海南专升本数据库
第一章数据库的基本概念
本章预览
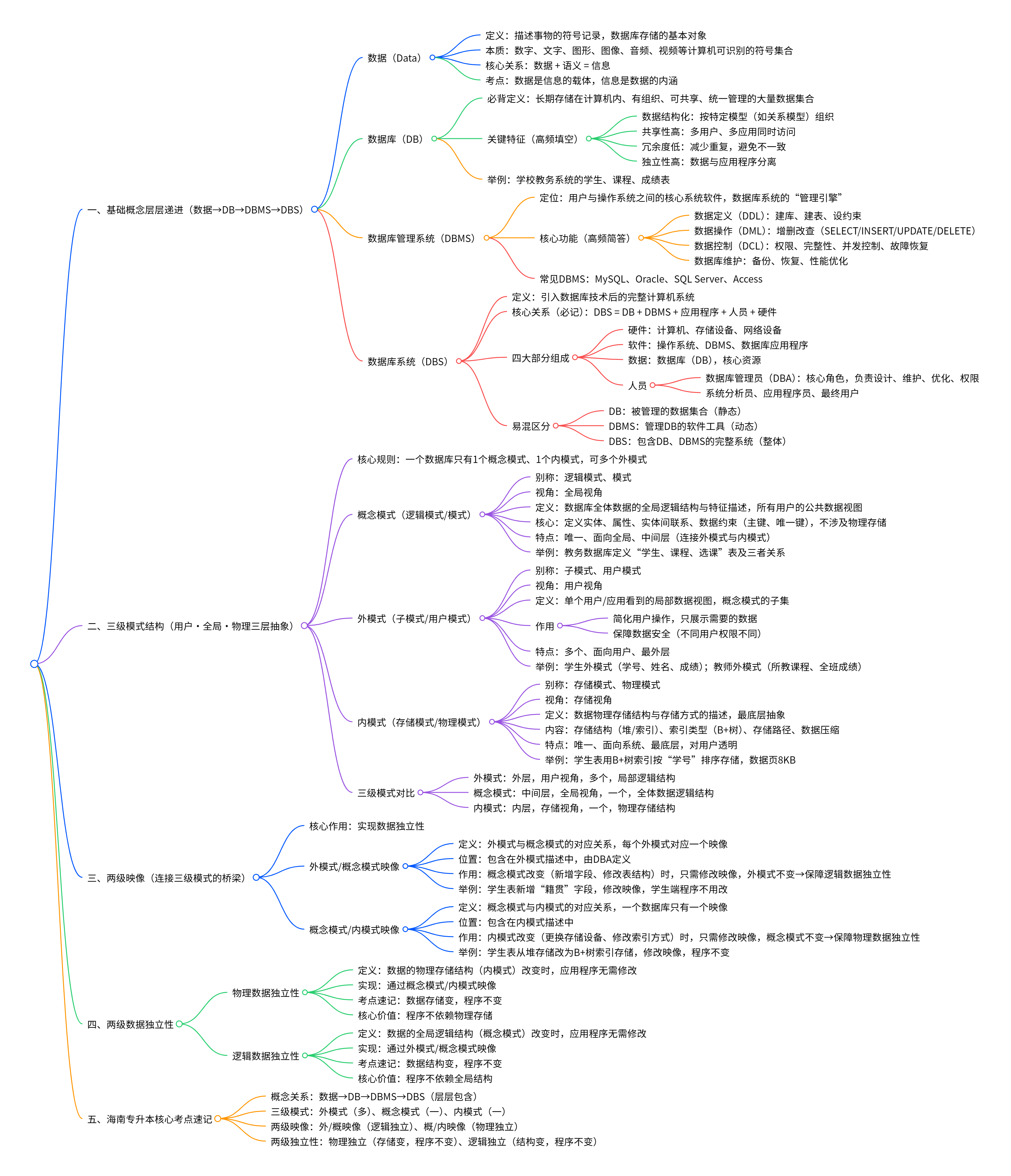
1.数据、数据库
(1).数据(Data)
- 定义:描述事物的符号记录,是数据库存储的基本对象。
- 本质:不仅是数字、文字,还包括图形、图像、音频、视频等能被计算机识别、存储和处理的符号集合,数据 + 语义 = 信息(如 “20” 本身无意义,“学生年龄 20 岁” 才是信息)。
- 专升本考点:数据是信息的载体,信息是数据的内涵。
(2). 数据库(Database,DB)
- 核心定义(必背):长期存储在计算机内、有组织、可共享、统一管理的大量数据集合。
- 关键特征(高频填空):
- 数据结构化:按特定数据模型(如关系模型)组织,不是杂乱堆积。
- 共享性高:多用户、多应用可同时访问。
- 冗余度低:减少重复数据,节省空间、避免不一致。
- 独立性高:数据与应用程序分离(后续两级独立性详解)。
- 举例:学校教务系统的 “学生数据库”,包含学生表、课程表、成绩表等结构化数据。
2.数据库管理系统、数据库系统、数据库系统的组成
(1). 数据库管理系统(DBMS)
- 定义:位于用户与操作系统之间的核心系统软件,是数据库系统的 “管理引擎”。
- 核心功能(高频简答):
- 数据定义(DDL):定义数据库结构(建表、建库、设约束)。
- 数据操作 (DML):实现增删改查(SQL 的
SELECT/INSERT/UPDATE/DELETE)。- 数据控制(DCL):安全控制(权限)、完整性控制、并发控制、故障恢复。
- 数据库维护:备份、恢复、性能优化。
- 常见 DBMS:MySQL、Oracle、SQL Server、Access(专升本常考)。
(2). 数据库系统(DBS)
- 定义:引入数据库技术后的完整计算机系统,是软硬件、数据、人员的集合。
- 核心关系(必记):DBS = DB + DBMS + 应用程序 + 人员 + 硬件。
- 与 DB、DBMS 的区别:
- DB:被管理的数据集合(静态)。
- DBMS:管理 DB 的软件工具(动态)。
- DBS:包含 DB、DBMS 的完整系统(整体)。
(3). 数据库系统的组成(四大部分,高频多选 / 填空)
- 硬件:计算机、存储设备(硬盘)、网络设备等,支撑系统运行。
- 软件:操作系统、DBMS、数据库应用程序(如教务管理系统)。
- 数据:数据库(DB),系统的核心资源。
- 人员:
- 数据库管理员(DBA):负责数据库设计、维护、优化、权限管理(核心角色)。
- 系统分析员、应用程序员、最终用户。
3.三级模式(概念模式、外模式、内模式)
三级模式是数据库的三层抽象结构,从用户、全局、物理三个视角描述数据,一个数据库只有一个概念模式、一个内模式,可多个外模式。
(1). 概念模式(Conceptual Schema,也称模式 / 逻辑模式)
- 定义:数据库全体数据的全局逻辑结构与特征描述,是所有用户的公共数据视图。
- 核心:定义实体、属性、实体间联系、数据约束(如主键、唯一键),不涉及物理存储。
- 特点:唯一、面向全局、中间层(连接外模式与内模式)。
- 举例:教务数据库的概念模式定义 “学生(学号,姓名,年龄,性别)、课程(课程号,课程名,学分)、选课(学号,课程号,成绩)” 及三者关系。
(2). 外模式(External Schema,也称子模式 / 用户模式)
- 定义:单个用户 / 应用看到的局部数据视图,是概念模式的子集。
- 作用:
- 简化用户操作,只展示需要的数据。
- 保障数据安全(不同用户权限不同,如学生只能看自己成绩,教师可看全班)。
- 特点:多个、面向用户、最外层。
- 举例:学生外模式只包含 “学号、姓名、所选课程、成绩”;教师外模式包含 “所教课程、学生成绩、课程信息”。
(3). 内模式(Internal Schema,也称存储模式 / 物理模式)
- 定义:数据物理存储结构与存储方式的描述,是最底层抽象。
- 内容:数据存储结构(堆存储 / 索引存储)、索引类型(B + 树)、存储路径、数据压缩方式等。
- 特点:唯一、面向系统、最底层,对用户透明。
- 举例:学生表数据用 B + 树索引按 “学号” 排序存储,数据页大小 8KB。
(4).三级模式对比表(专升本易混点)
模式 别称 视角 数量 核心内容 层次 外模式 子模式 / 用户模式 用户视角 多个 局部逻辑结构、用户视图 外层 概念模式 逻辑模式 / 模式 全局视角 一个 全体数据逻辑结构、联系 中间层 内模式 存储模式 / 物理模式 存储视角 一个 物理存储结构、存取方式 内层
4.两级映像
两级映像是连接三级模式的桥梁,核心作用是实现数据独立性(专升本核心原理)。
(1). 外模式 / 概念模式映像
- 定义:定义外模式与概念模式之间的对应关系,每个外模式对应一个映像。
- 位置:包含在外模式的描述中,由 DBA 定义。
- 作用:当概念模式改变(如新增字段、修改表结构)时,只需修改该映像,外模式不变,应用程序无需修改 → 保障逻辑数据独立性。
- 举例:概念模式给学生表新增 “籍贯” 字段,学生外模式无需包含该字段,修改映像即可,学生端程序不用改。
(2). 概念模式 / 内模式映像
- 定义:定义概念模式与内模式之间的对应关系,一个数据库只有一个映像。
- 位置:包含在内模式的描述中。
- 作用:当内模式改变(如更换存储设备、修改索引方式)时,只需修改该映像,概念模式不变,应用程序无需修改 → 保障物理数据独立性。
- 举例:学生表从堆存储改为 B + 树索引存储,修改映像即可,概念模式和应用程序不变。
5.两级数据独立性(物理、逻辑)
数据独立性指数据与应用程序相互独立,数据变化不影响程序,是数据库的核心优势。
(1). 物理数据独立性
- 定义:数据的物理存储结构(内模式)改变时,应用程序无需修改。
- 实现:通过概念模式 / 内模式映像实现,修改映像屏蔽物理变化。
- 专升本考点:物理独立性是 “数据存储变,程序不变”。
(2). 逻辑数据独立性
- 定义:数据的全局逻辑结构(概念模式)改变时,应用程序无需修改。
- 实现:通过外模式 / 概念模式映像实现,修改映像屏蔽逻辑变化。
- 专升本考点:逻辑独立性是 “数据结构变,程序不变”。
(3).两级独立性对比(高频简答)
独立性 对应映像 数据变化层面 程序影响 核心价值 物理独立性 概念模式 / 内模式 内模式(物理存储) 无影响 程序不依赖物理存储 逻辑独立性 外模式 / 概念模式 概念模式(全局逻辑) 无影响 程序不依赖全局结构
6.海南专升本考点总结(必背)
- 核心概念关系:数据→DB→DBMS→DBS(层层包含)。
- 三级模式:外模式(多)、概念模式(一)、内模式(一)。
- 两级映像:外 / 概映像(逻辑独立)、概 / 内映像(物理独立)。
- 两级独立性:物理独立(存储变,程序不变)、逻辑独立(结构变,程序不变)
第二章数据模型
本章预览
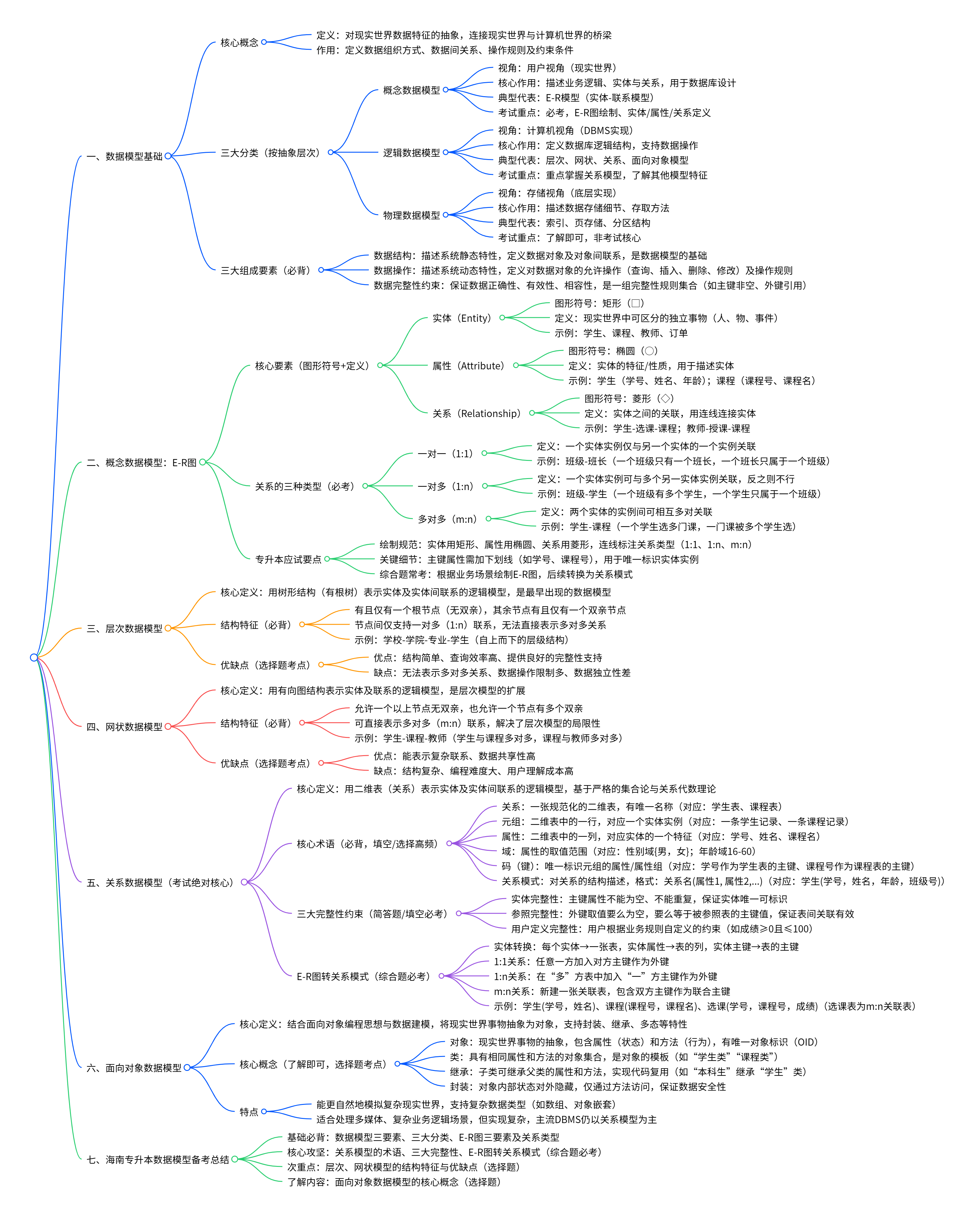
1.数据模型:概念、分类、组成要素
(1). 核心概念
数据模型是对现实世界数据特征的抽象,是数据库系统的核心与基础,用于定义数据的组织方式、数据间关系、操作规则及约束条件,是连接现实世界与计算机世界的桥梁。
(2). 三大分类(按抽象层次)
模型类型 视角 核心作用 典型代表 考试重点 概念数据模型 用户视角(现实世界) 描述业务逻辑、实体与关系,用于数据库设计 E-R 模型(实体 - 联系模型) 必考,E-R 图绘制、实体 / 属性 / 关系定义 逻辑数据模型 计算机视角(DBMS 实现) 定义数据库逻辑结构,支持数据操作 层次、网状、关系、面向对象模型 重点掌握关系模型,了解其他模型特征 物理数据模型 存储视角(底层实现) 描述数据存储细节、存取方法 索引、页存储、分区结构 了解即可,非考试核心
(3). 三大组成要素(必背)
- 数据结构:描述系统静态特性,定义数据库中数据对象(如实体、表)及对象间的联系,是数据模型的基础。
- 数据操作:描述系统动态特性,定义对数据对象的允许操作(查询、插入、删除、修改)及操作规则。
- 数据完整性约束:保证数据正确性、有效性、相容性,是一组完整性规则集合(如主键非空、外键引用)。
2.概念数据模型:E-R 图(实体、属性、关系)
E-R(Entity-Relationship)模型是专升本综合题高频考点,核心是用图形化方式描述现实世界的数据逻辑,由实体、属性、关系三要素构成。
(1). 核心要素(图形符号 + 定义)
要素 英文 图形符号 定义 示例 实体 Entity 矩形(□) 现实世界中可区分的独立事物(人、物、事件) 学生、课程、教师、订单 属性 Attribute 椭圆(○) 实体的特征 / 性质,用于描述实体 学生:学号、姓名、年龄;课程:课程号、课程名 关系 Relationship 菱形(◇) 实体之间的关联,用连线连接实体 学生 - 选课 - 课程;教师 - 授课 - 课程
(2). 关系的三种类型(必考)
- 一对一(1:1):一个实体实例仅与另一个实体的一个实例关联。
示例:班级 - 班长(一个班级只有一个班长,一个班长只属于一个班级)。
- 一对多(1:n):一个实体实例可与多个另一实体实例关联,反之则不行。
示例:班级 - 学生(一个班级有多个学生,一个学生只属于一个班级)。
- 多对多(m:n):两个实体的实例间可相互多对关联。
示例:学生 - 课程(一个学生选多门课,一门课被多个学生选)。
(3). 专升本应试要点
- 绘制规范:实体用矩形、属性用椭圆、关系用菱形,连线标注关系类型(1:1、1:n、m:n)。
- 关键细节:主键属性需加下划线(如学号、课程号),用于唯一标识实体实例。
- 综合题常考:根据业务场景绘制 E-R 图,后续转换为关系模式(见关系模型部分)。
3.层次数据模型
(1). 核心定义
用树形结构(有根树) 表示实体及实体间联系的逻辑模型,是最早出现的数据模型。
(2). 结构特征(必背)
- 有且仅有一个根节点(无双亲),其余节点有且仅有一个双亲节点。
- 节点间仅支持一对多(1:n) 联系,无法直接表示多对多关系。
- 示例:学校 - 学院 - 专业 - 学生(自上而下的层级结构)。
(3.) 优缺点(选择题考点)
- 优点:结构简单、查询效率高、提供良好的完整性支持。
- 缺点:无法表示多对多关系、数据操作限制多、数据独立性差。
4.网状数据模型
(1). 核心定义
用有向图结构表示实体及联系的逻辑模型,是层次模型的扩展。
(2). 结构特征(必背)
- 允许一个以上节点无双亲,也允许一个节点有多个双亲。
- 可直接表示多对多(m:n) 联系,解决了层次模型的局限性。
- 示例:学生 - 课程 - 教师(学生与课程多对多,课程与教师多对多)。
(3). 优缺点(选择题考点)
- 优点:能表示复杂联系、数据共享性高。
- 缺点:结构复杂、编程难度大、用户理解成本高。
5.关系数据模型(考试绝对核心)
关系模型是当前主流、专升本数据库考试重中之重,所有后续 SQL、关系代数、规范化均基于此模型。
(1). 核心定义
用二维表(关系) 表示实体及实体间联系的逻辑模型,基于严格的集合论与关系代数理论。
(2). 核心术语(必背,填空 / 选择高频)
术语 定义 对应二维表 关系 一张规范化的二维表,有唯一名称 学生表、课程表 元组 二维表中的一行,对应一个实体实例 一条学生记录、一条课程记录 属性 二维表中的一列,对应实体的一个特征 学号、姓名、课程名 域 属性的取值范围 性别域:{男,女};年龄域:16-60 码(键) 唯一标识元组的属性 / 属性组 学号(作为学生表的主键)、课程号(作为课程表的主键)
