如何借助AI大模型实现交叉编译(以Cartographer为例)
如何借助AI大模型实现交叉编译(以Cartographer为例)
最近在弄ARM交叉编译,这里总结一下经验!
在大模型越来越好用的背景下,记录一下如何使用AI帮助我们快速的推进工作,首先ARM交叉编译不是一个算法或者知识点而是一系列经验操作。所以不会一次交互就能解决问题,也不会操作我们的电脑,因为这里需要配置环境,做具体的编译操作。那么借助AI是可以帮助我们构建一个流程框架,然后我们和AI一起再敲定细节,解决具体的问题。(这样一个从想法到步骤,再实施review这样的一个过程,其实就是vibe coding的范式,如果有好用的Agent理论上是更好的,这个不在本文的讨论范围)
1.如何开始
我会以Cartographer为例,假如我们最开始对交叉编译没有一点概念,可以首先告诉他整体需求:
我需要将cartographer算法(不包含ros部分)移植到arm板上,我现在已经有了编译工具(gcc-arm-13.3.0-x86_64-aarch64-linux),我需要做哪些工作?
根据回复就可以确定流程:
-
准备交叉编译环境
-
创建CMake工具链文件
-
交叉编译Cartographer的依赖库
-
交叉编译Cartographer
-
移植库到ARM板
-
编写独立应用(替代ROS部分)
到这里其实4-6步大家都是知道的,1-2步为了更规范的开始(环境隔离、创建CMake)是AI告诉我的。因此我进一步明确我的需求,并让他填充细节:
请给出详细的交叉编译过程,以便于我可以按照步骤一步步实现。如果需要我提供更多其它信息请告诉我,并且我不希望将工具链路径添加到环境变量中,因为我的编译环境是Ubuntu20.04虚拟机,还希望编译其它项目,不希望相互影响。
这里的过程的核心思想是确定步骤(类似Skill文档的作用),并且保证你和你的模型之间没有信息差,确保他需要的但是你不知道要提供给他的信息能够准确的互通。
然后就可以按照详细的步骤实现就可以了。不过在此之前,有必要对交叉编译工具链有一个基本的认识,以gcc-arm-13.3.0-x86_64-aarch64-linux工具链为例,表示这是一个用于交叉编译的 ARM64 (AArch64) 工具链,基于 GCC 13.3.0 版本构建,可以在 x86_64 主机上编译运行于 ARM64 设备(如树莓派、嵌入式开发板)的程序。以下是目录结构的详细解读:
| 目录名 | 作用说明 |
|---|---|
aarch64-buildroot-linux-gnu/ |
目标平台标识符,包含针对该架构的特定工具(如调试器、链接器等)。 |
bin/ |
核心工具链可执行文件,包含编译器(aarch64-linux-gnu-gcc)、链接器、汇编器等。 |
lib/、lib64/ |
工具链依赖的库文件(如 GCC 运行时库、链接器脚本等)。 |
include/ |
交叉编译时使用的头文件(如 C 标准库、内核头文件等)。 |
share/、doc/ |
文档和共享数据(如 GCC 的帮助信息、手册页)。 |
libexec/ |
内部工具(如 GCC 的插件、辅助程序)。 |
sbin/ |
系统管理工具(较少使用)。 |
usr/ |
可能包含额外的用户空间工具或库。 |
environment-setup |
环境配置脚本,用于设置交叉编译所需的环境变量(如 PATH、CROSS_COMPILE)。 |
etc/ |
配置文件目录。 |
另外,注意到有这样一个目录gcc-arm-13.3.0-x86_64-aarch64-linux/aarch64-buildroot-linux-gnu/sysroot。这是交叉编译工具链的 sysroot(系统根目录),它模拟了目标设备(ARM64 Linux)的完整文件系统结构。
下面给出我编译成功的库版本。
库版本推荐
| 库 | 编译版本 | 用途 | 状态 | 说明 |
|---|---|---|---|---|
| zlib | 1.3.1 | ✔ | ||
| bzip2 | 1.0.8 | ✔ | ||
| boost | 1.87.0 | C++库 | ✔ | |
| glog | 0.6.0 | 日志 | ✔ | 新版不兼容 |
| eigen | 3.4.0 | 数值计算 | ✔ | |
| opencv | 4.2.0 | 图像调试 | ✔ | |
| gtest | 1.16.0 | 测试 | ✔ | 不需要测试 |
| gflags | glog的依赖 | ✔ | ||
| lua | 5.2.4 | 参数配置 | ✔ | |
| ceres |
1.13.0 | 后端优化 | ✔ | 2.0的版本好编译但是接口不兼容,确保开启了OpenMP支持 |
| SuiteSparse | 5.7.1 |
ceres的依赖 | ✔ | 要适配ceres版本 |
| Metis | 5.1.0 | SuiteSparse的依赖 | ||
| lapack |
openblas的依赖 | 内嵌在openblas |
||
| openblas | 0.3.27 | SuiteSparse的依赖 | ✔ | |
| … | ||||
| protobuf |
3.19.4 | 数据序列化 | ✔ | |
| xzUtils | ||||
| abseil-cpp | 20230125.3 | C++库 | ✔ | |
| Cairo | 1.14.0 | 画图 | ||
| pixman | Cairo的依赖 |
当然,事情并没有这么简单!如果你根据AI提示一步一步的完成,大概率会踩到很多坑!
