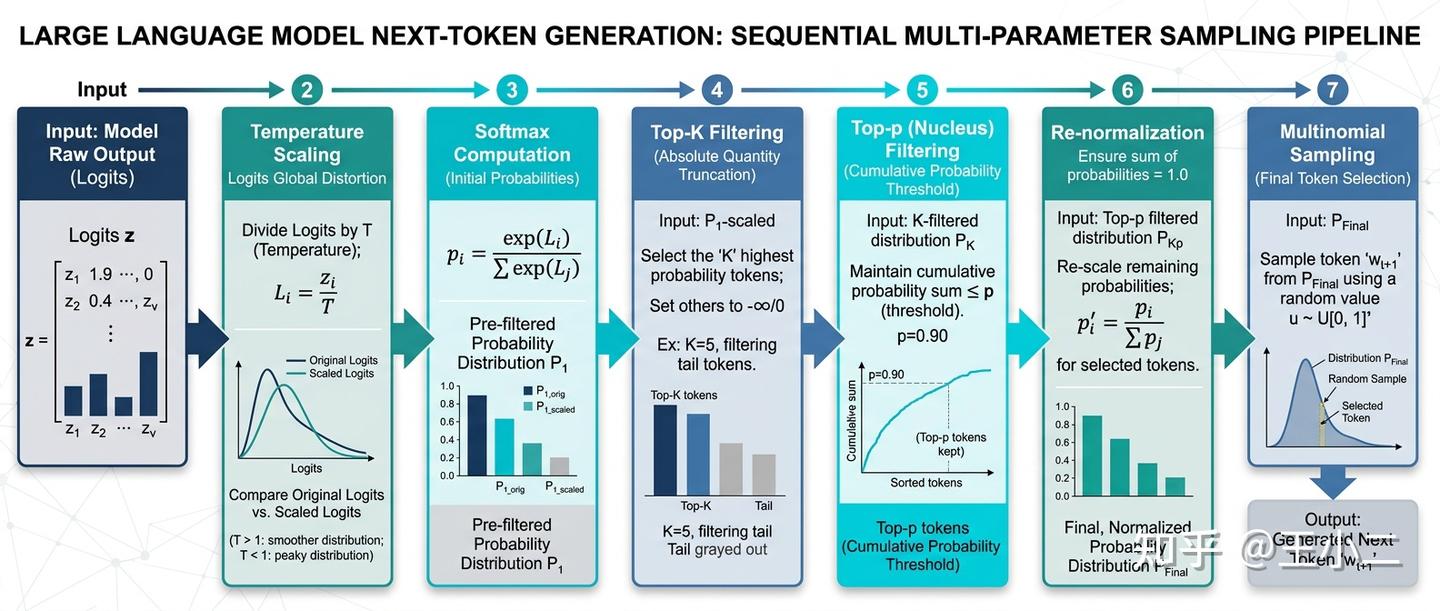
LLM API底层采样参数执行流水线示意图
- 原始输出(Logits)生成:模型网络吐出对词汇表中每个词的原始未归一化得分。
- Temperature 缩放:底层首先调用
TemperatureLogitsWarper,将所有 Logits 除以温度值 。这是在做全局的“揉捏”,拉伸或压平原始分布差异。 - Top-K 截断:接着调用
TopKLogitsWarper,按照绝对数值保留排名前 的得分候选词,强行舍弃排名靠外的“劣质尾巴”。 - Top-p 截断:随后调用
TopPLogitsWarper。框架内部会先对当前的 Logits 计算一次临时概率分布,按累积概率找到截断边界,并将边界外候选词的 Logits 直接“打入冷宫”(赋值为负无穷大-inf)。 - Softmax 与最终采样:最后,基于经过前几轮筛选后留下的 Logits,正式进行 Softmax 归一化,生成最终的概率分布,并扔一次“多面体骰子”决定最终被选中的 Token。
理解这条流水线至关重要。它意味着 Temperature 决定了候选词之间的相对竞争格局,而截断机制(Top-K / Top-p)决定了最终谁有资格登上牌桌参与抽卡。
联合调参禁忌:为什么官方建议“二选一”?