关系模式 对关系的结构描述,格式:关系名 (属性 1, 属性 2,...) 学生 (学号,姓名,年龄,班级号)
(3). 三大完整性约束(简答题 / 填空必考)
- 实体完整性:主键属性不能为空、不能重复,保证实体唯一可标识。
- 参照完整性:外键取值要么为空,要么等于被参照表的主键值,保证表间关联有效。
- 用户定义完整性:用户根据业务规则自定义的约束(如成绩≥0 且≤100)。
(4). 专升本应试核心
- E-R 图转关系模式:
- 每个实体→一张表,实体属性→表的列,实体主键→表的主键。
- 1:1 关系:任意一方加入对方主键作为外键。
- 1:n 关系:在 “多” 方表中加入 “一” 方主键作为外键。
- m:n 关系:新建一张关联表,包含双方主键作为联合主键。
- 示例:学生(学号,姓名)、课程(课程号,课程名)、选课(学号,课程号,成绩)(选课表为 m:n 关联表)。
6.面向对象数据模型
(1). 核心定义
结合面向对象编程思想与数据建模,将现实世界事物抽象为对象,支持封装、继承、多态等特性。
(2). 核心概念(了解即可,选择题考点)
- 对象:现实世界事物的抽象,包含属性(状态) 和方法(行为),有唯一对象标识(OID)。
- 类:具有相同属性和方法的对象集合,是对象的模板(如 “学生类”“课程类”)。
- 继承:子类可继承父类的属性和方法,实现代码复用(如 “本科生” 继承 “学生” 类)。
- 封装:对象内部状态对外隐藏,仅通过方法访问,保证数据安全性。
(3). 特点
- 能更自然地模拟复杂现实世界,支持复杂数据类型(如数组、对象嵌套)。
- 适合处理多媒体、复杂业务逻辑场景,但实现复杂,主流 DBMS 仍以关系模型为主。
7.海南专升本数据模型备考总结
- 基础必背:数据模型三要素、三大分类、E-R 图三要素及关系类型。
- 核心攻坚:关系模型的术语、三大完整性、E-R 图转关系模式(综合题必考)。
- 次重点:层次、网状模型的结构特征与优缺点(选择题)。
- 了解内容:面向对象数据模型的核心概念(选择题)。
第三章关系数据库理论
本章预览
1.关系模型(高频考点)
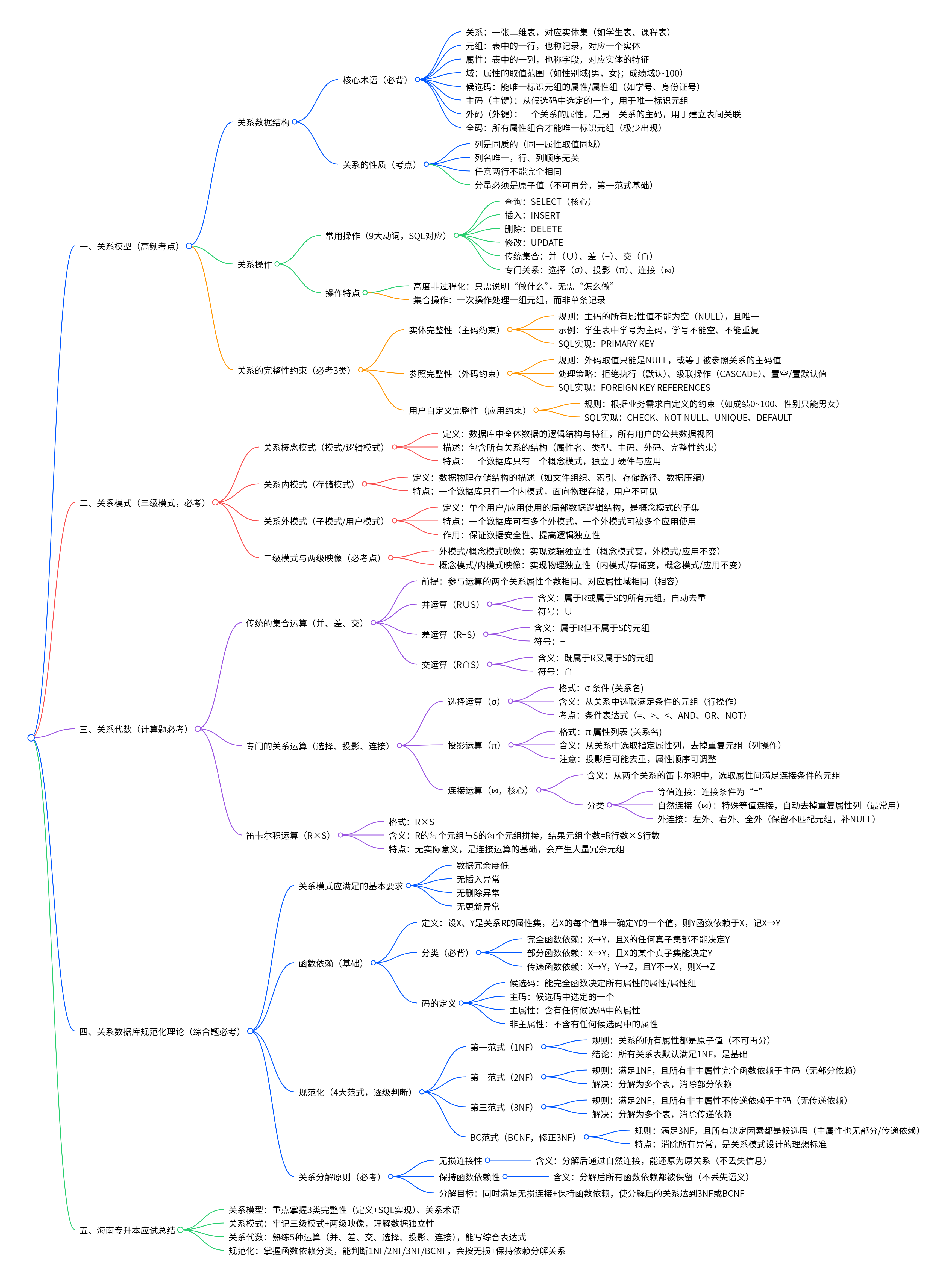
关系模型是关系数据库的基础,由数据结构、关系操作、完整性约束三部分组成。
(1).关系数据结构
关系模型用二维表表示数据,考试需掌握核心术语与性质:
核心术语(必背)
- 关系:一张二维表,对应现实世界的一个实体集(如学生表、课程表)。
- 元组:表中的一行,也称记录,对应一个实体(如 “张三,2023001,计算机”)。
- 属性:表中的一列,也称字段,对应实体的特征(如学号、姓名、专业)。
- 域:属性的取值范围(如性别域:{男,女};成绩域:0~100)。
- 候选码:能唯一标识一个元组的属性 / 属性组(如学号、身份证号)。
- 主码(主键):从候选码中选定的一个,用于唯一标识元组(如选 “学号” 为主码)。
- 外码(外键):一个关系的属性,是另一关系的主码,用于建立表间关联(如
成绩表中的"学号"字段是学生表的外键)。
- 全码:所有属性组合才能唯一标识元组(极少出现)。
关系的性质(考点)
- 列是同质的(同一属性取值同域)。
- 列名唯一,行、列顺序无关。
- 任意两行不能完全相同。
- 分量必须是原子值(不可再分,是第一范式基础)。
(2).关系操作
关系操作是对关系的运算,操作对象与结果都是关系,核心是查询,辅以增删改。
常用操作(9 大动词,SQL 对应)
- 查询:SELECT(核心)
- 插入:INSERT
- 删除:DELETE
- 修改:UPDATE
- 传统集合:并(∪)、差(−)、交(∩)
- 专门关系:选择(σ)、投影(π)、连接(⋈)
操作特点
- 高度非过程化:只需说明 “做什么”,无需 “怎么做”。
- 集合操作:一次操作处理一组元组,而非单条记录。
(3).关系的完整性约束(必考 3 类)
完整性约束保证数据正确、有效、相容,违反时系统拒绝执行。
1. 实体完整性(主码约束)
- 规则:主码的所有属性值不能为空(NULL),且唯一。
- 示例:学生表(学号,姓名,专业)中,学号为主码,学号不能空、不能重复。
- 考试:常考定义、SQL 实现(PRIMARY KEY)。
2. 参照完整性(外码约束)
- 规则:外码取值只能是 NULL,或等于被参照关系的主码值。
- 示例:成绩表(学号,课程号,成绩)中,学号是学生表外码,学号要么为空,要么是学生表中存在的学号。
- 处理策略:拒绝执行(默认)、级联操作(CASCADE)、置空 / 置默认值。
- 考试:常考外码定义、参照关系判断、SQL 实现(FOREIGN KEY REFERENCES)。
3. 用户自定义完整性(应用约束)
- 规则:根据业务需求自定义的约束(如成绩 0~100、性别只能男女、年龄≥18)。
- 实现:SQL 用 CHECK、NOT NULL、UNIQUE、DEFAULT 等。
- 示例:成绩表中 “成绩 CHECK (成绩 BETWEEN 0 AND 100)”。
2.关系模式(三级模式,必考)
关系模式是对关系的结构描述,对应数据库三级模式结构。
(1).关系概念模式(模式 / 逻辑模式)
- 定义:数据库中全体数据的逻辑结构与特征,是所有用户的公共数据视图。
- 描述:包含所有关系的结构(属性名、类型、主码、外码、完整性约束)。
- 特点:一个数据库只有一个概念模式,独立于硬件与应用。
(2).关系内模式(存储模式)
- 定义:数据物理存储结构的描述(如文件组织、索引、存储路径、数据压缩)。
- 特点:一个数据库只有一个内模式,面向物理存储,用户不可见。
(3).关系外模式(子模式 / 用户模式)
- 定义:单个用户 / 应用使用的局部数据逻辑结构,是概念模式的子集。
- 特点:一个数据库可有多个外模式,一个外模式可被多个应用使用。
- 作用:保证数据安全性(用户只能访问自己的外模式)、提高逻辑独立性。
(4).三级模式与两级映像(必考点)
- 外模式 / 概念模式映像:实现逻辑独立性(概念模式变,外模式 / 应用不变)。
- 概念模式 / 内模式映像:实现物理独立性(内模式 / 存储变,概念模式 / 应用不变)。
3.关系代数(计算题必考)
关系代数是关系操作的数学基础,用运算表达查询,是 SQL 的理论依据。
(1).传统的集合运算(并、差、交)
前提:参与运算的两个关系属性个数相同、对应属性域相同(相容)。
1. 并运算(R∪S)
- 含义:属于 R 或属于 S 的所有元组,自动去重。
- 示例:R(1 班学生)、S(2 班学生),R∪S = 所有学生。
- 符号:∪
2. 差运算(R−S)
- 含义:属于 R 但不属于 S 的元组。
- 示例:R(所有学生)、S(已选课学生),R−S = 未选课学生。
- 符号:−
3. 交运算(R∩S)
- 含义:既属于 R 又属于 S 的元组。
- 示例:R(男生)、S(党员),R∩S = 男党员。
- 符号:∩
(2).专门的关系运算(选择、投影、连接)
1. 选择运算(σ)
- 格式:σ 条件 (关系名)
- 含义:从关系中选取满足条件的元组(行操作)。
- 示例:σ 成绩 > 90 (成绩表) → 筛选 90 分以上的成绩记录。
- 考点:条件表达式(=、>、<、AND、OR、NOT)。
2. 投影运算(π)
- 格式:π 属性列表1,属性列表2 (关系名)
- 含义:从关系中选取指定属性列,去掉重复元组(列操作)。
- 示例:π 学号,姓名 (学生表) → 只保留学号、姓名两列。
- 注意:投影后可能去重,属性顺序可调整。
3. 连接运算(⋈,核心)
- 含义:从两个关系的笛卡尔积中,选取属性间满足连接条件的元组。
- 分类:
- 等值连接:连接条件为 “=”(如 R. 学号 = S. 学号)。
- 自然连接(⋈):特殊等值连接,自动去掉重复属性列(最常用)。
- 外连接:左外、右外、全外(保留不匹配元组,补 NULL)。
- 示例:学生表 ⋈ 成绩表 → 按学号自然连接,得到学生 + 成绩完整信息。
(3).笛卡尔积运算(R×S)
- 格式:R×S
- 含义:R 的每个元组与 S 的每个元组拼接,结果元组个数 = R 行数 ×S 行数。
- 特点:无实际意义,是连接运算的基础,会产生大量冗余元组。
- 示例:R(2 行)×S(3 行)=6 行元组。
关系代数综合示例(考试常考)
查询 “计算机专业且成绩> 80” 的学生姓名与成绩:
π 姓名,成绩 (σ 专业 =' 计算机 ' AND 成绩 > 80 (学生表 ⋈ 成绩表) )
4.关系数据库规范化理论(综合题必考)
规范化解决数据冗余、插入异常、删除异常、更新异常,核心是函数依赖与范式。
(1).关系模式应满足的基本要求
- 数据冗余度低(同一数据不重复存储)。
- 无插入异常(新数据可正常插入)。
- 无删除异常(删除数据不丢失其他信息)。
- 无更新异常(修改数据只需改一处)。
(2).函数依赖(基础)
1. 定义
设 X、Y 是关系 R 的属性集,若X 的每个值唯一确定 Y 的一个值,则 Y 函数依赖于 X,记 X→Y。
- 示例:学号→姓名、学号→专业;(学号,课程号)→成绩。
2. 分类(必背)
- 完全函数依赖:X→Y,且 X 的任何真子集都不能决定 Y(如(学号,课程号)→成绩)。
- 部分函数依赖:X→Y,且 X 的某个真子集能决定 Y(如(学号,课程号)→姓名,学号→姓名)。
- 传递函数依赖:X→Y,Y→Z,且 Y 不→X,则 X→Z(如学号→系号,系号→系主任,学号→系主任)。
3. 码的定义
- 候选码:能完全函数决定所有属性的属性 / 属性组。
- 主码:候选码中选定的一个。
- 主属性:含有任何候选码中的属性。
- 非主属性:不含有任何候选码中的属性。
(3).规范化(4 大范式,逐级判断)
范式是关系模式满足的规范级别,级别越高,冗余越少,从低到高:1NF→2NF→3NF→BCNF。
1. 第一范式(1NF)
- 规则:关系的所有属性都是原子值(不可再分)。
- 违反示例:属性 “联系方式” 含 “电话 + 邮箱”,需拆分为 “电话”“邮箱”。
- 结论:所有关系表默认满足 1NF,是基础。
2. 第二范式(2NF)
- 规则:满足 1NF,且所有非主属性完全函数依赖于主码(无部分依赖)。
- 违反示例:关系(学号,课程号,姓名,成绩),主码(学号,课程号),姓名部分依赖学号→不满足 2NF。
- 解决:分解为学生表(学号,姓名)、成绩表(学号,课程号,成绩)。
3. 第三范式(3NF)
- 规则:满足 2NF,且所有非主属性不传递依赖于主码(无传递依赖)。
- 违反示例:关系(学号,系号,系主任),主码学号,学号→系号→系主任→传递依赖→不满足 3NF。
- 解决:分解为学生表(学号,系号)、系表(系号,系主任)。
4. BC 范式(BCNF,修正 3NF)
- 规则:满足 3NF,且所有决定因素都是候选码(主属性也无部分 / 传递依赖)。
- 特点:消除所有异常,是关系模式设计的理想标准。
- 示例:关系(课程号,教师号,教室),候选码(课程号,教师号)、(课程号,教室),所有决定因素都是候选码→满足 BCNF。
(4).关系分解原则(必考)
将 “不好” 的关系分解为多个 “好” 的关系,需满足两大原则:
1. 无损连接性
- 含义:分解后通过自然连接,能还原为原关系(不丢失信息)。
- 判定:常用表格法( chase 算法) 或函数依赖法。
2. 保持函数依赖性
- 含义:分解后所有函数依赖都被保留(不丢失语义)。
- 判定:检查原关系的所有函数依赖,是否都在分解后的子关系中。