为了减少试错,接下来介绍一下踩过的坑以及可以提高效率的经验。
避坑指南
| 关注点 | 坑 | 避坑思路 |
|---|---|---|
| 版本选择 | AI更倾向于推荐更新更稳定的版本,但是这不一定适合我们自己的项目,否则容易出现接口不兼容。 | 搞清楚版本依赖再开始 |
| 库类型 | 如果全都是共享库没问题,如果是静态库也没问题,如果想混用也没问题,问题是要想提前想清楚每种方案的优劣势,不然还要重新编译。 | 搞清楚库类型再开始 |
| 编译选项 | 针对特定架构的优化编译选项 未开启PIC的各种问题 未保持库命名风格的各种问题 |
以下场景中必须开启 PIC: 1.你打算将这个静态库链接到一个共享库 (.so) 中。 2.你在某些架构(如 ARM64/aarch64)上遇到重定位错误。 3.你希望生成的代码具有更好的兼容性。 |
| 混合编译 | 生成库和生成可执行文件时,静态链接和动态链接同时使用,导致符号冲突(如glog)。 | 统一使用一种链接方式 |
| 库移植 | 压缩打包库,链接丢失 | tar -czvhf lib_all.tar.gz lib (注意加了 h 参数,这样会把所有 .so -> .so.xx -> .so.xx.x.x 都变成实体文件打包,避免链接失效) |
一些好用的指令
| 指令 | 作用 |
|---|---|
| nm | 符号检查如:nm /tmp/libpng_install/lib/libpng.a | grep png_riffle_palette_neon,确认libpng.a库中是否包含png_riffle_palette_neon |
| readelf | 参数检查如:readelf -h src/some_file.o | grep Type,检查some_file.o是否开启了某个参数 库架构检查如:readelf -h libglog.a |
| ldd | 查看动态库或可执行文件的动态库依赖 |
有一些点有必要展开说明。
2.记录有用的信息
因为在实际操作的过程中,我们会遇到各种而样的问题,我们也会逐步搞清楚一些问题,如果全部都在一个对话框让AI自己进行上下文关联,由于存在上下文爆炸,模型会自动压缩,造成信息丢失。如果它忘了前面的要求和错误,反复试错这个效率是不高的,我们可以开启新的对话框,通过记录有用的信息,让它聚焦在一个新问题上。(功能类似AGENT.md)
有用的信息比如:
-
我的整体需求
-
我的整体进度到哪里了,哪些已经解决(避免它在没必要的方向思考)
-
刚才配置好的环境配置信息(避免它重新定义不一致的环境)
-
已经在刚才交互中获取的信息(比如我的工具链不支持某些东西,避免它又绕回不可行的方案)
-
现在需要解决的问题(报错、以及涉及到的相应文件喂给它,避免它给的修改方案不符合实际是文件版本)
比如我会在提问的同时给出有用的信息:
3个附加信息如下:
交叉编译环境:虚拟机ubuntu20.04
信息1.编译工具
• 编译工具:gcc-arm-13.3.0-x86_64-aarch64-linux
• 工具链是基于Buildroot构建的,编译器文件名是 aarch64-buildroot-linux-gnu-gcc,
工具链使用了 toolchain-wrapper 包装器,工具链没有包含 Fortran 支持
信息2.已经配置/path/environment-setup
【具体内容】
信息3./path/arm_deps/aarch64-toolchain.cmake
【具体内容】
3.搞清楚版本依赖再开始
编译依赖库会涉及到二级依赖、甚至三级依赖,AI推荐的并不一定适配,所以现在宿主机环境编一个可以运行的,然后把所有依赖库的版本确定下来,避免因为接口不匹配重复返工,依赖层数越深,返工越麻烦。
而且在跟AI提问时,注意带上版本号,不然解决方案不一定适合(即使说了,也不一定不会混淆,但比不说好)
即使某些版本编译困难,确定兼容后再修改好编译的版本。不然最后虽然二级依赖编译过了,一级依赖还是接口不兼容,等于白干!