如果你仔细阅读过 OpenAI 的 API 文档,会发现一行极其关键的标注:“We generally recommend altering this (Temperature) or top_p but not both.”(我们通常建议调整 Temperature 或 Top-p,但尽量不要同时调整两者。)
为何官方要设立这样的调参禁忌?这是基于控制变量失效与概率分布失真的底层数学逻辑:
- 控制变量的逻辑悖论:Temperature 通过平滑或锐化分布来控制随机性,而 Top-p 通过调节候选池的大小来控制随机性。如果你同时调高 Temperature 并调低 Top-p,相当于你一边用高温把长尾词的概率拉升上来,一边又用极度严苛的 Top-p 将这些好不容易“冒头”的长尾词一刀切除。这种操作让两者的意图互相抵消,最终的输出往往难以预测。
- 过度裁剪导致分布失真:同时修改两者极易引发“畸形分布”。例如在高温(如 T=1.2)且极低 Top-p(如 p=0.3)的组合下,头部极少数的词概率差距被拉近,但其他所有候选词被强行抹杀。模型每次只能在区区两三个得分相近的词中抛硬币,极易丧失连贯的语境感,表现出类似于“醉汉说胡话”的逻辑断裂现象。
因此,工业界的最佳实践是:锚定一个参数作为常量(通常固定 Top-p = 0.95 或 1.0),专门通过微调 Temperature 来控制确定性;或者反之。
全场景参数配置速查表(SOP)
不同的工程任务对“确定性”与“多样性”的诉求截然不同。基于上述理论,我们为日常高频的 AI 应用场景梳理了以下实用的参数配置模板:
| 应用场景 | 任务特征描述 | Temperature推荐 | Top-p推荐 | 补充参数建议 |
|---|---|---|---|---|
| 代码生成 / 数据提取 | 需要严密的逻辑与100%的事实遵循,不允许自由发挥 | 0.0 - 0.2 | 1.0 (固定) | 追求极致的贪心搜索,禁用惩罚项以免影响正常语法。 |
| 文本总结 / 机器翻译 | 既要求信息准确无误,又需要表达通顺、自然平稳 | 0.3 - 0.7 | 1.0 (固定) | 适度释放一定的自由度,以便模型优化长句结构。 |
| 创意写作 / 头脑风暴 | 追求发散性思维、破除平庸,需要极高的词汇丰富度 | 0.8 - 1.2 | 1.0 (固定) | 配合使用 Frequency Penalty (0.5-1.0) 防止词汇冗余。 |
注:本表严格遵循“控制变量法”,将 Top-p 锚定为常量 1.0(即不进行截断),仅通过调节 Temperature 来控制输出多样性。在实际工程中,你也可以反向操作:固定 Temperature = 1.0,仅通过微调 Top-p 来实现同等控制。
场景一:逻辑推理与代码生成(低T,固定 Top-p,追求严密)
在编写代码、解析 JSON 或进行复杂数学推理时,代码的语法和推理的逻辑往往只有一条最优解(1+1 绝对等于 2)。此时应当在保持 Top-p 为 1.0 的前提下,开启极低温度(),本质上让模型回退到贪心搜索模式,扼杀所有的长尾幻觉可能。由于 Temperature 已经将最高分词的概率放大到接近 100%,此时任何额外的截断操作都毫无意义。
场景二:内容总结与机器翻译(中T,固定 Top-p,追求平稳一致)
对于摘要提炼、长文翻译或 RAG(检索增强生成)系统,我们希望模型输出符合人类语言习惯的流畅句子,但又绝对不能捏造输入中不存在的信息。保持 Top-p 为 1.0(不做额外物理截断),仅设定中等温度(如 0.3 - 0.7),能够让模型在表达方式上保留一定的遣词造句空间。适度降低的温度天然压制了低频突变词的概率,在单一变量下实现了准确性与可读性的平稳平衡。
场景三:创意写作与头脑风暴(高T,固定 Top-p,配合惩罚机制)
当你需要生成营销文案、构思小说大纲或头脑风暴时,平庸和可预测性才是最大的敌人。此时在固定 Top-p 为 1.0 的基础上,将 Temperature 拉高(0.8及以上),抹平概率分布的差异,迫使模型去探索概率空间的边缘,带来“意料之外”的惊喜。
值得注意的是,如果为了追求创造力而盲目将 Temperature 调至极端高温,极易引发第二章提到的幻觉与逻辑崩盘。因此在创意场景中,一种更稳妥的进阶做法是保持中高温度(如 0.8),并配合开启频率惩罚(Frequency Penalty)或存在惩罚(Presence Penalty)。它们会在模型输出过某些词汇后,动态打压这些词的后续生成概率,从而在不极端拉高随机性的前提下,强逼大模型“换着花样说话”,更安全地激发创作潜力。
大模型那看似深不可测的“黑盒”能力,在每一次生成下一个 Token 的微观瞬间,终究回归到数学逻辑与概率论的基石之上。从原始 Logits 的涌现,到 Temperature 的全局伸缩,再到 Top 截断家族的物理滤网,LLM 文本生成的本质,就是一场对概率空间进行精准计算与动态裁剪的微观舞蹈。理解并掌握这些参数背后的物理意义,便是我们从迷信“魔法提示词”的盲目试错者,蜕变为真正能够精准驾驭AI生产力的架构工程师的必经之路。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?
别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明:AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。


四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)