分解目标
同时满足无损连接 + 保持函数依赖,使分解后的关系达到 3NF 或 BCNF。
(5).海南专升本应试总结
- 关系模型:重点掌握3 类完整性(定义 + SQL 实现)、关系术语。
- 关系模式:牢记三级模式 + 两级映像,理解数据独立性。
- 关系代数:熟练5 种运算(并、差、交、选择、投影、连接),能写综合表达式。
- 规范化:掌握函数依赖分类,能判断 1NF/2NF/3NF/BCNF,会按无损 + 保持依赖分解关系。
第四章关系数据库标准查询语言SQL
本章预览
1.SQL 语言的组成、基本功能
(1). 语言组成(必考分类)
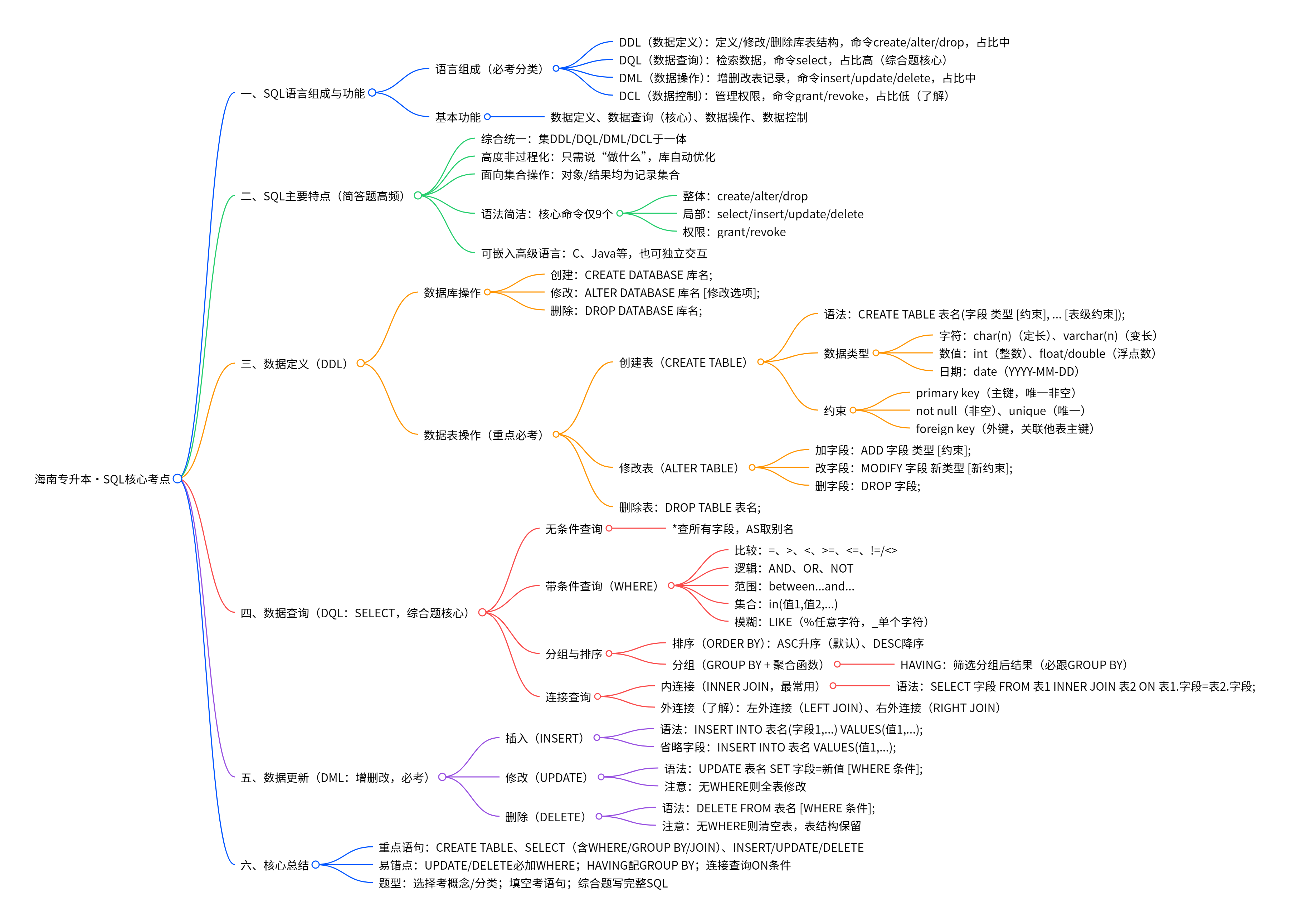
SQL(Structured Query Language,结构化查询语言)按功能分为四大核心部分,专升本重点考查前 3 类:
分类 英文缩写 核心功能 常用命令 考试占比 数据定义语言 DDL 定义 / 修改 / 删除数据库、表、索引等结构 create、alter、drop 中 数据查询语言 DQL 从表中检索数据(最常用) select 高(综合题核心) 数据操作语言 DML 增 / 删 / 改表中数据记录 insert、update、delete 中 数据控制语言 DCL 管理数据库访问权限 grant、revoke 低(了解即可)
(2). 基本功能(简答题 / 选择题考点)
- 数据定义:创建、修改、删除数据库及表结构,定义完整性约束。
- 数据查询:单表 / 多表查询、条件筛选、分组统计、排序,是 SQL 核心功能。
- 数据操作:插入新记录、修改已有记录、删除无用记录。
- 数据控制:分配用户权限、保障数据安全(专升本仅需了解)
2.SQL 语言的主要特点(简答题高频)
- 综合统一:集 DDL、DQL、DML、DCL 于一体,统一语法完成数据库全生命周期操作。
- 高度非过程化:只需说明 “做什么”,无需描述 “怎么做”,数据库自动优化执行。
- 面向集合操作:操作对象与结果均为记录集合,而非单条记录。
- 语法简洁、易学易用:核心命令仅 9 个
create/alter/drop(整体) select/insert/update/delete(局部) grant/revoke(权限)- 可嵌入高级语言:可嵌入 C、Java 等程序,也可独立交互使用。
3.数据定义(DDL):库与表的创建、修改、删除
1. 数据库操作(基础)
(1) 创建数据库
CREATE DATABASE 数据库名; -- 示例:创建学生管理数据库 CREATE DATABASE StudentDB;(2) 修改数据库(专升本极少考,了解)
ALTER DATABASE 数据库名 [修改选项];(3) 删除数据库
DROP DATABASE 数据库名; -- 示例:删除StudentDB数据库 DROP DATABASE StudentDB;
2. 数据表操作(重点,必考)
(1) 创建表(
CREATE TABLE,高频综合题)CREATE TABLE 表名 ( 字段名1 数据类型 [约束], 字段名2 数据类型 [约束], ... [表级约束] );常用数据类型(专升本核心):
- 字符型:char
(n)(定长)、varcher(n)(变长)- 数值型:int(整数)、
float/doublefle(浮点数)- 日期型:date(YYYY-MM-DD)
常用约束(完整性,必考):
- primary key:主键(唯一标识记录,非空)
- not null:字段不能为空
unique:字段值唯一foreign key:外键(关联另一表主键)示例(学生表,考试高频):
CREATE TABLE Student ( Sno CHAR(10) PRIMARY KEY, -- 学号,主键 Sname VARCHAR(20) NOT NULL, -- 姓名,非空 Sage INT, -- 年龄 Ssex CHAR(2) DEFAULT '男', -- 性别,默认男 Sdept VARCHAR(20) -- 所在系 );
(2) 修改表(
ALTER TABLE,选择题 / 填空题)添加字段:
ALTER TABLE 表名 ADD 字段名 数据类型 [约束]; -- 示例:给Student表添加"入学日期"字段 ALTER TABLE Student ADD Sdate DATE;修改字段类型 / 约束:
ALTER TABLE 表名 MODIFY 字段名 新数据类型 [新约束]; -- 示例:将Sage字段改为非空 ALTER TABLE Student MODIFY Sage INT NOT NULL;删除字段:
ALTER TABLE 表名 DROP 字段名; -- 示例:删除Sdate字段 ALTER TABLE Student DROP Sdate;
(3). 删除表(
DROP TABLE)DROP TABLE 表名; -- 示例:删除Student表 DROP TABLE Student;
4.数据查询(DQL:SELECT,综合题核心,占比最高)
1. 无条件查询(基础)
语法:
SELECT 字段列表 FROM 表名;
*表示查询所有字段- 可给字段取别名:
字段名 AS 别名示例:
-- 查询所有学生的学号、姓名 SELECT Sno, Sname FROM Student; -- 查询学生表所有信息 SELECT * FROM Student; -- 查询姓名并取别名"学生姓名" SELECT Sname AS 学生姓名 FROM Student;
2. 带条件查询(
WHERE,高频)语法:
SELECT 字段 FROM 表名 WHERE 条件;常用条件运算符:
- 比较:
=、>、<、>=、<=、!=(或<>)- 逻辑:
AND(且)、OR(或)、NOT(非)- 范围:between
... and ...- 集合: in
(值1,值2,...)- 模糊查询:
LIKE(%匹配任意字符,_匹配单个字符)示例:
-- 查询计算机系(CS)的所有学生 SELECT * FROM Student WHERE Sdept = 'CS'; -- 查询年龄在18-22岁的男生 SELECT * FROM Student WHERE Sage BETWEEN 18 AND 22 AND Ssex = '男'; -- 查询姓"李"的学生 SELECT * FROM Student WHERE Sname LIKE '李%';
3. 分组查询与排序(
GROUP BY/ORDER BY,综合题必考)(1) 排序(
ORDER BY)
ASC:升序(默认),DESC:降序- 可多字段排序
示例:
-- 按年龄升序、学号降序查询学生 SELECT * FROM Student ORDER BY Sage ASC, Sno DESC;(2) 分组查询(
GROUP BY+ 聚合函数)常用聚合函数:count
()(计数)、sum()(求和)、avg()(平均值)、max()(最大值)、min()(最小值)
having:根据条件,筛选分组后的结果(必须跟在GROUP BY后,区别于WHERE)示例:
-- 统计各系学生人数,仅显示人数>30的系 SELECT Sdept, COUNT(*) AS 人数 FROM Student GROUP BY Sdept HAVING COUNT(*) > 30;
4. 连接查询(多表查询,难点 + 高频)
用于从两张及以上表中查询关联数据,核心是外键关联。
(1) 内连接(
INNER JOIN,最常用)语法:
SELECT 字段列表 FROM 表1 INNER JOIN 表2 ON 表1.字段 = 表2.字段;示例(学生表 + 成绩表):
-- 查询学生姓名、课程号、成绩 SELECT Student.Sname, SC.Cno, SC.Grade FROM Student INNER JOIN SC ON Student.Sno = SC.Sno;(2) 外连接(了解,专升本较少考)
- 左外连接(
LEFT JOIN):保留左表所有记录,右表无匹配则显示NULL- 右外连接(
RIGHT JOIN):保留右表所有记录
5.数据更新(DML:增 / 删 / 改,必考)
1. 插入数据(
INSERT)语法 1(指定字段):
INSERT INTO 表名 (字段1,字段2,...) VALUES (值1,值2,...);语法 2(全字段,省略字段名):
INSERT INTO 表名 VALUES (值1,值2,...);示例:
-- 插入一条学生记录 INSERT INTO Student (Sno, Sname, Sage, Ssex, Sdept) VALUES ('2026001', '张三', 20, '男', 'CS');
2. 修改数据(
UPDATE,注意WHERE,否则全表修改)语法:
UPDATE 表名 SET 字段1=新值1, 字段2=新值2 [WHERE 条件];注意
- 执行修改操作时若不指定 WHERE 条件,将更新该表中该字段的所有记录值。
示例:
-- 将学号2026001的学生年龄改为21 UPDATE Student SET Sage = 21 WHERE Sno = '2026001';
3. 删除数据(
DELETE,注意WHERE)语法:
DELETE FROM 表名 [WHERE 条件];注意:
- 如果不指定 WHERE 条件,执行删除操作将清空表中的所有数据,但表结构会保留。
示例:
-- 删除年龄大于30的学生 DELETE FROM Student WHERE Sage > 30;
6.海南专升本 SQL 核心总结
- 重点语句:
CREATE TABLE、SELECT(含WHERE/GROUP BY/JOIN)、INSERT/UPDATE/DELETE。- 易错点:
UPDATE/DELETE必须加WHERE;HAVING与GROUP BY配套;连接查询的ON条件正确。- 题型:选择题考概念 / 分类;填空题考语句填空;综合题要求写完整 SQL 语句(如建表、多表查询)。
第五章数据库中的对象
本章预览
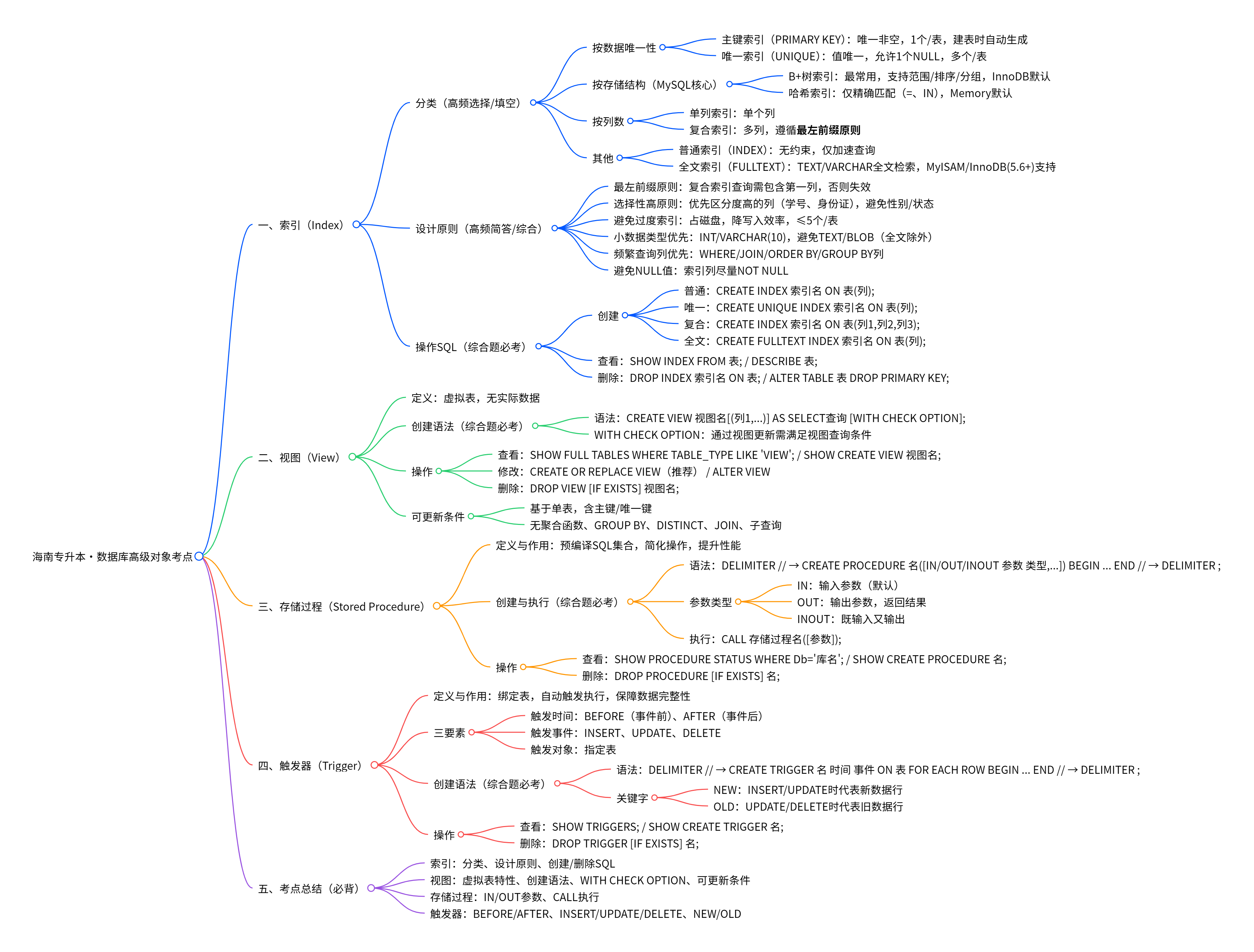
1.索引(Index)
(1).索引的分类(高频考点:选择、填空)
索引是数据库表中一列或多列值的排序结构,核心作用是加速数据查询,按存储结构、数据唯一性、创建方式分为以下几类:
按数据唯一性划分
主键索引(PRIMARY KEY):唯一标识表中记录,不允许 NULL 值,一张表仅能有 1 个;创建表时定义主键自动生成,如
student(sid)设为主键,sid列自动创建主键索引。唯一索引(UNIQUE):列值必须唯一,允许 1 个 NULL 值,一张表可创建多个;语法:
UNIQUE (列名)。按存储结构划分(MySQL 核心)
B + 树索引:最常用,支持范围查询、排序、分组,InnoDB 存储引擎默认索引类型,适合大数据量查询。
哈希索引:基于哈希表实现,仅支持精确匹配查询(=、IN),不支持范围查询,Memory 存储引擎默认索引。
按列数划分
单列索引:基于单个列创建,如
INDEX idx_name (name)。复合索引(多列索引):基于多个列创建,遵循最左前缀原则(查询必须包含索引第一列才生效),如
INDEX idx_stu (sid, name, age)。其他分类
普通索引(INDEX):无唯一性约束,仅加速查询,最基础索引类型。
全文索引(FULLTEXT):针对