4.搞清楚库类型再开始
首先考虑这样一个需求:想把cartographer算法移植到ARM板端运行,需要生成cartographer核心库,以及算法数据和应用接口库,以及应用程序。
这里涉及的问题有:库类型在静态库和动态库两种类型选择上如何考量,包括算法库的依赖库。已知的考量因素包括库的加载和运行效率,项目前期和后期的对库的更新频度和便利性。
将以上问题提问给大模型,将会得到一个全面解答:
将 Google Cartographer 移植到 ARM 嵌入式平台(如基于 Cortex-A 系列的核心板)是一个典型的“高性能算法落地”场景。针对你提出的静态库与动态库的选择问题,结合 Cartographer 的架构特点(重度依赖 Ceres Solver、Eigen、Boost 等)以及 ARM 端的资源约束,以下是详细的考量分析和建议方案。
核心结论先行
对于 Cartographer 这种计算密集型且依赖复杂的 SLAM 算法,在 ARM 嵌入式场景下,推荐采用“混合策略”:
- 核心算法层(Cartographer Core + 重型依赖): 优先编译为 静态库 (
.a)。- 理由: 消除动态链接开销,确保实时性;避免 ARM Linux 发行版依赖缺失问题;方便整体优化(LTO)。
- 应用接口层(ROS Wrapper / API): 编译为 动态库 (
.so) 或直接链接进可执行文件。- 理由: 便于上层应用迭代更新,解耦业务逻辑与底层算法。
- 重型第三方依赖(Ceres, glog, gflags): 强烈建议 静态链接。
- 理由: 这些库在 ARM 上动态加载可能引发符号冲突或版本不兼容,且静态链接允许编译器进行跨模块优化。
4.1. 加载与运行效率 (Performance & Efficiency)
-
静态库 (
.a) 的优势:- 启动速度: 程序启动时无需动态链接器 (
ld-linux) 解析符号和重定位,对于需要快速启动的机器人应用(如看门狗重启)更有利。 - 运行时性能:
- 位置无关代码 (PIC) 开销: 动态库必须编译为
-fPIC(Position Independent Code),这在 ARM 架构上会占用额外的寄存器并略微增加指令跳转开销。Cartographer 内部包含大量矩阵运算(Eigen)和优化求解(Ceres),静态链接允许编译器生成针对特定 ARM 核心(如 Cortex-A72/A53)的最优指令序列,无需保留 PIC 的间接寻址。 - 链接时优化 (LTO): 如果整体静态链接,可以开启
-flto,编译器可以跨越库边界进行内联优化和死代码消除。这对于 Cartographer 这种调用链极深的算法至关重要,能显著降低函数调用开销。
- 位置无关代码 (PIC) 开销: 动态库必须编译为
- 缓存局部性: 代码段连续,有利于 CPU 指令缓存(I-Cache)。
- 启动速度: 程序启动时无需动态链接器 (
-
动态库 (
.so) 的劣势:- 在资源受限的 ARM 板上,动态链接带来的内存页增加和上下文切换开销虽然微小,但在高频调用的 SLAM 循环中(通常 10Hz-50Hz)会累积成可观的延迟抖动。
4.2. 依赖管理与移植便利性 (Dependency & Portability)
Cartographer 的依赖树较深:Cartographer -> Ceres Solver -> glog/gflags -> Eigen (头文件) -> Boost (部分模块) -> Lua (配置解析)。
-
静态库方案:
- 优点: “自包含” (Self-contained)。你只需要生成一个最终的可执行文件或少数几个
.a文件,复制到 ARM 板即可运行。不需要担心目标板上的libceres.so版本是否与编译环境一致,也不需要配置LD_LIBRARY_PATH。这对于嵌入式 Linux 裁剪系统(Buildroot/Yocto)非常友好,因为你可以只打包必要的库,而不必安装完整的开发环境到目标板。 - 缺点: 如果多个应用程序共用 Cartographer,内存中会有多份代码副本(现代 OS 有共享页机制,但静态库本身不具备显式共享属性,除非使用动态库)。
- 优点: “自包含” (Self-contained)。你只需要生成一个最终的可执行文件或少数几个
-
动态库方案:
- 优点: 多个进程共享同一份库内存。
- 缺点(痛点):
- 依赖地狱: 你需要确保 ARM 板上安装了正确版本的
libceres,libglog,liblua等。不同 ARM 发行版(Ubuntu Core vs. Buildroot)的库版本差异极大,极易导致Symbol not found或Segmentation Fault。 - ABI 兼容性: C++ 的 ABI(应用二进制接口)对编译器版本敏感。如果编译库的 GCC 版本与运行环境的 GCC 版本不一致(例如编译用 GCC 9,板载 GCC 7),动态库极易崩溃。静态链接在一定程度上缓解了 ABI 问题,因为符号在链接期就被解析了。
- 依赖地狱: 你需要确保 ARM 板上安装了正确版本的
4.3. 项目生命周期与更新频度 (Update Frequency)
-
前期(开发与调试阶段):
- 动态库更便利: 修改算法逻辑后,只需重新编译
.so文件替换到板上,无需重新链接整个应用程序,部署速度快。 - 调试友好: GDB 可以更方便地动态加载符号。
- 动态库更便利: 修改算法逻辑后,只需重新编译
-
后期(量产与维护阶段):
- 静态库更稳健: 产品定型后,算法库更新频度降低。此时稳定性压倒一切。静态库避免了因目标板系统升级导致依赖库版本变化而引发的崩溃。
- 版本控制: 将算法固化为静态库,可以确保固件版本与算法版本严格绑定,便于追溯。
4.4.针对 Cartographer 的具体移植建议架构
建议将系统划分为三层,采用不同的库类型策略:
第一层:基础依赖层 (Third-party Dependencies)
- 包含:
Ceres Solver,glog,gflags,lua,boost_system(如需)。 - 策略: 全部静态编译 (
.a)。 - 理由: 这些库内部逻辑复杂,动态链接容易出错。Ceres 是非线性优化的核心,静态链接并开启
-O3 -mcpu=native(或指定 ARM 架构) 能最大化求解速度。
第二层:Cartographer 核心算法层 (Core Algorithm)
- 包含:
libcartographer_common,libcartographer_mapping,libcartographer_sensor等。 - 策略: 静态库 (
.a)。 - 理由:
- Cartographer 内部模块间调用极其频繁(如 Local SLAM 到 Global SLAM 的数据传递)。
- 避免动态库导出符号的复杂性(Cartographer 并非所有类都设计了
export宏)。 - 便于进行整体 LTO 优化。
第三层:应用接口与业务层 (Application Interface & App)
- 包含:
libcartographer_ros_api.so(可选):封装 ROS 话题订阅、消息转换、参数加载等业务逻辑。cartographer_node(可执行文件):主程序。
- 策略:
- 方案 A (高内聚,推荐用于最终产品): 将第二层的静态库直接链接进可执行文件。生成单一二进制文件。
- 优点: 部署最简单,性能最好,无外部依赖。
- 方案 B (解耦,推荐用于多应用共享或频繁迭代): 将 Cartographer 核心打包为
libcartographer_engine.so。- 前提: 需要修改 Cartographer 源码,显式导出需要对外暴露的 C/C++ 接口类(使用
__attribute__((visibility("default"))))。 - 优点: 上层应用(如不同的机器人车型)可以复用同一个算法库,仅更新上层业务逻辑。
- 前提: 需要修改 Cartographer 源码,显式导出需要对外暴露的 C/C++ 接口类(使用