TEXT、VARCHAR类型列,用于全文检索(如文章关键词搜索),仅 MyISAM、InnoDB(MySQL 5.6+)支持。
(2).索引的设计原则(高频考点:简答、综合题)
索引并非越多越好,需遵循以下原则,避免索引失效、降低增删改效率:
最左前缀原则:复合索引查询必须包含第一列,否则索引失效;如复合索引
(a,b,c),仅WHERE a=?、WHERE a=? AND b=?生效,WHERE b=?不生效。选择性高原则:优先为区分度高的列创建索引(如学号、身份证号),避免为性别、状态等区分度低的列建索引(索引选择性 = 唯一值数 / 总行数,越接近 1 越好)。
避免过度索引:索引会占用磁盘空间,且增删改数据时需同步更新索引,降低写入效率;一张表索引数建议≤5 个。
小数据类型优先:为
INT、VARCHAR(10)等短字段建索引,避免为TEXT、BLOB大字段建索引(全文索引除外)。频繁查询列优先:为
WHERE、JOIN、ORDER BY、GROUP BY子句中频繁使用的列建索引。避免 NULL 值:索引列尽量设为
NOT NULL,NULL 值会导致索引失效或查询效率降低。
(3).创建索引(核心实操:SQL 语句,综合题必考)
1. 创建普通索引
-- 语法:CREATE INDEX 索引名 ON 表名(列名); CREATE INDEX idx_stu_name ON student(name); -- 为student表name列创建普通索引2. 创建唯一索引
-- 语法:CREATE UNIQUE INDEX 索引名 ON 表名(列名); CREATE UNIQUE INDEX idx_stu_id ON student(sid); -- 为sid列创建唯一索引(值唯一,允许1个NULL)3. 创建主键索引(建表时定义)
CREATE TABLE student( sid INT PRIMARY KEY, -- 主键索引自动创建 name VARCHAR(20), age INT );4. 创建复合索引
-- 语法:CREATE INDEX 索引名 ON 表名(列1,列2,列3); CREATE INDEX idx_stu_info ON student(sid, name, age); -- 复合索引,遵循最左前缀5. 创建全文索引
-- 语法:CREATE FULLTEXT INDEX 索引名 ON 表名(列名); CREATE FULLTEXT INDEX idx_article_content ON article(content);
(4).查看索引(实操考点:查询索引信息)
-- 查看指定表的所有索引 SHOW INDEX FROM student; -- 或 DESCRIBE student; -- 简略查看,主键索引会标注PRI
(5).删除索引(实操考点)
-- 语法:DROP INDEX 索引名 ON 表名; DROP INDEX idx_stu_name ON student; -- 删除普通索引 -- 删除主键索引(需先取消主键约束) ALTER TABLE student DROP PRIMARY KEY;
2.视图(View)
(1).定义视图(核心:虚拟表,无实际数据)
视图是基于一个或多个基本表(或视图)的查询结果构建的虚拟表,本身不存储数据,数据来源于基本表,随基本表数据变化而实时更新。作用:简化复杂查询、保障数据安全(隐藏敏感列)、实现数据逻辑独立。
创建视图语法(综合题必考)
-- 语法: CREATE VIEW 视图名[(列名1,列名2,...)] AS SELECT 查询语句 [WITH CHECK OPTION]; -- 例1:创建单表视图,仅显示学生学号、姓名、年龄 CREATE VIEW v_stu_info AS SELECT sid, name, age FROM student; -- 例2:创建多表视图,关联学生表与成绩表 CREATE VIEW v_stu_score AS SELECT s.sid, s.name, sc.course, sc.score FROM student s JOIN score sc ON s.sid=sc.sid; -- 例3:带CHECK OPTION(通过视图更新数据时,需满足视图查询条件) CREATE VIEW v_stu_adult AS SELECT sid, name, age FROM student WHERE age>=18 WITH CHECK OPTION;WITH CHECK OPTION:通过视图插入 / 修改数据时,必须满足
WHERE age>=18条件,否则报错,保障数据一致性。
(2).查看视图(实操)
-- 查看数据库中所有视图 SHOW FULL TABLES WHERE TABLE_TYPE LIKE 'VIEW'; -- 查看视图定义 SHOW CREATE VIEW v_stu_info; -- 查询视图数据(和查询表语法一致) SELECT * FROM v_stu_info;
(3.)修改视图(两种方式)
CREATE OR REPLACE VIEW(覆盖原有视图,推荐)
-- 修改视图,添加性别列 CREATE OR REPLACE VIEW v_stu_info AS SELECT sid, name, age, gender FROM student;
ALTER VIEW(修改视图列或查询逻辑)
ALTER VIEW v_stu_info AS SELECT sid, name FROM student WHERE age>=16;
(4).删除视图
-- 语法:DROP VIEW [IF EXISTS] 视图名; DROP VIEW IF EXISTS v_stu_info; -- 避免视图不存在时报错
(5).更新视图(考点:视图可更新条件)
视图并非所有情况都可更新(INSERT/UPDATE/DELETE),需满足以下条件:
视图基于单个基本表创建,且包含主键 / 唯一键;
视图未使用聚合函数(SUM/COUNT/AVG)、GROUP BY、DISTINCT、JOIN(多表)、子查询;
未使用
WITH CHECK OPTION时,更新需符合基本表约束;使用时需符合视图查询条件。可更新示例:
-- 更新单表视图数据(同步更新基本表student) UPDATE v_stu_info SET age=20 WHERE sid=1001; -- 插入数据(需满足基本表非空约束) INSERT INTO v_stu_info(sid, name, age) VALUES(1005, '张三', 19);不可更新示例:多表视图、聚合视图无法更新,会报错。
3.存储过程(Stored Procedure)
(1.)定义与作用
存储过程是一组预编译的 SQL 语句集合,存储在数据库中,可通过名称调用执行。优点:模块化设计(一次创建多次调用)、减少网络传输、提高执行效率(预编译)、简化复杂操作。
(2.)创建和执行存储过程(核心实操,综合题必考)
1 创建存储过程(MySQL 语法)
-- 语法: DELIMITER // -- 修改语句结束符为//(避免与存储过程内;冲突) CREATE PROCEDURE 存储过程名([IN/OUT/INOUT 参数名 数据类型,...]) BEGIN -- SQL语句集合 END // DELIMITER ; -- 恢复结束符为; -- 例1:无参存储过程,查询所有学生信息 DELIMITER // CREATE PROCEDURE proc_get_all_stu() BEGIN SELECT * FROM student; END // DELIMITER ; -- 例2:带IN参数(输入参数),根据学号查询学生 DELIMITER // CREATE PROCEDURE proc_get_stu_by_id(IN p_sid INT) BEGIN SELECT * FROM student WHERE sid=p_sid; END // DELIMITER ; -- 例3:带OUT参数(输出参数),查询学生总数 DELIMITER // CREATE PROCEDURE proc_get_stu_count(OUT p_count INT) BEGIN SELECT COUNT(*) INTO p_count FROM student; END // DELIMITER ;参数类型:
IN:输入参数,调用时传入值(默认);
OUT:输出参数,存储过程返回结果;
INOUT:既输入又输出。2 执行存储过程
-- 执行无参存储过程 CALL proc_get_all_stu(); -- 执行带IN参数的存储过程 CALL proc_get_stu_by_id(1001); -- 执行带OUT参数的存储过程(需定义变量接收结果) SET @stu_count=0; -- 定义用户变量 CALL proc_get_stu_count(@stu_count); SELECT @stu_count; -- 查看结果3查看存储过程
-- 查看数据库中所有存储过程 SHOW PROCEDURE STATUS WHERE Db='数据库名'; -- 查看存储过程定义 SHOW CREATE PROCEDURE proc_get_all_stu;4删除存储过程
-- 语法:DROP PROCEDURE [IF EXISTS] 存储过程名; DROP PROCEDURE IF EXISTS proc_get_all_stu;
4.触发器(Trigger)
(1).定义与作用
触发器是特殊的存储过程,由数据库事件(INSERT/UPDATE/DELETE)自动触发执行,无需手动调用。核心作用:维护数据完整性、实现级联操作、记录数据变更日志、强化业务约束。
(2).创建触发器(核心实操,综合题必考)
1. 触发器三要素
触发时间:
BEFORE(事件执行前)、AFTER(事件执行后);触发事件:
INSERT、UPDATE、DELETE;触发对象:指定表(触发器绑定在表上)。
2. 创建语法(MySQL)
-- 语法: DELIMITER // CREATE TRIGGER 触发器名 触发时间 触发事件 ON 表名 FOR EACH ROW -- 行级触发器(每操作一行触发一次,MySQL仅支持行级) BEGIN -- 触发时执行的SQL语句 END // DELIMITER ; -- 例1:AFTER INSERT触发器,学生表插入数据时,记录日志 DELIMITER // CREATE TRIGGER trig_stu_insert AFTER INSERT ON student FOR EACH ROW BEGIN INSERT INTO stu_log(operation, opt_time, stu_id) VALUES('INSERT', NOW(), NEW.sid); -- NEW代表插入的新记录 END // DELIMITER ; -- 例2:BEFORE UPDATE触发器,修改学生年龄时,限制年龄≥16 DELIMITER // CREATE TRIGGER trig_stu_update BEFORE UPDATE ON student FOR EACH ROW BEGIN IF NEW.age<16 THEN SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT='年龄不能小于16岁'; END IF; END // DELIMITER ; -- 例3:AFTER DELETE触发器,删除学生时,同步删除成绩表数据(级联操作) DELIMITER // CREATE TRIGGER trig_stu_delete AFTER DELETE ON student FOR EACH ROW BEGIN DELETE FROM score WHERE sid=OLD.sid; -- OLD代表删除的旧记录 END // DELIMITER ;关键字:
NEW:触发INSERT/UPDATE时,代表新数据行;
OLD:触发UPDATE/DELETE时,代表旧数据行。
(3).查看触发器
-- 查看数据库中所有触发器 SHOW TRIGGERS; -- 查看指定触发器定义 SHOW CREATE TRIGGER trig_stu_insert;
(4).删除触发器
-- 语法:DROP TRIGGER [IF EXISTS] 触发器名; DROP TRIGGER IF EXISTS trig_stu_insert;
5.海南专升本考点总结(必背)
索引:分类(主键 / 唯一 / 普通 / 复合 / B + 树)、设计原则(最左前缀、选择性高)、创建 / 删除 SQL;
视图:虚拟表特性、创建语法(
CREATE VIEW...AS)、WITH CHECK OPTION作用、可更新条件;存储过程:
IN/OUT参数、CALL执行、预编译优势;触发器:
BEFORE/AFTER、INSERT/UPDATE/DELETE、NEW/OLD关键字、数据完整性应用。
第六章数据库设计
本章预览
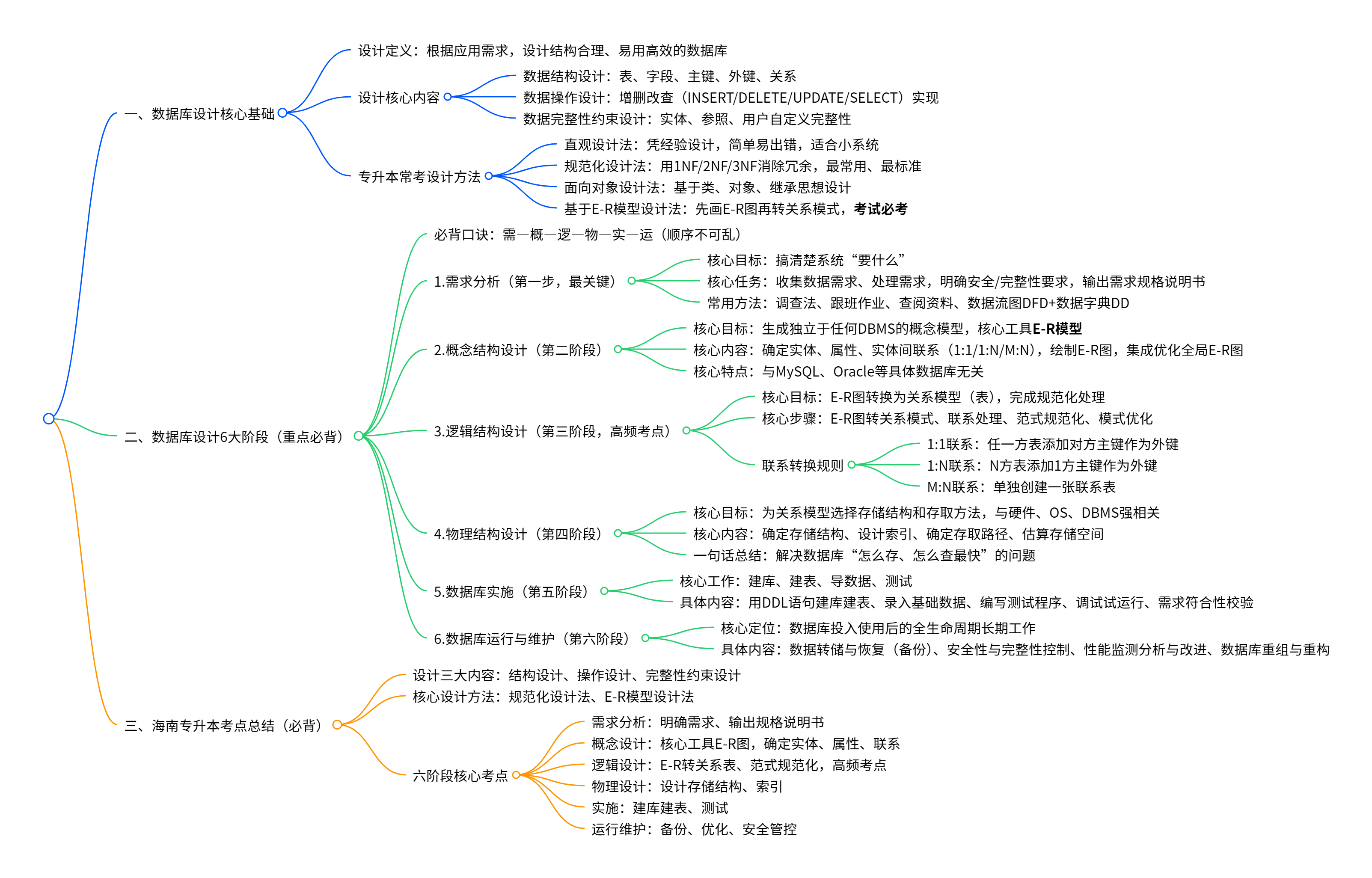
1. 数据库设计的内容
数据库设计就是根据应用需求,设计出结构合理、使用方便、效率高的数据库。主要包括三方面内容:
- 数据结构设计设计表、字段、主键、外键、关系等。
- 数据操作设计增删改查(INSERT、DELETE、UPDATE、SELECT)如何实现。
- 数据完整性约束设计保证数据正确、不重复、不矛盾(实体完整性、参照完整性、用户自定义完整性)。
2. 数据库设计的方法
常见设计方法(专升本常考):
- 直观设计法凭经验直接设计,简单但容易出错,适合小系统。
- 规范化设计法用 范式(1NF、2NF、3NF)消除冗余,最常用、最标准。
- 面向对象设计法用类、对象、继承思想设计数据库。
- 基于 E-R 模型的设计法先画 E-R 图,再转关系模式,考试必考。
3. 数据库设计的阶段(重点!必背顺序)
数据库设计一共 6 个阶段,顺序不能乱:
- 需求分析
- 概念结构设计
- 逻辑结构设计
- 物理结构设计
- 数据库实施
- 数据库运行与维护
口诀:需 — 概 — 逻 — 物 — 实 — 运
4. 需求分析
(1).需求分析的任务
需求分析是数据库设计的第一步,也是最关键一步。任务:
- 收集用户数据需求:要存什么数据
- 收集用户处理需求:要做什么操作
- 明确安全性、完整性要求
- 写出需求规格说明书(文档)
一句话:搞清楚 “要什么”
(2).需求分析的方法
常用方法:
- 调查法:访谈、问卷、开会
- 跟班作业:亲自看业务流程
- 查阅资料:看报表、单据、制度
- 数据流图 DFD + 数据字典 DD
- 数据流图:表示数据流动、处理、存储
- 数据字典:详细定义每个数据项含义
5. 概念结构设计(第二阶段)
目标:把需求变成独立于任何 DBMS 的概念模型。核心工具:E-R 模型(实体 - 联系模型)
主要内容:
- 确定实体(如学生、课程、教师)
- 确定属性(如学号、姓名、成绩)
- 确定实体间联系
- 一对一 1:1
- 一对多 1:N
- 多对多 M:N
- 画出E-R 图
- 集成、优化全局 E-R 图
特点:与具体数据库(MySQL、Oracle)无关。
6. 逻辑结构设计(第三阶段・高频考点)
目标:把 E-R 图转换成关系模型(表),并规范化。
步骤:
- E-R 图 → 关系模式
- 实体 → 表
- 属性 → 字段
- 主键 → 唯一标识
- 处理联系
- 1:1:任一方加外键
- 1:N:N 方加 1 方主键作为外键
- M:N:单独建一张联系表
- 规范化(范式)用 1NF、2NF、3NF 消除冗余、异常。
- 优化:合并、分解表,提高效率。
7. 物理结构设计(第四阶段)
目标:为关系模型选择具体存储结构和存取方法,与硬件、OS、DBMS 相关。
内容:
- 确定存储结构表如何存储、记录顺序。
- 设计索引加快查询。
- 确定存取路径怎么查最快。
- 估算存储空间。
一句话:数据库 “怎么存、怎么查最快”。
8. 数据库的实施(第五阶段)
就是真正建库、建表、导数据、测试。
主要工作:
- 用 DDL 语句建库、建表
- 录入数据
- 编写测试程序,调试、试运行
- 检查是否满足需求
9. 数据库的运行和维护(第六阶段)
数据库投入使用后的长期工作:
- 数据库转储与恢复(备份)
- 安全性、完整性控制
- 性能监测、分析、改进
- 数据库重组与重构优化表结构、索引,不改变逻辑结构。
10.海南专升本考点总结
- 设计内容:结构、操作、完整性
- 设计方法:直观、规范化、E-R、面向对象
- 六阶段:需 — 概 — 逻 — 物 — 实 — 运
- 需求分析:做什么、存什么、写文档
- 概念设计:画 E-R 图
- 逻辑设计:E-R 转表 + 范式
- 物理设计:怎么存、建索引
- 实施:建库、建表、测试
- 运行维护:备份、优化、安全
第七章数据库技术的发展
本章预览
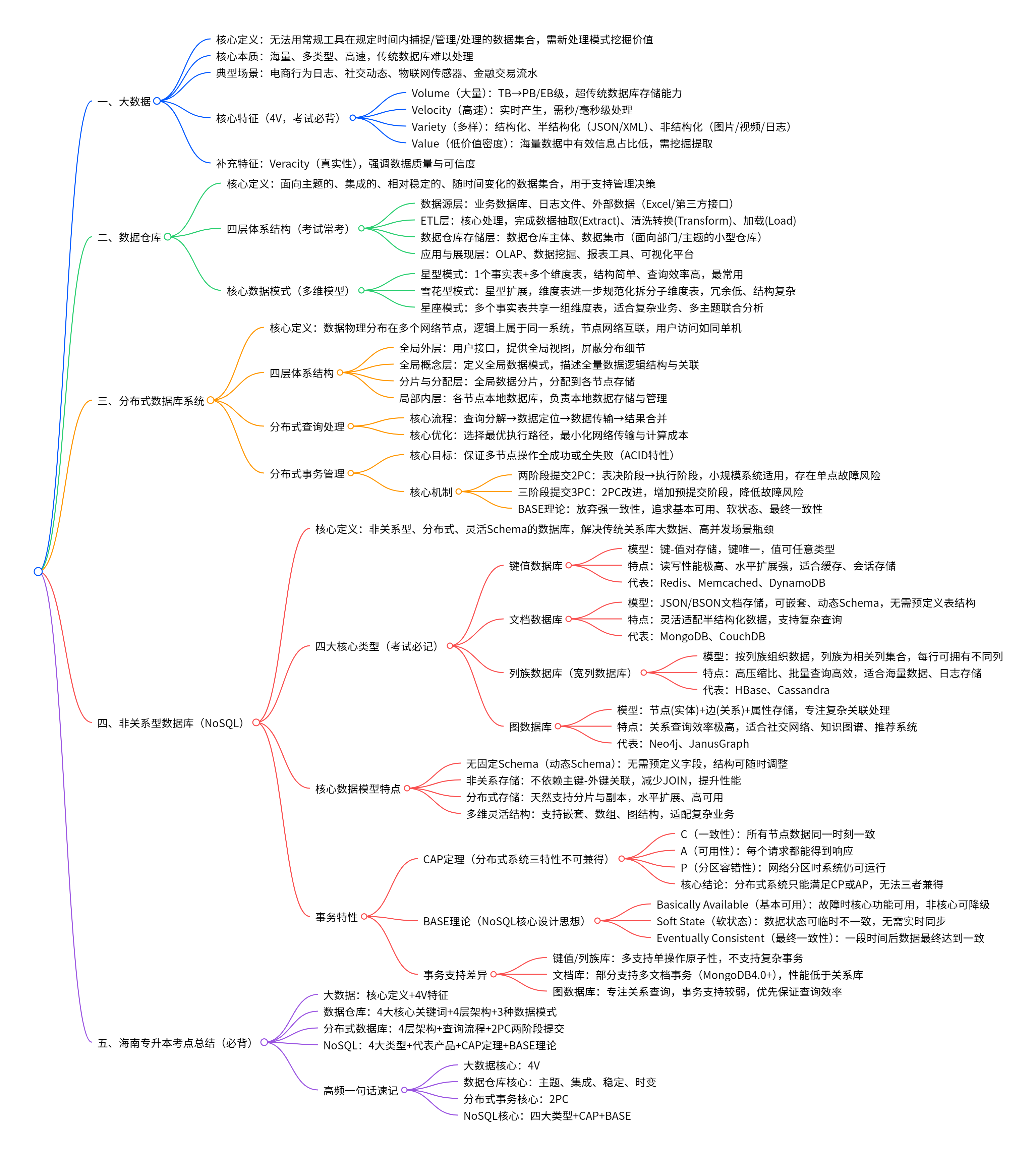
1. 大数据
(1) 什么是大数据
定义:大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
- 核心本质:数据量极大、类型极多、产生速度极快,传统数据库难以处理。
- 典型场景:电商用户行为日志、社交平台动态、物联网传感器数据、金融交易流水。
(2) 大数据的特征(4V 核心,考试必背)
- Volume(大量):数据规模从 TB 级跃升至 PB、EB 级,远超传统数据库存储能力。
- Velocity(高速):数据实时产生、实时流入,需秒级 / 毫秒级处理(如直播弹幕、实时订单)。
- Variety(多样):数据类型复杂,含结构化(数据库表)、半结构化(JSON/XML)、非结构化(图片、视频、日志)。
- Value(低价值密度):海量数据中有效信息占比低,需通过挖掘提取高价值内容(如从用户日志中分析消费偏好)。
- 补充:部分教材增加Veracity(真实性),强调数据质量与可信度。
2. 数据仓库
(1) 数据仓库系统的体系结构(四层架构,考试常考)
数据仓库(Data Warehouse,DW)是面向主题的、集成的、相对稳定的、随时间变化的数据集合,用于支持管理决策。其标准四层体系结构:
- 数据源层:数据来源,含业务数据库、日志文件、外部数据(如 Excel、第三方接口)。
- 数据抽取、转换与加载层(ETL):核心处理层,完成数据抽取(Extract)、清洗转换(Transform)、加载(Load)到数据仓库。
- 数据仓库存储层:核心存储,含数据仓库主体(存储整合后数据)、数据集市(Data Mart)(面向部门 / 主题的小型数据仓库)。
- 应用与展现层:提供数据访问与分析,含 OLAP(联机分析处理)、数据挖掘、报表工具、可视化平台。
(2) 数据仓库的数据库模式
数据仓库采用多维数据模型,区别于关系数据库的二维表模型,核心模式:
- 星型模式(Star Schema)
- 结构:1 个事实表(核心,存储业务度量数据,如销售额、订单量)+ 多个维度表(描述事实的属性,如时间、商品、地区、用户)。
- 特点:结构简单、查询效率高,是最常用模式。
- 示例:销售事实表关联时间维度表、商品维度表、地区维度表。
- 雪花型模式(Snowflake Schema)
- 结构:星型模式的扩展,维度表可进一步规范化,拆分为多个子维度表(如商品维度表拆分为商品分类、品牌子表)。
- 特点:减少数据冗余,但结构复杂、查询效率略低。
- 星座模式(Galaxy Schema)
- 结构:多个事实表共享一组维度表(如销售事实表、库存事实表共享时间、商品维度表)。
- 特点:适合复杂业务场景,支持多主题联合分析。
3. 分布式数据库系统
(1) 分布式数据库系统的体系结构
分布式数据库(DDB)是数据物理分布在多个网络节点(计算机)上,但逻辑上属于同一系统的数据库,节点通过网络互联,用户访问如同单机数据库。核心四层结构:
- 全局外层:用户接口,提供全局视图,屏蔽数据分布细节。
- 全局概念层:定义全局数据模式,描述所有数据的逻辑结构与关联。
- 分片与分配层:将全局数据分片(Sharding)(按规则拆分),并分配到各节点存储。
- 局部内层:各节点的本地数据库,负责本地数据的存储、管理与操作。
(2) 分布式查询处理
分布式查询需解决数据分布带来的查询效率与一致性问题,核心流程:
- 查询分解:将全局 SQL 查询拆分为多个可在本地节点执行的子查询。
- 数据定位:根据数据分片规则,确定子查询需访问的节点。
- 数据传输:节点间传输中间结果,减少网络开销(优先本地计算)。
- 结果合并:汇总各节点子查询结果,返回最终全局结果。
- 核心优化:查询优化器选择最优执行路径,最小化网络传输与计算成本。
(3) 分布式事务管理
分布式事务需保证多个节点上的操作要么全部成功,要么全部失败(ACID 特性)
核心机制:
- 两阶段提交协议(2PC,Two-Phase Commit)
- 阶段 1(表决阶段):协调者向所有参与者发送事务请求,参与者执行操作并返回 “同意 / 终止”。
- 阶段 2(执行阶段):协调者根据反馈,若全同意则发送 “提交”,否则发送 “回滚”,参与者执行对应操作。
- 缺点:协调者单点故障、性能低,适合小规模分布式系统。
- 三阶段提交协议(3PC):2PC 的改进,增加 “预提交” 阶段,降低协调者故障风险。
- BASE 理论:分布式事务常用替代方案,放弃强一致性,追求基本可用、软状态、最终一致性(后续 NoSQL 章节详解)。
4. 非关系数据库(NoSQL)
(1) NoSQL 的类型(四大类,考试必记)
NoSQL(Not Only SQL)是非关系型、分布式、灵活 Schema 的数据库,解决传统关系数据库在大数据、高并发场景的瓶颈。四大核心类型:
- 键值数据库(Key-Value Store)
- 模型:以 “键 - 值” 对存储数据,键唯一,值可为任意类型(字符串、JSON、二进制)。
- 特点:读写性能极高、水平扩展强,适合缓存、会话存储。
- 代表:Redis、Memcached、DynamoDB。
- 文档数据库(Document Store)
- 模型:以 JSON/BSON 文档存储数据,文档可嵌套、动态 Schema,无需预定义表结构。
- 特点:灵活、适合半结构化数据,支持复杂查询。
- 代表:MongoDB、CouchDB。
- 列族数据库(Column-Family Store,宽列数据库)
- 模型:按列族组织数据,列族是相关列的集合,每行可拥有不同列。
- 特点:高压缩比、批量查询高效,适合海量数据与日志存储。
- 代表:HBase、Cassandra。
- 图数据库(Graph Database)
- 模型:以 “节点(实体)+ 边(关系)+ 属性” 存储数据,专注处理复杂关联。
- 特点:关系查询效率极高,适合社交网络、知识图谱、推荐系统。
- 代表:Neo4j、JanusGraph。
(2) NoSQL 数据模型
NoSQL 突破关系数据库的二维表限制,核心模型特点:
- 无固定 Schema(动态 Schema):无需预先定义字段、数据类型,数据结构可随时调整,适配快速迭代与非结构化数据。
- 非关系存储:不依赖主键 - 外键关联,数据可独立存储,减少 JOIN 操作,提升性能。
- 分布式存储:天然支持分片(Sharding)与副本(Replica),数据分散在多节点,实现水平扩展与高可用。
- 多维 / 灵活结构:支持嵌套、数组、图结构等,适配复杂业务数据(如商品详情、社交关系)。
(3) NoSQL 事务特性
NoSQL不严格遵循 ACID,基于CAP 定理与BASE 理论设计,核心特性:
- CAP 定理(分布式系统三特性不可兼得)
- C(一致性):所有节点数据同一时间一致。
- A(可用性):每个请求都能得到响应(成功 / 失败)。
- P(分区容错性):网络分区时系统仍可运行。
- 结论:分布式系统中,只能同时满足 CP 或 AP,无法三者兼得。
- BASE 理论(NoSQL 核心设计思想)
- Basically Available(基本可用):系统出现故障时,保证核心功能可用,非核心功能可降级。
- Soft State(软状态):数据状态可临时不一致,无需实时同步。
- Eventually Consistent(最终一致性):经过一段时间后,所有节点数据最终达到一致(放弃强一致,换高可用与高性能)。
- 事务支持差异
- 键值 / 列族数据库:多支持单操作原子性,不支持复杂事务。
- 文档数据库:部分支持多文档事务(如 MongoDB 4.0+),但性能低于关系数据库。
- 图数据库:专注关系查询,事务支持较弱,优先保证查询效率。
5.海南专升本考点总结
1.大数据
- 定义:无法用常规工具在一定时间内捕捉、管理、处理的数据集合,需新模式处理。
- 4V 特征(必背)
- Volume 大量:数据规模巨大
- Velocity 高速:产生、处理速度快
- Variety 多样:结构化、半结构化、非结构化
- Value 低价值密度:有效信息少,需挖掘
2.数据仓库
- 数据仓库定义(关键词):面向主题、集成、稳定、随时间变化、支持决策。
- 体系结构(四层)
- 数据源层
- ETL 层(抽取、转换、加载)
- 数据仓库存储层
- 应用与展现层
- 数据仓库模式(3 种)
- 星型模式:1 事实表 + 多个维度表
- 雪花型模式:星型扩展,维度表再拆分
- 星座模式:多个事实表共享维度表
3.分布式数据库系统
- 定义:物理分布、逻辑统一,通过网络互联。
- 体系结构(四层)
- 全局外层
- 全局概念层
- 分片与分配层
- 局部内层
- 分布式查询处理
- 查询分解 → 数据定位 → 数据传输 → 结果合并
- 分布式事务管理
- 2PC 两阶段提交:表决阶段、执行阶段
- 目标:要么全成功,要么全失败
4.非关系数据库 NoSQL
- NoSQL 四大类型(必背)
- 键值数据库:Redis、Memcached
- 文档数据库:MongoDB
- 列族数据库:HBase、Cassandra
- 图数据库:Neo4j
- NoSQL 数据模型特点
- 无固定 Schema、非关系、分布式、灵活结构
- 事务理论(重点)
- CAP 定理:一致性 C、可用性 A、分区容错性 P,三者只能选其二
- BASE 理论:基本可用、软状态、最终一致性
5.考试高频一句话速记
- 大数据:4V
- 数据仓库:主题、集成、稳定、时变
- 分布式事务:2PC
- NoSQL:四大类型 + CAP + BASE
第八章选择题考点
模块一 数据库基本概念
1.核心概念辨析(必考)
- 数据:不仅是数字,还包括文字、图形、图像、音频等所有能被计算机存储和处理的符号集合。
- 数据库(DB):长期存储在计算机内、有组织、可共享的大量数据的集合,核心是结构化、可共享。
- 数据库管理系统(DBMS):数据库系统的核心软件,位于用户和操作系统之间,用于数据的定义、操纵、管理和维护。
- 数据库系统(DBS):由DB、DBMS、应用程序、数据库管理员(DBA)、用户五部分组成,DBS 包含 DBMS 和 DB(选择题必考包含关系)。
2.三级模式结构(超高频必考)
模式类型 别名 数量 核心定义 概念模式 模式、逻辑模式 全局唯一 1 个 数据库全体数据的逻辑结构和特征的描述,所有用户的公共数据视图,对应基本表 外模式 用户模式、子模式 可以有多个 单个用户能看到的局部数据的逻辑结构,和应用程序一一对应,对应视图 内模式 存储模式 全局唯一 1 个 数据物理结构和存储方式的描述,对应存储文件、索引、存储路径
3.两级映像与两级数据独立性(超高频必考,每套卷必出)
- 两级映像正确对应关系:
- 外模式 / 概念模式映像:保证逻辑数据独立性—— 概念模式(表结构)修改时,只需修改映像,外模式和应用程序无需改动。
- 概念模式 / 内模式映像:保证物理数据独立性—— 内模式(存储结构、物理位置)修改时,只需修改映像,概念模式和应用程序无需改动。
- 易错点:物理独立性对应存储结构变化,逻辑独立性对应表逻辑结构变化,不可混淆。
模块二 数据模型
1.数据模型核心基础(必考)
- 数据模型三要素:数据结构、数据操作、完整性约束(选择题必考三要素,常考 “哪个不属于三要素”)。
- 数据模型分类:
- 概念数据模型:独立于 DBMS,用于需求分析到设计的过渡,代表是E-R 模型。
- 逻辑数据模型:面向 DBMS,包括层次模型、网状模型、关系模型、面向对象模型。
- 物理数据模型:面向底层存储,和硬件、DBMS 强相关。
2.E-R 图(实体 - 联系模型,必考)
- 三要素及图形表示:实体(矩形)、属性(椭圆)、联系(菱形)。
- 联系的类型:一对一(1:1)、一对多(1:n)、多对多(m:n)(选择题必考场景判断,如学生 - 课程是 m:n,部门 - 员工是 1:n)。
3.四大逻辑模型核心特点(必考)
- 层次模型:树形结构,有且只有一个根节点,除根节点外其他节点只有一个双亲节点。
- 网状模型:网状结构,允许一个节点有多个双亲,允许多个节点无双亲,解决了层次模型不能表示多对多的问题。
- 关系模型:二维表结构,核心术语:行 = 元组、列 = 属性、主键 = 主码、外键 = 外码,是当前主流数据库的核心模型。
- 面向对象模型:核心是对象和类,支持封装、继承、多态。
4.高频易错点
- E-R 图的图形符号混淆,联系的类型判断错误。
- 层次模型和网状模型的核心区别:是否允许一个节点有多个双亲。
模块三 关系数据库理论
1.关系模型三大完整性约束(超高频必考)
- 实体完整性:主键(主码)的值不能为空、不能重复,一个表只能有一个主键。
- 参照完整性:外键的值要么为空,要么等于被参照表中对应主键的值,用于维护两张表的关联关系。
- 用户定义完整性:用户自定义的约束,如性别只能是男 / 女、年龄大于 0,是针对具体业务的规则。
- 选择题常考:判断某条数据违反了哪类完整性约束。
2.关系代数运算(必考)
- 笛卡尔积:R 有 m 个元组,S 有 n 个元组,笛卡尔积结果为m×n 个元组,是所有关系运算的基础。
- 传统集合运算:并、差、交,要求两个关系属性个数、属性类型完全一致(相容)。
- 专门的关系运算(必考辨析):
- 选择(σ):水平分割,筛选行,根据条件保留符合要求的元组,不改变表的列结构。
- 投影(π):垂直分割,筛选列,保留指定的属性列,自动去除重复元组,会改变表的列结构。
- 连接:自然连接是最常用的连接,基于两个表的同名属性做等值连接,自动去除重复列。
3.规范化理论(超高频必考,选择题难点核心)
- 函数依赖核心:完全函数依赖、部分函数依赖、传递函数依赖(单属性主键的表,一定不存在部分函数依赖)。
- 范式判断(必考,按优先级排序):
- 第一范式(1NF):属性不可再分,原子性,是关系表的最低要求,不满足 1NF 就不是合法的关系表。
- 第二范式(2NF):在 1NF 基础上,消除了非主属性对主键的部分函数依赖(复合主键时,非主属性必须依赖整个主键,不能只依赖主键的一部分)。
- 第三范式(3NF):在 2NF 基础上,消除了非主属性对主键的传递函数依赖(非主属性不能依赖其他非主属性)。
- BC 范式(BCNF):在 3NF 基础上,消除了主属性对主键的部分和传递函数依赖,要求每一个决定因素都必须包含主键。
- 关系分解的两个核心原则:无损连接性、保持函数依赖。
高频易错点
- 选择和投影的区别:选行是选择,选列是投影,极易混淆。
- 范式判断:复合主键的部分函数依赖、传递函数依赖的识别错误。
- 完整性约束的适用场景:空值判断、主键重复对应的约束类型。
模块四 关系数据库标准语言 SQL
1.SQL 基础(必考)
- SQL 核心特点:综合统一、高度非过程化、面向集合的操作方式、同一种语法支持多种使用方式、语言简洁易学。
- SQL 语句分类(必考匹配)
分类 核心功能 关键字 数据定义语言(DDL) 定义库、表结构 CREATE、ALTER、DROP 数据查询语言(DQL) 数据查询 SELECT 数据操纵语言(DML) 数据增删改 INSERT、UPDATE、DELETE 数据控制语言(DCL) 权限管理 GRANT、REVOKE 2.数据定义(必考)
- 表修改语法:
ALTER TABLE中,ADD 用于新增列,MODIFY 用于修改列的类型 / 约束,DROP 用于删除列(选择题必考关键字匹配)。- 删除辨析:
DROP TABLE是删除表结构 + 所有数据;DELETE仅删除数据,表结构保留。
3.数据查询 SELECT(超高频必考,每套卷必有 3-5 道题)
- 语句执行顺序(必考):
FROM→WHERE→GROUP BY→HAVING→SELECT→ORDER BY。- 核心子句辨析:
WHERE:筛选行,在分组前执行,不能使用聚合函数。HAVING:筛选分组,必须和GROUP BY一起使用,可以使用聚合函数。ORDER BY:排序,ASC升序(默认值),DESC降序。- 条件查询必考细节:
- 模糊查询
LIKE:%匹配任意多个字符,_匹配单个字符。- 空值判断:必须用
IS NULL/IS NOT NULL,不能用=NULL。- 范围查询
BETWEEN...AND...:是闭区间,包含左右两个边界值。- 聚合函数(必考):
COUNT()、SUM()、AVG()、MAX()、MIN(),所有聚合函数都会忽略 NULL 值;COUNT(*)统计所有行,COUNT(列名)仅统计该列非空的行。- 连接查询:左外连接
LEFT JOIN保留左表所有行,右表匹配不到的行填充 NULL;内连接INNER JOIN只保留两张表匹配成功的行。
4.数据更新(必考易错)
UPDATE 表 SET 列=值 WHERE 条件:不写WHERE子句,会更新表中所有行。DELETE FROM 表 WHERE 条件:不写WHERE子句,会删除表中所有行。
5.高频易错点
WHERE和HAVING的使用场景混淆,聚合函数的使用位置错误。- 空值判断用
=NULL,忽略IS NULL的正确用法。- 不写
WHERE子句的 UPDATE/DELETE 的后果,是选择题高频陷阱。COUNT(*)和COUNT(列名)的区别。
模块五 数据库中的对象
1.索引(必考)
- 核心作用:加快查询速度,会降低 INSERT/UPDATE/DELETE 的执行效率。
- 分类核心规则:一个表只能有 1 个聚簇索引(物理存储顺序和索引顺序一致),可以有多个非聚簇索引;主键会自动创建唯一聚簇索引。
- 设计原则(必考):适合建索引的字段 ——WHERE 条件、排序、分组、主键、外键字段;不适合建索引的字段 —— 重复值多、很少查询、更新频繁的字段。
- 操作语法:创建