- 方案 A (高内聚,推荐用于最终产品): 将第二层的静态库直接链接进可执行文件。生成单一二进制文件。
4.5. 针对 ARM 平台的特殊优化提示
- 交叉编译工具链: 务必使用与目标板匹配的工具链(如
gcc-arm-linux-gnueabihf或aarch64-linux-gnu)。 - NEON 指令集加速: Cartographer 大量使用 Eigen 进行矩阵运算。在编译静态库时,务必开启 NEON 优化:
- CMake 参数:
-DEIGEN_USE_NEON=ON(如果 Ceres/Eigen 支持) 或在 CXXFLAGS 中添加-mfpu=neon -mfloat-abi=hard(ARMv7) 或-march=armv8-a+simd(ARMv8)。 - 静态链接能更好地让编译器感知到这些标志并应用于所有内部函数。
- CMake 参数:
- 内存管理: ARM 板内存通常有限(2GB-4GB)。
- 静态链接可能会导致最终二进制文件体积变大(因为未使用的代码如果没有被链接器剔除会保留),但可以通过
-Wl,--gc-sections链接参数去除未使用的段。 - 动态库虽然文件小,但运行时每个进程加载都会占用独立的内存页(Text Segment 除外,如果是共享库)。对于单进程运行的 SLAM 节点,静态链接通常更节省总内存开销(无动态链接器开销)。
- 静态链接可能会导致最终二进制文件体积变大(因为未使用的代码如果没有被链接器剔除会保留),但可以通过
- Ceres Solver 配置: 编译 Ceres 静态库时,建议禁用不必要的求解器后端(如仅保留
CXSparse或SuiteSparse中的一个,视精度和速度权衡而定),以减小体积。
4.6.总结决策表
| 考量因素 | 静态库 (.a) |
动态库 (.so) |
Cartographer 移植推荐 |
|---|---|---|---|
| 运行效率 | ⭐⭐⭐⭐⭐ (无 PIC 开销,支持 LTO) | ⭐⭐⭐ (有间接跳转开销) | 静态库 (核心算法必须) |
| 启动速度 | ⭐⭐⭐⭐⭐ (快) | ⭐⭐⭐ (需解析符号) | 静态库 |
| 依赖管理 | ⭐⭐⭐⭐⭐ (自包含,无依赖地狱) | ⭐⭐ (需目标板安装对应版本) | 静态库 (尤其是 Ceres/Lua) |
| 调试便利 | ⭐⭐⭐ (重链接慢) | ⭐⭐⭐⭐⭐ (替换快) | 前期可用动态,后期转静态 |
| 更新频度 | 低 (需重链接) | 高 (热替换) | 算法稳定后选静态 |
| 多进程共享 | ❌ (内存不共享) | ✅ (共享 Text 段) | SLAM 通常单进程,静态库足矣 |
| ABI 兼容性 | ⭐⭐⭐⭐ (链接期检查) | ⭐⭐ (运行期易崩溃) | 静态库 |
最终建议路径:
在开发初期,为了方便调试,可以将 Cartographer 编译为动态库。但在进入集成测试和量产阶段前,务必切换为全静态链接模式(将 Ceres、glog、Cartographer 核心全部静态链接进主程序),以获得最高的运行效率、最稳定的依赖环境和最简便的部署流程。
5.保留编译日志
这个日志不是终端打印或保存的,而是我们的操作记录,特别是cmake的参数和修改的编译配置文件。
这样做的好处:
-
便于问题回溯,知道自己做了哪些编译开关(避免一个地方多次踩坑)
-
便于重操做(比如修改版本后重编)
全静态链接模式(将 Ceres、glog、Cartographer 核心全部静态链接进主程序),以获得最高的运行效率、最稳定的依赖环境和最简便的部署流程。
5.保留编译日志
这个日志不是终端打印或保存的,而是我们的操作记录,特别是cmake的参数和修改的编译配置文件。
这样做的好处:
-
便于问题回溯,知道自己做了哪些编译开关(避免一个地方多次踩坑)
-
便于重操做(比如修改版本后重编)
最后,奉上成功截图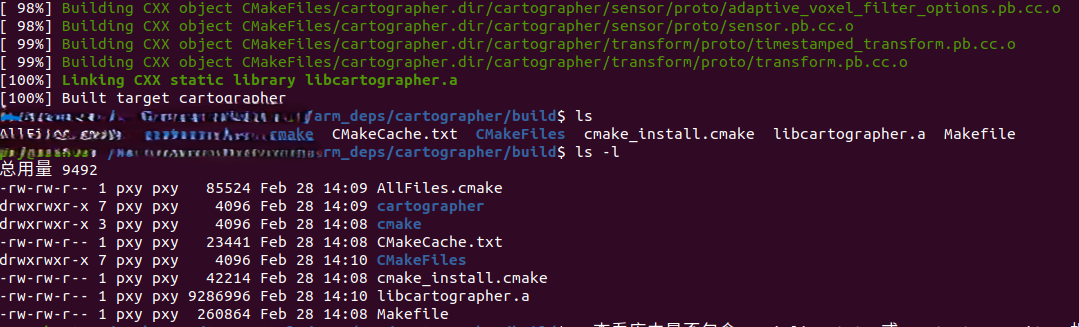

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)