CREATE INDEX、删除DROP INDEX。
2.视图(必考)
- 本质:虚表,只存储查询定义,不存储实际数据,数据来自底层基表。
- 核心作用:简化复杂查询、提升数据安全性、提供逻辑数据独立性。
- 更新限制:包含聚合函数、GROUP BY、DISTINCT、多表连接的视图,无法执行更新操作。
- 操作语法:创建
CREATE VIEW、修改ALTER VIEW、删除DROP VIEW。
3.存储过程(必考)
- 定义:预编译的 SQL 语句集合,一次编译,多次执行。
- 核心优点:提升执行效率、减少网络传输、提升数据安全性。
- 执行语法:用
CALL关键字调用。
4.触发器(必考)
- 定义:特殊的存储过程,由 INSERT/UPDATE/DELETE 事件自动触发执行,无法手动调用。
- 触发时机:BEFORE(事件前)、AFTER(事件后)。
5.高频易错点
- 聚簇索引的数量限制,一个表只能有 1 个。
- 视图的本质是虚表,不存储实际数据。
- 触发器无法手动调用,只能由事件触发。
模块六 数据库设计
数据库设计六大阶段(必考顺序):
- 需求分析 → 概念结构设计 → 逻辑结构设计 → 物理结构设计 → 数据库实施 → 数据库运行和维护
2.各阶段核心产出(超高频必考)
- 需求分析:核心产出数据流图(DFD)、数据字典(DD),是整个设计的基础。
- 概念结构设计:核心产出E-R 图,独立于具体的 DBMS。
- 逻辑结构设计:核心工作是将 E-R 图转换为关系模式,进行范式优化;m:n 的联系必须单独转换为一个关系模式,1:1 联系可合并到任意一方,1:n 联系合并到 n 方。
- 物理结构设计:设计数据的存储结构、存取路径(索引),依赖于具体的 DBMS 和硬件环境。
3.数据库运行和维护:
- 核心工作由 DBA 完成,包括数据库的备份与恢复、性能监控与优化、安全维护、结构重构。
4.高频易错点
- 设计阶段的顺序混淆,各阶段的核心产出匹配错误。
- E-R 图转关系模式的规则,m:n 联系必须单独建表,是高频考点。
模块七 数据库技术的发展
1.大数据(必考)
- 四大核心特征(4V):Volume(海量数据规模)、Velocity(高速处理)、Variety(数据类型多样)、Value(低价值密度)。
2.数据仓库(必考)
- 核心特点:面向主题、集成的、相对稳定的、反映历史变化的,用于联机分析处理(OLAP);和面向日常业务的操作型数据库(OLTP)形成区分。
3.分布式数据库系统
- 核心特点:数据物理分布、逻辑整体,核心特性是透明性(分片透明、位置透明等)。
4.NoSQL 非关系型数据库(必考)
- 四大类型及代表产品:键值数据库(Redis)、文档数据库(MongoDB)、列存储数据库(HBase)、图数据库(Neo4j)。
- 核心特性:支持 BASE 特性(基本可用、软状态、最终一致性),区别于关系型数据库的 ACID 事务特性。
5.高频易错点
- 大数据 4V 特征的记忆,常考 “哪个不属于 4V”。
- NoSQL 的四大类型及代表产品的匹配。
第九章填空题考点
1.数据库基本概念
考频星级 必考挖空考点 标准答案 ★★★ 数据是描述事物的______ 符号记录 ★★★ 数据库是长期存储在计算机内、有组织的、可共享的______ 大量数据的集合 ★★★ 数据库管理系统的英文缩写是______ DBMS ★★★ 数据库系统的英文缩写是______ DBS ★★★ 数据库系统的核心组成部分是______ 数据库管理系统(DBMS) ★★★ 数据库系统的核心人员是______ 数据库管理员(DBA) ★★★ 数据库三级模式结构分别是:概念模式、______、内模式 外模式 ★★★ 三级模式中,唯一描述数据库全局逻辑结构的是______ 概念模式(模式) ★★★ 三级模式中,描述数据库物理存储结构与存取方式的是______ 内模式 ★★★ 三级模式中,用户可见的局部数据逻辑视图、可设置多个的是______ 外模式 ★★★ 数据库两级映像分别是: 外模式/概念模式映像 、______ 概念模式 / 内模式映像 ★★★ 逻辑数据独立性由______映像保证 外模式 / 概念模式 ★★★ 物理数据独立性由______映像保证 概念模式 / 内模式 ★★ 三级模式中,全局唯一的两个模式是概念模式和______ 内模式
2.数据模型
考频星级 必考挖空考点 标准答案 ★★★ 数据模型的三大组成要素:______、数据操作、数据的完整性约束 数据结构 ★★★ E-R 图(实体 - 联系图)的三大核心要素:实体、______、联系 属性 ★★★ E-R 图属于______数据模型(概念 / 逻辑 / 物理) 概念 ★★★ 两个实体集之间的联系分为三类:一对一 (1:1)、一对多 (1:n)、______ 多对多 (m:n) ★★★ 层次模型的基本数据结构是______ 树形结构 ★★★ 网状模型的基本数据结构是______ 有向图结构 ★★★ 关系模型的基本数据结构是______ 二维表结构 ★★ 数据模型按层级分为:概念数据模型、______数据模型、物理数据模型 逻辑
3.关系数据库理论
考频星级 必考挖空考点 标准答案 ★★★ 关系模型的三大完整性约束:实体完整性、______、用户定义完整性 参照完整性 ★★★ 实体完整性规则:关系的主码(主键)取值必须______且非空 唯一 ★★★ 参照完整性中,外码的取值要么为空,要么等于被参照关系中主码的______ 某个有效值 ★★★ 传统的集合运算包括:并、差、______、笛卡尔积 交 ★★★ 专门的关系运算中,从关系中选取满足条件的元组的操作是______ 选择 ★★★ 专门的关系运算中,从关系中选取指定属性列的操作是______ 投影 ★★★ 专门的关系运算中,按指定条件将两个关系的元组拼接的操作是______ 连接 ★★★ 第一范式(1NF)的核心要求:关系中每个属性都是______的原子值 不可再分 ★★★ 第二范式(2NF):在 1NF 基础上,消除了非主属性对主码的______函数依赖 部分 ★★★ 第三范式(3NF):在 2NF 基础上,消除了非主属性对主码的______函数依赖 传递 ★★★ BC 范式(BCNF):在 3NF 基础上,消除了主属性对主码的______函数依赖 部分和传递 ★★★ 关系模式分解的两大核心原则:无损连接性、______ 保持函数依赖 ★★ 函数依赖 X→Y 中,X 被称为______ 决定因素
4.关系数据库标准查询语言 SQL
考频星级 必考挖空考点 标准答案 ★★★ SQL 的中文全称是______ 结构化查询语言 ★★★ SQL 中,数据定义语言的英文缩写是______,核心语句为 CREATE/ALTER/DROP DDL ★★★ SQL 中,数据操纵语言的英文缩写是______,核心语句为 INSERT/UPDATE/DELETE DML ★★★ SQL 中,数据查询的核心语句是______ SELECT ★★★ 创建数据库的 SQL 关键字是______ DATABASE CREATE ★★★ 修改数据库的 SQL 关键字是______ DATABASE ALTER ★★★ 删除数据库的 SQL 关键字是______ DATABASE DROP ★★★ 创建数据表的 SQL 关键字是______ TABLE CREATE ★★★ 修改数据表的 SQL 关键字是______ TABLE ALTER ★★★ 删除数据表的 SQL 关键字是______ TABLE DROP ★★★ SELECT 语句中,用于设置行筛选条件的子句是______ WHERE ★★★ SELECT 语句中,用于分组统计的子句是______ GROUP BY ★★★ SELECT 语句中,用于对分组后结果进行筛选的子句是______ HAVING ★★★ SELECT 语句中,用于对查询结果排序的子句是______ ORDER BY ★★★ ORDER BY 子句中,升序关键字是______,降序关键字是 DESC ASC ★★★ 插入数据的 SQL 关键字是______ INTO INSERT ★★★ 修改数据的 SQL 关键字是______ UPDATE ★★★ 删除数据的 SQL 关键字是______ FROM DELETE
5.数据库中的对象
考频星级 必考挖空考点 标准答案 ★★★ 索引的核心作用是提高数据的______效率 查询 ★★★ 创建索引的 SQL 关键字是______ INDEX CREATE ★★★ 删除索引的 SQL 关键字是______ INDEX DROP ★★★ 视图是从一个或多个基本表导出的______,本身不存储实际数据 虚表 ★★★ 创建视图的 SQL 关键字是______ VIEW CREATE ★★★ 删除视图的 SQL 关键字是______ VIEW DROP ★★★ 存储过程是一组预先编译好的______的集合 SQL 语句 ★★★ 创建存储过程的 SQL 关键字是______ PROCEDURE(procedure) CREATE ★★★ 触发器是由 INSERT/UPDATE/DELETE 等______自动触发执行的特殊存储过程 事件 ★★★ 创建触发器的 SQL 关键字是______ TRIGGER(trigger) CREATE
6.数据库设计
考频星级 必考挖空考点 标准答案 ★★★ 数据库设计的核心阶段:需求分析、______、逻辑结构设计、物理结构设计、数据库实施、运行和维护 概念结构设计 ★★★ 需求分析阶段的核心输出产物是数据流图(DFD)和______ 数据字典(DD) ★★★ 概念结构设计的核心工具是______ E-R 图(实体 - 联系图) ★★★ 逻辑结构设计的核心任务:将 E-R 图转换为______ 关系模式 ★★ 物理结构设计是为逻辑模型选取最合适的______和存取方法 物理存储结构
7.数据库技术的发展
考频星级 必考挖空考点 标准答案 ★★★ 大数据的四大核心特征(4V):Volume(大量)、Velocity(高速)、Variety(多样)、______ Value(低价值密度) ★★★ 数据仓库的四大核心特征:面向主题、集成的、______、反映历史变化 相对稳定(非易失) ★★★ NoSQL 的中文全称是______ 非关系型数据库 ★★★ NoSQL 的四大主流类型:键值数据库、文档数据库、______、图数据库 列族数据库 ★★ 分布式数据库的两大核心特性:数据分布性、______ 逻辑整体性
8.专升本填空超高频必背
- 数据库三级模式:概念模式、外模式、内模式
- 两级映像对应的独立性: 外模式/ 概念模式 保证逻辑独立性, 概念模式/ 内模式保证物理独立性
- 数据模型三要素:数据结构、数据操作、完整性约束
- E-R 图三要素:实体、属性、联系
- 关系三大完整性:实体完整性、参照完整性、用户定义完整性
- 选择、投影、连接运算的核心定义
- 1NF 核心:属性不可再分
- 2NF 核心:消除非主属性对主码的部分函数依赖
- 3NF 核心:消除非主属性对主码的传递函数依赖
- SELECT 语句核心子句:WHERE、GROUP BY、HAVING、ORDER BY
- SQL 数据定义核心关键字:CREATE、ALTER、DROP
- SQL 数据更新核心关键字:INSERT、UPDATE、DELETE
- 视图的本质:虚表
- 数据库设计六大核心阶段:需,概,逻,物,实施,运行维护
- 概念结构设计工具:E-R 图,逻辑结构设计核心:E-R 图转关系模式
- 大数据 4V 特征:大量化,高速化,多样化,低价密度
- NoSQL 四大类型:键值,文档,列族,图
- 数据库系统核心:DBMS,核心人员:DBA
- 关系分解两大原则:无损连接、保持函数依赖
- 触发器的触发事件:INSERT、UPDATE、DELETE
第十章简答题考点
1.超高频必考简答题 TOP20
序号 必考题目 核心得分要点 1 简述数据库系统(DBS)的组成及各部分核心作用 5 大核心组成:数据库(DB,数据存储载体)、数据库管理系统(DBMS,核心软件)、数据库应用系统、数据库管理员(DBA,运维管理)、终端用户 2 详述数据库的三级模式结构及各层级核心作用 三级模式:①内模式(物理级,描述数据物理存储结构与存取方式);②概念模式(逻辑级,全局数据的逻辑结构与约束,唯一);③外模式(用户级,面向用户的局部数据视图,可多个) 3 简述数据库的两级映像技术,以及它们如何保障数据独立性 两级映像:①外模式 / 概念模式映像:对应逻辑独立性,概念模式变化时,只需修改该映像,外模式和应用程序不变;②概念模式 / 内模式映像:对应物理独立性,内模式(物理存储)变化时,只需修改该映像,概念模式和应用程序不变 4 分别解释数据的逻辑独立性、物理独立性,以及对应的保障机制 ①逻辑独立性:数据的全局逻辑结构(概念模式)改变时,用户的局部逻辑结构(外模式)和应用程序无需修改;靠外模式 / 概念模式映像保障;②物理独立性:数据的物理存储结构(内模式)改变时,全局逻辑结构和应用程序无需修改;靠概念模式 / 内模式映像保障 5 简述数据库管理系统(DBMS)的核心功能 6 大核心功能:数据定义功能(DDL)、数据操纵功能(DML)、数据查询功能、数据库运行管理(事务、安全、完整性控制)、数据库建立与维护、数据通信接口 6 简述数据模型的三大组成要素及各要素含义 三要素:①数据结构:静态特征,描述数据库的研究对象类型(表、属性等);②数据操作:动态特征,描述对数据允许的操作集合(增删改查);③数据完整性约束:描述数据的有效性规则,保证数据正确、相容、有效 7 简述 E-R 模型的核心组成要素,以及实体间联系的类型 核心要素:实体(客观存在可区分的事物)、属性(实体的特征)、联系(实体间的关联关系);联系类型:一对一(1:1)、一对多(1:n)、多对多(m:n) 8 简述关系模型的三类完整性约束及各自的规则要求 三类约束:①实体完整性:主键必须非空、取值唯一;②参照完整性:外键的取值要么为空,要么等于对应参照表的主键值;③用户自定义完整性:针对具体业务的约束规则(如非空、唯一、取值范围等) 9 简述关系代数中传统集合运算、专门的关系运算的分类 ①传统集合运算:并、差、交、笛卡尔积,从集合维度操作,以行为单位;②专门的关系运算:选择、投影、连接、除,针对关系场景设计,支持行 + 列的双向操作 10 简述 WHERE 子句和 HAVING 子句的核心区别 3 个核心区别:①作用对象不同:WHERE 作用于基本表 / 视图,筛选行;HAVING 作用于分组后的结果集,筛选组;②执行顺序不同:WHERE 在分组前执行,HAVING 在分组后执行;③聚合函数使用:WHERE 不能用聚合函数,HAVING 可以 11 简述 DROP、DELETE、TRUNCATE 三者的核心区别 4 个核心维度区分:①语句类型:DELETE 是 DML 语句,DROP、TRUNCATE 是 DDL 语句;②删除对象:DELETE 删除指定行数据(可加 WHERE),TRUNCATE 清空整张表数据,DROP 删除表 / 库的结构与数据;③事务特性:DELETE 可回滚,DROP、TRUNCATE 不可回滚;④执行效率:DROP>TRUNCATE>DELETE 12 什么是索引?简述索引的优缺点 定义:索引是对数据表一列 / 多列的值排序的存储结构,用于加速数据查询;优点:加快查询速度、保证数据唯一性、加速表连接、排序、分组操作;缺点:占用额外存储空间、降低数据增删改的效率、增加数据库维护成本 13 简述索引的设计原则 核心原则:①频繁作为查询条件的字段建立索引;②主键、外键必须建立索引;③高选择性(重复值少)的字段建立索引;④避免对大量重复值的字段建索引;⑤避免对频繁更新的字段建索引;⑥小表无需建索引,避免索引冗余 14 什么是视图?简述视图的核心作用 定义:视图是从一个 / 多个基本表导出的虚表,仅存储视图定义,不存储实际数据;核心作用:简化用户操作、提供数据逻辑独立性、实现数据安全保护(屏蔽敏感字段)、支持多角度看待数据、集中分散数据 15 简述视图和基本表的核心区别 核心区别:①本质:基本表是实表,物理存储数据;视图是虚表,仅存储定义;②存储:基本表占用物理存储空间,视图不占用;③操作:基本表可直接增删改查,视图的更新有严格限制;④依赖关系:视图依赖基本表存在,基本表独立存在 16 简述数据库设计的六大核心阶段,以及每个阶段的核心任务 六大阶段(按顺序):①需求分析:分析用户需求,输出数据字典、数据流图;②概念结构设计:设计 E-R 模型,输出全局 E-R 图;③逻辑结构设计:将 E-R 图转换为关系模式,做范式优化;④物理结构设计:设计存储结构与存取路径;⑤数据库实施:建库建表、数据录入、测试;⑥数据库运行与维护:日常运维、备份恢复、性能优化、结构调整 17 简述 E-R 图转换为关系模式的核心规则 核心规则:①实体:直接转换为一个关系模式,实体的属性为关系的属性,实体的主键为关系的主键;②1:1 联系:可合并到任意一端的关系模式;③1:n 联系:合并到 n 端的关系模式;④m:n 联系:必须独立为一个关系模式,属性为两端实体的主键 + 联系自身的属性 18 简述 1NF、2NF、3NF 的核心定义 逐级递进定义:
①第一范式(1NF):关系中的每个属性都是不可再分的原子值,保证属性的原子性;
②第二范式(2NF):在 1NF 的基础上,消除非主属性对主键的部分函数依赖;
③第三范式(3NF):在 2NF 的基础上,消除非主属性对主键的传递函数依赖
19 什么是存储过程?简述存储过程的核心优点 定义:存储过程是预编译的 SQL 语句集合,存储在数据库中,可通过调用重复执行;核心优点:预编译执行效率高、减少网络传输流量、提升数据安全性、实现代码复用、简化业务操作 20 什么是触发器?简述触发器的核心作用与触发时机 定义:触发器是由事件自动触发执行的特殊存储过程,当表发生 INSERT/UPDATE/DELETE 操作时自动触发;核心作用:强制数据完整性约束、实现级联操作、审计跟踪数据变化;触发时机:BEFORE(事件前)、AFTER(事件后)
2.次高频核心简答题
(一)数据库基本概念模块
题目 简答答案 1. 简述数据、数据库定义及数据库核心特征 数据:描述事物的符号记录。数据库:长期存于计算机内、有组织、可共享的数据集合。特征:结构化、共享性高、冗余低、独立性高、由 DBMS 统一管理。 2. 简述数据库系统的核心特点 ① 数据整体结构化(与文件系统本质区别)② 共享性高、冗余度低、易扩充③ 数据独立性高(物理 + 逻辑)④ DBMS 统一控制(安全、完整、并发、恢复) 3. 简述三级模式结构 ① 外模式:用户局部逻辑视图② 概念模式:全局逻辑结构(唯一)③ 内模式:物理存储结构(唯一) 4. 简述两级映像与数据独立性 ① 外模式 / 概念模式映像:保证逻辑独立性
② 概念模式 / 内模式映像:保证物理独立性
(二)数据模型模块
题目 简答答案 1. 层次、网状、关系模型区别与优缺点 层次:树形、一对多、简单高效,但不支持多对多。
网状:网状、多对多、能力强,但复杂难用。
关系:二维表、简单、易操作、数据独立性高。
2. 数据模型按层级分类及应用 ① 概念模型:E-R 图,用于设计
② 逻辑模型:关系 / 层次 / 网状,用于 DBMS
③ 物理模型:描述存储,用于物理设计
3. 面向对象数据模型核心特征 1. 封装性:数据与操作绑定
2. 继承性:子类可继承父类属性与方法
3. 多态性:同一操作不同对象有不同实现
4. 复合对象:支持复杂数据类型
(三)关系数据库理论模块
题目 简答答案 1. 什么是函数依赖?平凡 / 非平凡、完全 / 部分、传递依赖 函数依赖:X 值确定则 Y 值唯一确定(X→Y)。
平凡:Y⊆X;
非平凡:Y⊈X。
完全:X 任意真子集不能决定 Y。
部分:X 真子集可决定 Y。
传递:X→Y,Y→Z,则 X→Z。
2. BCNF 定义及与 3NF 区别 BCNF:1NF 基础上,每个决定因素都含候选码。
3NF:消除非主属性对码传递依赖。BCNF 更严格,消除所有属性对码的部分与传递依赖。
3. 关系模式分解原则 ① 无损连接性:可还原
② 保持函数依赖:依赖不丢失
4. 选择、投影、连接核心区别 选择:筛选行
投影:筛选列
连接:多表按条件合并
5. 关系模式三级模式结构 • 外模式:用户视图,局部逻辑结构
• 概念模式:全局逻辑结构,唯一
• 内模式:物理存储结构,对应存储方式
(四)SQL 语言模块
题目 简答答案 1. SQL 语言核心特点 综合统一、高度非过程化、面向集合、两种使用方式、简洁易学 2. 内连接、左外、右外区别 内连接:只保留匹配行
左外:左表全保留,右表匹配
右外:右表全保留,左表匹配
3. SQL 按功能分类及语句 ① DDL:CREATE、ALTER、DROP
② DML:INSERT、UPDATE、DELETE
③ DQL:SELECT
④ DCL:GRANT、REVOKE
(五)数据库对象模块
题目 简答答案 1. 存储过程与触发器核心区别 存储过程:手动调用,执行业务。
触发器:自动触发(增删改时),保证完整性。
2. 视图更新限制 多表连接、聚合函数、分组、去重、计算列 → 一般不可更新 3. 索引分类 ① 存储:聚集、非聚集
② 列数:单列、复合
③ 特性:主键、唯一、普通
(六)数据库设计模块
题目 简答答案 1. 需求分析任务与方法 任务:明确数据、处理、安全、完整性需求,产出数据流图、数据字典。
方法:调查、访谈、跟班、自顶向下。
2. 概念结构设计方法与步骤 方法:E-R 模型法。步骤:局部 E-R→合并→优化→全局 E-R。 3. 物理结构设计内容 确定存储结构、设计存取路径(索引)、分配存储、评价优化 4. 数据库运行与维护工作 备份恢复、安全完整性控制、性能监控优化、重组重构
(七)数据库技术发展模块
题目 简答答案 1. 大数据 4V/5V 4V:大量、高速、多样、低价值密度
5V:+ 真实性
2. 数据仓库定义及特征 面向主题、集成、稳定、随时间变化的数据集合,支持决策。
特征:主题、集成、稳定、反映历史。
3. OLTP 与 OLAP 区别 OLTP:日常业务、增删改、短事务、实时。
OLAP:分析查询、海量历史数据、决策支持。
4. NoSQL 四大类型及场景 键值:缓存、会话
文档:内容、灵活结构
列族:大数据、存储
图:社交、推荐
5. 关系型与 NoSQL 区别 关系:强事务、固定结构、强一致
NoSQL:灵活、高扩展、高可用、弱一致
6. 分布式数据库特点 物理分布、逻辑统一、高可用、高扩展、透明性、支持分布式事务
(八)专升本简答题答题得分技巧
- 踩点给分优先:优先写核心定义、核心要点,每个要点单独成句,避免大段无结构文字,阅卷老师按关键词踩点给分。
- 规范术语表述:严格使用参考书目标准术语,优先使用「主键、外键、实体完整性、概念模式」等规范表述,避免口语化或非主流别名。
- 先总后分结构:先写核心定义总述,再分点解释,逻辑清晰,方便阅卷老师快速定位得分点。
- 分值对应内容:5 分题写 5 个核心要点即可,10 分题可补充简单示例,不要漏核心得分点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)